Embed Size (px)
Citation preview

Licence Professionnelle Assistant de Projet Informatique –
Développement d'applications e-business
ETUDE, ADAPTATION ET EVOLUTION D'UN
MOTEUR DE RECHERCHE FÉDÉRÉ
RAPPORT DE STAGE
Réalisé par :Sylvain Milanesi
Année 2008-2009 Sujet proposé et suivi par M. Granouillac Bruno


ETUDE, ADAPTATION ET EVOLUTION D'UN
MOTEUR DE RECHERCHE FÉDÉRÉ

Remerciements
Je remercie tout d'abord Bruno Granouillac, Régis Hocdé, Stéphane Debard pour leur
accueil chaleureux, leurs encouragements et leurs conseils avisés.
Un grand merci à Thierry Helmer et Olivier Douarche pour leur aide et leur expertise.
Merci aussi à l'IRD de m'avoir offert de bonnes conditions de stage.
Enfin, je remercie vivement les personnes qui m'ont conseillé et aidé durant le
déroulement du stage et la conception de ce rapport.
Rapport de stage IV

Sommaire
Remerciements.................................................................................................................................4Sommaire.........................................................................................................................................5Table des Figures.............................................................................................................................7Glossaire..........................................................................................................................................8Introduction....................................................................................................................................121- Matériel et méthodes.................................................................................................................13
1-1- Étude de l'existant .............................................................................................................131-1-1- Des informations hétérogènes...................................................................................131-1-2- Un besoin de visibilité et de partage.........................................................................131-1-3- Cahier des charges initial...........................................................................................141-1-4- Cahier des charges révisé..........................................................................................15
1-2- Stratégies envisageables et solution choisie......................................................................151-2-1- Les stratégies.............................................................................................................151-2-2- Étude de faisabilité : sur le plan général....................................................................161-2-3- Étude de faisabilité : sur le plan technique................................................................17
1-3- Étapes et calendrier............................................................................................................181-4- Méthodes de travail...........................................................................................................191-5- Outils utilisés durant le projet...........................................................................................19
1-5-1- Modélisation..............................................................................................................191-5-2- Programmation..........................................................................................................191-5-3- Environnement de développement............................................................................201-5-4- Base de données........................................................................................................20
2- Résultats....................................................................................................................................212-1- Architecture générale.........................................................................................................21
2-1-1- Arborescence des fichiers..........................................................................................212-2- Module Hubble : le module principal................................................................................23
2-2-1- Présentation générale.................................................................................................232-2-2- Relation avec les autres modules...............................................................................242-2-3- Adaptation du code....................................................................................................27
2-3- Le web-service : HubbleClient / HubbleWebservice........................................................292-3-1- Intérêt du web-service...............................................................................................292-3-2- Fonctionnement général d'un web-service................................................................292-3-2- Adaptation du code : nouveautés PHP5....................................................................29
2-4- Module PearDBfinder : interrogation multi-SGBD..........................................................312-4-1- Présentation générale.................................................................................................312-4-2- Présentation d'extraits de code..................................................................................322-4-3- Génération de la documentation................................................................................36
2-5- Gestion d'accès différenciés..............................................................................................372-5-1- Présentation générale.................................................................................................372-5-2- Extraits de code : paramètres de session...................................................................37
3- Limites et évolutions possibles de l'outil...................................................................................394- Conclusion.................................................................................................................................40
Rapport de stage V

5- Références bibliographiques.....................................................................................................415-1- Ouvrages............................................................................................................................415-2- Liens Internet.....................................................................................................................41
6- Annexes.....................................................................................................................................426-1- Évaluation des sites à explorer..........................................................................................426-2- Schéma et diagrammes UML............................................................................................43
6-2-1- Diagramme de séquence : exemple d'appel d'une méthode du web-service.............436-2-2- Diagramme de séquence : recherche via le web-service...........................................446-2-3- Diagramme de séquence : le Coordinateur...............................................................456-2-4- Diagramme de séquence : le Connecteur..................................................................46
6-3 Description du web-service : HubbleWebservice.wsdl......................................................476-4- Module de recherche dans les bases de données...............................................................50
6-4-1- Code réalisé...............................................................................................................506-4-2- Documentation..........................................................................................................50
6-5- Documentations d'installation...........................................................................................516-5-1- Installation du moteur de recherche fédéré...............................................................516-5-2- Installation de phpDocumentor.................................................................................55
Rapport de stage VI

Table des Figures
Illustration 1: Arborescence originale du SIST..............................................................................21Illustration 2: Arborescence d'un module: exemple de Mysqlfinder.............................................22Illustration 3: Interface publique du moteur de recherche fédéré..................................................23Illustration 4: Schéma du fonctionnement générale du module Hubble........................................24Illustration 5: Exemple d'insertion d'une source dans Hubble.......................................................25Illustration 6: Exemple d'un connecteur, la classe PearDBFinder.................................................26Illustration 7: Initialisation de la variable "spip-lang"...................................................................27Illustration 8: La classe unserializeData modifié retourne un tableau vide...................................28Illustration 9: Création du web-service, côté serveur....................................................................30Illustration 10: Création d'un client SOAP et appel d'une méthode..............................................30Illustration 11: Ajout d'une source dans l'administration du module PearDBfinder......................32Illustration 12: Méthode de connexion de la classe BaseMysql du module Mysqlfinder.............33Illustration 13: Méthode de connexion de la classe PearDB du module PearDBfinder................34Illustration 14: Exemple d'une méthode qui utilise la librairie MDB2..........................................35Illustration 15: Méthode GetSelectableDB....................................................................................36Illustration 16: Test pour le choix du fichier de configuration......................................................38Illustration 17: Tableau d'évaluation des exemples de sites à explorer (début).............................42Illustration 18: Tableau d'évaluation des exemples de sites à explorer (fin).................................43Illustration 19: exemple d'un appel de méthode via le web-service..............................................44Illustration 20: Diagramme de séquence : recherche via le web service.......................................45Illustration 21: Diagramme de séquence : le Coordinateur...........................................................46Illustration 22: Diagramme de séquence : le Connecteur..............................................................47Illustration 23: Notice d'installation du moteur de recherche fédéré sur un serveur de l'IRD.......55Illustration 24: Notice d'installation de phpDocumentor sur un serveur de l'IRD.........................57
Rapport de stage VII

Glossaire
Les mots définis ci-dessous sont marqués d'un astérisque (*) dans le rapport.
Apache (Diminutif de The Apache HTTP Serveur) : Serveur de page web réputé et très
répandu. Il est diffusé sous une licence Apache, apparentée aux logiciels libres.
CIRAD (Centre de coopération Internationale en Recherche Agronomique pour le
Développement) : Établissement Public à Intérêt Commercial (EPIC) dont la mission
première est de "contribuer au développement rural des régions chaudes, par des
recherches et des réalisations expérimentales, principalement dans les secteurs
agricoles, forestiers et agroalimentaires".
CMS (Content Management System) : Les systèmes de gestion de contenu
appartiennent à une famille de logiciels destinés à la conception et à la mise à jour
dynamique de site web ou d'application multimédia.
Connecteur (élément de Hubble) : Script contenu dans le module* Hubble qui lui
permet d'utiliser et récupérer le résultat d'une recherche effectuée par un autre module*.
CSS (Cascading Style Sheets) : Langage de description de mise en forme qui permet de
définir les règles de mise en page d'un document HTML. Son but est de séparer le
contenu de la présentation.
DSI-IS (Direction des Systèmes d'Information – Informatique Scientifique) : l'IS est un
service de l'IRD* dont la mission est l'organisation, la gestion ou le traitement de
données scientifiques à l'aide d'outils numériques. Il a un rôle d'appui et de conseil
auprès de unités de recherche.
GPL (General Public Licence) : Accord qui réglemente la distribution des logiciels
libres. Selon cet accord, chaque personne est libre de diffuser, de commercialiser et de
modifier un logiciel libre dès qu'elle garantit l'accès au code source et qu'elle respecte
Rapport de stage VIII

les droits d'auteur.
Hubble (module* du SIST*) : Module principal du SIST*, il contient le moteur de
recherche fédéré proprement dit. Capable de faire des recherches sur les sources ayant
un formulaire accessible sur le web, il peut aussi utiliser un autre module* par
l'intermédiaire d'un connecteur*.
IRD (Institut de Recherche pour le Développement) : Établissement Public à caractère
Scientifique et Technologique (EPST), placé sous la tutelle des ministères de la
Recherche et des Affaires Étrangères. Il conduit des missions de recherche sur les axes
suivant : environnement et grands écosystèmes, l'agriculture en milieux tropicaux
fragiles, l'environnement et la santé, les hommes et les sociétés en mutation.
LDAP (Lightweight Directory Access Protocol) : Protocole standard permettant de
gérer des annuaires, c'est-à-dire d'accéder à des bases d'informations sur les utilisateurs
d'un réseau.
Module (du SIST*) : Élément constitutif du SIST* qui permet de faire une recherche
sur un type de données (web, base de données, flux RSS*...). Un module possède ses
propres interfaces publiques et d'administration mais peut aussi interagir avec Hubble*,
le module principal.
PEAR / MDB2 (PHP Extension and Application Repository ) : PEAR est une collection
de bibliothèque PHP qui permet d'avoir accès, sans les re-développer, à des fonctions
utiles pour un site web. MDB2 est une bibliothèque PEAR qui met en place une couche
générique d'accès aux données indépendante du SGBD* utilisé.
PHP4 / PHP5 : PHP est un langage de programmation Open Source dont la principale
application se situe au niveau de la gestion de sites web dynamiques. Les différences
notables entre PHP4 et PHP5 sont la prise en charge complète du développement
orienté objet et une refonte de la prise en charge du XML*.
PHPDocumentor (ou phpdoc) : Outil d'auto-documentation du code pour le PHP. De la
Rapport de stage IX

même façon que Javadoc, il permet à partir de commentaires formatés de générer
automatiquement une documentation complète dans différents formats (html, pdf...).
RSS (Really Simple Syndication) : Désigne une famille de formats XML* souvent
utilisés pour des échanges de contenu web.
SGBD (Système de Gestion de Base de Données) : Outil informatique qui permet
d'insérer de modifier et de rechercher efficacement des données spécifiques dans une
base de données.
SIG (Systèmes d'Information Géographique) : Logiciels permettant de gérer des
informations géographiques. Ce sont des systèmes pour la saisie, le stockage,
l'extraction, l'interrogation, l'analyse, le traitement et l'affichage de données localisées.
SIST (Système d'Information Scientifique et Technique) : Projet de coopération du
ministère français des Affaires Étrangères, piloté par le CIRAD*. Il vise à désenclaver
la recherche africaine, à promouvoir une dynamique de l’expertise et à mettre la science
africaine au service du développement durable. SIST se décline en trois volets : la mise
en place d’un système d’informations dans chaque pays partenaire du projet, la création
de réseaux d’expertise sur des thèmes prioritaires, la formation et le transfert
d’expertise.
SOAP : Protocole basé sur XML* utilisé par les web-services*. Il autorise à un objet
d'invoquer des méthodes d'objets physiquement situés sur un autre serveur.
SQL (Structured Query Language) : Langage de définition, de manipulation et de
contrôle de données, pour les bases de données relationnelles.
SSH (Secure SHell) : Protocole qui permet de se connecter à une machine distante avec
une liaison sécurisée. Les données sont cryptées entre machines. Il permet d'exécuter
des commandes sur un serveur distant.
SVN (Contraction de SubVersioN) : Système de gestion de versions qui permet de
Rapport de stage X

conserver un historique de chaque fichier d'un projet. SVN est un logiciel libre.
UML (Unified Modeling Langage ou langage de modélisation unifié) : Langage
graphique de modélisation des données et des traitements.
Web-service : Principe de développement qui permet à un client de demander une
action à un serveur via le protocole SOAP*.
WSDL (Web Service Description Language) : Document XML* qui décrit les méthodes
proposées par un serveur web-service.
XML (eXtensible Markup Language) : Langage de balises permettant de manipuler des
données définis dans une arborescence.
XSLT (eXtensible Stylessheet Language Transformation) : Langage dédié à la
transformation de données XML. Il permet convertir un document XML en un nouveau
format (HTML par exemple).
Rapport de stage XI

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
Introduction
L'Institut de Recherche pour le Développement (IRD) est un Établissement Public à
caractère Scientifique et Technologique (EPST), placé sous la tutelle des ministères de
la Recherche et des Affaires Étrangères. Près de 2600 personnes y travaillent en
métropole, dans les DOM-TOM et dans 26 pays de la zone intertropicale.
L'un des enjeux majeurs pour l'IRD* est d'assurer la pérennité des données scientifiques
produites. Un des axes de travail consiste à favoriser l'indexation et le catalogage des
jeux de données produits et proposer des outils permettant de rechercher et d'identifier
l'existence de ces données.
C'est dans ce cadre que la DSI-IS* – service transversal de l'IRD* qui a un rôle de
conseil et d'appui auprès des unités de recherche – souhaite mettre en place un outil
fonctionnel à disposition des unités, permettant de diffuser, partager et mutualiser leurs
informations scientifiques.
L'objectif de ce stage de 3 mois et demi (du 9 mars au 19 juin 2009) est d'étudier la
faisabilité et l'impact de la mise en place d'un moteur de recherche fédéré capable de
faire des requêtes sur les données des différentes unités de recherche. Grâce à une veille
technologique, l'équipe a pressenti un logiciel libre qu'elle souhaite évaluer puis
éventuellement adapter aux besoins particulier de l'Institut.
Après une présentation des méthodes de travail, nous discuterons des résultats obtenus à
partir de quelques exemples. Nous nous proposons ensuite de faire un point sur les
limites de ce projet et d'aborder quelques évolutions envisageables.
Rapport de stage 12

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
1- Matériel et méthodes
1-1- Étude de l'existant
1-1-1- Des informations hétérogènes
Les données de l'IRD* sont fournies par les unités de recherche dans le cadre de leurs
travaux. Elles sont réparties sur plusieurs bases de données. Plusieurs d'entre elles sont
consultables via des interfaces web. Cependant, certains projets n'ont que des bases de
données sans interface particulière. A travers tous ces systèmes aux technologies
variées, on peut se rendre compte de la richesse et de l'hétérogénéité des informations à
manipuler.
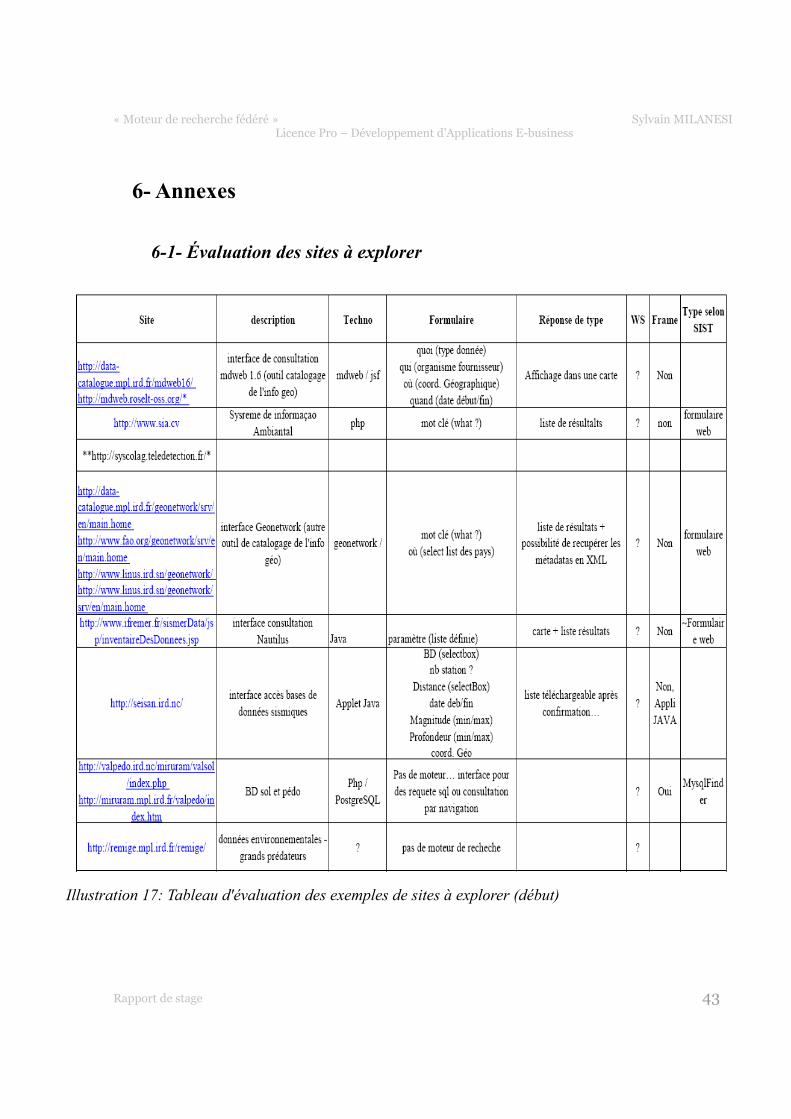
Ainsi, à partir d'un échantillon de sites à fouiller (cf. Annexes §6-1), on remarque que
dans certains cas, les données sont géolocalisées et présentées par des outils tels que
« geonetwork » ou « mdweb ». Ces applications de catalogage SIG* peuvent être
interrogées avec plusieurs critères par l'intermédiaire de web-services*. Dans d'autres
cas, les données sont accessibles via des formulaires web en Java (jsp), ColdFusion
(cfm) ou PHP. Enfin, deux cas particuliers présentent leurs informations à travers une
applet Java ou une interface générée par AdobeSVGViewer (logiciel propriétaire de la
suite Adobe).
Les moteurs de recherche de ces sites utilisent tous le principe de mots clés définissant
« sur quoi » porte la recherche. Cependant pour certains, on peut aussi renseigner : une
période définissant de « quand » datent les informations recherchées ainsi que les
coordonnées géographiques du secteur d'« où » elles proviennent.
1-1-2- Un besoin de visibilité et de partage
Dans l'objectif d'une mise en commun des savoirs de l'IRD*, la DSI-IS* a d'abord
sensibilisé les unités de recherche à l'intérêt de rajouter dans leurs systèmes
Rapport de stage 13

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
d'information (SI) des métadonnées permettant le catalogage - c'est-à-dire d'ajouter des
données normées décrivant les données réellement contenues dans le SI. Ceci, entre
autre, dans l'esprit de la directive européenne INSPIRE qui demande que toutes les
données publiques géolocalisées sur l'Europe soient mises en ligne.
Devant les difficultés et la lenteur de mise en place d'une telle démarche, et aussi parce
que nombre de SI ne sont pas de type géographique, l'IS a exprimé le besoin d'un outil
palliatif, léger, facile à mettre en œuvre et capable d'interroger des SI hétérogène. C'est
le rôle du moteur de recherche fédéré qui doit être développé pendant le stage.
1-1-3- Cahier des charges initial
Après une rapide découverte des possibilités offertes par le SIST* et à partir des attentes
de l'équipe DSI-IS*, le cahier des charges suivant est envisagé :
A/ L'interface web du moteur est un formulaire HTML, mise en forme via un fichier
CSS*. Il contient d'une part les champs de recherche possibles (quoi, où,quand) et de
l'autre, la liste des sites référencés inclus ou non dans une recherche.
B/ Chaque site référencé est défini et paramétré via une autre interface réservée à
l'administrateur. Il doit pouvoir les ajouter, les supprimer ou les modifier. C'est aussi via
ce formulaire que sera fait la correspondance entre le moteur et le site référencé –
notamment pour le nom des champs de recherche et les types de données.
C/ Pour découpler le moteur d'un CMS*, les interfaces sont « embarquées » dans l'outil
et intégrables dans des pages HTML.
D/ Le moteur doit être capable de générer un fichier XML* de sortie, à partir des
informations d'entrées suivantes : un ou plusieurs mot clés, des données d'emplacement
géographique (latitude et longitude min/max) et une période (date de début, date de fin).
E/ Le fichier de résultats doit contenir des informations de type : hyperlien de
Rapport de stage 14

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
consultation, titre, auteur, description et degré de pertinence.
F/ Le moteur est capable de faire des requêtes sur des sites web (soumission
automatique de formulaires), sur des web-services* d'informations géolocalisées CSW
(Catalogue Service Web) ou sur des bases de données (MySql ou Postgres).
1-1-4- Cahier des charges révisé
Au cours du projet, avec une meilleure vision des types d'accès aux données à explorer,
il a fallu en affiner les objectifs.
Ainsi ont été abandonnées la recherche multi-critères (mot clé et coordonnées
géographiques) et la consommation de web-service* CSW. En revanche, l'effort s'est
porté sur l'interrogation de base de données, indépendamment des SGBD*.
Il est aussi apparu nécessaire de pouvoir gérer des recherches sur des données en accès
réservé, donc de mettre en place un système de gestion de plusieurs configurations.
1-2- Stratégies envisageables et solution choisie
1-2-1- Les stratégies
On trouve sur la toile des outils permettant de faire des recherches ciblées, on peut
notamment donner l'exemple de la personnalisation du moteur de Google (CSE) qui
permet de limiter les domaines sur lesquels s'applique la recherche. Ces outils sont
souvent simples à mettre en place, cependant, ils ne conviennent que dans le cas où les
informations à fouiller sont accessibles sur Internet, ce qui n'est pas le cas de toutes les
données de l'IRD*.
La solution d'un logiciel propriétaire de recherche a été exclue par l'équipe DSI-IS* qui,
dès l'offre de stage, a marqué une volonté forte pour que les développements issus de ce
Rapport de stage 15

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
projet soient déposés sous licence libre. D'abord pour mieux appréhender ces outils
ouverts, d'en comprendre les potentialités comme les limites d'utilisation; ensuite pour
éviter le risque de la "boite noire" d'une solution commerciale.
Utiliser et adapter un logiciel libre a été considéré comme la solution la plus en
adéquation avec les attentes et les besoins de l'équipe. Elle permet à la DSI-IS* d'avoir à
la fois un outil ajusté à son environnement, de pouvoir palier à l'hétérogénéité de ses
sources de données et de contribuer à l'évolution d'un projet Open Source. C'est dans ce
sens que l'équipe a marqué son intérêt pour le SIST*, un moteur de recherche fédéré
développé par le CIRAD*, un autre organisme de recherche.
Enfin, le développement d'une nouvelle solution propre à l'IRD* a paru peu
souhaitable :
- d'une part, l'analyse et la conception d'un moteur de recherche fédéré prendrait bien
plus de temps que les trois mois de ce stage.
- d'autre part, refaire un outil - ayant les qualités du SIST* par exemple - demanderait
sans doute, aussi, un effort financier qui ne semble pas pertinent.
1-2-2- Étude de faisabilité : sur le plan général
Le début du stage est consacré à l'évaluation générale de l'application du CIRAD* pour
tenter de mesurer la faisabilité et la difficulté de son adaptation au contexte de l'IRD*.
A l'issue de cette brève étape, il est apparu que le SIST* offre de nombreux avantages :
- D'abord d'un point de vue pratique: des manuels d'installation, d'utilisation et même
une documentation technique sont consultables. De plus, l'IRD* a un contact avec le
référent du projet SIST* pour le CIRAD*, Thierry Helmer, et par son intermédiaire
avec Olivier Douarche, le concepteur de l'application.
Rapport de stage 16

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
- Ensuite, d'un point de vue technique, le SIST* est constitué d'un ensemble de
modules* dont chacun est considéré comme indépendant mais capable d'interagir avec
les autres modules*. Ceci permet de ne choisir et modifier que les éléments intéressants
pour notre projet. Autre fait encourageant, le code est orienté objet ou suit des normes
de développement pour palier au fait que PHP4* n'est pas un langage objet. Enfin les
classes sont documentées à la manière des générateurs de documentation automatique et
sont riches en commentaires.
1-2-3- Étude de faisabilité : sur le plan technique
La simple installation de l'outil du CIRAD* sur les serveurs de l'IRD* est impossible
pour deux raisons majeures :
- développée en PHP4*, son comportement n'est pas garanti sur les serveurs PHP5* de
l'Institut,
- l'application est couplée à un CMS* différent de celui du site de la DSI-IS*. Spip-
Agora est de plus incompatible avec PHP5* et obsolète (il n'est plus maintenu depuis
mai 2008).
Ces obstacles peuvent néanmoins être contournés en modifiant le code afin de le rendre
compatible avec PHP5* et en modifiant les interfaces pour supprimer Spip-Agora.
D'un point de vue langage, une consultation du livre « PHP5 avancé » (cf. §5-1)
rassure : « La compatibilité avec PHP4* a été l'une des préoccupations majeures durant
le développement de PHP5 » (chap. 30, p 793). Cependant des différences notables
entre les versions 4 et 5 de PHP sont susceptibles d'impacter le SIST* :
- Impact limité par l'intégration de la programmation objet par PHP. Des éléments ont
simplement été ajoutés dans la liste de mots réservés (ex : interface, instanceof, final,
public...). Il faut vérifier par une recherche dans tout le code de l'application que ces
Rapport de stage 17

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
mots ne sont pas utilisés.
- Impact plus important avec la refonte de la gestion du XML*. En effet, ce langage est
beaucoup utilisé par Hubble*, le module* principal du SIST*. On peut citer comme
exemples : les échanges de résultats de recherche avec les autres modules* qui se font
au format RSS*; l'affichage des résultats qui est fait via des fichiers de mise en forme
XSLT*; ou encore, le web-service* dont les librairies spécifiques qu'il utilise pour la
prise en charge du SOAP* deviennent inutiles.
Le couplage du SIST* avec le CMS* Spip-Agora est faible, comme cela est précisé
dans sa documentation technique. Ainsi, chaque module* gère ses propres affichages
dans des objets qui sont appelés par le CMS*, et seules quelques lignes dans les fichiers
de paramétrage des modules* sont à modifier pour ne plus utiliser SPIP.
Enfin, une question plus technico-pratique doit être résolue. Pour installer le moteur de
recherche fédéré, le serveur qui l'héberge doit contenir, outre PHP, des librairies ou des
extensions telles que PEAR*, MDB2* ou PHP-CURL. Or, le site de la DSI-IS* est
hébergé et administré par un autre service de la DSI qui ne souhaite pas, pour des
raisons internes, y apporter de modifications. Pour palier à cela, l'utilisation de
l'interface client du web-service* peut être utilisée sur le site principal et interroger ainsi
le moteur qui serait installé, lui, sur un autre serveur hébergé et administré par l'IS.
1-3- Étapes et calendrierPour mener à bien le projet du stage défini ci-dessus, les étapes suivantes sont mises en
place :
● Semaines 1 à 3 (du 9/03 ou 27/03) :
○ prise en main, lecture de la documentation
○ découplage du moteur et du CMS* (conservation des modules* utiles)
○ mise en place du web-service*
● Semaines 4 à 7 (du 30/03 au 24/04) :
Rapport de stage 18

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
○ rétro-ingénierie du SIST*, établissement de diagrammes UML* et schéma général
○ passage à PHP5*
● Semaines 8 à 12 (du 27/05 au 29/05) :
○ développement d'un nouveau connecteur*
○ génération de la documentation avec PHPDocumentor*
○ tests sur des bases réelles
● Semaines 13 à 15 (01/06 au 19/06) :
○ documentation pour les installations (moteur et PHPDocumentor*)
○ ajout d'une gestion base privée/base publique
1-4- Méthodes de travailLe déroulement de ce projet dépend d'éléments inconnus, comme par exemple le temps
nécessaire à adapter l'ancienne application à PHP5*. Pour palier à cela et optimiser le
déroulement du stage, chaque étape est ponctuée d'une réunion avec le responsable du
stage pour faire le point et définir les priorités de l'étape suivante.
Par ailleurs, je bénéficie d'une grande autonomie pour découvrir les éléments utiles pour
ce projet. Par exemple dans la prise de contact avec les interlocuteurs du CIRAD* ou
des équipes de recherche.
Enfin des échanges informels permettent d'obtenir des informations plus générales. Par
exemple sur l'organisation et l'environnement de l'IRD* ou sur les relations entre la
DSI-IS* et les équipes de recherche ou encore sur le rôle de la DSI et de l'IS.
1-5- Outils utilisés durant le projet
1-5-1- Modélisation
PowerAMC est un logiciel de modélisation produit par la société Sybase. Il permet de
Rapport de stage 19

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
modéliser en UML* mais aussi suivant la méthode Merise. Il a permis d'établir des
diagrammes de classes, et des diagrammes de séquences systèmes pour mieux
appréhender le fonctionnement de Hubble*.
1-5-2- Programmation
L'édition et la modification du code sont faites avec jEdit. Cet éditeur de texte écrit en
Java, a pour avantages d'être multiplateforme et diffusé sous licence GPL*. De plus,
grâce à ses extensions « Project Viewer » et « PHPParserPlugin », il peut afficher
l'arborescence d'un projet et afficher une arborescence des méthodes d'un objet.
Les ajouts et modifications de code sont suivis par Subversion (SVN*). Ce logiciel libre
est un système de gestion de versions qui permet de conserver un historique de chaque
fichier d'un projet.
1-5-3- Environnement de développement
Les développements sont d'abord effectués « en local » sur une machine équipée de
Windows XP pro sur laquelle est installé WampServer. Ce logiciel libre permet
d'installer rapidement un serveur web (avec Apache*, PHP et MySql) sur une machine
Windows.
Ils sont ensuite portés sur un serveur virtualisé equipé de Linux CentOs accessible avec
un client SSH* (ex : Putty). Les opérations sont passées en lignes de commande.
Les mise à jour du code se font via le dépôt SVN*. Elles sont exportées de la machine
locale par la commande « commit », puis importée sur le serveur par la commande «svn
update ».
1-5-4- Base de données
Les systèmes de gestion de base de données (SGBD*) manipulés dans ce projet sont :
Rapport de stage 20

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
Mysql 5.0 et PostgreSQL 8.1. Ce sont deux logiciels libres qui représentent les SGBD*
relationnels les plus utilisés sur le web. Ils répondent aux normes du langage SQL*.
Rapport de stage 21

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
2- Résultats
2-1- Architecture générale
2-1-1- Arborescence des fichiers
La structure de fichier est reprise de celle du SIST* présentée ci-contre. En revanche,
tous les fichiers et répertoires qui concernent le
CMS* sont supprimés. De même pour les
modules* inutilisés dont le passage à PHP5* n'est
pas assuré.
Les répertoires qui restent présents à la racine
sont :
● afficher/ : contient les CSS* et images utilisés par le moteur
● infos/ : contient les fichiers de configuration d'accès aux bases de données qui était contenu dans ecrire/
● modules/ : contient les répertoires des modules* utilisés
Chaque module* a une structure incitant à respecter un développement en couches dont
la nomenclature est définie par des conventions de développement (c'est ce qui ressort
de la documentation mais ces conventions ne sont pas disponibles). Un module*
possède ses propres interfaces de recherche et d'administration. Il peut aussi, comme
nous le verrons plus loin, être « utilisé » par Hubble*.
Rapport de stage 22
Illustration 1: Arborescence originale du SIST

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
On peut comprendre à partir de l'exemple ci-dessus qu'un module* se trouve dans le
dossier modules/. Il est contenu dans un répertoire NomModule (ici Mysqlfinder). Y
sont présents au moins les fichiers suivants :
● NomModule.sql : contient les requêtes SQL* nécessaires à la création du module* dans la base utilisée par le SIST*
● NomModuleParam.inc : définie des paramètres nécessaires au fonctionnement du module*
● NomModule.php : classe coordinatrice qui gère la partie publique du module*
● NomModuleAdmin.php : classe coordinatrice qui gère la partie administration du module*
Les classes de traitement sont dans le répertoire Metier/ et peuvent utiliser des fichiers
du répertoire Include/. Les dossiers Template/ et Style/ contiennent les fichiers .html
et .css utilisés pour l'affichage.
Rapport de stage 23
Illustration 2: Arborescence d'un module: exemple de Mysqlfinder

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
Enfin, l'outil est multilingue. Le répertoire Langue/ contient des fichiers de type
NomModule_FR qui définissent (ici pour le français) tous les textes affichés dans les
interfaces publiques ou d'administration.
2-2- Module Hubble : le module principal
2-2-1- Présentation générale
Hubble* est le module* principal du SIST*. Il contient le moteur de recherche fédéré à
proprement parler. Il utilise les autres modules* pour effectuer des recherches sur
différents types de sources (site web, archives ouvertes, flux RSS*). Il permet de
présenter et sélectionner ces sources comme on le voit dans l'illustration suivante. Il
peut aussi les classer par thème, par type de connecteur* ou en y appliquant des filtres.
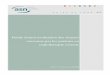
Hubble* reçoit la requête du client (mot clé et sources), issue de l'interface publique ou
du web-service*. Il détermine les connecteurs* à utiliser, parallélise les recherches,
rassemble les résultats puis les affiche ou les retourne. Le schéma ci-dessous permet de
Rapport de stage 24
Illustration 3: Interface publique du moteur de recherche fédéré
« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
mieux comprendre son rôle central.
Pour bien appréhender le fonctionnement de ce module*, des diagrammes UML* établis
par rétro-ingénierie sont consultables en annexes (cf. §6-2).
2-2-2- Relation avec les autres modules
Comme nous l'avons vu précédemment chaque modules* possède ses propres
interfaces. Ainsi les sources utilisant le même module* y seront intégrées. Pour pouvoir
les utiliser, Hubble* les intègre aussi en leur associant un connecteur*. L'illustration
Rapport de stage 25
Illustration 4: Schéma du fonctionnement générale du module Hubble
« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
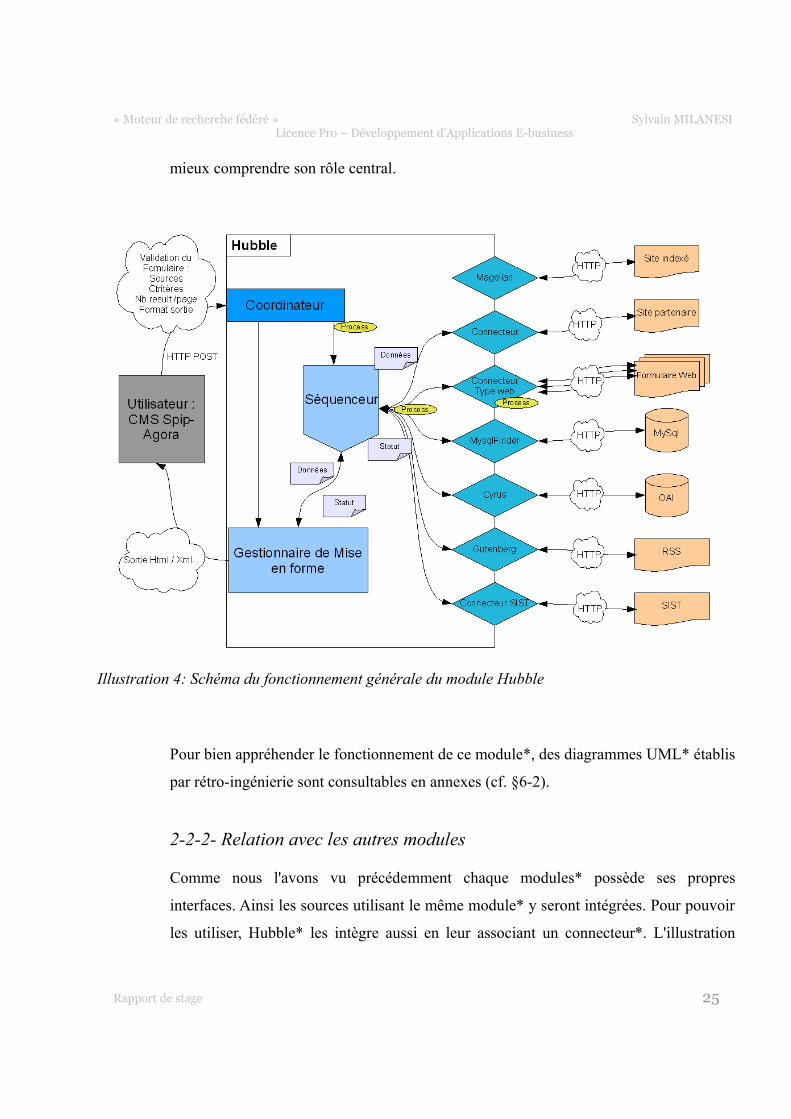
suivante en donne un exemple, le champ « catégorie de la source » correspond au
connecteur* à appliquer.
ConnecteurWeb est le connecteur* principal de Hubble*. Il contient toutes les méthodes
utilisées par le moteur. Les autres connecteurs* héritent de ConnecteurWeb et
redéfinissent les méthodes search() et searchSingle(). Ces méthodes permettent
d'interroger les autres modules* et de récupérer les résultats. L'interrogation est faite en
HTTP en utilisant la fonction curl de PHP. Les résultats sont transmis au format RSS*
puis retransformés en tableau pour Hubble*. Un exemple est donné ci-dessous avec le
connecteur* du module* PearDBfinder.
Rapport de stage 26
Illustration 5: Exemple d'insertion d'une source dans Hubble

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
Rapport de stage 27
Illustration 6: Exemple d'un connecteur, la classe PearDBFinder

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
Cet exemple montre aussi l'une des difficultés récurrentes du passage à PHP5*:
l'encodage en UTF8. En effet, les manipulations de données avec PHP5* sont par défaut
en UTF8 pour certaines fonctions. Comme certaines données dans le système de l'IRD*
sont encodées en ISO8859-1 (ou LATIN-1), il est nécessaire d'utiliser les fonctions
utf8_encode() et utf8_decode().
2-2-3- Adaptation du code
Hubble* gère ses propres interfaces, le couplage de ce module* avec un CMS* se limite
à la modification du fichier de paramétrage HubbleParam.inc. En effet, Spip-Agora
définissait une variable de langue, récupérée par Hubble* pour en faire une variable
globale. Une modification dans le paramétrage permet de récupérer cette variable de
langue directement du navigateur et ainsi la redéfinir comme le montre l'illustration ci-
après.
Le passage à PHP5* n'a pas nécessité beaucoup de modification du code. Cependant
quelques modifications de comportement de certaines fonctions rendaient l'application
inutilisable. Voici un exemple avec la fonction unserialize(). Cette fonction est utilisée
par Hubble* pour récupérer les items d'un résultat de recherche préalablement stocké
dans un fichier temporaire.
Rapport de stage 28
Illustration 7: Initialisation de la variable "spip-lang"

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
Dans la version initiale, on trouve la ligne : return unserialize($core); où $core est une
variable linéarisée. Il semble qu'avec PHP4*, si $core est un tableau vide, unserialize
renvoie un tableau vide. Or, avec PHP5*, la fonction retourne False. Le code a évolué
pour tester le retour et renvoyer un tableau vide si nécessaire.
Enfin, comme évoqué dans le §1-2-3, PHP5* ajoute des « mots réservés ». Hubble*
utilise l'un de ces mots en manipulant l'objet « interface ». Cette classe, commune à tous
les modules*, gère les méthodes génériques des interfaces graphiques des modules*.
Avec PHP5*, ce terme prend le sens Objet en désignant une classe instanciable dont
toutes les méthodes sont vides et redéfinies par les classes qui implémentent l'interface.
Il est par conséquent nécessaire de faire du « refactoring » pour renommer la classe dans
l'application et modifier les autres classes où elle est instanciée.
Rapport de stage 29
Illustration 8: La classe unserializeData modifié retourne un tableau vide

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
2-3- Le web-service : HubbleClient / HubbleWebservice
2-3-1- Intérêt du web-service
La reprise du web-service* pour interroger le moteur de recherche fédéré répond à deux
démarche. Il permet dans un premier temps de mesurer l'impact du passage à PHP5*,
sans tenir compte du CMS*. En effet, le client du web-service* (HubbleClient.php)
n'utilise pas de CMS*, on peut donc évaluer la partie « métier » du moteur en dehors
des problématiques d'affichage. Ensuite, comme on l'a vu plus haut, il permet
d'interroger un moteur de recherche central depuis plusieurs interfaces différentes sans
avoir de difficultés d'installation - seule l'extension PHP-SOAP est nécessaire sur le
serveur client.
2-3-2- Fonctionnement général d'un web-service
Un web-service* représente un mécanisme de communication entre applications
distantes à travers le réseau Internet indépendant de tout langage de programmation et
de toute plate-forme d'exécution. Il fonctionne sur une logique client/serveur. Le
serveur, ou fournisseur, rend accessible par le web des services qu'il décrit suivant un
format standard dans un fichier WSDL*. Le client, ou consommateur du web-service*
connaît l'adresse du fichier WSDL* et ainsi sait quels sont les services qu'il peut
appeler. Les échanges entre le client et le serveur suivent le protocole SOAP*.
2-3-2- Adaptation du code : nouveautés PHP5
Dans sa version en PHP4*, le web-service* devait utiliser des bibliothèques spécifiques
(Nusoap). Avec PHP5*, SOAP* est inclus dans le langage (extension php-soap). Cela
simplifie, comme on peut le voir dans les illustrations suivantes, la création d'un serveur
et d'un client.
Rapport de stage 30

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
En revanche, il faut modifier le web-service* pour tenir compte de l'encodage : les
Rapport de stage 31
Illustration 9: Création du web-service, côté serveur
Illustration 10: Création d'un client SOAP et appel d'une méthode

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
échanges SOAP* ne peuvent se faire qu'avec des données en UTF8. De même, il n'y a
pas de génération automatique du fichier WSDL*, il est donc nécessaire de le créer à la
main (cf. § 6-3 des annexes).
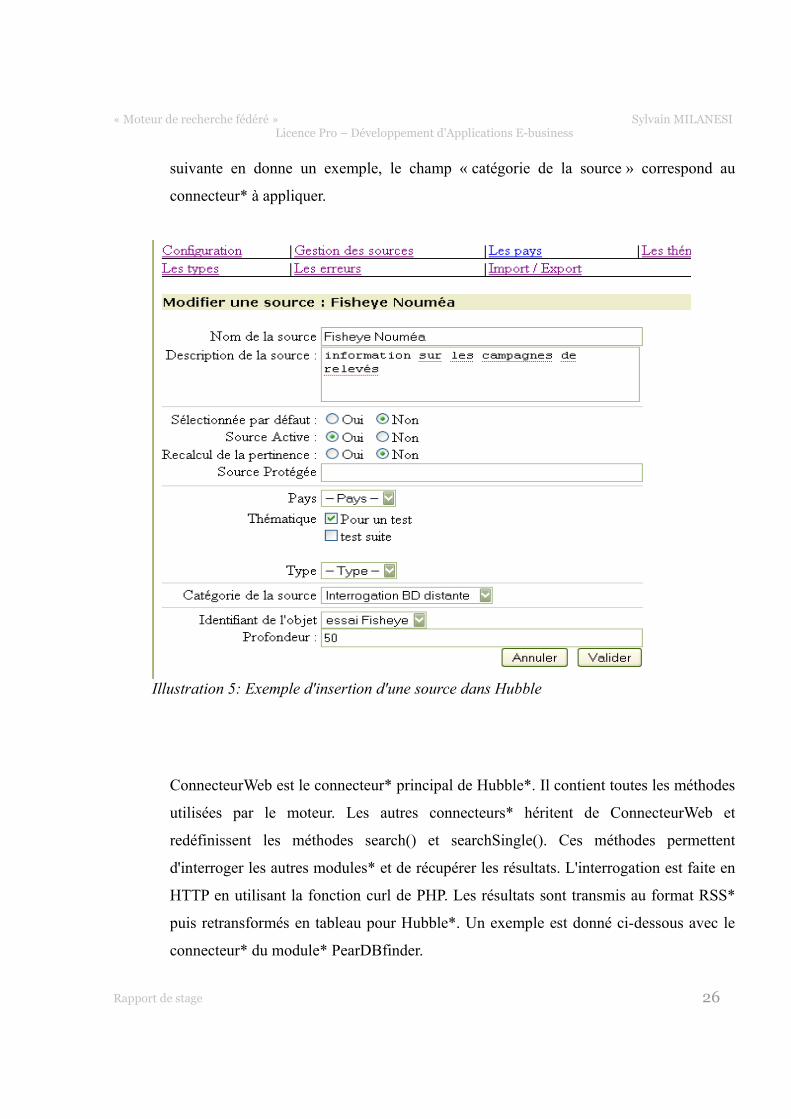
2-4- Module PearDBfinder : interrogation multi-SGBD
2-4-1- Présentation générale
Il existe dans le SIST* un module* d'interrogation de bases de données Mysql or l'IRD*
utilise Postgres pour la plupart de ses bases. Par souci d'obtenir un module* générique,
PearDBfinder - adapté de Mysqlfinder - est indépendant des SGBD*. Pour ce faire, il
utilise les bibliothèques PEAR* et notamment MDB2* qui permet de mettre en place
une couche d'abstraction capable de gérer les connexions suivant le type du SGBD* .
MDB2* utilise ensuite des drivers pour chaque type de base. Si l'on emploie les termes
de « Design Pattern », il se comporte comme une « Fabrique ». Ainsi, comme on le voit
sur l'illustration suivante, l'interface d'administration demande un « type de base » avec
les informations de connexion à la source.
Rapport de stage 32
« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
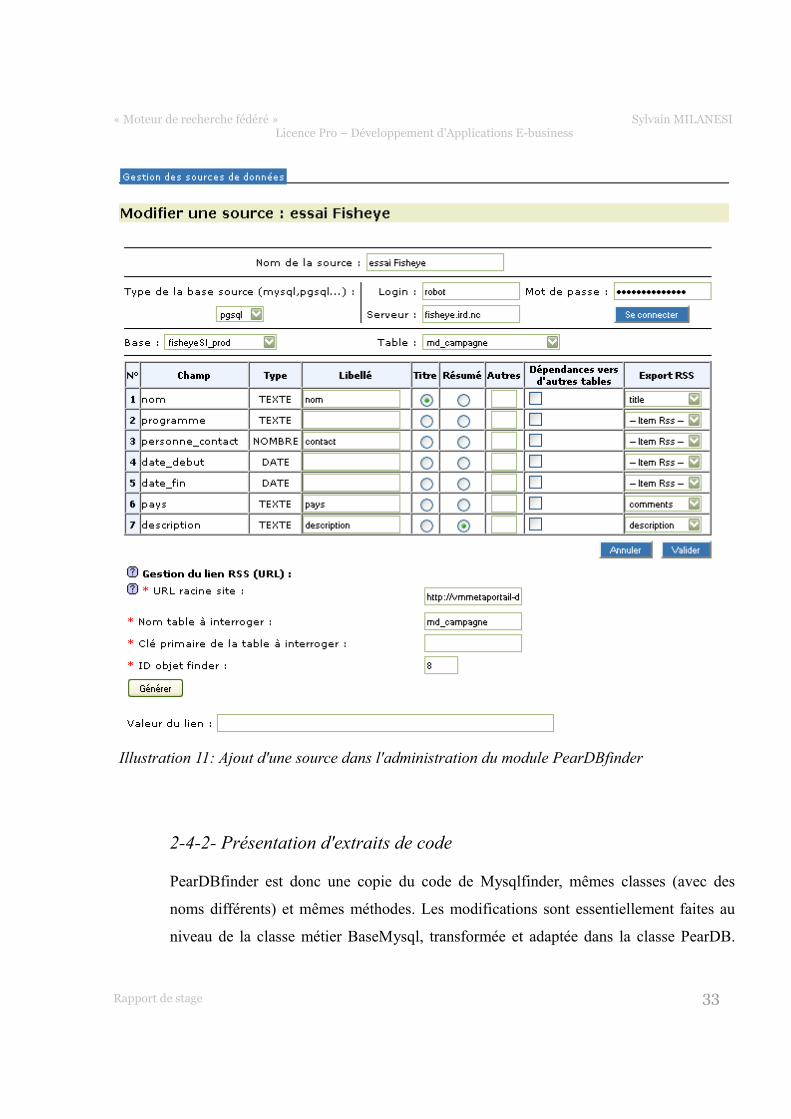
2-4-2- Présentation d'extraits de code
PearDBfinder est donc une copie du code de Mysqlfinder, mêmes classes (avec des
noms différents) et mêmes méthodes. Les modifications sont essentiellement faites au
niveau de la classe métier BaseMysql, transformée et adaptée dans la classe PearDB.
Rapport de stage 33
Illustration 11: Ajout d'une source dans l'administration du module PearDBfinder

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
Ci-dessous, un exemple comparatif de l'adaptation de la méthode de connexion de ces
classes.
Rapport de stage 34
Illustration 12: Méthode de connexion de la classe BaseMysql du module Mysqlfinder

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
De même les méthodes de la classe PearDB utilisent les méthodes définies par MDB2*
comme le montre l'exemple ci-dessous.
Rapport de stage 35
Illustration 13: Méthode de connexion de la classe PearDB du module PearDBfinder

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
Pour gérer la boîte de sélection des types de bases dans le formulaire d'administration,
une méthode GetSelectableDB() est ajoutée à la classe PearDBfinderAdmin qui en fait
l'affichage. Comme on le voit ci-dessous cette classe renvoie simplement la liste des
Rapport de stage 36
Illustration 14: Exemple d'une méthode qui utilise la librairie MDB2

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
bases disponibles. En fait, ce tableau correspond au nom des SGBD* pour lesquels un
driver est installé sur le serveur.
2-4-3- Génération de la documentation
Pour faciliter la prise en main de ce module*, une documentation complète du module*
est générée par PHPDocumentor*. Cependant, ce dernier n'est pas installé par défaut sur
les serveurs de développement de l'IS. Une phase d'installation et la rédaction d'un petit
document d'explication pour pouvoir la répéter facilement était donc nécessaire (cf. § 6-
5-2).
Pour répondre à la demande de l'offre de stage de faire un rendu 100% web, la
documentation est générée au format HTML et mise en ligne sur le serveur. Pour les
besoins de ce rapport, une version PDF est ajoutée aux annexes (cf. § 6-4-2)
Rapport de stage 37
Illustration 15: Méthode GetSelectableDB

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
2-5- Gestion d'accès différenciés
2-5-1- Présentation générale
Les informations utilisées par Hubble* et ses composants sont conservées dans une base
de données MySql. C'est le cas par exemple des coordonnées ou des types de sources.
Certaines données accessibles par le moteur de recherche fédéré sont confidentielles et
les unités de recherche ne souhaitent pas les diffuser largement. Cependant, une
consultation interne à l'IRD* reste envisageable. De plus, l'Institut possède un annuaire
LDAP* qui peut être utilisé pour obtenir une autorisation d'accès.
Pour éviter une double installation du moteur de recherche fédéré, l'un en accès libre et
l'autre avec une authentification, et ainsi alourdir la maintenance du code, le but est de
mettre en place dans Hubble*, un système capable de se connecter à une base
« publique » si le moteur est interrogé sur une URL libre ou à une base « privée » s'il est
interrogé sur une URL protégée.
2-5-2- Extraits de code : paramètres de session
La différence entre les bases est faite par le paramètre « BD » passé en GET (c'est-à-dire
directement dans l'URL). Ce paramètre correspond à un identifiant défini arbitrairement
et généré par la fonction d'encryptage md5(). Le fichier commun.inc définit au
lancement du moteur des variables de session, notamment celles concernant la base de
données utilisée. Comme on le voit ci -dessous, l'ajout dans ce fichier d'un test sur le
paramètre « BD » permet d'appeler la configuration de la bonne base (publique ou
privée).
Rapport de stage 38

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
L'utilisation de la protection des URL directement par le serveur web Apache* était
envisagée pour la sécurisation de la base privée. Ainsi, alors que l'url de la base
publique (http://.../hubble.php) restait en accès libre, celle de la base privée
(http://.../hubble.php?BD=241e535929d41174bc4b33b0e3e5be51) était protégée par
Apache* qui ouvrait l'accès après une authentification.
Malheureusement, renseignement pris auprès de l'administrateur système : « Apache ne
prend pas en compte les variables GET passées en paramètres ». Par conséquent, la
différence entre les URLs ne peut pas se faire seulement sur le paramètre BD. Une
solution est peut-être, au moment de l'identification du paramètre, si l'utilisateur veut
accéder à la base privée, de le rediriger sur une URL différente et protégée (ex:
http://.../accesprivee). Après l'identification, l'utilisateur est de nouveau redirigé sur l'url
Rapport de stage 39
Illustration 16: Test pour le choix du fichier de configuration.

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
de la base privée (http://.../hubble.php?BD=241e535929d41174bc4b33b0e3e5be51).
Cette solution n'a pas été mise en place, sa description reste théorique.
3- Limites et évolutions possibles de l'outil
A la fin de ce stage, un moteur de recherche fédéré, capable de faire des recherches via
des formulaires web ou directement sur des bases de données fonctionne sur un serveur
PHP5*. Cependant, il reste encore beaucoup d'amélioration à y apporter. Assurer le
passage à PHP5* des autres modules* du SIST* permettrait par exemple d'enrichir
rapidement le moteur de plusieurs autres connecteurs* (RSS*, archives ouvertes
OAI...).
De même, le module* PearDBfinder gagnerait en finesse s'il offrait la possibilité
d'exécuter directement des requêtes SQL*. En effet, la version actuelle ne permet que
des recherches sur une table principale sans permettre réellement les jointures. Or, pour
certaines bases de l'IRD*, remonter une information pertinente demande l'exécution de
requêtes complexes.
La mise en place d'une recherche multi-critères prenant en compte les coordonnées
géographiques et des notions de période est une évolution importante qui permettrait de
rendre les recherches plus fines et plus pertinentes. Cependant, avec la pluralité des
sources, un système de « mapping » entre les champs du moteur et ceux de chaque
source doit être mise en place, ce qui rend cette évolution relativement ardue.
Plus simplement, enrichir le moteur de nouveaux connecteurs* et ainsi lui permettre
d'interroger de nouveaux types de données semble être un bon vecteur d'évolution. Par
exemple, un connecteur* capable d'interroger des web-services* CSW (Catalogue
Service Web) pour fouiller des catalogues de données géo-référencées.
Rapport de stage 40

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
4- Conclusion
Rendre visible des informations afin de les partager ou tout simplement de les diffuser
est l'objectif prioritaire du moteur de recherche fédéré mis en place pendant ce stage.
Ainsi, l'ajout de ce module* de recherche dans des bases de données permet d'explorer
simultanément les informations de plusieurs équipes scientifiques qui n'avaient pas
d'autres moyens de diffusion. De même, grâce à son web-service*, les interfaces
« client » peuvent être facilement installées et ainsi contribuer rapidement à améliorer la
visibilité des données.
Mais ce projet m'a aussi permis d'explorer la problématique de la fouille automatique
d'informations et d'en évaluer la complexité. Quelle granularité de l'information est
visée ? Faut-il récupérer la donnée recherchée ou seulement si l'information existe et où
la trouver ? Doit-on essayer de rechercher de façon ouverte dans tous types de données
ou est-il préférable de privilégier l'utilisation d'un protocole et d'une norme
particulière ? Si l'on veut suivre une norme, laquelle choisir ? Voici quelques unes des
questions sous-tendues par la mise en place d'un moteur de recherche.
On se rend compte à travers ces questions que les choix dépendent beaucoup d'un
contexte. Par exemple, le choix d'un protocole suppose que le site exploré par le moteur
sache y répondre. Ce qui veut dire qu'une personne qui s'occupe de ce site, définisse des
données ou des métadonnées spécifiques pour le protocole. Dans le cas contraire, le
choix d'un autre type de recherche s'impose.
D'un point de vue plus personnel, ce stage m'a permis d'acquérir de bonnes
connaissances en PHP5* et d'avoir une meilleure vision du langage objet dans PHP. J'ai
aussi pu entrapercevoir les problématiques de stockage des informations géolocalisées
et des SIG* en général, ce qui a éveillé ma curiosité.
Rapport de stage 41

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
5- Références bibliographiques
5-1- Ouvrages- Eric Daspet, Cyril Pierre de Geyer. PHP5 avancé, 5e édition. Ed. : Eyrolles, 2008, 843 pages
- Olivier Douarche pour Clever-Age / SQLI. Documentation technique, manuels d'utilisation et support de formation du SIST
5-2- Liens Internet- Php : l'extention cURL par julp. Disponible sur http://julp.developpez.com/php/curl/ [en ligne en mars 2009]
- Webservice/SOAP. Les spécifications WebService. Disponible sur
http://www-igm.univ-mlv.fr/~dr/XPOSE2005/rouvio_WebServices/soap.html [consulté en avril 2009]
- Les bases de SOAP. Disponible sur http://www.soapuser.com/fr/basics1.html [consulté en avril 2009]
- PhpDocumentor QuickStart. Disponible sur
http://manual.phpdoc.org/HTMLframesConverter/phpedit/ [consulté en mai 2009]
- Documentation MDB2. Disponible sur
http://pear.php.net/package/MDB2/docs/latest/li_MDB2.html [consulté en avril 2009]
- Tutoriel MDB2. Disponible sur http://hugo.developpez.com/tutoriels/php/pear/mdb2/ [consulté en avril 2009]
- Manuel PHP. Disponible sur http://fr.php.net/manual/fr/index.php [consulté en 2009]
Rapport de stage 42
« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
6- Annexes
6-1- Évaluation des sites à explorer
Rapport de stage 43
Illustration 17: Tableau d'évaluation des exemples de sites à explorer (début)
« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
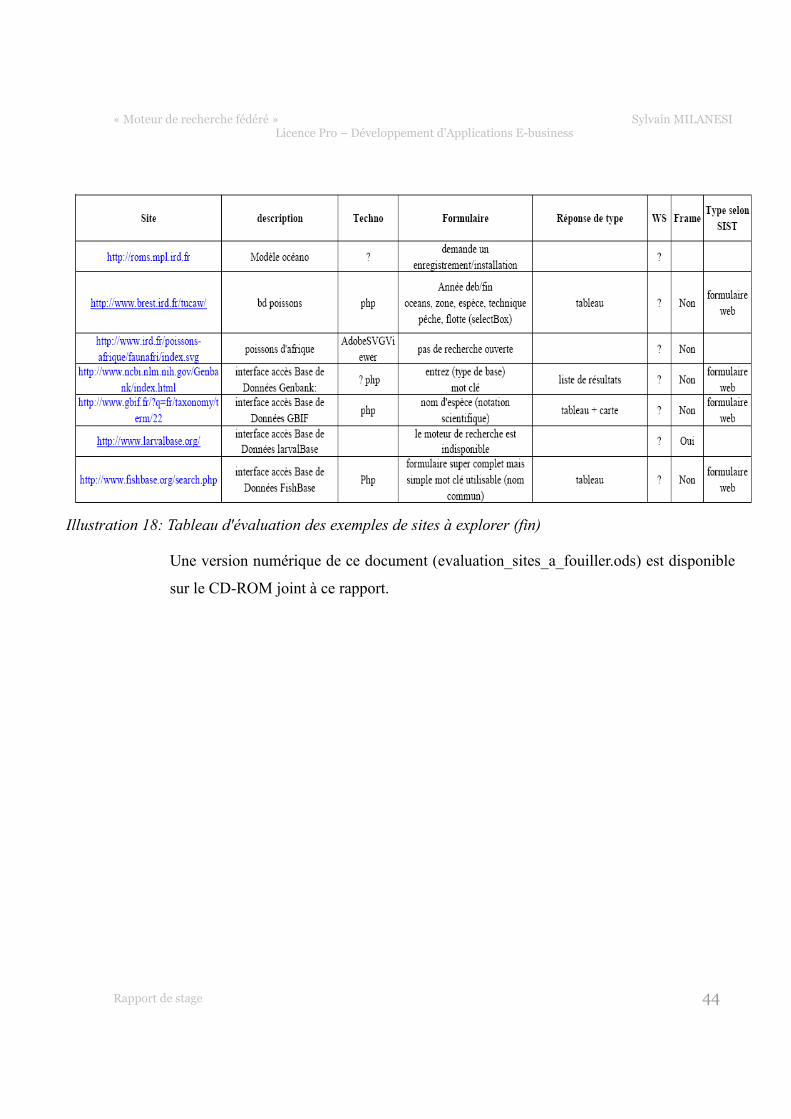
Une version numérique de ce document (evaluation_sites_a_fouiller.ods) est disponible
sur le CD-ROM joint à ce rapport.
Rapport de stage 44
Illustration 18: Tableau d'évaluation des exemples de sites à explorer (fin)
« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
6-2- Diagrammes UML
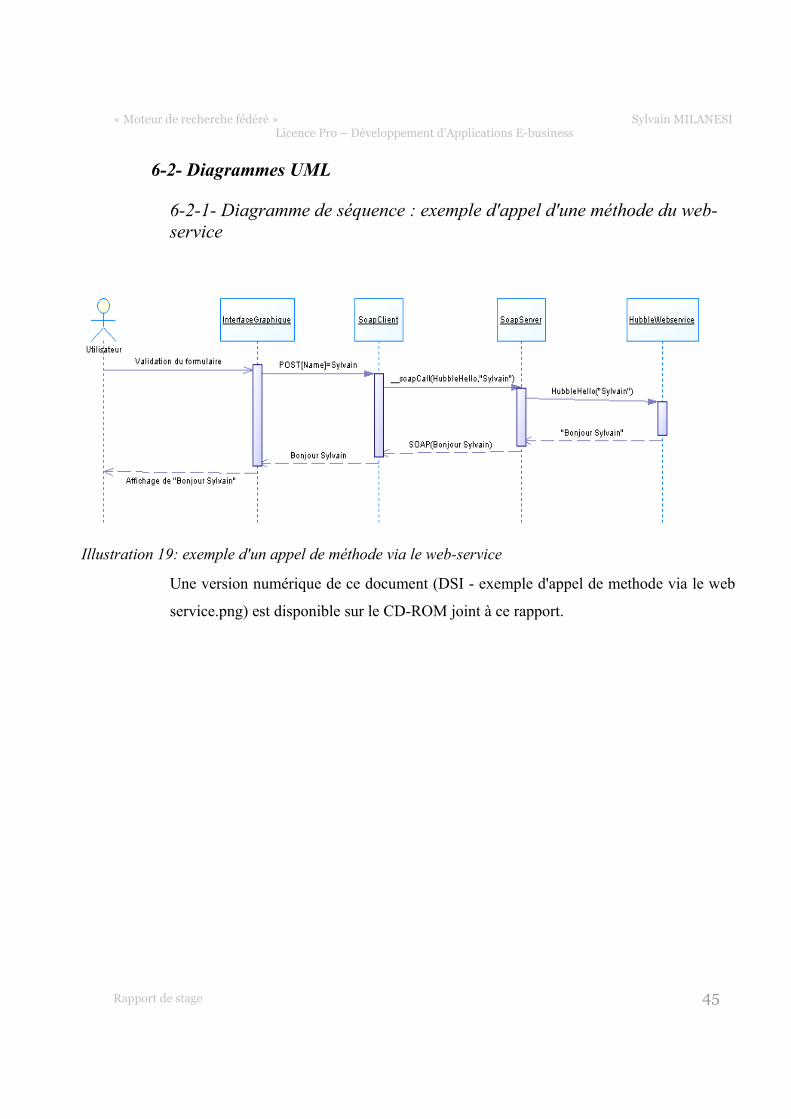
6-2-1- Diagramme de séquence : exemple d'appel d'une méthode du web-service
Une version numérique de ce document (DSI - exemple d'appel de methode via le web
service.png) est disponible sur le CD-ROM joint à ce rapport.
Rapport de stage 45
Illustration 19: exemple d'un appel de méthode via le web-service

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
6-2-2- Diagramme de séquence : recherche via le web-service
Une version numérique de ce document (DSI - Recherche Hubble via un
webservice.png) est disponible sur le CD-ROM joint à ce rapport.
Rapport de stage 46
Illustration 20: Diagramme de séquence : recherche via le web service

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
6-2-3- Diagramme de séquence : le Coordinateur
Une version numérique de ce document (DSS - ProcessFactory_Coordinateur.png) est
disponible sur le CD-ROM joint à ce rapport.
Rapport de stage 47
Illustration 21: Diagramme de séquence : le Coordinateur

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
6-2-4- Diagramme de séquence : le Connecteur
Une version numérique de ce document (DSS - ProcessFactory_Connecteur.png) est
disponible sur le CD-ROM joint à ce rapport.
Rapport de stage 48
Illustration 22: Diagramme de séquence : le Connecteur

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
6-3 Description du web-service : HubbleWebservice.wsdl
Rapport de stage 49
<?xml version="1.0" encoding="ISO-8859-1"?><definitions xmlns:SOAP-ENV="http://schemas.xmlsoap.org/soap/envelope/"
xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:SOAP-ENC="http://schemas.xmlsoap.org/soap/encoding/" xmlns:tns="urn:hubble" xmlns:soap="http://schemas.xmlsoap.org/wsdl/soap/" xmlns:wsdl="http://schemas.xmlsoap.org/wsdl/" xmlns="http://schemas.xmlsoap.org/wsdl/" targetNamespace="urn:hubble">
<types><xsd:schema targetNamespace="urn:hubble">
<xsd:import namespace="http://schemas.xmlsoap.org/soap/encoding/"/><xsd:import namespace="http://schemas.xmlsoap.org/wsdl/"/><xsd:complexType name="Source">
<xsd:all><xsd:element name="source_id" type="xsd:int"/><xsd:element name="source_lib" type="xsd:string"/><xsd:element name="source_description" type="xsd:string"/>
</xsd:all></xsd:complexType><xsd:complexType name="Thematique">
<xsd:all> <xsd:element name="thematique_id" type="xsd:int"/> <xsd:element name="thematique_lib" type="xsd:string"/></xsd:all>
</xsd:complexType><xsd:complexType name="InfosSource">
<xsd:all><xsd:element name="ID" type="xsd:int"/><xsd:element name="TIMEWAIT" type="xsd:float"/><xsd:element name="OPEN" type="xsd:byte"/>
</xsd:all></xsd:complexType><xsd:complexType name="SourceArray">
<xsd:complexContent><xsd:restriction base="SOAP-ENC:Array">
<xsd:attribute ref="SOAP-ENC:arrayType" wsdl:arrayType="tns:Source[]"/>
</xsd:restriction></xsd:complexContent>
</xsd:complexType>

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
Rapport de stage 50
<xsd:complexType name="ThematiqueArray"><xsd:complexContent>
<xsd:restriction base="SOAP-ENC:Array"><xsd:attribute ref="SOAP-ENC:arrayType"
wsdl:arrayType="tns:Thematique[]"/></xsd:restriction>
</xsd:complexContent></xsd:complexType><xsd:complexType name="StringArray">
<xsd:complexContent><xsd:restriction base="SOAP-ENC:Array">
<xsd:attribute ref="SOAP-ENC:arrayType" wsdl:arrayType="xsd:string"/>
</xsd:restriction></xsd:complexContent>
</xsd:complexType><xsd:complexType name="InfosSourceArray">
<xsd:complexContent><xsd:restriction base="SOAP-ENC:Array">
<xsd:attribute ref="SOAP-ENC:arrayType" wsdl:arrayType="tns:InfosSource[]"/>
</xsd:restriction></xsd:complexContent>
</xsd:complexType></xsd:schema>
</types><message name="HubbleListeSourceRequest"/><message name="HubbleListeSourceResponse">
<part name="ListeSources" type="tns:SourceArray"/></message><message name="HubbleListeSourceParThematiqueRequest">
<part name="ListeThematiques" type="xsd:string"/></message><message name="HubbleListeSourceParThematiqueResponse">
<part name="ListeSources" type="tns:SourceArray"/></message><message name="HubbleListeThematiqueRequest"/><message name="HubbleListeThematiqueResponse">
<part name="ListeThematiques" type="tns:ThematiqueArray"/></message><message name="HubbleRechercheRequest">
<part name="ListeSources" type="xsd:string"/><part name="Criteres" type="xsd:string"/><part name="NbResultats" type="xsd:string"/><part name="Page" type="xsd:string"/><part name="Identifiant" type="xsd:string"/>
</message><message name="HubbleRechercheResponse">
<part name="Resultat" type="tns:StringArray"/></message>

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
Rapport de stage 51
<message name="HubbleRafraichitRequest"><part name="Identifiant" type="xsd:string"/><part name="NbResultats" type="xsd:string"/><part name="Page" type="xsd:string"/>
</message><message name="HubbleRafraichitResponse">
<part name="Resultat" type="tns:StringArray"/></message><message name="HubbleInfosSourcesRequest">
<part name="Identifiant" type="xsd:string"/></message><message name="HubbleInfosSourcesResponse">
<part name="InfosSources" type="tns:InfosSourceArray"/></message><message name="HubbleNombreResultatRequest">
<part name="Identifiant" type="xsd:string"/></message><message name="HubbleNombreResultatResponse">
<part name="Nombre" type="xsd:int"/></message><message name="HubbleNameRequest">
<part name="Name" type="xsd:string"/></message><message name="HubbleNameResponse">
<part name="NameResult" type="xsd:string"/></message><portType name="hubblePortType">
<operation name="HubbleListeSource"><documentation>Retourne la liste des sources disponibles a l'interrogation.</documentation><input message="tns:HubbleListeSourceRequest"/><output message="tns:HubbleListeSourceResponse"/>
</operation><operation name="HubbleListeSourceParThematique">
<documentation>Retourne la liste des sources disponibles a l'interrogation pour une liste de thématique passée en paramètre.</documentation>
<input message="tns:HubbleListeSourceParThematiqueRequest"/><output message="tns:HubbleListeSourceParThematiqueResponse"/>
</operation><operation name="HubbleListeThematique">
<documentation>Retourne la liste des thématiques disponibles.</documentation><input message="tns:HubbleListeThematiqueRequest"/><output message="tns:HubbleListeThematiqueResponse"/>
</operation><operation name="HubbleRecherche">
<documentation>Retourne le flux RSS de résultat de la recherche</documentation><input message="tns:HubbleRechercheRequest"/><output message="tns:HubbleRechercheResponse"/>
</operation>

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
Une version numérique de ce document (HubbleWebservice.wsdl) est disponible sur le
CD-ROM joint à ce rapport.
6-4- Module de recherche dans les bases de données
6-4-1- Code réalisé
Une impression papier du code du moteur de recherche fédéré représente un trop grand
volume pour l'ajouter à ce rapport. Une version numérique est enregistrée sur le CD-
ROM joint à ce rapport.
6-4-2- Documentation
La version PDF de la documentation générée fait 87 pages. Pour cette raison, elle n'est
pas reproduite ici mais est disponible, de même que sa version HTML sur le CD-ROM
joint à ce rapport.
Rapport de stage 52
<operation name="HubbleNombreResultat"><soap:operation soapAction="urn:hubble#HubbleNombreResultat" style="rpc"/><input>
<soap:body use="encoded" namespace="urn:hubble" encodingStyle="http://schemas.xmlsoap.org/soap/encoding/"/>
</input><output>
<soap:body use="encoded" namespace="urn:hubble" encodingStyle="http://schemas.xmlsoap.org/soap/encoding/"/>
</output></operation>
</binding><service name="hubble">
<port name="hubblePort" binding="tns:hubbleBinding"><soap:address location="http://localhost/modules/Hubble/HubbleWebservice.php"/>
</port></service></definitions>

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
6-5- Documentations d'installation
6-5-1- Installation du moteur de recherche fédéré
Rapport de stage 53
Installation du moteur de recherche fédéré
Description des étapes d’installation du moteur de recherche fédéré, des librairies nécessaires à son fonctionnement ainsi que des modules qui lui sont liés.Les informations suivantes sont décrites pour la mise en place du moteur sur un serveur Linux CentOS avec un serveur web (type Apache) et un SGBD MySql, et un interpréteur PHP5 déjà installé.La mise en place basique du moteur comprend :
- Préparation de la base de données- Installation des bibliothèques PEAR et MDB2- Installation du module principal (Hubble)- Installation du module de connexion aux BDD (PearDBFinder)
Installation du module principal (Hubble) :
Hubble est le module qui génère l’interface du moteur de recherche fédéré, capable d’interroger plusieurs types de sources en utilisant d’autres modules pour lesquels il possède un connecteur. Seul, ce module peut faire des recherches sur des « formulaire web », c'est-à-dire tout site possédant un formulaire de recherche interne.
Les packages a installer sont : afficher, modules/Commun et modules/Hubble
Pour créer des interfaces d’utilisation, il faut prévoir dans le site utilisateur d’ajouter une page d’administration contenant le code (attention les chemins doivent être adaptés) :
include_once("modules/Hubble/HubbleParam.inc");include_once("modules/Hubble/HubbleAdmin.php");include_once ("modules/Hubble/Langue/Hubble_FR.inc");

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
Rapport de stage 54
(isset($_REQUEST["ACTIONHUBBLE"]))?$opt=$_REQUEST["ACTIONHUBBLE"]:$opt="ACCUEIL";
$obj = new HubbleAdmin($opt);
echo $obj->HtmlCode; (a placer à l’endroit où le formulaire doit apparaître)
De même, la page public contiendra :include_once("modules/Hubble/HubbleParam.inc");include_once("modules/Hubble/Hubble.php");include_once ("modules/Hubble/Langue/Hubble_FR.inc");
(isset($_REQUEST["ACTIONHUBBLE"]))?$opt=$_REQUEST["ACTIONHUBBLE"]:$opt="ACCUEIL";
$obj = new Hubble($opt);echo $obj->HtmlCode; (à placer à l’endroit où le formulaire doit apparaître)
Pour la description de l’utilisation de ce module, voir sur le dépôt svn equipe-is\Actions.IS\sist\documents\CIRAD - SIST - HUBBLE - Manuel d'utilisation - v3.0.5.doc
Un utilisateur public peut interroger le moteur de recherche fédéré de 2 façons :- via l’interface publique décrite ci-dessus- via un client web-service SOAP si celui-ci est installé (description plus loin)
Installation du module de connexion aux BDD (PearDBFinder) :
PearDBfinder est le module de recherche d’information dans des bases de données. Ce module utilise la bibliothèque pear ::mdb2 dont l’installation est détaillé plus loin.
Le package a installer est modules/PearDBfinder. Le module Hubble doit être installé.
Pour créer des interfaces d’utilisation, il faut prévoir dans le site utilisateur d’ajouter une page d’administration contenant le code (attention les chemins doivent être adaptés) :
require_once 'MDB2.php';include_once("modules/Hubble/HubbleParam.inc");include_once("modules/PearDBfinder/PearDBfinderParam.inc");include_once("modules/PearDBfinder/PearDBfinderAdmin.php");include_once ("modules/PearDBfinder/Langue/PearDBfinder_FR.inc");
(isset($_REQUEST["ACTIONPEARDBFINDER"]))?$opt=$_REQUEST["ACTIONPEARDBFINDER"]:$opt="GESTION_SOURCE";
$obj = new PearDBfinderAdmin($opt);echo $obj->HtmlCode; (a placer à l’endroit où le formulaire doit apparaître)

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
Rapport de stage 55
De même, la page public contiendra :include_once("modules/Hubble/HubbleParam.inc");include_once("modules/PearDBfinder/PearDBfinderParam.inc");include_once("modules/PearDBfinder/PearDBfinder.php");include_once ("modules/PearDBfinder/Include/PearDBfinderOutils.inc");include_once ("modules/PearDBfinder/Langue/PearDBfinder_FR.inc");
(isset($_REQUEST["ACTIONPEARDBFINDER"]))?$opt=$_REQUEST["ACTIONPEARDBFINDER"]:$opt="RECHERCHE_SIMPLE";
$obj = new PearDBfinder($opt);echo $obj->HtmlCode; (à placer à l’endroit où le formulaire doit apparaître)
L’utilisation de ce module est la même que celle décrite dans le document du dépôt svn equipe-is\Actions.IS\sist\documents\ CIRAD - SIST - MYSQLFINDER - Manuel d'utilisation - v3.0.4.docLa seule différence est à la création de la source où il faut définir le type de base connectée.
Préparation de la base de données du moteur de recherche fédéré :
Le moteur de recherche fédéré fonctionne avec une base de données MySql. Chaque module contient un fichier .sql contenant les scripts de création des tables qui lui sont nécessaire.
Une fois la base créée et les scripts sql joué, les informations de connexion sont a paramétrer dans le fichier inc_config_metier.php dont la localisation est défini dans le fichier modules/Commun/Commun.inc
Installation des bibliothèques PEAR et MDB2 :
Voici les commandes qu’il faut jouer sur le serveur pour installer MDB2.
Vérification des package pear disponible : yum list "*pear*"Installation du package MDB2 : yum install php-pear-MDB2Installation du driver Mysql : yum install php-pear-MDB2-Driver-mysqlInstallation du driver Postgres : yum install php-pear-MDB2-Driver-pgsqlVérification des paquets installés : rpm -qa|grep pearSi les chemins par défaut des include et open_basedir ne sont pas correctement définis, il faut éditer le php.ini :
vim /etc/php.inimodifier include_path = ".:/usr/lib/php:/usr/share/pear"et open_basedir = /data/www/:/usr/share/pear/:/usr/lib/php/redémarrer apache /etc/init.d/httpd restart

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
Une version numérique de ce document (infos_install_MoteurRechercheFedere.pdf) est
disponible sur le CD-ROM joint à ce rapport.
Rapport de stage 56
Installation du client web-service SOAP :
Il est possible d’interroger le moteur de recherche fédéré en utilisant un client SOAP. Un client utilisable est défini dans le package HubbleClient. Pour ce client, le paramétrage de l’adresse du .wsdl se fait dans modules/Hubble/HubbleParam.inc.
Le package a installer est HubbleClient. Le module Hubble doit être installé sur le serveur appelé.
Illustration 23: Notice d'installation du moteur de recherche fédéré sur un serveur de l'IRD

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
6-5-2- Installation de phpDocumentor
Rapport de stage 57
Installation de PhpDocumentor :
Ce document décrit les étapes à suivre pour installer l’api PhpDocumentor. Cet outil permet de générer automatiquement une documentation du code développé.
Pré-requis : pour suivre ces étapes, il est nécessaire d’avoir un accès avec les droits root sur un serveur web (ex : Apache) . Il faut aussi pouvoir uploader un fichier sur ce serveur (ftp, scp…)
- récupérer la dernière version stable sur http://sourceforge.net/project/showfiles.php?group_id=11194 Par exemple PhpDocumentor-1.4.2.zip- Poser par ftp ce fichier sur le serveur de dev.- En root, Le copier à la racine du serveur web : cp /home/utilisateur/xxxxxx/ PhpDocumentor-1.4.2.zip /data/www/html/- Se mettre à la racine : cd /data/www/html- Décompacter : unzip PhpDocumentor-1.4.2.zip- Supprimer le zip : rm PhpDocumentor-1.4.2.zip- Donner les droits apache : chown –r apache:root PhpDocumentor
A partir de là, l’utilisateur à accès à une interface web : http://vmmetaportail-dev.mpl.ird.fr/PhpDocumentor/ (cependant il reste une erreur open_basedir dont on
ne tiendra pas compte)
Pour généré la documentation, l’utilisateur peut soit utiliser l’interface web, soit utiliser un fichier de configuration personnalisé.
via l’interface web- Cliquer de l’onglet « Files » - ajouter le chemin complet du répertoire à parser dans « Directory to parse ». Ex : /data/www/html/modules/PearDBfinder
- Cliquer sur l’onglet « Output »
- Ajouter le chemin complet du répertoire contenant la documentation générée. Ex : /data/www/html/Phpdocumentor/DocumentationAttention les droits en écriture pour Apache doivent être ok sur le répertoire cible.- Modifier le « output format » pour HTML:Smarty:PHP (c’est le plus jolie ;-) c’est le template appliqué sur les pages de sortie )
- Générer les pages en cliquant sur le bouton « create » dans la zone bleu en bas de page (les erreurs opendir le rendent invisible, mais en diminuant la séparation entre les fenêtres il apparaît)Le log qui défile dans la fenêtre du bas donne les informations sur le déroulement de la génération. Une fois terminé, la doc est consultable à l’adresse indiquée par le chemin Output. A savoir, dans l’exemple ci-dessus : http://vmmetaportail-dev.mpl.ird.fr/PhpDocumentor/Documentation

« Moteur de recherche fédéré » Sylvain MILANESILicence Pro – Développement d'Applications E-business
Une version numérique de ce document (infos_install_PhpDocumentor.pdf) est
disponible sur le CD-ROM joint à ce rapport.
Rapport de stage 58
en utilisant un .iniL’utilisation d’un fichier de configuration personnalisé permet de ne pas avoir à redéfinir les informations à chaque accès à l’interface web.
- Sur le serveur, copier le fichier de conf par défaut (on est toujours en root à la racine du serveur web /data/www/html) : cp PhpDocumentor/user/default.ini PhpDocumentor/user/monfichier.ini
- Editer le fichier : vim PhpDocumentor/user/monfichier.ini
- Modifier les valeurs suivantes :- title = Documentation de XXX (titre qui apparaitra dans la page d’index de la documentation
générée)- target = /data/www/html/PhpDocumentor/Documentation (dossier cible)- directory = /data/www/html/modules/PearDBfinder (dossier source)- output = HTML:Smarty:PHP (format de sortie)
- Sur l’interface web, cliquer sur l’onglet « config »- Choisir le fichier de conf créé : monfichier.ini et cliquer sur « Go »- La génération se lance. Le log qui défile dans la fenêtre du bas donne les informations sur le déroulement
de la génération. Une fois terminé, la doc est consultable à l’adresse indiquée par le chemin Output. A savoir, dans l’exemple ci-dessus :
http://vmmetaportail-dev.mpl.ird.fr/PhpDocumentor/Documentation
Dans tous les cas, une fois la documentation générée et finalisée, il est possible de copier le répertoire « Documentation » dans n’importe quel serveur web où il est utile.
Illustration 24: Notice d'installation de phpDocumentor sur un serveur de l'IRD

Ce dossier présente le déroulement et les développements effectués durant le stage de fin
d'études de la formation « Licence Professionnelle, développement d'application e-
business » dispensée par l'IUT de Montpellier. L'objectif final de ce projet est de réaliser un
moteur de recherche fédéré capable de récupérer et présenter des informations depuis
plusieurs sources utilisant des technologies hétérogènes. L'adaptation du logiciel Open
Source SIST a permis de mener à bien ce projet .
Ce rapport détaille la prise en main du logiciel existant, son découplage d'un gestionnaire
de contenu, son adaptation à PHP5, l'ajout d'un module multi-SGBD* et d'une gestion
d'accès public/privé. Il énumère les moyens et outils sollicités pour parvenir aux résultats
finaux. Enfin sont abordées les limites et les évolutions possibles de l'outil réalisé.
Mots-clés : données scientifiques, portail d'accès aux données, moteur de recherche, recherche
fédérée - SIST
This file presents the progress and development carried out during the course of the end of
studies internship for « Licence professionnelle » in e-business provided by the IUT of
Montpellier. The aim of this project is to achieve a federated search engine able to recover
and submit data since several sources using heterogeneous technologies. The adaptation of
the Open Source software SIST has help to carry out the purpose.
This report details the handling of the existing software, its decoupling from a content
management system, its adaptation to PHP5, the addition of a multi-DBMS module and a
management of public/private access. It lists softwares used in this work and the reasons of
these choices to achieve the final results. Lastly are approached the limits and the possible
improvements which could be insured in the future.
Key Words : Scientific data, data web access, searchengine, federated research, SIST