Embed Size (px)
Citation preview

Doctoral Thesis ProposalLearning Semantics of WikiTables
Chandra Sekhar BhagavatulaDepartment of Electrical Engineering and Computer Science
Northwestern [email protected]
December 9, 2013
i

Abstract
Recent research has resulted in the creation of many fact extraction systems. To be ableto utilize the extracted facts to their full potential, it is essential to understand their semantics.Placing these extracted facts in an ontology is an effective way to provide structure, whichfacilitates better understanding of semantics. Today there are many systems that extract factsand organize them in an ontology, namely DBpedia, NELL, YAGO etc. While such ontologiesare used in a variety of applications, including IBM’s Jeopardy-winning Watson system, theydemand significant effort in their creation. They are either manually curated, or built usingsemi-supervised machine learning techniques. As the effort in the creation of an ontologyis significant, it is often hard to organize facts extracted from a corpus of documents that isdifferent from the one used to build these ontologies in the first place.
The goal of this work is to be able to automatically construct ontologies, for a given set ofentities, properties and relations. One key source of this data is the Wikipedia tables dataset.Wikipedia tables are unique in that they are a large (1.4 million) and heterogeneous set of tablesthat can be extracted at very high levels of precision. Rather than augmenting an existing ontol-ogy, which is a very challenging research problem in itself, I propose to automatically constructa new ontology by utilizing representations of entities, their attributes and relations. These rep-resentations will be learnt using unsupervised machine learning techniques on facts extractedfrom Wikipedia tables. Thus, the end system will not only extract facts from Wikipedia tables,but also automatically organize them in an Ontology to understand the semantics of Wikipediatables better.
ii

Contents
1 Introduction 11.1 Fact Extraction and Ontology Construction . . . . . . . . . . . . . . . . . . . . . 11.2 Source of Facts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
2 Related Work 22.1 Ontology Construction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22.2 Entity Linking in Tabular Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
3 Background 33.1 WikiTables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33.2 Entity Linking . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
4 Approach 54.1 Extract facts from Tables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
4.1.1 Table Wikification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64.1.2 Attribute Normalization . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
4.2 Entity, Property and Relation Representations . . . . . . . . . . . . . . . . . . . . 114.2.1 Matrix Factorization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114.2.2 Deep Learning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
4.3 Automatically Construct Ontology . . . . . . . . . . . . . . . . . . . . . . . . . . 14
5 Challenges and Open Questions 14
6 Evaluation 156.1 Table Wikification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 156.2 Ontology Creation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
7 Timeline 16
8 Acknowledgments 16
9 References 17
iii

1 Introduction
1.1 Fact Extraction and Ontology Construction
As the number of documents on the web increases, there is a growing need for systems that auto-matically extract information from these documents. Major strides have been made in the direc-tion of identifying named entities in text, creating lexicons, taxonomies, identifying hypernymy,meronymy and extracting relations between entities [1–3]. Information extraction has progressedfrom identifying type-of relations using manually curated text patterns [1] to domain independentautomatic discovery of relations using unsupervised machine learning techniques [2].
Many unsupervised or semi-supervised fact extraction systems have been built that extract factsfrom the web [2–6]. While these systems address a very important and challenging task of ex-tracting facts, the abundance of facts calls for systems that distill the extracted facts and organizethem systematically in an ontology so that computers can understand it and simulate intelligentbehavior. The vision of a Semantic Web [7] will only be realized when there is a much greatervolume of structured data available to power advanced applications. Organizing facts in an ontol-ogy facilitates much better Question-Answering systems and other Information Retrieval and NLPtasks.
The process of extracting facts and adding them to a Knowledge Base is called Knowledge Basepopulation. A Knowledge base holds facts about entities in a structured way, often provided in theform of an ontology. Many research systems, like DBpedia, NELL, Freebase, YAGO etc. extractfacts and organize them into ontologies. While such ontologies are used in a variety of applications,including IBM’s Jeopardy-winning Watson system, they demand significant effort in their creation.They are either manually curated, or built using semi-supervised machine learning techniques. Asthe effort in the creation of an ontology is significant, it is often hard to organize facts extractedfrom a corpus of documents that is different from the one used to build these ontologies in the firstplace.
1.2 Source of Facts
As information extraction (IE) is moving towards the open domain paradigm, systems need to pro-cess a large heterogeneous set of pages from which no particular “type” of information is beinglooked for. The aim of most IE systems today is to extract as many entities and facts as possible.Some systems use Wikipedia’s infobox data to bootstrap a process for generating additional struc-tured data from Wikipedia [8,9]. Many systems try to integrate an existing ontology, like WordNetor DBpedia, for class level structure and web or Wikipedia, for low level facts.
Most fact extraction systems mentioned in Section 1.1 extract facts from web text. While thesesystems achieve very high recall, web text is generally noisy and it is hard to achieve high precision.Lately, HTML Tables on the web have gained a lot of attention [10–14] as they are a good source ofsemi-structured data that convey many related facts in a succinct format. The Web is abundant withHTML tables (about 14.1 billion of them), but it is hard to filter out tables that are not relationaland only used for page layout. It was found that there are 154 million tables on the web that containrelational data [10], but tables may contain redundant data. Discovering semantics of these tables
1

is also a hard research problem [11]. Wikipedia, on the other hand, contains a large (about 1.4M)heterogeneous set of high quality tables, that are easily extractable [15]. Previous work has shownthat for the task of Table Search (the task of returning a ranked list of tables for a text query),systems that use Wikipedia tables perform comparably, or sometimes better than systems that usetables from the entire web [15].
2 Related Work
2.1 Ontology Construction
Most automatic ontology construction methods use lexical and syntactic pattern analysis methods.The pioneer of this method was Marti Hearst [1] who proposed what are now called “Hearst Pat-terns” to identify hyponyms in large text corpora. This method required manual design of patternswhich is not suitable for systems that need to extract unknown relations. This was followed byopen information extraction systems, like KnowItAll [16] and Open IE [2]. These systems useunsupervised techniques to extract facts at high recall values, but sometimes lack precision. Forexample < ColumbiaRecords, isthecapitalof , UnitedStates > is a fact in the Open IE system(although, it has a low confidence value). 1
Two other popular automatically constructed ontologies are DBpedia [8] and YAGO [9].
DBpedia is highly reliant on Wikipedia and its components - category structure, infoboxes, linksetc. It represents a category as a class and utilizes attributes and values from infoboxes as propertiesand relations of entities. The Wikipedia category structure is constructed by manually taggingindividual pages with category names, and is therefore not always consistent. DBpedia is a closemapping of structures found in Wikipedia and it makes little effort to clean up the structure.
Suchanek et. al. created the YAGO system to focus on extracting facts at high precision [9]. LikeDBpedia, YAGO also uses Wikipedia content to construct an ontology, but it maps class names withWordNet using several heuristics. The resulting ontology is high quality, but is limited in recallof relations. Recently, YAGO has been enhanced to include temporal and spatial information ofentities [6]. Owing to its high quality, YAGO has been used in IBM’s Jeopardy winning “Watson”system.
Wu et. al. [17] introduced the KOG system that automatically refined Wikipedia’s infobox classontology using both SVMs and joint inference models using Markov Logic Networks. Wu et.al. [18] previously created the Kylin system that uses CRF models to automatically create newinfoboxes and append data incomplete ones. Both Kylin and KOG are customized and optimizedfor Wikipedia articles and infoboxes. On the other hand, this thesis proposal is utilizing HTMLtables from Wikipedia, which are also otherwise found on the Web at large.
Suchanek et. al. also presented a system, SOFIE [19]. SOFIE extracts ontological facts from textdocuments and can link them to an ontology. While this system achieved high accuracy of factsextracted for a fixed set of relations, the system relies on manually curated logical rules. Also,experiments from [19] suggest that SOFIE is not designed for web-scale information extraction.
1http://openie.cs.washington.edu/search?arg1=what&rel=capital&arg2=united+states
2

Probase [20] is a probabilistic taxonomy of concepts extracted from the Web. It includes a widespectrum of concepts, including commonly used concepts like cities and less common conceptslike renewable energy technologies. Probase contains about 2.7 million concepts, but it does notextract relations other than the isA relation.
NELL [21] is a Never-Ending-Language-Learning system that runs continuously, scanning pageson the Web, and refines its knowledge. The system organizes facts into the NELL ontology. NELLemploys methods to account for type-constraints, similar to SOFIE. This system was originallydesigned to extract a fixed set of relations but later extended to automatically extract new relationsfor specific argument types. This system is still restricted to a limited set of relations.
2.2 Entity Linking in Tabular Data
Entity linking of table cells is a relatively recent research interest.
Limaye et. al. [14] presented a graphical model to link cell text to entities. The system incorporatedfeatures about cell values, column header and types, entities linked from cells etc. Their graphicalmodels achieve good results on Entity Linking tasks, but don’t do so well on Type prediction andthe Relation annotation tasks. The evaluation datasets are also relatively small.
Munoz et. al. [22] have proposed the task of “Triplifying Wikipedia’s Tables”, i.e. to expresstabular data as RDF triples. This systems does not handle the entity linking task, and considersonly existing links in Wikipedia tables. Assuming all existing links to be entities has considerablepitfalls and will be described in Section 4.1.1.
3 Background
This section describes previous work and projects that I’ve worked on. Some components fromthese systems will be used towards my thesis work, as described later in Section 4.
3.1 WikiTables
In previous work, I worked with collaborators on the WikiTables system. WikiTables leverageshigh quality tables on Wikipedia along with its rich content and link structure within machinelearning algorithms to search and mine extracted tables [15].
Experiments show that the disadvantages of Wikipedia’s smaller size are often outweighed by theadvantages of its high quality and more easily extracted features. We compared the WikiTablessystem on the TABLE SEARCH task - the task of retrieving the most relevant tables for a givenquery - to datasets from previous work which used all tables on the Web. WikiTables returnedrelevant results for 63 out of 100 queries as against 40 retrieved by the TABLE system describedby Venetis et. al. [11]. This proves the utility of tables from Wikipedia in fulfilling general userqueries.
WikiTables also introduced the novel task (RELEVANT JOIN) of automatically joining disparate ta-bles to uncover “interesting” relationships between table columns, and providing users with uniqueviews of data. Figure 1 shows a table from the “List of countries by GDP (nominal)” Wikipedia
3

page.2 WikiTables automatically selects a related column (“GDP (PPP) $Billion” in the example)using its learnt algorithms and appends it to the original table. The appended column is retrievedfrom a distinct table on the “List of countries by GDP (PPP)” Wikipedia page.3 The added col-umn provides new information that was not initially present in the original table, thus providing aunique view of data not available anywhere on the Web.
To facilitate the TABLE SEARCH and RELEVANT JOIN tasks, we extracted about 1.4 million highquality tables (TABLE CORPUS, T ) from Wikipedia. We also created a corpus (MATCH CORPUS,M) of ordered pairs of columns (c1, c2), such that at-least 50% of the values in column c1 are alsofound in column c2.
Both the TABLE CORPUS, T and MATCH CORPUS, M created by the WikiTables system will beused to automatically generate on ontology from table data - explained in Section 4.
Figure 1: WikiTables column addition in action: WikiTables shows the table containing list of countriesand their GDPs. The first 3 columns belong to this table. WikiTables automatically selects and adds theright-most column, ”GDP (PPP) Billion”, to this table.
3.2 Entity Linking
Entity Linking is the task of identifying mentions of entities in text and linking them to the identicalentity in a pre-defined Knowledge Base of entities. “Wikification” is the Entity Linking task whenWikipedia entities form the Knowledge Base. Figure 2 shows an example of Wikification of text.The difficulty of this task arises from the fact that the same word can have different meanings indifferent contexts. The first “Apple” in the example refers to the company, while the second refersto the fruit. “Wikification” involves this task of disambiguating meanings of an entity dependingon its context.
There are a couple of key challenges in the Wikification task: 1) Given some text, identify “whatto link?”; i.e. find surface mentions 2) Given a surface mention, find “where to link?”, based on
2http://en.wikipedia.org/wiki/List_of_countries_by_GDP\_(nominal)\#List3http://en.wikipedia.org/wiki/List_of_countries_by_GDP_(PPP)#Lists
4

its meaning in context; i.e. which entity in the Knowledge Base is identical with the meaning ofthe surface mention. In Figure 2, the words “Apple” and “apple” are the surface mentions and theWikipedia entity pages, “Apple Inc.” and “Apple” are their respective referent entities.
I’ve worked with collaborators on the Entity Linking task and some results have been presented in arecent tech report [23]. The WebSAIL Wikifier performs “Wikification” in three steps: 1) Identifiessurface mentions, i.e. identifies which parts of the text can be linked, 2) Identifies entity candidatesto which the surface mention could potentially be linked, and 3) Ranks the entity candidates usinga ranking model trained on various features, some of which capture the context surrounding thesurface mention.
Spitkovsky et. al. [24] released a dataset that contains the aggregation of the number of times agiven anchor text has been linked to a Wikipedia page on the entire Web. This dataset is used toidentify surface mentions in text and to also find all candidate entities that a surface mention canrefer to. These candidates are then ranked by a trained ranking model. An important features ofthis trained model is the context around a given surface mention. In the current version of thesystem, the context is the set of all words withing a fixed window from the surface mention.
Figure 2: Entity linking in text. The first occurrence of the word “Apple” refers to the company, but thesecond one refers to the fruit.
Table Wikification: To effectively and accurately extract facts from Wikipedia tables, cells intables need to be linked to their referent entities. This amounts to performing Wikification of cellsof all tables from Wikipedia. This is slightly different from “Wikification” of text alone - tablescontain many useful clues that are very indicative of the correct sense of a surface mention. Acolumn generally contains entities of the same type. The column header itself is a good indicatorof the type. These clues along with other features will be used to perform the Table Wikificationtask, explained in Section 4.1.1.
4 Approach
Goal: To automatically create an ontology from facts extracted from Wikipedia tables.
The key steps towards this goal are:
1. Extract facts from Tables(a) Table Wikification(b) Attribute Normalization
5

Figure 3: The 2008 Summer Olympics medals table contains a list of countries in the first column. Ratherthan linking country names to pages of respective countries, it links to a specific page about the performanceof the country at that particular event.
2. Create Entity, Property and Relation Representations(a) Using Matrix Factorization Techniques(b) Using Deep Learning Techniques
3. Automatically Construct Ontology(a) Hierarchical Clustering of entity representations from Step 2
4.1 Extract facts from Tables
4.1.1 Table Wikification
To extract facts from a table, the first step is to find which entities are mentioned in its cells. Thisis achieved by linking text in table cells to their referent entities in the Wikipedia Knowledge Baseof entities. This task of linking text in cells to their referent entities is called “Table Wikification”.
There are approximately 76 million cells in Wikipedia out of which only 19 million have a linkto another Wikipedia page. Not all pages on Wikipedia represent entities, as a result of which,many of the 19 million links found in table cells do not refer to entities. Such links will be referredto from now on as Non-Entity Links. For example, Figure 3 shows a table in which names ofcountries are linked to a specific page about the country’s performance at an event, rather than thepage of the country that represents the entity. Out of the 57 million remaining cells, which will bereferred to from now on as Unlinked Cells, many cells can potentially be linked to referent entitiesin Wikipedia. Figure 4 shows example of cells which do not contain a link, but can be linked.
To maximize the recall of facts, it is important to resolve these two problems.
6

Figure 4: Both Schizophrenia and Antipsychiatry are entities in Wikipedia, but the table is missing a linkto their referent pages
Resolving Non-Entity Links
As described above, cells in tables like Figure 3 link to pages which do not represent entitiesin Wikipedia. The MATCH CORPUS, M from the WikiTables [15] system can be utilized to nor-malize these cells and modify their link targets to entities rather than other descriptive pages. Mcontains about 140 million ordered pairs of columns (c1, c2), such that at-least 50% of the valuesin column c1 are also found in column c2.
Using column pairs and their percentage of overlap from M, the columns will be clustered suchthat a cluster contains columns that mutually have high overlap of cell values. Thus, the Non-Entity links can be replaced with the appropriate target entity by picking the most frequent targetof surface mentions found in cells of the clustered columns. Figure 5 shows a cluster of similarcolumns in which the text value t1 from a column links to P4, to P5 from a different column butgenerally links to P6 which can be considered the target entity for all occurrences of t1 in thecluster of columns. It must be noted that using the MATCH CORPUS and clustering columns bycell-value overlap percentage inherently disambiguates the sense of a surface mention. This isbecause columns generally contain entities of the same type, which means, that in a cluster like theone shown in Figure 5, the sense of a surface mention (say t1) remains constant across constants.
Resolving Unlinked Cells
MMUL: Wikipedia editors follows a convention of not linking a surface mention to its referententity if it has previously been linked on the same page. A similar convention is followed intables: when two cells in a row contain the same surface mentions that refer to the same entity,the first cell is linked but not the second cell. In this work, the second unlinked surface mention,whose text value matches that of a previously linked cell, will be referred to as Mention MatchingUnambiguous Link (MMUL).
In the set of tables obtained from the WikiTables system, there are over 262,000 potential MMULs.
7

Figure 5: One cluster of columns that have high overlap of cell values. t1 links to P4 or P5 sometimes, butmost often links to P6
They are discovered by looking for rows in which a cell ci has the same text as cell cj , ci links to anentity page in Wikipedia and j > i. Figure 6 shows an example table. It must be noted that not allcj can be trivially linked to the entity linked from ci. Figure 7 shows one such example. In the lastrow of the table, the third column has the same text as the second column, but the cells’ meaningsare different. While the first occurrence of the surface mention “King Lear” is about the movie,the second occurrence refers to the fictional character “King Lear’ in the movie of the same name.
I will use a binary classifier that decides whether to link cj with the target entity in ci. One usefulfeature for the binary classifier will be the types of other entities in the column. If ci and cj shouldlink to the same entity, other cells in the same column as ci and cj must also be of the same type.This equates to type-checking of the target entity. This feature is combined with other contextualfeatures to build the classifier.
Models: By resolving MMULs and Non-Entity links, we get a dataset of tables with more sur-face mentions linked to entities than before, and with some Non-Entity links modified to link toappropriate target entities. This new dataset of tables with additional and modified links will be re-ferred to as E-TABLE CORPUS. To link cells other than the easy cases as above, more sophisticatedtechniques using machine learning algorithms are required.
For the TABLE WIKIFICATION task, the links in the E-TABLE CORPUS are used as the trainingset. A subset of the existing links, unique from the training set will be used as the test set. Eachinstance of the training and test set consists of a surface mention and k candidates. The size of k isconfigurable. A candidate is an entity in the Wikipedia Knowledge Base. Candidates are obtainedfrom the dataset by Spitkovsky et. al. [24] as described in Section 3.2.
8

Figure 6: Itanagar in the 4th column can be linked to the Wikipedia page about Itanagar, but is missing inthe table
Figure 7: This table shows the Filmography of Paul Scofield .“King Lear” in the second columns of the lastrow refers to the movie, where as in the third column refers to the fictional character of the same name.
To build models for TABLE WIKIFICATION using the test and training sets described above, I willexperiment with two models, other than a Baseline method:
1. Baseline: The dataset, D1 from [24] by Spitkovsky et. al., provides counts of how manytimes a surface mention has been linked to a Wikipedia entity. To determine the referententity for a given surface mention, the Baseline method chooses the most frequent targetentity for that surface mention from D1.
2. WebSAIL Wikifier: This model has been described in Section 3.2. One of the most im-portant features of the WebSAIL Wikifier system is the context around a surface mention,which is the set of words around a surface mention within a window of fixed length. ForTABLE WIKIFICATION, the context is redefined for each surface mention as the set of allvalues and entities in the same column and same row as the surface mention. Entities in thesame column are strong indicators of the type of entity a surface mention refers to.
3. Generalization Model: This model is based on the concept that entities are organized inan ontology. In the WebSAIL Wikifier system, the context related features are sometimes
9

Method AccuracyBASELINE 71.9WEBSAIL WIKIFIER 67.5GENERALIZATION MODEL (NAIVE BAYES) 60.8
Table 1: Preliminary results of different models on the TABLE WIKIFICATION task
ineffective. There are many entities which have little context information owing to the factthat they are not mentioned in text very often. For example, “Allahabad”, a city in India, ismentioned in text far less than “Chicago”, but they are still both cities. They are conceptuallyequivalent. This problem of sparsity of contextual information for some entities can besolved by taking into account the type information.
This model utilizes an existing ontology - say the DBpedia ontology - to capture type in-formation. A classifier or ranking model is trained at each node in the DBpedia ontology.The idea behind this model is to be able to learn higher level features of generalizations ofentities.
Table 1 shows preliminary results of using each of the three methods above on the TABLE WIKI-FICATION task. The GENERALIZATION MODEL is using a Naive Bayes classifier at each node inthe ontology. It must be noted that although the results of the GENERALIZATION MODEL modellook worse than the baseline, it is using a very basic model and it relies on entities being present inthe DBpedia ontology, which is not always the case.
4.1.2 Attribute Normalization
Using the entities identified by the TABLE WIKIFICATION task, facts about those entities can beextracted from tables. One simple method to extract these facts is to consider the column headersin a table as the relation name. For example, in Figure 6, two facts that can be extracted from thethird row are
1. < ArunachalPradesh,AdministrativeCapital, Itanagar >
2. < ArunachalPradesh,LegislativeCapital, Itanagar >.
While this simple method of considering the column header as the relation name seems promising,it has considerable pitfalls. One example is shown in Figure 8 which shows two tables fromtwo distinct pages on Wikipedia. The first table has a column “Date of Birth” and the secondtable has the column “Born”. Extracting these column headers as two different relations results inunstandardized extractions. Thus, it is essential to normalize these attributes into the same name -say “Date of Birth”.
To perform this normalization, the following resources and methods can be utilized:
1. ACSDb as described in [10], is the attribute correlation statistics database. It consists ofcounts of the co-occurrence of different attributes in tables.
2. Distant Supervision using Infoboxes: Wikipedia’s Infoboxes are generally created usingtemplates. This brings uniformity of attribute names across entities of similar types, which
10

Figure 8: This figure shows two tables from Wikipedia. Both tables list the dates of birth of people, but onetable labels it as “Date of Birth” and the other as “Born”.
has been successfully exploited by information extraction systems [17, 25].
Figure 9 extends the previous example from Figure 8. The figure shows the Infoboxes fromarticles about “George Washington” and “Shimon Peres”.45 The value in the “Date of Birth”column for “George Washington” in the first table in Figure 8 matches the value of theattribute “Born” in the infobox on the “George Washington” Wikipedia page. Similarly,value of the “Born” attribute for “Shimon Peres” matches the table and the infobox.
Putting these pieces of evidence together, it can be established that the “Date of Birth” col-umn in the first table is the same property as the “Born” column in the second table in Figure8.
3. WordNet: WordNet is a lexical database of English nouns, verbs, adjectives and adverbsthat are organized under sets of synonyms called synsets. Identifying common synsets ofwords and phrases such as “Date of Birth” , “DOB” or “Born” will be good indicators of thenormalized relation.
4.2 Entity, Property and Relation Representations
Using facts extracted from the tables, one can learn representations of entities, their attributes andrelations between entity types. Lately, Non-Negative Matrix Factorization and Auto-encoders havebeen popular choices for learning entity or word representations. The two techniques can also beused in this work:
4.2.1 Matrix Factorization
Non-negative Matrix Factorization (NMF) is a technique for factorizing a matrix V = mX n intotwo low rank matrices W = mX k and H = k X n such that all three matrices have no negativeelements. NMF has widespread applications in clustering, computer vision and most importantlyrecommender systems.
Riedel et. al. [26] have recently used a matrix factorization technique to learn latent representationsof entity pairs and relations to predict if a fact is true based on evidence from other facts stored
4http://en.wikipedia.org/wiki/George\_Washington5http://en.wikipedia.org/wiki/Shimon\_Peres
11

Figure 9: Infoboxes found on the pages of “George Washington” and “Shimon Peres” contain the common“Born” attribute.
in the matrix. The input for their matrix is the list of < Entity1,Relation, Entity2 > triplesextracted from text or a structured knowledge base, like Freebase.
Extending this idea, the facts extracted from tables can be used to create a matrix, V of entitiesand properties. The ith row in the matrix represents an entity Ei and the jth column represents aproperty Pj . The matrix contains either 1 or 0 in a cell Vi,j depending on whether entity Ei hasthe property Pj . Thus, all tables on Wikipedia can be converted into a huge matrix as shown inFigure 10. The estimated dimensions of this matrix representation of entities and properties areV = 3million X 273K. A low rank Non-negative Matrix Factorization algorithm applied to thismatrix will produce two matrices, W = 3million X k and H = k X 273K. Each row of W isa latent feature vector representation of an entity and each column in H is a latent feature vectorrepresentation of a property.
While Riedel et. al. have used a very similar approach to learn vector representations for entitypairs, one key improvement of this work will be utilizing inheritance structure between entities tolearn better representations of entities. How this will be achieved is still an open question.
12
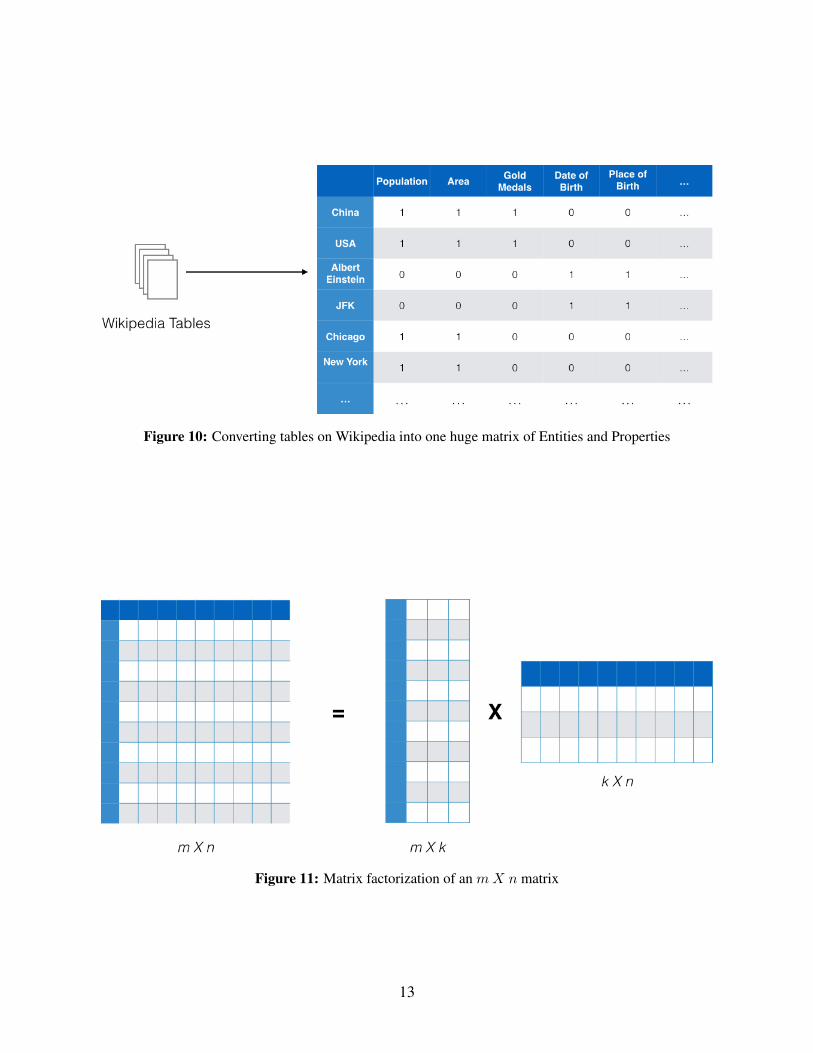
Figure 10: Converting tables on Wikipedia into one huge matrix of Entities and Properties
Figure 11: Matrix factorization of an mX n matrix
13
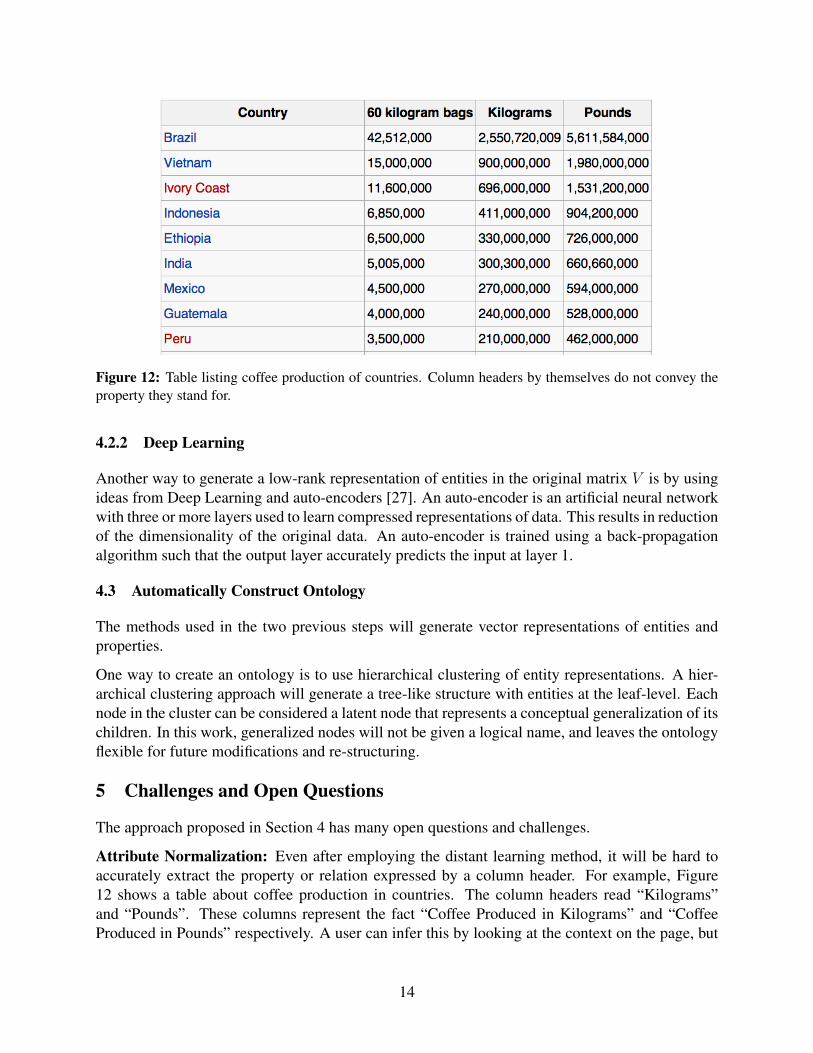
Figure 12: Table listing coffee production of countries. Column headers by themselves do not convey theproperty they stand for.
4.2.2 Deep Learning
Another way to generate a low-rank representation of entities in the original matrix V is by usingideas from Deep Learning and auto-encoders [27]. An auto-encoder is an artificial neural networkwith three or more layers used to learn compressed representations of data. This results in reductionof the dimensionality of the original data. An auto-encoder is trained using a back-propagationalgorithm such that the output layer accurately predicts the input at layer 1.
4.3 Automatically Construct Ontology
The methods used in the two previous steps will generate vector representations of entities andproperties.
One way to create an ontology is to use hierarchical clustering of entity representations. A hier-archical clustering approach will generate a tree-like structure with entities at the leaf-level. Eachnode in the cluster can be considered a latent node that represents a conceptual generalization of itschildren. In this work, generalized nodes will not be given a logical name, and leaves the ontologyflexible for future modifications and re-structuring.
5 Challenges and Open Questions
The approach proposed in Section 4 has many open questions and challenges.
Attribute Normalization: Even after employing the distant learning method, it will be hard toaccurately extract the property or relation expressed by a column header. For example, Figure12 shows a table about coffee production in countries. The column headers read “Kilograms”and “Pounds”. These columns represent the fact “Coffee Produced in Kilograms” and “CoffeeProduced in Pounds” respectively. A user can infer this by looking at the context on the page, but
14

how can this be automated? Incorporating context from the page outside of the table is challengethat needs to be addressed.
Non-Negative Matrix Factorization: The matrix generated from the tables is extremely large.Of-the-shelf NMF libraries do not support such large matrices. Also, inferring inheritance rela-tionships between entities in the matrix and then performing NMF is challenging.
Automatic Ontology Creation: Most systems that have tried to generate ontologies automati-cally have been successful in incorporating few selected relations. How to add relations betweengeneralized classes of the automatically generated ontology is still an open question.
6 Evaluation
6.1 Table Wikification
The TABLE WIKIFICATION system will be evaluated as the accuracy of predicting the held-out setof links. Using existing links to evaluate the system is easy, as there is no manual labeling required.But this set of held-out links may be a biased set. This is because generally, if a cell contains alink to an entity, other cells in the column are more likely to contain links. Using these links forprediction will make the task easier. To counter this, a second evaluation will be done in whicha random set of cells linked by the TABLE WIKIFICATION system will be manually evaluated foraccuracy.
6.2 Ontology Creation
As noted in a recent survey on automatic construction of lexicons, taxonomies and ontologies,evaluating a hierarchy of entities is a very difficult task [28]. Some researchers evaluate the qualityof these hierarchies by employing them in a specific task [29]. Some other evaluation methodsinclude per-relation quality measured by human judges [30, 31] or comparing overall coverageagainst an existing hierarchy [32]. Most commonly, knowledge bases are evaluated in terms ofaccuracy the entities, relations and facts it contains.
Representation of reality and internal consistency are also important aspects of a sound KnowledgeBase. For example, logical inconsistencies in an ontology can lead to contradictory inferencesbeing made. Representation of reality can be judged by measuring conceptual alignment of KBentities to real world entities or by studying how the KB gets changed when new concepts getadded or deleted.
Thus, for this work, the most appropriate way to evaluate the automatically ontology is by employ-ing it in a specific task. The GENERALIZATION MODEL model described in Section 4.1.1 usesthe DBpedia ontology for the TABLE WIKIFICATION task. The DBpedia dataset does not containabout 1M entities that are available in Wikipedia. Also, when new entities get added, it takes awhile before it gets incorporated into DBpedia. Thus, if an ontology is generated for the data inhand, i.e. facts extracted from tables, it can be utilized to perform better TABLE WIKIFICATION.The Ontology Generalization model can also be used in the WebSAIL Wikifier system.
15

7 Timeline
• Extract facts from Tables - May 20141. Table Wikification (2 months)2. Attribute Normalization (3 months)
• Create Entity, Property and Relation Representations - October 20141. Using Matrix Factorization Techniques (2.5 months)2. Using Deep Learning Techniques (2.5 months)
• Automatically Construct Ontology - March 20151. Hierarchical Clustering of entity representations (6 months)
8 Acknowledgments
The WikiTables and WebSAIL Wikifier were developed with collaborators in our research groupWebSAIL. I would like to thank my collaborators.
16

9 References
[1] Marti A Hearst. Automatic acquisition of hyponyms from large text corpora. In Proceedings of the 14thconference on Computational linguistics-Volume 2, pages 539–545. Association for ComputationalLinguistics, 1992.
[2] Michele Banko, Michael J Cafarella, Stephen Soderland, Matthew Broadhead, and Oren Etzioni. Openinformation extraction from the web. In IJCAI, volume 7, pages 2670–2676, 2007.
[3] Oren Etzioni, Anthony Fader, Janara Christensen, Stephen Soderland, and Mausam Mausam. Openinformation extraction: The second generation. In Proceedings of the Twenty-Second internationaljoint conference on Artificial Intelligence-Volume Volume One, pages 3–10. AAAI Press, 2011.
[4] Andrew Carlson, Justin Betteridge, Bryan Kisiel, Burr Settles, Estevam R Hruschka Jr, and Tom MMitchell. Toward an architecture for never-ending language learning. In AAAI, 2010.
[5] Ndapandula Nakashole, Martin Theobald, and Gerhard Weikum. Scalable knowledge harvesting withhigh precision and high recall. In Proceedings of the fourth ACM international conference on Websearch and data mining, pages 227–236. ACM, 2011.
[6] Johannes Hoffart, Fabian M Suchanek, Klaus Berberich, and Gerhard Weikum. Yago2: a spatially andtemporally enhanced knowledge base from wikipedia. Artificial Intelligence, 194:28–61, 2013.
[7] Tim Berners-Lee, James Hendler, Ora Lassila, et al. The semantic web. Scientific american, 284(5):28–37, 2001.
[8] Soren Auer, Christian Bizer, Georgi Kobilarov, Jens Lehmann, Richard Cyganiak, and Zachary Ives.Dbpedia: A nucleus for a web of open data. In The semantic web, pages 722–735. Springer, 2007.
[9] Fabian M Suchanek, Gjergji Kasneci, and Gerhard Weikum. Yago: a core of semantic knowledge. InProceedings of the 16th international conference on World Wide Web, pages 697–706. ACM, 2007.
[10] Michael J Cafarella, Alon Halevy, Daisy Zhe Wang, Eugene Wu, and Yang Zhang. Webtables: explor-ing the power of tables on the web. Proceedings of the VLDB Endowment, 1(1):538–549, 2008.
[11] Petros Venetis, Alon Halevy, Jayant Madhavan, Marius Pasca, Warren Shen, Fei Wu, Gengxin Miao,and Chung Wu. Recovering semantics of tables on the web. Proceedings of the VLDB Endowment,4(9):528–538, 2011.
[12] Michael J Cafarella, Alon Y Halevy, Yang Zhang, Daisy Zhe Wang, and Eugene Wu. Uncovering therelational web. In WebDB. Citeseer, 2008.
[13] Hazem Elmeleegy, Jayant Madhavan, and Alon Halevy. Harvesting relational tables from lists on theweb. Proceedings of the VLDB Endowment, 2(1):1078–1089, 2009.
[14] Girija Limaye, Sunita Sarawagi, and Soumen Chakrabarti. Annotating and searching web tables usingentities, types and relationships. Proceedings of the VLDB Endowment, 3(1-2):1338–1347, 2010.
[15] Chandra Sekhar Bhagavatula, Thanapon Noraset, and Doug Downey. Methods for exploring andmining tables on wikipedia. In Proceedings of the ACM SIGKDD Workshop on Interactive DataExploration and Analytics, pages 18–26. ACM, 2013.
17

[16] Oren Etzioni, Michael Cafarella, Doug Downey, Ana-Maria Popescu, Tal Shaked, Stephen Soderland,Daniel S Weld, and Alexander Yates. Unsupervised named-entity extraction from the web: An exper-imental study. Artificial Intelligence, 165(1):91–134, 2005.
[17] Fei Wu and Daniel S Weld. Automatically refining the wikipedia infobox ontology. In Proceedings ofthe 17th international conference on World Wide Web, pages 635–644. ACM, 2008.
[18] Fei Wu and Daniel S Weld. Autonomously semantifying wikipedia. In Proceedings of the sixteenthACM conference on Conference on information and knowledge management, pages 41–50. ACM,2007.
[19] Fabian M Suchanek, Mauro Sozio, and Gerhard Weikum. Sofie: a self-organizing framework forinformation extraction. In Proceedings of the 18th international conference on World wide web, pages631–640. ACM, 2009.
[20] Wentao Wu, Hongsong Li, Haixun Wang, and Kenny Q Zhu. Probase: A probabilistic taxonomy fortext understanding. In Proceedings of the 2012 ACM SIGMOD International Conference on Manage-ment of Data, pages 481–492. ACM, 2012.
[21] Andrew Carlson, Justin Betteridge, Richard C Wang, Estevam R Hruschka Jr, and Tom M Mitchell.Coupled semi-supervised learning for information extraction. In Proceedings of the third ACM inter-national conference on Web search and data mining, pages 101–110. ACM, 2010.
[22] Emir Munoz, Aidan Hogan, and Alessandra Mileo. Triplifying wikipedias tables.
[23] Thanapon Noraset, Chandra Bhagavatula, Yang Yi, and Doug Downey. WebSAIL Wikifier : EnglishEntity Linking at TAC 2013. Technical report, Northwestern University, 2013.
[24] Valentin I Spitkovsky and Angel X Chang. A cross-lingual dictionary for english wikipedia concepts.In LREC, pages 3168–3175, 2012.
[25] Jens Lehmann, Robert Isele, Max Jakob, Anja Jentzsch, Dimitris Kontokostas, Pablo N Mendes, Se-bastian Hellmann, Mohamed Morsey, Patrick van Kleef, Soren Auer, et al. Dbpedia-a large-scale,multilingual knowledge base extracted from wikipedia. Semantic Web Journal, 2013.
[26] Sebastian Riedel, Limin Yao, Andrew McCallum, and Benjamin M Marlin. Relation extraction withmatrix factorization and universal schemas. In Proceedings of NAACL-HLT, pages 74–84, 2013.
[27] Yoshua Bengio. Learning deep architectures for ai. Foundations and trends R⃝ in Machine Learning,2(1):1–127, 2009.
[28] Olena Medelyan, Ian H Witten, Anna Divoli, and Jeen Broekstra. Automatic construction of lexicons,taxonomies, ontologies, and other knowledge structures. Wiley Interdisciplinary Reviews: Data Miningand Knowledge Discovery, 3(4):257–279, 2013.
[29] Simone Paolo Ponzetto and Michael Strube. Taxonomy induction based on a collaboratively builtknowledge repository. Artificial Intelligence, 175(9):1737–1756, 2011.
[30] Emilia Stoica, Marti A Hearst, and Megan Richardson. Automating creation of hierarchical facetedmetadata structures. In HLT-NAACL, pages 244–251, 2007.
18

[31] Samuel Sarjant, Catherine Legg, Michael Robinson, and Olena Medelyan. All you can eat ontology-building: Feeding wikipedia to cyc. In Proceedings of the 2009 IEEE/WIC/ACM International JointConference on Web Intelligence and Intelligent Agent Technology-Volume 01, pages 341–348. IEEEComputer Society, 2009.
[32] Rion Snow, Daniel Jurafsky, and Andrew Y Ng. Semantic taxonomy induction from heterogenousevidence. In Proceedings of the 21st International Conference on Computational Linguistics and the44th annual meeting of the Association for Computational Linguistics, pages 801–808. Association forComputational Linguistics, 2006.
19





























