Embed Size (px)
Citation preview

Efficient Run-Time Dispatching in Generic Programming with
Minimal Code Bloat
Lubomir BourdevAdvanced Technology Labs
Adobe Systems
Jaakko JärviComputer Science Department
Texas A&M University

Agenda
• Context & problem statement
• Background – previous approaches
• Our approach to code bloat reduction
• Code bloat reduction in run-time dispatch
• Results & conclusion

Agenda
• Context & problem statement
• Background – previous approaches
• Our approach to code bloat reduction
• Code bloat reduction in run-time dispatch
• Results & conclusion

Context: Image Manipulation
• Images vary in many different ways
• Writing generic and efficient image processing algorithms is challenging
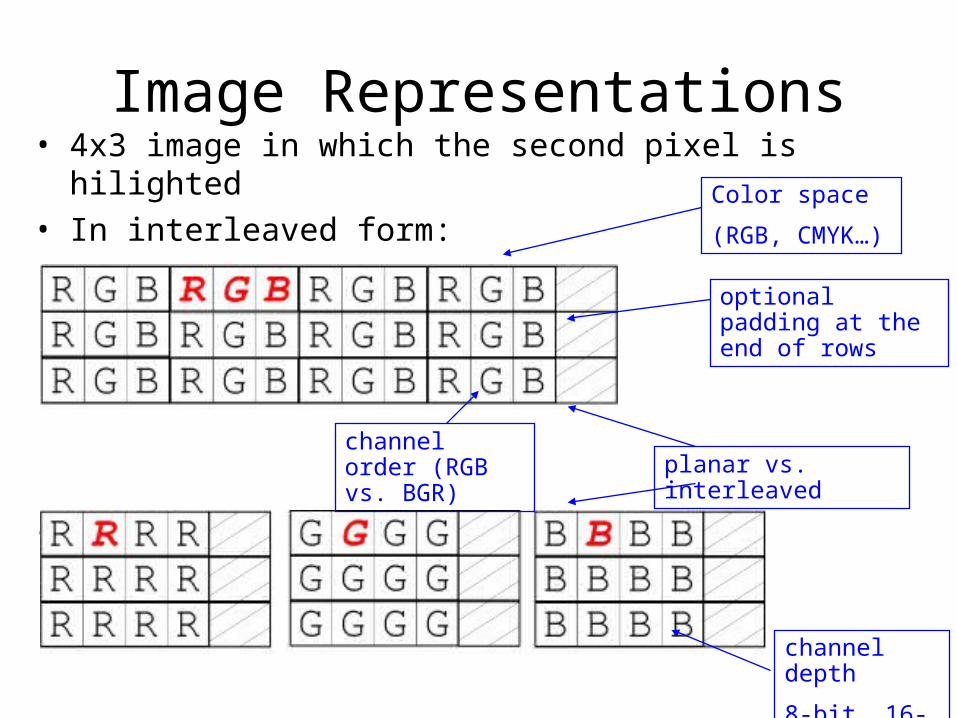
Image Representations• 4x3 image in which the second pixel is hilighted• In interleaved form:
• In planar form: planar vs. interleaved
channel depth
8-bit, 16-bit…
channel order (RGB vs. BGR)
Color space
(RGB, CMYK…)
optional padding at the end of rows

Generic Image Library (GIL)
• Adobe’s Open Source Image Libraryhttp://opensource.adobe.com/gil
• Abstracts image representations from algorithms on images
• Allows for writing the algorithm once & having it work on images of any representation, without loss of performance

Problem Statement
• How do we write image processing algorithms that are:– Generic– Efficient– Compact– Run-Time Flexible

Agenda
• Context & problem statement
• Background – previous approaches
• Our approach to code bloat reduction
• Code bloat reduction in run-time dispatch
• Results & conclusion

Image algorithms via inheritance & polymorphism
struct pixel { virtual void invert()=0; };
struct rgb_pixel : public pixel {
virtual void invert();
};
struct gray_pixel : public pixel {
virtual void invert();
};
struct image {
pixel* operator[](size_t i);
};
void invert(image* img) {
for (i=0; i<img.size(); ++i)
img[i]->invert();
}
Generic X
Efficient X
Compact √
Run-Time Flexible √
Performance problem:
dynamic dispatch once per pixel

Image Algorithms via Generic Programming
struct rgb_pixel {…};struct gray_pixel {…};void invert_pixel(rgb_pixel&) {…}void invert_pixel(gray_pixel&) {…}
template <typename Pixel>struct image { Pixel& operator[](size_t i);};
template <typename Image>void invert(Image& img) { for (i=0; i<img.size(); ++i) invert_pixel(img[i]);}
Generic √
Efficient √
Compact √
Run-Time Flexible X

Generic Code Lacks Flexibility
• We need run-time flexibility:
typedef boost::mpl::vector<rgb8_image, gray8_image> images;gil::any_image<images> runtime_image;
gil::jpeg_read_image(runtime_image, “test.jpg”);invert(runtime_image);
• How can we do that without loss of performance?– Variant construct (see boost::variant)– runtime_image holds:
• index: index to the type of image• bits: buffer containing the currently instantiated image
– To invoke an algorithm, go through a switch statement & cast– Efficient: invoke dynamic dispatch only once per algorithm

Variant invocation
void invert_image(void* bits, int index) {
switch (index) {
case kLAB: invert(*(image<lab_pixel>*)(bits));
case kRGB: invert(*(image<rgb_pixel>*)(bits));
}
}
Generic version:
template <typename Op>
void apply_operation(void* bits, int index, Op op) {
switch (index) {
case kLAB: op(*(image<lab_pixel>*)(bits));
case kRGB: op(*(image<rgb_pixel>*)(bits));
}
}
Generic √
Efficient √
Compact x
Run-Time Flexible √

Solution: Template Hoisting
• Define a class hierarchy:template <int k> class k_channel_image {…};
class rgb_image : public k_channel_image<3> {};
class lab_image : public k_channel_image<3> {};
• Define the algorithm at the appropriate level of the hierarchy:
template <int k> void invert(k_channel_image<k>&) {…}
- enforces a specific hierarchy
- different algorithms may need different hierarchies- switch statement overhead remains
- does not help when the function is inlined
Generic x
Efficient √
Compact
Run-Time Flexible √

Agenda
• Context & problem statement
• Background – previous approaches
• Our approach to code bloat reduction
• Code bloat reduction in run-time dispatch
• Results & conclusion

Type Reduction
• Every algorithm partitions the space of its argument types into a set of equivalence classes
• Members of an equivalence result in the same assembly when instantiated
• The algorithm is instantiated only with one representative from each equivalence class

Type Reduction Implementation
• Metafunction to define the partition:
template <typename Op, typename T>struct reduce { typedef T type;};
• Generic algorithm invocation:
template <typename Op, typename T>inline void apply_operation(const T& argument, Op op) { typedef typename reduce<Op,T>::type base_t; op(reinterpret_cast<const base_t&>(argument));}

Example: The invert algorithm• Define the algorithm as a function object:struct invert_op { template <typename Image> void operator()(Image&){…} };
• Provide a function overload to invoke it:template <typename Image> inline void invert(Image& image) { apply_operation(image, invert_op());}
• Inverting RGB and LAB images is assembly-level identical:template<> struct reduce<invert_op, lab8_image_t> { typedef rgb8_image_t;};

The technique generalizes to multiple dimensions
template <typename Op, typename T1, typename T2>void apply_operation(T1& arg1, T2& arg2, Op op) { typedef typename reduce<Op,T1>::type base1_t; typedef typename reduce<Op,T2>::type base2_t; typedef std::pair<T1*, T2*> pair_t; typedef typename reduce<Op,pair_t>::type base_pair_t; std::pair<void*,void*> p(&arg1,&arg2); op(reinterpret_cast<base_pair_t&>(p));}
template <> struct reduce<copy_pixels_op,lab8_image_t> {…};
template <> struct reduce<copy_pixels_op, std::pair<lab8_image_t,lab8_image_t> > {…};

Defining Reduce Specializations
• Reduce dimensions separately, then combine:template <typename Image> struct reduce<invert_pixels_op, Image> { typedef reduce_cs<Image::color_space_t>::type cs; typedef reduce_ch<Image::channel_t>::type channel; typedef image_type<cs,channel,…>::type type;};
• Reuse structures via metafunction forwarding:template <typename T1, typename T2> struct reduce<resample_pixels_op, std::pair<T1,T2> > : public reduce<copy_pixels_op, std::pair<T1,T2> > {};

Agenda
• Context & problem statement
• Background – previous approaches
• Our approach to code bloat reduction
• Code bloat reduction in run-time dispatch
• Results & conclusion

Reduction in variants
Input: a variant of:input_types: [rgb8_image, lab8_image, cmyk16_image, rgba16_image]input_index: 2
• Step 1: Reduce each member of the vector:reduced_t: [rgb8_image, rgb8_image, rgba16_image, rgba16_image]
• Step 2: Remove duplicates:output_types_t: [rgb8_image, rgba16_image]
• Step 3: Create index vector from reduced_t to output_types_t:indices_t: [0, 0, 1, 1]
• Step 4: Use indices_t to map the input index to an output index: output_index = indices_t[input_index] = indices[2] = 1
Invoke the algorithm on a variant of:output_types_t: [rgb8_image, rgba16_image]output_index: 1

Binary reduction in variants
• Step 1: Perform unary pre-reduction on each argument[A1, A2, A3, A4] with index 2 -> [A1, A3] with out_index1 = 1
[B1, B2, B3] with index 3 -> [B1, B2] with out_index2 = 0
• Step 2: Compute a vector of the cross-products of types[(A1,B1), (A1,B2), (A3,B1), (A3,B2)]
• Step 3: Apply unary reduction on it:output_types_t = [(A1,B1), (A1,B2), (A3,B2)]
• Step 4: Compute the index in the output vectorout_index = out_index1 * size(Vec1) + out_index2
Invoke the algorithm on a single variant of: output_types_t = [(A1,B1), (A1,B2), (A3,B2)]
out_index

Agenda
• Context & problem statement
• Background – previous approaches
• Our approach to code bloat reduction
• Code bloat reduction in run-time dispatch
• Results & conclusion

Tests
• Test sets– Set A: 90 types (10 color spaces, 3 channel types, other variations)– Set B: 10 types (4 color spaces, other) – Set C: 12 types (3 color spaces, planar/interleaved, step/nonstep)
• Tests– Test 1: copy_pixels on Set B (inlined binary algorithm)– Test 2: copy_pixels on Set C (inlined binary algorithm)– Test 3: resample_pixels on Set B (non-inlined binary algorithm)– Test 4: resample_pixels on Set C (non-inlined binary algorithm)– Test 5: invert_pixels on Set A (inlined unary algorithm)

Results
Test 1 42.0 34.5 18% 201.6 107.5 47%
Test 2 41.5 26.0 37% 252.8 75.9 70%
Test 3 46.0 42.5 8% 259.8 144.0 45%
Test 4 33.5 34.0 -1% 318.7 98.8 69%
Test 5 24.0 16.5 31% 62.2 31.2 50%
Visual Studio 8 GCC 4.0
No Reduce
ReducePercent
reductionNo
Reduce Reduce
Percent reduction
Test 1 106% 116%
Test 2 78% 97%
Test 3 87% 118%
Test 4 75% 103%
Test 5 194% 307%
VS 8.0 GCC 4.0Reduction in code bloat
Effect on compile time

Conclusion• Drawbacks
– Unsafe– Requires intimate knowledge of the types and the
algorithm– Some compilers can optimize most of the code bloat
• Benefits– Works even when functions are inlined– Simplifies code generated by variants (especially
double dispatch)– Does not impose class hierarchy (essential for
generic code!)– Works when algorithms differ in requirements

















![arXiv:1505.03873v1 [cs.CV] 14 May 2015Kevin Tang 1, Manohar Paluri2, Li Fei-Fei , Rob Fergus 2, Lubomir Bourdev 1Computer Science Department, Stanford University 2Facebook AI Research](https://img.pdfslide.us/doc/110x75/5f3d33e6f435b52f5b21629b/arxiv150503873v1-cscv-14-may-2015-kevin-tang-1-manohar-paluri2-li-fei-fei.jpg)
![availablpublicly dataset The e. is · 2015. 5. 24. · [1]Lubomir Bourdev and Jitendra Malik. Poselets: Body part detectors trained using 3D human pose annotations. In ICCV, 2009](https://img.pdfslide.us/doc/110x75/5ff924769b8ae230003bdb1e/availablpublicly-dataset-the-e-is-2015-5-24-1lubomir-bourdev-and-jitendra.jpg)










