Embed Size (px)
Citation preview

Equality Join R XR.A=S.B S
::
Relation R
M Pages
N Pages
Relation S
Pr records per pagePs records per page

Simple Nested Loops Join
For each tuple r in R dofor each tuple s in S do
if r.A == S.B then add <r, s> to result
•Scan the outer relation R.•For each tuple r in R, scan the entire inner relation S.•Ignore CPU cost and cost for writing result to disk
R has M pages with PR tuples per page.S has N pages with PS tuples per page.
Nested loop join cost = M+M*PR*N.
Cost to scan R.
Memory
Output
1 page for S
1 page for R

Exercise
• What is the I/O cost for using a simple nested loops join?– Sailors: 1000 pages, 100 records/page, 50
bytes/record– Reserves: 500 pages, 80 records/page, 40
bytes/record• Ignore the cost of writing the results• Join selectivity factor: 0.1
ResidSailors serves

Exercise
• What is the I/O cost for using a simple nested loops join?– Sailors: 1000 pages, 100 records/page, 50
bytes/record– Reserves: 500 pages, 80 records/page, 40
bytes/record• Ignore the cost of writing the results• Join selectivity factor: 0.1Answer• If Sailors is the outer relation,
– I/O cost = 1000 + 100,000*500 = 50,001,000 I/Os• If Reserves is the outer relation,
– I/O cost = 500 + 40,000*1000 = 40,000,500 I/Os
ResidSailors serves

Block Nested Loops Join
B-2 pages for R
Memory
Output buffer
R
Bring bigger relation S one page at a time.
Cost=M+NOptimal if one of the relation can fit in the memory (M=B-2).
For each ri of B-2 pages of R do
For each sj of s in S doif ri.a == sj.a then
add <ri, sj> to result
Cost=M+
2B
M
B: Available memory in pages.
Number of blocks of R for each retrieval
1 page for S
1 page
* N

Exercise
• What is the I/O cost for using a block nested loops join?– Sailors: 1000 pages, 100 records/page, 50
bytes/record– Reserves: 500 pages, 80 records/page, 40
bytes/record• Ignore the cost of writing the results• Memory available: 102 Blocks
ResidSailors serves

Exercise
• What is the I/O cost for using a block nested loops join?– Sailors: 1000 pages, 100 records/page, 50
bytes/record– Reserves: 500 pages, 80 records/page, 40
bytes/record• Ignore the cost of writing the results• Memory available: 102 BlocksAnswer• Sailors is the outer relation• #times to bring in the entire Reserves • I/O cost = 500 + 1000*5=5500
ResidSailors serves
5005
100

Indexed Nested Loops Join
for each tuple r in R dofor each tuple s in S do
if ri.A == sj.B then add <r, s> to result
Use index on the joining attribute of S.Cost=M+M*PR*(Cost of retrieving a matching tuple in S).
Depend on the type of index and the number of matching tuples.
cost to scan R

Exercise
• What is the I/O cost for using an indexed nested loops join?
• Ignore the cost of writing the results• Memory available: 102 Blocks• There is only a hash-based, dense index on sid
using Alternative 2Answer• Sailors is the outer relation• I/O Cost = 500 + 40,000*(1.2+1)=88500 I/Os
ResidSailors serves
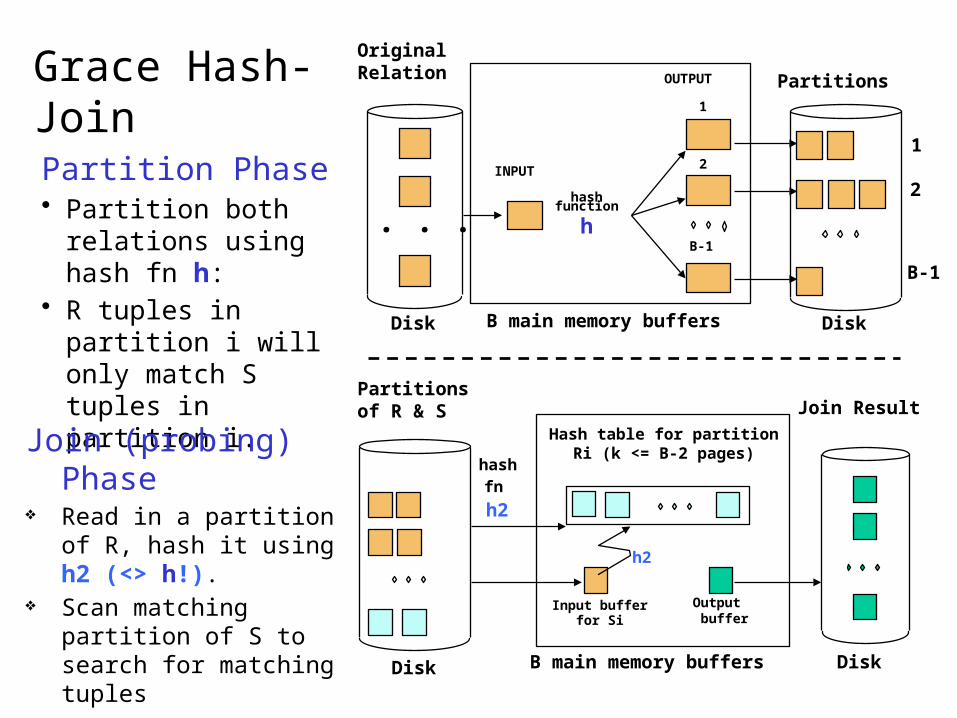
Grace Hash-Join
Partition Phase• Partition both
relations using hash fn h:
• R tuples in partition i will only match S tuples in partition i.
Join (probing) Phase Read in a partition of R,
hash it using h2 (<> h!).
Scan matching partition of S to search for matching tuples
Partitionsof R & S
Input bufferfor Si
Hash table for partitionRi (k <= B-2 pages)
B main memory buffersDisk
Output buffer
Disk
Join Result
hashfn
h2
h2
B main memory buffers DiskDisk
Original Relation OUTPUT
2INPUT
1
hashfunction
hB-1
Partitions
1
2
B-1
. . .

Cost of Grace Join• Assumption:
– Each partition fits in the B-2 pages– I/O cost for a read and a write is the same– Ignore the cost of writing the join results
• Disk I/O Cost– Partitioning Phase:
• I/O Cost: 2*M+2*N– Probing Phase
• I/O Cost: M+N– Total Cost 3*(M+N)
• Which one to use, block-nested loop or Grace join?
– Block-nested loop : Cost=M+
2B
M* N

• What is the I/O cost for using Grace hash join?
• Ignore the cost of writing the results• Assuming that each partition fits in memory.
Answer 3*(500+1000)=4500 I/Os
ResidSailors serves
Exercise

• Ideally, each partition fits in memory– To increase this chance, we need to minimize
partition size, which means to maximize #partitions • Questions
– What limits the number of partitions? – What is the minimum memory requirement?
• Partition Phase• Probing phase
Memory Requirement for Hash Join

• Partition Phase– To partition R into K partitions, we need at least K
output buffer and one input buffer– Given B buffer pages, the maximum number of
partition is B-1– Assume a uniform distribution, the size of each R
partition is equal to M/(B-1)
B main memory buffers DiskDisk
Original Relation OUTPUT
2INPUT
1
hashfunction
hB-1
Partitions
1
2
B-1
. . .

• Probing phase– # pages for the in-memory hash table built during
the probing phase is equal to f*M/(B-1) • f: fudge factor that captures the increase in the
hash table size from the buffer size– Total number of pages
• since one page for input buffer for S and another page for output buffer
21
f MB
B
B f M
Partitionsof R & S
Input bufferfor Si
Hash table for partitionRi (k <= B-2 pages)
B main memory buffersDisk
Output buffer
Disk
Join Result
hashfn
h2
h2

If memory is not enough to store a smaller partition
• Divide a partition of R into sub-partitions using another hash function h3
• Divide a partition of S into sub-partitions using another hash function h3
• Sub-partition j of partition i in R only matches sub-partition j of partition i in S
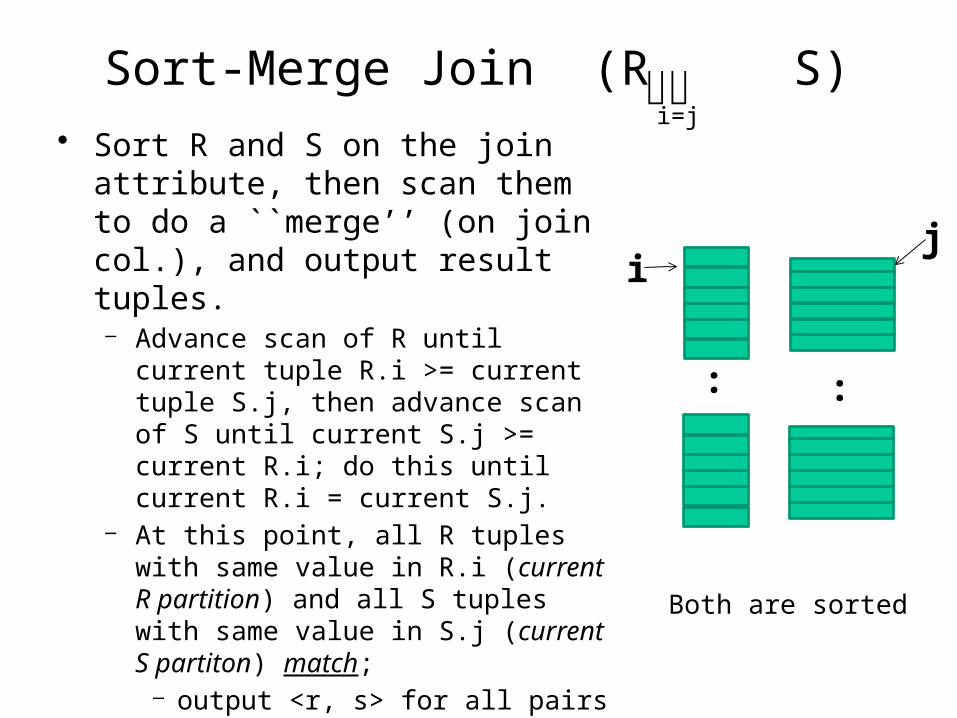
Sort-Merge Join (R S)• Sort R and S on the join
attribute, then scan them to do a ``merge’’ (on join col.), and output result tuples.– Advance scan of R until current
tuple R.i >= current tuple S.j, then advance scan of S until current S.j >= current R.i; do this until current R.i = current S.j.
– At this point, all R tuples with same value in R.i (current R partition) and all S tuples with same value in S.j (current S partiton) match;
– output <r, s> for all pairs of such tuples.
– Then resume scanning R and S.
i=j
ij
: :
Both are sorted

Example of Sort-Merge Join
sid sname rating age 22 dustin 7 45.0 28 yuppy 9 35.0 31 lubber 8 55.5 36 lubber 5 35.0 58 rusty 10 35.0
sid bid day rname
28 103 12/4/96 guppy28 103 11/3/96 yuppy31 101 10/10/96 dustin31 102 10/12/96 lubber31 101 10/11/96 lubber58 103 11/12/96 dustin
• I/O Cost for Sort-Merge Join• Cost of sorting: TBD
• O(|R| log |R|)+O(|S| log |S|) ??• Cost of merging: M+N
• Could be up to O(M+N) if the inner-relation has to be scanned multiple times (very unlikely)
Sailors Reserves

Sort-Merge Join
• Attractive if one relation is already sorted on the join attribute or has a clustered index on the join attribute

Exercise
• What is the I/O cost for using a sort-merge join?
• Ignore the cost of writing the results• Buffer pool: 100 pages
Answer• Sort Reserves in 2 passes:2*(1000+1000)
=4000• Sort Sailors in 2 passes: 2*(500+500)=2000• Merge: (1000+500) =1500• Total cost = 4000+2000+1500 = 7500
ResidSailors serves

Cost comparison for Exercise Example
• Block nested loops join: 5500• Index nested loops join using a hash-index:
88500 • Grace Hash Join: 4500• Sort-Merge Join: 7500

Why Sort?
• Sort-merge join algorithm involves sorting.• Problem: sort 1Gb of data with 1Mb of RAM.
– why not virtual memory?
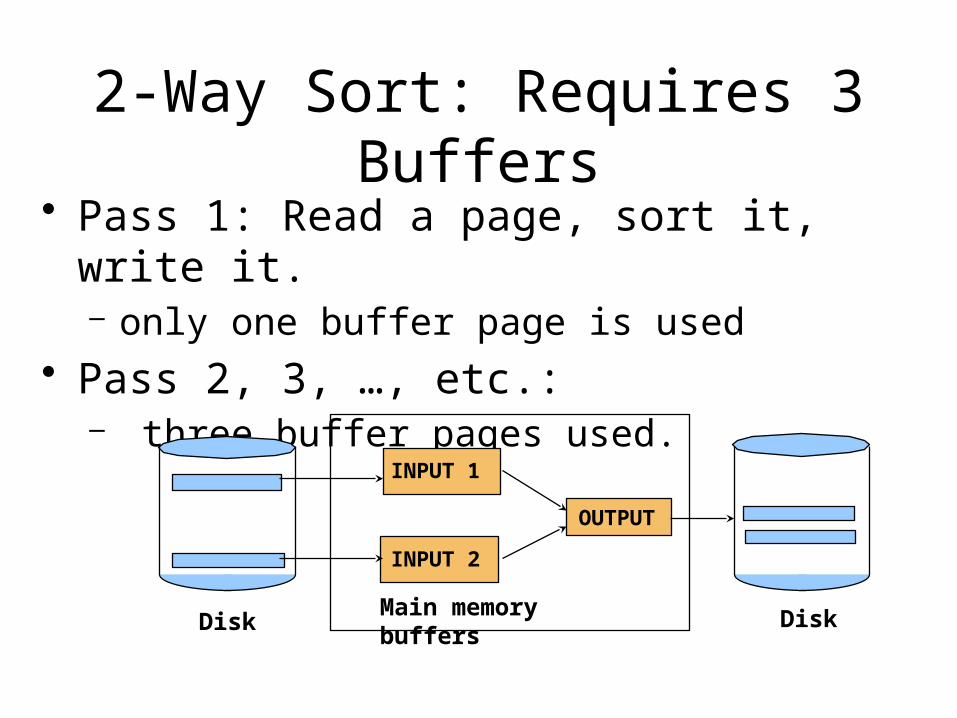
2-Way Sort: Requires 3 Buffers• Pass 1: Read a page, sort it, write it.
– only one buffer page is used
• Pass 2, 3, …, etc.:– three buffer pages used.
Main memory buffers
INPUT 1
INPUT 2
OUTPUT
DiskDisk

P1INPUT 1
INPUT 2
OUTPUT
P2
P1 P2
P3INPUT 1
INPUT 2
OUTPUT
P4
P3 P4
Example: Sorting 4 pages
P1 and P2 are sorted individually
P3 and P4 are sorted individidually
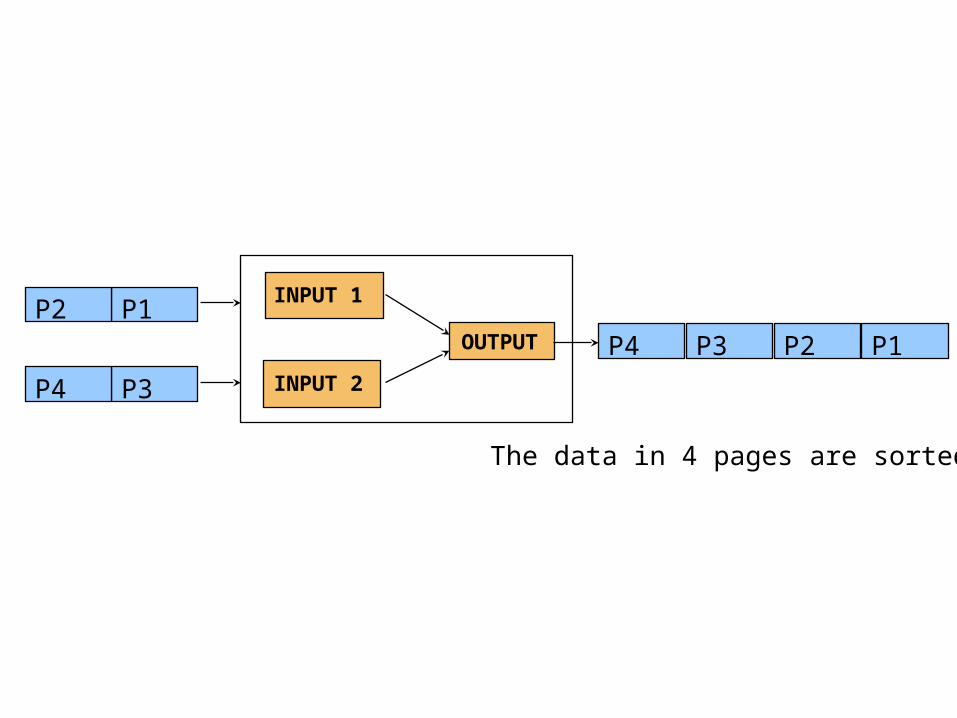
P1 and P2 are sorted
P3 and P4 are sorted
P1INPUT 1
INPUT 2
OUTPUT
P2
P3P4
P4 P3 P2 P1
The data in 4 pages are sorted

Two-Way External Merge Sort
• Each pass we read + write each page in file.
• N pages in the file => the number of passes
• So total cost is:
• Idea: Divide and
conquer: sort subfiles and merge
log2 1N
2 12N Nlog
Input file
1-page runs
2-page runs
4-page runs
8-page runs
PASS 0
PASS 1
PASS 2
PASS 3
9
3,4 6,2 9,4 8,7 5,6 3,1 2
3,4 5,62,6 4,9 7,8 1,3 2
2,34,6
4,7
8,91,35,6 2
2,3
4,46,7
8,9
1,23,56
1,22,3
3,4
4,56,6
7,8

Two-Phase Multi-Way Merge-Sort
Phase 1: 1. Fill all available main memory with blocks from the
original relation to be sorted. 2. Sort the records in main memory using main
memory sorting techniques. 3. Write the sorted records from main memory onto
new blocks of secondary memory, forming one sorted sublist. (There may be any number of these sorted sublists, which we merge in the next phase).
More than 3 buffer pages. How can we utilize them?
File to be sorted MM
Sorted f1
Sorted f2
Sorted fn:
n = N/M, where N is the file size and P is the main memory in pages

Phase 2: Multiway Merge-Sort
Pointers to first unchosen records
Select smallest unchosen key from the list for output Output
bufferInput buffer, one for each sorted list
Done in main memory
Merge all the sorted sublists into a single sorted list.
• Partition MM into n blocks• Load fi to block i

•Find the smallest key among the first remaining elements of all the lists. (This comparison is done in main memory and a linear search is sufficient. Better technique can be used.)
•Move the smallest element to the first available position of the output block.
• If the output block is full, write it to disk and reinitialize the same buffer in main memory to hold the next output block.
• If the block from which the input smallest element was taken is now exhausted, read the next block from the same sorted sublist into the same buffer.
• If no block remains, leave its buffer empty and do not consider elements from that list.
Phase 2: Multiway Merge-Sort
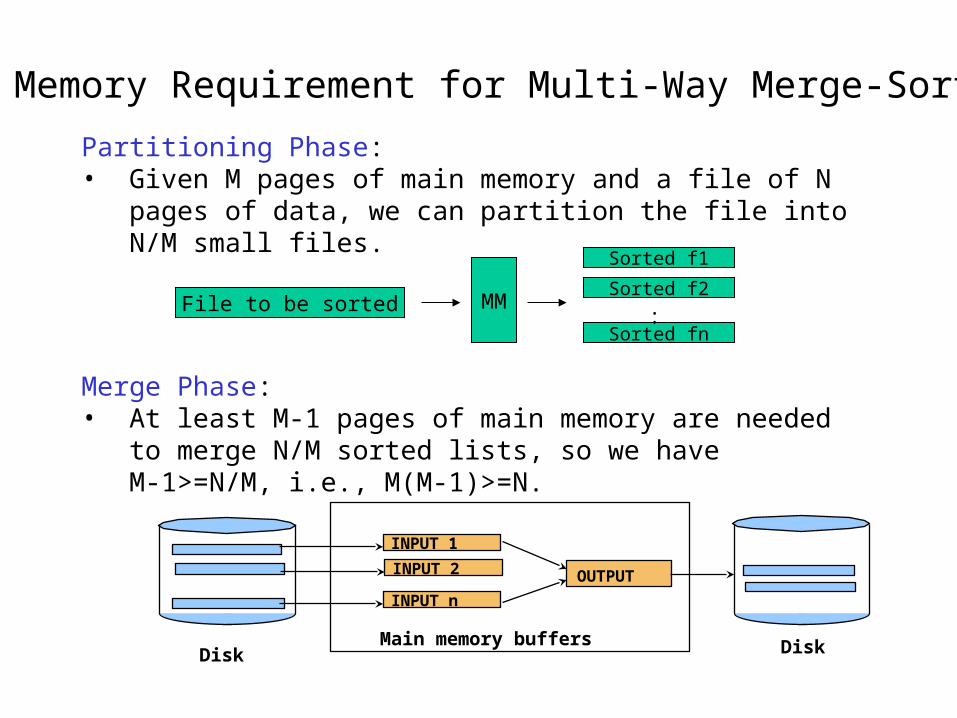
Memory Requirement for Multi-Way Merge-Sort
Partitioning Phase: • Given M pages of main memory and a file of N pages of
data, we can partition the file into N/M small files.
File to be sorted MM
Sorted f1
Sorted f2
Sorted fn:
Merge Phase: • At least M-1 pages of main memory are needed to
merge N/M sorted lists, so we have M-1>=N/M, i.e., M(M-1)>=N.
Main memory buffers
INPUT 1
OUTPUT
DiskDisk
INPUT 2
INPUT n

1. pick one element in the array, which will be the pivot. 2. make one pass through the array, called a partition step, re-
arranging the entries so that: a) the pivot is in its proper place. b) entries to the left of the pivot are smaller than the pivotc) entries to its right are larger than the pivotDetailed Steps: 1. Starting from left, find the item that is larger than the pivot, 2. Starting from right, find the item that is smaller than the pivot3. Switch left and right
3. recursively apply quicksort to the part of the array that is to the left of the pivot, and to the part on its right.
O(n log n) on average, worst case is O(n2)
In-memory Sort: Quick Sort
18 5 6 19 3 1 5 6 11 21 33 23
left right
1st pass: pivot = 18

Query Cost Estimation
)(Rc• Select: No index
unsorted data sorted data
Index tree index hash-based index
• Join: R S Simple nested loop Block nested loop Grace Hash Sort-merge




























