Embed Size (px)
Citation preview

E-Resources Management for
Academic Research
Dr. I.R.N. Goudar
Visiting Professor and Library Adviser University of Mysore, Mysore
Formerly Scientist ‘G’ and Head, ICAST, NAL, Bangalore [email protected]
9th Dr. TB Rajashekar Memorial Seminar on
Digital Information Services in Academic and R&D Information Centers
Indian Institute of Science, Bangalore November 23, 2013


How user may search… for a single title or article
• Online catalogue,
• Web list (A to Z List),
• Aggregated databases,
• Publisher's Platform,
• Internet search engine,
• Meta-search engine,
• IR /IR harvesters,
• E-resource gateway/Portals
• Subject directories/gateways,
• Directories indexing articles,
• Institutional/Departmental/Personal Web sites

E-Resources: Issues Complex - to describe, fund, acquire license and
support
• Budget issues driving shift to e-only journal access.
The number of licensed e-resources acquired by
libraries is growing geometrically.
So is the case with open access e-resources, with much more complexities
- Majority of OA E-resources are from smaller,
individual, or governmental publishers
- No platform of their own nor indexed by well-
known I and A services
• ERMs try to give solutions for such problems.

ERM Functions (Like ILMS)
Selection and evaluation • Acquisition and invoicing Access provision • Configuration and set up Discovery / Public access • Licensing information Access management • Title/Publisher changes Usage monitoring • Renewals • Problem resolution • Contact Management • Workflow management

Discovery Tools
Traditional Discovery Model of Libraries
FULL-TEXT
• Library Collection & ILL Services
METADATA
• OPAC
• Abstracting & Indexing (A&I) Services
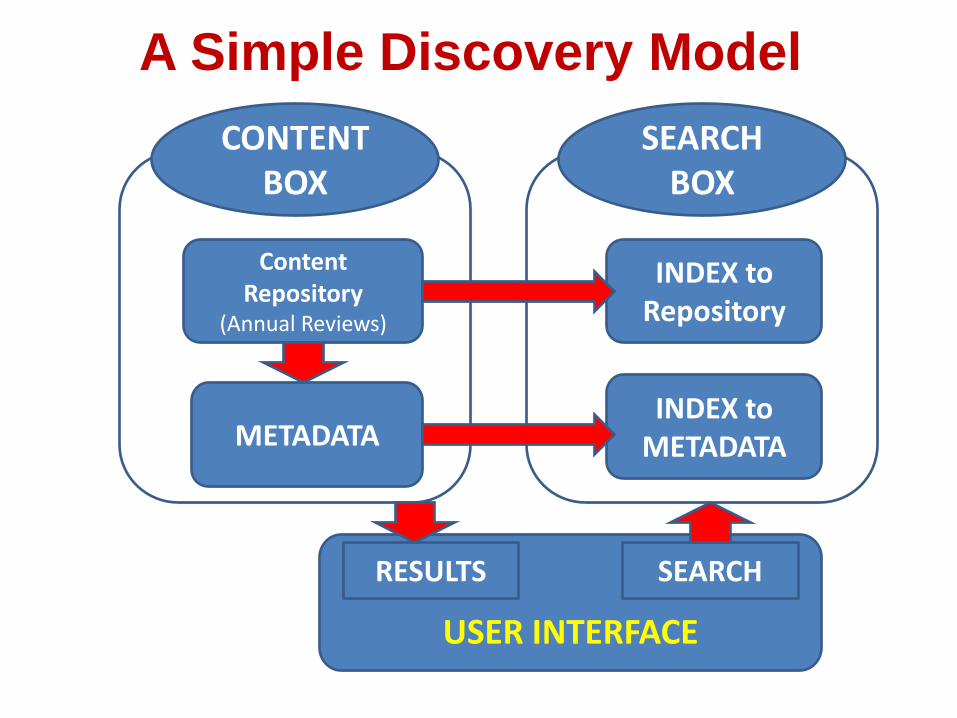
Content Repository
(Annual Reviews)
CONTENT BOX
METADATA
SEARCH BOX
INDEX to Repository
INDEX to METADATA
USER INTERFACE
SEARCH RESULTS
A Simple Discovery Model
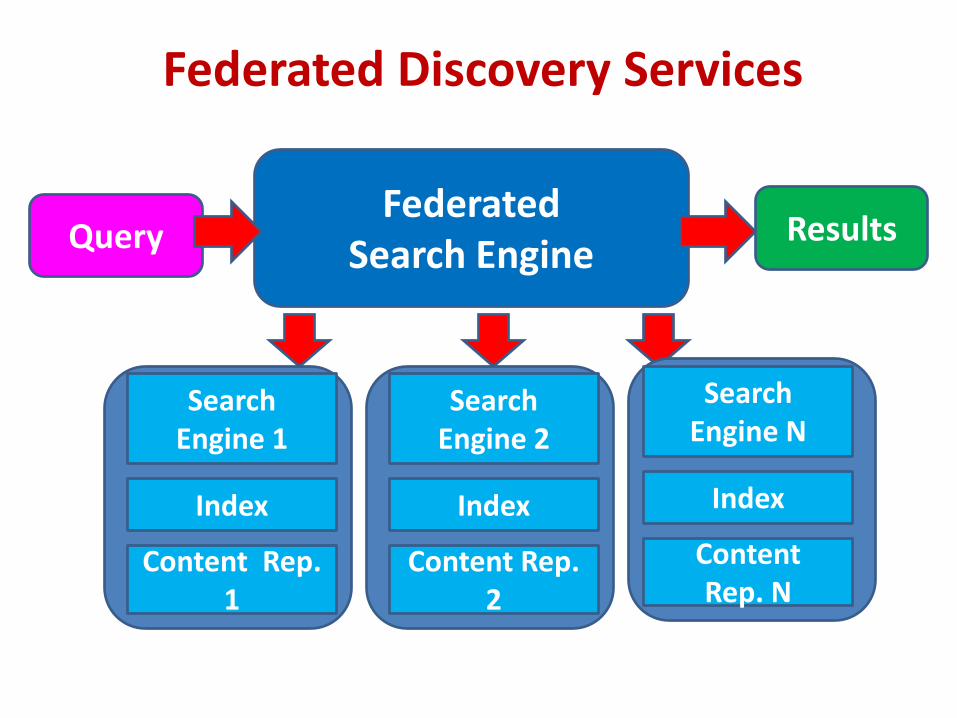
Federated Discovery Services
Federated Search Engine Query Results
Search Engine 1
Index
Content Rep. 1
Search Engine 2
Index
Content Rep. 2
Search Engine N
Index
Content Rep. N
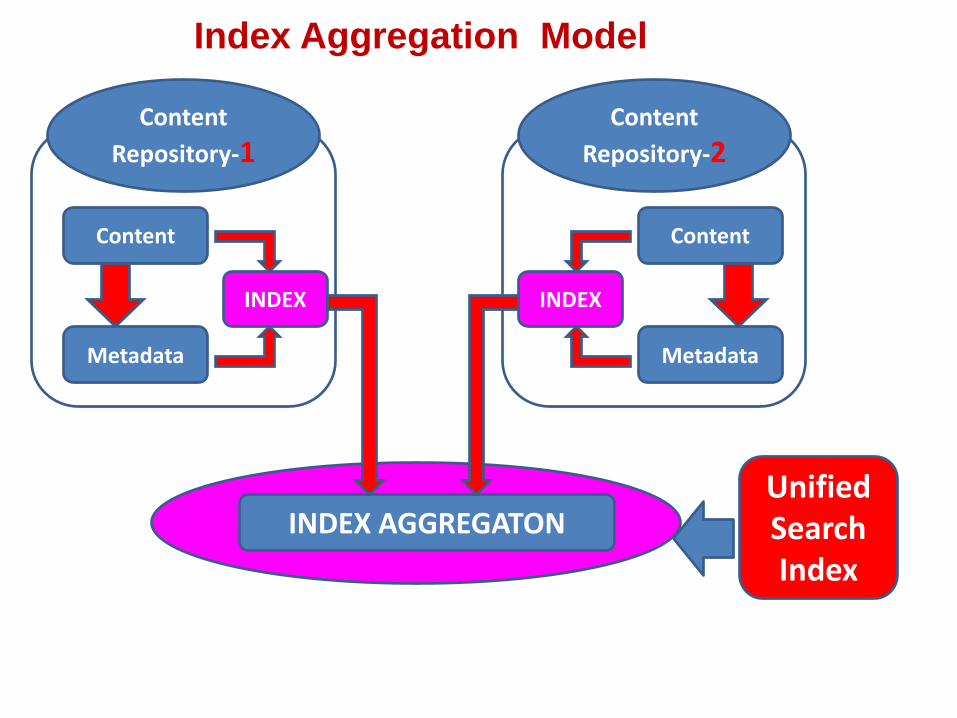
Content
Content
Repository-1
Metadata
Index Aggregation Model
INDEX
Content
Repository-2
Content
Metadata
INDEX AGGREGATON
INDEX
Unified Search Index
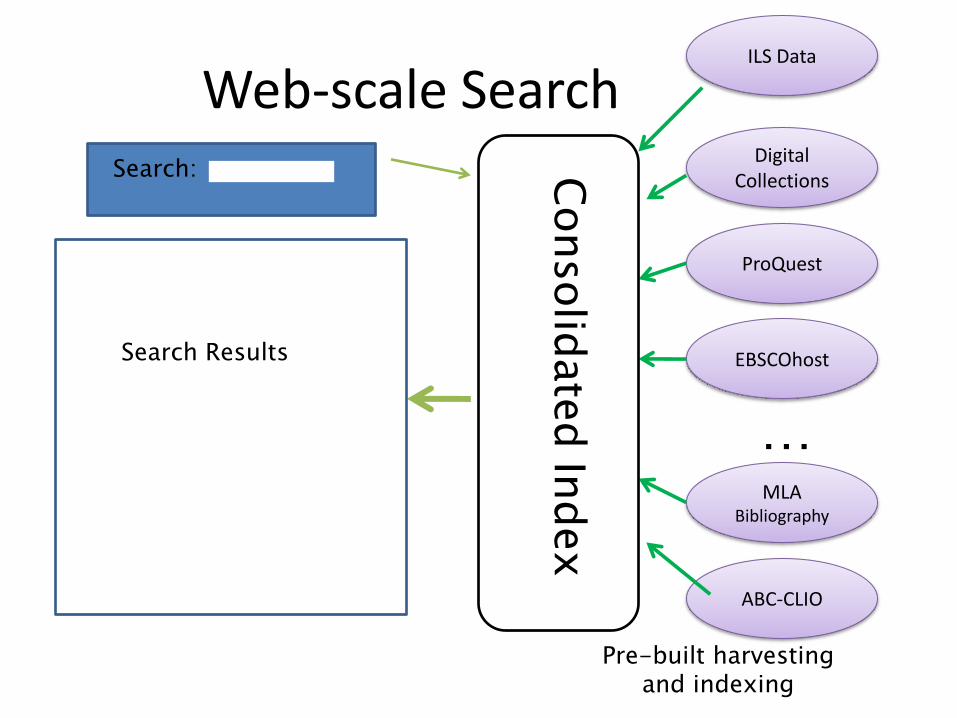
Web-scale Search Search:
Digital Collections
ProQuest
EBSCOhost
… MLA
Bibliography
ABC-CLIO
Search Results
Pre-built harvesting and indexing
Consolid
ate
d In
dex
ILS Data
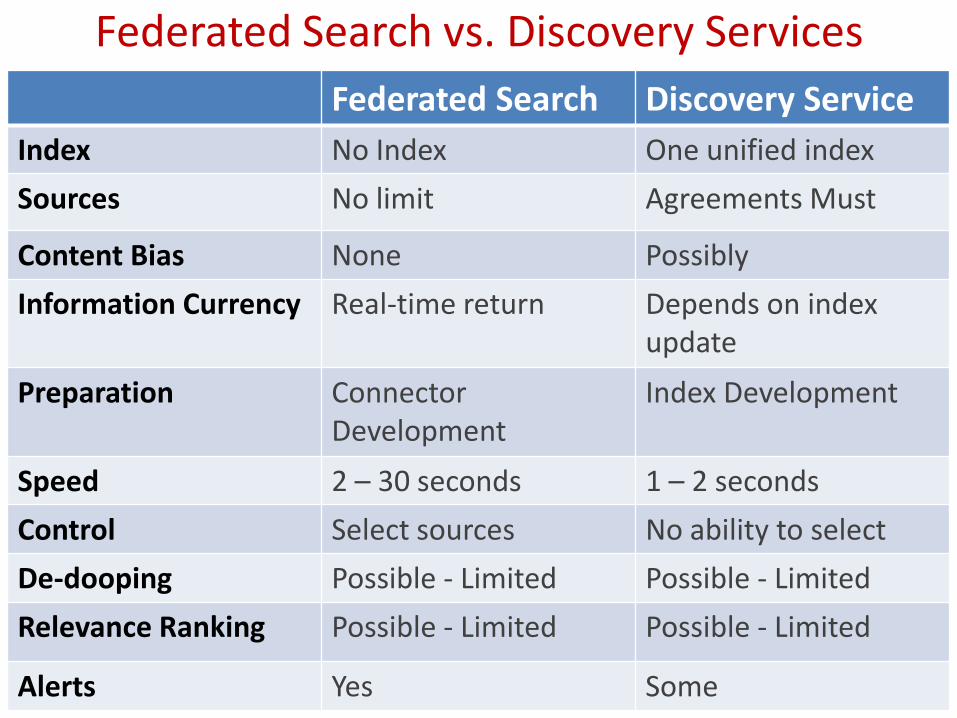
Federated Search vs. Discovery Services
Federated Search Discovery Service
Index No Index One unified index
Sources No limit Agreements Must
Content Bias None Possibly
Information Currency Real-time return Depends on index update
Preparation Connector Development
Index Development
Speed 2 – 30 seconds 1 – 2 seconds
Control Select sources No ability to select
De-dooping Possible - Limited Possible - Limited
Relevance Ranking Possible - Limited Possible - Limited
Alerts Yes Some

Ideal Discovery Model Combination of Aggregation and federation
1. Create Content Clusters through Aggregation
Cluster Examples could be: Journals-J-gate,
DOAJ, IR Harvesters like OAIster & BASE,
Specific IR Harvesters of Theses, Tech Reports,
Patents, etc
2. Federate the Aggregated Content Clusters

Open Access Statistics OA Registry/Harvester Statistics Source World-IRs Indian-IRs World-Articles
DOAR 2373 62
ROAR 3479 98
BASE 2,682 58 50 M
Journal Statistics DOAJ Total JL Article Level JL Articles Countries India 9938 5137 1171532 120 647
J-Gate+ World India
Total 35,000 2800
OA 15,500 1800
OA Scholarly 10,300 1200

Boosting E-Resources Usage:
UoM Experience

E-Resources@UoM • Subscribed/Purchased
E- Journals >6500 (Inflibnet & UoM)
Databases >10 (Inflibnet)
E-Books >18000 (UoM)
- Springer, Wiley, T & F, CRC Press
• Open Access
E-Journals >12,000
E-Books >20 Lacs
E-Theses - (Vidyanidhi, Shodhganga, NDLTD)
Institutional Repositories, Harvesters
E-Newspapers, News Channels
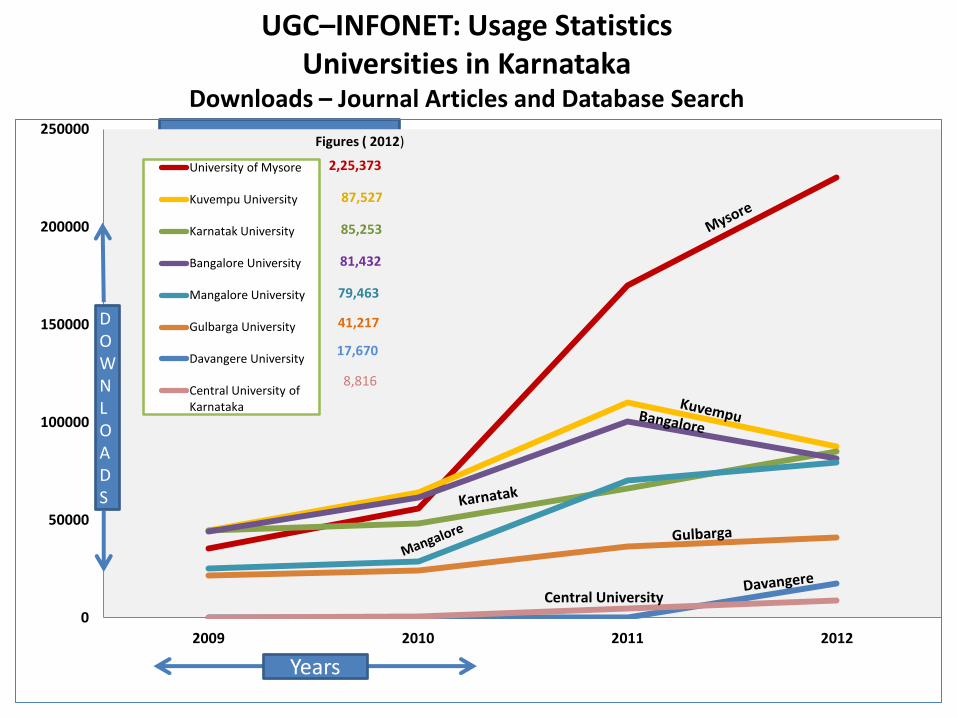
0
50000
100000
150000
200000
250000
2009 2010 2011 2012
University of Mysore
Kuvempu University
Karnatak University
Bangalore University
Mangalore University
Gulbarga University
Davangere University
Central University of Karnataka
2,25,373
87,527
85,253
81,432
79,463
41,217 17,670
8,816
Figures ( 2012)
Central University
DOWNLOADS
Years
UGC–INFONET: Usage Statistics Universities in Karnataka
Downloads – Journal Articles and Database Search
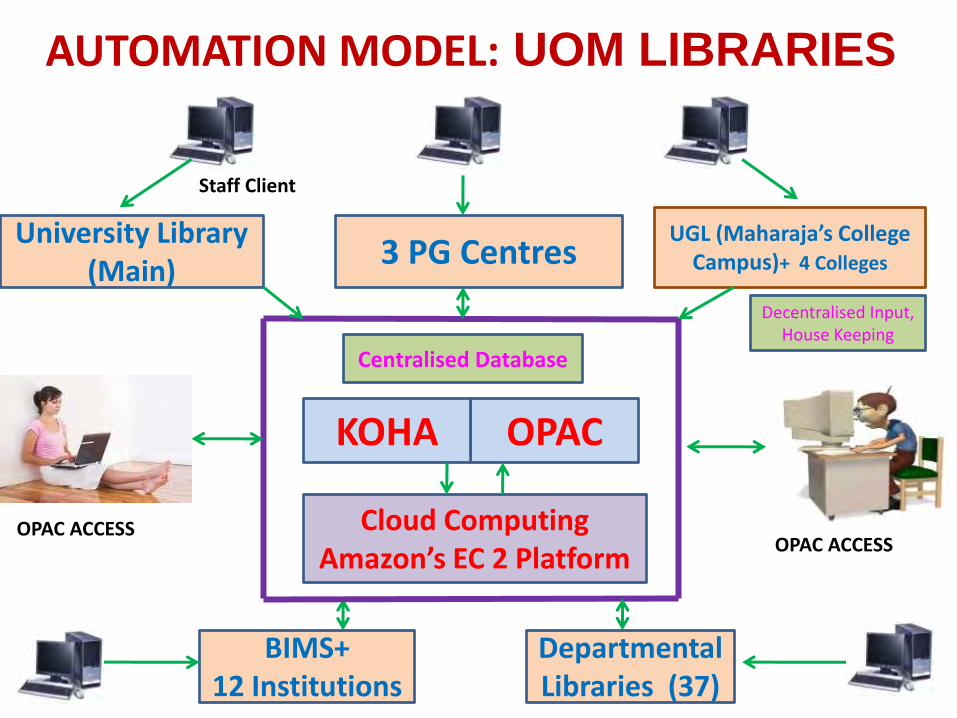
OPAC ACCESS
OPAC
UGL (Maharaja’s College Campus)+ 4 Colleges
BIMS+ 12 Institutions
KOHA
Departmental Libraries (37)
Cloud Computing Amazon’s EC 2 Platform
University Library (Main)
3 PG Centres
OPAC ACCESS
AUTOMATION MODEL: UOM LIBRARIES
Staff Client
Centralised Database
Decentralised Input, House Keeping
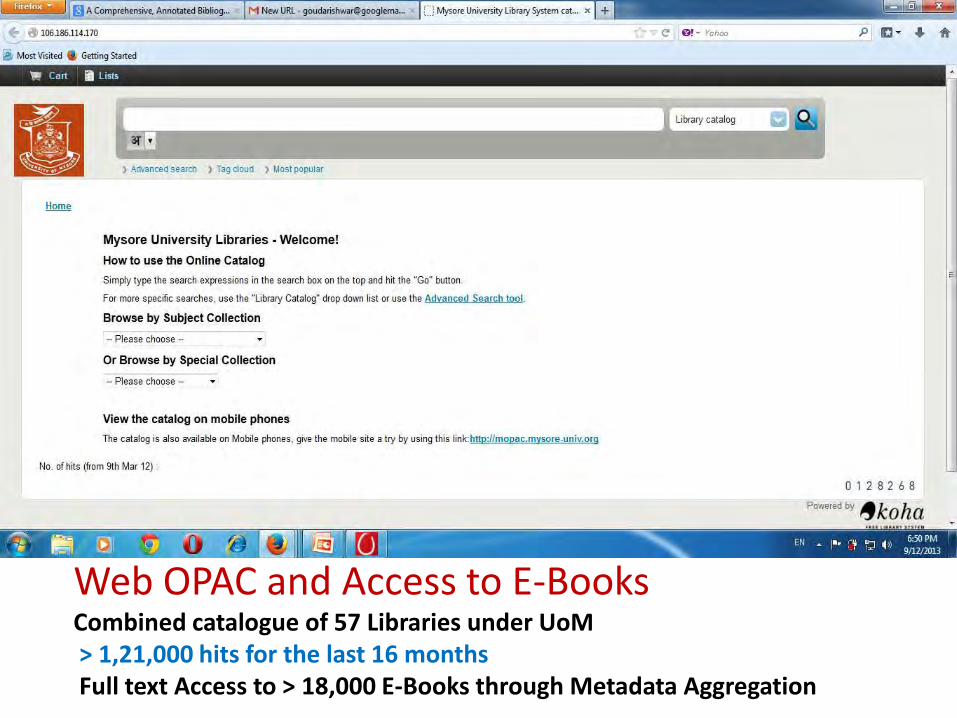
Web OPAC and Access to E-Books Combined catalogue of 57 Libraries under UoM > 1,21,000 hits for the last 16 months Full text Access to > 18,000 E-Books through Metadata Aggregation

UoM ICT Infrastructure • Presently 120 PCs (350 soon) with Internet
browsing facility at DIRC of Library with
600 visitors/day
• Additionally departmental Internet facility
• Campus Wide Wifi Connectivity
• NKN and Private ISP services
• Facility including WiFi extended to all PG Campuses, Constituents Colleges and Institutes

E-RESOURCES FOR VISUALLY CHALLENGED (LRC)
New MUL Website

E-RESOURCES PORTAL
Single point access to thousands of e-journals, e-
books, e-theses
• Campus wide (28,000 Hits since 6 months) and Off-campus access (24000 Hits) to residences, hostels, etc
>6500 subscribed e-journals of >20 publishers and
>12,000 open access e-journals
>18000 e-books of 4 publishers and >20 lacs open access e-books
Access to thousands of e-Theses, Academic Blogs world over
Access to Institutional Repositories of Indian Universities/Institutions and Harvesters
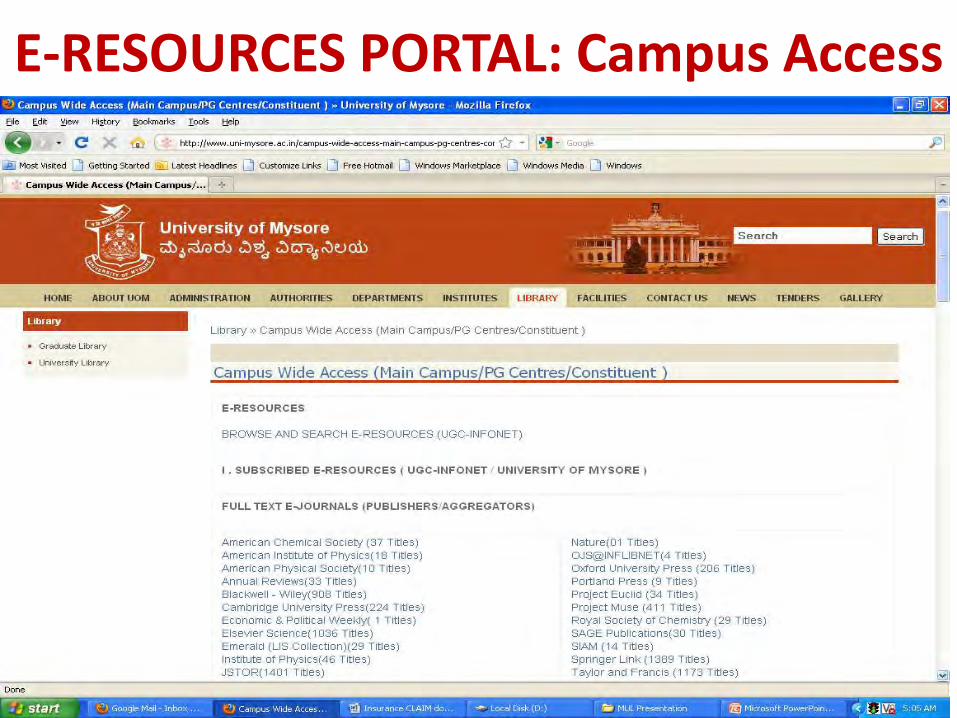
E-RESOURCES PORTAL: Campus Access
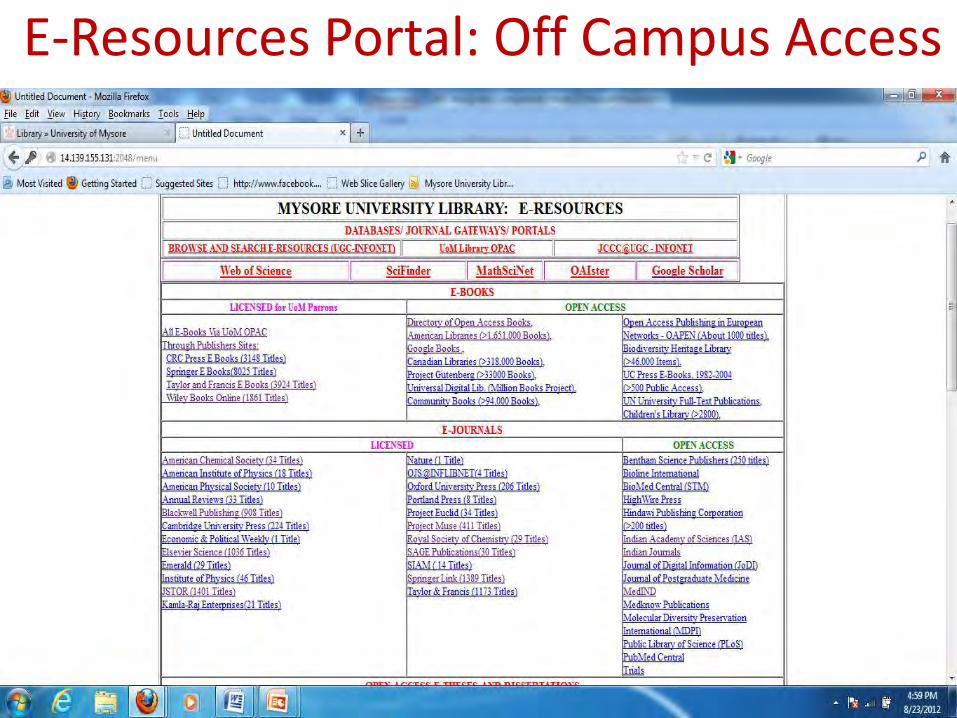
E-Resources Portal: Off Campus Access

Appropriate Tools for Facilitating Usage of E-Resources
August 20, 2012 29
Search Engines
Search engines are popular tools for locating web pages, but they often return thousands of results.
Search of e-resources are
more effective if you know how to talk to the computer systems.
Communicating with
these systems requires knowing certain basic search techniques.
Subject Based Information Gateways Web sites that act as a gateway to other
sites and information resources.
• Rely on human creation of meta data
• Selective catalogues
• Subject experts select, evaluate, describe, classify
• Smaller, subject-focused databases
• Lower recall, higher precision
• High quality information – selected by human subject experts
• Good starting places that lead to other quality resources
E.g. PINAKES (information gateway !)
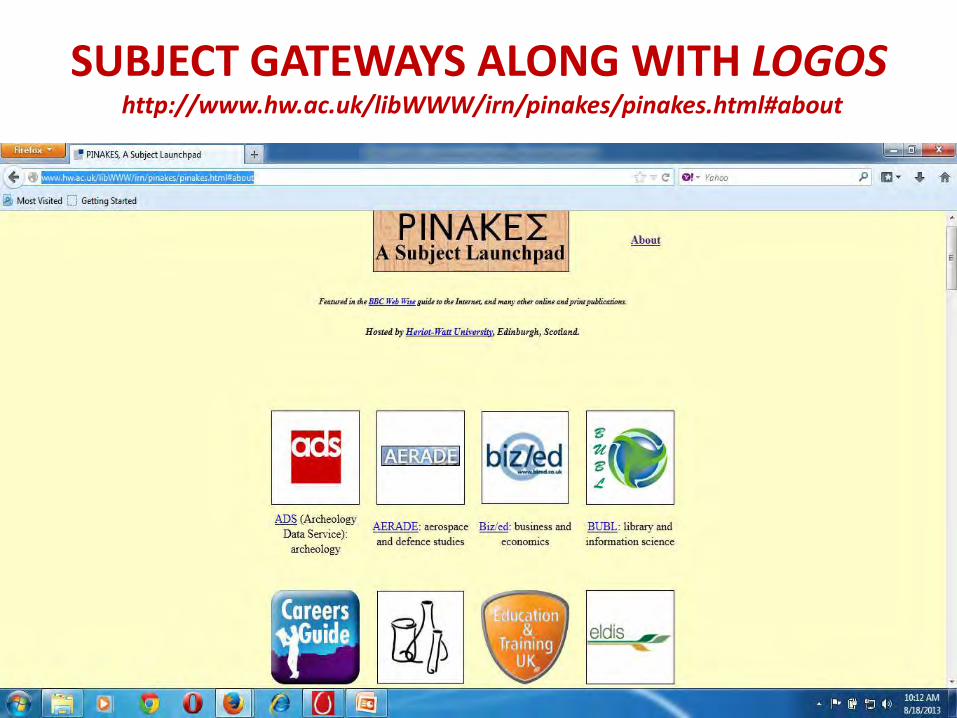
SUBJECT GATEWAYS ALONG WITH LOGOS http://www.hw.ac.uk/libWWW/irn/pinakes/pinakes.html#about
N-List http://nlist.inflibnet.ac.in/eresource.php
BASE http://www.base-search.net/

Google Scholar
Directory of Open Access Books www.doabooks.org/
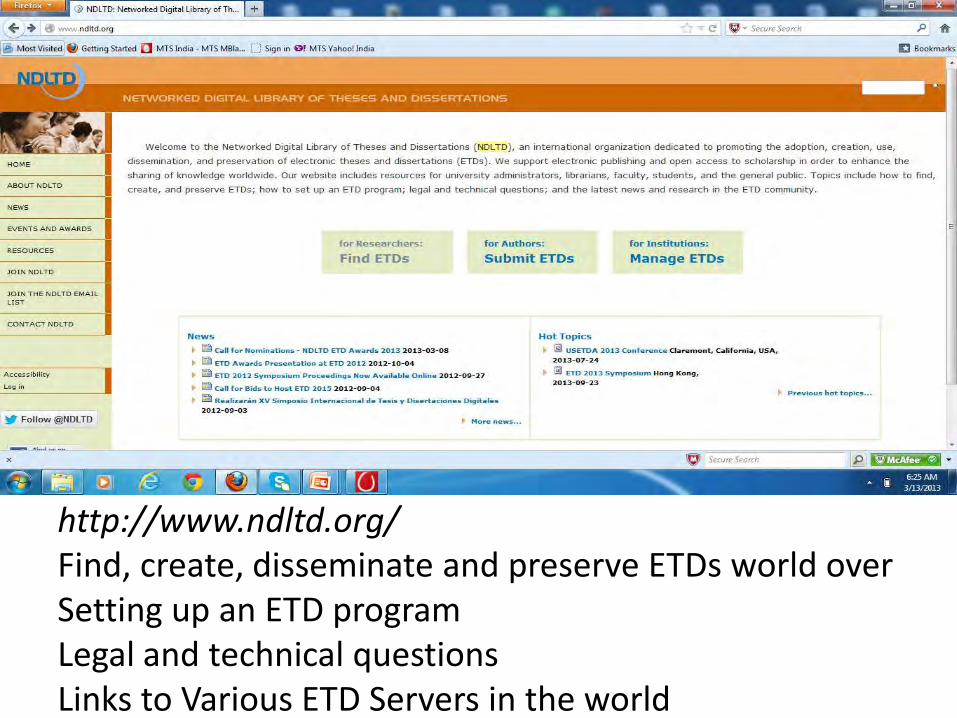
http://www.ndltd.org/ Find, create, disseminate and preserve ETDs world over Setting up an ETD program Legal and technical questions Links to Various ETD Servers in the world
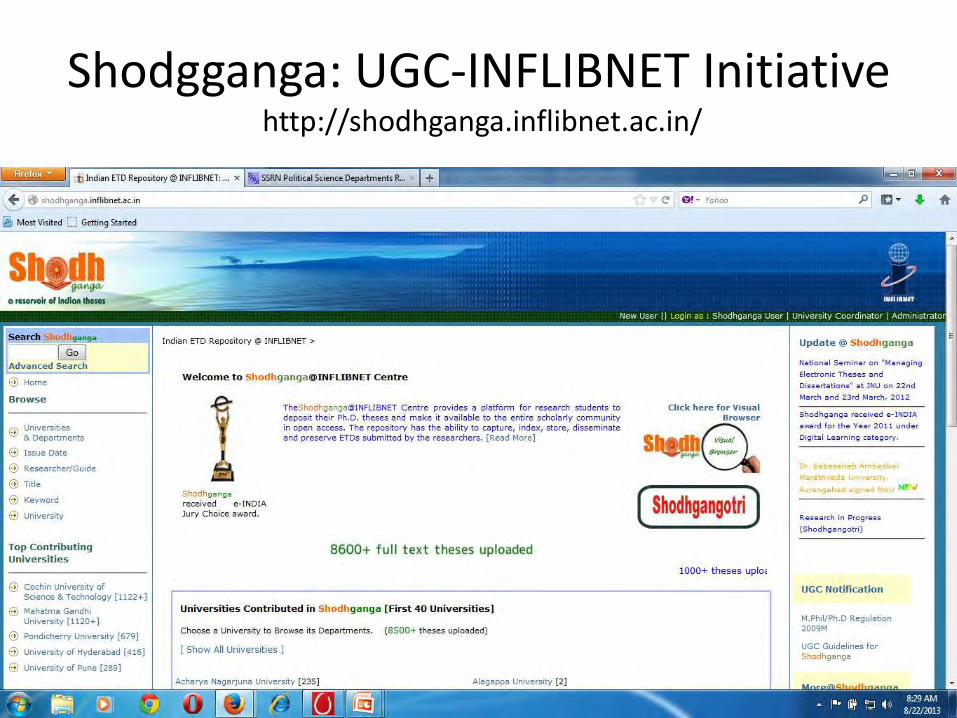
Shodgganga: UGC-INFLIBNET Initiative http://shodhganga.inflibnet.ac.in/
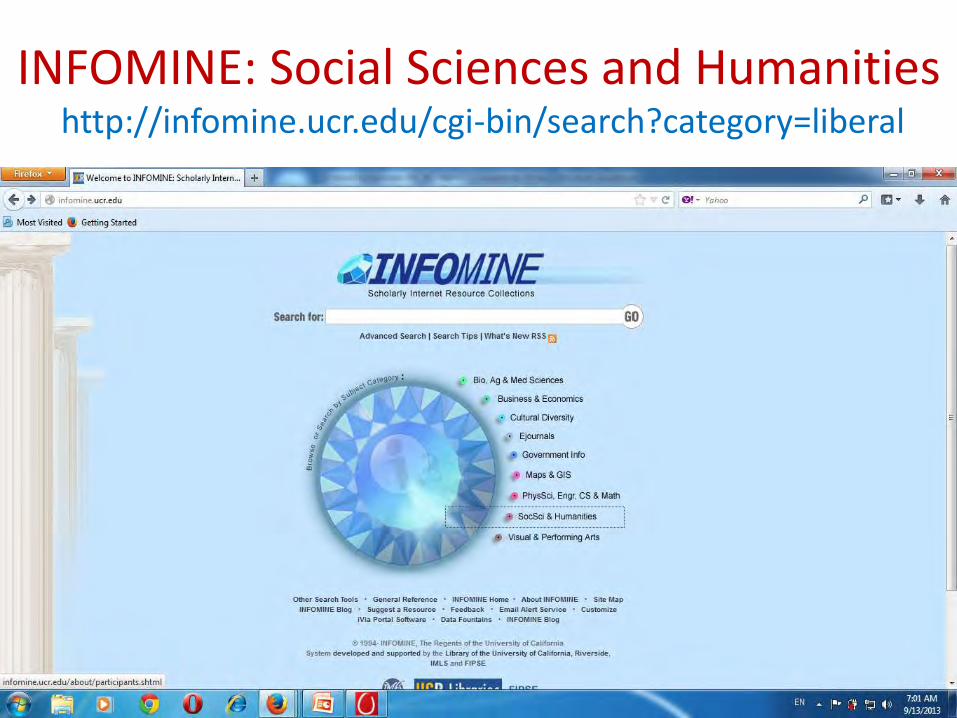
INFOMINE: Social Sciences and Humanities http://infomine.ucr.edu/cgi-bin/search?category=liberal
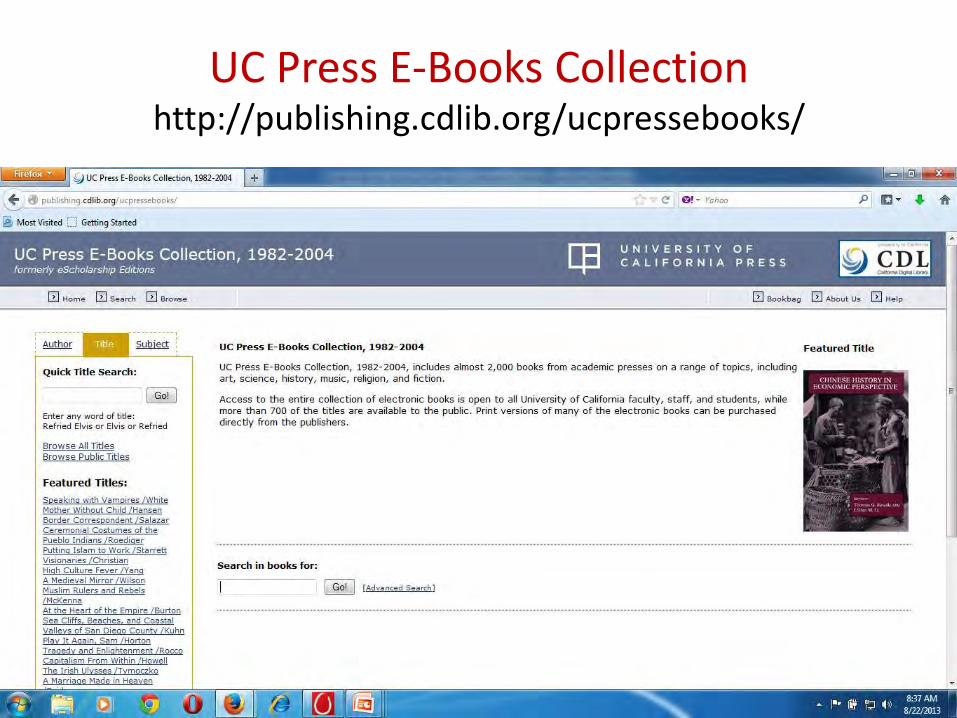
UC Press E-Books Collection http://publishing.cdlib.org/ucpressebooks/
SCIRUS http://www.scirus.com/srsapp/
SOSIG: Social Science Information Gateway
http://www.ariadne.ac.uk/issue2/sosig
eGyanKosh http://www.egyankosh.ac.in/
National Digital Repository of digital learning resources
Sakshat http://www.sakshat.ac.in/
WIKIBOOKS http://en.wikibooks.org/wiki/Main_Page
Internet Public Library (ipl2) http://www.ipl.org/index.html

NSDL http://nsdl.org/
Basically Metadata Harvester for Open Educational Resources
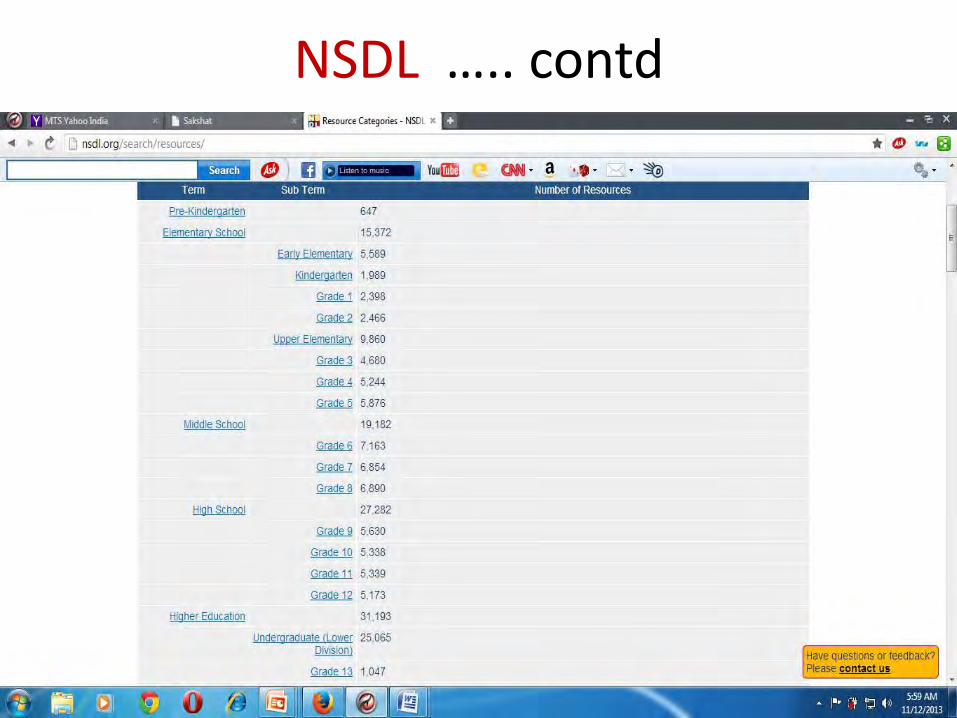
NSDL ….. contd
Open Access Journals Search Engine: Social Science
http://oajse.com/subjects/social_sciences.html
August 20, 2012 62
TechXtra http://www.techxtra.ac.uk/

Demos • DOAJ, DOAB, American Libraries, Eprints@UoM,
Google Scholar,
• Internet Public Library (ipl2): http://www.ipl.org/index.html
• NSDL: http://nsdl.org/
• OA Journals Search Engine: http://oajse.com/index.html






























