Embed Size (px)
Citation preview

DISTRIBUTED RANDOM FOREST CLASSIFICATION OF URBAN
MOBILE MAPPING DATA
Christian AlisUniversity College London, UK
IQmulus, Final WorkshopBergen, September 21, 2016
The research leading to these results has received funding from the European Union Seventh Framework Programme (FP7/2007-2013) under grant agreement n° 318787.

Distributed Random Forest classification of urban mobile mapping data
Christian Alis, Jan Boehm, Kun LiuDept of Civil, Environmental and Geomatic EngineeringUniversity College London

2M. Weinmann, B. Jutzi, S. Hinz, and C. Mallet, ‘Semantic point cloud interpretation based on optimal neighborhoods, relevant features and efficient classifiers’, ISPRS Journal of Photogrammetry and Remote Sensing, vol. 105, pp. 286–304, Jul. 2015.

3
Features Label
Model
TrainedModel
Features Label
TR
AIN
ING
PR
ED
ICT
ION

4
Point cloud classification features
Linearity
Planarity
Scattering
Omnivariance
Anisotropy
Eigenentropy
Eigenvalue sum
Change of curvature
Z value
Radius
Density
Verticality
Z range
Z standard deviation
2D radius
2D density
2D eigenvalue sum
2D eigenvalue ratio
Features are computed based on neighbourhood of the point
5
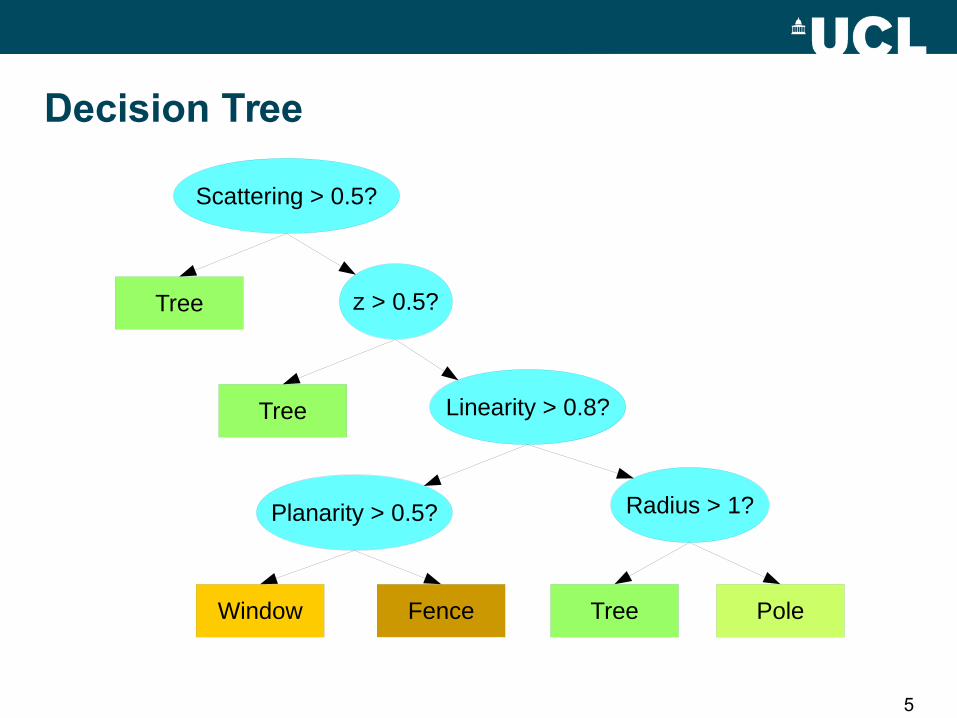
Scattering > 0.5?
z > 0.5?
Linearity > 0.8?
Planarity > 0.5? Radius > 1?
Tree
Tree
Window Fence Tree Pole
Decision Tree

6
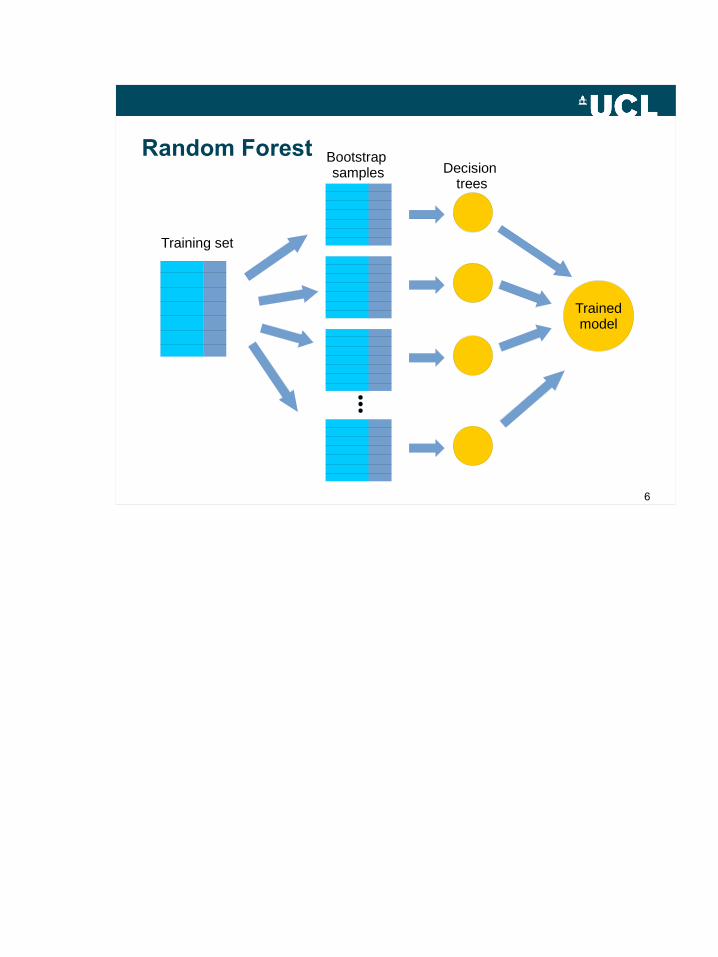
Random Forest
Trainedmodel
Training set
Bootstrap samples Decision
trees

7M. Weinmann, B. Jutzi, S. Hinz, and C. Mallet, ‘Semantic point cloud interpretation based on optimal neighborhoods, relevant features and efficient classifiers’, ISPRS Journal of Photogrammetry and Remote Sensing, vol. 105, pp. 286–304, Jul. 2015.
What if the point cloud consists of millions or billions of points?

8https://commons.wikimedia.org/wiki/File:BigData_2267x1146_white.png

9
Apache Spark
A processing engine for distributed computation Able to scale from single to multiple machines Allows coding using different languages Very active development and user community Allows processing of non-spatial data Has a machine learning library with random forest
No built-in support for point clouds Partitioning
10
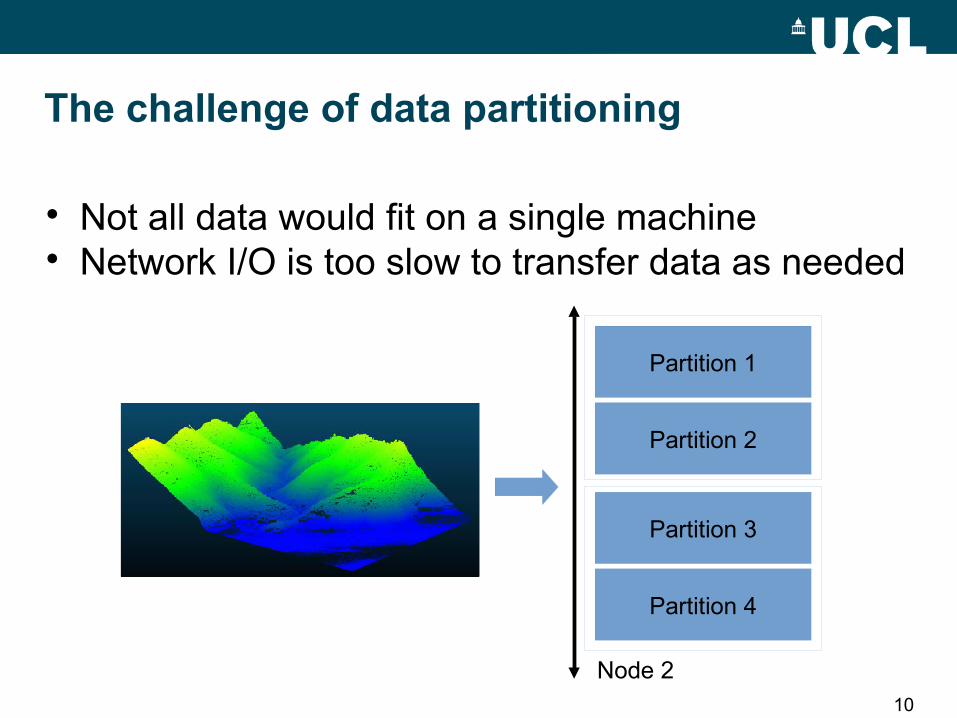
Not all data would fit on a single machine Network I/O is too slow to transfer data as needed
Partition 1
Partition 2
Partition 3
Partition 4
Node 2
The challenge of data partitioning
11
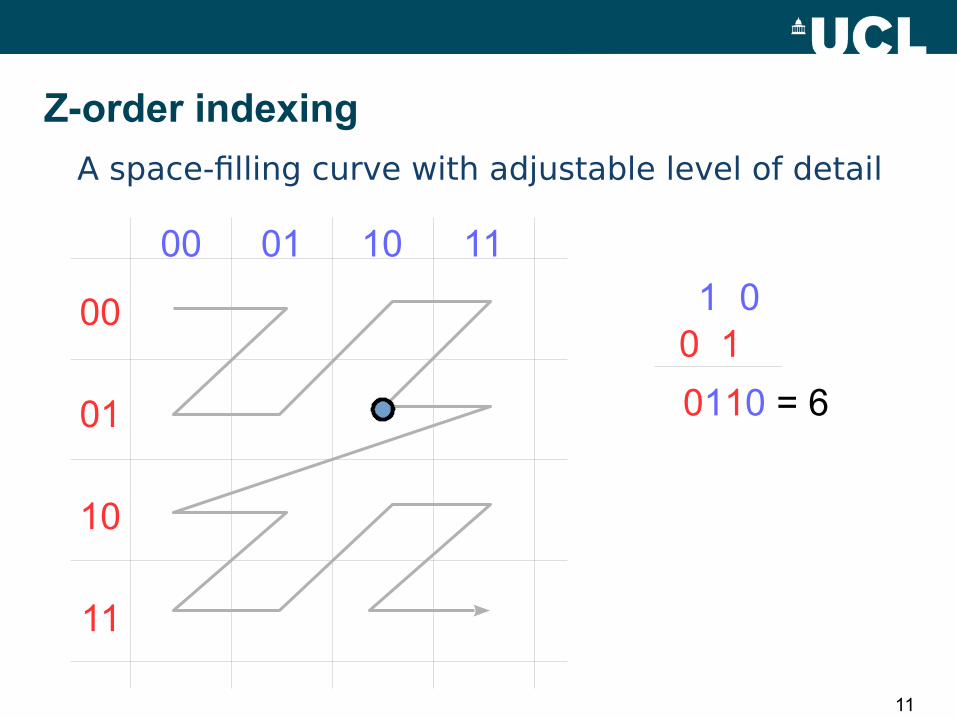
00 01 10 11
00
01
10
11
1 00 1
0110 = 6
A space-filling curve with adjustable level of detail
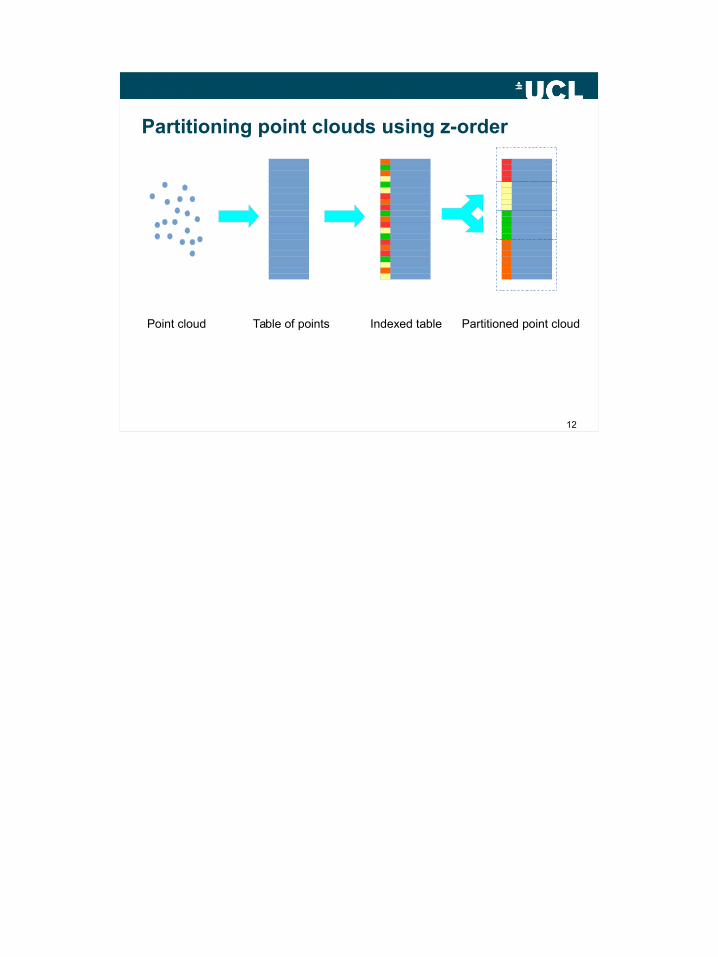
Z-order indexing
12
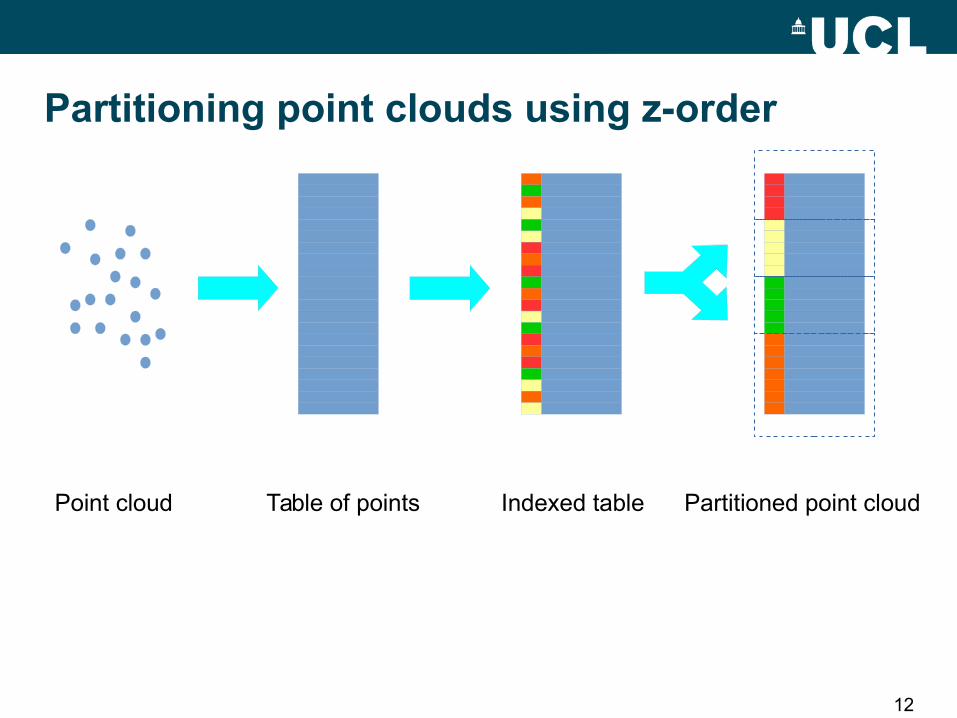
Point cloud Table of points Indexed table Partitioned point cloud
Partitioning point clouds using z-order
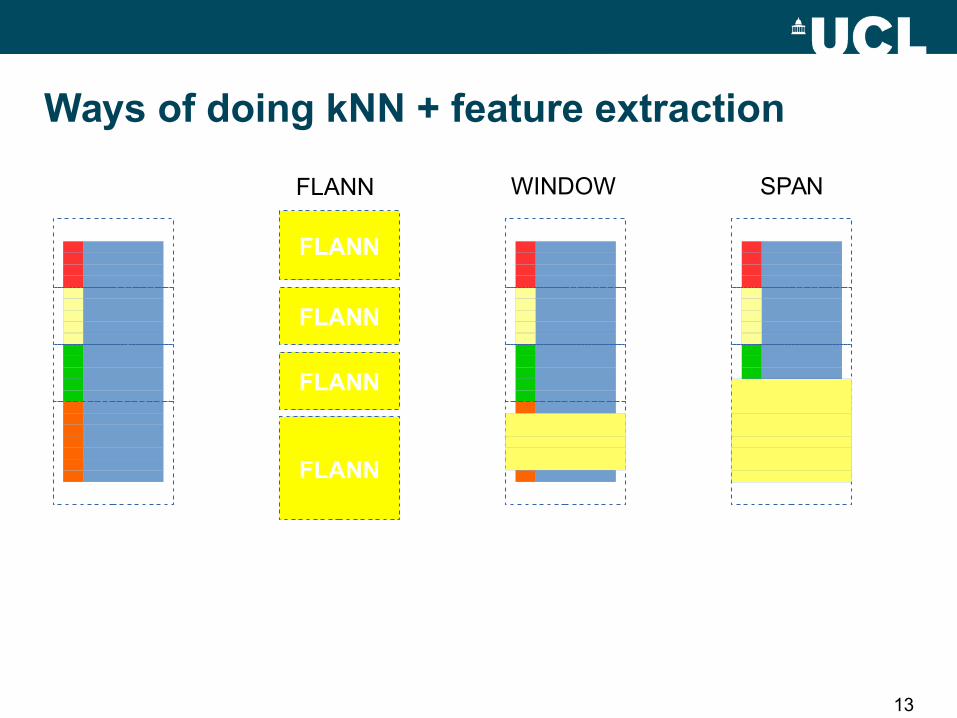
13
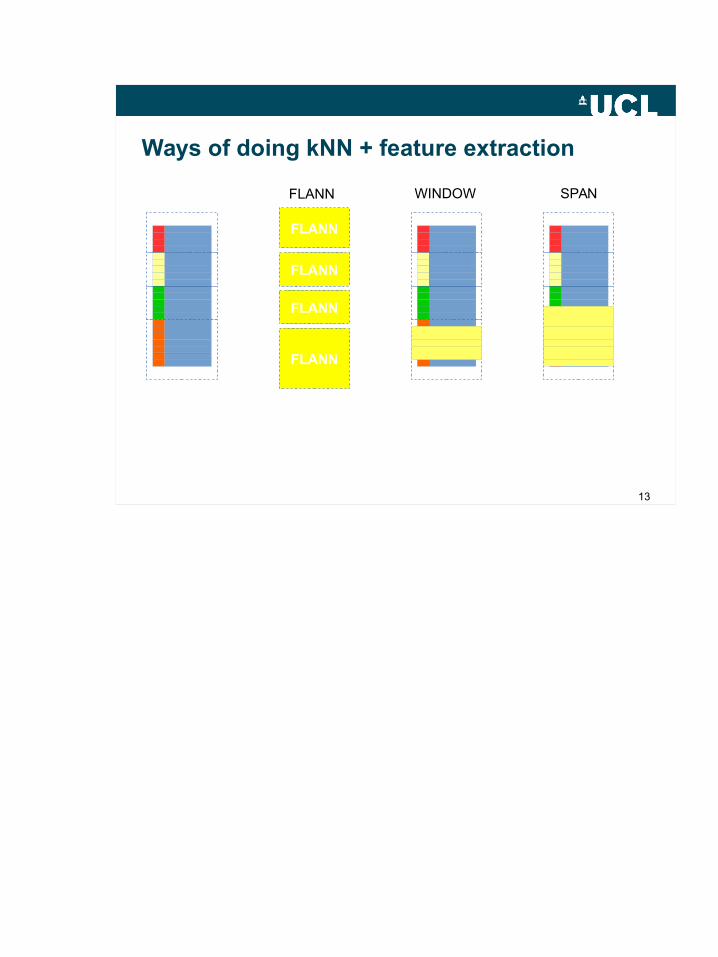
FLANN
FLANN
FLANN
FLANN
FLANN WINDOW SPAN
Ways of doing kNN + feature extraction
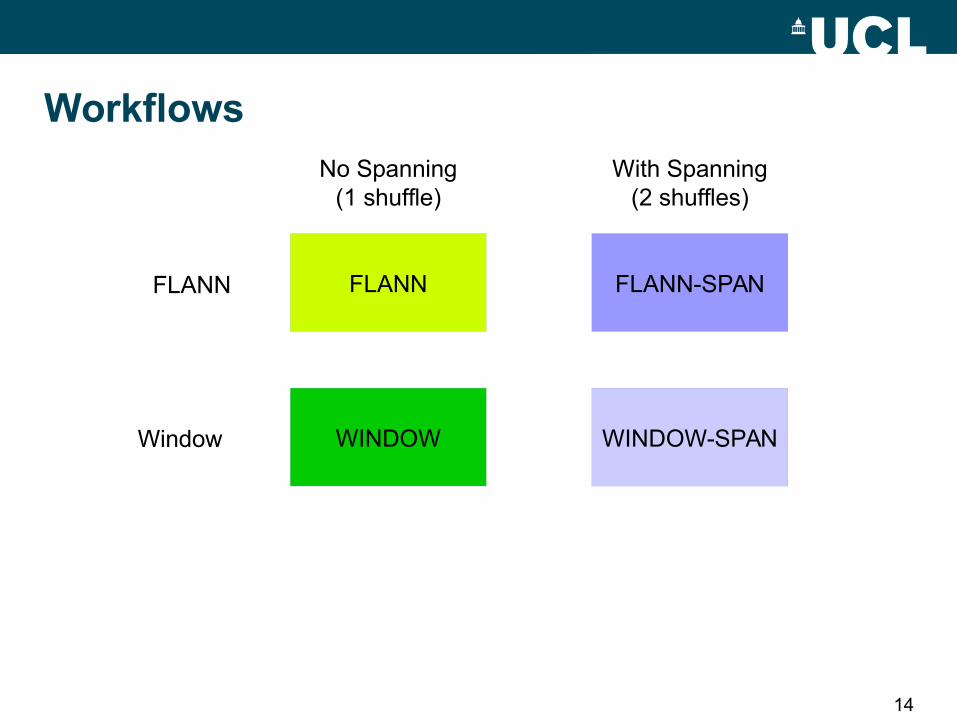
14
FLANN
Window
No Spanning(1 shuffle)
With Spanning(2 shuffles)
FLANN
WINDOW
FLANN-SPAN
WINDOW-SPAN
Workflows
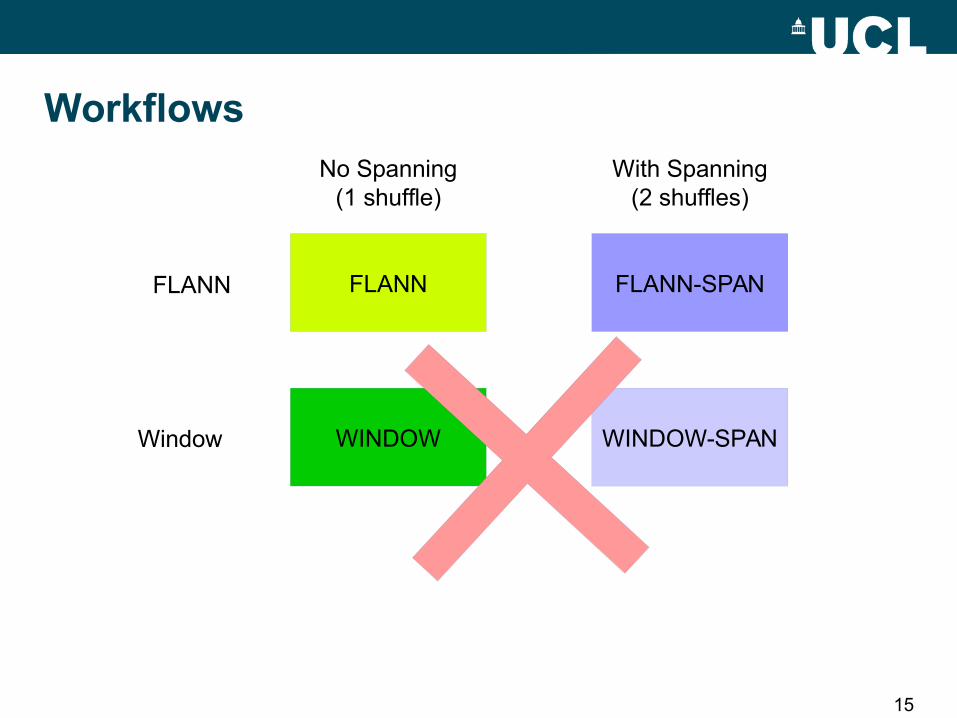
15
FLANN
Window
No Spanning(1 shuffle)
With Spanning(2 shuffles)
FLANN
WINDOW
FLANN-SPAN
WINDOW-SPAN
Workflows
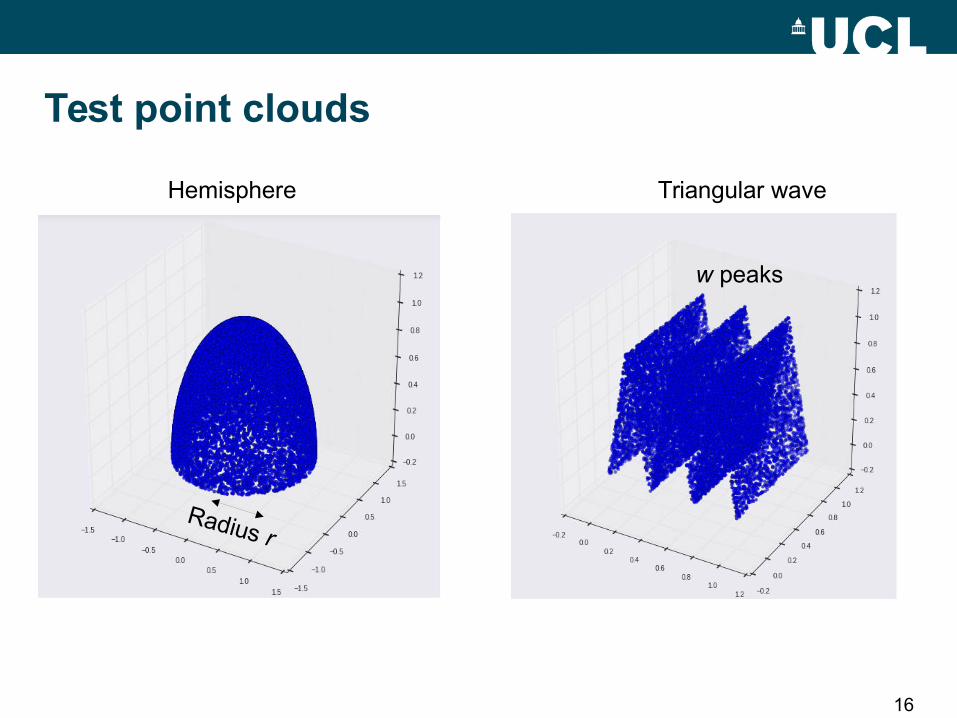
16
Hemisphere Triangular wave
Radius r
w peaks
Test point clouds

17
Accuracy at different pointsResults with or without spanning are similar
FLANN FLANN-SPAN FLANN FLANN-SPANHemispherical Triangular wave
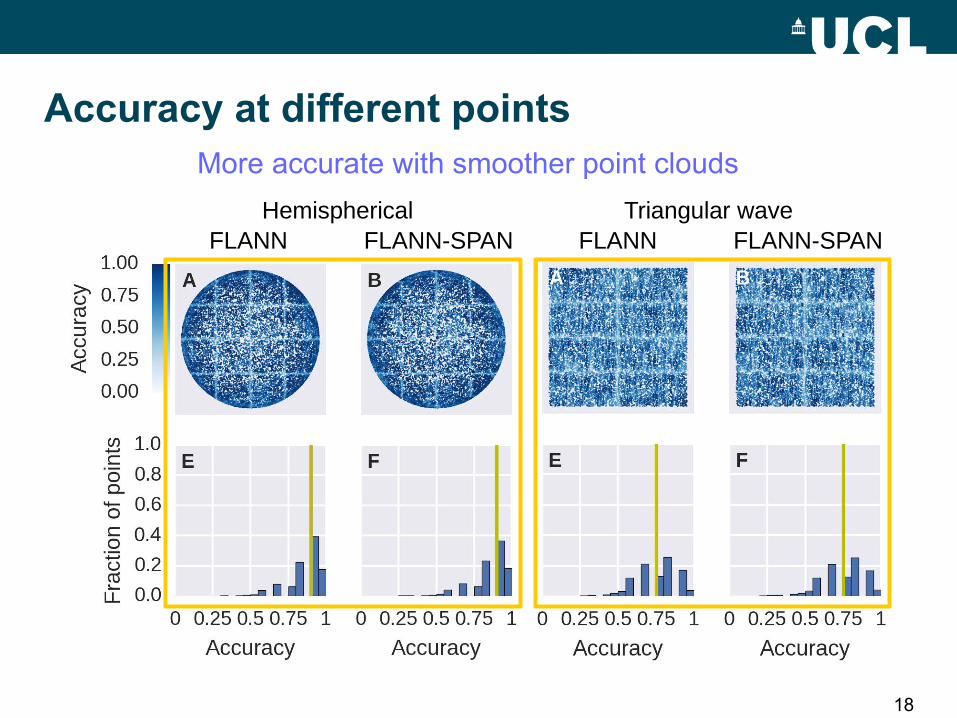
18
Accuracy at different pointsMore accurate with smoother point clouds
FLANN FLANN-SPAN FLANN FLANN-SPANHemispherical Triangular wave
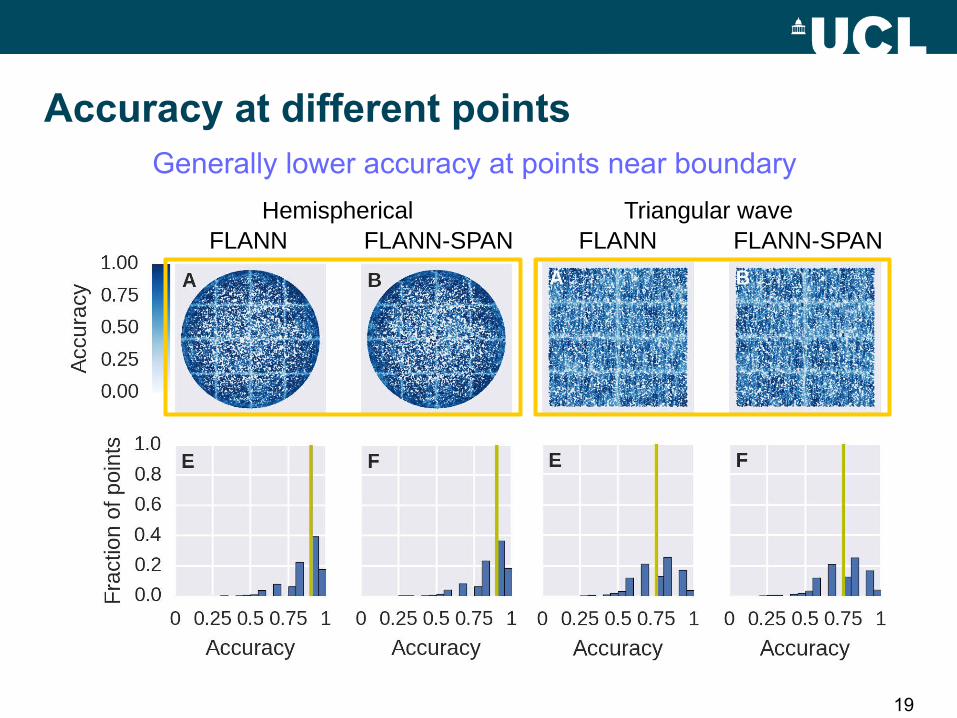
19
Accuracy at different pointsGenerally lower accuracy at points near boundary
FLANN FLANN-SPAN FLANN FLANN-SPANHemispherical Triangular wave
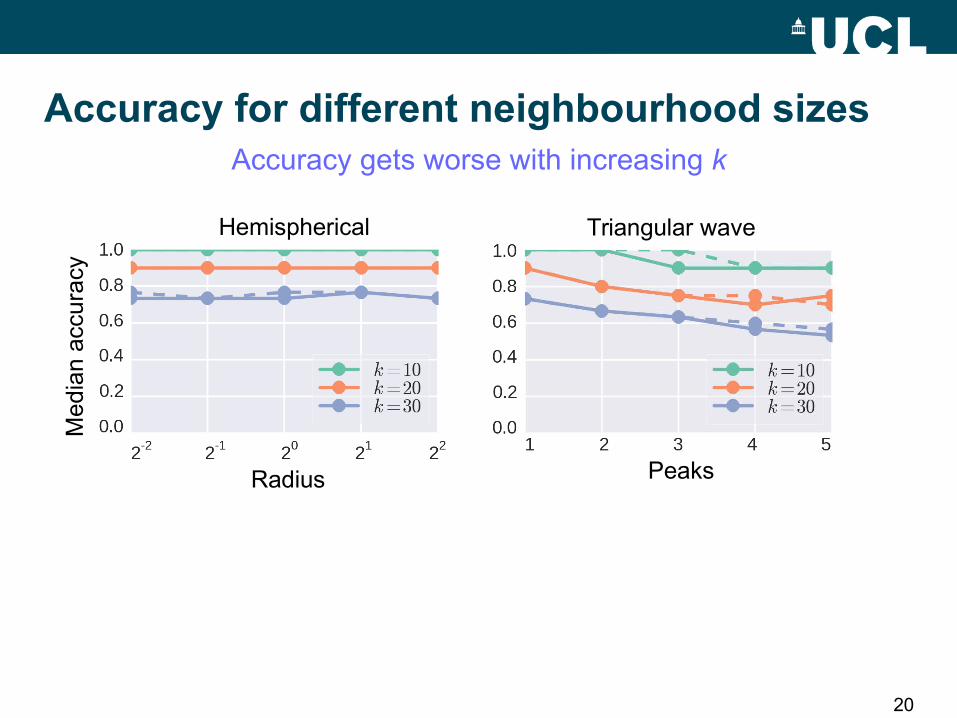
20
Radius Peaks
Med
ian
accu
racy
Accuracy for different neighbourhood sizes
Hemispherical
Accuracy gets worse with increasing k
Triangular wave

21
Spark MLlib machine learning library
Distributed machine learning library Supports DT, random forest and GBTree Interface similar to scikit-learn RDD and DataFrame-based interfaces

22
Tree/non-tree classification
Training set● Terramobilita/IQmulus data set (12M points)● ~200K tree points
Testing set● Toulouse data set● ~3M points per tile

23

24
0 5000 10000 15000 20000 250000
1000
2000
3000
4000
5000
6000
7000
8000
9000
Processing time vs. data size
1 Node
6 Nodes
12 Nodes
Input data size (MB)
Tim
e in s
ec
Linear scaling of running time with input data size
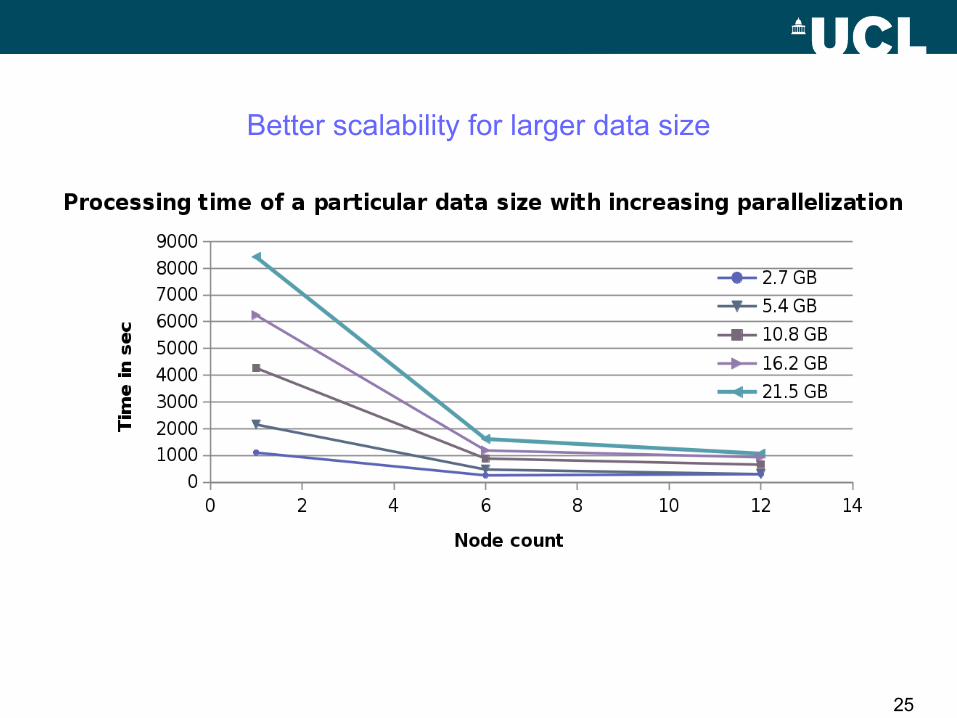
25
Better scalability for larger data size
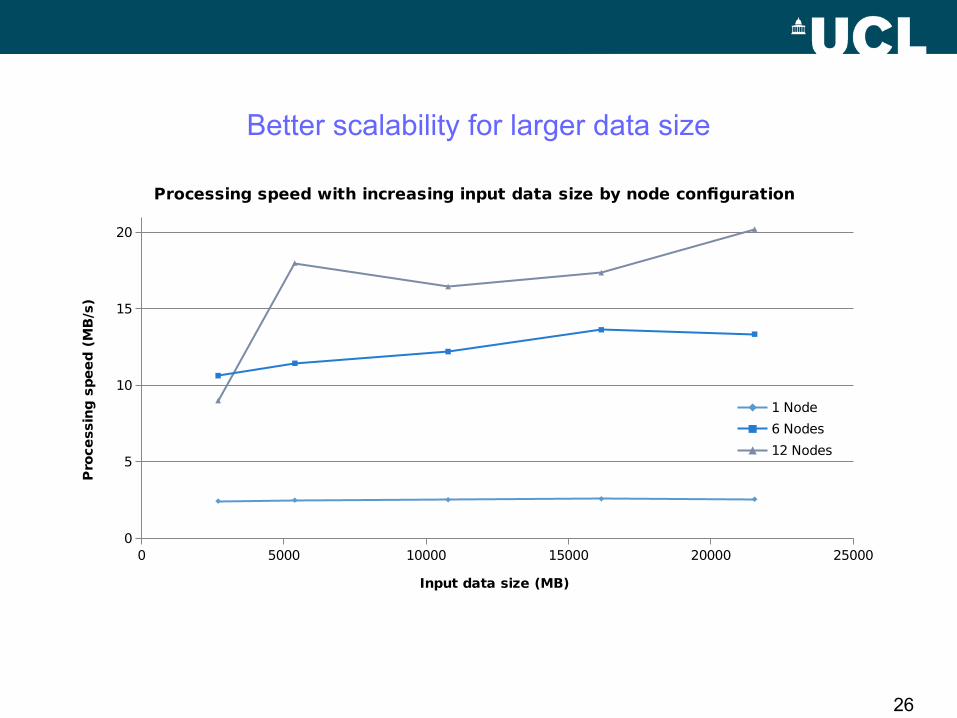
26
0 5000 10000 15000 20000 250000
5
10
15
20
Processing speed with increasing input data size by node configuration
1 Node
6 Nodes
12 Nodes
Input data size (MB)
Pro
cessin
g s
peed (
MB
/s)
Better scalability for larger data size

27
Random forests can be used to classify point clouds Distributed processing can be performed with Spark Z-order partitioning mitigates boundary error Spark MLlib allows scalable RF classification
Summary

Distributed Random Forest classification of urban mobile mapping data
Christian Alis, Jan Boehm, Kun LiuDept of Civil, Environmental and Geomatic EngineeringUniversity College London

2M. Weinmann, B. Jutzi, S. Hinz, and C. Mallet, ‘Semantic point cloud interpretation based on optimal neighborhoods, relevant features and efficient classifiers’, ISPRS Journal of Photogrammetry and Remote Sensing, vol. 105, pp. 286–304, Jul. 2015.

3
Features Label
Model
TrainedModel
Features Label
TR
AIN
ING
PR
ED
ICT
ION

4
Point cloud classification features
Linearity
Planarity
Scattering
Omnivariance
Anisotropy
Eigenentropy
Eigenvalue sum
Change of curvature
Z value
Radius
Density
Verticality
Z range
Z standard deviation
2D radius
2D density
2D eigenvalue sum
2D eigenvalue ratio
Features are computed based on neighbourhood of the point

5
Scattering > 0.5?
z > 0.5?
Linearity > 0.8?
Planarity > 0.5? Radius > 1?
Tree
Tree
Window Fence Tree Pole
Decision Tree
6
Random Forest
Trainedmodel
Training set
Bootstrap samples Decision
trees

7M. Weinmann, B. Jutzi, S. Hinz, and C. Mallet, ‘Semantic point cloud interpretation based on optimal neighborhoods, relevant features and efficient classifiers’, ISPRS Journal of Photogrammetry and Remote Sensing, vol. 105, pp. 286–304, Jul. 2015.
What if the point cloud consists of millions or billions of points?

8https://commons.wikimedia.org/wiki/File:BigData_2267x1146_white.png

GeoTrellis, SpatialSpark and Magellan provide support for raster and vector data

10
Not all data would fit on a single machine Network I/O is too slow to transfer data as needed
Partition 1
Partition 2
Partition 3
Partition 4
Node 2
The challenge of data partitioning

11
00 01 10 11
00
01
10
11
1 00 1
0110 = 6
A space-filling curve with adjustable level of detail
Z-order indexing
12
Point cloud Table of points Indexed table Partitioned point cloud
Partitioning point clouds using z-order
13
FLANN
FLANN
FLANN
FLANN
FLANN WINDOW SPAN
Ways of doing kNN + feature extraction

14
FLANN
Window
No Spanning(1 shuffle)
With Spanning(2 shuffles)
FLANN
WINDOW
FLANN-SPAN
WINDOW-SPAN
Workflows

15
FLANN
Window
No Spanning(1 shuffle)
With Spanning(2 shuffles)
FLANN
WINDOW
FLANN-SPAN
WINDOW-SPAN
Workflows

16
Hemisphere Triangular wave
Radius r
w peaks
Test point clouds

17
Accuracy at different pointsResults with or without spanning are similar
FLANN FLANN-SPAN FLANN FLANN-SPANHemispherical Triangular wave
18
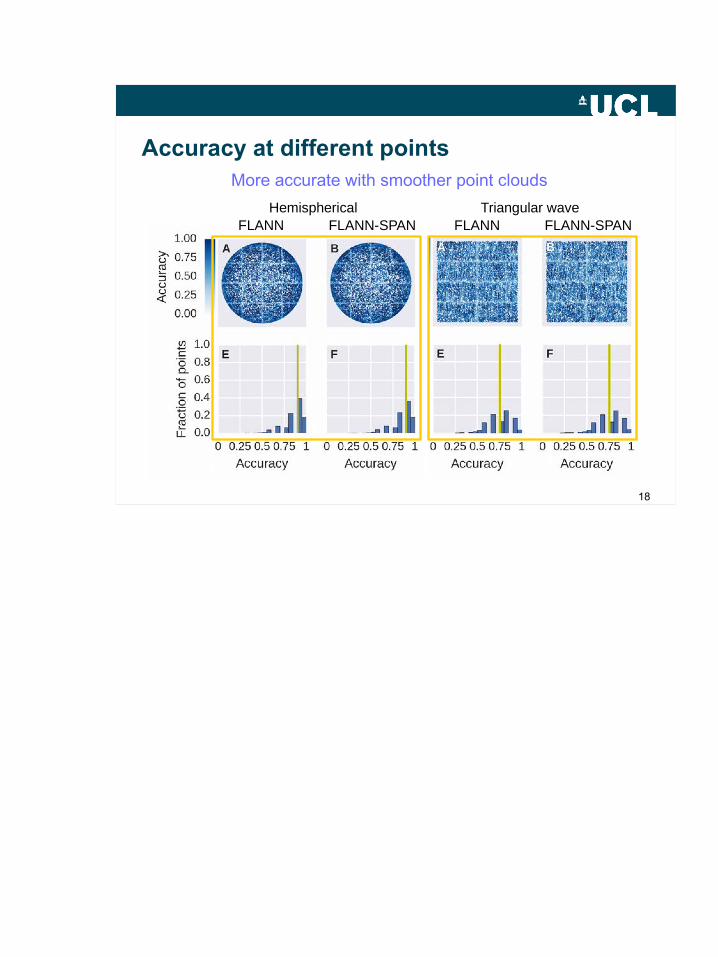
Accuracy at different pointsMore accurate with smoother point clouds
FLANN FLANN-SPAN FLANN FLANN-SPANHemispherical Triangular wave

19
Accuracy at different pointsGenerally lower accuracy at points near boundary
FLANN FLANN-SPAN FLANN FLANN-SPANHemispherical Triangular wave
20
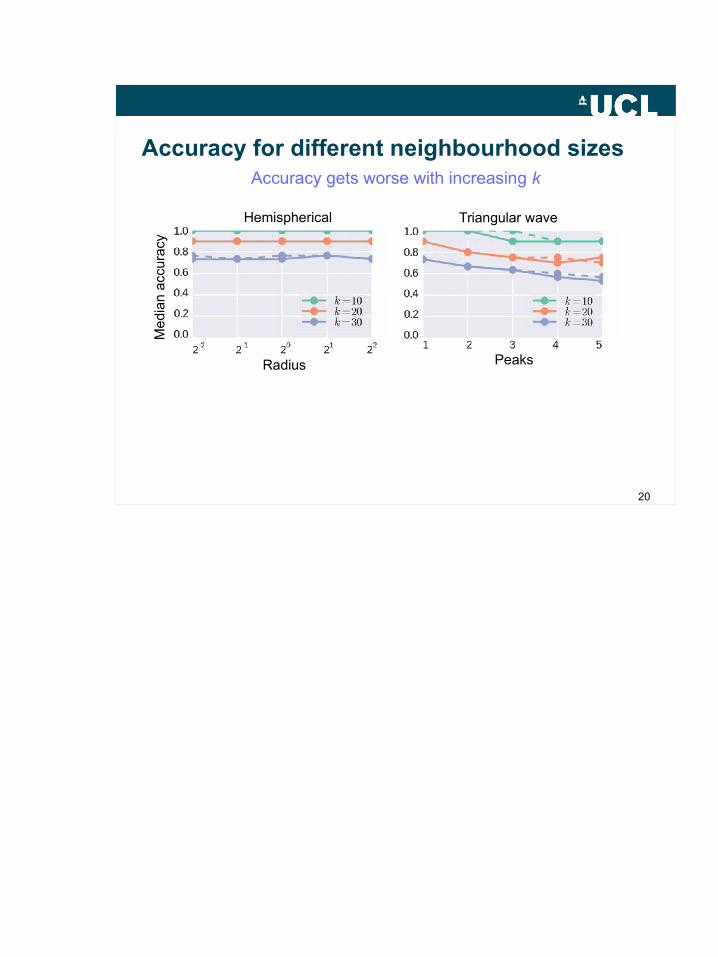
Radius Peaks
Me
dian
acc
urac
yAccuracy for different neighbourhood sizes
Hemispherical
Accuracy gets worse with increasing k
Triangular wave

21
Spark MLlib machine learning library
Distributed machine learning library Supports DT, random forest and GBTree Interface similar to scikit-learn RDD and DataFrame-based interfaces

22
Tree/non-tree classification
Training set● Terramobilita/IQmulus data set (12M points)● ~200K tree points
Testing set● Toulouse data set● ~3M points per tile

23
24
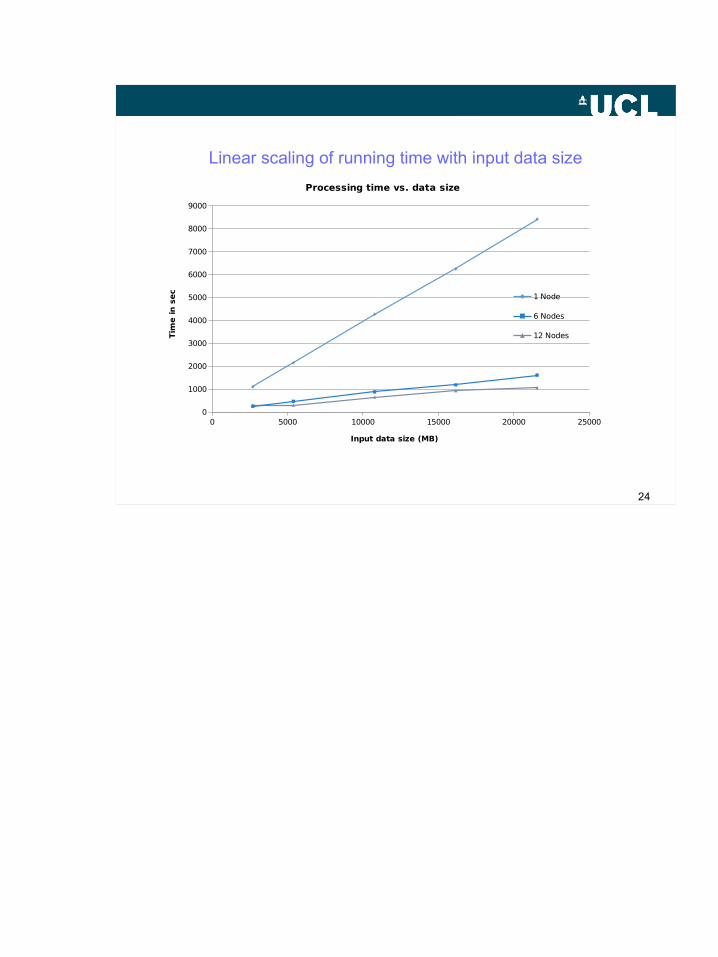
0 5000 10000 15000 20000 250000
1000
2000
3000
4000
5000
6000
7000
8000
9000
Processing time vs. data size
1 Node
6 Nodes
12 Nodes
Input data size (MB)
Tim
e in s
ec
Linear scaling of running time with input data size
25
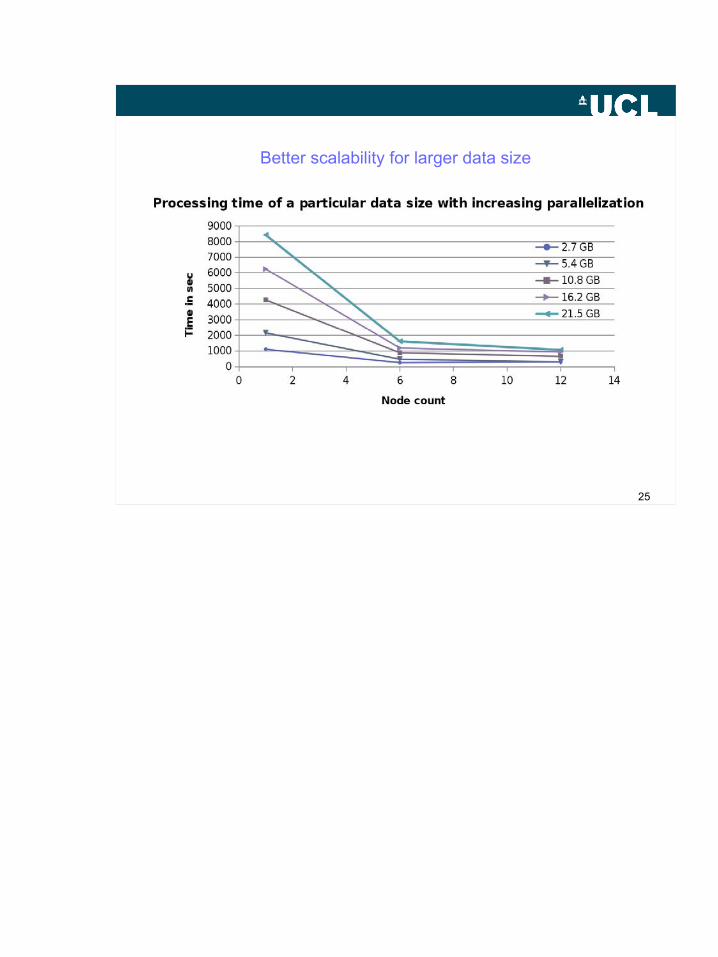
Better scalability for larger data size

26
0 5000 10000 15000 20000 250000
5
10
15
20
Processing speed with increasing input data size by node configuration
1 Node
6 Nodes
12 Nodes
Input data size (MB)
Pro
cessin
g s
peed (
MB
/s)
Better scalability for larger data size
27
Random forests can be used to classify point clouds Distributed processing can be performed with Spark Z-order partitioning mitigates boundary error Spark MLlib allows scalable RF classification
Summary




![THE KLEENE HIERARCHY CLASSIFICATION OF RECURSIVELY RANDOM ... · THE KLEENE HIERARCHY CLASSIFICATION OF RECURSIVELY RANDOM SEQUENCESO) BY D. W. LOVELAND Introduction. In [1], Church](https://img.pdfslide.us/doc/110x75/5c5dadff09d3f2dc448d2c35/the-kleene-hierarchy-classification-of-recursively-random-the-kleene-hierarchy.jpg)
























