Embed Size (px)
Citation preview

DEA I3: Master Thesis Report
Enhancing Security of Web Services
Workflows using Watermarking
Advisor: David Gross-Amblard 1
Julien LAFAYE2
2nd September 2004
1CNAM Paris
2Universite Paris XI and CNAM Paris

Abstract
In this work, we present a solution based on watermarking to address the problem of securing webservices workflows. Indeed, watermarking brings a practical solution to protect the intellectualproperty of a document.The work is divided into two parts. In a first part, we present a watermarking algorithm whichslightly modifies messages flooding through workflows. Then, we show how the aggregation ofwatermarked messages permit to claim ownership over a specific data. We study theoretically howresilient is this technique to the most current kinds of attacks and validate our results using a realexample.In a second part, we model web services as tree transformations and we isolate a class of trans-formations for which it is possible to track the watermarked nodes of the input. Straightforwardextensions of those results permit the simultaneous copyright protection of a composite documentbuilt by several peers.
Resume
Dans ce travail, nous proposons une solution basee sur le tatouage de donnees (watermarking)dans le but d’assurer l’integrite des donnees echangees par des services web. En effet, le tatouageapporte une solution technique permettant a une entite de prouver sa propriete sur des donneesqui lui appartiennent. Nous pensons que le fait d’avoir un certain niveau de confiance en l’ori-gine de donnees est un premier pas vers la securite des echanges. Ce rapport est divise en deuxparties. Dans une premiere partie, nous presentons un algorithme de tatouage qui travaille surles atomes d’informations echanges par les services web. Nous montrons comment l’agregat d’uncertain nombre d’atomes tatoues legitime la revendication de propriete. Nous regardons egalementla robustesse de notre technique relativement a la plupart des attaques habituelles.Dans une seconde partie, nous avons une approche beaucoup plus theorique en modelisant lesoperations effectuees par les services web sous forme de transducteurs d’arbre. Nous isolons uneclasse de transformations pour laquelle le suivi des donnees tatouees est statiquement decidable.Une extension immediate de ces resultats rend possible la preuve de propriete multiple sur undocument composite construit par plusieurs services.

CONTENTS 2
Contents
1 Introduction 3
2 Related work 5
3 Definitions 73.1 Web messages . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73.2 Web services . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
3.2.1 Web operation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83.2.2 Web services workflows . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83.2.3 Watermarking . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
4 Watermarking web messages 104.1 Specificity of web services . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104.2 Watermarking algorithm for data trees . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114.3 Guilt evaluation for web services . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
4.3.1 Decision algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124.3.2 Detection of false positives . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 144.3.3 False negatives . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 154.3.4 Resilient detectors . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
4.4 Experimentations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 194.4.1 Web service . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 194.4.2 Watermarking process . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 194.4.3 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
5 Automata and transducers 225.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 225.2 Definitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
5.2.1 Tree transducers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 225.2.2 String transducers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
5.3 Tracking watermarked data through transformations . . . . . . . . . . . . . . . . . . . . . 255.3.1 Definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 255.3.2 FQP tracking problem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 255.3.3 Unfeasibility result . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 265.3.4 Feasibility result . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
6 Conclusion and future work 29

CHAPTER 1. INTRODUCTION 3
Chapter 1
Introduction
Web Services Stating that the web is evolving has now become a platitude. At the beginning, itprovided a way to travel through hyperlinked documents that were distributed on peers located all overthe world. Since several years, a new paradigm has appeared: peers not only publish documents butalso operations on those documents. The stake is to be able to combine automatically those atomicoperations into more complicated processes. We focus our attention on the technology of web serviceswhich provides a technical tool to build such distributed computations. Several peers are involved in thecomputation of a single document, each peer performing a simple computation. On top of those peers,a structure is added so that one can describe the organization of simple operations to perform complexoperations. The typical example of web service is a weather forecast service which, given a location,outputs the expected temperatures for the next five days. At the beginning of the process, some weatherstations publish the measures of current weather parameters: temperature, air pressure, wind speed, ....Another peer, typically a very powerful computer using optimized algorithms, collects all those data andcomputes a weather forecast bulletin which will be sent to the user. We can also imagine a situationwhere a third kind of peer is added, e.g. a web portal, which integrates the previous information andprovides commercial services depending on the weather. Following W3C standards [Gro03], web servicesoperate on XML Documents and thus realize structural and value-based transformations.
Workflows The need to have a concrete model to describe the orchestration of peers incited the webcommunity to adopt the model of web services workflows. In workflows, a data source generates a firstinformation in solicitation of a user request. This information flows across some transformation servicesthat modify it. At the end of the pipeline, the data is sent back to the user. Interestingly, a workflowbecomes a higher level web service which can be involved in another workflow. The example of theprevious paragraph is an instantiation of a workflow. Indeed, a user sends its location to a weatherforecast web server. This web server analyzes the location and selects the weather stations from whichit needs to collect data to perform the computation of the forecast. Then, each distant station gets asolicitation from the web server and outputs the needed parameters. A third kind of web service, collectsall those parameters and performs the heavy computational task. At last, the answer is redirected to theuser. Another example of workflow is given in figure 1.1.
Copyright in Workflows Each service involved in a workflow adds a certain value to the informationwhich goes through it by performing (1) a costly computation or (2) adding some original data.An example of (1) could be the previously mentioned weather forecast web service. Everyone would admitthat it needs a big amount of CPU time to calculate pertinent forecastings. It is also very common to findservices that (2) publish original data. For instance, a web service like Mappy [MAP] publish originaldata in the sense that it takes time or money to build a huge and coherent database of geographical data.That is the reason why we can say that every peer of a workflow can be considered as the owner of achapter of that data. Since peers own a part of the information, they are likely to defend their ownershiprights against data stealers.
Evading copyright In the most common case, the distribution of copyrighted data is restricted. Un-fortunately, we live in an imperfect world where malicious users may me tempted to steal copyrighted

CHAPTER 1. INTRODUCTION 4
Figure 1.1: A common example of workflow
data. Having stolen copyrighted data from a web service, a hacker can redistribute it illegally. Cryptog-raphy, as far as we know, seems not to bring the ultimate solution for that problem because encrypteddata has to be decrypted. As soon as the data has to be used, it has to be decrypted. Detecting whatseems to be an illegal web server, the owner of the data would be unable to prove that his data has beenstolen. What we need is a tool which permits the embedding of a copyright mark in the data itself. Thus,the owner would be able to test the data coming from suspicious servers and sue malicious hackers.
Watermarking Watermarking aims at strengthening copyright information by embedding a mark inthe data. The mark has to be invisible and resilient. We need the invisibility of the watermark becausewe do not want the quality of the data to be too much altered. For instance, one can modify a temperaturewith an amplitude of one celsius without affecting too much its quality. We also need the mark to beresilient i.e. difficult, even impossible to remove. If somebody is able to remove the mark withoutaffecting the document, the watermarking process is ineffective. This robustness goal is usually reachedby modifying the data in a pseudo-random manner, pushing a potential attacker to considerably degradethe quality of the data when trying to remove the watermark. Common applications of watermarking arestill images, audio streams and video streams. Exotic applications go from unstructured data like textto highly constrained resources like relational databases, graph databases, etc ...
Goals In this work, we present a practical way to build cooperative web services workflows with wa-termarking features. In order to do so, we need to answer to the following questions:
• How to watermark the flooding messages ?
• How, given a certain transformation on the data, is it possible to guess where the watermarkeddata can be retrieved in the output ?
Organization The report is organized as follows:In a first introduction part we give main definitions that will be used in the rest of the report. We also
take the opportunity to recall some important points of XML theory. In a second part, we present ourwatermarking algorithm and prove its robustness against a specific set of brute force attacks. We alsogive some experimental results as validation samples for the main theorems. In a third part we will studythe frontier of tractability for deciding, given the code of a certain web service, whether it is possible totrack the watermarked data through that web service.

CHAPTER 2. RELATED WORK 5
Chapter 2
Related work
Watermarking The majority of works about watermarking techniques was published in the early 90s.Most of the papers deal with watermarking unstructured data like still images, sound streams, etc... Agood introduction to classic watermarking techniques can be found in [SK00]. This book also introducesthe concept of robustness of watermarking algorithms by exploring the field of potential attacks. Acommon point of the majority of approaches described in [SK00] is that they reduce the data to becopyrighted to a set of vectors and work on watermarking such sets. From a database point of view, aset of vectors is nothing but a relation. This analogy leads some people to study database watermarking.
Database watermarking Surprisingly, the number of works studying watermarking such highly struc-tured data is relatively small. Agrawal and Kiernan [AK02] introduce a relational database watermarkingalgorithm based on the insertion of pseudo-random bits at some pseudo-random positions of the database.They also show how a watermarked database can be attacked and how their algorithm can be enforced todefeat potential attackers. The wmdb project [SAP02] at Purdue University exploits statistical propertiesof the data to embed the watermark. They also introduce a method to deal with usability constraints,i.e. giving some explicit way to calculate a quality level of the watermarked data. For instance, it can beneeded in practice that the sum of a cashflow column remains zero after the embedding. Their method isa greedy one using an oracle which can validate or invalidate the data at any time of the watermarkingprocess. Obviously, there is a compromise to find between the number of those usability constraints andthe quantity of information which can be embedded into a database. Although the technique definedin [SAP02] uses a greedy method to deal with usability constraints, a recent paper, [GA03], studies theproblem of watermarking relational databases and XML documents from a theoretical side. The authorof the paper shows how the watermarking process can be optimized A prototype has also been imple-mented and is available as free software [WAT]. in order to respect a set of usability constraints definedin a query language. All those works suppose that the database owner has a full access to the suspectdatabase which is usually not the case. In [KZ00], the authors present a watermarking scheme for graphdatabases. They show how to embed information in such databases and how to retrieve this informationbeing allowed only a restricted class of queries on a suspicious database. A more recent work [SAP04]focuses on watermarking data streams. From an abstract point of view, streams can be viewed as infi-nite sequences of vectors. It happens that infinite sequences raise several issues because watermarkingalgorithms cannot see the entire stream. A range sliding window has to be defined and the watermarkingprocess exploits some property of the data in that window. We will see in chapter 4 how we deal withthat limitation in the context of web services.
XML Theory Since we work on available technologies which make a great use of XML documents wefocus our attention on modelling web services as tree transformations. A great literature can be foundon tree transformations which traces its roots back to the beginning of Computer Science. (e.g. see[HU79] for an introduction and [Tho99] for more recent work). There have been many proposals of treetransformations but there is none of them which transforms a regular tree language into another regulartree language . A variant of that issue is the typechecking problem which can be summarized as follows:given two tree languages L1 and L2 and a tree transformation T , is it true that L1(T ) ⊆ L2 ? Milo, Suciuand Vianu showed in [MSV00] that the typechecking problem is decidable for k-pebble tree transducers.An extension of that work [AMN+01] explored the frontier of tractability of that typechecking problem.

CHAPTER 2. RELATED WORK 6
We mention this work here because k-pebble tree transducers capture a subset of XSLT transformations.We can also cite the work of Neven and Martens [MN03] which deals with the typechecking problem fora restricted class of tree transducers. We mention those works here because our ultimate goal is to beable to guess statically where the content of a distinguished node of a tree goes through a transduction.It happens that the node tracking problem has strong links with the typechecking problem: they bothare flavors of the same and more general theoretical problem.

CHAPTER 3. DEFINITIONS 7
Chapter 3
Definitions
In this paragraph, we describe the data model that will be used throughout the report.
3.1 Web messages
First, we give the definition of data trees which can be considered as abstractions of XML documents.Then, we introduce a typing system for data trees. At last, we define the concept of keys.
Assume given a finite set Σ of words and D a (possibly infinite) set of values. Σ is a set of tags.
Definition 1 (Data Tree). A data tree t is a tuple (M, d, l, v) where:
• M = {m1, ..., mp} is a finite set of nodes.
• d : M →M∗ is a function from the set of nodes to the set of all nodes sequences without repetition.If m is a node, d(m) is the ordered sequence of all children (descendants of rank 1) of m. If d(m) = ε, m is a leaf.
• v : M → D is a valuation function which assigns a value to each node. If m is a node, v(m) is thevalue of m.
• l : M → Σ is a labelling function which assigns a label to each node. If m is a node, l(m) is thelabel of m.
• The structure implied by d on the set of nodes M is a tree.
This model has a huge descriptive power and captures all kinds if XML documents by using distin-guished labels for attributes, PCDATA and usual tags.
In order to type XML documents, we also give the formal definition of tree type:
Definition 2 (Tree Type). A tree type τ is a triple (N , λ, δ) where:
• N is a set of nodes.
• λ : N → Σ is a node labelling function.
• δ : N → N ∗ is a function which assigns to a node n a regular language on N .
A tree type is a syntactical characterization of regular tree languages which are by far the mostfamous formal languages on trees. Regular tree languages capture the majority of languages used inpractical applications and they present good closure properties. In the rest of the report, we will usetree type as well as regular tree language.
This type system is far more expressive than DTDs and cannot easily be compared to XML Schema[Gro01]. From a certain point of view, regular tree languages are more expressive than XML Schema.Indeed, in XML Schema the δ function is restricted in a way that the typechecking problem is relativelyefficient. Another feature of XML Schema is the possible restriction on data values. In regular treelanguages like in other languages focusing only on describing the structure of documents, such a restrictionis clearly impossible.
Now, we can introduce how we type documents:

CHAPTER 3. DEFINITIONS 8
Definition 3. The data tree t = (M, d, l, v) is valid w.r.t. τ = (N , δ, λ) if and only if there exists atype assigning function f :M→N such that:
• For each node m ∈M, the sequence of children d(m) = mi1 ...mipis correctly typed i.e. the sequence
of types f(mi1)...f(mip) is a word of the regular language δ(f(m)).
Thus, each tree type τ defines a language of data trees, the set Lτ of data trees having type τ . Now,we introduce paths:
Definition 4 (Path). A Σ-path in a is a word from Σ \ {ε}.
Definition 5. Let t = (M, d, l, v) be a data tree,M0 ⊆M and p a Σ-path. p(t,M0) is the set of nodesdefined recursively as follows:
• if p = a, p(t,M0) =M0 ∩ {m ∈ M|l(m) = a}
• if p = w.b where b ∈ Σ. Let M1 = w(t,M0). Then, p(t,M0) = b(t, d(M1)).
We often use the following syntactical shortcut: p(t, {root(t)}) = p(t).
Our last definition is the one of keys in data trees. It is a generalization of the one used for identifyingtuples in the relational model.
Definition 6 (Key). A key is a pair (p, c) where p is a Σ-path and c = (c1, ..., cq) is a tuple of pathssuch that:
• for i = 1..q,(
ci(t, {m}))
m∈p(t)is a partition of p.ci(t).
Intuitively, for all i, we can find a bijection from the set of nodes captured by the path p into theset of nodes captures by the path p.ci. Another constraint on f is hidden in our definition which is thefollowing: if m is captured by p, the associated node mi captured by p.ci is a descendant of m. This is anatural restriction.
3.2 Web services
3.2.1 Web operation
We view a web service as a library of functions. In the Web Services Description Language [Chr01], suchfunctions are called operations. In order to fit to the standards of the W3C we call functions whichmanipulate our data trees web operations.
Definition 7 (Operation). A web operation is a function O such that:
O : Lτi−→ Lτo
t 7−→ t′ = O(t)
where:
• τi is the input tree type.
• τo is the output tree type.
• For any input vector, the outputted result is in Lτo.
3.2.2 Web services workflows
In the workflow model, each peer is a black box that takes as input the data outputted by other sources.There is a distinguished direction for the data to be transmitted bringing the analogy of a floodingsubstance.
Definition 8 (Workflow). A web service workflow is a set of web services divided into layers. Peersfrom layer n can only use data from peers of layers from 1 to n− 1.

CHAPTER 3. DEFINITIONS 9
3.2.3 Watermarking
In this section, we give the formal definition of a watermarking algorithm:
Definition 9. If X is a set of data, a perfect watermarking algorithm on X is a pair of functions(w,d), w standing for watermarker and d for detector:
•w : X × N −→ X
(x, K) 7−→ x = w(x, K)
•d : X × N −→ {true, false}
(x,K) 7−→ d(x,K)
• N is the domain of private keys.
where the following condition holds:
d(x, K) = true if and only there exists some x′ ∈ X such that t = w(x′, K).
Thus, if given a suspicious piece of data x, the detector D outputs true then one can consider thatthe data has been stolen.
Let τ be a tree type. In the context of web services, we take for X the set Pf (Lτ ) of all finite subsetsof Lτ . Each element of Pf (Lτ ) can be viewed as a set of inputs (or outputs) from a web operation.
Definition 10. A watermarking algorithm on Pf (Lτ ) is a pair (W,D):
•W : Pf (Lτ )× N −→ Pf (Lτ )
({t1, ..., tq}, K) 7−→ {t1, ..., tq} = W ({t1, ..., tq}, K)
•D : Pf (Lτ )× N −→ {true,false}
({t1, ..., tq}, K) 7−→ D({t1, ..., tq}, K)
N is the domain of private keys.
Let (W, D) be a watermarking algorithm. Let S = {S1, ..., Sn} ∈ Pf (Lτ )n a finite set of finite set ofdata trees. We suppose that SW ⊂ S has been marked by the watermarking algorithm. Let SD ⊂ S thesubset of all subsets on which D outputs true.
Definition 11. The pertinence of a watermarking algorithm can be evaluated using the recall ρ and theprecision π where:
π =|SD ∩ SW |
|SW |
ρ =|S¬W ∩ SD |
|S¬W |
The precision is the proportion of detected watermarked objects whereas the recall is the proportion ofwatermarked objects that have not been recognized.
A perfect watermarking algorithm is such that π = 1 and ρ = 0. The stake is to find perfect algorithmswhich are also resilient against data modifications. Indeed, a malicious user can steal the data and modifyit in order to remove the watermark. The watermark detecting algorithm should adapt and still detectssuch modified objects.

CHAPTER 4. WATERMARKING WEB MESSAGES 10
Chapter 4
Watermarking web messages
In this section, we present a watermarking algorithm for data trees exchanged by web services.
4.1 Specificity of web services
Since we want to watermark messages from web services, we have to state what makes those messagesspecial:
• One can have a message-centric vision of web services. In that mode, messages flow through webservices in a synchronous manner. The peer gets an atomic data as input, processes it, outputs theresult and then reiterates the same operation on another atomic data.
• Web services can also be viewed as operators on data streams . In that mode, messages continuouslyflow across web services and peers perform operations on a small portion of that data. We alsomake the implicit assumption that, in stream mode, messages are small; trees are only used toencapsulate values.
We think that real applications are both messages-centric and streams-centric and it is an importantpoint to remember when designing a watermarking algorithm for web services. Indeed, one can find realapplications where the atomic data is “big” (a few kilobytes) and highly structured. This is the case forweb portals where the same structured information is transformed and spread to several different media.Clearly, the interesting content is the atomic answer itself. In some other applications, how the dataevolves is at least as important as the data itself. Then, messages have an intrinsic order. For instance,in the previously described weather forecast web service, the fact that air pressure decreases is moreimportant than its current value.
Surprisingly, the literature on watermarking streams, which can be viewed as infinite sets of orderedvectors, is relatively poor. A recent work [SAP04] focuses on watermarking sensor streams. The problemwhen trying to watermark streams is how to choose the property which will slightly be modified to embedhidden information. The active field of that property is linked to the amount of data the transformationis able to see simultaneously. The usual assumption is that the transformation is able to buffer the lastN answers constituting a sliding window on the input data. Intuitively, the larger the sliding window is,the larger is also the set of usable properties. Unfortunately, exploiting a property which requires toomany samples can lead to many bufferings. For instance, let’s imagine that we embed a bit 0 in the datastream, at time N, by forcing the mean of values having timestamps in ]N − 10, N ] to be odd. In thatcase, the transformation has to buffer 10 answers before being able to output the first vector of data. Thesecond problem is that the associated detector has to synchronize and the synchronization can be easilybroken by an attacker simply sampling or mixing the data. Furthermore, in [SAP04], only sampling andsummarization attacks are taken into account whereas it is possible to find many transformations on thestreams that are invertible or almost invertible and that destroy the full mark. An example of such atransformation is the differentiation which can be viewed as an easily invertible process.
In [GA03], a general watermarking technique for XML documents is discussed. It happens that thoseXML documents are indeed XML databases with the implicit assumptions that a large quantity of datais available and that there exists some recurrent structure. Although we have a recurrent structure

CHAPTER 4. WATERMARKING WEB MESSAGES 11
between different messages since they share the same type, the amount of data available in each answeris considerably smaller. If we apply a classic algorithm on a message, the quantity of information whichcan be embedded into an atomic message could be very small and even null. We think that it is stillpossible to build a resilient algorithm for watermarking such data by spreading the modifications on alldocuments. The following two points have to be solved:
• Finding an embedding algorithm exploiting a property which does only depend on one given answer.
• Evaluating how many answers a detector should retrieve from a suspicious web server to take apertinent decision on its guilt.
4.2 Watermarking algorithm for data trees
Let τ be a tree type and let’s suppose that (p, c), where c = (c1, ..., cq), is a key for all data trees inLτ . The algorithm we present here is inspired by the one from [AK02]. We have the strong intuitionthat those kinds of algorithms are in practice the most resilient ones. Let t ∈ Lτ and K a private key.Algorithm 1 shows how the watermark embedding is done in the data tree t. N and l are two parametersused to tune the algorithm. N is an integer such that 1/N is the frequency of watermarked messages.l is the number of bits the algorithm is allowed to modify per data value. Usually, we use the l leastsignificant bits.
Algorithm 1: MarkDataTree(t,K)
Input: A data tree t and a private key KParameters: two integers N and lOutput: the watermarked version of tk ← v(p(t));1
key ← concat (k,K);2
G.init (key);3
for i = 1..q do4
r ← G.nextInt () [N ];5
old ← v(p.ci(t));6
if r = 0 then7
pos ← G.nextInt () [l];8
bit ← G.nextBool ();9
tab ← intToBoolArray (old);10
tab[pos] ← bit;11
new ← boolArrayToInt (tab);12
if new is valid then13
v(p.ci(t)) ← new;14
end15
end16
end17
return t;18
A watermarking operation executes that algorithm for every message it receives . First, a randomgenerator is initialized (line 3). The random generator is used to decide whether some data values areto be modified at some positions. It also decides what are the values to be embedded, 0 or 1 (line 9). Itshould be taken into account that only data values are altered by the algorithm and not the structure ofthe document. The validity test (line 13) has been added because in real applications one may need torestrict in some way the domain of the watermarked data. For instance if we insert a bit in a millisecondfield the watermarked data should not exceed 999 otherwise it may raise suspicion.
Since keys are not altered by the watermarking process, the detecting algorithm for one answer isstraightforward and shown in algorithm 2. Algorithm 2, given a data tree t, computes the numbers ofbits that match and do not match with what would be the embedded bits. For a data tree t obtainedusing algorithm 1, we should obtain result[1] ≥ 0 and result[2] = 0.

CHAPTER 4. WATERMARKING WEB MESSAGES 12
Algorithm 2: retrieveMarkFromDataTree(t,K)
Input: A data tree t, a private key KParameters: two integers N and lsbOutput: number of matched and unmatched watermarked bitsresult ← [0,0];1
k ← v(p(t);2
key ← concat (k,k);3
G.init (key);4
for i = 1..q do5
r ← G.nextInt () mod N ;6
old ← v(p.ci(t));7
if r = 0 then8
pos ← G.nextInt () mod lsb;9
bit ← G.nextBool ();10
tab ← intToBoolArray (old);11
if tab[pos] == bit then12
result[1]++;13
end14
else15
result[2]++;16
end17
end18
return result19
end20
4.3 Guilt evaluation for web services
We now focus our attention on finding a good detecting algorithm. A good detector is an algorithm whichsays yes if and only if the data is owned by the performer of the detection process. Because a malicioususer may have tried to modify the data in order to remove the embedded watermark, we need to build aflexible algorithm.
What the watermarking algorithm does on a set of n answers from a web service is only assigningsome boolean values to some positions of the data. Let u ∈ {0, 1}n be the sequence of boolean valuesassigned by the watermarking algorithm. From a certain point of view, we can consider that the detectoroutputs another sequence v ∈ {0, 1}n. From those two sequences of boolean values u and v it is possibleto decide for the ownership proof problem. Indeed, if ui = vi for all i ≥ 0, it is clear that the data hasbeen previously modified by a watermarking algorithm. On the contrary, if ui 6= vi for all i ≥ 0, we canalso suspect that somebody has inverted all the watermarked bits. If ui = vi with a probability close to12 then, the data comes obviously from a third party. If the decision is relatively easy to take when suchextreme situations are reached, it is practically more complicated because one may find modified datawhere the majority of the watermark has been erased. Another disturbing situation, which a detectorshould deal with, is when v presents some strange similarities with u even if the data has not been stolen.
In order to be able to take a legitimate decision in a trial context, we lead a theoretical study on thatdecision problem. First, we will show how to get rid of false positives, i.e. when the data from a distinctsource is stamped as stolen. Next, we will try to get rid of false negatives, i.e. stolen data that has beenmodified to pass the detection algorithm. We will isolate a set of attacks to which our watermarkingalgorithm is resilient.
4.3.1 Decision algorithm
Let α a real value such that 0 < α < 12 . Intuitively, α is a threshold value which permits to decide
on the ownership problem. We say that a data is suspicious if the percentage of matches x is far from12 , i.e. |x − 1
2 | > α. This is a legitimate solution because if we apply the retrieveMarkFromDataTreealgorithm we are likely to observe as many as matching bits as non-matching bits if the laws that controlthe watermarking process and data generation are not correlated. We will make that assumption. The
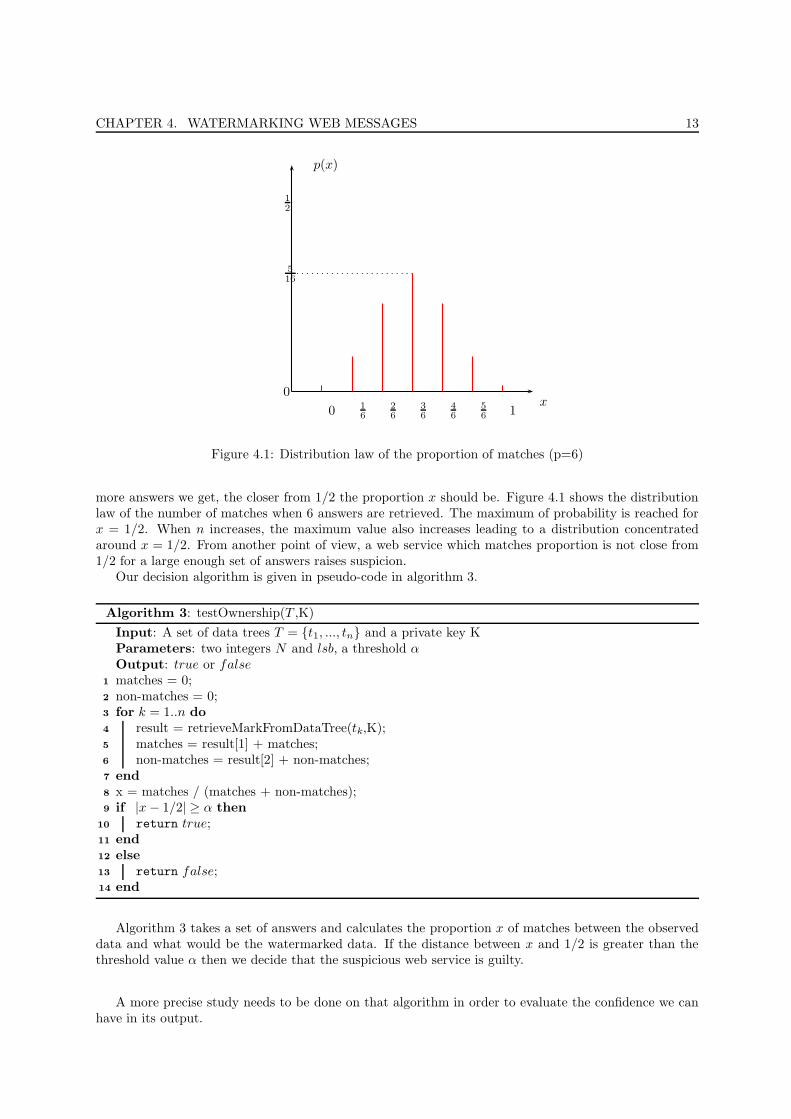
CHAPTER 4. WATERMARKING WEB MESSAGES 13
0 16
26
36
46
56 1
0
12
x
p(x)
516
Figure 4.1: Distribution law of the proportion of matches (p=6)
more answers we get, the closer from 1/2 the proportion x should be. Figure 4.1 shows the distributionlaw of the number of matches when 6 answers are retrieved. The maximum of probability is reached forx = 1/2. When n increases, the maximum value also increases leading to a distribution concentratedaround x = 1/2. From another point of view, a web service which matches proportion is not close from1/2 for a large enough set of answers raises suspicion.
Our decision algorithm is given in pseudo-code in algorithm 3.
Algorithm 3: testOwnership(T ,K)
Input: A set of data trees T = {t1, ..., tn} and a private key KParameters: two integers N and lsb, a threshold αOutput: true or falsematches = 0;1
non-matches = 0;2
for k = 1..n do3
result = retrieveMarkFromDataTree(tk,K);4
matches = result[1] + matches;5
non-matches = result[2] + non-matches;6
end7
x = matches / (matches + non-matches);8
if |x− 1/2| ≥ α then9
return true;10
end11
else12
return false;13
end14
Algorithm 3 takes a set of answers and calculates the proportion x of matches between the observeddata and what would be the watermarked data. If the distance between x and 1/2 is greater than thethreshold value α then we decide that the suspicious web service is guilty.
A more precise study needs to be done on that algorithm in order to evaluate the confidence we canhave in its output.

CHAPTER 4. WATERMARKING WEB MESSAGES 14
4.3.2 Detection of false positives
We consider here that the detector observes the data from a suspicious web service which happens to benon guilty. Obviously, it is possible to find a web service which data entails the decision algorithm tooutput an incorrect answer, here true. One may be interested in finding the minimum number of answersnε to retrieve in order to limit the probability that an error occurs to ε.
As we already said, guilt evaluation is done by comparing two sequences of bits u, v ∈ {0, 1}n. Weconsider that u (resp. v) is a realization of a sequence of random variables. Let U = {Ui}i≥0 (resp.V = {Vi}i≥0) be that sequence.
In order to give a theorem about how to build pertinent detectors, we begin by introducing somegeneral definitions and properties on random variables.
Let Xi be the random variable which value is 1 if ui = vi and 0 otherwise.
Definition 12. If U = (Ui)i≥0, V = (Vi)i≥0 are two infinite sequences of i.i.d. random variables, wesay that U and V are independent if for all i ∈ N
∗, Ui and Vi are independent.
Proposition 1. If U, V are independent and for all i ≥ 1, Ui and Vi are uniform laws on the domain{0, 1} then:
• p(Ui = Vi) = 12 .
• E(Xi) = 12 .
• V (Xi) = 14 .
Proof. For the first equality we have:
p(Ui = Vi) = p(Ui = 0 ∧ Vi = 0) + p(Ui = 1 ∧ Vi = 1)
= p(Ui = 0)p(Vi = 0) + p(Ui = 1)p(Vi = 1)
=1
4+
1
4
=1
2.
and the two other equalities are straightforward consequences of the first one.
Let Pn = 1n
n∑
1Xi be the random variable which represents the ratio of matchings between the two
partial sequences (Ui)1,n and (Vi)1,n.
Proposition 2. We have the following relations:
• E[Pn] = 1/2.
• V [Pn] = 14n .
Proof. We have:
E[Pn] = E
[
1
n
n∑
1
Xi
]
=1
n
n∑
1
E[Xi]
=1
2.
V [Pn] = V
[
1
n
n∑
1
Xi
]
=1
n2
n∑
1
V [Xi]
=1
4n.

CHAPTER 4. WATERMARKING WEB MESSAGES 15
A direct consequence of this theorem is that the probability that ui and vi match is 1/2.
Theorem 1 (FP threshold). Let α be the threshold value of our algorithm and ε the probability of falsepositives we want to reach. Then there exists an integer n0 we can easily compute such that if the numberof answers retrieved is greater that n0 then the probability that a non-guilty web service is declared guiltyis less than ε.
In order to show theorem 1, we use the Hoeffding inequality which is given in lemma 1:
Lemma 1. If X1, ..., Xn are independent Bernoulli’s laws of parameter p = E[pn] then:
P
(
|Pn − p| ≥ ε)
≤ 2e−2nε2
.
Proof. The algorithm returns true if |x − 12 | > α where x is the proportion of matchings detected. A
direct application of lemma 1 shows that the probability pfp that a false positive occurs is such that:
pfp = P
(
|Pn −1
2| ≥ α
)
= P
(
|Pn −E[Pn]| ≥ α)
≤ 2e−2nα2
.
Let 0 < ε < 1 the false positive occurrence probability we want to reach and n0 = d 12α2 ln(ε/2)e. We
have:
n ≥ n0
⇐⇒ n > 12α2 ln(ε/2)
⇐⇒ 2e−2nα2
< ε⇐⇒ pfp < ε.
The theorem is shown.
Corollary 1. It is possible to decide at any time on the guiltiness of a web service with a probability offalse positives close to ε by readjusting the threshold value α using the relation:
α =
√
−1
2nln(ε/2)
Graph 4.2 shows how the threshold value should vary in function of the number of answers retrieved.
Clearly, the higher is the number of answers we retrieve the lower the threshold can be. An interestingpoint is that we can superpose the evolution of α and the observed values of |x − 1/2|. On figure 4.2, Aand B are two observed values of |x− 1/2|. For A, we have |xA − 1/2| < α and thus, A is not consideredas a point proving the guilt of the web service. On the contrary, B is above the threshold curve whichlet us think that the web service uses watermarked data.Remark: A limitation of that analysis is that we determine the guilt of a web service only by analyzingthe proportion at a given time. Since it is possible to imagine a situation where the proportion oscillatesbetween guilt and innocence areas, the detector can easily be cheated. A straightforward extension is todesign a more resilient algorithm which takes into account the history of the proportion and decides bycomparing the time spent in both areas. This a natural extension that will not be discussed here.
4.3.3 False negatives
We study here how a malicious user can cheat a detector by altering the data in a way the algorithmoutputs no instead of outputting yes. Our goal is to improve the intelligence of the detecting algorithmso that it can deal with such attacks. Obviously, it is hard, maybe impossible to design a resilient toeverything watermarking framework. We will not try to solve this general problem but only explore howan attacker can crack our algorithm. Obviously, an attacker who does not possess the private key canonly try to modify some bits of the data and pray that the induced modification is sufficient enoughto remove the watermark. We define those attacks as blind ones. The fact is that we can study how
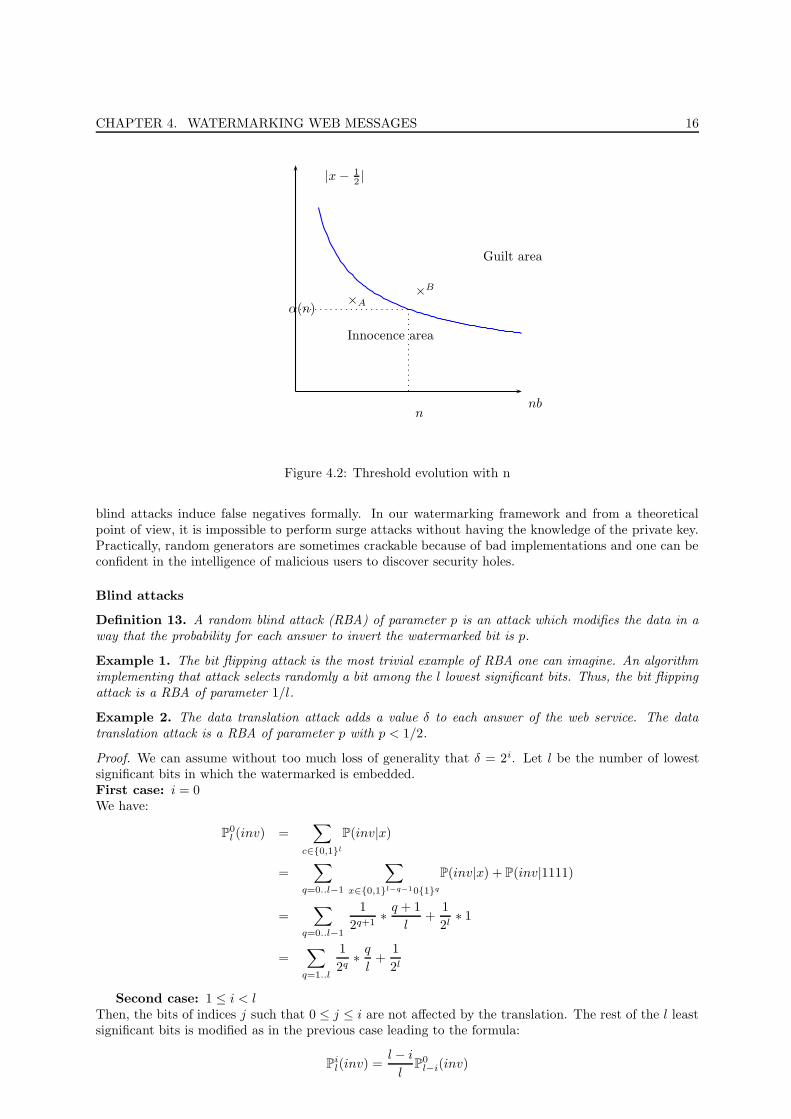
CHAPTER 4. WATERMARKING WEB MESSAGES 16
n
α(n)
Innocence area
Guilt area
×A×B
nb
|x− 12 |
Figure 4.2: Threshold evolution with n
blind attacks induce false negatives formally. In our watermarking framework and from a theoreticalpoint of view, it is impossible to perform surge attacks without having the knowledge of the private key.Practically, random generators are sometimes crackable because of bad implementations and one can beconfident in the intelligence of malicious users to discover security holes.
Blind attacks
Definition 13. A random blind attack (RBA) of parameter p is an attack which modifies the data in away that the probability for each answer to invert the watermarked bit is p.
Example 1. The bit flipping attack is the most trivial example of RBA one can imagine. An algorithmimplementing that attack selects randomly a bit among the l lowest significant bits. Thus, the bit flippingattack is a RBA of parameter 1/l.
Example 2. The data translation attack adds a value δ to each answer of the web service. The datatranslation attack is a RBA of parameter p with p < 1/2.
Proof. We can assume without too much loss of generality that δ = 2i. Let l be the number of lowestsignificant bits in which the watermarked is embedded.First case: i = 0We have:
P0l (inv) =
∑
c∈{0,1}l
P(inv|x)
=∑
q=0..l−1
∑
x∈{0,1}l−q−10{1}q
P(inv|x) + P(inv|1111)
=∑
q=0..l−1
1
2q+1∗
q + 1
l+
1
2l∗ 1
=∑
q=1..l
1
2q∗
q
l+
1
2l
Second case: 1 ≤ i < lThen, the bits of indices j such that 0 ≤ j ≤ i are not affected by the translation. The rest of the l leastsignificant bits is modified as in the previous case leading to the formula:
Pil(inv) =
l − i
lP
0l−i(inv)
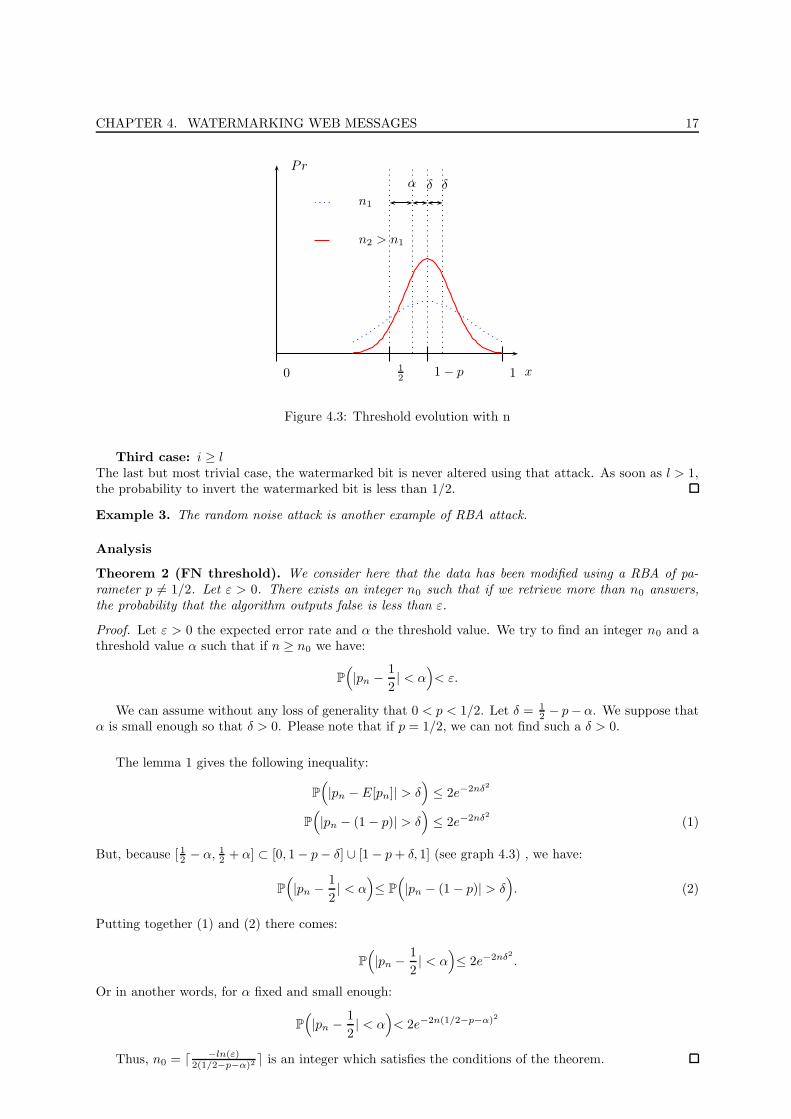
CHAPTER 4. WATERMARKING WEB MESSAGES 17
n1
n2 > n1
Pr
x
δ δα
1− p 10 12
Figure 4.3: Threshold evolution with n
Third case: i ≥ lThe last but most trivial case, the watermarked bit is never altered using that attack. As soon as l > 1,the probability to invert the watermarked bit is less than 1/2.
Example 3. The random noise attack is another example of RBA attack.
Analysis
Theorem 2 (FN threshold). We consider here that the data has been modified using a RBA of pa-rameter p 6= 1/2. Let ε > 0. There exists an integer n0 such that if we retrieve more than n0 answers,the probability that the algorithm outputs false is less than ε.
Proof. Let ε > 0 the expected error rate and α the threshold value. We try to find an integer n0 and athreshold value α such that if n ≥ n0 we have:
P
(
|pn −1
2| < α
)
< ε.
We can assume without any loss of generality that 0 < p < 1/2. Let δ = 12 − p− α. We suppose that
α is small enough so that δ > 0. Please note that if p = 1/2, we can not find such a δ > 0.
The lemma 1 gives the following inequality:
P
(
|pn −E[pn]| > δ)
≤ 2e−2nδ2
P
(
|pn − (1− p)| > δ)
≤ 2e−2nδ2
(1)
But, because [ 12 − α, 12 + α] ⊂ [0, 1− p− δ] ∪ [1− p + δ, 1] (see graph 4.3) , we have:
P
(
|pn −1
2| < α
)
≤ P
(
|pn − (1− p)| > δ)
. (2)
Putting together (1) and (2) there comes:
P
(
|pn −1
2| < α
)
≤ 2e−2nδ2
.
Or in another words, for α fixed and small enough:
P
(
|pn −1
2| < α
)
< 2e−2n(1/2−p−α)2
Thus, n0 = d −ln(ε)2(1/2−p−α)2 e is an integer which satisfies the conditions of the theorem.

CHAPTER 4. WATERMARKING WEB MESSAGES 18
Figure 4.4: Choosing threshold value
n
α
n0
α0
pfp < ε
pfn < ε
4.3.4 Resilient detectors
Theorem 3 sums up results obtained in the two previous subsections:
Theorem 3. Let 0 < ε < 1. Let 0 < pl < 1/2. There exists N0 ∈ N and a detecting algorithm D suchthat for every set of answers TN of size N ≥ N0 on which we make the following assumption:
• either TN is a watermarked set of data attacked by a p-RBA with 0 < p < pl.
• either TN is an uncorrelated set of data.
The probability that D takes the wrong decision is less that ε.
Proof. Let 0 < ε and 0 < pl < 1/2. Let TN a set of N answers from a web service:First case:TN is a watermarked data attacked by a p-RBA attack where 0 < p < pl. Applying theorem 2 we know
that if N0 = d −ln(ε)2(1/2−p−α)2 e, then the probability for the detector with threshold α to be cheated is less
than ε. Furthermore, we can draw the graph 4.3.4 which shows how α should evolve to keep the errorrate inferior to ε. The threshold value is given by the following formula:
α2 =1
2− p−
√
−ln(ε/2)
2n
Second case:TN is a watermarked data coming from a third party source. Having retrieved N answers we know thatwe have to fix the threshold to the value α1 if we want to have an error rate shortest than ε where α1 isgiven by the following formula:
α1 =
√
−ln(ε/2)
2n
The evolution of the two curves is shown on figure 4.3.4. When the two curves intersect, we knowthat the corresponding threshold value α permits to build an algorithm which mistakes only less for ε%of its input data if the size of the input is more than the corresponding value n0 where:
np0 =−ln(ε/2)
1− 2p
And if we make p tends to its limit pl we can say that n0 given by the formula behind is ok:
n0 =−ln(ε/2)
1− 2pl

CHAPTER 4. WATERMARKING WEB MESSAGES 19
Figure 4.5: A SOAP message outputted by our web service
<?xml version="1.0" encoding="UTF-8"?>
<soapenv:Envelope>
<soapenv:Body>
<ns1:whatTimeResponse>
<outdate href="#id0"/>
</ns1:whatTimeResponse>
<multiRef id="id0" type="ns2:dateType">
<year xsi:type="xsd:int">104</year>
<month xsi:type="xsd:int">6</month>
<hours xsi:type="xsd:int">11</hours>
<minutes xsi:type="xsd:int">38</minutes>
<seconds xsi:type="xsd:int">54</seconds>
<milliseconds type="xsd:int">325</milliseconds>
</multiRef>
</soapenv:Body>
</soapenv:Envelope>
Corollary 2. It is possible to decide at any time on the guiltiness of a web service with a probability offalse negatives for p-RBAs inferior to ε and a probability of false positives inferior to ε by readjusting thethreshold value α2 using the relation:
α1 =1
2− p−
√
1
2nln(ε/2)
4.4 Experimentations
4.4.1 Web service
In order to validate our model, we performed tests using a time web service. We embed a copyright markin the output of the service using our watermarking algorithm. We use Apache Axis [AXI] as a webservice container, an implementation of SOAP [Gro03] by the Apache foundation. The axis distributionis bundled with software packages that enable to quickly publish Java classes as web services and also togenerate Java Classes from a web service description written in WSDL [Chr01]. The tests were lead ona Intel Pentium 4 processor with 512Mb of Ram.
Figure 4.5 shows an example of output from our toy web service.
4.4.2 Watermarking process
For a given answer, we build a key by concatenating the value of the following fields of the input: minutesand seconds. We insert the watermark in the l = 4 least significant bits of the milliseconds field generatinga maximum perturbation of 7 milliseconds.
4.4.3 Results
We try various attacks in order to remove the watermark and we give below results obtained when thedata is altered by (1) a RBA and (2) by a more intelligent attack which will be described further on.
Bit Flipping attack We fix a decision error rate of ε = 0.1 and we draw the distance between theobserved proportion of matches x and what would be the expected proportion of an arbitrary data 1/2.
Figure 4.6 shows the evolution of |x−1/2| with the number of answers retrieved. When |x−1/2| > α2
the service is declared guilty. Remark that this condition is true at any time. Secondly, the curve lookslike a step function. In that test-bed, we observe a ratio x < 1/2 so that |x−1/2| = 1/2− < 0. When onematching bit is observed, the curve suddenly raises and when no matching bits are found, it decreasesuntil another matching bit is found.
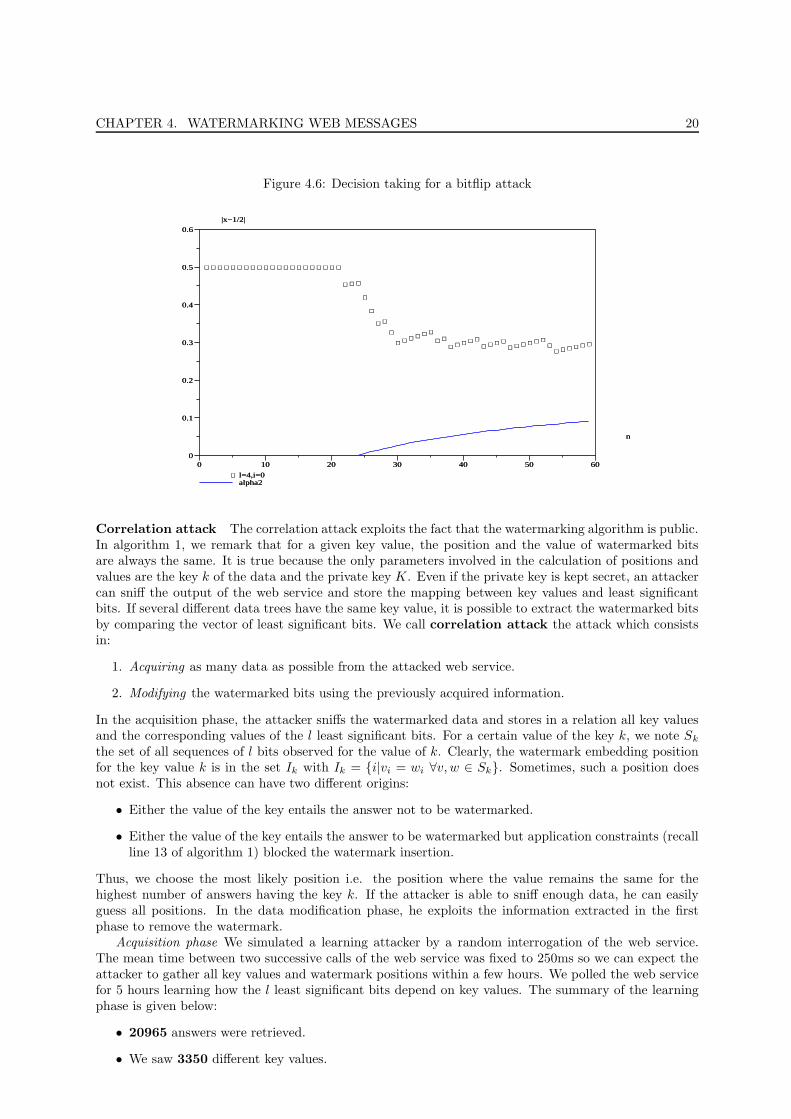
CHAPTER 4. WATERMARKING WEB MESSAGES 20
Figure 4.6: Decision taking for a bitflip attack
0 10 20 30 40 50 600
0.1
0.2
0.3
0.4
0.5
0.6
+ + + + + + + + + + + + + + + + + + + + +
+ + +
+
+
+ +
+
+ + + + + ++ +
+ + + + ++ + + +
+ + + + + ++
+ + + + + +
l=4,i=0+
alpha2
n
|x−1/2|
0 10 20 30 40 50 600
0.1
0.2
0.3
0.4
0.5
0.6
+ + + + + + + + + + + + + + + + + + + + +
+ + +
+
+
+ +
+
+ + + + + ++ +
+ + + + ++ + + +
+ + + + + ++
+ + + + + +
l=4,i=0+
alpha2
n
|x−1/2|
Correlation attack The correlation attack exploits the fact that the watermarking algorithm is public.In algorithm 1, we remark that for a given key value, the position and the value of watermarked bitsare always the same. It is true because the only parameters involved in the calculation of positions andvalues are the key k of the data and the private key K. Even if the private key is kept secret, an attackercan sniff the output of the web service and store the mapping between key values and least significantbits. If several different data trees have the same key value, it is possible to extract the watermarked bitsby comparing the vector of least significant bits. We call correlation attack the attack which consistsin:
1. Acquiring as many data as possible from the attacked web service.
2. Modifying the watermarked bits using the previously acquired information.
In the acquisition phase, the attacker sniffs the watermarked data and stores in a relation all key valuesand the corresponding values of the l least significant bits. For a certain value of the key k, we note Sk
the set of all sequences of l bits observed for the value of k. Clearly, the watermark embedding positionfor the key value k is in the set Ik with Ik = {i|vi = wi ∀v, w ∈ Sk}. Sometimes, such a position doesnot exist. This absence can have two different origins:
• Either the value of the key entails the answer not to be watermarked.
• Either the value of the key entails the answer to be watermarked but application constraints (recallline 13 of algorithm 1) blocked the watermark insertion.
Thus, we choose the most likely position i.e. the position where the value remains the same for thehighest number of answers having the key k. If the attacker is able to sniff enough data, he can easilyguess all positions. In the data modification phase, he exploits the information extracted in the firstphase to remove the watermark.
Acquisition phase We simulated a learning attacker by a random interrogation of the web service.The mean time between two successive calls of the web service was fixed to 250ms so we can expect theattacker to gather all key values and watermark positions within a few hours. We polled the web servicefor 5 hours learning how the l least significant bits depend on key values. The summary of the learningphase is given below:
• 20965 answers were retrieved.
• We saw 3350 different key values.
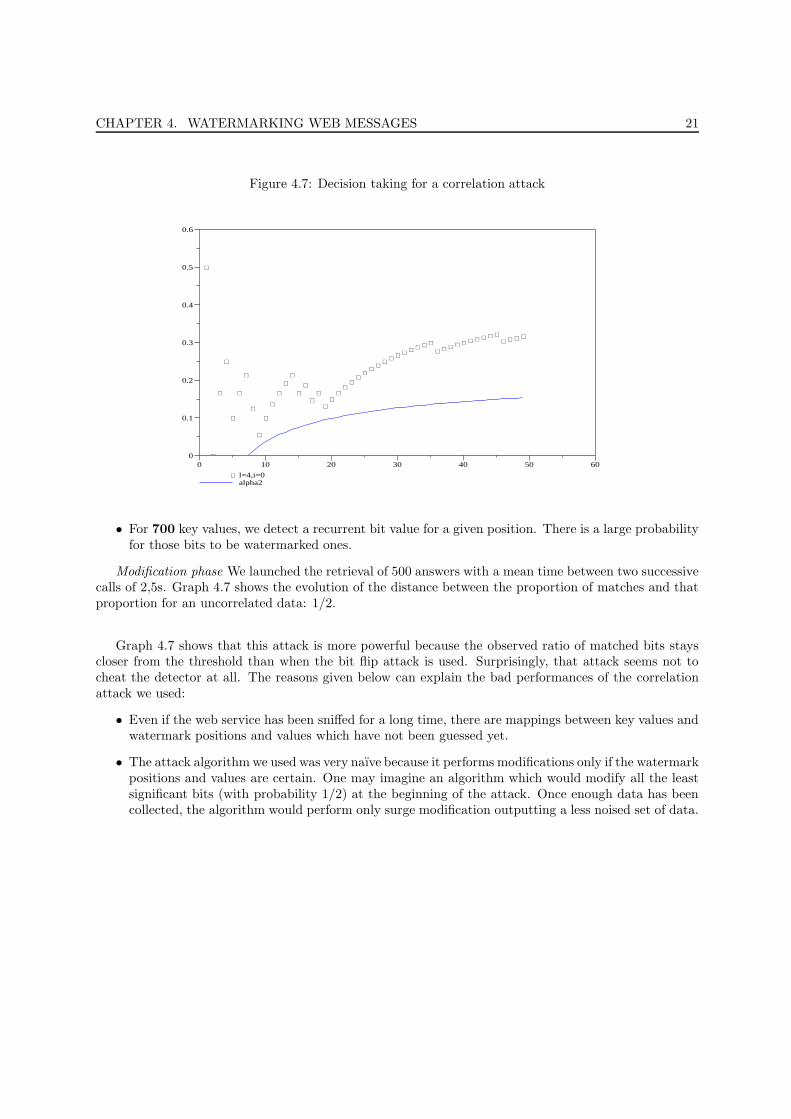
CHAPTER 4. WATERMARKING WEB MESSAGES 21
Figure 4.7: Decision taking for a correlation attack
0 10 20 30 40 50 600
0.1
0.2
0.3
0.4
0.5
0.6
+
+
+
+
+
+
+
+
+
+
+
+
++
++
++
++
++
++
++
+ + + + + + + + ++ + + + + + + + + +
+ + + +
l=4,i=0+
alpha2
• For 700 key values, we detect a recurrent bit value for a given position. There is a large probabilityfor those bits to be watermarked ones.
Modification phase We launched the retrieval of 500 answers with a mean time between two successivecalls of 2,5s. Graph 4.7 shows the evolution of the distance between the proportion of matches and thatproportion for an uncorrelated data: 1/2.
Graph 4.7 shows that this attack is more powerful because the observed ratio of matched bits stayscloser from the threshold than when the bit flip attack is used. Surprisingly, that attack seems not tocheat the detector at all. The reasons given below can explain the bad performances of the correlationattack we used:
• Even if the web service has been sniffed for a long time, there are mappings between key values andwatermark positions and values which have not been guessed yet.
• The attack algorithm we used was very naıve because it performs modifications only if the watermarkpositions and values are certain. One may imagine an algorithm which would modify all the leastsignificant bits (with probability 1/2) at the beginning of the attack. Once enough data has beencollected, the algorithm would perform only surge modification outputting a less noised set of data.

CHAPTER 5. AUTOMATA AND TRANSDUCERS 22
Chapter 5
Automata and transducers
5.1 Introduction
We have come to the point where we know how to watermark single objects exchanged between twopeers of a workflow. The problem is now to find whether it is possible or not to track the watermarkedpiece of data through the transformations. Clearly, it is impossible in the most general case but we thinkthe study of a restricted class of transformations is worth of interest. As a consequence we will studystructural transformations on trees that include:
• moving, deleting existing nodes.
• creating new nodes.
• inserting values in the output using values found in the input.
One may argue that using only values of the input is a very restrictive choice but we answer that it ispossible to enrich our model to add external values without affecting the theoretical results. Furthermorebecause we are only interested in tracking the watermarked data, we take into account only the input data.That kind of transformation can be found in real applications. For instance, XSL 1.0 transformationscan be expressed in the formalism we give. First, we give some definitions and examples and next, wegive some feasibility results.
5.2 Definitions
5.2.1 Tree transducers
We give here the definition of k-pebble tree transducers. It is shown in [MSV00] that they expressall XSLT structural transformations. They work on binary trees and interestingly it is not a restrictionsince it is possible to encode any ranked even unranked tree into a binary one. The interested readermay refer to [MSV00] for deeper explanations.
Informally, given two alphabets of labels Σ and Σ′ a k-pebble tree transducer is a finite statemachine which takes a Σ-tree as input and outputs a Σ′-tree (a data tree is a Σ-tree if all its nodes labelsare in Σ).
Definition 14 (k-pebble tree transducer). A k-pebble tree transducer is a tuple T = (Σ, Σ′, Q, q0, P )such that:
• Σ and Σ′ are two sets of labels. We denote (a0, b0, a2, b2, ...) elements of Σ and (a′
0, b′
0, a′
2, b′
2, ...)elements of Σ′.
• Q is a finite set of states which can be partitioned into k subsets: Q = Q1 ∪ ... ∪ Qk. We denoteelements in Qi with a superscript, as in qi.
• q0 ∈ Q1 is the initial state.
• P is the set of transitions. If p ∈ P , p is one of the following rule

CHAPTER 5. AUTOMATA AND TRANSDUCERS 23
– Move transitions
(a, b, qi1) → (qi
2, stay)
(a, b, qi1) → (qi
2,down-left)
(a, b, qi1) → (qi
2,down-right)
(a, b, qi1) → (qi
2,up)
– Pebbles management transitions
(a, b, qi1) → (qi+1
1 ,place-new-pebble)
(a, b, qi1) → (qi−1
1 ,pick-current-pebble)
– Output transitions
(a, b, qi) → (a′
0,output0)
(a, b, qi) → (a′
2(qi1, q
i2),output2)
Next, we give the formal definition of how an output data tree is generated using a k-pebble transducer.Intuitively, the input tree can be regarded as a game deck on which you can place and move pebbles.Those pebbles are the physical materialization of states.
Keeping in mind that analogy helps to understand the intuitions beyond the formal model given above.Indeed, move transitions can be viewed as pebble moves on the deck. Furthermore, pebble managementtransitions can be viewed as a way to put and remove pebbles. The b parameter in a transition enablesto test whether some pebbles are on the same position on the deck or not.
Formally, the state of a deck is called a configuration. A configuration γ is a triple (i, (xp)1..i, qi)
where i is the number of pebbles already on the deck. The vector x = (x1, ..., xi) codes the positionsof the different pebbles and the state qi is the current state of the last pebble put on the deck. The
computation process begins by the initial configuration γ0 = (1, (root), q0). We say that γp−→ γ′ if there
exists a transition p ∈ P such that xp = xi if and only if bp = 1 and label(xi) = a and:
• p = (a, b, qi1)→ (qi
2, stay), γ = (i, (xp)1..i, qi1) and γ′ = (i, (xp)1..i, q
i2)
• p = (a, b, qi1) → (qi
2,down-left), γ = (i, (xp)1..i, qi1), γ′ = (i, (x1, .., xp−1, y), qi
2) and the node y isthe left child of xp.
• p = (a, b, qi1) → (qi
2,down-right), γ = (i, (xp)1..i, qi1), γ′ = (i, (x1, .., xp−1, y), qi
2) and the node y isthe right child of xp.
• p = (a, b, qi1)→ (qi
2,up), γ = (i, (xp)1..i, qi1), γ′ = (i, (x1, .., xp−1, y), qi
2) and the node y is the fatherof xp.
• p = (a, b, qi1)→ (qi+1
1 ,place-new-pebble), γ = (i, (xp)1..i, qi1) and γ′ = (i+1, (x1, ..., xi, root), q
i+11 )
• p = (a, b, qi1) → (qi+1
1 ,pick-current-pebble), γ = (i, (xp)1..i, qi1) and γ′ = (i + 1, (x1, ..., xi −
1), qi−11 )
Furthermore we say that γp0
−→ a0′ if there exists a transition p0 of the form (a, b, qi)→ (a
′
0,output0) and
γ = (i, (xp)1..i, qi1). Finally, γ
p2
−→ a2(γ1, γ2) if p2 = (a, b, qi)→ (a′
2(qi1, q
i2),output2) , γ = (i, (xp)1..i, q
i),γ1 = (i, (xp)1..i, q
i1) and γ2 = (i, (xp)1..i, q
i2).
Thus, given an input tree, the transducer computes an output tree from top to bottom. At any time,the leaves labelled by configurations represent the non-finished parts of the computation. Each time anoutput2 transition is activated the transducer forks and the first thread computes the left child while thesecond thread computes the right one. So, the building of the output tree is a recursive process. A datatree t is an output of the transducer if there exists a sequence of transitions which can be activated such

CHAPTER 5. AUTOMATA AND TRANSDUCERS 24
that γ0 → ... → t. We add data values to the output by copying the value of the node under the lastpebble each time an output transition is taken.
The definition of the transducer through its states and its transitions table can regarded as the sourcecode of an XML transformation. Despite the fact that this language is not Turing complete, somestrange things can occur. Indeed, if we are given a DTD and the source code of such a transducer itis not straightforward whether a particular input data tree generates an output or not. At any time ofthe execution of the transducer, a partially computed tree is available which leaves are either labeled byterminal symbols or by configurations of the transducer. It is possible to find trees which never gives acomplete output tree, i.e. a tree which nodes are exclusively labeled by terminal symbols. The result oftheorem 4 shows that one can build an algorithm that statically decide if a transformation will generatean output for all the elements of its input language.
Theorem 4. Let τ a tree type. Checking that each data tree in L(τ) generates an output through ak-pebble transducer is decidable.
Proof. Let T be a k-pebble tree transducer. We can convert T = (Σ, Σ′, Q, q0, P ) into a recognizerautomaton A = (Σ, Q, q0, P0) where the transition table P0 can be easily deduced from P by replacingthe output transitions by the following rules:
• (a0, b, qi)→ (branch0)
• (a, b, qi)→ ((qi1, q
i2),branch2)
It is shown in [MSV00] that the language recognized by A is regular. Let LA be that language. It isstraightforward that A accepts a data tree t if and only if t ∈ LA. As a consequence, T generates anoutput data tree t for every t ∈ L(τ) if and only if L(τ) ⊆ LA. We conclude by saying that checking theinclusion of two regular tree languages is decidable.
5.2.2 String transducers
As we defined a finite state machine to build trees from trees, we also give the definition of another kindof finite state machines which transforms strings (e.g. sequences of symbols) into other strings.
Definition 15 (k-pebble string transducer). A k-pebble string transducer is a tuple T = (Σ, Σ′, Q, q0, P )such that:
• Σ and Σ′ are two sets of labels. We denote (a, b, c, ...) elements of Σ and (a′, b′, c′, ...) elements ofΣ′.
• Q is a finite set of states which can be partitioned into k subsets: Q = Q1 ∪ ... ∪ Qk. We denoteelements in Qi with a superscript, as in qi.
• q0 ∈ Q1 is the initial state.
• P is the transitions set. If p ∈ P , p is one of the following rule
– Move transitions
(a, b, qi1) → (qi
2, stay)
(a, b, qi1) → (qi
2,next)
(a, b, qi1) → (qi
2, back)
– Pebbles management transitions
(a, b, qi1) → (qi+1
1 ,place-new-pebble)
(a, b, qi1) → (qi−1
1 ,pick-current-pebble)

CHAPTER 5. AUTOMATA AND TRANSDUCERS 25
– Output transitions
(a, b, qi) → (a′
,output)
The definition of how the output of a k-pebble string transducer is built can be easily deduced by thereader using the one given above for k-pebble tree transducers.
Example 4. The 1-pebble transducer given below is the most common example. It simply copies aninput tree to the output. We denote by an underscript 2 the words which label branching nodes and by anunderscript 0 the words which label leaves.
∀a2 (q, a2) → (a2(q1, q2),output2)
∀a2 (q1, a2) → (q, bottom-left)
∀a2 (q1, a2) → (q, bottom-left)
∀a0 (q, a0) → (a0,output0)
Example 5. The transducer given below renames the nodes labelled by b and c into nodes labelled by d.
(q0, a) → (a(q1, q2),output2)
(q1, a) → (q0, bottom-left)
(q2, a) → (q0, bottom-right)
(q0, b) → (d,output0)
(q0, c) → (d,output0)
5.3 Tracking watermarked data through transformations
5.3.1 Definition
Let’s suppose that A and B are two peers involved in a web services workflow and that B performs anoperation OB on the watermarked data outputted by A. In order to retrieve its watermark in the dataoutputted by B, A has to know where its data goes. The theoretical problem A want to solve is to findwhere he has to put his watermark in order to retrieve it in B’s output. Clearly, this problem is linkedwith the problem of finding where a distinguished node of the input can be found in the output tree.
As a way to characterize a node in a tree, we use the concept of fully qualified path. Intuitively, afully qualified path is a path expression which selects only one node in a data tree.
Definition 16 (fully qualified path). A fully qualified path (fqp) is a sequence of pairs ((li, di))i=1..n
such that:
• for i = 1..n− 1, li is a label from Σ and where di ∈ {l, r} (l stands for left and r for right).
• ln is a label from Σ and dn = −.
5.3.2 FQP tracking problem
The main goal we want to achieve is summarized below under the name of fqp-tracking problem:
FQP-tracking problemIf O : L1 → L2 is a web operation, is it possible to find a function f whichconverts any fully qualified path p1 into a finite set of fully qualified paths
such that for every t1 ∈ L1 we have the following relation:
∀p2 ∈ f(p1) v(p1(t1)) = v(p2(O(t1)))? (equality of values)
The example below shows how f should map a fqp on the input tree to a fqp on the output tree:

CHAPTER 5. AUTOMATA AND TRANSDUCERS 26
Figure 5.1: An example of tree transducer
q0
q1
q2
qf
(a,a2)
(a,↙)(a,a2)
(a,↘)
(b,d0)
(b,c0)
Example 6. Let O be a web operation which input and output DTDs are given below:
DTDi DTDo
a::=bc a:=ddb::=ε d::=εc::=ε
A friendly vision of this transducer is available on figure 5.1. Let t = a(b(12)c(13)) and t′ = O(t). Then,we have t′ = a(d(12)d(13)) and the fqp converting function f should give the following mappings:
• (a, l)(b,−)f7−→ (a, l)(d,−)
• (a, r)(c,−)f7−→ (a, r)(d,−)
5.3.3 Unfeasibility result
Theorem 5. It is impossible to solve the FQP-tracking problem for any web operation O defined by akptt.
Proof. The main reason why we can not do this is that pebbles are able to walk on the input tree andthus, are able to go out a predefined fqp. Thus, one needs to have the full knowledge of the input tree todecide where the data embedded in the node defined by the fqp will be outputted. As a counter example,consider the web operation O : Lτ → Lτ ′ where:
• τ = {N , λ, δ} withN = {na, nb, nc}, λ(na) = a, λ(nb) = b and λ(nc) = c, δ(na) = nb[nb|nc], δ(nb) =δ(nc) = ε.
• τ ′ is a tree type on the alphabet Σ′ = {a′}.
Since the description of the counter example in terms of kppt is a bit heavy to write and understandonce written, we explain only how O constructs its output. At the beginning of the computation, the headof the automaton is located on the root node of the input, labeled by a. It then makes a bottom− rightmovement. Then the computation can take two different ways in function of the label of the right child:

CHAPTER 5. AUTOMATA AND TRANSDUCERS 27
• If the left child if labeled by b, the automaton takes an output0(a′) transition.
• If the left child if labeled by b, it makes a up transition followed by bottom− left and output0(a′)
transition.
Then, it is impossible to find a corresponding fqp for (a, l)(b,−). Indeed, (a′,−) would be a goodcandidate but for a tree t1 which right child is labeled by c, we generally have: v(p1(t1)) 6= v(p2(O(t1)))with p1 = (a, l)(b,−) and p2 = (a′,−).
Figure 5.2: An example of fqp transducer
q0
q1
q2
qf
((a,*),(a,g),stay)
((a,g),∅,next)((a,*),(a,d),stay)
((a,d),∅,next)
((b,*),(d,-),stay)
((c,*),(d,-),stay)
5.3.4 Feasibility result
Now, we isolate a class of operations for which we can solve the FQP-tracking problem. Obviously,the problem comes from the fact that the automaton is able to move up and down and thus is able tovisit all nodes of the input tree. Furthermore, when a new pebble is added, it can explore another fullyqualified path. It seems that a sufficient condition to solve the FQP-tracking would be that the numberof pebble is restricted to one and that the automaton is not able to make up transitions.
It happens that we can construct the fqp converting function by transforming a tree transducer intoa string transducer for a restricted class of tree transducers.
Theorem 6. It is possible to solve the FQP-tracking problem for any web operation O defined by a kpttwith the restrictions:
• O has only one pebble.
• there is no up transition in the transition table of O.
Remark: In the literature, such transducers are called top-down transducers.
Proof. The proof can be divided into two parts:
1. First, we transform the tree transducer which defines the web operation into a string transducer onfully qualified paths. We call that kind of transducers fqp transducers.
2. We prove the theorem using the defined string transducer as the f function.

CHAPTER 5. AUTOMATA AND TRANSDUCERS 28
Let T = (Σ, Σ′, Q, q0, P ) meeting the restrictions of the theorem. Let T ′ = (Σ × {l, r,−}, Σ′ ×{l, r,−}, Q∪ {qf}, q0, P
′) be a string transducer where the transition table P ′ is easily computed from Pusing the formulas given below:
P P ′
(a, b, qi1)→ (qi
2, stay) ((a, ∗), b, qi1)→ (qi
2, stay)
(a, b, qi1)→ (qi
2,down-left) ((a, l), b, qi1)→ (qi
2,next)
(a, b, qi1)→ (qi
2,down-right) ((a, r), b, qi1)→ (qi
2,next)
(a, b, qi)→ (a′0,output0) ((a, ∗), b, qi
1)→ ((a′0,−), qf ,output)
(a, b, qi)→ (a′
2(qi1, q
i2),output2) ((a, ∗), b, qi)→ ((a′
2, l), qi1output)
((a, ∗), b, qi)→ ((a′2, r), q
i2,output)
In order to illustrate the previous definition, the graphs on figures 5.1 and 5.2 offer a friendly visionof how the conversion is done.
It is clear that the function defined by f(p) = T ′(p) is a function which solves the fqp-trackingproblem.

CHAPTER 6. CONCLUSION AND FUTURE WORK 29
Chapter 6
Conclusion and future work
After a motivation for our work, we introduced a watermarking framework for documents manipulatedby web services. We implemented the watermark insertion and retrieval algorithm for a single data tree.
Since one can imagine real applications where such documents are small, we make the assumptionthat it is impossible to embed a watermark in a single document in a resilient manner. What we do isspreading the watermark on a set of answers A pertinent decision on the guilt of a suspicious web serviceis taken by collecting enough successive answers from it.
We performed a theoretical study on how to build a pertinent and resilient detector leading to thefollowing results:
1. We know how to calculate the minimum number of answers to retrieve from a suspicious web servicein order to take a pertinent decision on its guilt.
2. We explored the field of attacks and showed that it is a difficult task to perform a perfect removalof the watermark i.e. invert the watermarking process, if the secret key remains unknown.
3. We validated our theoretical results by using a time web service and performing common attackson the watermarked data outputted by this web service.
Even if our solution is not the ultimate one to protect copyright rights, we think that it can bepractically usable with good results as a complement to cryptographic techniques. The problem does notrequire any further theoretical study but only the development of a generic watermarking software forweb services. This is only a coding issue.
In parallel of that study, we study how it is possible to build cooperative web service workflows i.e.finding a way to protect the ownership of several peers by an offline agreement of those peers. Clearly,a first problem to solve is to find a way to check the property of a watermarked data even if that datahas been transformed, e.g. by another web service. In order to solve that problem, we modeled WebOperations as formal tree transducers and try to guess, given the code of a tree transducer, where eachpart of the input data can be retrieved in the output. We obtained the following result:
4. The node tracking problem is decidable for top-down tree transducers.
It is an open problem whether there are other classes of transducers for which the node trackingproblem is decidable. An interesting point would be to study invertibility properties of tree transducers.

BIBLIOGRAPHY 30
Bibliography
[AK02] R. Agrawal and J. Kiernan. Watermarking relational databases, 2002.
[AMN+01] Noga Alon, Tova Milo, Frank Neven, Dan Suciu, and Victor Vianu. XML with data values:Typechecking revisited. In Symposium on Principles of Database Systems, 2001.
[AXI] http://ws.apache.org/axis/.
[Chr01] Erik Christensen. Web services description language. http://www.w3.org/TR/wsdl.html,March 2001.
[GA03] David Gross-Amblard. Query-preserving watermarking in databases and xml documents. InSymposium on Principles of Database Systems (PODS), 2003.
[Gro01] XML Schema Working Group. Xml schema. http://www.w3.org/XML/Schema, May 2001.
[Gro03] XML Protocol Working Group. Soap 1.2 recommandation. http://www.w3.org/TR/soap12/,June 2003.
[HU79] John Hopcroft and Jeffrey Ullman. Introduction to Automata Theory, Languages and Com-putation. Addison-Wesley, 1979.
[KZ00] Sanjeev Khanna and Francis Zane. Watermarking maps: hiding information in structureddata. In Symposium on Discrete Algorithms, pages 596–605, 2000.
[MAP] http://www.mappy.com.
[MN03] W. Martens and F. Neven. Typechecking top-down uniform unranked tree transducers, 2003.
[MSV00] Tova Milo, Dan Suciu, and Victor Vianu. Typechecking for XML transformers. In Proceedingsof the Nineteenth ACM SIGMOD-SIGACT-SIGART Symposium on Principles of DatabaseSystems, pages 11–22. ACM, 2000.
[SAP02] Radu Sion, Mikhail Atallah, and Sunil Prabhakar. Watermarking relational databases. Tech-nical report, CERIAS, 2002. CERIAS TR 2002-28.
[SAP04] Radu Sion, Mikhail Atallah, and Sunil Prabhakar. Resilient rights protection for sensorstreams. In Proc. of the 30th International Conference on Very Large Data Bases, Toronto,2004.
[SK00] Fabien A.P. Petitcolas Stefan Katzenbeisser. Information hiding, techniques for steganographyand digital watermarking. Artech house, 2000.
[Tho99] Wolfgang Thomas. Handbook of formal Languages, volume Vol. 3 - Beyond Words, chapterLanguages, Automata and Logic. G. Rozenberg and A. Salomaa, 1999.
[WAT] http://watermill.sourceforge.net.


























![[Digital Watermarking 01 & 02] Applications and Properties of Watermarking](https://img.pdfslide.us/doc/110x75/577d34c41a28ab3a6b8ecca2/digital-watermarking-01-02-applications-and-properties-of-watermarking.jpg)


