Embed Size (px)
Citation preview

Discovering Localized Attributes for Fine-grained Recognition
Kun DuanIndiana UniversityBloomington, [email protected]
Devi ParikhTTI-ChicagoChicago, IL
David CrandallIndiana UniversityBloomington, IN
Kristen GraumanUniversity of Texas
Austin, [email protected]
Abstract
Attributes are visual concepts that can be detected bymachines, understood by humans, and shared across cat-egories. They are particularly useful for fine-grained do-mains where categories are closely related to one other (e.g.bird species recognition). In such scenarios, relevant at-tributes are often local (e.g. “white belly”), but the ques-tion of how to choose these local attributes remains largelyunexplored. In this paper, we propose an interactive ap-proach that discovers local attributes that are both discrim-inative and semantically meaningful from image datasetsannotated only with fine-grained category labels and objectbounding boxes. Our approach uses a latent conditionalrandom field model to discover candidate attributes that aredetectable and discriminative, and then employs a recom-mender system that selects attributes likely to be seman-tically meaningful. Human interaction is used to providesemantic names for the discovered attributes. We demon-strate our method on two challenging datasets, Caltech-UCSD Birds-200-2011 and Leeds Butterflies, and find thatour discovered attributes outperform those generated bytraditional approaches.
1. IntroductionMost image classification and object recognition ap-
proaches learn statistical models of low-level visual fea-tures like SIFT and HOG. While these approaches givestate-of-the-art results in many settings, such low-level fea-tures and statistical classification models are meaninglessto humans, thus limiting the ability of humans to under-stand object models or to easily contribute domain knowl-edge to recognition systems. Recent work has introducedvisual attributes as intermediate-level features that are bothmachine-detectable and semantically meaningful (e.g. [2, 3,6, 9, 11, 14, 27]). Attributes help to expose the details of anobject model in a way that is accessible to humans: in birdspecies recognition, for example, they can explicitly modelthat a cardinal has a “red-orange beak,” “red body,” “sharp
red stripes on wings orange stripes on wings
white belly yellow belly
Figure 1. Sample local and semantically meaningful attributes au-tomatically discovered by our approach. The names of the at-tributes are provided by the user-in-the-loop.
crown,” “black face,” etc. Attributes are particularly attrac-tive for fine-grained domains like animal species where thecategories are closely related, so that a common attributevocabulary exists across categories. Attributes also enableinnovative applications like zero-shot learning [15, 18] andimage-to-text generation [6, 18].
So where do these attributes come from? Most existingwork uses hand-generated sets of attributes (e.g. [3, 14]), butcreating these vocabularies is time-consuming and often re-quires a domain expert (e.g. an ornithologist familiar withthe salient parts of a bird). Moreover, while these attributesare guaranteed to be human-understandable (which sufficesfor human-in-the-loop classification applications [3]), theymay not be machine-detectable and hence may not workwell in automatic systems. Some recent work has discov-ered image-level attributes (e.g. “outdoors” or “urban”) au-tomatically [17], but such global attributes are of limited usefor fine-grained object classification in which subtle differ-ences between object appearances are important.
Discovering local attributes (like those illustrated in Fig-ure 1) is significantly harder because a local attribute mightcorrespond to features at different unknown positions andscales across images. Automatic techniques to do this havegenerally either found attributes that are discriminative orthat are meaningful to humans, but not both. Finding dis-
1

criminative local regions (e.g. [27]) works well for attaininggood image classification performance, but the regions maynot be semantically meaningful and thus not useful for ap-plications like zero-shot learning and automatic image de-scription. On the other hand, mining text can produce at-tribute vocabularies that are meaningful (e.g. [2]) but notnecessarily complete, discriminative, or detectable.
In this paper, we propose an interactive system thatdiscovers discriminative local attributes that are bothmachine-detectable and human-understandable from an im-age dataset annotated with fine-grained category labels andobject bounding boxes. At each iteration in the discoveryprocess, we identify two categories that are most confusablegiven the attributes that have been discovered so far; we callthese two categories an active split. We use a latent con-ditional random field model to automatically discover can-didate local attributes that separate these two classes. Forthese candidates, we use a recommender system to iden-tify those that are likely to be semantically meaningful toa human, and then present them to a human user to collectattribute names. Candidates for which the user can give aname are added to the pool of attributes, while unnamedones are ignored. In either case, the recommender sys-tem’s model of semantic meaningfulness is updated usingthe user’s response. Once the discovery process has built avocabulary of local attributes, these attributes are detectedin new images and used for classification.
To the best of our knowledge, ours is the first sys-tem to discover vocabularies of local attributes that areboth machine-detectable and human-understandable, andthat yield good discriminative power on fine-grained recog-nition tasks. We demonstrate our approach through sys-tematic experiments on two challenging datasets: Caltech-UCSD Birds-200-2011 [22] and Leeds Butterflies [24]. Wefind on these datasets that our discovered local attributesoutperform those generated by human experts and by otherstrong baselines, on fine-grained image classification tasks.
2. Related workVisual attributes for classification and recognition have
received significant attention over the last few years. Muchof this work assumes that the attribute vocabulary is definedahead of time by a human expert [3, 14, 15, 25]. An ex-ception is the work of Parikh and Grauman [17] which pro-poses a system that discovers the vocabulary of attributes.Their system iteratively selects discriminative hyperplanesbetween two sets of images (corresponding to two differentsubsets of image classes) using global image features (e.g.color, GIST); it would be difficult to apply this approach tofind local attributes because of the exponential number ofpossible local regions in each image.
A few papers have studied how to discover local at-tributes. Berg et al. [2] identify attributes by mining text
and images from the web. Their approach is able to lo-calize attributes and rank them based on visual character-istics, but these attributes are not necessarily discrimina-tive and thus may not perform well for image classifica-tion; they also require a corpus of text and images, whilewe just need images. Wang and Forsyth [23] present a mul-tiple instance learning framework for both local attributesand object classes, but they assume attribute labels for eachimage are given. In contrast, our approach does not requireattribute labels; we discover these attributes automatically.
Related to our work on local attribute selection is the ex-tensive literature on learning part-based object models forrecognition (e.g. [7, 8, 26]). These learning techniquesusually look for highly distinctive parts – regions that arecommon within an object category but rare outside of it –and they make no attempt to ensure that the parts of themodel actually correspond to meaningful semantic parts ofan object. Local attribute discovery is similar in that we tooseek distinctive image regions, but we would like these re-gions to be shared across categories and to have semanticmeaning. Note that while most semantically meaningful lo-cal attributes are likely to correspond to semantic parts ofobjects, we view attributes as more general: an attribute ispotentially any visual property that humans can preciselycommunicate or understand, even if it does not correspondto a traditionally-defined object part. For example “red-dotin center of wings” is a valid local attribute, even thoughthere is not a single butterfly part that corresponds to it.
Finally, our work is also related to the literature on au-tomatic object discovery and unsupervised learning of ob-ject models [4, 12, 16]. However, these methods aim tofind objects that are common across images, while we areinterested in finding discriminative local regions that willmaximize classification performance.
3. ApproachWe first consider the problem of finding discriminative
and machine-detectable visual attributes in a set of trainingimages. We then describe a recommender system that findscandidates that are likely to be human-understandable andpresents them to users for human verification and naming.
3.1. Latent CRF model formulation
We assume that each image in the training set has beenannotated with a class label (e.g. species of bird) and ob-ject bounding box similar to [24, 27],1 but that the set ofpossible attributes and the attribute labels for each imageare unknown. We run a hierarchical segmentation algo-rithm on the images to produce regions at different scales,and assume that any attribute of interest corresponds to atmost one region in each image. This assumption reduces the
1[24] in fact requires the user to interactively segment the object out.

computational complexity and is reasonable because the hi-erarchical segmentation gives regions at many scales.
Formally, we are given a set of annotated training imagesI = (I1, . . . , IM ), with each exemplar Ii = (Ii, yi) con-sisting of an image Ii and a corresponding class label yi.For now we assume a binary class label, yi ∈ {+1,−1};we will generalize this to multiple classes in Section 3.4.Each image Ii consists of a set of overlapping multi-scaleregions produced by the hierarchical segmentation. To finda discriminative local attribute for these images, we look forregions in positive images, one per image, that are similar toone another (in terms of appearance, scale and location) butnot similar to regions in negative images. We formulate thistask as an inference problem on a latent conditional randomfield (L-CRF) [19], the parameters of which we learn via adiscriminative max-margin framework in the next section.
First consider finding a single attribute k for the trainingset I. For each image we want to select a single region lki ∈Ii such that the selected regions in the positive images havesimilar appearances to one another, but are different fromthose on the negative side. We denote the labeling for theentire training set as Lk = (lk1 , . . . , l
kM ), and then formulate
this task in terms of minimizing an energy function [5],
E(Lk|I) =M∑i=1
φk(lki |Ii) +M∑i=1
M∑j=1
ψk(lki , lkj |Ii, Ij), (1)
where φk(lki |Ii) measures the preference of a discrimina-tive classifier trained on the selected regions to predict thecategory labels, while ψk(lki , l
kj |Ii, Ij) measures pairwise
similarities and differences between the selected regions. Inparticular, we define the unary term as,
φk(lki |Ii) = −yiwTk · f(lki ) (2)
where f(lki ) denotes a vector of visual features for regionlki and wk is a weight vector. We will use several differenttypes of visual features, as discussed in Section 4; for nowwe just assume that there are d feature types that are con-catenated together into a single n-dimensional vector. Theweights are learned as an SVM on the latent regions frompositive and negative images (discussed in Section 3.2).
The pairwise consistency term is given by,
ψk(lki , lkj |Ii, Ij) =
~α+k ·D(f(lki ), f(lkj )) + β+
k if yi, yj = +1β0k if yi, yj = −1
~α−k ·D(f(lki ), f(lkj )) + β−k otherwise,(3)
where D(·, ·) is a function Rn × Rn → Rd that given twofeature vectors computes a distance for each feature type,~α−k and ~α+
k are weight vectors, and ~βk = (β−k , β+k , β0
k)are constant bias terms (all learned in Section 3.2). Thispairwise energy function encourages similarity among re-gions in positive images and dissimilarity between positive
Latent RegionImageClass Label
y=−1y=+1
Figure 2. Our L-CRF model for one active split with K = 2 at-tributes, where white circles represent latent region variables (lki ),shaded circles represent observed image features (Ii), and squaresrepresent observed image class labels (yi).
and negative regions. We allow negative regions to be dif-ferent from one another since they serve only as negativeexemplars; thus we use a constant β0
k as the edge potentialbetween negative images in lieu of a similarity constraint.
The energy function presented in equation (1) definesa first-order Conditional Random Field (CRF) graphicalmodel. Each vertex of the model corresponds to an im-age, and the inference problem involves choosing one ofthe regions of each image to be part of the attribute. Edgesbetween nodes reflect pairwise constraints across images,where here we use a fully-connected graphical model suchthat there is a constraint between every image pair.
The single attribute candidate identified by the L-CRFmay not necessarily be semantically meaningful, but theremay be other candidates that can discriminate between thetwo categories that are semantically meaningful. To in-crease the chances of finding these, we wish to identify mul-tiple candidate attributes. We generalize the above approachto select K≥2 attributes for a given split by introducing anenergy function that sums equation (1) over allK attributes.We encourage the CRF to find a set of diverse attributes byadding an additional term that discourages spatial overlapamong selected regions,
E(L|I) =K∑k=1
E(Lk|I) +M∑i=1
∑k,k′
δ(lki , lk′
i |Ii), (4)
where L = (L1, . . . , LK) denotes the latent region vari-ables, δ measures spatial overlap between two regions,
δ(lki , lk′
i |Ii) = σ · area(lki ∩ lk′
i )area(lki ∪ lk
′i ), (5)
and σ ≥ 0 is a scalar which is also learned in the next sec-tion. This term is needed because we want a diverse setof candidates; without this constraint, the CRF may find a

Figure 3. Sample latent region evolution on an active split, acrossthree iterations (top to bottom). The latent region selected by theCRF on each positive image in each iteration is shown. Thesevariables converged after three iterations to roughly correspond tothe bird’s red head. Best viewed on-screen and in color.
set of very similar candidates because those are most dis-criminative. Intuitively, δ(·) penalizes the total amount ofoverlap between regions selected as attributes. Minimiz-ing the energy in equation (4) also corresponds to an infer-ence problem on a CRF; one can visualize the CRF as athree-dimensional graph withK layers, each correspondingto a single attribute, with the edges in each layer enforc-ing the pairwise consistency constraints ψ among trainingimages and the edges between layers enforcing the anti-overlap constraints δ. The vertices within each layer forma fully-connected subgraph, as do the vertices across layerscorresponding to the same image. Figure 2 illustrates theCRF for the case of two attributes.
3.2. Training
There are two sets of model parameters that must belearned: the weight vectors wk in the unary potential of theCRF, and the parameters of the pairwise potentials ψ and δwhich we can concatenate into a single vector ~α,
~α = (~α−1 , . . . , ~α−K , ~α
+1 , . . . , ~α
+K ,~β1, . . . , ~βK , σ).
We could easily learn these parameters if we knew thecorrect values for the latent variables L, and we could per-form CRF inference to estimate the values of the latentvariables if we knew the parameters. To solve for both,we take an iterative approach in the style of Expectation-Maximization. We initialize the latent variables L to ran-dom values. We then estimate wk in equation (2) for eachk by learning a linear SVM on the regions in Lk, usingregions in positive images as positive exemplars and re-gions in negative images as negative exemplars. Holdingwk fixed, we then estimate the pairwise parameters ~α via astandard latent structural SVM (LSSVM) framework,
min~αλ‖~α‖2 + ξ, such that ∀li ∈ Ii, ∀yi ∈ {+1,−1}, (6)
E({li}|{(Ii, yi)})−minL∗
E(L∗|I) ≥ ∆({yi}, {yi})− ξ
where ξ ≥ 0 is a slack variable and the loss function is
defined as the number of mislabeled images,
∆({yi}, {yi}) =∑i
1yi 6=yi.
We solve this quadratic programming problem usingCVX [10]. Since there are an exponential number ofconstraints in equation (6), we follow existing work onstructured SVMs [21] and find the most violated con-straints, in this case using tree-reweighted message passing(TRW) [13] on the CRF. Once the CRF parameters havebeen learned, we hold them fixed and estimate new val-ues for the latent variables L by performing inference usingTRW. This process of alternating between estimating CRFparameters and latent variable values usually takes 3 to 5 it-erations to converge (Figure 3). In our experiments we useK = 5. This takes about 3-5 minutes on a 3.0GHz server.
The above formulation was inspired by Multiple InstanceCRFs [4, 5], but with some important differences (besidesapplication domain). Our formulation is a standard latentstructural SVM in which we minimize classification error,whereas the loss function in [5] is based on incorrect in-stance selections. Their unary potential is pre-trained in-stead of being updated iteratively. Finally, our model si-multaneously discovers multiple discriminative candidateattributes (instances).
3.3. Attribute detection
To detect attributes in a new image It, we simply add Itto the L-CRF as an additional node, fixing the values of thelatent variables for the training image nodes. We performCRF inference on this new graph to estimate both the classlabel yt and its corresponding region label lt ∈ It. If yt =1, then we report a successful detection and return lt, andotherwise report that It does not have this attribute. Notethat this inference is exact and can be done in linear time.
3.4. Active attribute discovery
Having shown how to automatically discover attributesfor images labeled with one of two classes (positive or nega-tive), we now describe how to discover attributes in a datasetwith multiple category labels, yi ∈ {1, . . . , N}. We wouldlike to discover an attribute vocabulary that collectively dis-criminates well among all categories. It is intractable toconsider all O(N2) possible binary splits of the labels, sowe use an iterative approach with a greedy heuristic to tryto actively prioritize the order in which splits are consid-ered. At each iteration, we identify the two categories thatare most similar in terms of the presence and absence ofattributes discovered so far. We use these two categoriesto define an active split, and find a set of discriminative at-tributes for this split using the procedure above. We thenadd these to our attribute set, and repeat the process.

3.5. Identifying semantic attributes
The approach we described in previous sections is ableto discover K candidate discriminative local attributes foreach active split, but not all of these will be meaningful at asemantic level. We now describe how to introduce a mini-mal amount of human feedback at each iteration of the dis-covery process in order to identify candidates that are dis-criminative and meaningful. Of the K candidates, we firstidentify the candidate that is most discriminative – i.e. thatincreases the performance of a nearest neighbor classifierthe most on held out validation data. We present this candi-date to a human user by displaying a subset of the positivetraining images from the corresponding active split markedwith the hypothesized attribute regions determined by the L-CRF (see Figure 8). If the user finds the candidate meaning-ful (and thus provides it with a name), it is added to our vo-cabulary of attributes. If not, that candidate is rejected, andwe select the second most discriminative candidate in ourpool of K candidates. If none of the candidates is judgedto be meaningful, no attribute is added to our pool, and weidentify the second most confusing pair of categories as ournext active split.
In order to reduce user response time we propose an at-tribute recommender system that automatically prioritizescandidates before presenting them to a user. It uses past userfeedback to predict whether the user is likely to find a newcandidate attribute meaningful. Our recommender systemis based on the hypothesis that users judge the meaningful-ness of an attribute by whether it is located on consistentparts of the object across the positive instances (e.g. if theregions in the images correspond to the same nameable partof a bird).
We use a simple approach to measure the spatial consis-tency of an attribute with respect to the object (illustratedin Figure 4). At each active split, we train our attributerecommendation system using all attribute candidates thathave been presented to human users so far, with acceptedones as positive exemplars and rejected ones as negativeexemplars. Note that the L-CRF model (Section 3.1) canalso encourage spatial consistency among training images(as we will see in Section 4); however those constraintsare only pairwise, whereas the features here are higher-order statistics capturing the set of regions as a whole. Ourrecommender system is related to the nameability modelof [17], but that model was restricted to global image-levelattributes, whereas we model whether a group of local re-gions are likely to be deemed consistent and hence mean-ingful by a human.
4. Experiments
We now test our proposed approach to local attribute dis-covery. We use data from two recent datasets with fine-
Attribute Recommender
Figure 4. Illustration of the recommender system. A backgroundmask is estimated for each image (top row, blue) using Grab-Cut [20]. The foreground mask is divided into a 2 × 2 grid. Foreach attribute region in the positive images (top row, dark red), wemeasure its spatial overlap with each grid cell shown in the sec-ond row, where degree of overlap is represented by colors rangingfrom dark blue (no overlap) to dark red (high overlap). Averag-ing these features across all positive images in the split (third row)gives a representation for the candidate attribute. We add two ex-tra dimensions containing the mean and standard deviation of theareas of the selected regions, creating a 6-D feature vector to traina classifier. This is a positive exemplar if the candidate is deemedmeaningful by the user, and negative otherwise.
grained category labels: a subset of the Caltech-UCSDBirds-200-2011 (CUB) [22] dataset containing about 1,500images of 25 categories of birds, and the Leeds Butterfly(LB) [24] dataset, which contains 832 images from 10 cat-egories of butterflies. We apply a hierarchical segmentationalgorithm [1] on each image to generate regions, and fil-ter out background regions by applying GrabCut [20] usingthe ground truth bounding boxes provided by the datasets(for LB, using a bounding box around the GT segmenta-tion mask in order to be consistent with CUB). Most imagescontain about 100− 150 such regions.
For the region appearance features f(·) in equations (2)and (3), we combine a color feature (color histogram with8 bins per RGB channel), a contour feature (gPb [1]), a sizefeature (region area and boundary length), a shape feature(an 8×8 subsampled binary mask), and spatial location (ab-solute pixel location of the centroid). For the distance func-tion D(·, ·) in equation (3), we compute χ2 distances forthe color, contour, size, and shape features, and Euclideandistance for the spatial location feature. During learning,we constrain the weights of ~α+
k and ~α−k corresponding tothe spatial location feature to be positive to encourage can-didates to appear at consistent locations. The weights in~α+k and ~α−k corresponding to other feature types are con-
strained to be nonnegative and nonpositive, respectively, toencourage visual similarity among regions on the positiveside of an active split and dissimilarity for regions on oppo-site sides. The bias terms ~βk are not constrained.
Exhaustive data collection for all 200 categories in the

CUB birds dataset is not feasible because it would requireabout a million user responses. So we conduct system-atic experiments on three subsets of CUB: ten randomly-selected categories, the ten hardest categories (defined asthe 10 categories for which a linear SVM classifier usingglobal color and gist features exhibits the worst classifica-tion performance), and five categories consisting of differ-ent species of warblers (to test performance on very fine-grained category differences). Each dataset is split intotraining, validation, and testing subsets. For CUB thesesubsets are one-half, one-quarter, and one-quarter of the im-ages, respectively, while for LB each subset is one-third.
We use Amazon’s Mechanical Turk to run our human in-teraction experiments. For each dataset, we generate an ex-haustive list of all possible active splits, and use an “offline”collection approach [17] to conduct systematic experimentsusing data from real users without needing a live user-in-the-loop. We present attribute visualizations by superim-posing on each latent region a “spotlight” consisting of a2-D Gaussian whose mean is the region centroid and whosestandard deviation is proportional to its size (and includinga red outline for the butterfly images to enhance contrast).We do this to “blur” the precise boundaries of the selectedregions, since they are an artifact of the choice of segmen-tation algorithm and are not important. We present eachcandidate attribute to 10 subjects, each of whom is asked toname the highlighted region (e.g. belly) and give a descrip-tive word (e.g. white). See Figure 8. We also ask the sub-jects to rate their confidence on a scale from 1 (“no idea”)to 4 (“very confident”); candidates with mean score above3 across users are declared to be semantically meaningful.
4.1. Attribute-based image classification
We now use our discovered attributes for image classifi-cation. We detect attributes in validation images and learnlinear SVM and nearest-neighbor classifiers, and then de-tect attributes and measure performance on the test subset.We represent each image as a binary feature vector indicat-ing which attributes were detected. Each category is repre-sented as the average feature vector of its training images.The nearest-neighbor classifier works by assigning the testimage to the category with the closest feature vector (similarto [15]). The SVM classifier is trained directly on the abovebinary features using cross-validation to choose parameters.
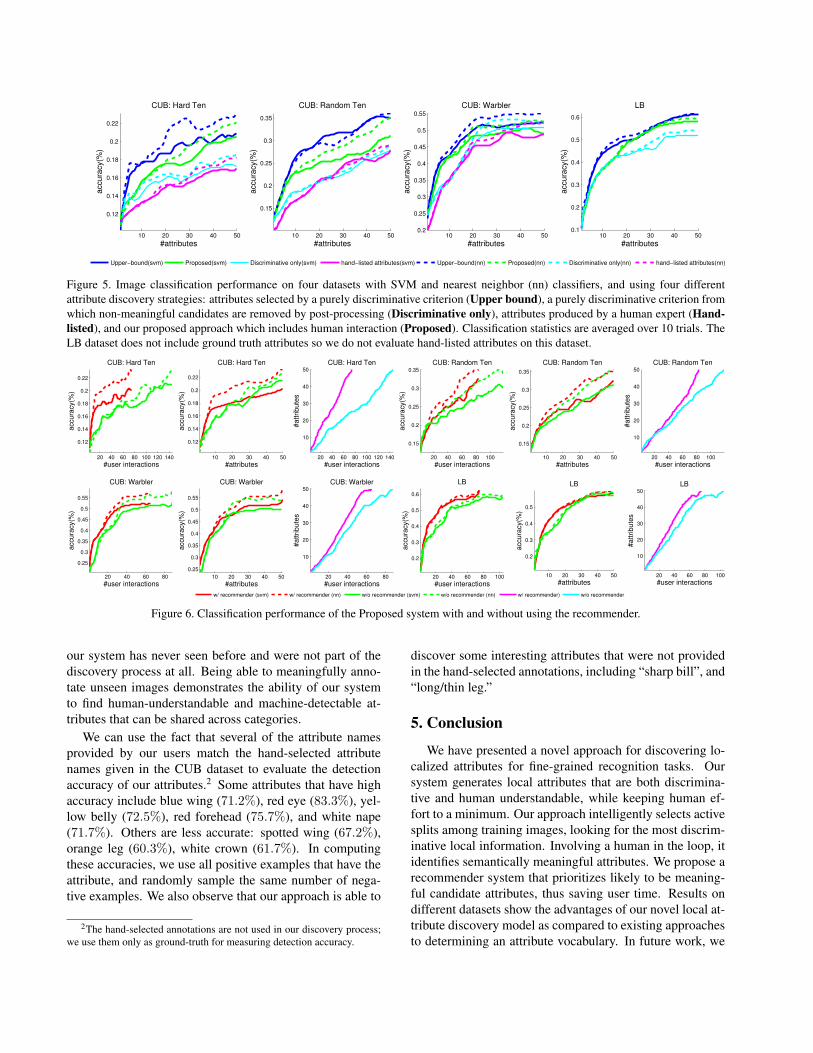
Figure 5 presents classification results on CUB birdsand LB butterflies, comparing the attribute vocabulariesproduced by our Proposed technique with two baselinesthat are representative of existing approaches in the litera-ture. These results do not include the recommender system;we evaluate that separately. Hand-listed uses the expert-generated attributes provided with the datasets. These areguaranteed to be semantically meaningful but may not bediscriminative. Discriminative only, at the other extreme,
Figure 7. Examples of automatic text generation.
greedily finds the most discriminative candidates and hopesfor them to be semantic. At each iteration (i.e. activesplit) among K candidates, it picks the one that providesthe biggest boost in classification performance on a held-outvalidation set. Candidates that are not semantic (and hencenot attributes) are dropped in a post-process. As reference,we also show performance if all discriminative candidatesare used (semantic or not). This Upper bound performancedepicts the sacrifice in performance one makes in return forsemantically meaningful attributes.
We see in Figure 5 that our proposed method performssignificantly better than either the hand-listed attributes ordiscriminative only baselines. These conclusions are stableacross all of the datasets and across both SVM and near-est neighbor classifiers. Hand-listed can be viewed as asemantic-only baseline (since the human experts likely ig-nored machine-detectability while selecting the attributes)and discriminative only can be thought of as focusing onlyon discriminative power and then addressing semanticsafter-the-fact. Our proposed approach that balances boththese aspects performs better than either one.
We also evaluate our recommender system as shown inFigure 6. We see that using the recommender allows usto gather more attributes and achieve higher accuracy fora fixed number of user iterations. The recommender thusallows our system to reduce the human effort involved inthe discovery process, without sacrificing discriminability.
4.2. Image-to-text Generation
Through the interaction with users, our process gener-ates names for each of our discovered attributes; Figure 8shows some examples. We can use these names to producetextual annotations for unseen images. We list the name ofthe attribute with maximum detection score among all can-didates detected on the detected region. Sample annotationresults are shown in Figure 7 using the system trained onthe 10 random categories subset of the CUB birds dataset.Note that some of these images belong to categories that
10 20 30 40 50
0.12
0.14
0.16
0.18
0.2
0.22
#attributes
accura
cy(%
)CUB: Hard Ten
Upper−bound(svm) Proposed(svm) Discriminative only(svm) hand−listed attributes(svm) Upper−bound(nn) Proposed(nn) Discriminative only(nn) hand−listed attributes(nn)
10 20 30 40 50
0.15
0.2
0.25
0.3
0.35
#attributesaccura
cy(%
)
CUB: Random Ten
10 20 30 40 500.2
0.25
0.3
0.35
0.4
0.45
0.5
0.55
#attributes
accura
cy(%
)
CUB: Warbler
10 20 30 40 500.1
0.2
0.3
0.4
0.5
0.6
#attributes
accura
cy(%
)
LB
Figure 5. Image classification performance on four datasets with SVM and nearest neighbor (nn) classifiers, and using four differentattribute discovery strategies: attributes selected by a purely discriminative criterion (Upper bound), a purely discriminative criterion fromwhich non-meaningful candidates are removed by post-processing (Discriminative only), attributes produced by a human expert (Hand-listed), and our proposed approach which includes human interaction (Proposed). Classification statistics are averaged over 10 trials. TheLB dataset does not include ground truth attributes so we do not evaluate hand-listed attributes on this dataset.
20 40 60 80 100 120 140
0.12
0.14
0.16
0.18
0.2
0.22
#user interactions
accu
racy(%
)
CUB: Hard Ten
10 20 30 40 50
0.12
0.14
0.16
0.18
0.2
0.22
#attributes
accu
racy(%
)
CUB: Hard Ten
20 40 60 80 100 120 140
10
20
30
40
50
#user interactions
#a
ttrib
ute
s
CUB: Hard Ten
20 40 60 80 100
0.15
0.2
0.25
0.3
0.35
#user interactions
accu
racy(%
)
CUB: Random Ten
10 20 30 40 50
0.15
0.2
0.25
0.3
0.35
#attributes
accu
racy(%
)
CUB: Random Ten
20 40 60 80 100
10
20
30
40
50
#user interactions
#a
ttrib
ute
s
CUB: Random Ten
20 40 60 80
0.25
0.3
0.35
0.4
0.45
0.5
0.55
#user interactions
accu
racy(%
)
CUB: Warbler
10 20 30 40 50
0.25
0.3
0.35
0.4
0.45
0.5
0.55
#attributes
accu
racy(%
)
CUB: Warbler
20 40 60 80
10
20
30
40
50
#user interactions
#a
ttrib
ute
s
CUB: Warbler
20 40 60 80 100
0.2
0.3
0.4
0.5
0.6
#user interactions
accu
racy(%
)
LB
10 20 30 40 50
0.2
0.3
0.4
0.5
#attributes
accu
racy(%
)
LB
w/ recommender (svm) w/ recommender (nn) w/o recommender (svm) w/o recommender (nn)
20 40 60 80 100
10
20
30
40
50
#user interactions
#a
ttrib
ute
s
LB
w/ recommender) w/o recommender
Figure 6. Classification performance of the Proposed system with and without using the recommender.
our system has never seen before and were not part of thediscovery process at all. Being able to meaningfully anno-tate unseen images demonstrates the ability of our systemto find human-understandable and machine-detectable at-tributes that can be shared across categories.
We can use the fact that several of the attribute namesprovided by our users match the hand-selected attributenames given in the CUB dataset to evaluate the detectionaccuracy of our attributes.2 Some attributes that have highaccuracy include blue wing (71.2%), red eye (83.3%), yel-low belly (72.5%), red forehead (75.7%), and white nape(71.7%). Others are less accurate: spotted wing (67.2%),orange leg (60.3%), white crown (61.7%). In computingthese accuracies, we use all positive examples that have theattribute, and randomly sample the same number of nega-tive examples. We also observe that our approach is able to
2The hand-selected annotations are not used in our discovery process;we use them only as ground-truth for measuring detection accuracy.
discover some interesting attributes that were not providedin the hand-selected annotations, including “sharp bill”, and“long/thin leg.”
5. Conclusion
We have presented a novel approach for discovering lo-calized attributes for fine-grained recognition tasks. Oursystem generates local attributes that are both discrimina-tive and human understandable, while keeping human ef-fort to a minimum. Our approach intelligently selects activesplits among training images, looking for the most discrim-inative local information. Involving a human in the loop, itidentifies semantically meaningful attributes. We propose arecommender system that prioritizes likely to be meaning-ful candidate attributes, thus saving user time. Results ondifferent datasets show the advantages of our novel local at-tribute discovery model as compared to existing approachesto determining an attribute vocabulary. In future work, we

legleft leg
tail
belly
bla
ck
thin
long
eyeforehead
crownheadbill
wh
ite
blackgray
eyeforeheadthroat
bla
ck yellow
eyebillleft eye
bla
ckre
d
short
throatbreast
belly
eye
yello
w white
black
wingsleft wing
right wing
eye
blackblack
& whitestriped
(a)
whitewhite edge
black
&white edge
bla
cksp
otte
d
orange
&black
win
g
forewing
left wing
black
whitestriped
ora
nge
black dots
blackspotted
& brown
eye
win
g
hind wingforewing
white spots
win
gforewing
left wing
and
spotte
dora
nge e
dge
thorax
abd
om
en
win
g
forewingright wing
golden
yellow
striped
win
g
forewingspots
yellow
black dots
(b)Figure 8. Some local attributes discovered by our approach, along with the semantic attribute names provided by users (where font size isproportional to number of users reporting that name), for (a) CUB birds, and (b) LB butterflies. Best viewed on-screen and in color.
would like to find links between local attributes and objectmodels, in order to bring object detection into the loop ofdiscovering localized attributes, such that both tasks benefitfrom each other. We would also like to study how to betterincorporate human interactions into recognition techniques.
Acknowledgments: The authors thank Dhruv Batra fordiscussions on the L-CRF formulation, and acknowledgesupport from NSF IIS-1065390, the Luce Foundation, theLilly Endowment, and the IU Data-to-Insight Center.
References[1] P. Arbelaez, M. Maire, C. Fowlkes, and J. Malik. Contour detection
and hierarchical image segmentation. PAMI, 33:898–916, 2011.[2] T. L. Berg, A. C. Berg, and J. Shih. Automatic attribute discovery
and characterization from noisy web data. In ECCV, 2010.[3] S. Branson, C. Wah, B. Babenko, F. Schroff, P. Welinder, P. Perona,
and S. Belongie. Visual recognition with humans in the loop. InECCV, 2010.
[4] T. Deselaers, B. Alexe, and V. Ferrari. Localizing objects while learn-ing their appearance. In ECCV, 2010.
[5] T. Deselaers and V. Ferrari. A conditional random field for multiple-instance learning. In ICML, 2010.
[6] A. Farhadi, I. Endres, D. Hoiem, and D. Forsyth. Describing objectsby their attributes. In CVPR, 2009.
[7] P. F. Felzenszwalb, R. B. Girshick, D. A. McAllester, and D. Ra-manan. Object detection with discriminatively trained part-basedmodels. PAMI, 32(9):1627–1645, 2010.
[8] R. Fergus, P. Perona, and A. Zisserman. Object class recognition byunsupervised scale-invariant learning. In CVPR, 2003.
[9] V. Ferrari and A. Zisserman. Learning visual attributes. In NIPS,2007.
[10] M. Grant and S. Boyd. CVX: Matlab software for disciplined convexprogramming, v1.21. http://cvxr.com/cvx.
[11] S. J. Hwang, F. Sha, and K. Grauman. Sharing features betweenobjects and their attributes. In CVPR, 2011.
[12] G. Kim and A. Torralba. Unsupervised detection of regions of inter-est using iterative link analysis. In NIPS, 2009.
[13] V. Kolmogorov. Convergent tree-reweighted message passing for en-ergy minimization. PAMI, 28(10):1568–1583, 2006.
[14] N. Kumar, A. C. Berg, P. N. Belhumeur, and S. K. Nayar. Attributeand Simile Classifiers for Face Verification. In ICCV, 2009.
[15] C. H. Lampert, H. Nickisch, and S. Harmeling. Learning to detectunseen object classes by between-class attribute transfer. In CVPR,2009.
[16] Y. J. Lee and K. Grauman. Foreground focus: Unsupervised learningfrom partially matching images. IJCV, 85(2):143–166, 2009.
[17] D. Parikh and K. Grauman. Interactively building a discriminativevocabulary of nameable attributes. In CVPR, 2011.
[18] D. Parikh and K. Grauman. Relative attributes. In ICCV, 2011.[19] A. Quattoni, S. Wang, L.-P. Morency, M. Collins, and T. Darrell.
Hidden-state conditional random fields. PAMI, 29(10):1848–1852,2007.
[20] C. Rother, V. Kolmogorov, and A. Blake. Grabcut: interactive fore-ground extraction using iterated graph cuts. In SIGGRAPH, 2004.
[21] I. Tsochantaridis, T. Joachims, T. Hofmann, and Y. Altun. Largemargin methods for structured and interdependent output variables.JMLR, 6:1453–1484, 2005.
[22] C. Wah, S. Branson, P. Welinder, P. Perona, and S. Belongie. TheCaltech-UCSD Birds-200-2011 dataset. In CVPR Workshop on Fine-Grained Visual Categorization, 2011.
[23] G. Wang and D. Forsyth. Joint learning of visual attributes, objectclasses and visual saliency. In ICCV, 2009.
[24] J. Wang, K. Markert, and M. Everingham. Learning models for ob-ject recognition from natural language descriptions. In BMVC, 2009.
[25] Y. Wang and G. Mori. A discriminative latent model of object classesand attributes. In ECCV, 2010.
[26] Y. Yang and D. Ramanan. Articulated pose estimation with flexiblemixtures-of-parts. In CVPR, 2011.
[27] B. Yao, A. Khosla, and L. Fei-Fei. Combining randomization anddiscrimination for fine-grained image categorization. In CVPR, 2011.