Embed Size (px)
Citation preview

Systems and Computers in Japan, Vol. 23, No. 3, 1992 Translated from Detuhi JohoTluahin Gakkai Ronbunshi, Vol. 73-PI, No. 10, October 1990. pp. 802-811
Efficient Distributed Algorithm to Solve Updating Minimum Spanning Tree Problem
Jungho Park, Ken’ichi Hagihara, and Nobuki Tokura, Members
Faculty of Engineering Science, Osaka University, Toyonaka, Japan 560
Toshimitsu Masuzawa, Member
Education Center for Information Processing, Osaka University, Toyonaka, Japan 560
SUMMARY
This paper proposes a distributed algorithm for reconstructing a minimum-weight spanning tree T’ of a network N‘ when link addition and deletion occur in a network N with a minimum-weight spanning tree T. In this algorithm each processor uses information whose adjacent links belong to T in order to construct T’ effi- ciently. The communication complexity and ideal time complexity of the algorithm are O(n log(f + r ) + m) and O(n log(f + 1) + n, respectively, where n and e are the number of processors and that of links in N’, t is the number of added links, and f represents that of deleted links belonging to T. Here, m = n + t when f = 0 and m = e otherwise.
This paper also presents a distributed algorithm for reconstructing a minimum-weight spanning tree T+ when links and processors are added and deleted. The com- munication complexity and ideal time complexity of the algorithm are O(n log(g + h) + r) and O(n log@ + h) + n), respectively, where g is the total number of added links (including links incident to added processors) and h represents the number of deleted links belonging to T (including links incident to deleted processors). Thus, r = n + g w h e n h = O a n d r = e w h e n h > O .
1
1. Introduction
A minimum-weight spanning tree (MST) of a network often is used for efficient implementation of broadcasting a message and collecting information. Fig- ure l@) presents an example of an MST. In a network, to construct an MST is to determine which adjacent links belong to MST from the initial situation in which each processor knows its own identifier and weights of its incident links (such information is called basic informa- tion). For example, in Fig. l@), processor v decides that the links (v , u) and (v , w ) belong to an MST. To date, distributed algorithms have been studied which construct the MST from scratch. Gallager et al. [3] proposed a distributed algorithm (abbreviated as GHS) for construct- ing an MST in O(n log n + e‘) time and showed that its communication complexity is asymptotically optimal. Here, n and e’ are the number of processors and that of links of N.
In practical networks there arise deletion of proces- sors or links (due to failures, etc.) and addition of them (for example, due to recovery from failure). Thus, we may consider that topology of a practical network may change dynamically. Suppose that an MST (called OMST (old MST), hereafter) shown in Fig. l(b) has been built for N in Fig. l(a). Consider a situation in which, due to
ISSNO882-1666/92/00034XM1$7.50/0 1992 Scripta Technica, Inc.

10 24
(a) Network N (b) MST of N
Added link Deleted link
I 47
10 10 24
(c) Network N' (d) MST of N'
Fig. 1. Networks and MST.
the deletion of one link and to the addition of two links, it has been changed to the network N' in Fig. l(c). Then, the OMST is not an MST for N'. Therefore, for efficient message broadcast and information collection we must reconstruct an MST for N' indicated by bold lines in Fig. l(d), which is called an NMST (new MST).
The problem of reconstructing an MST for a net- work after topology change is called the updating MST problem (hereafter called UMP). In this paper we consid- er the case in which link deletion and link addition oc- curs and the case where deletion and addition of links and processors are mixed.
If we apply the algorithm GHS to N', UMP can be solved in communication complexity O(n log n + e), where n and e are the number of processors and that of links in N'. However, when we construct an MST for a network N, we may build up auxiliary information at each processor to solve a UMP efficiently. It is interest- ing not only from a theoretical viewpoint but also practi- cally to clarify what information should be used for the auxiliary information.
In this paper, we will solve a UMP using as auxil- iary information the information concerning an OMST possessed by each processor (whose adjacent links belong to the OMST; this information is called old solution). Since the old solution can be obtained from OMST with- out any message exchange, it is a kind of natural auxilia- ry information.
Distributed algorithms for solving UMPs in the case of only link addition and in the case of only link deletion have been presented in [6] and [2]. However, no studies have been made so far for a UMP for which link addition and link deletion are mixed. For UMP in the case in which link addition and link deletion occur h s paper presents a distributed algorithm MA whose com- munication complexity and ideal time complexity are q n log(f + 1) + m) and O(n log(f + t ) + n). respectively. Here, t is the number of added links andfis the number of deleted links belonging to OMST and m = n + t iff = 0 and m = e othenvise. In the following, we compare the complexity of the algorithm MA with the results in [6] and [2], in the case in which either link addition or link deletion occurs.
First, in the case in which only link addition oc- curs, distributed algorithm whose communication com- plexity and ideal time complexity are both q n r + ?) is presented in [a] . Since the communication complexity and ideal time complexity of the algorithm MA in this paper become O(n log t + n ) in this case, the algorithm MA is superior with respect to communication and ideal time complexities.
Next, in the case in which only link deletion oc- curs, a distributed algorithm (referred to as CK, hereaf- ter) is presented in [2]. The communication complexity and ideal time complexity of this algorithm are both og' 'p), where j ( 2 j) is the number of deleted links and p represents the length of the longest (simple) cycle in N'. In this case, the communication complexity and ideal time complexity of the algorithm MA become O(n log f + e) and O(n log f + n), respectively. In the following, we show the points where the algorithm MA is superior to CK.
It is superior with respect to the length of one message. The length of one message is q l o g n) in MA while it is U(e log n) in CK.
It is superior with regard to bit complexity. The bit complexity of CK is O(fpe log n ) while that of MA is O(n logz n + e log n).
2

When j = Q ( S + X ) , it is superior in its communication complexity. In addition, whenj = Q( mogfn3) , it is superior in its ideal time complexity.
It is superior with respect to space complexity. Since CK uses Replacement set (a set of links for each link belonging to OMST which, when the link is deleted, can be links of NMST) in addition to Old Solution as auxiliary informa- tion, it requires more space.
2. Definitions
L.1. Definitions concerning graphs
A weighted undirected graph G is defined by a three-tuple G = (V, E, W); V is a nonempty set of verti- ces; E is a set of undirected edges (unordered pairs of distinct vertices); and W is a function W E - N (N is a set of natural numbers) and for each e ( ~ E)W(e) is called a weight of e. When e = (u, v), W(e) is sometimes rep- resented as W(u, v). In the following, for simplicity, a weighted undirected graph G = (V, E, W) is expressed simply as G = (V, E) when edge weight is not a factor. Since we consider only weighted undirected graphs in this paper, we refer to a weighted graph simply as a graph. When (u, v) E E in G = (V, E), u is said to be a neighbor of v and a set {v E VI (u, v) E: E} of neighbors of IA is represented by NEGG(u). The degree degG(u) of u is defined by degG(u) = I NEG& 1 .
If a sequence of distinct vertices C v I , . . . , vm > in G = (V, E ) satisfies (v,, vi+J E E for each i(l s i s rn - 1). this sequence is called a v1 - vm path and rn - 1 is said to be the length of the path. Especially, a sequence < v> consisting of only one vertex v also is considered asav-vpathoflengtho. Ifthereexistsau-vpathfor two arbitrary vertices u and v in G, G is said to be con- nected. We define the distance ddu, v) between two vertices u and v of G to be the length of the shortest u - v path. Note that if there is no u - v path, then we define d d u , v ) = Q).
When there exists a v, - vm path < v,, ..., vm> of length more than one and an edge (vl, vm), the vertex sequence <v,, ..., vm, v,> is called a cycle. An undi- rected graph containing no cycle is called a tree. Espe- cially, a tree in which a vertex called the root (let it be i) is specified is called a rooted tree with root i . For a
rooted tree with root i , the following terminologies and notations are introduced.
Parent and son: Let u and v be any two verti- ces which are adjacent to each other. When dd i , v) = d d i , u) - 1 holds, v is called the parent of u and u is called a son of v.
Ancestor and descendant: Let u and v be any two vertices. An i - v path is determined uniquely in T. When the vertex u appears in the i - v path, u is called an ancestor of v and v is called a descendant of u (u itself is an ancestor of u and a descendant, too). The set of descen- dants of u is denoted by DESdu).
Leaf: A vertex having no son is called a leaf.
For graphs G = (V, E, W) and G' = (V, E', W), when V s Vand E' G E hold and furthermore, a func- tion W' satisfies W ( e ) = W(e) for each e ( ~ E'), G' is called a subgraph of G and we denote G' G G. Termi- nologies and notations concerning subgraphs are defined as follows.
Spanning tree: Let G' = (V, E') be a subgraph of G = (V, E) . When V = Vand G' is a tree, G' is called a spanning tree of G. In the following, we consider only rooted spanning trees in this paper. Thus, for simplicity, a rooted spanning tree is called simply a spanning tree.
Minimum-weight spanning tree: Among span- ning trees of G one such that the total sum of edge weights is smallest is called a minimum- weight spanning tree (hereafter called MST). When edge weights are all different in G, the MST of G is determined uniquely [3].
Induced subgraph: Let G' = (V', E') be a subgraph of G = (V, E). When E' = { (u , v ) E E I (u, v E V}, G' is called a subgraph of G induced by V and denoted by qV].
0 Subtree: Let u be an arbitrary vertex of a rooted tree T; ZTDESdu)] is called a subtree of T with root u.
Connected component: Maximal connected subgraphs of a graph G are called connected components of the graph G.
3

2.2. Definitions on networks and distributed (7) An arbitrary processor (perhaps more than one) becomes an initiator (a processor which starts exe- cution of a program spontaneously). Processors other
algorithms
We present definitions and assumptions concerning networks and distributed algorithms. See [4] for details.
A network N is defined by a three-tuple N = (P, L, W). Here, P is a set of processors and L is a set of links (unordered pairs of distinct processors). A link (u, v) is a bidirectional link; W is a function W:L - N (N is a set of natural integers) and for each I ( € L)W(Z) is called a weight of 1. From the definition, a network N can be considered as an undirected graph and thus we use termi- nologies and notations for undirected graphs.
We make the following assumptions concerning networks and distributed algorithms.
(1) There is no common memory in a network and processors can communicate only by message ex- changes.
(2) A network is asynchronous. That is, transfer delay of a message is finite, but it is unpredictable and variable.
(3) A message processor u sent to its neighbor v reaches v without any loss.
(4) In the initial state each processor knows its identifier, weights of incident links, which incident links are deleted and whch ones are added. Furthermore. in some cases, auxiliary information (refer to Definition 1) is available.
(5 ) Every processor has a unique identifier of O(log n ) bits.
(6) Weights of links are all different and each link weight can be expressed by O(1og n) bits.'
This assumption is merely for simplicity of de- scription and is not essential. When there are links of the same weight, if we let the weight of a link (u, v) be a three-tuple < W(u, v), identifier of u, identifier of v> (where we assume that u's identifier C v's identifier), every link has different weight. For this purpose we need to exchange identifiers between adjacent processors. But this does not affect the complexity of the results in this paper.
than the initiator start execution of their programs when they receive messages from other processors.
(8) While distributed programs are executed, addition or deletion of processors and links does not occur.
In this paper, first we consider the problem of updating an MST when link addition and link deletion occur. The MST updating problem in the case in which processor addition and deletion occur as well as that of links is considered in section 5 .
Definition 1 (Updating MST problem, referred to as UMP hereafter). Let N be an arbitrary network. When N is changed into a network N' due to addition or dele- tion of links, the problem of constructing an MST of N' (each processor determines which incident links belong to the MST of N') is the UMP. In some cases, we can use auxiliary information which each processor has to solve the UMP efficiently. In the case in which each processor has auxiliary information, when we solve UMP we also need to update the auxiliary information so that it corresponds to N'.
In general, efficiency of a distributed algorithm is measured using communication complexity, bit complexi- ty, and ideal time complexity. However, we may use auxiliary information to reduce community, bit complex- ity, and ideal time complexity. Hence, in this paper we consider local space complexity and global space com- plexity in addition to the forementioned complexity measures.
Communication complexity is the total number of messages exchanged in the worst case during the execu- tion of a distributed algorithm and the bit complexity is the sum of bits in messages exchanged in the worst case among all processors. When we neglect the processing time within processors and assume that it takes at most one unit time for a message to transfer on a link, the ideal time complexity is the total unit times before the algorithm terminates. The local space complexity is the quantity of local memory used by each processor and the global space complexity is the sum of local memory used by all processors.
4

3. Distributed Algorithm for Updating Minimum Weight Spanning Tree
3.1. The case of mixture of link addition and deletion
Here we consider the topology change in which addition and deletion of links occur. In the following, let N = (P. t) be an arbitrary network and N' = (P, L') be a network after topology change. Note that we consider only connected networks in this paper. In other words, we assume that N and K are both C O M I X ~ ~ ~ . Also, we express an MST of N by M q N ) = (PI L q N ) ) and an MST of N' by M q N ) = (PI LqN')).
In the following we present a distributed algorithm MA (minimum spanning tree updating algorithm) to solve a UMP in N' when a network is changed from N to N' due to link addition and deletion.
When some links are deleted (in the following, deleted links belonging to M q N ) are called deleted branches and a set of deleted branches is represented by Ed), M T N ) is divided into some connected components. An arbitrary connected subgraph of MqW) is called a fragment (of MT(N')). Using the property that each connected component of M q N ) - Ed = (P, L q N ) - Ed) is a fragment of M q N ' ) , a distributed algorithm for constructing M q N ' ) efficiently was presented in [5]. The algorithm in [5] constructs M q N ' ) from the initial con- figuration where there exist r fragments in communica- tion complexity O(n log r + e) by repeating connection of fragments. On the other hand, if a link (u, v) is added to N, there arises a cycle consisting of a u - v path in MTN) and the link (u, v). Then, by deleting the maxi- mum weight link a m n g the links of the cycle, we can construct M q N ' ) [ 13. When more than one link is added (hereafter, a set of added links is represented by E J , there arise more than one cycle in M n N ) + E,(= P, W N ) u E,,)).
Reference [l] presents a distributed algorithm for constructing MqW) by repeating the finding of a cycle and deleting a maximum weight link from the cycle until there exists no cycle in M q N ) + E,,. However, since the algorithm in [ I ] finds a cycle and deletes a maximum weight link in a sequential manner, its efficiency is not good. On the other hand, it is not so easy to perform this operation efficiently for more than one cycle in a parallel fashion. Thus, in the algorithm MA in this paper, we introduce a new notion of "partitioning links" (described later) to resolve this difficulty. In the following we de- scribe briefly the idea of the algorithm MA.
0 Polluted processor
# Primarypath 0 Diverging processor
Fig. 2. The diagram of Definition 2.
When link addition and deletion occur (let a set of added links be E,, and that of deleted branches be Ed) , M q N ) is divided into more than one connected compo- nent. However, since there may exist an added link, each connected component in M q N ) - Ed is not always a fragment of M q N ' ) . In the algorithm MA, first, we remove some links from M q N ) in addition to deleted branches (those links, including deleted branches which are removed from MVN) are called partitioning links (refer to Definition 2) and a set of partitioning links is represented by Ep). Hence, the following properties (1) and (2) hold:
(1) M q N ) - Ep is a subgraph of M q N ' ) (see Lemma 1);
(2) M q N ) - Ep consists of O(f + r ) connected r = IE,I. components (set? Lemma 2), wheref=
In the algorithm MA, after deleting partitioning links, using the Properties (1) and (2), we efficiently construct an NMST by applying the algorithm in [5] in a situation in which there are O(f + r ) fragments. It is important that we can efficiently find partitioning links. First, we define partitioning links as follows.
Definition 2. Processors connected with added links or deleted branches are called polluted processors (see Fig. 2). Also, a processor which has a polluted processor among descendants of more than one distinct son is called a diverging processor. Let u and v be any polluted or diverging processors. When there is no other polluted or diverging processor on a u - v path, this u - v path is called the primary path with two ends u and v. A maximum weight link in each primary path is called a partitioning link (see Fig. 2).
5

. / L/ Fig 3. Graph of the proof of Lemma 1.
From the definition of a partitioning link, a parti- tioning link is a link of M q M .
Let a set of partitioning links be Ep. For M q N ) - Ep we have the following lemma.
Lemma I . M V N ) - Ep is a subgraph of M q N ’ ) . Suppose that some connected component of M q N ) - Ep is not a fragment of MVN’) . Then the connected compo- nent contains a link which does not belong to MT(N‘). Let the link be (u, v) and assume that v is a son of u (in W N ) ) .
If we remove (u, v) from MT(N), M q N ) is parti- tioned into a subtree of M q N ) with root v (denoted by T,) and the other subgraph (denoted by G’) and either (1) or (2) in the following holds.
(1) There is an added link connecting a processor in T,, with one in G‘ (see Fig. 3).
Since there is an added link between a processor in T, and one in G‘, there is a polluted or diverging proces- sor in the ancestors of u. Let t be a processor nearest to u among them. Similarly, there is also a polluted or diverging processor in the descendants of v. Let s be the one nearest to v among them. By the definition of parti- tioning links, a maximum weight link in a t - s path (let it be (g, g‘ ) and g is a son of g‘ ) is a partitioning link.
Without loss of generality, we can assume that (8, g ’ ) lies on a u - f path. When we remove (u, v) and (g,
g’) from M q N ) , M q N ) is partitioned into a subgraph containing u and g (let it be G1) and subgraphs contain- ing u and g ’ , respectively. Since there is no polluted or diverging processor on a u - g path from the manner of choosing 1, for any link (z, 2 ’ ) connecting a processor of G1 with one not belonging to GI we have either W(z, 2’)
> W(u, v) or W(z, z’) > W(g, g‘) [3]. Also, s i n e (g, g ’ ) is a maximum weight link on a t - s path and thus we have W(g, g‘ ) > W(u, v) . we have W(z, z’) > W(u, v) .
If we add (u, v) to MT(N’), a cycle arises due to a u - v path in M q N ’ ) and (u, v). In this cycle there exists a link other than (u, v) connecting a processor in G1 and one not belonging to G1 and let @, q) be an arbitrary one among them; (P, (LT(N‘) - {@, q) } ) u {(u, v ) } ) is a spanning tree and we have W@, q) > W(u, v). There- fore, the sum of links in this spanning tree is less than that in M V N ‘ ) . Thus, it contradicts the fact that M q N ’ ) is an MST of N’.
(2) There is no added link connecting a processor in T, with one in G’.
Since (u, v) belongs to M q N ) and M q N ) is a spanning tree, for any link @, q) between a processor in T,, and one in G’, W(p, q) > W(u, v) holds [3].
For the number of connected components of M q N ) - Ep the following holds.
Lemma 2. The number of connected components of M q N ) - Ep is O(t +A, where t = I E,I ,f = I E d [ .
Proof. Define a graph G’ = (V‘ , E’) whose verti- ces are connected components of M V N ) - Ep as follows. Let Ci(i = 1, 2, ..., z) be connected components of M V N ) - Ep. Let the vertex set be V = {Cili = 1, ..., z}, and the set of edges be E’ = {(Ci, q) I . There is a partitioning link between a processor in Ci and one in %(i + J ] } ; G‘ = (V, E’) is obviously a tree. Each con- nected component includes either a polluted processor or a diverging processor. Since the number of polluted processors is at most 2(t +A, the number of vertices corresponding to connected components containing pol- luted processors is at most 2(t +A. A vertex correspond- ing to a connected component containing a diverging processor (hereafter called a diverging vertex) has two or more sons in G from the definition of diverging proces- sors. Therefore, the number of diverging vertices is at most 2(t +j) - 1 and thus the number of connected com- ponents is o(t +A.
6

Consider the case in which a network N is changed into N’ only due to addition of links (H = 0, It1 > 0). In this case, from the following property, links in N which are not contained in MT(N) are not contained in MT(N’). Using this property, to save messages, in MA we do not send any message to links which are not con- tained in M q N ) .
Property 1. LT(N’) s LTN) u E, holds.
Proof. Suppose that there is a link (u, v) which belongs to MT(N’) but does not belong to MT(N).
If we delete (u, v) from MT(W), MT(N’) is parti- tioned into two subgraphs G1 and G.2. Since (u, v) is a link in MT(N’), for any link (s, t) ( E L’ - {(u, v)}) con- necting a processor in G1 with one in G2, we have W(u, v) < W(s, t). Since (u, v) does not belong to MT(N), if we add (u, v) to M V N ) a cycle arises, and in this cycle there is a link (x, y) other than (u, v) between G1 and G2. Then we have W(u, v) < W(x, y ) ; (P, LT(N,l - {(x, y ) } u {(u, v ) } ) is a spanning tree and we have W(u, v) < W(x, y). Thus, the total sum of weights of links in this spanning tree is smaller than that of MT(N). There- fore, it contradicts the fact that M q N ) is an MST of N.
Next, we show an outline of the algorithm MA.
3.2. Outline of MA
MA consists of two phases. In the first phase we find partitioning links and then delete them from MT(N). In the second phase, applying the algorithm in [S], we construct MT(N‘). Here we describe briefly the prepro- cessing of Phase 1 and Phase 1 itself. Refer to [5] for Phase 2.
Outline of the preprocessing of Phase 1.
First, as a preprocessing, the initiator examines whether there is a deleted branch using links of M q N ) - Ed*
(1) The case where there is no deleted branch
(2) The case where there is a deleted branch
The initiator awakes every processor by sending a message through every link. Then, in each of thef + 1 connected components of M q N ) -Ed , choose the leader of the connected component.
Outline of Phase 1
The leader i of each connected component sends the < START P message to every processor in the com- ponent via links of M n N ) - Ed to notify the start of Phase 1. A leaf u which received < START > transmits the <NO> message to its parent to notify the parent that there is no polluted processor in the descendants of u if u is not a polluted processor. If a leaf u is a polluted processor, it transmits the message < EXT( W(u, u’ ) ) > to its parent u’ notification that there is a polluted proces- sor in the descendants of u , where W(u, u’) represents a candidate of a partitioning link on a primary path with endpoint u.
Each processor u other than a leaf waits until it receives < N) > or < EXT > from every son.. When it receives <EXT(val)> from two or more sons, u is found to be a diverging processor and otherwise it is found that u is not a diverging processor.
If u is a diverging processor, to delete a partition- ing link on a primary path with endpoint u from M q N ) , it sends < CUT(va1) > (the val value of <CUT > mes- sage is the Val value of < EXT > message) to every son that sent < EXT(val) > to u. Then it sends < EXT(W(u, u‘)> to its parent u’. Processors s and t that received < EXT(va1) > such that W(s, t ) = Val see that (s, t ) is a partitioning link.
If u is not a diverging processor, one of the follow- ing is performed.
(1) The case where u received <NO> from all of its sons:
If u is a polluted processor, it sends < EXT( W(u, u‘)) > to its parent u’ and otherwise it sends <NO > to u’. Do nothing if u is a root.
Every processor is initiated by a message to exam- ine the existence of a deleted branch. In this case, since there is only one connected component, choose an arbi- trary processor (let it be i ) in the component as the lead- er in the component.
’Here, for simplicity of description, we make each processor wait until it receives a message from all of its sons. However, we can do this also in such a way that it immediately performs an action for a received message.
7
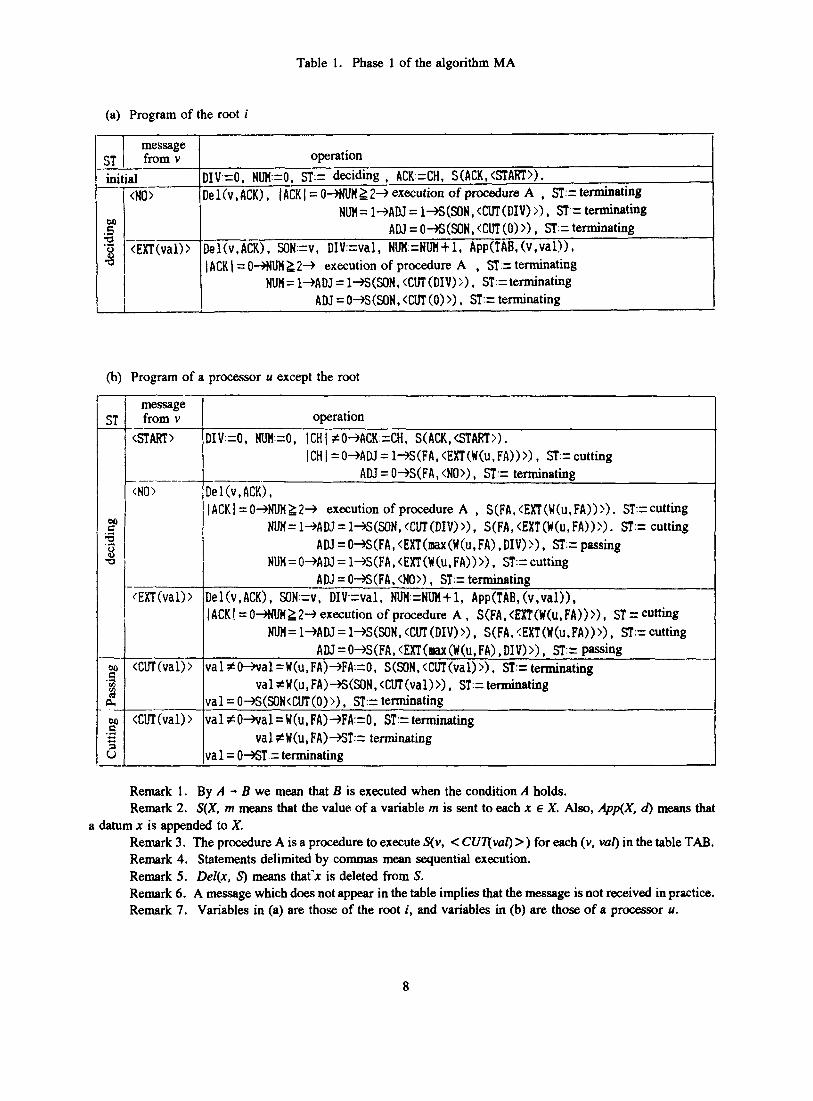
Table 1. Phase 1 of the algorithm MA
M C 3
'p
.- 'S
--
(a) Program of the root i
ST I from v operation I 1 I message 1
(EXT(val)>
DIV.=O, NM:=O, ST:= deciding , ACK=CH, S(ACK,<START>). De 1 (v, ACK) , I ACK I = O W H 2 2+ execution of procedure A , ST:= termhating I <NO>
ADJ = O+S(FA, <NO>), ST.= terminating Del(v,ACK), SON=v, DIV.=val, N W = N M + l , App(TAB, (v,val)), IACK[=OjHUnL2+execution ofprocedure A , S(FA,<EXT(W(u,FA))>), ST=Cu*th
Nun = 1+ADJ = l+S(SON, <CUT (DIV) >) , S( FA, {EXT (W (U , FA) >) , 3.z cutting
NUI(=~~ARI=~~S(SDN,(CU~(DIV),), ST= terminating AI!J=O+S(SON,<CUT(O)>), ST = terminating
Del(v,ACK), SON =v, DIV =Val, NU)( = N M + l , App(TAB, (v,val)), I ACK I = O - A U H 2 2+ execution of procedure A , ST = terminating
Nut! = 1jADJ = l+S(SON, <CUT (DIV) ;) , ST =terminating A D J = O+S(SON, <CUT (0) >) , ST = terminating I
<CUT(val)>
(b) Program of a processor u except the root
b
ADJ=O+S(FA,<EXT(max(W(u,FA),DIV)>), ST:= passing valfO+val=W(u,FA)+FA:=O, S(SON,<CUT(val)>), ST:= terminating
<CUT(val)> pi a . -
- val#W(u,FA)-Uj(SON,<CUT(val)>) Sf:= terminating
- Val = o+S(SON<CUT(O) >) , ST:= terminating val#O+val=W(u,FA)+FA:=O, ST:= terminating
Val #W(u, FA)+ST:= terminating va 1 = O+ST.= terminating
!-
operation
ICHl fO+ACK.=CH, S(ACK,<START>). I message
from v
\CHI =O+ADJ= l~S(FA,<EXT(W(u,FA))>), ST:=cutting
Remark 1. By A - B we mean that B is executed when the condition A holds. Remark 2. S(X, rn meaus that the value of a variable rn is sent to each x E X. Also, App(X, d) means that
Remark 3. The procedure A is a procedure to execute S(v, < CUT(vul) >) for each (v, vuf) in the table TAB. Remark 4. Statements delimited by commas mean sequential execution. Remark 5. DeZ(x, S) means that'x is deleted from S. Remark 6. A message which does not appear in the table implies that the message is not received in practice. Remark 7. Variables in (a) are those of the root i, and variables in (b) are those of a processor u.
a datum x is appended to X.
a

(2) The case where u received < EXT(val) > from only one son:
(a) W e n u is a root.
If it is not a polluted processor, do nothing. If it is a polluted processor, it sends < CUT(val) > to the son that sent < EXT(va1) > .
(4) cCUT(val)> message:
Notification is sent that a partitioning link is a link with weight val.
3.4. Local variables
Each processor u has the following local variables. (b) When u is not a root.
If it is not a polluted processor, it sends <EXT(max(W(u, u’), Val))> to the parent u’. If it is a polluted processor, it sends < CUT(va1) > to the son that sent <EXT(val)> and sends <EXT((u, u’))> to the parent u’.
Each processor that sent <NO> to its parent becomes the terminating status after transmitting < NO > (in other words, termination of Phase 1). and each pro- cessor that sent <EXT> to its parent becomes the terminating status when it receives < CUT> from the parent. Also, the mot becomes the terminating status when it receives a message from every son and finishes the process for it.
Operations of each processor in Phase 1 (except the preprocessing) of the algorithm MA is shown in Table 1.
3.3. Messages
Here we describe briefly messages and variables used in Phase 1 of MA.
(1) <START> message:
It is a message that the root of each connected component transmits notification of the start of the exe- cution of Phase 1.
(2) <NO> message:
The parent is notified that there is no polluted processor in the subgraph with itself as the root.
(3) < EXT(va1) > message:
The parent is notified that there is a polluted pro- cessor in the subgraph with itself as the root. The param- eter Val represents a candidate of a partitioning link on a primary path.
(1) FA,: It stores an identifier of its parent in M q N ) - Ed. In the beginning of Phase 1, it stores an identifier of the parent of u in a rooted spanning tree found in the preprocessing of Phase 1. Letting FA, = v in the beginning of Phase 1, if (u, v) is a partitioning link, FA, = 0 holds when Phase 1 terminates.
(2) CH,: It stores a set of identifiers of u’s sons in M q N ) - Ed. When Phase 1 is started, it stores identi- fiers of u’s sons in a rooted spanning tree found in the preprocessing of Phase 1. Its value never changes during Phase 1.
(3) WM,: It stores the number of messages < EXT(va1) > received from sons.
(4) ACK,: It stores a set of identifiers of sons from which neither < EXT(va1) > nor < NO > has been received.
( 5 ) ON,: It stores the val of the latest < EXT(va1) > which is received from sons.
(6) SON,: It stores an identifier of a son which sent the latest < EXT(val) > .
(7) POL,: A variable expressing whether it is a polluted processor. When Phase 1 is started, it is initial- ized to be 1 if it is a polluted processor and 0 otherwise.
(8) ST,: It represents a state of u. The state is one of the following.
deciding state: This is the initial state of Phase 1 and it is examined whether it is a diverging processor.
passing state: This is the state in which it is found that it is neither a polluted processor nor a diverging processor but a processor on a primary path.
9

cutting state: This is the state in which it is determined whether it is a polluted or a diverg- ing processor.
terminating state: The state after termination of execution of Phase 1.
4. Correctness and Evaluation of Algorithm MA
It is obvious that Phase 1 and the preprocessing of Phase 1 terminates within finite time and links deleted from an OMST in Phase 1 are partitioning links. Since each connected component obtained by removing parti- tioning links is a fragment of MT(N') from Lemma 1, using the method in [ 5 ] , we can correctly construct MT(N') within finite time in Phase 2. Therefore, we have the following
Theorem 1. The distributed algorithm MA correct- ly solves the UMP.
Next, we shall evaluate communication complexity and ideal time complexity of the distributed algorithm MA. In the following, let t = I E, 1 , f = I Ed I , n repre- sent the number of processors and e that of links in a network after topology change.
Theorem 2. The communication complexity of the distributed algorithm MA is O(n log(t +f) + m), where M = n + t when f = 0 andm = e otherwise.
Proof. (1) When f = 0, q n log(t +f) + (n + 2))
The communication complexity of the preprocess- ing of Phase 1 is q n ) [5]. In Phase 1, <START> is transmitted at most once to each link of M q N ) and for one < START > either < NO > or < EXT(va1) > is sent back once. Also, <CUT(val)> is sent at most once to each link of MT(N). Therefore, the communication com- plexity of Phase 1 is q n ) . Next, we show the communi- cation complexity of Phase 2. Since we have LT(N') s (LT(N) u E,, it suffices to construct the MST of M q N ) + E, (consisting of (t + n) links). Further, the number of connected components of L q N ) - Ep is O(t +
j) (Lemma 2) and they are fragments of MqM) (Lemma 1). Thus, the communication complexity of Phase 2 is qn iog(t +A + (n + t ) 151.
(2) Whenf > 0, O(n log(t +j) + e
The communication complexity of the preprocess- ing of Phase 1 is O(e) and the communication complexity of Phase 1 is q n ) . Next, we show the communication complexity of Phase 2. Since L n N ' ) s L', all the links (that is, e links) can be links of MT(N'). In a manner similar to item (1) we can show that the communication complexity of Phase 2 is q n lo& +f) + e).
Since the lengths of messages used in Algorithm MA are O(log n) , we have the following
Theorem 3. The bit complexity of the distributed algorithm MA is
O( 12log( f -t f) * logn + rnlog12)
Theorem 4. The ideal time complexity of the distributed algorithm MA is
Proof. The ideal time complexities of Phase 1 and the preprocessing of Phase 1 are both q n ) . Since there are q t +A fragments when Phase 2 is started, the ideal time complexity of Phase 2 is q n log(t +A + n) [5 ] .
Since each processor suffices to remember the identifier of the leader of the fragment to which it be- longs, the incident links of OMST and those of NMST, we have the following
Theorem 5 . The local space complexity of the distributed algorithm MA is O(d + log n ) and its global space complexity is O(e + n log n), where d =
max(deg&), degN(u)).
5. When Addition and Deletion of Links and Processors are Mixed
Here, we describe briefly the idea of a distributed algorithm of communication complexity O(n log@ + h) + r) and ideal time complexity O(n log@ + h) + n ) for solving the MST updating problem (or finding MT(N') = (PI, LT(M)) in the case in which a network N is changed into N' = (PI, L') due to addition and deletion of processors as well as those of links. Here, let g be the number of added links (including links incident to added processors) and h be the number of deleted links belong- ing to OMST (including links incident to deleted proces- sors). Also, we have r = n + g when h = 0, and r = e
10

Also, we have r = n + g when h = 0, and r = e when h > 0 (n and e are the number of processors and of links, respectively, in a network after topology change).
Definition 3. A processor u is called a polluted processor if one of the following holds for U(E P) in N:
(a) a processor incident to a deleted link in N;
which additions and deletions of links and processors are mixed.
Here, n and e are the numbers of processors and links in a network after topology change, and g is the number of added links and h the number of deleted links belonging to OMST. Also, we have t = g + n when h = 0, and r = e when h > 0, and d = max(degdu), degN.(u)).
(b) a processor adjacent to an added processor in N'; and
6. Conclusions (c) a processor incident to an added link in hr.
Diverging processors, primary paths and partition- ing links are defined in the same manner as in Definition 2.
When a processor is deleted, all the incident links also are deleted; and processors adjacent to a deleted processor in N are also polluted processors.
When a network M T = ( ( P - Pd) u Pa, (L - Ep) u Ea) (where Pd and Pa represent a set of deleted proces- sors and that of added processors respectively, and Ep and E, represent a set of partitioning links and that of added links, respectively), the following items (1) and (2) hold (which can be shown similarly to Lemmas 1 and 2):
(1) MT' is a subgraph of MT(K); and
(2) MT' consists of o(8 + J) connected compo- __ nents.
In the same way as in Phase 1 of algorithm MA we can find partitioning links. By applying the algorithm in [5 ] after removing partitioning links from N', we can construct the NMST in the case in which additions and deletions of links and processors arise.
The following theorems can be shown similarly to Theorems 2 to 5.
These results are further generalization of Theo- rems 2 to 5 and when Pa = Pd = 4, they coincide with the results in the preceding section.
Theorem 6. There is a distributed algorithm with communication complexity O(n log@ + h) + r), bit complexity O(n log@ + h) * log n + r log n), ideal time complexity q n log@ + h) + n), local space complexity O(d + log n) and global space complexity O(e + n log n) for solving the MST updating problem in the case in
In this paper we have presented a distributed algo- rithm with communication complexity O(n lo& + A + n) and ideal time complexity q n log@ + j) + n) for solving the MST updating problem in the case in which addition and deletion of links arise. Here, n and e are the numbers of processors and links, respectively, in a net- work after topology change and t is the number of added links, and f is the number of deleted links which belong t o O M S T . W e h a v e m = n + f w h e n f = O a n d m = e when f > 0.
We also proposed a distributed algorithm with communication complexity q n log@ + h) + r) and ideal time complexity O(n lo& + h) + n ) for solving the MST updating problem in the case in which addition and deletion of links and processors are mixed. Here, g is the number of added links and h the number of deleted links belonging to OMST. Also, we have r = g + n when h = 0, and r = e when h > 0, and d = max(degdu), degh,*(u)).
Acknowledgement. This research was partially supported by the Mazda Research Encouragement Fund, Research Assistant Fund from Inamori Foundation, and Grant-in-Aid for Scientific Research (C), (B) and (A) from the Ministry of Education, Science, and Culture.
REFERENCES
1. C. Cheng, I. A. Cimet, and S. P. Kumar. A protocol to maintain a minimum spanning tree in a dynamic topology. Proc. of SIGCOMM '88 Sym- posium, Communications Architectures, and Proto- cols, California, pp. 330-337 (1988). I. A. Cimet and S. P. Kumar. A resilient distrib- uted algorithm for minimum weight spanning trees. proc. 1987 International Conference on Parallel Processing, pp. 196-203 (1987).
2.
11

3. R. Gallager, P. Humblet, and P. Spira. A distrib- Tokura. On a distributed algorithm for construct- uted algorithm for minimum weight spanning tm. ing a minimum weight spanning tree-The case of ACM TOPLAS, 5, 1 , pp. 66-77 (1983). link deletion. Technical Report, I.E.I.C.E.,
algorithm. Proc. of The Logic Programming Con- 6. Y. H. Tsin. An asynchronous distributed MST
ference, '87, pp. 11-20 (1987). updating algorithm for handling vertex insertions in networks. Proc. Int. Conference on Parallel Pro- cessing and Applications (1987).
4. Ken'ichi Hagihara. On complexity of distributed COMl'89-25 (1989).
5 . J. Park, T. Masuzawa, K. Hagihara, and N.
AUTHORS (from left to right)
Jungho Park graduated in 1980 from the University of Seikinkan, Korea. In 1982, he obtained a Master's degree from the University's Graduate School of Management. In 1990, he obtained a Dr.. of Eng. degree from Osaka University. He is engaged in research on distributed algorithms. He is a member of Information Processing Society of Japan.
Toshimitsu Masuzawa graduated in 1982 from the Department of Computer and Information Sciences, Faculty of Engineering Science, Osaka University, where in 1987 he obtained a Ph.D. and joined the Information Processing Education Center as a Research Associate. He is engaged in research on distributed algorithms, parallel algorithms, and graph theory. He is a member of Information Processing Society of Japan.
Ken'ichi Hagihara graduated in I974 from the Department of Computer and Information Sciences, Faculty of Engineering Science, Osaka University, where in 1979 he obtained a Dr. of Eng. degree. He then joined the Faculty of Engineering Science, Osaka University, as a Research Associate. He is currently an Associate Professor. Since 1982 he has been a member of a working group in the new generation computer technology development institute (ICOT). He is engaged in research on database theory, parallel algorithms, distributed algorithms, and programming language education. He served as a secretary of the Special Interest Group on Computation of ICOT during 1986 and 1988. He is a member of IEEE; Information Processing Society of Japan; and Japanese Software Science Association.
Nobuki Tokura graduated in 1963 from the Department of Electronics, Faculty of Engineering, Osaka University, where he obtained a Dr. of Eng. degree in 1968. He then joined the Faculty of Engineering Science of the University as a Lecturer. Currently he is a Professor in the Department of Information and Computer Sciences. he is engaged in research on programming techniques and theory, programming language, VLSI computational complexity and its theory. He is a member of ACM; Information Processing Society of Japan; Japanese Software Science Association; and Japanese Association on Artificial Intelligence.
12





























