Embed Size (px)
Citation preview

www.movidius.com © Copyright Movidius 2016
EMBEDDED DEEP NEURAL NETWORKS
“The Cost of Everything and the Value of Nothing”
David Moloney, CTO
Hot Chips 28, Cupertino, California August 23, 2016

www.movidius.com © Copyright Movidius 2016
2 AGENDA
DEEP LEARNING: THE GREAT DISRUPTOR
TRAINING VS INFERENCE: INFERENCE MATTERS IN EMBEDDED
THE DEEPER THE BETTER?
BENEFITS OF EMBEDDED PROCESSING AT NETWORK EDGE
MAXIMISING PERFORMANCE OF NETWORKS ON MYRIAD 2 MA2x50
OPTIMISING CNNs ON VECTOR PROCESSORS FOR MOBILE PLATFORMS
CONCLUSIONS

www.movidius.com © Copyright Movidius 2016
3 DEEP LEARNING: THE GREAT DISRUPTOR
„Tesla Zooms Past BMW, Audi Limos In Europe, Closes In On Mercedes“
www.forbes.com, Oct 19th 2015

www.movidius.com © Copyright Movidius 2016
4 AGENDA
DEEP LEARNING: THE GREAT DISRUPTOR
TRAINING VS INFERENCE: INFERENCE MATTERS IN EMBEDDED
THE DEEPER THE BETTER?
BENEFITS OF EMBEDDED PROCESSING AT NETWORK EDGE
MAXIMISING PERFORMANCE OF NETWORKS ON MYRIAD 2 MA2x50
OPTIMISING CNNs ON VECTOR PROCESSORS FOR MOBILE PLATFORMS
CONCLUSIONS

www.movidius.com © Copyright Movidius 2016
5 DEEP CONVOLUTIONAL NEURAL NETWORKS (CNNs) Inference Matters in Embedded
Layer 1 Layer 2 Layer 3 Layer 4 Layer N Output
Inference
Input
Weights
Repeated for N layers in Network
Error
Backpropagation
Convolution
Activation
(pointwise
ReLU)
Max-Pooling
(blockwise
maximum)
+
Training
Expected
Output
(label)
Weights from
DDR/RAM
Inputs
Previous layer
or DDR/RAM
Inputs to
next layer

www.movidius.com © Copyright Movidius 2016
6 AGENDA
DEEP LEARNING: THE GREAT DISRUPTOR
TRAINING VS INFERENCE: INFERENCE MATTERS IN EMBEDDED
THE DEEPER THE BETTER?
BENEFITS OF EMBEDDED PROCESSING AT NETWORK EDGE
MAXIMISING PERFORMANCE OF NETWORKS ON MYRIAD 2 MA2x50
OPTIMISING CNNs ON VECTOR PROCESSORS FOR MOBILE PLATFORMS
CONCLUSIONS

www.movidius.com © Copyright Movidius 2016
7 THE DEEPER THE BETTER… Yet With Increased Complexity
2012 2013 2014 2015
Layers 8 16 58 158
Accuracy % 83.60% 88.80% 93.33% 95.06%
8 16
58
158
AlexNet
VGG16
GoogLeNet
ResNet
0
20
40
60
80
100
120
140
160
180
76.00%
78.00%
80.00%
82.00%
84.00%
86.00%
88.00%
90.00%
92.00%
94.00%
96.00%
Ac
cu
rac
y %
Year
ImageNet Accuracy % over Time

www.movidius.com © Copyright Movidius 2016
8 COMPLEXITY OF A STANDARD NETWORK GoogLeNet
Computational cost is increased by less than 2x compared to AlexNet (<1.5 Bn operations/ evaluation)
5M parameters
1 2 3 4 5 6 7 8 9
480 480 512 512 512 832 832 256 1024 Width Filters
9 Inception Layers
Convolution
Pooling
Softmax
Other

www.movidius.com © Copyright Movidius 2016
9 AGENDA
DEEP LEARNING: THE GREAT DISRUPTOR
TRAINING VS INFERENCE: INFERENCE MATTERS IN EMBEDDED
THE DEEPER THE BETTER?
BENEFITS OF EMBEDDED PROCESSING AT NETWORK EDGE
MAXIMISING PERFORMANCE OF NETWORKS ON MYRIAD 2 MA2x50
OPTIMISING CNNs ON VECTOR PROCESSORS FOR MOBILE PLATFORMS
CONCLUSIONS

www.movidius.com © Copyright Movidius 2016
10 EMBEDDED PROCESSING AT THE NETWORK EDGE Huge Benefits
Latency
Bandwidth
Energy
Improvement Due to Edge Processing 1,000,000 x
more energy-efficient
10,000 x
less bandwidth consumed
1,000 x
lower latency
Other Improvements in:
Privacy
Fault-tolerance/ Continuity of service

www.movidius.com © Copyright Movidius 2016
11 AGENDA
DEEP LEARNING: THE GREAT DISRUPTOR
TRAINING VS INFERENCE: INFERENCE MATTERS IN EMBEDDED
THE DEEPER THE BETTER?
BENEFITS OF EMBEDDED PROCESSING AT NETWORK EDGE
MAXIMISING PERFORMANCE OF NETWORKS ON MYRIAD 2 MA2x50
OPTIMISING CNNs ON VECTOR PROCESSORS FOR MOBILE PLATFORMS
CONCLUSIONS

www.movidius.com © Copyright Movidius 2016
12 MYRIAD 2 MA2x50 Vision Processing Unit (VPU) Architecture
DDR Controller
12
8
Bridge
RISC-
RTOS
L1
32/32kB
L2
256KB
ROM
128KB
Stacked KGD
1-8Gbit LP-DDR2/3
PLL &
CPM
RISC-RT
L1 4/4
kB
L2 32kB
AMC Crossbar
32x
HW
Mutex
Inter-SHAVE Interconnect (ISI)
CMX Memory Fabric Multi-Ported RAM Subsystem
RAW Shading
Correction DEBAYER
LUMA
DNF
CHROMA
GEN & DNF
Sharpening EDGE HARRIS CONV 5x5 MEDIAN
LUT 3-D LUT
LTM
Color Comb. Poly-phase
Scaling x3 MIPI TX Filter MIPI RX Filter
BAYER
De-noise
>20 independent power islands
Software Controlled I/O Multiplexing
MIPI
D-PHY x12 lanes SD USB3
Eth
1 Gb
SPI
x3
I2C
x3
UART
x2
I2S
x3 LCD CIF NAL
L2 cache 256KB
Arbiter & 16:1 mux
SH
AV
E 0
SH
AV
E 1
SH
AV
E 3
SH
AV
E 2
SH
AV
E 4
SH
AV
E 5
SH
AV
E 6
SH
AV
E 7
SH
AV
E 8
SH
AV
E 9
SH
AV
E 1
0
SH
AV
E 1
1
Ma
in B
us

www.movidius.com © Copyright Movidius 2016
13 SHAVE PROCESSING Maximising GEMM Performance
VRF 32x128-bit (12 ports)
IRF 32x32-bit (17 ports)
PEU Predication
BRU BranchUnit
LSU0 Load-Store
LSU1 Load-Store
IAU IntegerUnit
SAU ScalarUnit
VAU VectorUnit
2 KB
I-cache CMU
CompareU
DCU Debug
IDC Instr
Decode
1 KB
D-cache
SHAVE Processor v3.0
32 128 64 64 128 128 Computes 2 rows of A*B = 2 rows of C
16 lines of SHAVE VLIW Assembler
8-bit MACs in VAU & 32b Partials
Summation A0n*B0n n{0-7} in SAU 32-bit Accumulation
in IAU
Load/Store Port 0 Load/Store Port 1
Zero Overhead
Looping
SAU 32-bit PP
Summation
IAU 32-bit
Accumulation
32 ops/cycle 15 ops/cycle 1 ops/cycle
48 ops/cycle @ 600MHz on 12 SHAVEs
345.6GOPS
VAU 16x8-bit MACs

www.movidius.com © Copyright Movidius 2016
14 GoogLeNet RELATIVE GFLOPS/W Performance Results
GoogLeNet Single Inference (Batch = 1) no Heatsink or Fan
Myriad 2 28 25 1.2 85.61
GPU-B 20 22 7.5 75.34 10.04
28 15 7.5 51.37 6.85 GPU-A
71.34
nm Process GFLOPS/W GFLOPS fps Power (W)

www.movidius.com © Copyright Movidius 2016
15 AGENDA
DEEP LEARNING: THE GREAT DISRUPTOR
TRAINING VS INFERENCE: INFERENCE MATTERS IN EMBEDDED
THE DEEPER THE BETTER?
BENEFITS OF EMBEDDED PROCESSING AT NETWORK EDGE
MAXIMISING PERFORMANCE OF NETWORKS ON MYRIAD 2 MA2x50
OPTIMISING CNNs ON VECTOR PROCESSORS FOR MOBILE PLATFORMS
CONCLUSIONS
www.movidius.com © Copyright Movidius 2016
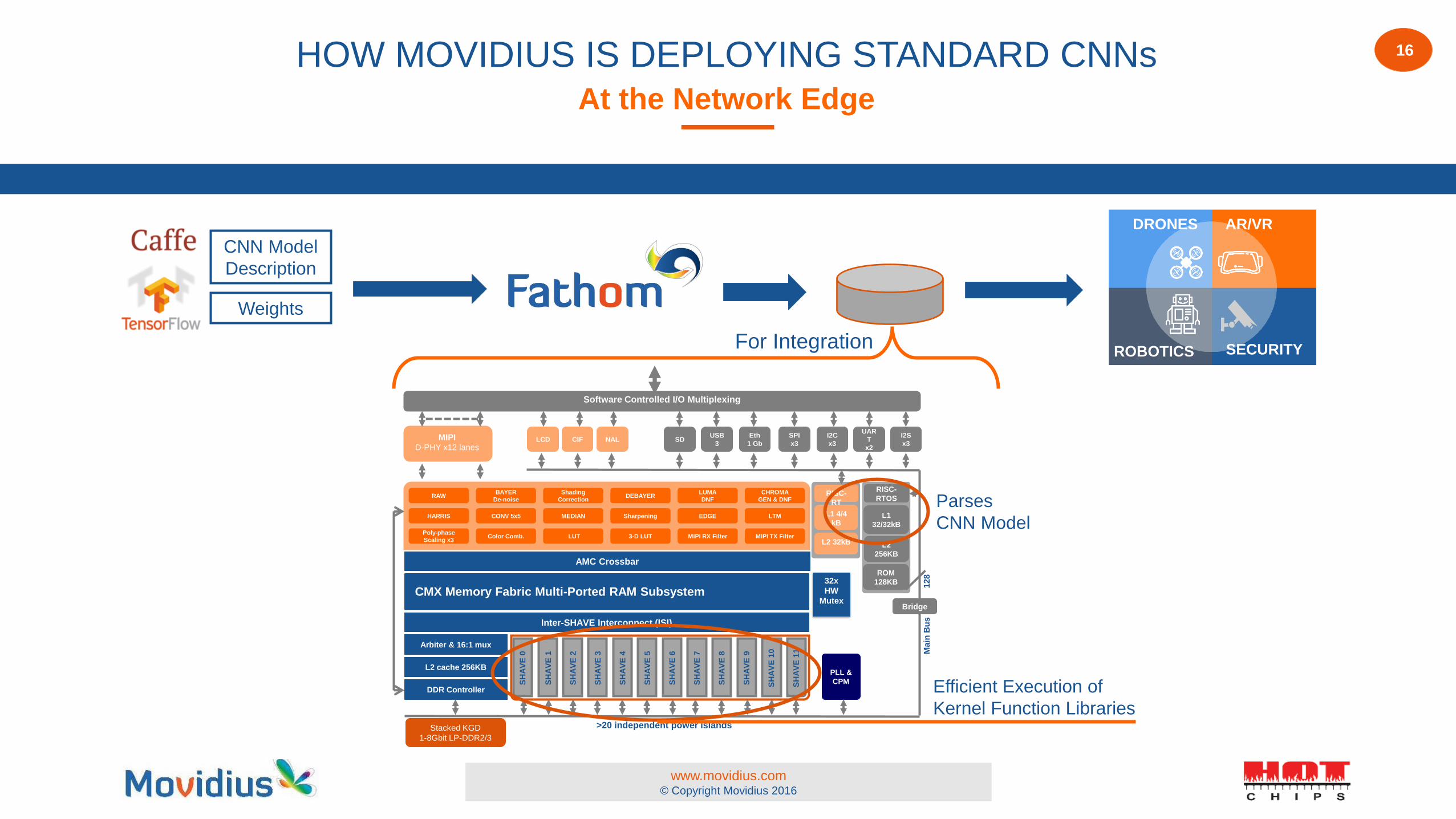
16 HOW MOVIDIUS IS DEPLOYING STANDARD CNNs At the Network Edge
DDR Controller
128
Bridge
RISC-
RTOS
L1
32/32kB
L2
256KB
ROM
128KB
Stacked KGD
1-8Gbit LP-DDR2/3
PLL &
CPM
RISC-
RT
L1 4/4
kB
L2 32kB
AMC Crossbar
32x
HW
Mutex
Inter-SHAVE Interconnect (ISI)
CMX Memory Fabric Multi-Ported RAM Subsystem
RAW Shading
Correction DEBAYER
LUMA
DNF
CHROMA
GEN & DNF
Sharpening EDGE HARRIS CONV 5x5 MEDIAN
LUT 3-D LUT
LTM
Color Comb. Poly-phase
Scaling x3 MIPI TX Filter MIPI RX Filter
BAYER
De-noise
>20 independent power islands
Software Controlled I/O Multiplexing
MIPI
D-PHY x12 lanes SD
USB
3
Eth
1 Gb
SPI
x3
I2C
x3
UAR
T
x2
I2S
x3 LCD CIF NAL
L2 cache 256KB
Arbiter & 16:1 mux
SH
AV
E 0
SH
AV
E 1
SH
AV
E 3
SH
AV
E 2
SH
AV
E 4
SH
AV
E 5
SH
AV
E 6
SH
AV
E 7
SH
AV
E 8
SH
AV
E 9
SH
AV
E 1
0
SH
AV
E 1
1
DRONES
ROBOTICS
AR/VR
SECURITY
CNN Model
Description
Weights
Parses
CNN Model
Efficient Execution of
Kernel Function Libraries
For Integration
Ma
in B
us

www.movidius.com © Copyright Movidius 2016
17 AGENDA
DEEP LEARNING: THE GREAT DISRUPTOR
TRAINING VS INFERENCE: INFERENCE MATTERS IN EMBEDDED
THE DEEPER THE BETTER?
BENEFITS OF EMBEDDED PROCESSING AT NETWORK EDGE
MAXIMISING PERFORMANCE OF NETWORKS ON MYRIAD 2 MA2x50
OPTIMISING CNNs ON VECTOR PROCESSORS FOR MOBILE PLATFORMS
CONCLUSIONS

www.movidius.com © Copyright Movidius 2016
18
1,7
IS IT WORTH IT? Incremental Accuracy and the Power Efficiency Cost
1.59 1.13 0
15.66
8.81
4.69
41.43
24.54
10.26
1.97 1.61 1.43 1.10
15.86
11.13 9.69
6.60
83.00%
92.00% 93.33%
83.00%
0.00%
10.00%
20.00%
30.00%
40.00%
50.00%
60.00%
70.00%
80.00%
90.00%
100.00%
0.00
5.00
10.00
15.00
20.00
25.00
30.00
35.00
40.00
45.00
AlexNet (2012) VGG-16 (2013) GoogLeNet (2014) SqueezeNet (2016)
% A
cc
ura
cy
Po
wer
Eff
icie
nc
y (
GF
LO
PS
/W)
Network, Year Developed
XU4 TK1 TX1 x86 K40 Accuracy %
mobile server
Notes: ImageNet, Batch = 10/64, using active cooling

www.movidius.com © Copyright Movidius 2016
19
• Deep Learning for Embedded is all about Inference
• Standard Networks are designed to achieve high-accuracy
• Embedded implementation on architectures such as Movidius VPU can achieve significant performance results at the network edge
• Next challenge is to further optimise networks to maximise performance per Watt
SUMMARY
The research leading to these results has received funding from the
European Union Seventh Framework Programme (FP7/2007-2013) under
grant agreement n°611183 (EXCESS Project, www.excess-project.eu).
Achievements and Future Challenges

www.movidius.com © Copyright Movidius 2016
THANK YOU
FOR YOUR ATTENTION





























