Embed Size (px)
Citation preview

Efficient VLSI architectures for baseband signal processing in wireless base-station
receivers
Sridhar Rajagopal, Srikrishna Bhashyam,
Joseph R. Cavallaro, and Behnaam Aazhang
This work is supported by Nokia, TI, TATP and NSF

Introduction
A real-time VLSI architecture for channel estimation
Usually neglected, but high computational complexity
Current DSP solutions do not meet real-time
Iterative fixed point algorithm developed
Area-Time Tradeoffs discussed
– Area-Constrained (Pico-cells)
– Time-Constrained (Theoretical Data Rates)
– Area-Time efficient (Real-Time Solution)

Outline
What is multiuser channel estimation?
Need for multiuser channel estimation
Implementation problems
Algorithm enhancements
VLSI architectures
– Area-constrained,Time-constrained, Area-Time efficient
Comparisons with DSP solutions
Related Work and Conclusions
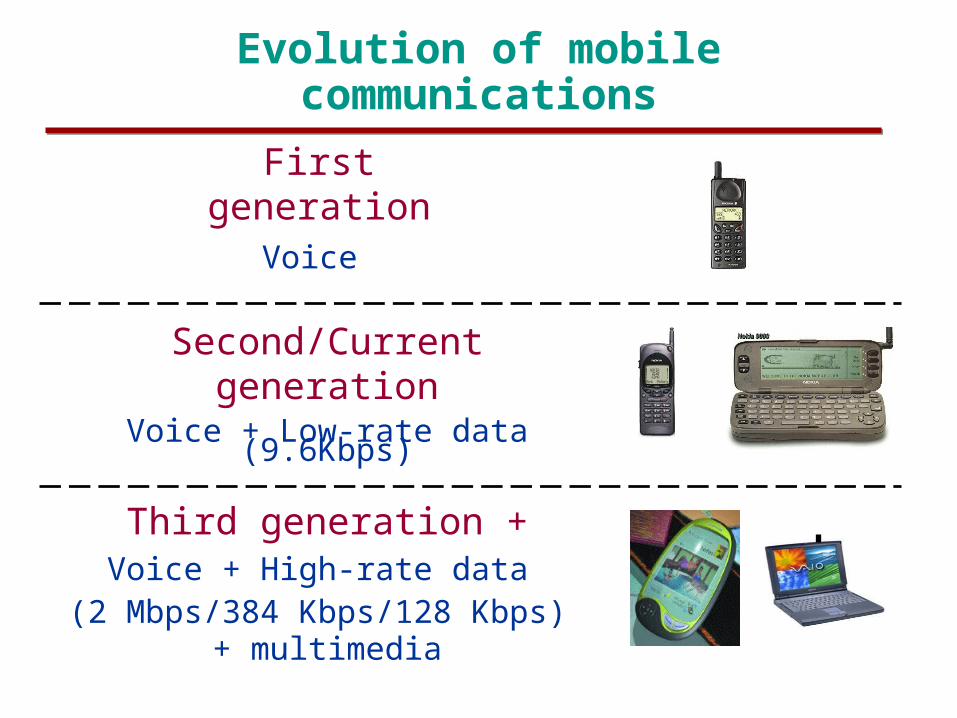
Evolution of mobile communications
First generationVoice
Second/Current generationVoice + Low-rate data
(9.6Kbps)
Third generation +Voice + High-rate data
(2 Mbps/384 Kbps/128 Kbps) + multimedia
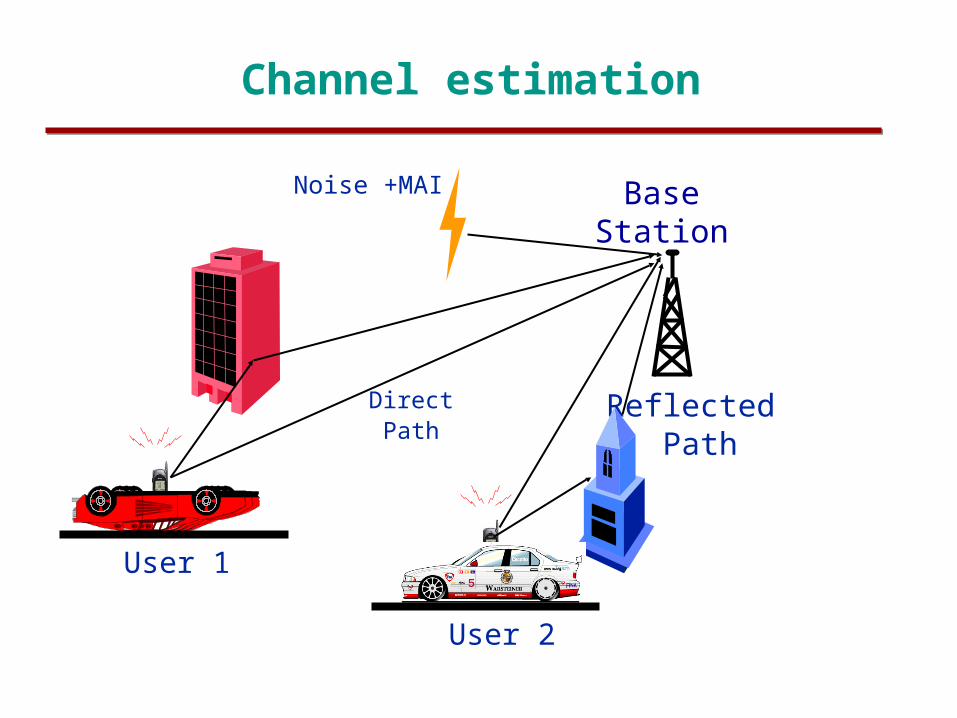
Channel estimation
Direct Path
Reflected Path
Noise +MAI
User 1
User 2
Base Station

Need for channel estimation
To compensate for unknown fading amplitudes and
asynchronous delays.
Detector performance depends on accuracy of channel
estimator

Computing channel estimates
Computed by sending a training sequence of known
bits to the receiver.
When absent, detected bits can be used to update
estimates in a decision feedback mode for tracking.
Importance usually neglected
May exceed detector complexity
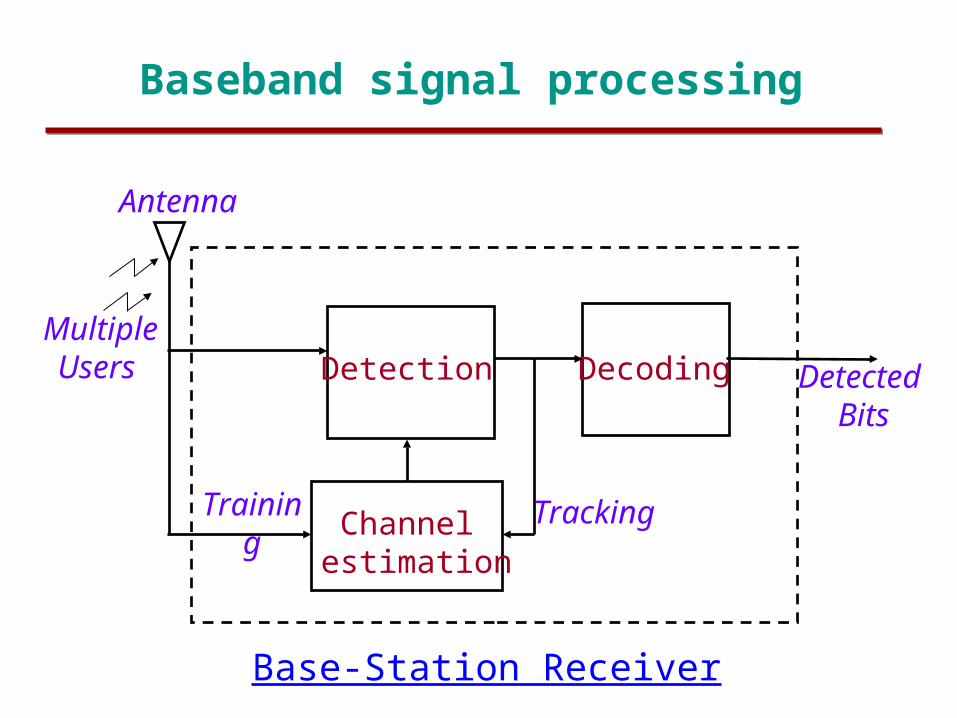
Baseband signal processing
Base-Station Receiver
Channel estimation
Detection DecodingMultiple Users
Antenna
Detected Bits
TrackingTraining

Implementation complexity
Matrix inversions (size 32x32) per windowUnable to meet real-time on DSPs [Asilomar’99]VLSI fixed-point architectures for matrix inversions
– Precision problems
Typically, simpler single-user sliding correlator structures used.
rbRH
iibr
bbRT
iibb
RAR bribb *

Outline
What is multiuser channel estimation?
Need for multiuser channel estimation
Implementation problems
Algorithm enhancements
VLSI architectures
– Area-constrained,Time-constrained, Area-Time efficient
Comparisons with DSP solutions
Related Work and Conclusions

Iterative scheme for channel estimation
Method of Gradient DescentStable convergence behaviorSame PerformanceSimpler Bit-Streaming Hardware Implementation
TTLLbbbb bbbbRR 00 **
HHLLbrbr rbrbRR 00 **
)*( brbb RRAAA rbR
H
iibr
bbRT
iibb
RAR bribb *
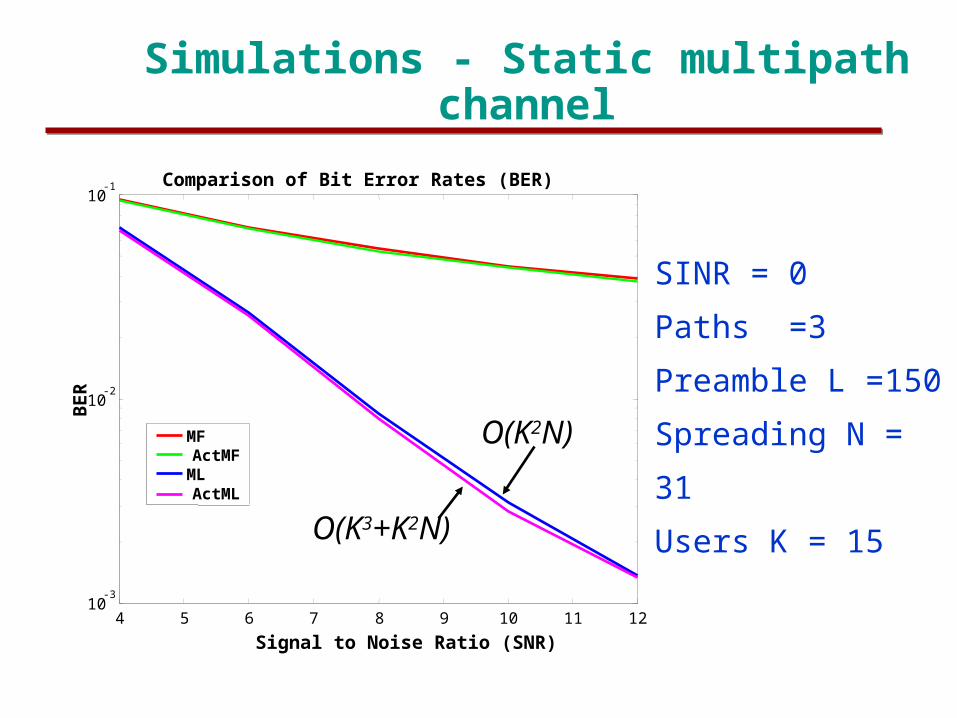
4 5 6 7 8 9 10 11 1210
-3
10-2
10-1 Comparison of Bit Error Rates (BER)
Signal to Noise Ratio (SNR)
BER
MF ActMFML ActML
O(K2N)
O(K3+K2N)
Simulations - Static multipath channel
SINR = 0
Paths =3
Preamble L =150
Spreading N = 31
Users K = 15
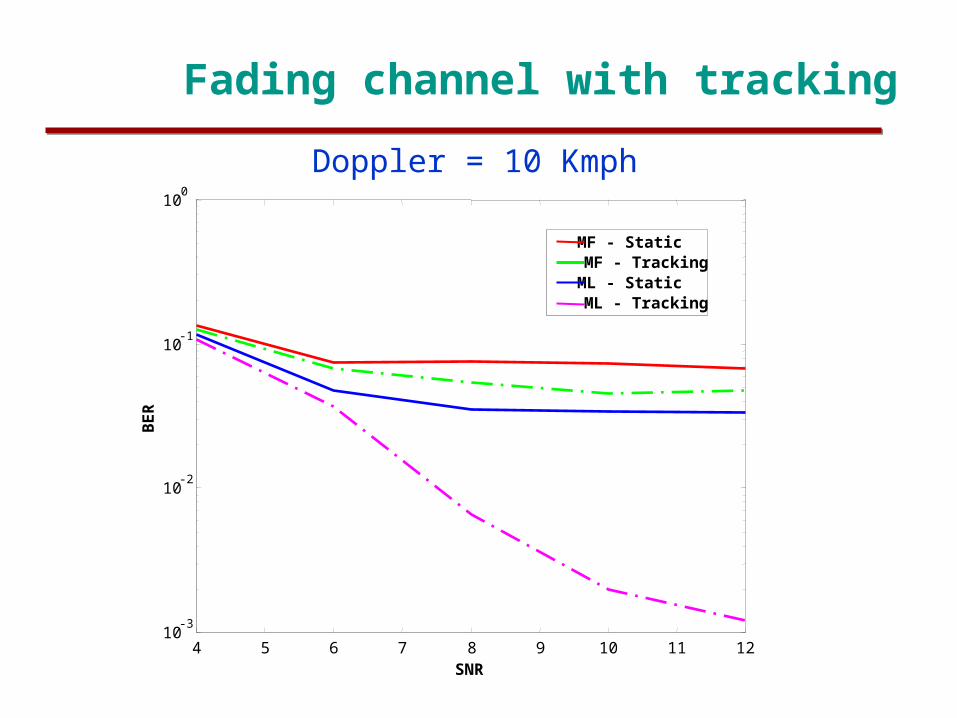
Fading channel with tracking
4 5 6 7 8 9 10 11 1210
-3
10-2
10-1
100
SNR
BE
R
MF - Static MF - TrackingML - Static ML - Tracking
Doppler = 10 Kmph

Outline
What is multiuser channel estimation?
Need for multiuser channel estimation
Implementation problems
Algorithm enhancements
VLSI architectures
– Area-constrained,Time-constrained, Area-Time efficient
Comparisons with DSP solutions
Related Work and Conclusions

Area-Time Tradeoffs
Design for 32 users (K) and spreading code (N) 32
Target Data Rate = 128 Kbps
Low Power Issues ignored!
Area-Constrained Architecture
– Pico-cells ; lower data rates
Time-Constrained Architecture
– Maximum achieve-able data rates
Area-Time Efficient Architecture
– Real-Time with minimum area overhead
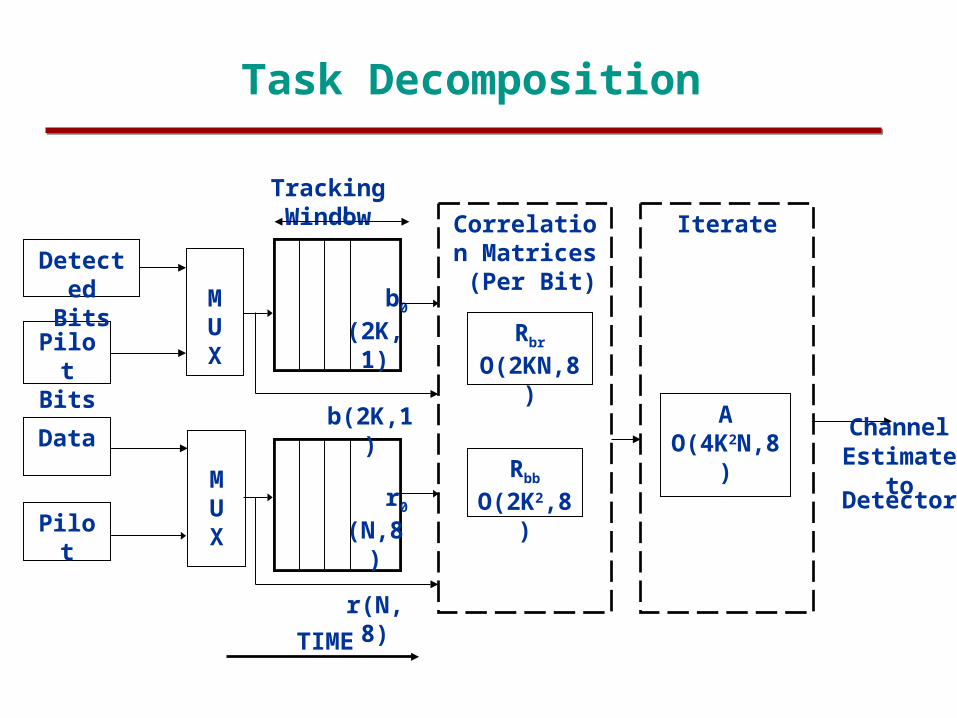
Task Decomposition
IterateCorrelation Matrices (Per Bit)
Pilot Bits
Pilot
MUX
Detected Bits
Data
MUX
AO(4K2N,8)
Rbr
O(2KN,8)
Rbb
O(2K2,8)
TIME
ChannelEstimate
to Detector
b0
(2K,1)
Tracking Window
r0
(N,8)
b(2K,1)
r(N,8)
L

TTLLbbbb bbbbRR 00 **
Architecture Design: Auto-correlation
b = {+1,-1}
Multiplication is a XNOR operation
Entire matrix can be updated sequentially or in
parallel using XNOR gates
Auto-correlation matrix implemented as an
UP/DOWN counter(s)

Architecture Design: Cross-Correlation
HHLLbrbr rbrbRR 00 **
b = {+1,-1}, r = 8-bit integer vector (complex)
Multiplications reduce to additions/subtractions
Entire matrix (complex) can be updated sequentially
or in parallel using 8-bit adders
Cross-correlation matrix stored as RAM.

Architecture Design: Channel Estimate
)*( brbb RRAAA
A = 8-bit integer matrix (complex) µ << 1 : Truncated Multiplication [Schulte’93]Matrix-matrix (real-complex) multiplication of
integersForms the bottleneckCan be done sequentially with a single multiplier or
totally parallel or partially parallelConcentrate on multiplication for area-time tradeoffs!
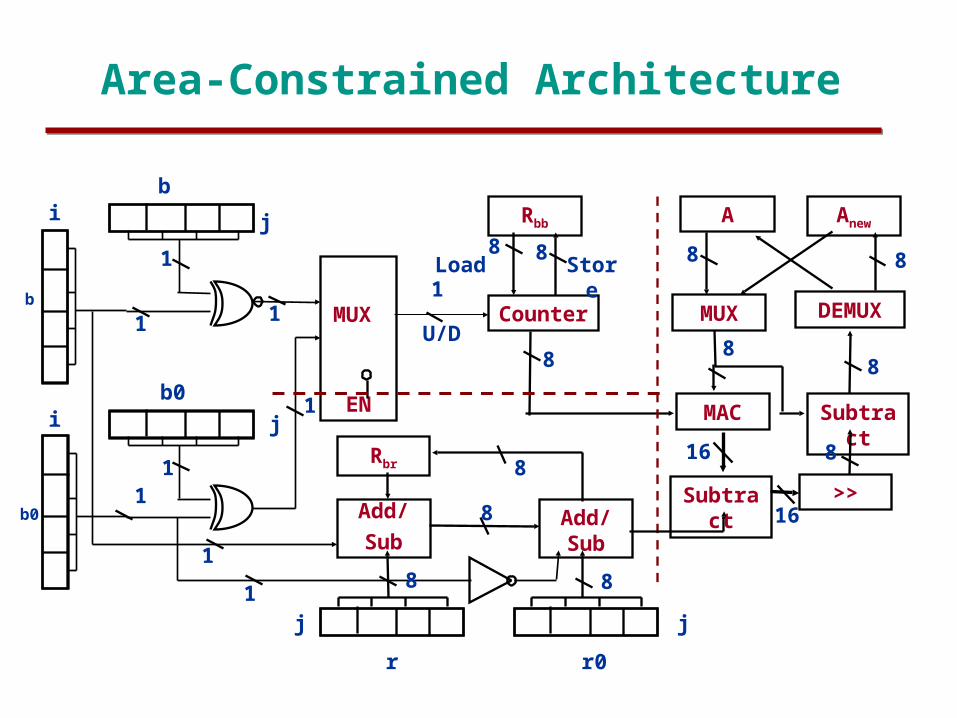
Area-Constrained Architecture
b0
bMUX
EN
Counter
Rbb A
DEMUXMUX
MAC
Add/
SubAdd/Sub
Subtract
Subtract
Anew
U/D
Load Store
ji
i j
j j
r0r
b
b0
16
8
8
88
8 8
1
11
1
1
1
1
1
1
88
88
Rbr
>>8
816
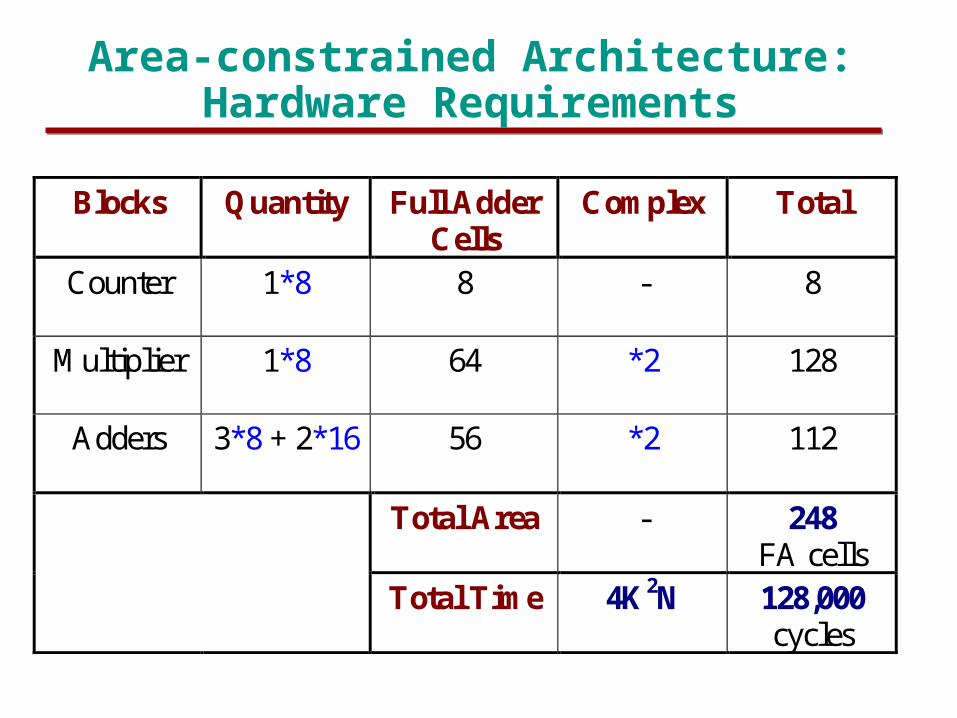
Area-constrained Architecture: Hardware Requirements
Blocks Quantity Full AdderCells
Complex Total
Counter 1*8 8 - 8
Multiplier 1*8 64 *2 128
Adders 3*8 + 2*16 56 *2 112
Total Area - 248FA cells
Total Time 4K2N 128,000cycles
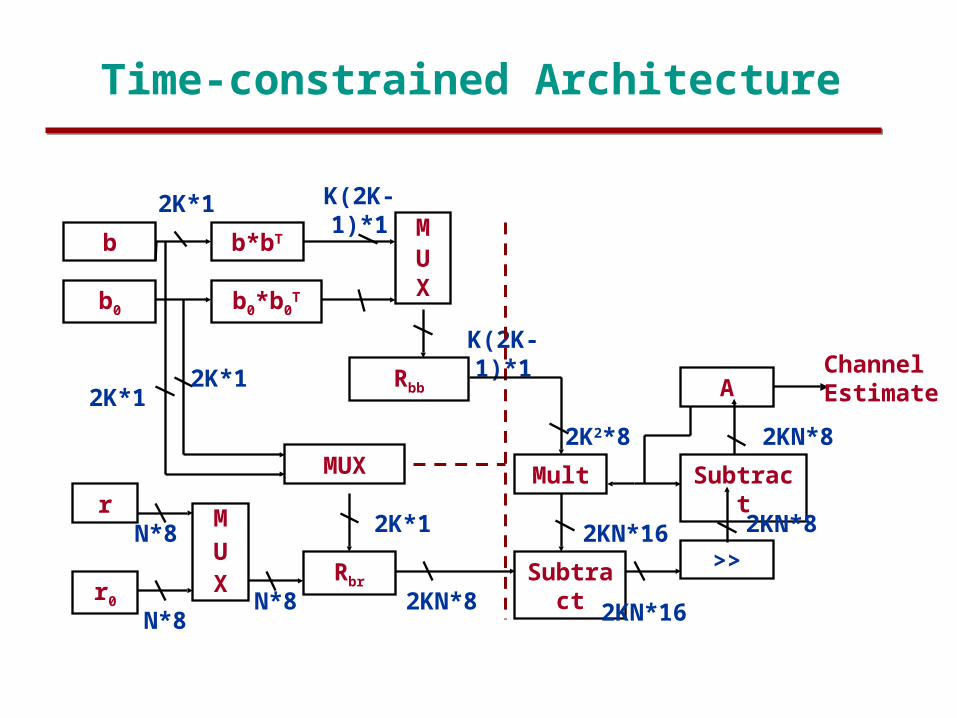
Time-constrained Architecture
b*bT
b0*b0T
b
b0
MUX
Rbr
M
UX
r
r0
MUX
Rbb A
Mult
Subtract >>
Subtract
2K*12K*1
2K*1 K(2K-1)*1
K(2K-1)*1
2K2*8
2KN*16
2KN*162KN*8
2K*1
N*8
N*8
N*8
2KN*8
2KN*8
ChannelEstimate

Auto-correlation Update in Parallel
Rbb(i,j)
Counter
bbT(i,j)
U/D#
Rbb(i,i)
Counter
1
U/D#
Array of XNORs
a·b a·c a·d
b·c b·d
c·d
b c da
b (2K)
bbT (K*{2K-1}*1) Rbb (2K2*8)
Array of Counters
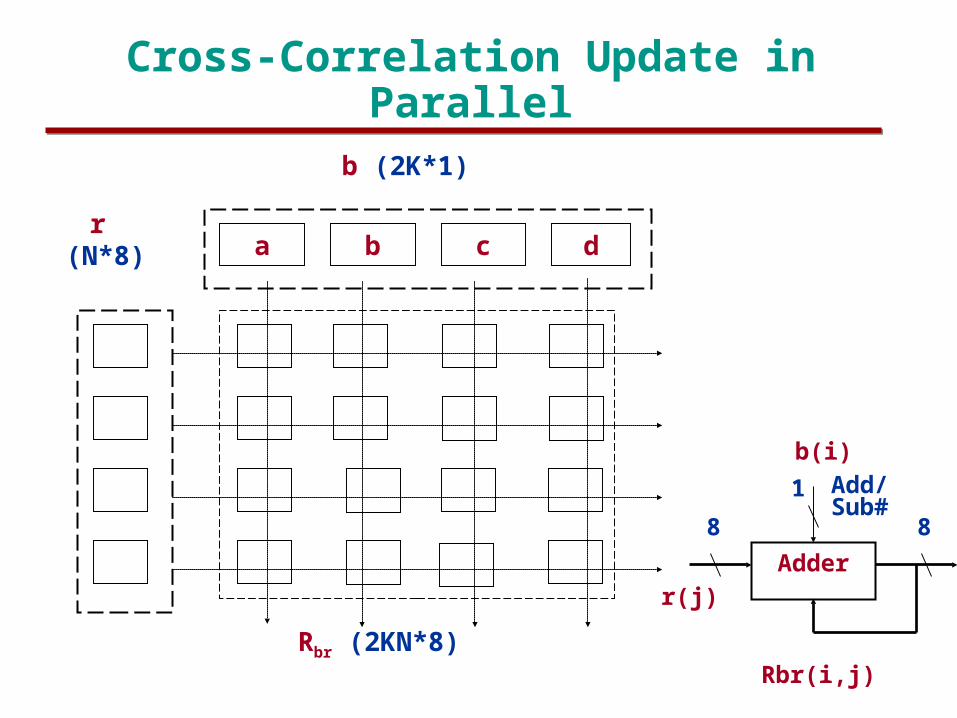
Cross-Correlation Update in Parallel
b c da
b (2K*1)
r (N*8)
Rbr (2KN*8)
r(j)
Rbr(i,j)
Adder
b(i)
Add/Sub#
8 8
1
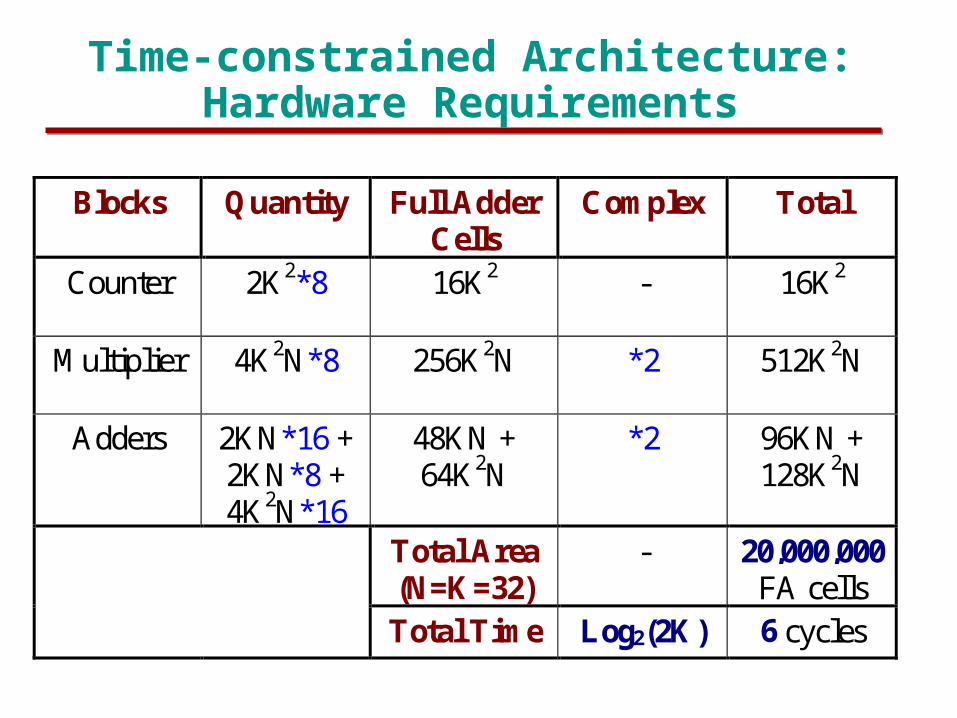
Time-constrained Architecture: Hardware Requirements
Blocks Quantity Full AdderCells
Complex Total
Counter 2K2*8 16K2 - 16K2
Multiplier 4K2N*8 256K2N *2 512K2N
Adders 2KN*16 +2KN*8 +4K2N*16
48KN +64K2N
*2 96KN +128K2N
Total Area(N=K=32)
- 20,000,000FA cells
Total Time Log2(2K) 6 cycles
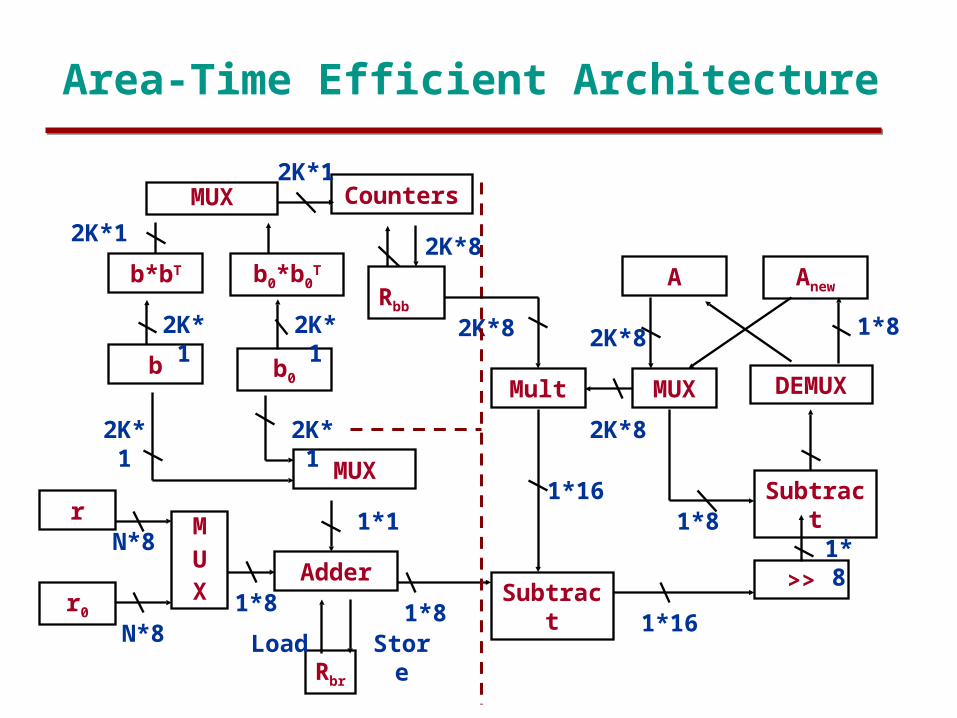
Area-Time Efficient Architecture
b*bT b0*b0T
b b0
MUX
M
UX
r
r0
MUX
Mult
Subtract >>
Subtract
2K*1 2K*1
2K*12K*1
2K*12K*8
2K*8
1*16
1*161*8
1*1
1*8
N*8
N*8
1*8
Rbr
Counters
StoreLoad
Rbb
A
DEMUXMUX
Anew
1*8
Adder
1*8
2K*1
2K*8
2K*8
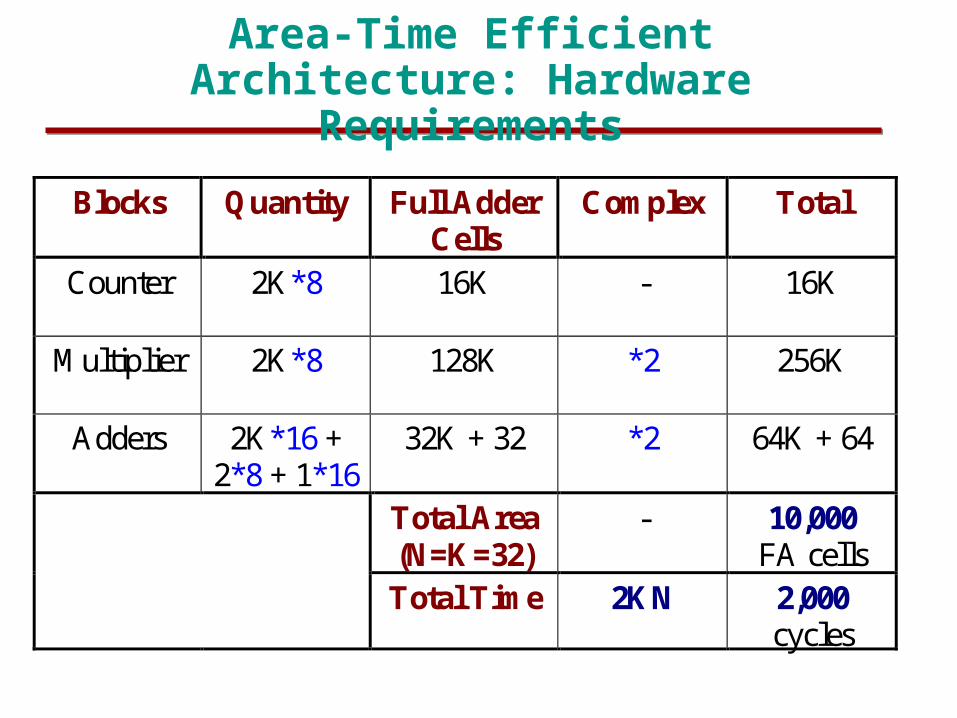
Area-Time Efficient Architecture: Hardware Requirements
Blocks Quantity Full AdderCells
Complex Total
Counter 2K*8 16K - 16K
Multiplier 2K*8 128K *2 256K
Adders 2K*16 +2*8 + 1*16
32K + 32 *2 64K + 64
Total Area(N=K=32)
- 10,000FA cells
Total Time 2KN 2,000cycles

Outline
What is multiuser channel estimation?
Need for multiuser channel estimation
Implementation problems
Algorithm enhancements
VLSI architectures
– Area-constrained,Time-constrained, Area-Time efficient
Comparisons with DSP solutions
Related Work and Conclusions
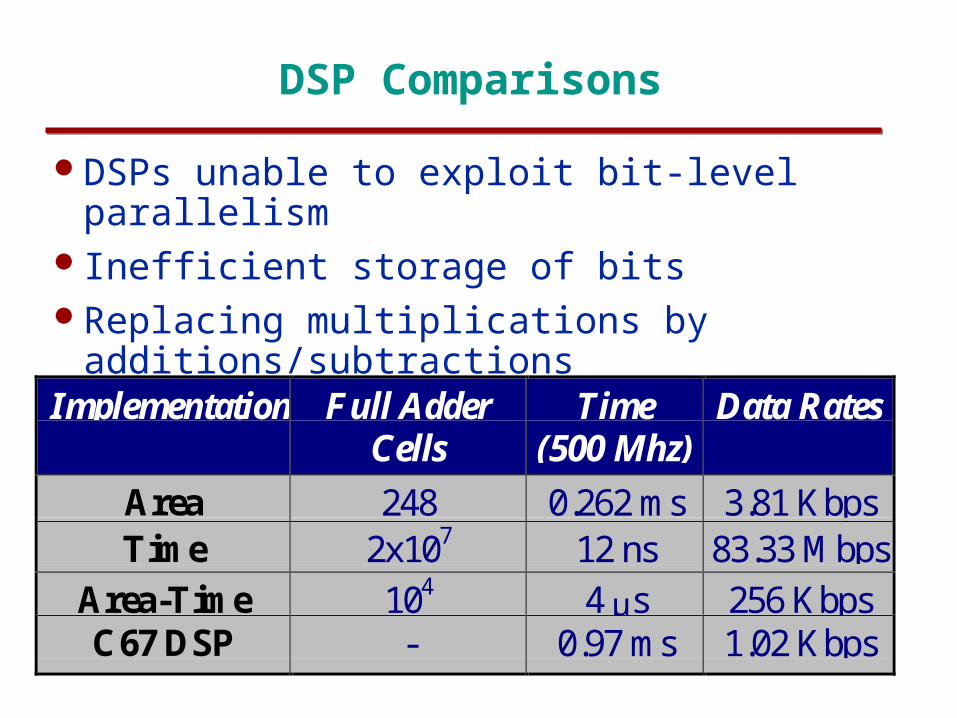
DSP Comparisons
Implementation Full AdderCells
Time(500 Mhz)
Data Rates
Area 248 0.262 ms 3.81 KbpsTime 2x107 12 ns 83.33 Mbps
Area-Time 104 4 µs 256 KbpsC67 DSP - 0.97 ms 1.02 Kbps
DSPs unable to exploit bit-level parallelismInefficient storage of bitsReplacing multiplications by additions/subtractions
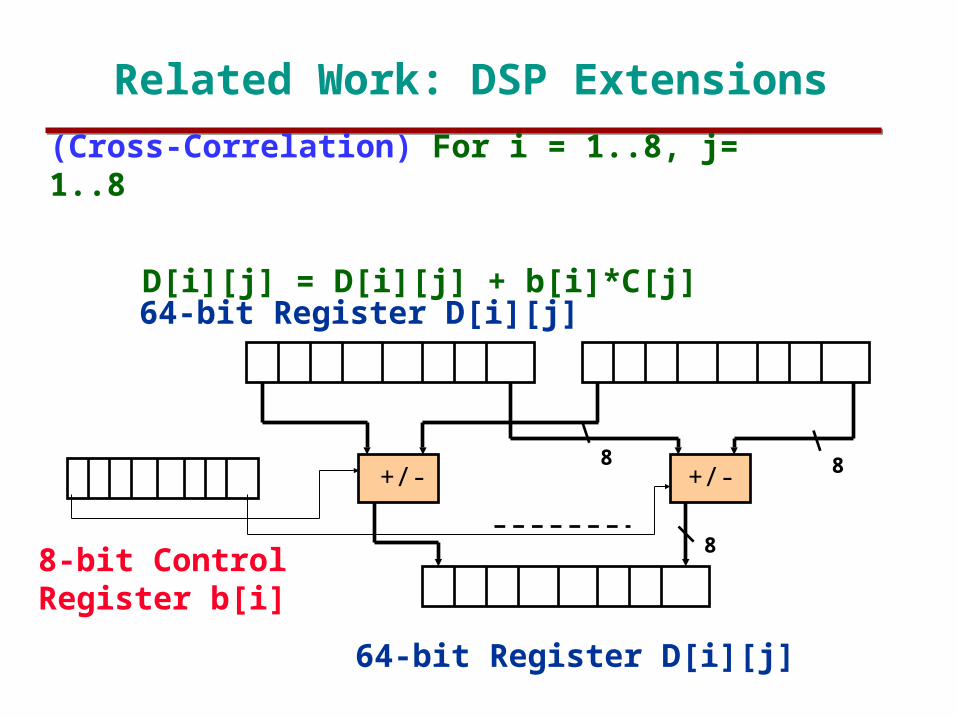
Related Work: DSP Extensions
64-bit Register D[i][j]
+/- +/-
64-bit Register D[i][j]
8-bit ControlRegister b[i]
88
8
(Cross-Correlation) For i = 1..8, j= 1..8
D[i][j] = D[i][j] + b[i]*C[j]

Related Work: Online Arithmetic
Multiuser Detection
– Need to compute only the Sign Bit (Most Significant Digit )
– No back-conversion to conventional representation
– complex-number representation possible
– Integration with channel estimation also.

Related Work : DSP-FPGA solutions
Multiple DSP-FPGA task partitioning
Bit level parallelism on FPGAs
Multiplications on DSPs.
Sundance Multi-DSP System
– 2 TI C67 DSPs
– 2 Xilinx Virtex FPGAs
– http://www.sundance.com

Conclusions
Real-Time VLSI architecture for multiuser channel estimation
Iterative fixed-point algorithm developed to avoid matrix inversions
Area-Time Tradeoffs discussed– Area-Constrained (Pico-cells)
– Time-Constrained (Data Rates)
– Area-Time efficient (Real-Time)
VLSI architectures better exploit bit-level computations and parallelism to meet real-time constraints than DSPs.





























