Embed Size (px)
Citation preview

DISTRIBUTED DATABASE DESIGN

Distributed Database Design
• Introduction– Alternative design strategies
• Distribution design issues
• Data fragmentation
• Data allocation
DISTRIBUTED DATABASE DESIGN
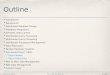
The organization of distributed systems can be investigated along three orthogonal dimensions:
1. Level of sharing
2. Behavior of access patterns
3. Level of knowledge on access pattern behavior

DISTRIBUTED DATABASE DESIGN
Level of sharing– no sharing - each application and its data execute at one site,
– data sharing - all the programs are replicated at all the sites, but data files are not,
– data plus program sharing - both data and programs may be shared.
Behavior of access patterns– static - access patterns of user requests do not change over time,
– dynamic - access patterns of user requests change over time.
Level of knowledge on access pattern behavior– complete information - the access patterns can reasonably be
predicted and do not deviate significantly from the predictions,
– partial information - there are deviation from the predictions.
ALTERNATIVE DESIGN STRATEGIESTwo major strategies that have been identified for designing distributed databases are:
• the top-down approach
• the bottom-up approach
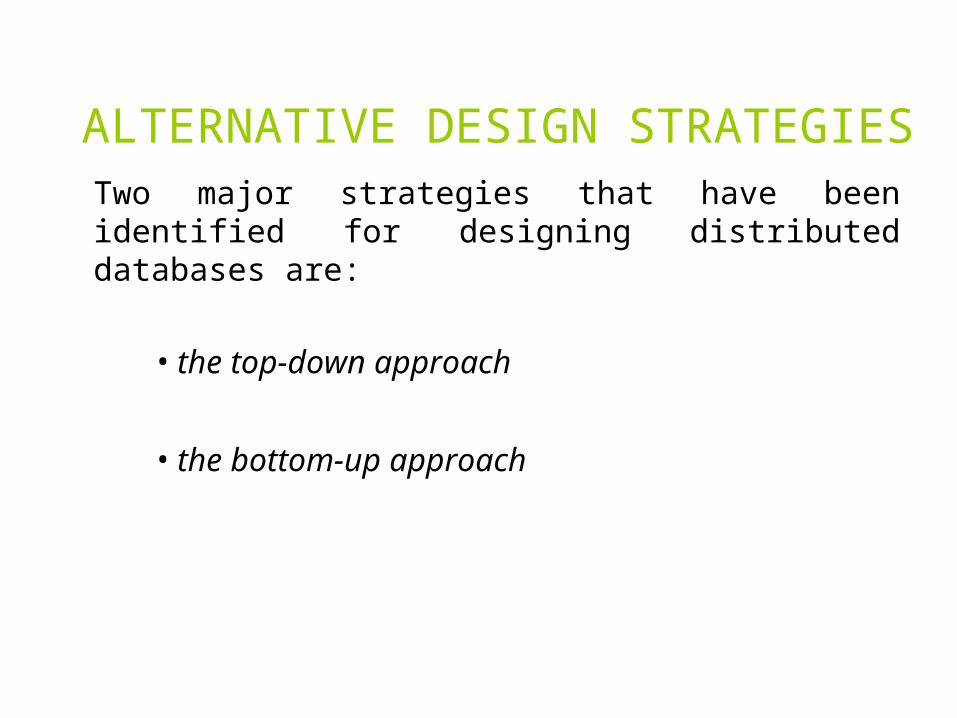
ALTERNATIVE DESIGN STRATEGIESTOP-DOWN DESIGN PROCESS

ALTERNATIVE DESIGN STRATEGIESTOP-DOWN DESIGN PROCESS
• view design - defining the interfaces for end users,
• conceptual design - is the process by which the enterprise is examined to determine entity types and relationships among these entities. One can possibly divide this process into to related activity groups:– entity analysis - is concerned with determining the entities, their
attributes, and the relationships among these entities,– functional analysis - is concerned with determining the
fundamental functions with which the modeled enterprise is involved.
The results of these two steps need to be cross-referenced to get a better understanding of which functions deal with which entities.

ALTERNATIVE DESIGN STRATEGIESTOP-DOWN DESIGN PROCESS• distributions design - design the local conceptual schemas
by distributing the entities over the sites of the distributed system. The distribution design activity consists of two steps:– fragmentation– allocation
• physical design - is the process, which maps the local conceptual schemas to the physical storage devices available at the corresponding sites,
• observation and monitoring - the results is some form of feedback, which may result in backing up to one of the earlier steps in the design.

ALTERNATIVE DESIGN STRATEGIESBOTTOM-UP DESIGN PROCESS
Top-down design is a suitable approach when a database system is being designed from scratch.
If a number of databases already exist, and the design task involves integrating them into one database - the bottom-up approach is suitable for this type of environment. The starting point of bottom-up design is the individual local conceptual schemas. The process consists of integrating local schemas into the global conceptual schema.

Fragmentation Alternatives
Horizontal Partitioning
JNO JNAME BUDGET LOCJ1 Instrumental 150,000 MontrealJ2 Database Dev. 135,000 New York
J1
JNO JNAME BUDGET LOCJ3 CAD/CAM 150,000 MontrealJ4 Maintenance. 310,000 Paris
J2
JNO JNAME BUDGET LOCJ1 Instrumental 150,000 MontrealJ2 Database Dev. 135,000 New YorkJ3 CAD/CAM 250,000 New YorkJ4 Maintenance 350,000 Paris
J
Vertical Partitioning
JNO BUDGET J1 150,000 J2 135,000 J3 250,000 J4 310,000
JNO JNAME LOC
J1 Instrumentation MontrealJ2 Database Devl New YorkJ3 CAD/CAM New YorkJ4 Maintenance Paris

DISTRIBUTION DESIGN ISSUESREASONS FOR FRAGMENTATION
• Why fragment at all?• How should we fragment?• How much should we fragment?• Is there any way to test the correctness of
decompositions?• How should we allocate?• What is the necessary information for
fragmentation and allocation?

Why fragment at all?
Reasons:
• Interquery concurrency
• Intraquery concurrency
Disadvantages:
• Vertical fragmentation may incur overhead.
• Attributes participating in a dependency may be allocated to different sites.
Integrity checking is more costly.

DISTRIBUTION DESIGN ISSUESREASONS FOR FRAGMENTATION
• The important issue is the appropriate unit of distribution. For a number of reasons it is only natural to consider subsets of relations as distribution units.
• If the applications that have views defined on a given relation reside at different sites, two alternatives can be followed, with the entire relation being the unit of distribution. The relation is not replicated and is stored at only one site, or it is replicated at all or some of the sites where the applications reside.
• The fragmentation of relations typically results in the parallel execution of a single query by dividing it into a set of sub queries that operate on fragments. Thus, fragmentation typically increases the level of concurrency and therefore the system throughput.

DISTRIBUTION DESIGN ISSUESREASONS FOR FRAGMENTATION
• There are also the disadvantages of fragmentation:– if the application have conflicting requirements which prevent
decomposition of the relation into mutually exclusive fragments, those applications whose views are defined on more than one fragment may suffer performance degradation,
– the second problem is related to semantic data control, specifically to integrity checking.

Degree of Fragmentation
•Application views are usually subsets of relations. Hence, it is only natural to consider subsets of relations as distribution units.
•The appropriate degree of fragmentation is dependent on the applications.

DISTRIBUTION DESIGN ISSUESFRAGMENTATION ALTERNATIVES
• The are clearly two alternatives:– horizontal fragmentation– vertical fragmentation
• The fragmentation may, of course, be nested. If the nestings are of different types, one gets hybrid fragmentation.

DISTRIBUTION DESIGN ISSUESDEGREE OF FRAGMENTATION
• The extent to which the database should be fragmented is an important decision that affects the performance of query execution.
• The degree of fragmentation goes from one extreme, that is, not to fragment at all, to the other extreme, to fragment to the level of individual tuples (in the case of horizontal fragmentation) or to the level of individual attributes (in the case of vertical fragmentation).

DISTRIBUTION DESIGN ISSUESCORRECTNESS RULES OF FRAGMENTATION
Completeness (ensure no loss of fragments)If a relation instance R is decomposed into fragments R1,R2, ..., Rn, each data item that can be found in R can also be found in one or more of Ri’s. This property is also important in fragmentation since it ensures that the data in a global relation is mapped into fragments without any loss. (lossless decomposition property)
Reconstruction (functional dependency preserved)If a relation R is decomposed into fragments R1,R2, ..., Rn, it should be possible to define a relational operator such that:
R = Ri, RiFR
The reconstruct ability of the relation from its fragments ensures that constraints defined on the data in the form of dependencies are preserved.

DISTRIBUTION DESIGN ISSUESCORRECTNESS RULES OF FRAGMENTATION
DisjointnessIf a relation R is horizontally decomposed into fragments R1,R2, ..., Rn and data item di is in Rj, it is not in any other fragment Rk (k j). This criterion ensures that the horizontal fragments are disjoint. If relation R is vertically decomposed, its primary key attributes are typically repeated in all its fragments. Therefore, in case of vertical partitioning, disjointness is defined only on the nonprimary key attributes of a relation.

DISTRIBUTION DESIGN ISSUESALLOCATION ALTERNATIVES
• The reasons for replication are reliability and efficiency of read-only queries.
• Read-only queries that access the same data items can be executed in parallel since copies exist on multiple sites.
• The execution of update queries cause trouble since the system has to ensure that all the copies of the data are updated properly.
• The decisions regarding replication is a trade-off which depends on the ratio of the read-only queries to the update queries.

DISTRIBUTION DESIGN ISSUESALLOCATION ALTERNATIVES
• A nonreplicated database (commonly called a partitioned database) contains fragments that are allocated to sites, and there is only one copy of any fragment on the network.
• In case of replication, either the database exists in its entirety at each site (fully replicated database), or fragments are distributed to the sites in such a way that copies of a fragment may reside in multiple sites (partially replicated database).

DISTRIBUTION DESIGN ISSUESALLOCATION ALTERNATIVES

DISTRIBUTION DESIGN ISSUESINFORMATION REQUIREMENTS
• The information needed for distribution design can be divided into four categories:– database information,– application information,– communication network information,– computer system information.

DISTRIBUTION DESIGN ISSUES FRAGMENTATION
• Horizontal fragmentation partitions a relation along its tuples
• Two versions of horizontal fragmentation
– Primary horizontal fragmentation of relation is performed using predicates that are defined on that relation
– Derived fragmentation is the partitioning of relation that results from predicates being defined on another relation

DISTRIBUTION DESIGN ISSUES FRAGMENTATION
• Vertical fragmentation partitions a relation into a set of smaller relations so that many of users aplications will run on only one fragment
• Vertical fragmentation is inherently more complicated than horizontal partitioning

DISTRIBUTION DESIGN ISSUESALLOCATION
• Allocation problem– there are set of fragments F= { F1, F2, ... , Fn } and
network consisiting of sites S = { S1, S2, ... , Sm } on wich sets aplications Q= { q1, q2, ... , qq } is running
– The allocation problem involves finding the “optimal” distribution of F to S

DISTRIBUTION DESIGN ISSUESALLOCATION
• One of important issues that need to be discussed is the definition of optimality
• The optimality can be defined with respects of two measures [ Dowdy and Foster, 1982 ]– Minimal cost. The cost consists of the cost of storing
each Fi at the site Sj, the cost of quering Fi at Sj, the cost of updating Fi, at all sites it is stored, and cost of data comunication. The allocation problem,then, attempts to find an alocations scheme that minimizes cost function.

DISTRIBUTION DESIGN ISSUESALLOCATION
– Perfomance. The allocation strategy is designed to maintain a performance mertic. Two well-known are to minimize the response time and to maximize the system throughput at each site

A Fragment is a subset of a relation that is stored on a different site from another subset of the same relation.
1- Why

• For large organizations, increased pressure of users• Localization of Data and Local Autonomy• Increased time/NW cost of centralized access• Increased chances of failure• Increased failure damage• Distribution of data allows fast access of data due to
localization• Parallel execution of queries

2- How

• Unit of Fragmentation– Entire table is not a suitable unit

Fragmentation Alternatives

1- Vertical; Different subsets of attributes are stored at different places, like,
Table EMP(eId, eName, eDept, eQual, eSal)
Interests of the local and head offices may result following vertical partitions of this table:
EMP1(eId, eName, eDept)
EMP2(eId, eQual, eSal)

• 2- Horizontal Fragmentation: • based on the localization of data rows of a table
are split on multiple sites, like the data in .
• CLIENT(cAC#, cName, cAdr, cBal) table is placed in different databases based on their location,
• like from Lahore, Pindi, Karachi, Peshawar, Quetta

3- Degree of Fragmentation Between no to the extreme level that could be to the
individual tuple or column level; a compromised decision

4- Correctness Rules for Fragmentation

If a relation R is fragmented into R1, R2, …, Rn, then
• Completeness: each of the data item (a tuple or a attribute) that can be in R can also be in one or more Ri
∀ x R, R∈ ∃ i such that x R∈ i

• Reconstruction: it should be possible to define a relational operator such that the original relation can be reconstructed
R = g(R1, R2, …, Rn)

• Disjointness: if data item x is in Rj, it is not in any other fragment
∀ x R∈ i, R∃ j such that x ∈Rj, i ≠ j

5- Allocation Strategy: Partitioned, fully or partially replicated; depends mainly on requirements.

6:- Information Requirements: Different; discussed in each case individually

Horizontal Fragmentation

• Partitions a table along its tuples
• is performed based on some Predicate/ Condition

Primary: Predicate defined on the same relation
Derived: Predicate defined on another relation

Primary Horizontal Fragmentation(PHF)

Information Requirements

Database Information: We may need to consult the conceptual DB design.
Apart from tables, we need relationships, cardinality and the owner and member tables
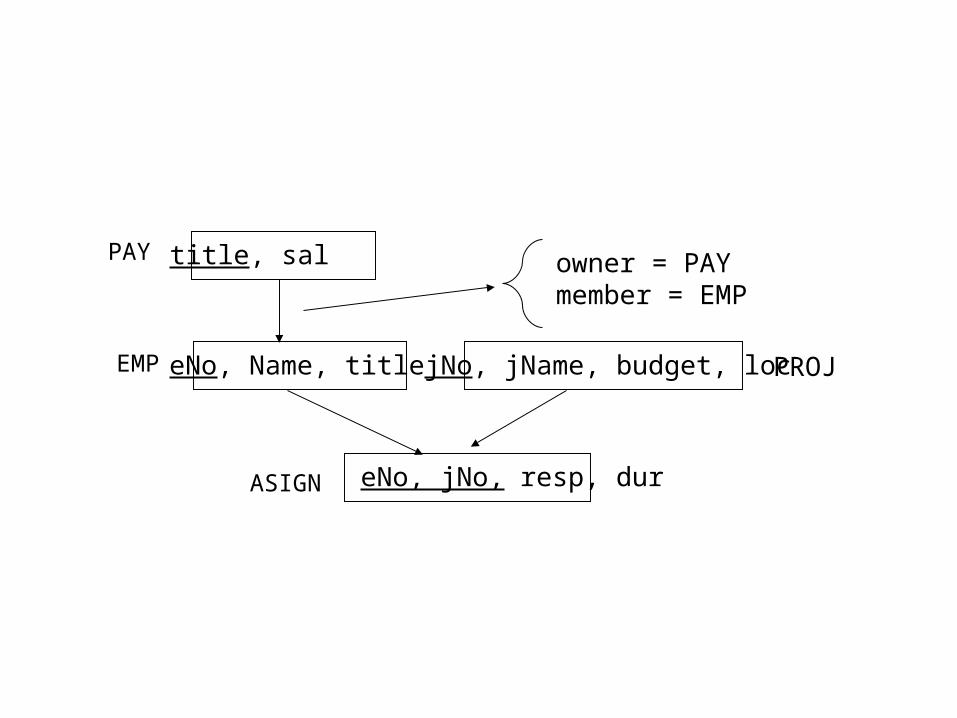
owner = PAYmember = EMP
title, sal
eNo, Name, title jNo, jName, budget, loc
eNo, jNo, resp, dur
PAY
EMP
ASIGN
PROJ

Application Requirement

1- Major simple predicates used in the user queries.

Given a relation R(A1, A2, …, An), where Ai is attribute with domain Di, then a simple predicate pj has the form.
pj: Ai θ Value,
where θ {=, <, ≠≤, >, ≥} and Value ∈ D∈ i
lnName = “Housing”, lnAmount > 200,000