Embed Size (px)
Citation preview


Disclaimer
• This presentation may contain product features that are currently under development.
• This overview of new technology represents no commitment from VMware to deliver these features in any generally available product.
• Features are subject to change, and must not be included in contracts, purchase orders, or sales agreements of any kind.
• Technical feasibility and market demand will affect final delivery.
• Pricing and packaging for any new technologies or features discussed or presented have not been determined.
CONFIDENTIAL 2

Agenda / Table of Contents
• Introduction – Why Virtualize SQL Server?
• Designing for Performance (Tier-1 Production)
– Data Volume and Protocol Considerations
– Database Workload Types and Characteristics
– Understanding Memory Management
– Memory Best Practices in SQL Server Guests
– Networking Best Practices
– NUMA
• Consolidating Multiple SQL Server Workloads
– Consolidation Options
– Mixing Workload Types
• SQL Server Availability
– vSphere Features
– Supported SQL Server Clustering Configurations
CONFIDENTIAL 4

IntroductionWhy virtualize SQL Server?
CONFIDENTIAL5

Quick Facts
• SQL Server database servers account for ~10% of all x86 workloads and are typically underutilized (6-20% CPU utilization)
• Many Database Administrators (DBAs) are hesitant to virtualize database servers due to perceived issues with performance, availability, and licensing
• Running SQL Server workloads on vSphere can help to reduce physical server and licensing costs while increasing availability without sacrificing performance
• The VMware SDDC platform offers management benefits that extend to both the infrastructure administrator and the DBA
• In-depth application monitoring and trend analysis
• Automation and provisioning of database components for developers (self-service)
• Application and site resilliency

Reduce hardware costs by > 50%
• Consolidate servers by 4X – 20X
Provision databases on demand
• Minutes to provision in production and in the lab
Reduce licensing costs
• Potentially increase utilization of SQL Server licenses (depending on degree of consolidation)
Increase application Quality of Service
• Scale dynamically
• Built-in high availability and simple disaster recovery
DB On Demand
Quality of Service
DB Consolidation
Why Deploy Databases on VMware SDDC?
7
Licensing
Complete isolation between systems on the same host
• Protects databases and applications against network-based threats
Security

VMware SDDC Simplifies Common DBA Tasks

Designing for PerformanceTier-1 Production Workloads
CONFIDENTIAL9

Performance Best Practices Summary
• Design for performance in addition to capacity; more disks = faster
• Dedicate DataStores for performance critical workloads
• Avoid Lazy Zeroing; use VAAI array or eagerzeroedthick
• Pre-test your workload
• Use PVSCSI adapters when possible (non-clustered databases)
• Use multiple paths to storage array (minimum 2 HBAs)
• Use Large Memory Pages at the host
• Avoid host-level swapping; don’t disable TPS and ballooning
• Optimize network for IP-based storage protocols
• Use PVSCSI adapters when possible (non-clustered databases)
• Use multiple vSCSI adapters (up to 4)
• Avoid CPU and Memory overcommit; alternatively, use reservations
• Use Large Memory Pages in the guest; enable LockPagesInMemory user right
• Place t-logs, tempdb, and data files on separate LUNs

VMFS
Design for Storage Performance (not just Capacity)
• The fundamental relationship between consumption and supply has not changed
– Spindle count and RAID configuration are still important
– But host demand is an aggregate of virtual machines
• DataStores (work with Storage Engineer early in Design)
– Create dedicated data stores to service BCA database workloads
– svMotion / SDRS to balance workloads across DataStores
– Load Balance your workloads across as many disk spindles as possible
– Follow storage vendor’s best practices when laying out database
– Storage Multipathing – Set up a minimum of four paths from an ESX Server to a storage array (requires at least two HBA ports)
• Factors that affect storage performance include storage protocols, storage configuration, and Virtual Machine File System (VMFS) configuration

Design for Storage Performance (cont.)
• Ensure storage adapter cards are installed in slots with enough bandwidth to support their expected throughput
• Ensure appropriate read/write controller cache is enabled
• Pick the right multipathing policy based on vendor storage array design
• Configure maximum queue depth if needed for Fibre Channel HBA cards. See:
– http://kb.vmware.com/kb/1267
– http://kb.vmware.com/kb/1267

VMFS or RDM?
• Generally similar performance http://www.vmware.com/files/pdf/performance_char_vmfs_rdm.pdf
• vSphere 5.5 supports up to 62TB VMDK files
• Disk size no longer a limitation of VMFS
VMFS RDM
Better storage consolidation – multiple virtual disks/virtual machines per
VMFS LUN. But still can assign one virtual machine per LUN
Enforces 1:1 mapping between virtual machine and
LUN
Consolidating virtual machines in LUN – less likely to reach vSphere
LUN Limit of 256
More likely to hit vSphere LUN limit of 256
Manage performance – combined IOPS of all virtual machines in LUN <
IOPS rating of LUN
Not impacted by IOPS of other virtual machines
• When to use raw device mapping (RDM)
– Required for shared-disk failover clustering
– Required by storage vendor for SAN management tools such as backup and snapshots
• Otherwise use VMFS

VMDK Lazy Zeroing *
• Default VMDK allocation policy lazy zeroes 1M VMFS blocks on first write
• Write penalty on an untouched VMDK
• SQL Server operations could be affected by lazy zeroing
– Write operations
– Read operations that use tempdb extensively
– Bulk load/index maintenance
• For best performance, format VMDK as eagerzeroedthick *
• * Zero offload capability in VAAI improves zeroing in supported arrays 0
20
40
60
80
100
120
140
160
180
200
1 host 2 hosts4 hosts8 hosts 16hosts
Th
rou
gh
pu
t (M
Bp
s)
Effect of Zeroing on Storage Performance
"Post-zeroing" "Zeroing"
Choose Storage which supports VMware vStorage
APIs for Array Integration (VAAI)

Eagerzeroed Thick in the GUI
• When using VMFS for SQL Server data, create VMDK files as eagerzeroed thick or uncheck Windows “Quick Format” option
vSphere 4
vSphere 5

Understand Your Workload!!!

OLTP
Large amount of small queries
Sustained CPU utilization during working hours
Sensitive to peak contentions (slow downs affects SLA)
Generally Write intensive
May generate many chatty network round trips
Typically runs during off-peak hours, low CPU utilization during
normal working hours
Can withstand peak contention, but sustain activity is key
Batch / ETL
DSS
Small amount of large queries
CPU, memory, disk IO intensive
Peaks during month end, quarter end, year end
Can benefit from inter-query parallelism with large number of threads
Database Workloads Types

SQL Server I/O Characteristics
• Understanding the I/O characteristics of common SQL Server operations and scenarios can help determine how to configure storage
• Some of the more common scenarios below
• Monitor I/O to determine specifics of each scenario
Operation Random/Sequential Read/Write Size Range
OLTP – Log Sequential Write Up to 64K
OLTP – Data Random Read/Write 8K
Bulk Insert Sequential Write Any multiple of 8K up to 256K
Read Ahead – DSS and Index Scans Sequential Read Any multiple of 8KB up to 512K
Backup Sequential Read 1MB

Storage – Test Before Deployment
• Simulate SQL Server disk I/O patterns using a generic tool, such as the native SQLIOSim or Iometer
• Test to make sure requirements, such as throughput and latency, have been met
• Example SQL I/O patterns to tests
R/W% Type Block Threads/ Queue Simulates
80/20 Random 8K # cores/files Typical OLTP data files
0/100 Sequential 60K 1/32 Transaction log
100/0 Sequential 512K 1/16 Table scans
0/100 Sequential 256K 1/16 Bulk load
100/0 Random 32K # cores/1 SSAS workload
100/0 Sequential 1MB 1/32 Backup
0/100 Random 64K-256K # cores/files Checkpoints

Storage – Best Practices Summary
• Size for performance, not just capacity (apps often drive performance requirements)
• Format database VMDK files as Eager Zeroed Thick* for demanding workload database
– * Required ONLY if the storage array is not VAAI-compliant. See VMware KB #1021976 (http://kb.vmware.com/kb/1021976)
• Ensure that blocks are aligned at both the ESXi and Windows levels
• Understand the path to the drives, such as storage protocol and multipathing
• Understand the I/O requirements of the workload and TEST
• Use small LUNs for better manageability and performance
• Optimize IP network for iSCSI and NFS
– NOTE: Network protocol processing for software-initiated iSCSI / NFS operations take place on the host system, requiring CPU resources
• Use multiple vSCSI adapters to evenly distribute target devices and increase parallel access for databases with demanding workloads

Performance Best Practices Summary
• Design for performance in addition to capacity; more disks = faster
• Dedicate DataStores for performance critical workloads
• Avoid Lazy Zeroing; use VAAI array or eagerzeroedthick
• Pre-test your workload
• Use multiple paths to storage array (minimum 2 HBAs)
• Use Large Memory Pages at the host
• Avoid host-level swapping; don’t disable TPS and ballooning
• Optimize network for IP-based storage protocols
• Design with NUMA in mind; use Virtual NUMA to extend awareness to guest
• Use PVSCSI adapters when possible (non-clustered databases)
• Use multiple vSCSI adapters (up to 4)
• Avoid CPU and Memory overcommit; alternatively, use reservations
• Use Large Memory Pages in the guest; enable LockPagesInMemory user right
• Place t-logs, tempdb, and data files on separate LUNs

Large Pages
• Use ESXi Large Pages (2MB)
– Improves performance by significantly reducing TLB misses (applications with large active memory working sets)
– Does not share large pages unless memory pressure (KB 1021095 and 1021896)
– Slightly reduces the per-virtual-machine memory space overhead
• For systems with Hardware-assisted Virtualization
– Recommend use guest-level large memory pages
– ESXi will use large pages to back the GOS memory pages even if the GOS does not make use of large memory pages(full benefit of huge pages is when GOS use them as well as ESXi does)

“Large Pages Do Not Normally SWAP”
http://kb.vmware.com/kb/1021095
In the cases where host memory is overcommitted, ESX may have
to swap out pages. Since ESX will not swap out large pages,
during host swapping, a large page will be broken into small
pages. ESX tries to share those small pages using the pre-
generated hashes before they are swapped out. The motivation of
doing this is that the overhead of breaking a shared page is
much smaller than the overhead of swapping in a page if the
page is accessed again in the future.

Swapping is Bad!
• Swapping happens when:
– The host is trying to service more memory than it has physically AND
– ESXi memory optimization features (TPS and Ballooning) are insufficient to provide relief
• Swapping Occurs in Two Places
– Guest VM Swapping
– ESXi Host Swapping
• Swapping can slow down I/O performance of disks for other VM’s
• Two ways to keep swapping from affecting your workload:
– At the VM: Set memory reservation = allocated memory (avoid ballooning/swapping)
• Use active memory counter with caution and always confirmed usage by checking memory counter in Perfmon
– At the Host: Do not overcommit memory until vCenter reports that steady state usage is < the amount of RAM on the server

ESXi Memory Features that Help Avoid Swapping
• Transparent Page Sharing
– Optimizes use of memory on the host by “sharing” memory pages that are identical between VMs
– More effective with similar VMs (OS, Application, configuration)
– Very low overhead
• Ballooning
– Allows the ESXi host to “borrow” memory from one VM to satisfy requests from other VMs on that host
– The host exerts artificial memory pressure to the VM via the “balloon driver” and returns to the pool usable by other VMs
– Ballooning is the host’s last option before being forced to swap
– Ballooning is only effective if VMs have “idle” memory
• DON’T TURN THESE OFF

Memory Reservations
• Allows you to guarantee a certain share of the physical memory for an individual VM
• The VM is only allowed to power on if the CPU and memory reservation is available (strict admission)
• The amount of memory can be guaranteed even under heavy loads.
• In many cases, the configured size and reservation size could be the same

Reservations and vswp
• Setting a reservation creates a 0.00 K

Network Best Practices
• Allocate separate NICs for vMotion, FT logging traffic, and ESXi console access management
– Alternatively use VLAN-trunking support to separate production users, management, VM network, and iSCSI storage traffic
• vSphere 5.0 supports the use of more than 1 NIC for vMotion allowing more simultaneous vMotions; added specifically for memory intensive applications like Databases
• Use NIC load-based teaming (route based on physical NIC load) for availability, load balancing, and improved vMotion speeds
• Have minimum 4 NICs per host to ensure performance and redundancy of network
• Recommend the use of NICs that support:
– Checksum offload , TCP segmentation offload (TSO)
– Jumbo frames (JF), Large receive offload (LRO)
– Ability to handle high-memory DMA (i.e. 64-bit DMA addresses)
– Ability to handle multiple Scatter Gather elements per Tx frame
– NICs should support offload of encapsulated packets (with VXLAN)

Network Best Practices (continued)
• Separate SQL workloads with chatty network traffic (Microsoft Always On – Are you there) from the one with chunky access into different physical NICs
• Use Distributed Virtual Switches for cross-ESX network convenience
• Optimize IP-based storage (iSCSI and NFS)
– Enable Jumbo Frames
– Use dedicated VLAN for ESXi host's vmknic & iSCSI/NFS server to minimize network interference from other packet sources
– Exclude iSCSI NICs from Windows Failover Cluster use
– Be mindful of converged networks; storage load can affect network and vice versa as they use the same physical hardware; ensure no bottlenecks in the network between the source and destination
• Use VMXNET3 Paravirtualized adapter drivers to increase performance
– Reduces overhead versus vlance or E1000 emulation
– Must have VMware Tools to enable VMXNET3
• Tune Guest OS network buffers, maximum ports

Jumbo Frames• Use Jumbo Frames – confirm there is no MTU mismatch
• To configure, see iSCSI and Jumbo Frames configuration on ESX 3.x and ESX 4.xhttp://kb.vmware.com/kb/1007654

AlwaysOn Availability Group Cluster Settings
• Depending on YOUR network, tuning may be necessary – work with Network Team and Microsoft to determine appropriate settings
Cluster Heartbeat
Parameters
Default
Value
CrossSubnetDelay 1000 ms
CrossSubnetThreshold 5hb
SameSubnetDelay 1000 ms
SameSubnetThreshold 5 hb
View: cluster /cluster:<clustername> /prop
Modify: cluster /cluster:clustername> /prop <prop_name> = <value>

Non-Uniform Memory Access (NUMA)
• Designed to avoid the performance hit when several processors attempt to address the same memory by providing separate memory for each NUMA Node.
• Speeds up Processing
• NUMA Nodes Specific to Each Processor Model

Virtual NUMA in vSphere 5
• Extends NUMA awareness to the guest OS
• Enabled through multicore UI
– On by default for 8+ vCPU multicore VM
– Existing VMs are not affected through upgrade
– For smaller VMs, enable by setting numa.vcpu.min=4
• Do NOT turn on CPU Hot-Add
• For wide virtual machines, confirm feature is on for best performance
• SQL Server
– Automatically detects NUMA architecture
– SQL Server process and memory allocation optimized for NUMA architecture

NUMA Best Practices
• http://www.vmware.com/files/pdf/techpaper/VMware-vSphere-CPU-Sched-Perf.pdf
• Avoid Remote NUMA access
– Size # of vCPUs to be <= the # of cores on a NUMA node (processor socket)
• Hyperthreading
– Initial conservative sizing: set vCPUs to # of cores
– HT benefit around 20-25%, < for CPU intensive batch jobs (based on OLTP workload tests )
– Increase vCPUs to get HT benefit, but consider “numa.vcpu.preferHT” option – individual case basis
• # of virtual sockets and # of cores / virtual socket
– Recommendation , keep default 1 core / socket
• Align VMs with physical NUMA boundaries
• ESXTOP to monitor NUMA performance at vSphere
• If vMotioning, move between hosts with the same NUMA architecture to avoid performance hit (until reboot)

Performance Best Practices Summary
• Design for performance in addition to capacity; more disks = faster
• Dedicate DataStores for performance critical workloads
• Avoid Lazy Zeroing; use VAAI array or eagerzeroedthick
• Pre-test your workload
• Use PVSCSI adapters when possible (non-clustered databases)
• Use multiple paths to storage array (minimum 2 HBAs)
• Use Large Memory Pages at the host
• Avoid host-level swapping; don’t disable TPS and ballooning
• Optimize network for IP-based storage protocols
• Use PVSCSI adapters when possible (non-clustered databases)
• Use multiple vSCSI adapters (up to 4)
• Avoid CPU and Memory overcommit; alternatively, use reservations
• Use Large Memory Pages in the guest; enable LockPagesInMemory user right
• Place t-logs, tempdb, and data files on separate LUNs

PVSCSI Adapters
• The latest and most advanced vSphere SCSI controller drivers; recommended for workloads with a high performance requirement
• Larger queue depth per-device (256, actual 254) and per-adapter(1024)
– Default values are 64 and 254
• Less CPU overhead
• Requires VMware Tools
– Drivers not native to Windows
– Cannot be used for OS partition without some work-around
• Increase queue depth in Windows Guest OS by increase request ring to 32
– HKLM\SYSTEM\CCS\services\pvscsi\Parameters\Device\DriverParameter"RequestRingPages=32,MaxQueueDepth=254”
– ESX 5.0 U3 and above only
• Not currently supported for ANY type of Windows Clustering configuration

NFS, In-guest iSCSI, and vSCSI Adapters
• NFS
– Supported for SQL Server (must meet data write ordering requirements and guarantee write-through)
– Not supported by VMware for Windows Clustering
• In-guest iSCSI
– Supported for Standalone and Clustered
• No VMware-mandated considerations
– Facilitates easy storage zoning and access masking
– Useful for minimizing number of LUNs zoned to an ESXi host
– Offloads storage processing resources away from ESXi hosts
– Should use dedicated network and NIC
• vSCSI Adapters (configured in VM properties)
– Use multiple vSCSI adapters to evenly distribute target devices and increase parallel access for databases with demanding workloads

Guest Memory – Best Practices Summary
• Avoid overcommitment of memory at the host level (HostMem >= Sum of VMMem – overhead)
– If overcommitment is unavoidable, use reservations to protect important VMs
• To avoid NUMA remote memory access, size VM memory equal to or less than the memory per NUMA node if possible
– Utilize ESXi virtual NUMA features (especially for wide VMs)
• Use Large Pages in the guest – start SQL Server with trace flag -T834
• Enable Lock Pages in Memory right for SQL Server service account
• Use Max Server Memory and Min Server Memory when running multiple instances of SQL Server in the same VM
• Disable unnecessary processes within Windows

Large Pages in SQL Server Configuration Manager (Guest)
• Use Large Pages in the guest – start SQL Server with trace flag -T834
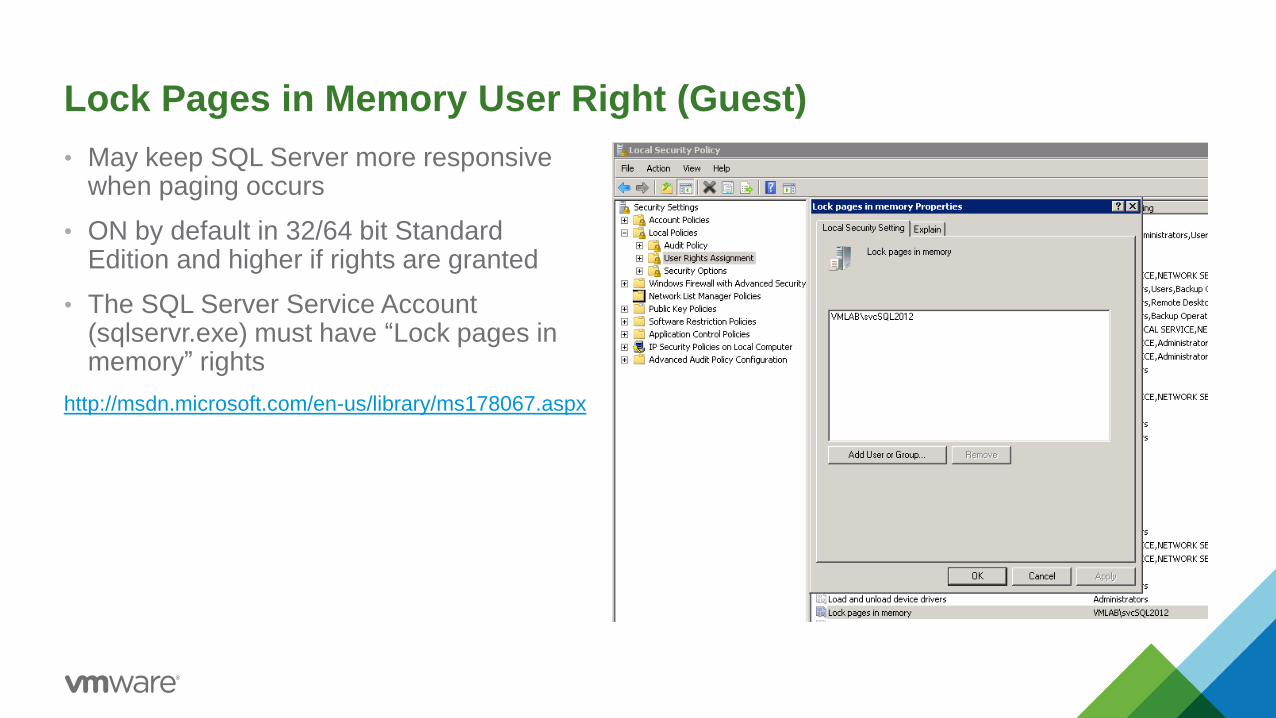
Lock Pages in Memory User Right (Guest)
• May keep SQL Server more responsive when paging occurs
• ON by default in 32/64 bit Standard Edition and higher if rights are granted
• The SQL Server Service Account (sqlservr.exe) must have “Lock pages in memory” rights
http://msdn.microsoft.com/en-us/library/ms178067.aspx

CPU Sizing Considerations
• Understand existing workload, average and peak; consider future growt
• Properly manage pCPU allocation
– For Tier 1 workload, avoid pCPU overcommitment or use reservations
– For lower-tiered databases workload
• Reasonable overcommitment can increase aggregate throughput and maximize license savings – consolidation ratio varies depending on workloads
• Leverage vMotion and DRS for resource load balancing
– Monitor to optimize
• Host level – %RDY, %MLMTD, and %CSTP
• Virtual machine level – processor queue length
• Keep NUMA node size in mind
– For smaller virtual machine, try to stay inside a NUMA node if possible
– For wide virtual machine – vSphere 5.x
• Align vCPUs to physical NUMA boundaries
• Enable vNUMA on vSphere host to allow SQL Server NUMA optimization

CPU Sizing Considerations (cont.)
• Leverage hardware-assisted virtualization (enabled by default)
• Be aware of hyper-threading, a hyper-thread does not provide the full power of a physical core
• In high performance environment, consider adding additional hosts when avg. host CPU utilization exceeds 65%
• Ensure Power Saving Features are “OFF”
• Use vCOPs for consumption & capacity metrics

SQL Server Guest Storage Best Practices
• Follow SQL Server storage best practices – http://technet.microsoft.com/en-us/library/cc966534.aspx
• Pre-allocate data files to avoid autogrow during peak time
– If using auto-growth, use MB and not % increments
• Use multiple data files for data and tempdb – start with 1 file per CPU core
– Multiple TempDB files can co-exist on the same volume – Not encouraged
• Database file placement priority – fastest to slowest drive
– Transaction Log Files > TempDB Data Files > Data Files
• Place data and log files on separate LUNs
• Perform routine maintenance with index rebuild/reorg, dbcc checkdb
• Number of Data Files Should Be <= Number of Processor Cores
• Use multiple vSCSI adapters to evenly distribute target devices and increase parallel access for databases with demanding workloads

Block Alignment
• Configure storage presented to vSphere hosts using vCenter to ensure VMFS block alignment
• Even though Windows is supposed to automatically align as of Windows 2008, Microsoft recommends double checking
– http://msdn.microsoft.com/en-us/library/dd758814.aspx
– http://blogs.msdn.com/b/jimmymay/archive/2014/03/14/disk-partition-alignment-for-windows-server-2012-sql-server-2012-and-sql-server-2014.aspx (Jimmy May - MSDN Blogs)
• Whatever the operating system, confirm that new partitions are properly aligned
Unaligned partitions result in additional I/O
Aligned partitions reduce I/O
stripe unit size value should be an integer

Consolidating Multiple Workloads
CONFIDENTIAL45

Consolidation Options
• Scale-up approach
– Multiple databases or SQL instances per virtual machine
– Fewer virtual machines
– Poor workload management
– Potential reduction in SQL licensing cost
• Scale-out approach
– Single database per VM
– Potential increase in mgmt. overhead
– Better isolation/performance
– Easier security and change mgmt.
– DRS more effective with smaller VMs
– Faster migration (vMotion)
46

OLTP vs. Batch Workloads
• What this says:
– Average 15% Utilization
– Moderate sustained activity (around 28% during working hours 8am-6pm)
– Minimum activities during non working hours
– Peak utilization of 58%
• What this says:
– Average 15% Utilization
– Very quiet during the working day (less than 8% utilization)
– Heavy activity during 1am-4am, with avg. 73%, and peak 95%
Batch Workload (avg. 15%)
OLTP Workload (avg. 15%)

OLTP vs. Batch Workloads
• What This Means
– Better Server Utilization
– Improved Consolidation Ratios
– Less Equipment To Patch, Service, Etc
– Saves Money/Less Licensing
OLTP/Batch Combined Workload

Running with Mixed SQL Server Workloads
• Consider workload characteristics, and manage pCPU overcommitment as a function of typical utilization
– OLTP workloads can be stacked up to a sustained utilization level
– OLTP workloads that are high usage during daytime and batch workloads that run during off-peak hours mix well together
– Batch/ETL workloads with different peak periods are mixed well together
• Consider operational history, such as month-end and quarter-end
– Additional virtual machines can be added to handle peak period during month-end, quarter-end, and year-end, if scale out is a possibility
– CPU and memory hot add can be used to handle workload peak
– Reduce virtual machine density, or add more hosts to the cluster
• Use DRS as your insurance policy, but don’t rely on it for resource planning

SQL Server Availability

Business-Level Approach
• What are you trying to protect?
– i.e. What does the business care about protecting?
• What are your RTO/RPO requirements?
• What is your Service Level Agreement (SLA)?
• How will you test and verify your solution?

vSphere 5 Availability Features
• vSphere vMotion
– Can reduce virtual machine planned downtime
– Relocate SQL Server VMs without end-user interruption
– Perform host maintenance any time of the day
• vSphere DRS
– Monitors state of virtual machine resource usage
– Can automatically and intelligently locate virtual machine
– Can create a dynamically balanced SQL deployment
• VMware vSphere High Availability (HA)
– Does not require Microsoft Cluster Server
– Uses VMware host clusters
– Automatically restarts failed SQL virtual machine in minutes
– Heartbeat detects hung virtual machines
– Application HA can provide availability at the SQL Server service level!

Microsoft
Clustering on
VMware
vSphere supportVMware HA
support
vMotion DRS
support
Storage vMotion
supportMSCS Node Limits
Storage Protocols support Shared Disk
FCIn-Guest
OS iSCSI
Native
iSCSI
In-Guest
OS SMBFCoE RDM VMFS
Shared
Disk
MSCS with
Shared DiskYes Yes1 No No
2
5 (5.1 only)Yes Yes No Yes5 Yes4 Yes2 Yes3
Exchange Single
Copy ClusterYes Yes1 No No
2
5 (5.1 only)Yes Yes No Yes5 Yes4 Yes2 Yes3
SQL Clustering Yes Yes1 No No2
5 (5.1 only)Yes Yes No Yes5 Yes4 Yes2 Yes3
SQL AlwaysOn
Failover Cluster
Instance
Yes Yes1 No No2
5 (5.1 only)Yes Yes No Yes5 Yes4 Yes2 Yes3
Non
shared
Disk
Network Load
BalanceYes Yes1 Yes Yes
Same as
OS/appYes Yes Yes N/A Yes N/A N/A
Exchange CCR Yes Yes1 Yes YesSame as
OS/appYes Yes Yes N/A Yes N/A N/A
Exchange DAG Yes Yes1 Yes YesSame as
OS/appYes Yes Yes N/A Yes N/A N/A
SQL AlwaysOn
Availability
Group
Yes Yes1 Yes YesSame as
OS/appYes Yes Yes N/A Yes N/A N/A
Shared Disk Configurations: Supported on
vSphere with additional considerations for storage
protocols and disk configs
Non-Shared Disk Configurations: Supported on
vSphere just like on physical
* Use affinity/anti-affinity rules when using vSphere HA
** RDMs required in “Cluster-across-Box” (CAB) configurations, VMFS required in “Cluster-in-Box” (CIB) configurations
VMware Knowledge Base Article: http://kb.vmware.com/kb/1037959
VMware Support for Microsoft Clustering on vSphere

Shared Disk Clustering (Failover Clustering and AlwaysOn FCI)
• Provides application high-availability through a shared-disk architecture
• One copy of the data, rely on storage technology to provide data redundancy
• Automatic failover for any application or user
• Suffers from restrictions in storage and VMware configuration

vSphere HA with Shared Disk Clustering
• Supports up to five-node cluster in vSphere 5.1 and above
• Failover cluster nodes can be physical or virtual or any combination of the two
• Host attach (FC) , FCoE* or in-guest (iSCSI)
• Supports RDM only
• vSphere HA + failover clustering
– Seamless integration, virtual machines rejoin clustering session after vSphere HA recovery
– Can shorten time that database is in unprotected state
– Use DRS affinity/anti-affinity rules to avoid running cluster virtual machines on the same host
Failover clustering supported with vSphere HA as of vSphere 4.1
http://kb.vmware.com/kb/1037959

Non-Shared Disk Clustering (Always On Availability Groups)
• Database-level replication over IP; no shared storage requirement
• Same advantages as failover clustering (service availability, patching, etc.)
• Readable secondary
• Automatic or manual failover through WSFC policies

vSphere HA with AlwaysOn Availability Groups
• Seamless integration
• Protect against hardware/software failure
• Support multiple secondary and readable secondary
• Provide local and remote availability
• Full feature compatibility with availability group
• VMware HA shortens time that database is in unprotected state
• DRS anti-affinity rule avoids running virtual machines on the same host
EMC Study – SQL Server AlwaysOn running vSphere 5 and EMC FAST VP
http://www.emc.com/collateral/hardware/white-papers/h10507-mission-critical-sql-server-2012.pdf

WSFC – Cluster Validation Wizard
• Use this to validate support for your configuration
– Required by Microsoft Support for condition of support for YOUR configuration
• Run this before installing AAG(AlwayOn Availabilty Group), and every time you make changes
– Save resulting html reports for reference
• If running non-symmetrical storage, possible hotfixes required
– http://msdn.microsoft.com/en-us/library/ff878487(SQL.110).aspx#SystemReqsForAOAG
58

Patching Non-clustered Databases
• Benefits
– No need to deploy an MS cluster simply for patching / upgrading the OS and database
– Ability to test in a controlled manner (multiple times if needed)
– Minimal impact to production site until OS patching completed and tested
– Patching of secondary VM can occur during regular business hours
• Requires you to layout VMDKs correctly to support this scenario

Resources
• Visit us on the web to learn more on specific apps
– http://www.vmware.com/solutions/business-critical-apps/
– Specific page for each major app
– Includes Best Practices and Design/Sizing information
• Visit our Business Critical Application blog
– http://blogs.vmware.com/apps/

New RDBMS books from VMware Press
61
vmwarepress.com
http://www.pearsonitcertification.com/store/virtu
alizing-oracle-databases-on-vsphere-
9780133570182
http://www.pearsonitcertification.com/store/virtuali
zing-sql-server-with-vmware-doing-it-right-
9780321927750

Questions?































