Embed Size (px)
Citation preview

Energy and Performance Exploration of Accelerator Coherency Port Using Xilinx
ZYNQ
Mohammadsadegh Sadri, Christian Weis, Norbert When and Luca Benini Department of Electrical, Electronic and Information Engineering (DEI) University of Bologna, Italy
Microelectronic Systems Design Research Group, University of Kaiserslautern, Germany
{mohammadsadegh.sadr2,luca.benini}@unibo.it, {weis,wehn}@eit.uni-kl.de
ver0
Mohammadsadegh Sadri, Christian Weis, Norbert Wehn, Luca Benini – Energy and performance exploration of ACP Using ZYNQ 2
Outline
Experimental Results
Memory Sharing Methods
Infrastructure Setup (Hardware & Software)
Motivations & Contributions
ZYNQ Architecture (Brief)
Introduction
Lessons Learned & Conclusion
Mohammadsadegh Sadri, Christian Weis, Norbert Wehn, Luca Benini – Energy and performance exploration of ACP Using ZYNQ(c) Luca Bedogni 2012
Introduction
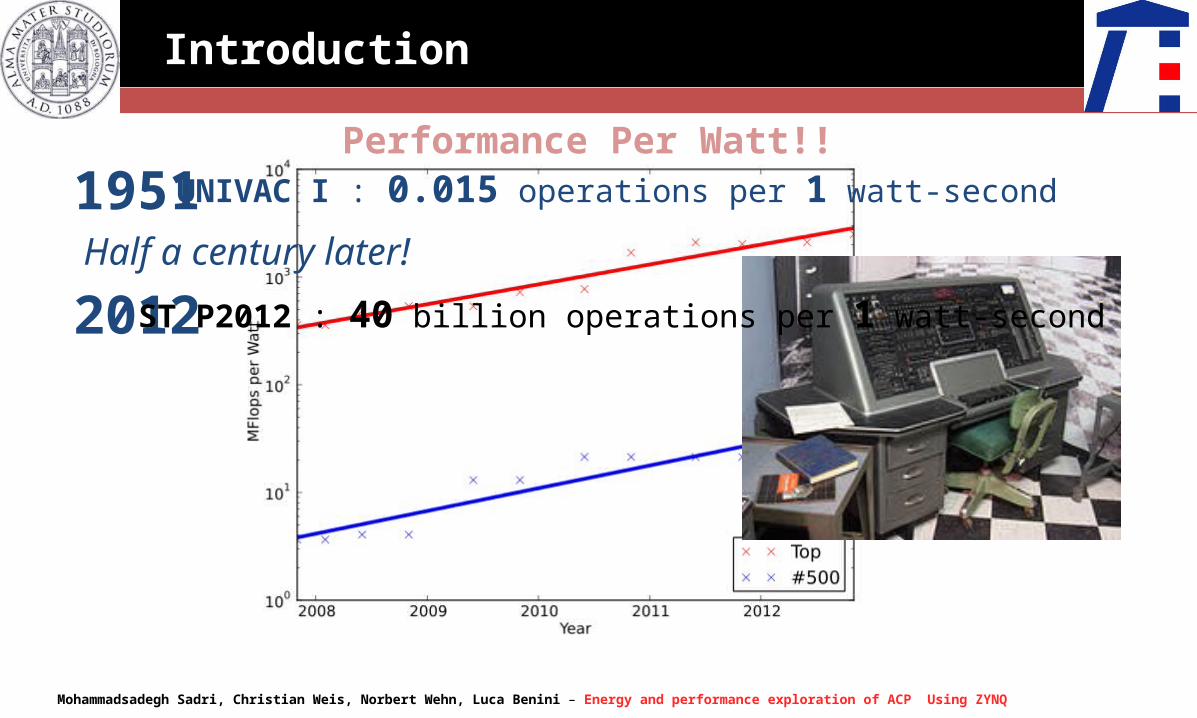
Performance Per Watt!!
1951 UNIVAC I : 0.015 operations per 1 watt-second
2012Half a century later!
ST P2012 : 40 billion operations per 1 watt-second

Mohammadsadegh Sadri, Christian Weis, Norbert Wehn, Luca Benini – Energy and performance exploration of ACP Using ZYNQ
Accelerator(specialized hardware)
Accelerator(specialized hardware)
Introduction
Solution : Specialized functional units (Accelerators)
CPU
L1$
DRAM
Case 1
TASK 1
TASK 2
TASK 3
TASK 4
var1
var2
var3var1var2
cached
Case 2Faster! More Power Efficient!
Better Performance Per Watt!
What about Variables?
?????CPU should Flush the cache!
- Problem can be more complicated! e.g. Multiple CPU cores!
- Every processing element:Should have a consistent view of the shared
memory!
- Accelerator Coherency Port (ACP):Allows accelerator hardware
To Perform coherent accessesTo CPU(s) memory space!
Mohammadsadegh Sadri, Christian Weis, Norbert Wehn, Luca Benini – Energy and performance exploration of ACP Using ZYNQ 5
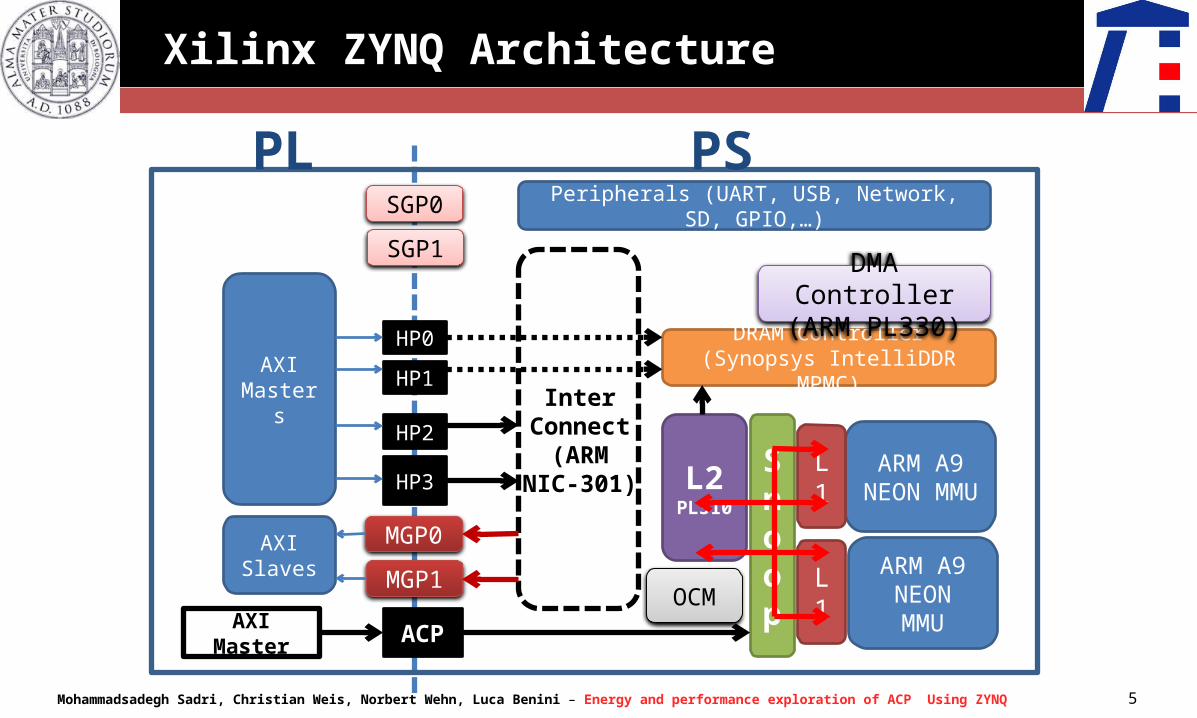
OCM
PL PS
ARM A9NEON MMU
ARM A9NEONMMU
L1
L1
Snoop
L2PL310
DRAM Controller(Synopsys IntelliDDR MPMC)
Peripherals (UART, USB, Network, SD, GPIO,…)
InterConnect
(ARMNIC-301)
HP0
HP1
HP2
HP3
SGP0
SGP1
MGP0
MGP1
AXIMasters
AXISlaves
AXI Master ACP
DMA Controller (ARM PL330)
Xilinx ZYNQ Architecture

Mohammadsadegh Sadri, Christian Weis, Norbert Wehn, Luca Benini – Energy and performance exploration of ACP Using ZYNQ 6
OCM
PL PS
DRAM ControllerHP0
AXI Master(Accelerator)
ACP
L2PL310
Motivations & Contributions
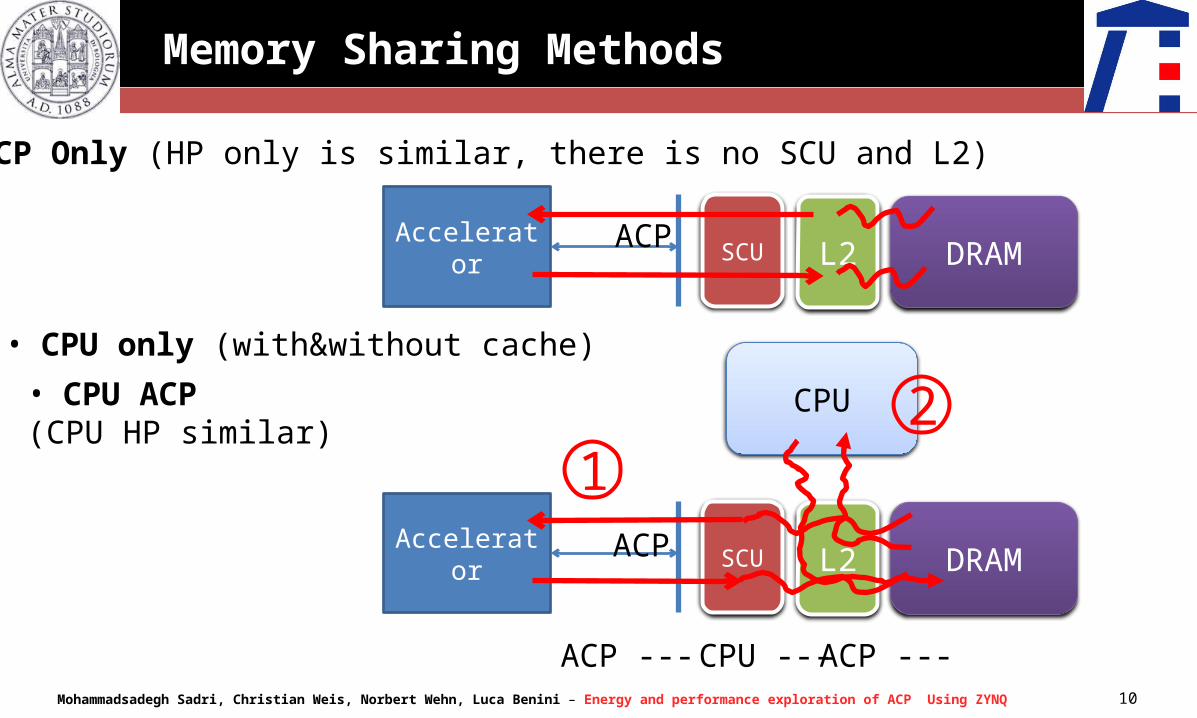
Which method is better to share data between CPU and Accelerator?
ARM A9NEON MMU
ARM A9NEONMMU
L1
L1
Snoop
For each method,What is the data transfer speed?How much is the energy consumption?Effect of background workload on performance?
- Various acceleration methods are addressed in the literature (GPU, hardware boards, …)
- We develop an infrastructure (HW+SW)
For the Xilinx ZYNQ
- We run practical tests & measurementsTo quantify the efficiency of different CPU-accelerator
memory sharing methods.
Mohammadsadegh Sadri, Christian Weis, Norbert Wehn, Luca Benini – Energy and performance exploration of ACP Using ZYNQ 7
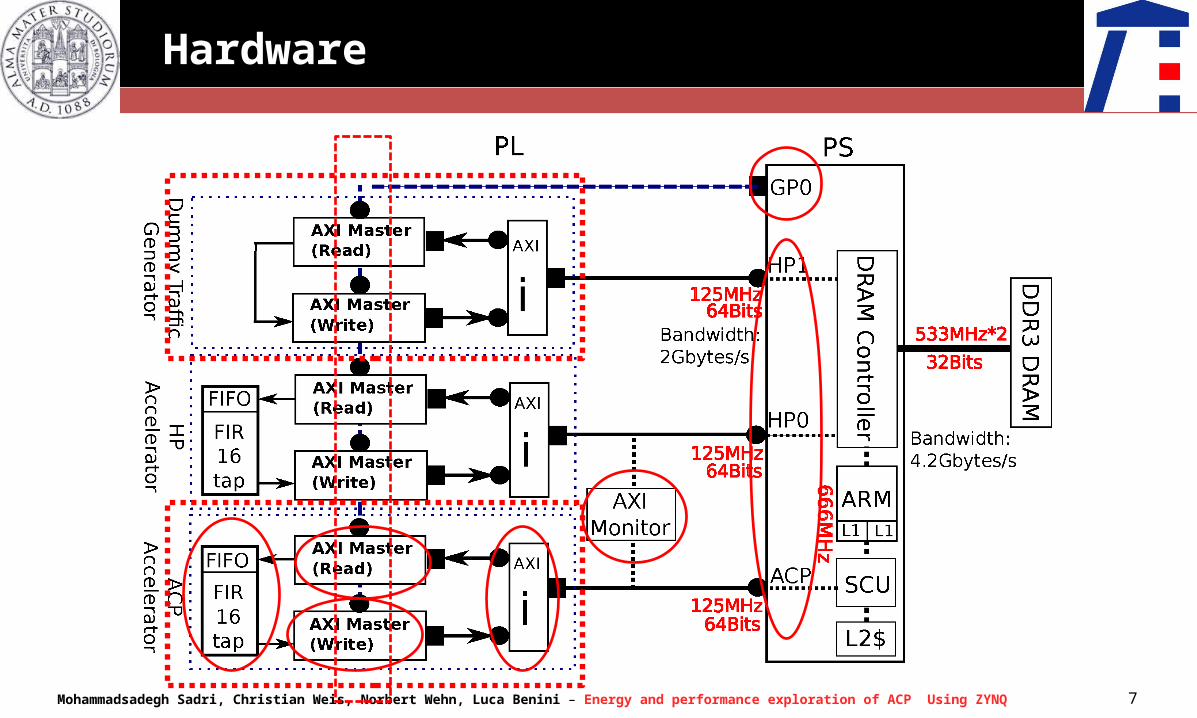
Hardware
Mohammadsadegh Sadri, Christian Weis, Norbert Wehn, Luca Benini – Energy and performance exploration of ACP Using ZYNQ 8
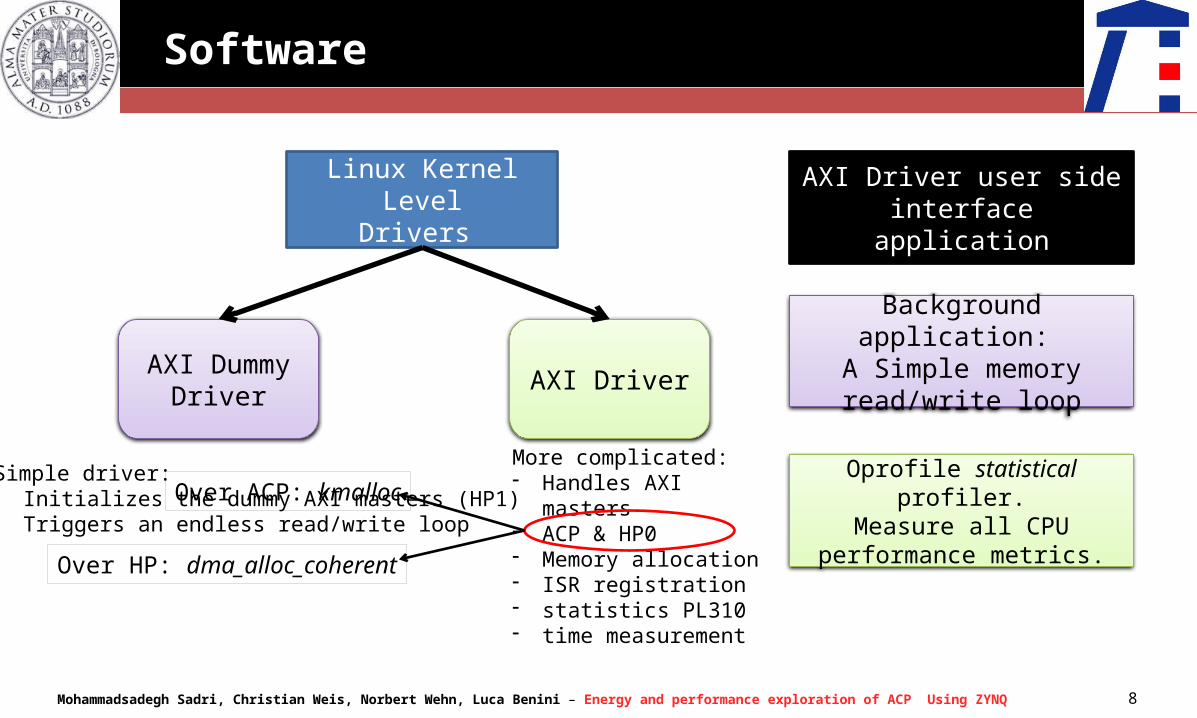
Software
Linux Kernel LevelDrivers
AXI DummyDriver
AXI Driver
Simple driver:- Initializes the dummy AXI masters (HP1)- Triggers an endless read/write loop
More complicated:- Handles AXI masters - ACP & HP0- Memory allocation- ISR registration- statistics PL310- time measurement
Over ACP: kmalloc
Over HP: dma_alloc_coherent
AXI Driver user side interface application
Background application: A Simple memory
read/write loop
Oprofile statistical profiler.Measure all CPU performance
metrics.
Mohammadsadegh Sadri, Christian Weis, Norbert Wehn, Luca Benini – Energy and performance exploration of ACP Using ZYNQ 9
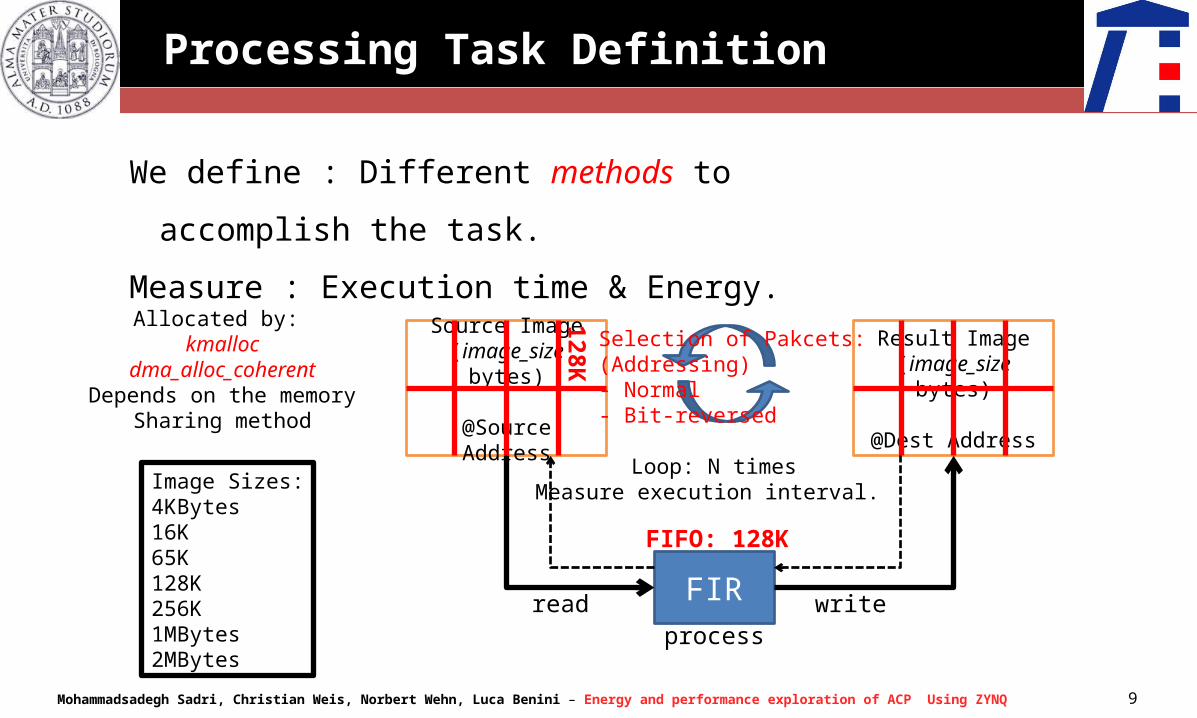
Source Image(image_size bytes)
@Source Address
FIR
Result Image(image_size bytes)
@Dest Address
readprocess
write
Loop: N timesMeasure execution interval.
FIFO: 128K
128K
Selection of Pakcets:(Addressing)- Normal- Bit-reversed
Allocated by: kmalloc
dma_alloc_coherentDepends on the memory
Sharing method
Image Sizes:4KBytes16K65K128K256K1MBytes2MBytes
We define : Different methods to accomplish the task.
Measure : Execution time & Energy.
Processing Task Definition
Mohammadsadegh Sadri, Christian Weis, Norbert Wehn, Luca Benini – Energy and performance exploration of ACP Using ZYNQ 10
Memory Sharing Methods
Accelerator ACP SCU L2 DRAM
• ACP Only (HP only is similar, there is no SCU and L2)
• CPU only (with&without cache)
• CPU ACP(CPU HP similar)
Accelerator ACP SCU L2 DRAM
CPU
12
ACP --- CPU --- ACP ---
Mohammadsadegh Sadri, Christian Weis, Norbert Wehn, Luca Benini – Energy and performance exploration of ACP Using ZYNQ 11
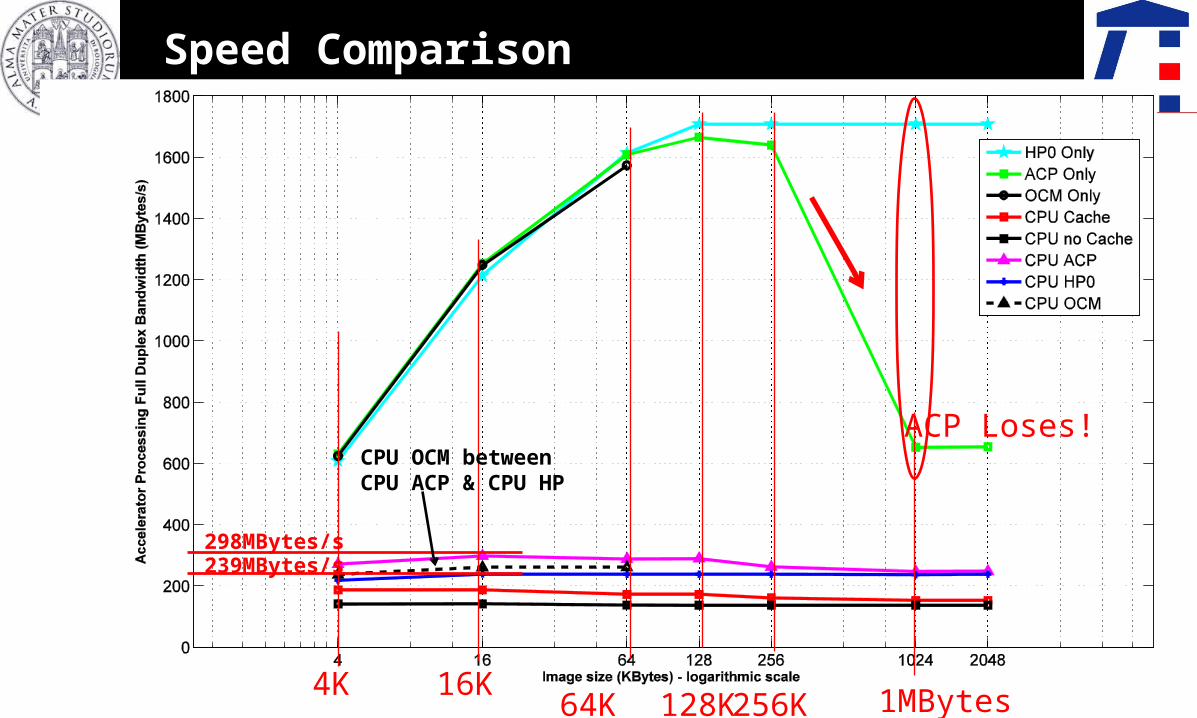
Speed Comparison
256K 1MBytes128K64K16K4K
ACP Loses!
298MBytes/s239MBytes/s
CPU OCM between CPU ACP & CPU HP
Mohammadsadegh Sadri, Christian Weis, Norbert Wehn, Luca Benini – Energy and performance exploration of ACP Using ZYNQ 12
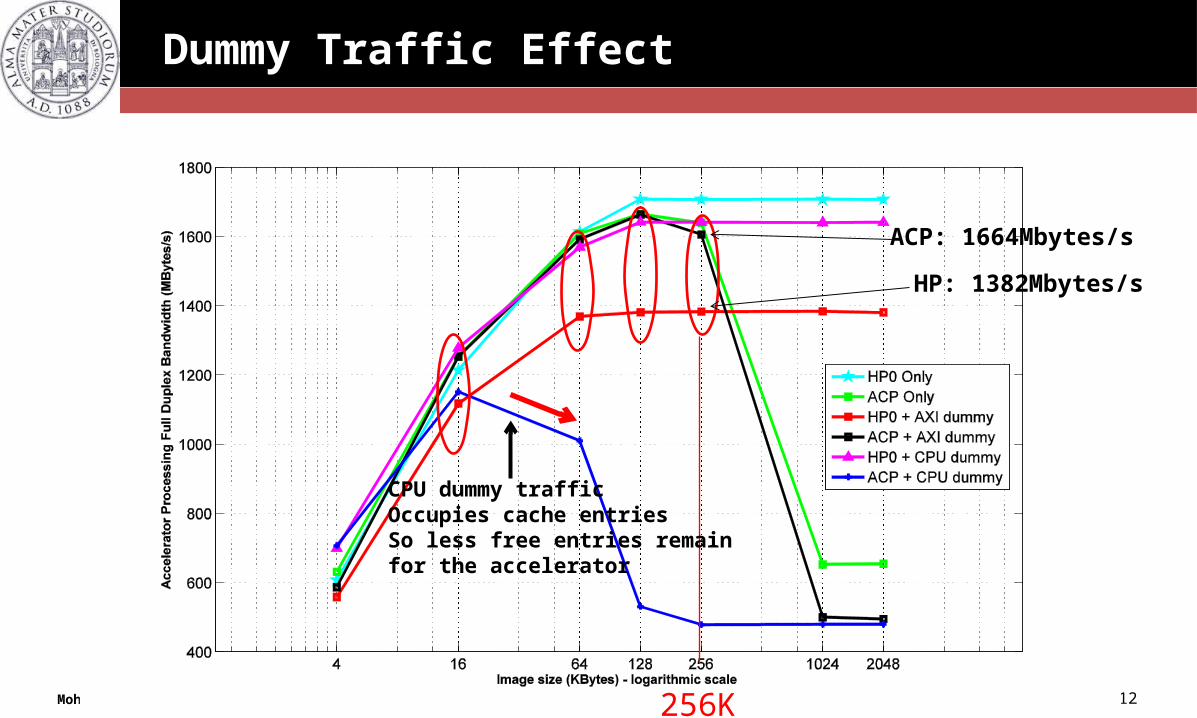
Dummy Traffic Effect
256K
HP: 1382Mbytes/s
ACP: 1664Mbytes/s
CPU dummy trafficOccupies cache entriesSo less free entries remain for the accelerator
Mohammadsadegh Sadri, Christian Weis, Norbert Wehn, Luca Benini – Energy and performance exploration of ACP Using ZYNQ 13
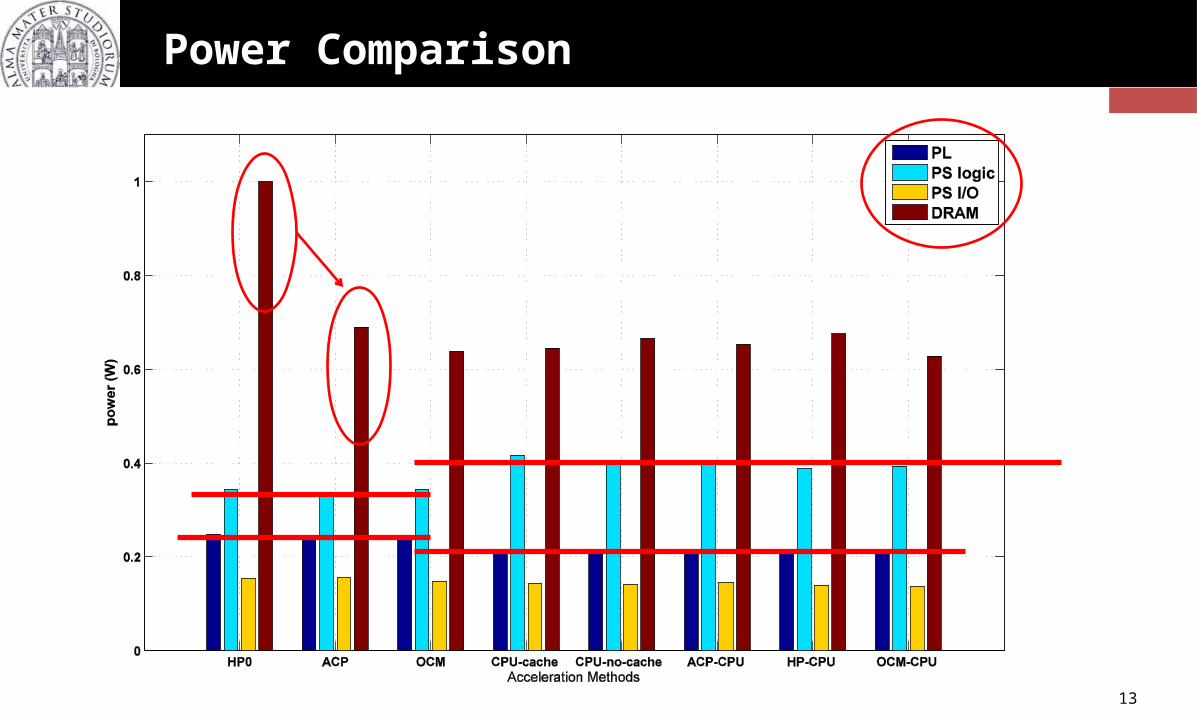
Power Comparison
Mohammadsadegh Sadri, Christian Weis, Norbert Wehn, Luca Benini – Energy and performance exploration of ACP Using ZYNQ 14
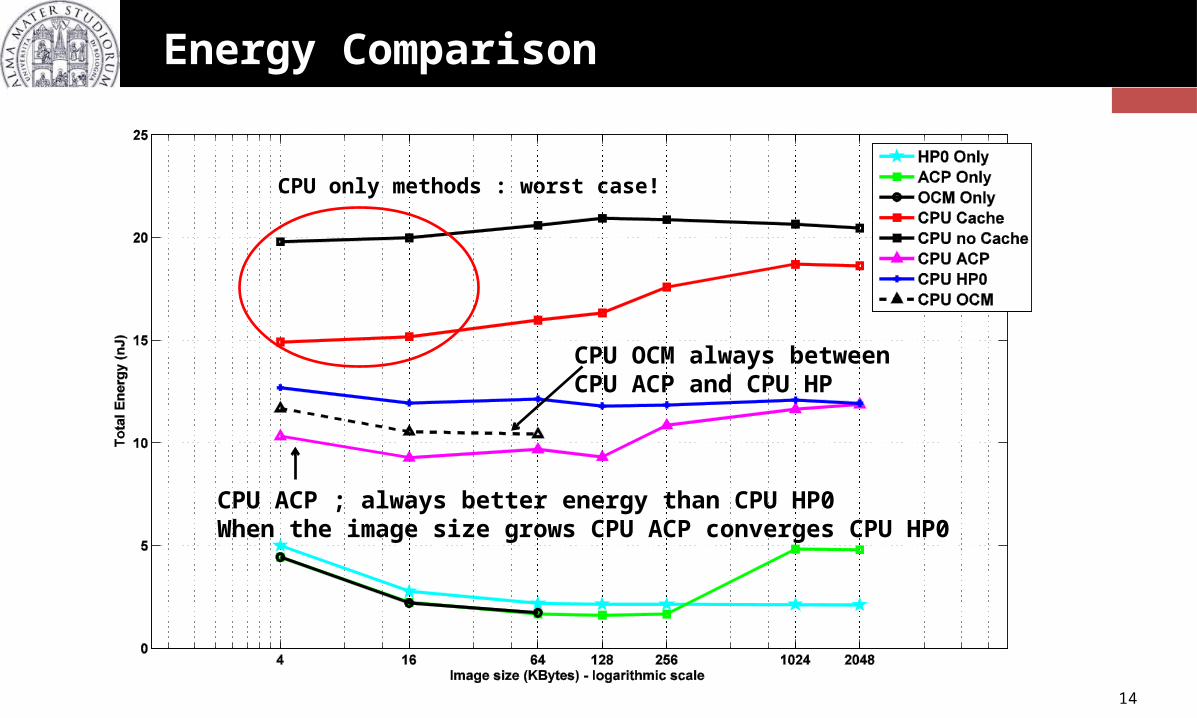
Energy Comparison
CPU only methods : worst case!
CPU ACP ; always better energy than CPU HP0When the image size grows CPU ACP converges CPU HP0
CPU OCM always between CPU ACP and CPU HP

Mohammadsadegh Sadri, Christian Weis, Norbert Wehn, Luca Benini – Energy and performance exploration of ACP Using ZYNQ 15
Lessons Learned & Conclusion
• If a specific task should be done by the cooperation ofCPU and accelerator:
• CPU ACP and CPU OCM are always better than CPU HP in terms of energy• If we are running other applications whichheavily depend on caches, CPU OCM and then CPU HP are preferred!
• If a specific task should be done by accelerator only:• For small arrays ACP Only & OCM Only can be used• For large arrays (>size of L2$) HP Only always acts better.





























