Embed Size (px)
Citation preview

Efficient Edit Distance based String Similarity Search usingDeletion Neighborhoods
Shashwat Mishra, Tejas Gandhi, Akhil Arora, Arnab Bhattacharya
Special Interest Group in Data,IIT Kanpur
String Similarity Search/Join Workshop,EDBT 2013
March 21, 2013

Introduction
Main Task
• Given a dictionary of strings, perform fast lookups/joins of similarstrings in the dictionary.
• Use edit distance to quantify the notion of similarity betweenstrings.
• Two tracks:
1. Join: Perform self-join of strings. Given a threshold τ , list all stringpairs in the dictionary with edit-distance ≤ τ .
2. Search: Process range queries as specified in a supplied query file.
2 of 24

Introduction
Main Task
• Given a dictionary of strings, perform fast lookups/joins of similarstrings in the dictionary.
• Use edit distance to quantify the notion of similarity betweenstrings.
• Two tracks:
1. Join: Perform self-join of strings. Given a threshold τ , list all stringpairs in the dictionary with edit-distance ≤ τ .
2. Search: Process range queries as specified in a supplied query file.
2 of 24

Introduction
Main Task
• Given a dictionary of strings, perform fast lookups/joins of similarstrings in the dictionary.
• Use edit distance to quantify the notion of similarity betweenstrings.
• Two tracks:
1. Join: Perform self-join of strings. Given a threshold τ , list all stringpairs in the dictionary with edit-distance ≤ τ .
2. Search: Process range queries as specified in a supplied query file.
2 of 24
Introduction
Search Track: Problem Statement
Given a set of strings, D, and a query tuple containing a query string,q, and an edit distance threshold τ , identify all pairs < q, s > s.t.s ∈ D and EditDistance(q, s) ≤ τ .
• Generate and maintain an index structure for the dictionaryrespecting certain time and memory constraints.
• Use the index structure to process a list of queries (2-tuples). Listall answers in the specified format.
• Evaluation Parameter: Minimize total time taken to process allqueries.
3 of 24

Introduction
Search Track: Problem StatementGiven a set of strings, D, and a query tuple containing a query string,q, and an edit distance threshold τ , identify all pairs < q, s > s.t.s ∈ D and EditDistance(q, s) ≤ τ .
• Generate and maintain an index structure for the dictionaryrespecting certain time and memory constraints.
• Use the index structure to process a list of queries (2-tuples). Listall answers in the specified format.
• Evaluation Parameter: Minimize total time taken to process allqueries.
3 of 24

Introduction
Search Track: Problem StatementGiven a set of strings, D, and a query tuple containing a query string,q, and an edit distance threshold τ , identify all pairs < q, s > s.t.s ∈ D and EditDistance(q, s) ≤ τ .
• Generate and maintain an index structure for the dictionaryrespecting certain time and memory constraints.
• Use the index structure to process a list of queries (2-tuples). Listall answers in the specified format.
• Evaluation Parameter: Minimize total time taken to process allqueries.
3 of 24

Problem Statement: Further Details
• Index construction time not counted towards the score, but mustbe less than 3 hrs.
• Peak memory consumption must be less than 48 GB.
• Score dependent solely on Teffective where
Teffective = tend − tbegin
where tbegin and tend are time instances marking the beginning andthe end of the processing of the query file, respectively.
• Evaluation environment: 8 cores, 64 GB RAM, FC 17.
4 of 24

The Dictionary
• Dictionary 1: Geographicalnames◦ Names of places from
across the globe.◦ Character-set |Σ|=255◦ Mean string length µ=10◦ Dictionary size |D|=400K
• Dictionary 2: Humangenome read data◦ Strings containing human
genomic data.◦ Character-set |Σ|=4◦ Mean string lengthµ=100.3
◦ Dictionary size |D|=750K
0
10
20
30
40
50
5 10 15 20 25 30 35 40 45 50 55
Num
ber
of S
trin
gs (
in 1
03)
String Length (in characters)
Length Distribution
0
50
100
150
200
250
300
350
400
86 88 90 92 94 96 98 100 102 104 106
Num
ber
of
Str
ings (
in 1
03)
String Length (in characters)
Length Distribution
5 of 24

Typical Methodology
• Observation: Modern methods follow a general scheme.
◦ Generate a signature for each string in the dictionary.◦ Maintain an inverted index for generated signatures.◦ Signature must result in a (tight) filtering criteria.◦ Given a query string, q, use the filter and query signature to generate
a candidate list.◦ For each string s ′ in the candidate list, verify if s ′ is answer.
• Signature results in a filtering criteria. ?◦ Signature Function SF (s) maps string s to a signature space.◦ Filtering condition is specific to the choice of the signature function.◦ In general, for string s, query string q, threshold τ , filtering condition
is an inequality.F (s, q, τ, SF ) <> 6= 0
6 of 24

Typical Methodology
• Observation: Modern methods follow a general scheme.◦ Generate a signature for each string in the dictionary.◦ Maintain an inverted index for generated signatures.◦ Signature must result in a (tight) filtering criteria.
◦ Given a query string, q, use the filter and query signature to generatea candidate list.
◦ For each string s ′ in the candidate list, verify if s ′ is answer.
• Signature results in a filtering criteria. ?◦ Signature Function SF (s) maps string s to a signature space.◦ Filtering condition is specific to the choice of the signature function.◦ In general, for string s, query string q, threshold τ , filtering condition
is an inequality.F (s, q, τ, SF ) <> 6= 0
6 of 24

Typical Methodology
• Observation: Modern methods follow a general scheme.◦ Generate a signature for each string in the dictionary.◦ Maintain an inverted index for generated signatures.◦ Signature must result in a (tight) filtering criteria.◦ Given a query string, q, use the filter and query signature to generate
a candidate list.◦ For each string s ′ in the candidate list, verify if s ′ is answer.
• Signature results in a filtering criteria. ?◦ Signature Function SF (s) maps string s to a signature space.◦ Filtering condition is specific to the choice of the signature function.◦ In general, for string s, query string q, threshold τ , filtering condition
is an inequality.F (s, q, τ, SF ) <> 6= 0
6 of 24

Typical Methodology
• Observation: Modern methods follow a general scheme.◦ Generate a signature for each string in the dictionary.◦ Maintain an inverted index for generated signatures.◦ Signature must result in a (tight) filtering criteria.◦ Given a query string, q, use the filter and query signature to generate
a candidate list.◦ For each string s ′ in the candidate list, verify if s ′ is answer.
• Signature results in a filtering criteria. ?◦ Signature Function SF (s) maps string s to a signature space.◦ Filtering condition is specific to the choice of the signature function.◦ In general, for string s, query string q, threshold τ , filtering condition
is an inequality.F (s, q, τ, SF ) <> 6= 0
6 of 24

Signature
• Completeness of solution required → No False Dismissals.
• Filter condition must ensure no false dismissals.
• For query < q, τ >, if ED(s, q) ≤ τ then F (s, q, τ, SF ) must hold.
• Computation of signature should be computationallynon-expensive.
• Filter condition should be tight. Resultant candidate list should besmall.
• Popular signature schemes in literature:◦ Q-Gram◦ Deletion Neighborhood
7 of 24

Signature
• Completeness of solution required → No False Dismissals.
• Filter condition must ensure no false dismissals.
• For query < q, τ >, if ED(s, q) ≤ τ then F (s, q, τ, SF ) must hold.
• Computation of signature should be computationallynon-expensive.
• Filter condition should be tight. Resultant candidate list should besmall.
• Popular signature schemes in literature:◦ Q-Gram◦ Deletion Neighborhood
7 of 24

Signature: Deletion Neighborhood
• Defined w.r.t. a specified edit distance threshold.
• For a string s and edit distance τ , deletion neighborhood signatureof s, SFτ (s) is the set of all strings that can be generated bydeleting at-most τ characters from s.
• Ex. s = ”SIGDATA”◦ SF1(s) ={”IGDATA”,”SGDATA”,”SIDATA”,”SIGATA”,”SIGDTA”,
”SIGDAA”,”SIGDAT”, ”SIGDATA”}• Filtering Condition: -
If ED(s1,s2) ≤ τ , then |SFτ (s1) ∩ SFτ (s2)| > 0
• Intuition: Both strings s1, s2 should be reducible to a commonform after at-most τ deletion operations.
8 of 24

Signature: Deletion Neighborhood
• Defined w.r.t. a specified edit distance threshold.
• For a string s and edit distance τ , deletion neighborhood signatureof s, SFτ (s) is the set of all strings that can be generated bydeleting at-most τ characters from s.
• Ex. s = ”SIGDATA”
◦ SF1(s) ={”IGDATA”,”SGDATA”,”SIDATA”,”SIGATA”,”SIGDTA”,”SIGDAA”,”SIGDAT”, ”SIGDATA”}
• Filtering Condition: -
If ED(s1,s2) ≤ τ , then |SFτ (s1) ∩ SFτ (s2)| > 0
• Intuition: Both strings s1, s2 should be reducible to a commonform after at-most τ deletion operations.
8 of 24

Signature: Deletion Neighborhood
• Defined w.r.t. a specified edit distance threshold.
• For a string s and edit distance τ , deletion neighborhood signatureof s, SFτ (s) is the set of all strings that can be generated bydeleting at-most τ characters from s.
• Ex. s = ”SIGDATA”◦ SF1(s) ={”IGDATA”,”SGDATA”,”SIDATA”,”SIGATA”,”SIGDTA”,
”SIGDAA”,”SIGDAT”, ”SIGDATA”}
• Filtering Condition: -
If ED(s1,s2) ≤ τ , then |SFτ (s1) ∩ SFτ (s2)| > 0
• Intuition: Both strings s1, s2 should be reducible to a commonform after at-most τ deletion operations.
8 of 24

Signature: Deletion Neighborhood
• Defined w.r.t. a specified edit distance threshold.
• For a string s and edit distance τ , deletion neighborhood signatureof s, SFτ (s) is the set of all strings that can be generated bydeleting at-most τ characters from s.
• Ex. s = ”SIGDATA”◦ SF1(s) ={”IGDATA”,”SGDATA”,”SIDATA”,”SIGATA”,”SIGDTA”,
”SIGDAA”,”SIGDAT”, ”SIGDATA”}• Filtering Condition: -
If ED(s1,s2) ≤ τ , then |SFτ (s1) ∩ SFτ (s2)| > 0
• Intuition: Both strings s1, s2 should be reducible to a commonform after at-most τ deletion operations.
8 of 24

Signature: Deletion Neighborhood
• Defined w.r.t. a specified edit distance threshold.
• For a string s and edit distance τ , deletion neighborhood signatureof s, SFτ (s) is the set of all strings that can be generated bydeleting at-most τ characters from s.
• Ex. s = ”SIGDATA”◦ SF1(s) ={”IGDATA”,”SGDATA”,”SIDATA”,”SIGATA”,”SIGDTA”,
”SIGDAA”,”SIGDAT”, ”SIGDATA”}• Filtering Condition: -
If ED(s1,s2) ≤ τ , then |SFτ (s1) ∩ SFτ (s2)| > 0
• Intuition: Both strings s1, s2 should be reducible to a commonform after at-most τ deletion operations.
8 of 24

Signature: Deletion Neighborhood
• Defined w.r.t. a specified edit distance threshold.
• For a string s and edit distance τ , deletion neighborhood signatureof s, SFτ (s) is the set of all strings that can be generated bydeleting at-most τ characters from s.
• Ex. s = ”SIGDATA”◦ SF1(s) ={”IGDATA”,”SGDATA”,”SIDATA”,”SIGATA”,”SIGDTA”,
”SIGDAA”,”SIGDAT”, ”SIGDATA”}• Filtering Condition: -
If ED(s1,s2) ≤ τ , then |SFτ (s1) ∩ SFτ (s2)| > 0
• Intuition: Both strings s1, s2 should be reducible to a commonform after at-most τ deletion operations.
8 of 24

Signature: Q-Gram
• For a string s, Q-Gram signature of s, SF (s) is the set of all stringsthat can be generated by taking q contiguous characters from s.
• Ex. s = ”SIGDATA”, Q = 3◦ SF (s) ={”SIG”,”IGD”,”GDA”,”DAT”,”ATA”}
• Filtering Condition: -
If ED(s1,s2) ≤ τ , then |SF (s1)∩SF (s2)| ≥ max(|s1|, |s2|)+1−(τ+1).Q
• In practice, RHS = |q|+ 1− (τ + 1).Q, where q is the query string.
• For filter to be tight, RHS > 0 → |q| > (τ + 1).Q − 1.◦ Serious limitation ! For Q = 2, τ = 2, only queries with |q| ≥ 6 can
be processed, for τ = 3, |q| ≥ 8.
9 of 24

Signature: Q-Gram
• For a string s, Q-Gram signature of s, SF (s) is the set of all stringsthat can be generated by taking q contiguous characters from s.
• Ex. s = ”SIGDATA”, Q = 3◦ SF (s) ={”SIG”,”IGD”,”GDA”,”DAT”,”ATA”}
• Filtering Condition: -
If ED(s1,s2) ≤ τ , then |SF (s1)∩SF (s2)| ≥ max(|s1|, |s2|)+1−(τ+1).Q
• In practice, RHS = |q|+ 1− (τ + 1).Q, where q is the query string.
• For filter to be tight, RHS > 0 → |q| > (τ + 1).Q − 1.◦ Serious limitation ! For Q = 2, τ = 2, only queries with |q| ≥ 6 can
be processed, for τ = 3, |q| ≥ 8.
9 of 24

Signature: Q-Gram
• For a string s, Q-Gram signature of s, SF (s) is the set of all stringsthat can be generated by taking q contiguous characters from s.
• Ex. s = ”SIGDATA”, Q = 3◦ SF (s) ={”SIG”,”IGD”,”GDA”,”DAT”,”ATA”}
• Filtering Condition: -
If ED(s1,s2) ≤ τ , then |SF (s1)∩SF (s2)| ≥ max(|s1|, |s2|)+1−(τ+1).Q
• In practice, RHS = |q|+ 1− (τ + 1).Q, where q is the query string.
• For filter to be tight, RHS > 0 → |q| > (τ + 1).Q − 1.◦ Serious limitation ! For Q = 2, τ = 2, only queries with |q| ≥ 6 can
be processed, for τ = 3, |q| ≥ 8.
9 of 24

Signature: Q-Gram
• For a string s, Q-Gram signature of s, SF (s) is the set of all stringsthat can be generated by taking q contiguous characters from s.
• Ex. s = ”SIGDATA”, Q = 3◦ SF (s) ={”SIG”,”IGD”,”GDA”,”DAT”,”ATA”}
• Filtering Condition: -
If ED(s1,s2) ≤ τ , then |SF (s1)∩SF (s2)| ≥ max(|s1|, |s2|)+1−(τ+1).Q
• In practice, RHS = |q|+ 1− (τ + 1).Q, where q is the query string.
• For filter to be tight, RHS > 0 → |q| > (τ + 1).Q − 1.◦ Serious limitation ! For Q = 2, τ = 2, only queries with |q| ≥ 6 can
be processed, for τ = 3, |q| ≥ 8.
9 of 24

Signature: Q-Gram
• For a string s, Q-Gram signature of s, SF (s) is the set of all stringsthat can be generated by taking q contiguous characters from s.
• Ex. s = ”SIGDATA”, Q = 3◦ SF (s) ={”SIG”,”IGD”,”GDA”,”DAT”,”ATA”}
• Filtering Condition: -
If ED(s1,s2) ≤ τ , then |SF (s1)∩SF (s2)| ≥ max(|s1|, |s2|)+1−(τ+1).Q
• In practice, RHS = |q|+ 1− (τ + 1).Q, where q is the query string.
• For filter to be tight, RHS > 0 → |q| > (τ + 1).Q − 1.◦ Serious limitation ! For Q = 2, τ = 2, only queries with |q| ≥ 6 can
be processed, for τ = 3, |q| ≥ 8.
9 of 24

Choice of Signature
• Deletion Neighborhood seems to be better than Q-Gram.◦ No restriction on query size.◦ Every inverted list should (expectedly) be more selective.
• However, they have high space requirement.
• For |s| = 14, τ = 2,◦ |SF3−Gram| = |s| − Q + 1 = 12 O(|s|)◦ |SFDeletion| =
(|s|τ
)= 91 O(|s|τ )
10 of 24

Choice of Signature
• Deletion Neighborhood seems to be better than Q-Gram.◦ No restriction on query size.◦ Every inverted list should (expectedly) be more selective.
• However, they have high space requirement.
• For |s| = 14, τ = 2,◦ |SF3−Gram| = |s| − Q + 1 = 12 O(|s|)◦ |SFDeletion| =
(|s|τ
)= 91 O(|s|τ )
10 of 24

Our System
Design Decision
Decided to implement a system following the generic scheme andusing deletion neighborhood as the signature scheme.
11 of 24

Choice of Signature
• Deletion Neighborhood seems to be better than Q-Gram.◦ No restriction on query size.◦ Every inverted list should (expectedly) be more selective.
• However, they have high space requirement.
• For |s| = 14, τ = 2,◦ |SF3−Gram| = |s| − Q + 1 = 12 O(|s|)◦ |SFDeletion| =
(|s|τ
)= 91 O(|s|τ )
• Challenge: Reduce space complexity of a deletion neighborhoodsignature based system while maintaining completeness of solution.
• Signature defined w.r.t. a threshold, need dedicated indexstructures, Iτ , for each threshold, τ = [0 : 4].
12 of 24

Choice of Signature
• Deletion Neighborhood seems to be better than Q-Gram.◦ No restriction on query size.◦ Every inverted list should (expectedly) be more selective.
• However, they have high space requirement.
• For |s| = 14, τ = 2,◦ |SF3−Gram| = |s| − Q + 1 = 12 O(|s|)◦ |SFDeletion| =
(|s|τ
)= 91 O(|s|τ )
• Challenge: Reduce space complexity of a deletion neighborhoodsignature based system while maintaining completeness of solution.
• Signature defined w.r.t. a threshold, need dedicated indexstructures, Iτ , for each threshold, τ = [0 : 4].
12 of 24

Reducing Space Requirement
• Key Idea: Introduce collisions among objects in SFτ (s).
O1
O2
O3
O4
O ′1
O ′2
O ′3
• Possible Solution ? Hashing !• For O ∈ SFτ (s), h(O) = suffixL(O).◦ Hashing results in a reduced set representation of SFτ (s).◦ Ex. for s =”SIGDATA”, τ = 1, L = 3,
• h(SF (s)) = {”ATA”, ”DTA”, ”DAA”, ”DAT”}• |h(SFτ (s))| = 4 < |SFτ (s)| = 8
• Added Benefit: Need not generate all elements in SFτ (s).|h(SFτ (s))| = O(
(L+ττ
)).
13 of 24

Reducing Space Requirement
• Key Idea: Introduce collisions among objects in SFτ (s).
O1
O2
O3
O4
O ′1
O ′2
O ′3
• Possible Solution ? Hashing !• For O ∈ SFτ (s), h(O) = suffixL(O).◦ Hashing results in a reduced set representation of SFτ (s).◦ Ex. for s =”SIGDATA”, τ = 1, L = 3,
• h(SF (s)) = {”ATA”, ”DTA”, ”DAA”, ”DAT”}• |h(SFτ (s))| = 4 < |SFτ (s)| = 8
• Added Benefit: Need not generate all elements in SFτ (s).|h(SFτ (s))| = O(
(L+ττ
)).
13 of 24

Reducing Space Requirement
• Key Idea: Introduce collisions among objects in SFτ (s).
O1
O2
O3
O4
O ′1
O ′2
O ′3
• Possible Solution ?
Hashing !• For O ∈ SFτ (s), h(O) = suffixL(O).◦ Hashing results in a reduced set representation of SFτ (s).◦ Ex. for s =”SIGDATA”, τ = 1, L = 3,
• h(SF (s)) = {”ATA”, ”DTA”, ”DAA”, ”DAT”}• |h(SFτ (s))| = 4 < |SFτ (s)| = 8
• Added Benefit: Need not generate all elements in SFτ (s).|h(SFτ (s))| = O(
(L+ττ
)).
13 of 24

Reducing Space Requirement
• Key Idea: Introduce collisions among objects in SFτ (s).
O1
O2
O3
O4
O ′1
O ′2
O ′3
• Possible Solution ? Hashing !• For O ∈ SFτ (s), h(O) = suffixL(O).◦ Hashing results in a reduced set representation of SFτ (s).◦ Ex. for s =”SIGDATA”, τ = 1, L = 3,
• h(SF (s)) = {”ATA”, ”DTA”, ”DAA”, ”DAT”}• |h(SFτ (s))| = 4 < |SFτ (s)| = 8
• Added Benefit: Need not generate all elements in SFτ (s).|h(SFτ (s))| = O(
(L+ττ
)).
13 of 24

Our System
Design Decision
To implement a system following the generic scheme and usingdeletion neighborhood as the signature.
Reduction of Space Requirement
To hash generated signature and index the resultant strings.
14 of 24

Our System
Design Decision
To implement a system following the generic scheme and usingdeletion neighborhood as the signature.
Reduction of Space Requirement
To hash generated signature and index the resultant strings.
14 of 24

Hashing: Completeness Guarantee ?
• Any hashing scheme guarantees the completeness of solution.
◦ If s is an answer for a query < q, τ >, then ∃ o s.t. o ∈ SFτ (s) ando ∈ SFτ (q).
◦ Thus, h(o) ∈ h(SFτ (s)), h(SFτ (q)), and hence s is in the candidatelist.
• Why suffix ?◦ No real reason. Initial design decision.◦ Performed well, stuck around.
• Possibly lucrative to try other hash functions/schemes.
15 of 24

Hashing: Completeness Guarantee ?
• Any hashing scheme guarantees the completeness of solution.◦ If s is an answer for a query < q, τ >, then ∃ o s.t. o ∈ SFτ (s) and
o ∈ SFτ (q).◦ Thus, h(o) ∈ h(SFτ (s)), h(SFτ (q)), and hence s is in the candidate
list.
• Why suffix ?◦ No real reason. Initial design decision.◦ Performed well, stuck around.
• Possibly lucrative to try other hash functions/schemes.
15 of 24

Hashing: Completeness Guarantee ?
• Any hashing scheme guarantees the completeness of solution.◦ If s is an answer for a query < q, τ >, then ∃ o s.t. o ∈ SFτ (s) and
o ∈ SFτ (q).◦ Thus, h(o) ∈ h(SFτ (s)), h(SFτ (q)), and hence s is in the candidate
list.
• Why suffix ?
◦ No real reason. Initial design decision.◦ Performed well, stuck around.
• Possibly lucrative to try other hash functions/schemes.
15 of 24

Hashing: Completeness Guarantee ?
• Any hashing scheme guarantees the completeness of solution.◦ If s is an answer for a query < q, τ >, then ∃ o s.t. o ∈ SFτ (s) and
o ∈ SFτ (q).◦ Thus, h(o) ∈ h(SFτ (s)), h(SFτ (q)), and hence s is in the candidate
list.
• Why suffix ?◦ No real reason. Initial design decision.◦ Performed well, stuck around.
• Possibly lucrative to try other hash functions/schemes.
15 of 24

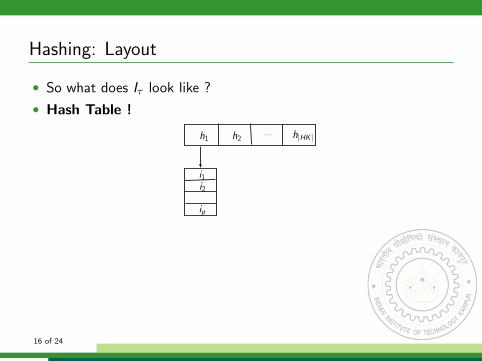
Hashing: Layout
• So what does Iτ look like ?
• Hash Table !
h1 h2 h|HK |
i1i2
ip
.....
◦ Keys consist of string resulting from hash (suffix operation).◦ List consists of ids of strings in D that generate the key.
16 of 24
Hashing: Layout
• So what does Iτ look like ?
• Hash Table !
h1 h2 h|HK |
i1i2
ip
.....
◦ Keys consist of string resulting from hash (suffix operation).◦ List consists of ids of strings in D that generate the key.
16 of 24
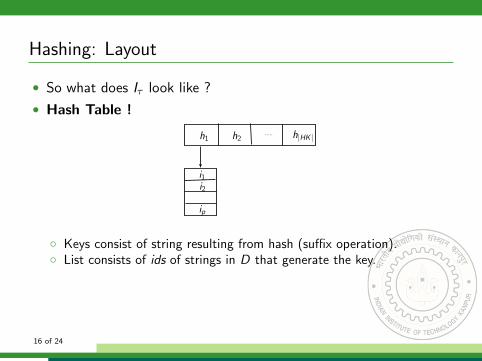
Hashing: Layout
• So what does Iτ look like ?
• Hash Table !
h1 h2 h|HK |
i1i2
ip
.....
◦ Keys consist of string resulting from hash (suffix operation).◦ List consists of ids of strings in D that generate the key.
16 of 24

Bucketing
• Should Iτ be a single structure (hash-table) for all strings ?
• No reason why !• Infact it helps to partitions strings on the basis of length.◦ Iτ consists of buckets.◦ Every bucket responsible for indexing strings within a particular length
range.
Iτ
B1 B2 B3
3 10
7 16
13 25
2τ 2τ
17 of 24

Bucketing
• Should Iτ be a single structure (hash-table) for all strings ?
• No reason why !• Infact it helps to partitions strings on the basis of length.◦ Iτ consists of buckets.◦ Every bucket responsible for indexing strings within a particular length
range.
Iτ
B1 B2 B3
3 10
7 16
13 25
2τ 2τ
17 of 24

Bucketing
• Should Iτ be a single structure (hash-table) for all strings ?
• No reason why !• Infact it helps to partitions strings on the basis of length.
◦ Iτ consists of buckets.◦ Every bucket responsible for indexing strings within a particular length
range.
Iτ
B1 B2 B3
3 10
7 16
13 25
2τ 2τ
17 of 24

Bucketing
• Should Iτ be a single structure (hash-table) for all strings ?
• No reason why !• Infact it helps to partitions strings on the basis of length.◦ Iτ consists of buckets.◦ Every bucket responsible for indexing strings within a particular length
range.
Iτ
B1 B2 B3
3 10
7 16
13 25
2τ 2τ
17 of 24

Bucketing: Why ?
• Ex. Let s =”PLACATING”, |s| = 9.
• Query < BATING , 2 >. |q| = 6.
• For I2, if L = 4, s will be in the candidate list.◦ ”TING” common hash-key.
• abs(|s| − |q|) > τ . s is ruled out.
• Apply length filter higher up in the pipeline.
• Say Iτ had B1 s.t. the bucket was responsible for range [1 : 8].◦ Query could be answered by B1 alone.◦ B1 would not index ”PLACATING”.
• 25% reduction in average search time for τ = 2.150µs → 110µs .
18 of 24

Bucketing: Why ?
• Ex. Let s =”PLACATING”, |s| = 9.
• Query < BATING , 2 >. |q| = 6.
• For I2, if L = 4, s will be in the candidate list.◦ ”TING” common hash-key.
• abs(|s| − |q|) > τ . s is ruled out.
• Apply length filter higher up in the pipeline.
• Say Iτ had B1 s.t. the bucket was responsible for range [1 : 8].◦ Query could be answered by B1 alone.◦ B1 would not index ”PLACATING”.
• 25% reduction in average search time for τ = 2.150µs → 110µs .
18 of 24

Bucketing: Why ?
• Ex. Let s =”PLACATING”, |s| = 9.
• Query < BATING , 2 >. |q| = 6.
• For I2, if L = 4, s will be in the candidate list.◦ ”TING” common hash-key.
• abs(|s| − |q|) > τ . s is ruled out.
• Apply length filter higher up in the pipeline.
• Say Iτ had B1 s.t. the bucket was responsible for range [1 : 8].◦ Query could be answered by B1 alone.◦ B1 would not index ”PLACATING”.
• 25% reduction in average search time for τ = 2.150µs → 110µs .
18 of 24

Bucketing: Why ?
• Ex. Let s =”PLACATING”, |s| = 9.
• Query < BATING , 2 >. |q| = 6.
• For I2, if L = 4, s will be in the candidate list.◦ ”TING” common hash-key.
• abs(|s| − |q|) > τ . s is ruled out.
• Apply length filter higher up in the pipeline.
• Say Iτ had B1 s.t. the bucket was responsible for range [1 : 8].◦ Query could be answered by B1 alone.◦ B1 would not index ”PLACATING”.
• 25% reduction in average search time for τ = 2.150µs → 110µs .
18 of 24

Our System
Design Decision
To implement a system following the generic scheme and usingdeletion neighborhood as the signature.
Reduction of Space Requirement
To hash generated signature and index the resultant strings.
Bucketing: Reducing collisions in Hash-Table
Partition strings on basis of length. Apply early length filtering.Results in smaller individual hash-tables. Increases space requirement.
19 of 24

Our System
Design Decision
To implement a system following the generic scheme and usingdeletion neighborhood as the signature.
Reduction of Space Requirement
To hash generated signature and index the resultant strings.
Bucketing: Reducing collisions in Hash-Table
Partition strings on basis of length. Apply early length filtering.Results in smaller individual hash-tables. Increases space requirement.
19 of 24

Verification
• How to verify if s ∈ Candidate-List is an answer ? Check ifED(s, q) ≤ τ
• Naive Method: Explicitly compute ED(s, q).
• Not interested in value of ED(s, q).
S1
S2
• For each row i , only need to examine j s.t.i −
⌊τ−δ2
⌋< j < i +
⌊τ+δ2
⌋. δ = abs(|s1| − |s2|).
• Li et al., VLDB 2012.
20 of 24

Verification
• How to verify if s ∈ Candidate-List is an answer ? Check ifED(s, q) ≤ τ
• Naive Method: Explicitly compute ED(s, q).
• Not interested in value of ED(s, q).
S1
S2
• For each row i , only need to examine j s.t.i −
⌊τ−δ2
⌋< j < i +
⌊τ+δ2
⌋. δ = abs(|s1| − |s2|).
• Li et al., VLDB 2012.
20 of 24

Verification
• How to verify if s ∈ Candidate-List is an answer ? Check ifED(s, q) ≤ τ
• Naive Method: Explicitly compute ED(s, q).
• Not interested in value of ED(s, q).
S1
S2
• For each row i , only need to examine j s.t.i −
⌊τ−δ2
⌋< j < i +
⌊τ+δ2
⌋. δ = abs(|s1| − |s2|).
• Li et al., VLDB 2012.20 of 24

Execution
• Generate dedicated index structures, Iτ for each τ .
• Read and group all queries depending on threshold τ .
• Sequentially process queries for each τ = [0 : 4].◦ Multiple threads read their own queries.◦ Thread j responsible for all queries s.t. idq % 8 = j .◦ Result of each query written to a global buffer in memory.
Contention between threads on memory write.
• Flush the buffer to the disk.
21 of 24

Results
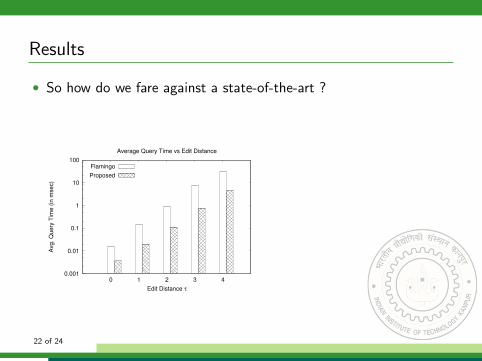
• So how do we fare against a state-of-the-art ?
0.001
0.01
0.1
1
10
100
0 1 2 3 4
Avg. Q
uery
Tim
e (
in m
sec)
Edit Distance τ
Average Query Time vs Edit Distance
Flamingo
Proposed
τ Avg. query time (ms)Flamingo Proposed
0 0.015 0.0041 0.146 0.0192 0.901 0.1083 7.245 0.7364 30.906 4.801
22 of 24
Results
• So how do we fare against a state-of-the-art ?
0.001
0.01
0.1
1
10
100
0 1 2 3 4
Avg. Q
uery
Tim
e (
in m
sec)
Edit Distance τ
Average Query Time vs Edit Distance
Flamingo
Proposed
τ Avg. query time (ms)Flamingo Proposed
0 0.015 0.0041 0.146 0.0192 0.901 0.1083 7.245 0.7364 30.906 4.801
22 of 24
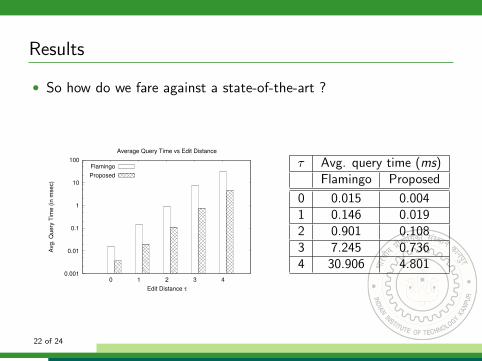
Results
• So how do we fare against a state-of-the-art ?
0.001
0.01
0.1
1
10
100
0 1 2 3 4
Avg. Q
uery
Tim
e (
in m
sec)
Edit Distance τ
Average Query Time vs Edit Distance
Flamingo
Proposed
τ Avg. query time (ms)Flamingo Proposed
0 0.015 0.0041 0.146 0.0192 0.901 0.1083 7.245 0.7364 30.906 4.801
22 of 24

The Team
23 of 24

The Team
23 of 24
The Team
23 of 24
The Team
23 of 24
The Team
23 of 24

Thank You !
24 of 24







![Knowledge Discovery and Data Mining 1 [0.1cm] (Data Mining … · 2019-12-09 · E cient Similarity Join Processing For very large databases, e cient join techniques are available](https://img.pdfslide.us/doc/110x75/5e6b529f4c9b002b453ce7b4/knowledge-discovery-and-data-mining-1-01cm-data-mining-2019-12-09-e-cient.jpg)




![Computationally E˜cient Earthquake Detection in Continuous ... · •Min-Hash [3] reduces fingerprint dimensionality, while preserving Jaccard similarity in probabilistic way, to](https://img.pdfslide.us/doc/110x75/5f529d8dd8b095497513dd93/computationally-eoecient-earthquake-detection-in-continuous-amin-hash-3.jpg)
















