Embed Size (px)
Citation preview

Distributed Search over the Hidden Web
Hierarchical Database Sampling and Selection
Panagiotis G. Ipeirotis
Luis Gravano
Computer Science Department
Columbia University

04/18/23 Columbia University 2
Distributed Search? Why?“Surface” Web vs. “Hidden” Web
“Surface” Web– Link structure– Crawlable– Documents indexed
by search engines
“Hidden” Web– No link structure– Documents “hidden” in databases– Documents not indexed by search engines– Need to query each collection
individually
SUBMIT
Keywords
CLEAR

04/18/23 Columbia University 3
Hidden Web: Examples
Database Query Matches Google
PubMed diabetes 178,975 119
U.S. Patents wireless network 16,741 0
Library of Congress visa regulations >10,000 0
… … … …
PubMed search: [diabetes] 178,975 matchesPubMed is at http://www.ncbi.nlm.nih.gov/PubMed
Google search: [diabetes site:www.ncbi.nlm.nih.gov] 119 matches

04/18/23 Columbia University 4
Distributed Search: Challenges
Metasearcher
Library of Congress
Hidden Web
PubMed ESPN
Content summaries of databases
(vocabulary, word frequencies)
kidneys 220,000 stones 40,000...
kidneys 5 stones 40...
kidneys 20 stones950
...
Select good databases for query Evaluate query at these databases Merge results from databases
04/18/23 Columbia University 5
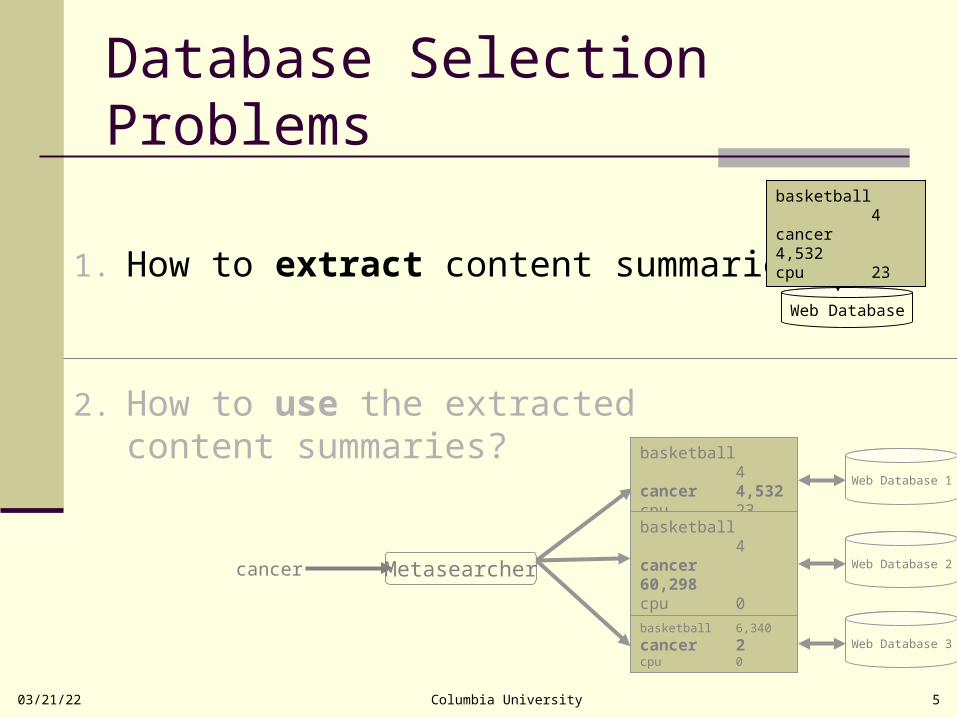
Database Selection Problems
1. How to extract content summaries?
2. How to use the extracted content summaries?
Web Database
Web Database 1
Metasearchercancer
basketball 4cancer 4,532cpu 23
basketball 4cancer 4,532cpu 23
Web Database 2basketball 4cancer 60,298cpu 0
Web Database 3basketball 6,340
cancer 2cpu 0

04/18/23 Columbia University 6
Extracting Content Summariesfrom Web Databases
No direct access to remote documents other than by querying
Resort to query-based document sampling: Send queries to database Retrieve document sample Use sample to create approximate content summary

04/18/23 Columbia University 7
“Random” Query-Based Sampling
Pick a word and send it as a query to database
Retrieve top-k documents returned (e.g., k=4)
Repeat until “enough” (e.g., 300) documents are retrieved
metallurgy
dna
aidsfootball
cancerkeyboardram
polo
Sample
Use word frequencies in sample to create content summary
Word Frequency in Sample
cancer 150 (out of 300)
aids 114 (out of 300)
heart 98 (out of 300)
…
basketball 2 (out of 300)
Callan et al., SIGMOD’99, TOIS 2001

04/18/23 Columbia University 8
Random Sampling: Problems
No actual word frequencies computed for content summaries, only a “ranking” of words
Many words missing from content summaries (many rare words)
Many queries return very few or no matches
# documents
word rank
Zipf’s law
Many words appear in only
one or two documents

04/18/23 Columbia University 9
Our Technique: Focused Probing
1. Train document classifiers Find representative words for each category
2. Use classifier rules to derive a topically-focused sample from database
3. Estimate actual document frequencies for all discovered words

04/18/23 Columbia University 10
Focused Probing: Training
Start with a predefined topic hierarchy and preclassified documents
Train document classifiers for each node
Extract rules from classifiers: ibm AND computers → Computers lung AND cancer → Health …
angina → Heart hepatitis AND liver → Hepatitis …
} Root
} Health
HealthComputers
Root
...... ...
HepatitisHeart ...... ...
SIGMOD 2001
04/18/23 Columbia University 11
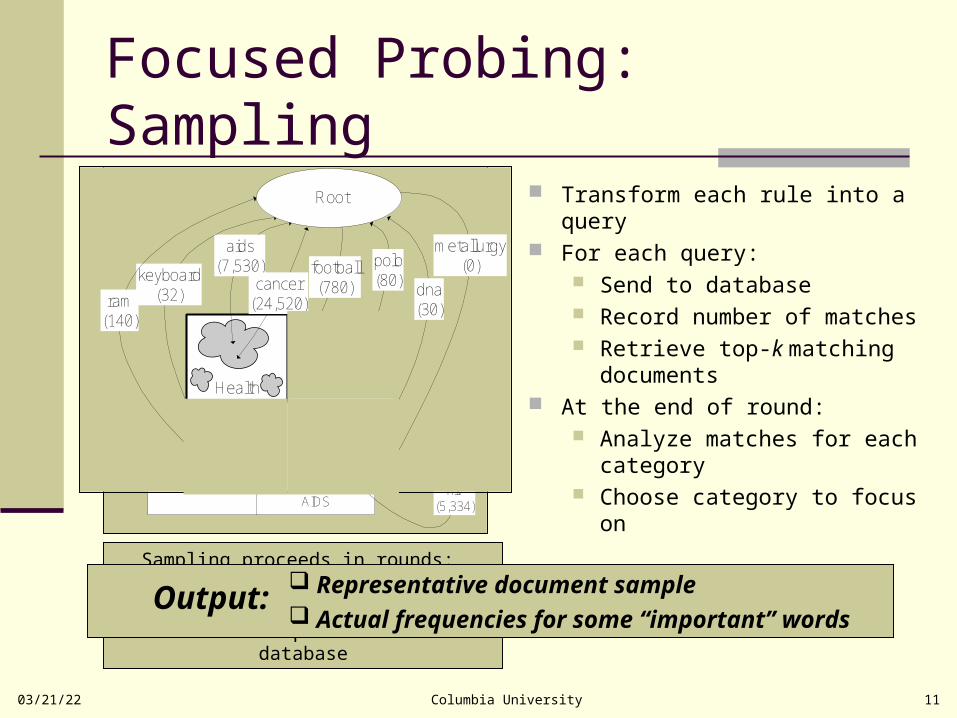
Focused Probing: Sampling
Transform each rule into a query For each query:
Send to database Record number of matches Retrieve top-k matching
documents At the end of round:
Analyze matches for each category
Choose category to focus on
Sampling proceeds in rounds:
In each round, the rules associated with each node are turned into queries for the database
Cancer
Hepatitis
Heart
AIDS
oncology(1,230)
angina(150)
psa(7,700)
liver(4,345)
chf(2,340)
Health
safe AND sex(245)
hiv(5,334)
Health
Sports
Science
metallurgy(0)
dna(30)
Computers
aids(7,530) football
(780)cancer(24,520)
keyboard(32)ram
(140)
polo(80)
Root
Representative document sample Actual frequencies for some “important” words
Output:

04/18/23 Columbia University 12
Sample Frequencies and Actual Frequencies
“liver” appears in 200 out of 300 documents in sample “kidney” appears in 100 out of 300 documents in sample “hepatitis” appears in 30 out of 300 documents in sample
Document frequencies in actual database?
Can exploit number of matches from one-word queries
Query “liver” returned 140,000 matches Query “hepatitis” returned 20,000 matches “kidney” was not a query probe…

04/18/23 Columbia University 13
?
?
?
Known Frequency
?Unknown Frequency
Frequency in Sample (always known)
... ...
cancer liver stomachkidneys
......
hepatitis... ...
...
20,000 matches
140,000 matches
60,000 matches
f = P (r+p) -B
?
?
?
Known Frequency
?Unknown Frequency
Frequency in Sample (always known)
... ...
cancer liver stomachkidneys
......
hepatitis... ...
...
20,000 matches
140,000 matches
60,000 matches
f = P (r+p) -B
?
?
?
Known Frequency
?Unknown Frequency
Frequency in Sample (always known)
... ...
cancer liver stomachkidneys
......
hepatitis... ...
...
20,000 matches
140,000 matches
60,000 matches
Frequency in Sample (always known)
... ...
cancer liver stomachkidneys
......
hepatitis... ...
...
Adjusting Document Frequencies We know ranking r of
words according to document frequency in sample
We know absolute document frequency f of some words from one-word queries
Mandelbrot’s formula connects empirically word frequency f and ranking r
We use curve-fitting to estimate the absolute frequency of all words in sample
r
f

04/18/23 Columbia University 14
Actual PubMed Content Summary
Extracted automatically
~ 27,500 words in extracted content summary
Fewer than 200 queries sent
At most 4 documents retrieved per query
PubMed content summary
Number of Documents: 3,868,552
category: Health, Diseases
…
cancer 1,398,178
aids 106,512
heart 281,506
hepatitis 23,481
…
basketball 907
cpu 487
The extracted content summary accurately represents
size, contents, and classification of the database

04/18/23 Columbia University 15
Focused Probing: Contributions
Focuses database sampling on dense topic areas
Estimates absolute document frequencies of words
Classifies databases along the way Classification useful for database selection

04/18/23 Columbia University 16
Database Selection Problems
1. How to extract content summaries?
2. How to use the extracted content summaries?
Metasearchercancer
Web Database 1basketball 4cancer 4,532cpu 23
Web Database 2basketball 4cancer 60,298cpu 0
Web Database 3basketball 6,340
cancer 2cpu 0
Web Database
basketball 4cancer 4,532cpu 23

04/18/23 Columbia University 17
Database Selection and Extracted Content Summaries
Database selection algorithms assume complete content summaries
Content summaries extracted by (small-scale) sampling are inherently incomplete (Zipf's law)
Queries with undiscovered words are problematic
Database Classification Helps:
Similar topics ↔ Similar content summaries
Extracted content summaries complement each other
04/18/23 Columbia University 18
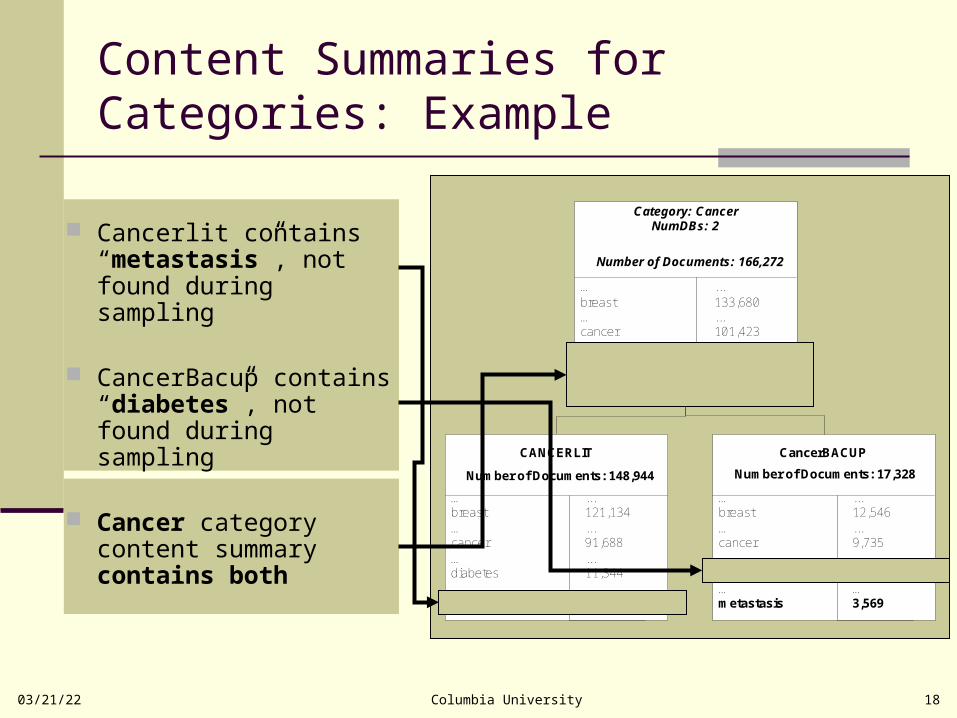
Content Summaries for Categories: Example
CANCERLIT
… ...breast 121,134… ...cancer 91,688… ...diabetes 11,344… …metastasis <not found>
CancerBACUP
… ...breast 12,546… ...cancer 9,735… ...diabetes <not found>… …metastasis 3,569
Category: CancerNumDBs: 2
Number of Documents: 166,272
… ...breast 133,680… ...cancer 101,423… ...diabetes 11,344… …metastasis 3,569
Number of Documents: 148,944 Number of Documents: 17,328
Cancerlit contains “metastasis”, not found during sampling
CancerBacup contains “diabetes”, not found during sampling
Cancer category content summary contains both

04/18/23 Columbia University 19
Hierarchical DB Selection: Outline
Create aggregated content summaries for categories
Hierarchically direct queries using categories
Category content summaries are more complete than database content summaries
Various traversal techniques possible
04/18/23 Columbia University 20
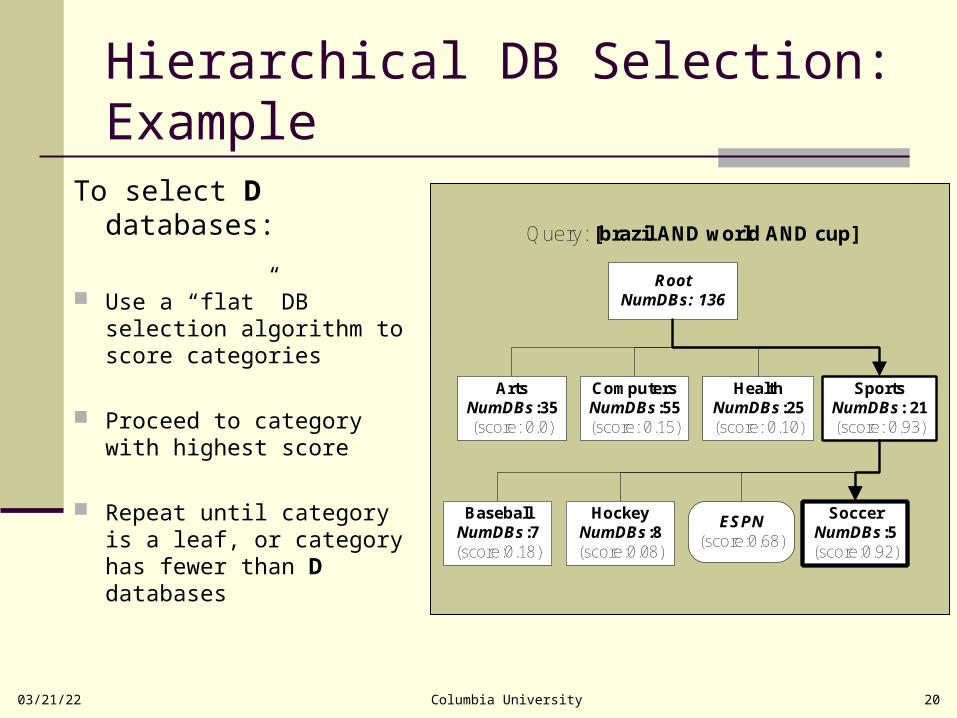
Hierarchical DB Selection: Example
RootNumDBs: 136
SportsNumDBs: 21(score: 0.93)
ArtsNumDBs:35(score: 0.0)
ComputersNumDBs:55(score: 0.15)
HockeyNumDBs:8(score:0.08)
BaseballNumDBs:7(score:0.18)
ESPN(score:0.68)
HealthNumDBs:25(score: 0.10)
SoccerNumDBs:5(score:0.92)
Query: [brazil AND world AND cup]
To select D databases:
Use a “flat” DB selection algorithm to score categories
Proceed to category with highest score
Repeat until category is a leaf, or category has fewer than D databases

04/18/23 Columbia University 21
Retrieves same number of documents using fewer queries
Topic detection helps
Actual
aids
basketball
cancer
heart
…
pneumonia
Sample
aids
basketball
cancer
heart
…
pneumonia
Actual
cancer
pneumonia
aids
heart
…
basketball
Sample
aids
basketball
cancer
heart
…
pneumonia
Ignores “off-topic” documents
Better sample:Each retrieved document
“represents” many unretrieved, so “on-topic” sampling helps
Focused Probing compared to Random Sampling:
Better vocabulary coverage
Better word ranking
More efficient for same sample size
More effective for same sample size
Experiments: Content Summary Extraction
More results in the paper!4 types of classifiers (SVM, Ripper, C4.5, Bayes), frequency estimation, different data sets…

04/18/23 Columbia University 22
LoCLoC
LoCLoC
LoCLoC
LoCLoC
Experiments: Database Selection
LoCcData set and workload: 50 real Web databases 50 TREC Web Track queries
Metric: Precision @ 15 For each query pick 3 databases Retrieve 5 documents from each database Return 15 documents to user Mark “relevant” and “irrelevant” documents
LoCLoC
LoCLoC
LoC
LoCLoC
LoCLoC
LoCLoC
LoC
Database Selection
Query
Good database selection algorithms choose databases with relevant documents

04/18/23 Columbia University 23
Experiments: Precision of Database Selection Algorithms
Hierarchical Flat
Focused Probing 0.27 0.17
Random Sampling - 0.18
Hierarchical database selection improves precision drastically Category content summaries more complete Topic-based database clustering helps
Best result for centralized search ~ 0.35
Not an option for Hidden Web!
More results in the paper!(different flat selection algorithms, more content summary extraction algorithms…)

04/18/23 Columbia University 24
Contributions
Technique for extracting content summaries from completely autonomous Hidden-Web databases
Technique for estimating frequencies: Possible to distinguish large from small databases
Hierarchical database selection exploits classification improving drastically precision of distributed search
Content summary extraction implemented and available for download at: http://sdarts.cs.columbia.edu

04/18/23 Columbia University 25
Future Work
Different techniques for merging content summaries for category content summary creation
Effect of frequency estimation on database selection
Different hierarchy “traversing” algorithms for hierarchical database selection





























