Embed Size (px)
Citation preview

ECE 1747 Parallel Programming
Shared Memory: OpenMP
Environment and Synchronization

What is OpenMP?
• Standard for shared memory programming for scientific applications.
• Has specific support for scientific application needs (unlike Pthreads).
• Rapidly gaining acceptance among vendors and application writers.
• See http://www.openmp.org for more info.

OpenMP API Overview
• API is a set of compiler directives inserted in the source program (in addition to some library functions).
• Ideally, compiler directives do not affect sequential code.– pragma’s in C / C++ .– (special) comments in Fortran code.

OpenMP API Example
Sequential code:statement1;
statement2;
statement3;
Assume we want to execute statement 2 in parallel, and statement 1 and 3 sequentially.

OpenMP API Example (2 of 2)
OpenMP parallel code:statement 1;
#pragma <specific OpenMP directive>
statement2;
statement3;
Statement 2 (may be) executed in parallel.
Statement 1 and 3 are executed sequentially.

Important Note
• By giving a parallel directive, the user asserts that the program will remain correct if the statement is executed in parallel.
• OpenMP compiler does not check correctness.
• Some tools exist for helping with that.• Totalview - good parallel debugger
(www.etnus.com)

API Semantics
• Master thread executes sequential code.
• Master and slaves execute parallel code.
• Note: very similar to fork-join semantics of Pthreads create/join primitives.

OpenMP Implementation Overview
• OpenMP implementation– compiler, – library.
• Unlike Pthreads (purely a library).
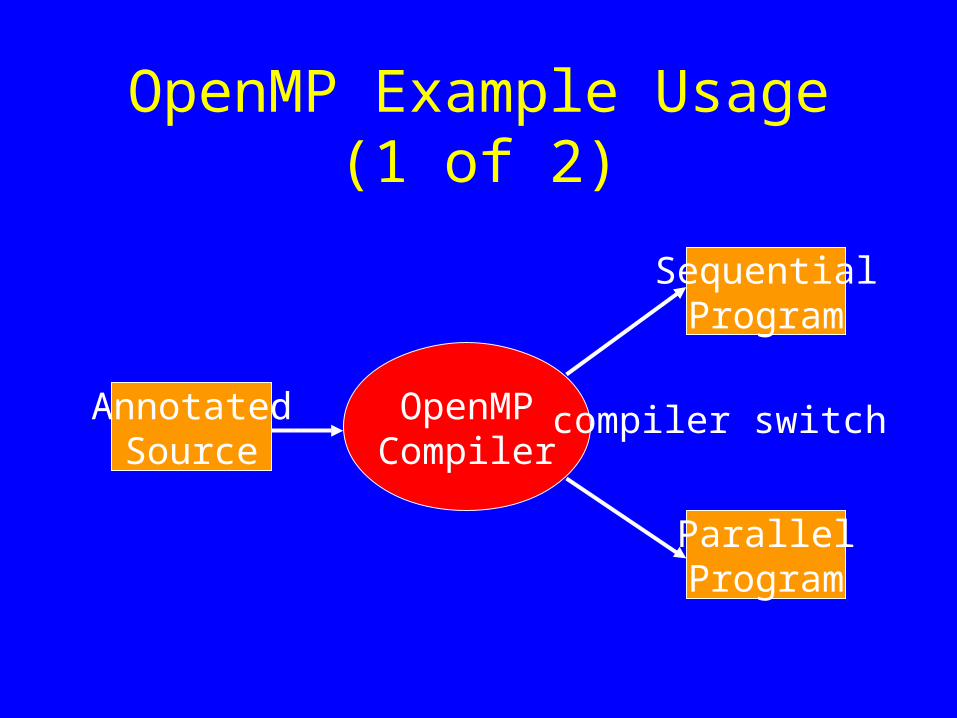
OpenMP Example Usage (1 of 2)
OpenMPCompiler
AnnotatedSource
SequentialProgram
ParallelProgram
compiler switch

OpenMP Example Usage (2 of 2)
• If you give sequential switch,– comments and pragmas are ignored.
• If you give parallel switch,– comments and/or pragmas are read, and– cause translation into parallel program.
• Ideally, one source for both sequential and parallel program (big maintenance plus).

OpenMP Directives
• Parallelization directives:– parallel region– parallel for
• Data environment directives:– shared, private, threadprivate, reduction, etc.
• Synchronization directives:– barrier, critical

General Rules about Directives
• They always apply to the next statement, which must be a structured block.
• Examples– #pragma omp …
statement– #pragma omp …
{ statement1; statement2; statement3; }

OpenMP Parallel Region
#pragma omp parallel
• A number of threads are spawned at entry.
• Each thread executes the same code.
• Each thread waits at the end.
• Very similar to a number of create/join’s with the same function in Pthreads.

Getting Threads to do Different Things
• Through explicit thread identification (as in Pthreads).
• Through work-sharing directives.

Thread Identification
int omp_get_thread_num()
int omp_get_num_threads()
• Gets the thread id.
• Gets the total number of threads.

Example
#pragma omp parallel
{
if( !omp_get_thread_num() )
master();
else
slave();
}

Work Sharing Directives
• Always occur within a parallel region directive.
• Two principal ones are– parallel for– parallel section

OpenMP Parallel For
#pragma omp parallel
#pragma omp for
for( … ) { … }
• Each thread executes a subset of the iterations.
• All threads wait at the end of the parallel for.

Multiple Work Sharing Directives
• May occur within a single parallel region#pragma omp parallel{#pragma omp forfor( ; ; ) { … }#pragma omp forfor( ; ; ) { … }}
• All threads wait at the end of the first for.

The NoWait Qualifier
#pragma omp parallel{#pragma omp for nowaitfor( ; ; ) { … }#pragma omp forfor( ; ; ) { … }}
• Threads proceed to second for w/o waiting.

Parallel Sections Directive
#pragma omp parallel{#pragma omp sections
{ { … }
#pragma omp section this is a delimiter{ … } #pragma omp section { … }…}
}

A Useful Shorthand
#pragma omp parallel
#pragma omp for
for ( ; ; ) { … }
is equivalent to#pragma omp parallel for
for ( ; ; ) { … }
(Same for parallel sections)

Note the Difference between ...
#pragma omp parallel
{
#pragma omp for
for( ; ; ) { … }
f();
#pragma omp for
for( ; ; ) { … }
}

… and ...
#pragma omp parallel for
for( ; ; ) { … }
f();
#pragma omp parallel for
for( ; ; ) { … }

Sequential Matrix Multiply
for( i=0; i<n; i++ )
for( j=0; j<n; j++ ) {
c[i][j] = 0.0;
for( k=0; k<n; k++ )
c[i][j] += a[i][k]*b[k][j];
}

OpenMP Matrix Multiply
#pragma omp parallel for
for( i=0; i<n; i++ )
for( j=0; j<n; j++ ) {
c[i][j] = 0.0;
for( k=0; k<n; k++ )
c[i][j] += a[i][k]*b[k][j];
}

Sequential SOR
for some number of timesteps/iterations {for (i=0; i<n; i++ )
for( j=1, j<n, j++ )temp[i][j] = 0.25 *
( grid[i-1][j] + grid[i+1][j]
grid[i][j-1] + grid[i][j+1] );for( i=0; i<n; i++ )
for( j=1; j<n; j++ )grid[i][j] = temp[i][j];
}

OpenMP SOR
for some number of timesteps/iterations {#pragma omp parallel for
for (i=0; i<n; i++ )for( j=0, j<n, j++ )
temp[i][j] = 0.25 *( grid[i-1][j] + grid[i+1][j]grid[i][j-1] + grid[i][j+1] );
#pragma omp parallel forfor( i=0; i<n; i++ )
for( j=0; j<n; j++ )grid[i][j] = temp[i][j];
}

Equivalent OpenMP SOR
for some number of timesteps/iterations {#pragma omp parallel
{ #pragma omp for
for (i=0; i<n; i++ )for( j=0, j<n, j++ )
temp[i][j] = 0.25 *( grid[i-1][j] + grid[i+1][j]grid[i][j-1] + grid[i][j+1] );
#pragma omp forfor( i=0; i<n; i++ )
for( j=0; j<n; j++ )grid[i][j] = temp[i][j]
}}

Some Advanced Features
• Conditional parallelism.
• Scheduling options.
(More can be found in the specification)

Conditional Parallelism: Issue
• Oftentimes, parallelism is only useful if the problem size is sufficiently big.
• For smaller sizes, overhead of parallelization exceeds benefit.

Conditional Parallelism: Specification
#pragma omp parallel if( expression )
#pragma omp for if( expression )
#pragma omp parallel for if( expression )
• Execute in parallel if expression is true, otherwise execute sequentially.

Conditional Parallelism: Example
for( i=0; i<n; i++ )
#pragma omp parallel for if( n-i > 100 )
for( j=i+1; j<n; j++ )
for( k=i+1; k<n; k++ )
a[j][k] = a[j][k] - a[i][k]*a[i][j] / a[j][j]

Scheduling of Iterations: Issue
• Scheduling: assigning iterations to a thread.
• So far, we have assumed the default which is block scheduling.
• OpenMP allows other scheduling strategies as well, for instance cyclic, gss (guided self-scheduling), etc.

Scheduling of Iterations: Specification
#pragma omp parallel for schedule(<sched>)
• <sched> can be one of– block (default)– cyclic – gss

Example
• Multiplication of two matrices C = A x B, where the A matrix is upper-triangular (all elements below diagonal are 0).
0
A

Sequential Matrix Multiply Becomes
for( i=0; i<n; i++ )
for( j=0; j<n; j++ ) {
c[i][j] = 0.0;
for( k=i; k<n; k++ )
c[i][j] += a[i][k]*b[k][j];
}
Load imbalance with block distribution.

OpenMP Matrix Multiply
#pragma omp parallel for schedule( cyclic )
for( i=0; i<n; i++ )
for( j=0; j<n; j++ ) {
c[i][j] = 0.0;
for( k=i; k<n; k++ )
c[i][j] += a[i][k]*b[k][j];
}

Data Environment Directives (1 of 2)
• All variables are by default shared.
• One exception: the loop variable of a parallel for is private.
• By using data directives, some variables can be made private or given other special characteristics.

Reminder: Matrix Multiply
#pragma omp parallel for
for( i=0; i<n; i++ )
for( j=0; j<n; j++ ) {
c[i][j] = 0.0;
for( k=0; k<n; k++ )
c[i][j] += a[i][k]*b[k][j];
}
• a, b, c are shared• i, j, k are private

Data Environment Directives (2 of 2)
• Private
• Threadprivate
• Reduction

Private Variables
#pragma omp parallel for private( list )
• Makes a private copy for each thread for each variable in the list.
• This and all further examples are with parallel for, but same applies to other region and work-sharing directives.

Private Variables: Example (1 of 2)
for( i=0; i<n; i++ ) {tmp = a[i];a[i] = b[i];b[i] = tmp;
}
• Swaps the values in a and b.
• Loop-carried dependence on tmp.
• Easily fixed by privatizing tmp.

Private Variables: Example (2 of 2)
#pragma omp parallel for private( tmp )for( i=0; i<n; i++ ) {
tmp = a[i];a[i] = b[i];b[i] = tmp;
}
• Removes dependence on tmp.• Would be more difficult to do in Pthreads.

Private Variables: Alternative 1
for( i=0; i<n; i++ ) {tmp[i] = a[i];a[i] = b[i];b[i] = tmp[i];
}
• Requires sequential program change.
• Wasteful in space, O(n) vs. O(p).

Private Variables: Alternative 2
f() {
int tmp; /* local allocation on stack */for( i=from; i<to; i++ ) {
tmp = a[i];a[i] = b[i];b[i] = tmp;
}}

Threadprivate
• Private variables are private on a parallel region basis.
• Threadprivate variables are global variables that are private throughout the execution of the program.

Threadprivate
#pragma omp threadprivate( list )
Example: #pragma omp threadprivate( x)
• Requires program change in Pthreads.
• Requires an array of size p.
• Access as x[pthread_self()].
• Costly if accessed frequently.
• Not cheap in OpenMP either.

Reduction Variables
#pragma omp parallel for reduction( op:list )
• op is one of +, *, -, &, ^, |, &&, or ||
• The variables in list must be used with this operator in the loop.
• The variables are automatically initialized to sensible values.

Reduction Variables: Example
#pragma omp parallel for reduction( +:sum )
for( i=0; i<n; i++ )
sum += a[i];
• Sum is automatically initialized to zero.

SOR Sequential Code with Convergence
for( ; diff > delta; ) {for (i=0; i<n; i++ )
for( j=0; j<n, j++ ) { … }diff = 0;for( i=0; i<n; i++ )
for( j=0; j<n; j++ ) { diff = max(diff, fabs(grid[i][j] -
temp[i][j])); grid[i][j] = temp[i][j];
}}

SOR Sequential Code with Convergence
for( ; diff > delta; ) {#pragma omp parallel forfor (i=0; i<n; i++ )
for( j=0; j<n, j++ ) { … }diff = 0;#pragma omp parallel for reduction( max: diff )for( i=0; i<n; i++ )
for( j=0; j<n; j++ ) { diff = max(diff, fabs(grid[i][j] - temp[i]
[j])); grid[i][j] = temp[i][j];
}}

SOR Sequential Code with Convergence
for( ; diff > delta; ) {#pragma omp parallel forfor (i=0; i<n; i++ )
for( j=0; j<n, j++ ) { … }diff = 0;#pragma omp parallel for reduction( max: diff )for( i=0; i<n; i++ )
for( j=0; j<n; j++ ) { diff = max(diff, fabs(grid[i][j] - temp[i][j])); grid[i][j] = temp[i][j];
}}
Bummer: no reduction operator for max or min.

Synchronization Primitives
• Critical#pragma omp critical name
Implements critical sections by name.
Similar to Pthreads mutex locks (name ~ lock).
• Barrier#pragma omp critical barrier
Implements global barrier.

OpenMP SOR with Convergence (1 of 2)
#pragma omp parallel private( mydiff )for( ; diff > delta; ) {
#pragma omp for nowaitfor( i=from; i<to; i++ )
for( j=0; j<n, j++ ) { … }diff = 0.0;mydiff = 0.0;#pragma omp barrier...

OpenMP SOR with Convergence (2 of 2)
...#pragma omp for nowaitfor( i=from; i<to; i++ ) for( j=0; j<n; j++ ) {
mydiff=max(mydiff,fabs(grid[i][j]-temp[i][j]);
grid[i][j] = temp[i][j]; }#pragma critical
diff = max( diff, mydiff );#pragma barrier
}

Synchronization Primitives
• Big bummer: no condition variables.
• Result: must busy wait for condition synchronization.
• Clumsy.
• Very inefficient on some architectures.

PIPE: Sequential Program
for( i=0; i<num_pic, read(in_pic); i++ ) {
int_pic_1 = trans1( in_pic );
int_pic_2 = trans2( int_pic_1);
int_pic_3 = trans3( int_pic_2);
out_pic = trans4( int_pic_3);
}

Sequential vs. Parallel Execution
• Sequential
• Parallel
(Color -- picture; horizontal line -- processor).

PIPE: Parallel Program
P0: for( i=0; i<num_pics, read(in_pic); i++ ) {
int_pic_1[i] = trans1( in_pic );signal(event_1_2[i]);
} P1: for( i=0; i<num_pics; i++ ) {
wait( event_1_2[i] );int_pic_2[i] = trans2( int_pic_1[i] );signal(event_2_3[i]);
}

PIPE: Main Program
#pragma omp parallel sections{ #pragma omp section stage1(); #pragma omp section stage2(); #pragma omp section stage3(); #pragma omp section stage4();}

PIPE: Stage 1
void stage1(){
num1 = 0;for( i=0; i<num_pics, read(in_pic); i++ ) { int_pic_1[i] = trans1( in_pic );
#pragma omp critical 1 num1++;
}}

PIPE: Stage 2
void stage2 (){
for( i=0; i<num_pic; i++ ) {do {
#pragma omp critical 1 cond = (num1 <= i);
} while (cond);int_pic_2[i] = trans2(int_pic_1[i]);
#pragma omp critical 2 num2++;
}}

OpenMP PIPE
• Note the need to exit critical during wait.
• Otherwise no access by other thread.
• Never busy-wait inside critical!

Example 1
for( i=0; i<n; i++ ) {
tmp = a[i];
a[i] = b[i];
b[i] = tmp;
}
• Dependence on tmp.

Scalar Privatization
#pragma omp parallel for private(tmp)
for( i=0; i<n; i++ ) {
tmp = a[i];
a[i] = b[i];
b[i] = tmp;
}
• Dependence on tmp is removed.

Example 2
for( i=0, sum=0; i<n; i++ )
sum += a[i];
• Dependence on sum.

Reduction
#pragma omp parallel for reduction(+,sum)
for( i=0, sum=0; i<n; i++ )
sum += a[i];
• Dependence on sum is removed.

Example 3
for( i=0, index=0; i<n; i++ ) {index += i;a[i] = b[index];
}
• Dependence on index.• Induction variable: can be computed from
loop variable.

Induction Variable Elimination
#pragma omp parallel for
for( i=0, index=0; i<n; i++ ) {
a[i] = b[i*(i+1)/2];
}
• Dependence removed by computing the induction variable.

Example 4
for( i=0, index=0; i<n; i++ ) {
index += f(i);
b[i] = g(a[index]);
}
• Dependence on induction variable index, but no closed formula for its value.

Loop Splitting
for( i=0; i<n; i++ ) {index[i] += f(i);
}#pragma omp parallel forfor( i=0; i<n; i++ ) {
b[i] = g(a[index[i]]);}
• Loop splitting has removed dependence.

Example 5
for( k=0; k<n; k++ ) for( i=0; i<n; i++ )
for( j=0; j<n; j++ )a[i][j] += b[i][k] + c[k][j];
• Dependence on a[i][j] prevents k-loop parallelization.
• No dependencies carried by i- and j-loops.

Example 5 Parallelization
for( k=0; k<n; k++ )
#pragma omp parallel for
for( i=0; i<n; i++ )
for( j=0; j<n; j++ )
a[i][j] += b[i][k] + c[k][j];
• We can do better by reordering the loops.

Loop Reordering
#pragma omp parallel for
for( i=0; i<n; i++ )
for( j=0; j<n; j++ )
for( k=0; k<n; k++ )
a[i][j] += b[i][k] + c[k][j];
• Larger parallel pieces of work.

Example 6
#pragma omp parallel forfor(i=0; i<n; i++ )
a[i] = b[i];#pragma omp parallel forfor( i=0; i<n; i++ )
c[i] = b[i]^2;
• Make two parallel loops into one.

Loop Fusion
#pragma omp parallel for
for(i=0; i<n; i++ ) {
a[i] = b[i];
c[i] = b[i]^2;
}
• Reduces loop startup overhead.

Example 7: While Loops
while( *a) {
process(a);
a++;
}
• The number of loop iterations is unknown.

Special Case of Loop Splitting
for( count=0, p=a; p!=NULL; count++, p++ );
#pragma omp parallel for
for( i=0; i<count; i++ )
process( a[i] );
• Count the number of loop iterations.
• Then parallelize the loop.

Example 8: Linked Lists
for(p=head; !p; p=p->next )
/* Assume process does not affect linked list */
process(p);
• Dependence on p

Another Special Case of Loop Splitting
for( p=head, count=0; p!=NULL;
p=p->next, count++);
count[i] = f(count, omp_get_numthreads());
start[0] = head;
for( i=0; i< omp_get_numthreads(); i++ ) {
for( p=start[i], cnt=0; cnt<count[i]; p=p->next);
start[i+1] = p->next;
}

Another Special Case of Loop Splitting
#pragma omp parallel sections
for( i=0; i< omp_get_numthreads(); i++ ) #pragma omp section
for(p=start[i]; p!=start[i+1]; p=p->next)
process(p);

Example 9
for( i=0, wrap=n; i<n; i++ ) {
b[i] = a[i] + a[wrap];
wrap = i;
}
• Dependence on wrap.
• Only first iteration causes dependence.

Loop Peeling
b[0] = a[0] + a[n];
#pragma omp parallel for
for( i=1; i<n; i++ ) {
b[i] = a[i] + a[i-1];
}

Example 10
for( i=0; i<n; i++ )
a[i+m] = a[i] + b[i];
• Dependence if m<n.

Another Case of Loop Peeling
if(m>n) {#pragma omp parallel forfor( i=0; i<n; i++ )
a[i+m] = a[i] + b[i];}else {… cannot be parallelized
}

Summary
• Reorganize code such that– dependences are removed or reduced– large pieces of parallel work emerge– loop bounds become known – …
• Code can become messy … there is a point of diminishing returns.