Embed Size (px)
Citation preview

Disciplina: Tópicos em Engenheira de Computação VI Prof. Léo Pini Magalhães Apresentação por:
Celso Henrique Cesila Alex Rodriguez Ruelas

Background
Métodos
Resultados
Discussão
Conclusão
Referências

Cancer Biomedical Informatics Grid (caBIG)
CAP cancer checklists as a domain standard in pathology
Cancer Common Ontologic Representation Environment
(caCORE) – a four layer approach to interoperability

Grade dedicada à criação de uma rede Inter operável de dados e serviços de análise que beneficia a comunidade de pesquisa do câncer.
Usando uma abordagem multinível que facilita a interoperabilidade semântica de sistemas.
Existem mais de 800 institutos participantes do projeto
O programa é financiado pelo National Cancer Institute (NCI)
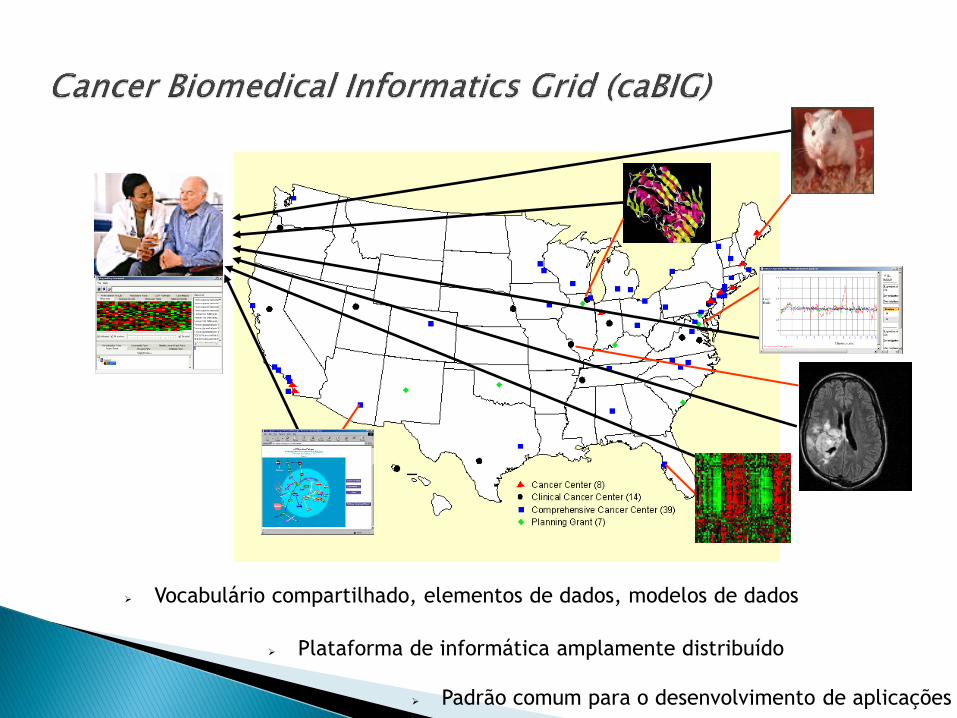
Vocabulário compartilhado, elementos de dados, modelos de dados
Plataforma de informática amplamente distribuído
Padrão comum para o desenvolvimento de aplicações
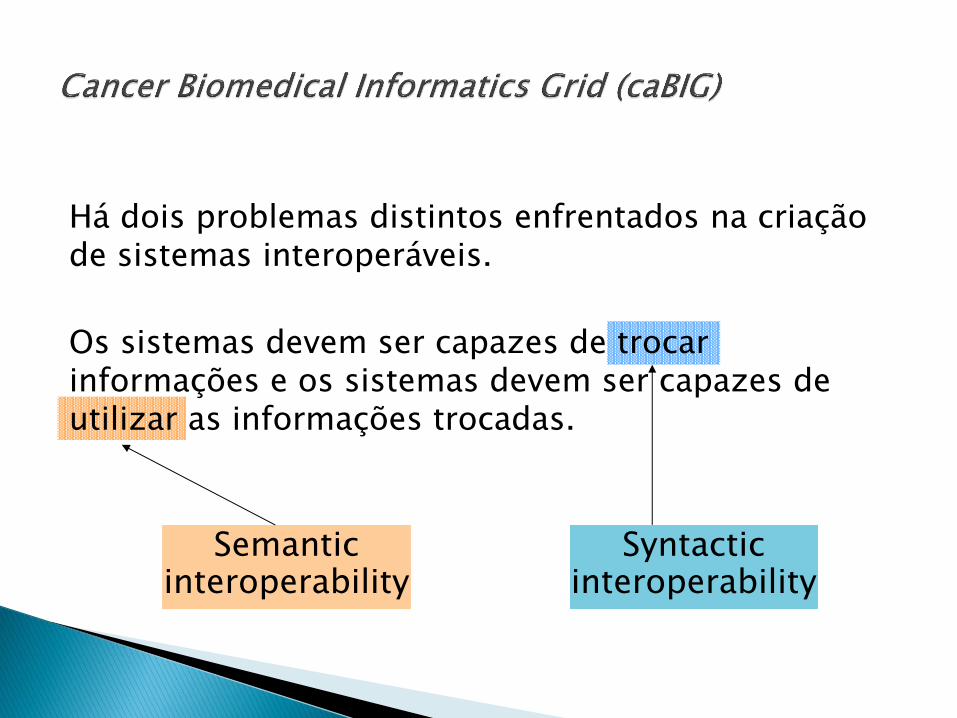
Há dois problemas distintos enfrentados na criação de sistemas interoperáveis.
Os sistemas devem ser capazes de trocar informações e os sistemas devem ser capazes de utilizar as informações trocadas.
Semantic interoperability
Syntactic interoperability

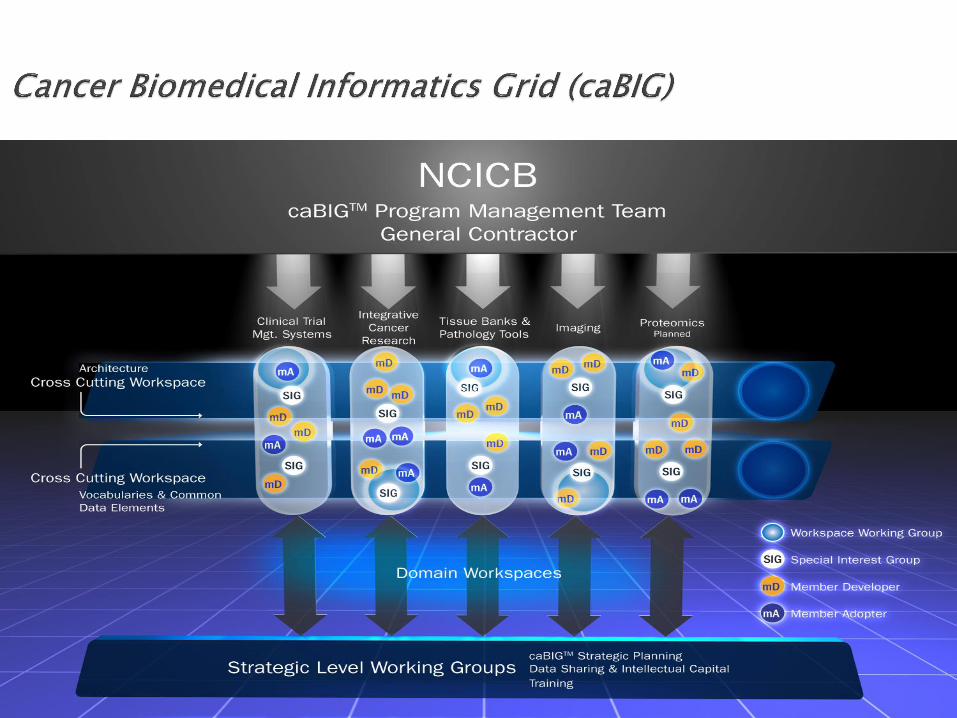
O caBIG tem quatro espaços de trabalho de domínio (Workspace): ◦ Clinical Trial Management Systems (CTMS)
◦ Tissue Banks and Pathology Tools (TBPT)
◦ In Vivo Imaging(IVI)
◦ Integrative Cancer Research (ICR)
Existem ainda dois espaços de trabalho transversais. Eles mantêm as estruturas tecnológicas e sociológicas que permitem a interoperabilidade entre os sistemas.

Em seu formato atual, os checklists de câncer CAP consistem em uma série de informes de diretrizes para relatórios de patologia cirúrgica de diagnóstico para 45 importantes cânceres humanos.
Cada protocolo e checklist foi desenvolvido por um painel independente de peritos subespecialidade para esse sistema de órgãos, muitas vezes representando diferentes escolas de pensamento.
Cada diretriz consiste em uma checklist especificando os elementos de dados do espécime e tumor que deve ser incluído no relatório de diagnóstico da patologia, bem como os valores válidos que esses elementos de dados podem tomar (Figura 1) e (2); é um protocolo detalhado fornecendo definições e mais informações sobre a base científica para avaliar estas variáveis.

O padrão de papel, (1) agrupa logicamente, elementos de dados em conjunto por procedimentos cirúrgicos ou tipo de exame (macroscópica vs microscópica) a que se aplicam, (2) faz uma distinção entre elementos de dados necessários para o qual há provas científicas inequívocas do seu valor, e elementos de dados opcionais que fazem não atender a essa threshold, e (3) mantém relevância, com versões de revistas publicadas, como novos dados estiverem disponíveis sobre fatores de prognóstico e os resultados clínicos.
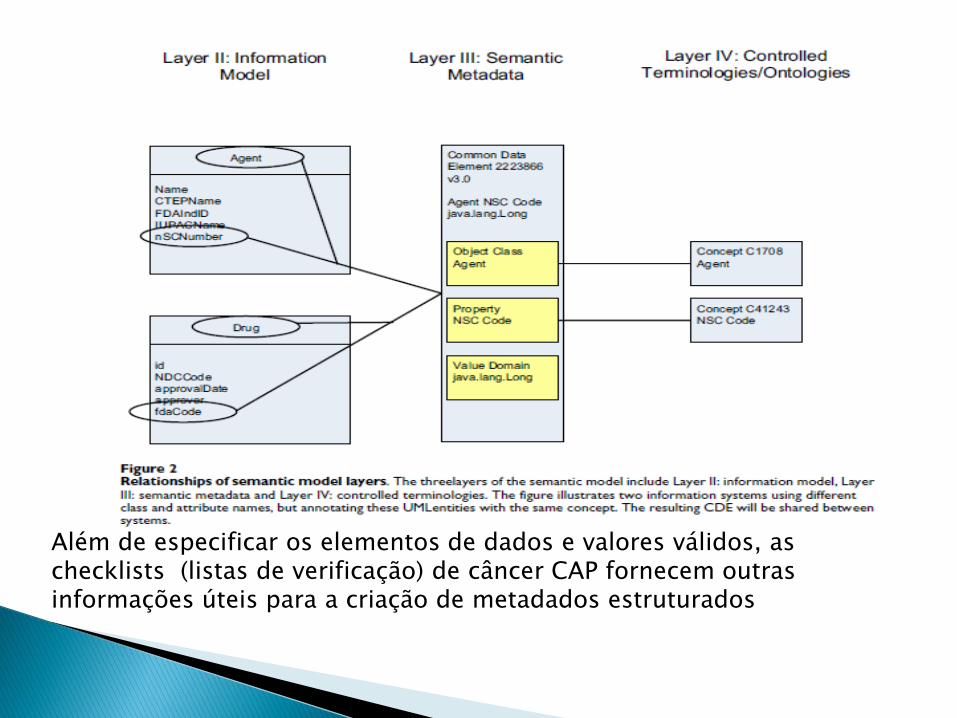
Além de especificar os elementos de dados e valores válidos, as checklists (listas de verificação) de câncer CAP fornecem outras informações úteis para a criação de metadados estruturados

A verdadeira interoperabilidade tem dois componentes: a interoperabilidade sintática, que se preocupa com a capacidade de trocar informações; e interoperabilidade semântica, que é a capacidade de compreender e usar a informação, uma vez que é recebido.
Para ajudar os desenvolvedores a implantar essas camadas no seu sistema de dados, o programa caBIG criou um conjunto de recursos de suporte e ferramentas que juntos são conhecidos como caCORE.
Uma camada está preocupada com o componente sintático da interoperabilidade, enquanto as restantes três camadas estão preocupadas com a parte semântica da interoperabilidade.
Essas camadas são (1), integração de interface, (2) modelos de informação, (3) metadados semânticos, e (4) vocabulários controlados, e ontologias.

Isto é alcançado através de um interface de programação de aplicativos (API) que é o principal mecanismo pelo qual os usuários caBIG irá interagir com os dados ou serviços analíticos.
Os objetos de dados criado por estes sistemas de informação são movidos de um lugar para outro sobre o caGrid, por eXtensible Markup Language (XML).

A camada de base da etapa de interoperabilidade semântica é a representação de um sistema de dados na forma de um modelo de informação no Unified Modeling Language (UML) .
Este modelo tem duas características essenciais. ◦ Em primeiro lugar, deve imitar exatamente a estrutura do API orientada a
objetos que o sistema está implantando.
◦ Em segundo lugar, tem de ser um modelo de informação de domínio que representa uma compreensão do domínio científica, incluindo ambas as entidades que estão envolvidas, assim como as relações entre essas entidades.
Estas entidades podem fornecer a língua franca para interoperação.

Tão úteis quanto o modelo de informação é transmitir a descrição semântica de um sistema de dados, é insuficiente para garantir a interoperabilidade semântica.
Considere um objeto na caGrid, como representado pelo XML abaixo:
<Agent>
<name>Taxol</name>
<NSCNumber>007</NSCNumber>
</Agent>
O que representa uma entidade chamada de "Agent" com dois atributos, seu nome é "Taxol" e tem NSC número '007'.
Tão úteis quanto o modelo de informação é transmitir a descrição semântica de um sistema de dados, é insuficiente para garantir a interoperabilidade semântica.

Embora o metamodelo ISO 11179 e caDSR fornecem um formalismo para descrever metadados semânticos arbitrária, não resolveu completamente o problema, porque (como visto anteriormente) palavras muitas vezes têm vários significados.
Além disso, as palavras não são formalmente computáveis, ou seja, uma máquina não necessariamente será capaz de determinar se duas sequências de linguagem natural distintas representam a mesma entidade ou atributo.
A solução para este problema é o uso de terminologias de conceito básico e ontologias com definições claras.
Quando as classes e atributos do UML são mapeados para esses códigos, é possível para uma máquina determinar se duas distintas classes e atributos se referem à mesma entidade e característica, independentemente dos nomes dados a eles por seus desenvolvedores.
Isso poderia resultar em geração de únicos elementos comuns de dados (common data elements, CDES), em vez de reutilização de aqueles criados para o domínio câncer.

Os quatro camadas descritas acima fornecem um meio técnico para atingir a interoperabilidade semântica e sintática em caBIG.
Os sistemas usam palavras diferentes para descrever a mesma classe, mas eles são ambos mapeados para o mesmo conceito na terminologia controlada.
Esta tecnologia permite a identificação de pontos de interação entre sistemas de dados que foram criados por grupos distintos de trabalho sem a interação direta, o que nos referimos como “chaves Grid” devido à sua analogia com as chaves estrangeiras em sistemas de gerenciamento de banco de dados relacionais (RDBMS).

Creating information models with the UML
Semantic metadata based on the ISO/IEC 11179 standard
NCI Thesaurus
The caDSR – a metadata registry
Generating caDSR CDEs from UML

Um diagrama de classes UML é um tipo de diagrama UML que descreve um conjunto de elementos de modelo estático, como entidades físicas ou conceituais e seus relacionamentos.
Em um específico diagrama de classe UML, as entidades conceituais são representadas por classes.
Associações são relacionamentos "peer-to-peer" entre classes.

Esta especificação foi desenvolvida com o propósito específico de facilitar a padronização de metadados em todo o mundo, fornecendo orientações sobre a própria framework (Part 1), a classificação de dados (Parte 2), a estrutura semântica de dados (Parte 3), a formulação de definições (Parte 4), nomeando e identificação (Parte 5), e orientação e instrução do registo de metadados (Parte 6). Os elementos de dados que estão em conformidade com a norma ISO / IEC 11179 devem ser associados a um conceito de elemento de dados (DEC) e um domínio de valores.

NCI Thesaurus é um sistema de terminologia baseada no conceito que utiliza descrição lógica para impor coerência lógica e fornecer um modelo formal com a semântica computacionalmente tratáveis.
NCI Thesaurus é a terminologia de referência central dentro do NCI EVS conjunto integrado de recursos e serviços - projetado para atender às necessidades controladas terminologia do NCI e seus parceiros -, bem como dentro da arquitetura bioinformática caBIG / caCORE.
Cada conceito representa um único significado específico, e inclui vários termos, códigos, definições de texto e outras propriedades que refletem esse significado.

Uma implementação padrão para registros de metadados
caDSR dispõe de um banco de dados, APIs, e aplicações baseadas na web para criar, editar, controlar, implantar, monitorar e encontrar metadados reutilizável.
Estes metadados descrevem elementos comuns de dados (CDES) e modelos de informação e formas de caso-relatório (CRFs) que são usados para a coleta e análise de dados ou para o desenvolvimento de software.

Baseada conforme a ISO / IEC 11179
O caDSR e seus aplicativos associados apoiam a comunidade de pesquisa através do fornecimento de um meio de gerenciar: ◦ descrições detalhadas dos dados mantidos em conjuntos de
dados de acesso público
◦ detalhes de modelos de informações compartilhadas
◦ descrições de dados a serem coletados e informações sobre as formas de relatório de caso (CRFs)
caDSR WebLink

As ferramentas usadas pelo engenheiro de software para transformar modelos de informação UML em metadados caDSR são:
Semantic Connector,
Semantic Integration Workbench (SIW)
UML Loader.

Semantic Connector
O modelo de informação UML é exportados para XMI.
Os nomes de elementos em UML são associados a conceitos NCI Thesaurus.
SIW
Anotação semântica para cada entidade UML.
Conector semântica é aplicada de novo para produzir um arquivo XMI anotada.
O arquivo final XMI é então usado para rever todas as associações e tipos de dados.

◦ Para cada elemento de dados em potencial que poderia ser gerado a partir do modelo de informação, o UML Loader primeiro determina se existe um elemento de dados que é equivalente em significado semântico com base no conceito DEC anotações existentes e outros metadados associado. Se uma correspondência exata é detectado, um elemento de dados existente será utilizado por designação. Nestes casos, realmente dados equivalentes compartilharão um elemento de dados idêntico na caDSR.
◦ Cria classes caDSR, esquema de classificação de itens de pacotes UML, classes de objetos a partir de classes UML e valores e atributos UML. Ele preserva as associações de classe UML e generalizações como relações de classe de objeto caDSR.
◦ Detecta os tipos de dados de atributos e os mapeia em domínios de valor não enumerados genéricos. Depois que o modelo tenha sido carregado, os proprietários do modelo devem usar as ferramentas baseadas na web caDSR para criar domínios de valores enumerados.

Suporte terminologia
Modelos de informação CAP cancer checklists
- Uncovering and naming the high level classes
- Creating basic UML structure
- Representing specific classes by extension
- Packages
- Enumeration of valid values
UML loading and post-load metadata curation

Foi usado a abordagem caCORE para desenvolver modelos UML e semântica de metadados para três listas de verificação de câncer CAP:
Carcinoma invasivo de próstata (Câncer de Próstata)
Carcinoma invasivo da mama (Câncer de Mama)
Melanoma cutânea (Câncer de Pele)

Terminologia e semântica NCI Thesaurus
Adição de novos conceitos, acrescentando novas associações para conceitos já existentes.
Novos termos foram adicionados a conceitos já existentes
Por Exemplo: os termos de protocolo CAP "unifocal" e "multifocal" foram adicionados aos conceitos de Lesão Unifocal e Lesão multifocal existentes no NCI Thesaurus

Descobrindo e nomeando as classes de alto nível
Primeiramente foram analisados uma parte dos checklists existentes, e criado modelos UML para descobrir termos em comum e, em seguida inspecionados os restantes da listas de verificação para garantir a generalização desses termos.
Foi encontrado chave de objetos gerais que cruzavam todos os checklists.
Em seguida, foram identificados elementos de dados pertencentes a cada objeto de nível elevado e atribuiu-lhes como atributos da classe.
Quando nenhum conceito NCI Thesaurus existente foi identificado,
foram adicionados novos conceitos de vocabulário. O resultado desta etapa do processo foi o de identificar e nomear um
conjunto geral de classes e atributos a partir do qual poderiam ser desenvolvidas todas as listas de verificação específicos da CAP.

A criação de estrutura UML básica
Classes UML de alto nível foram unidas por ligações que representam as relações lógicas entre classes.
Relações de herança foram usados para estender as classes gerais como cada lista de verificação específica câncer CAP foi desenvolvido.

Uma vez que a estrutura básica e classes gerais foram estabelecidas - modelamos três checklists CAP na sua totalidade.
Como descrito acima, as classes gerais foram alargados para cada, checklist CAP nós modelamos.
Por exemplo, cutâneo-MelanomaNegativeSurgicalMargin herda três atributos da classe geral SurgicalMargin, e estende esta classe com dois atributos adicionais (Figura ).
Três CDEs será criado para margem cirúrgica, e cinco serão criados para CutaneousMelanomaNegativeSurgicalMargin Construção de classes e atributos por vezes necessária a definição do tipo de dados, o que não é especificada no protocolo do CAP.
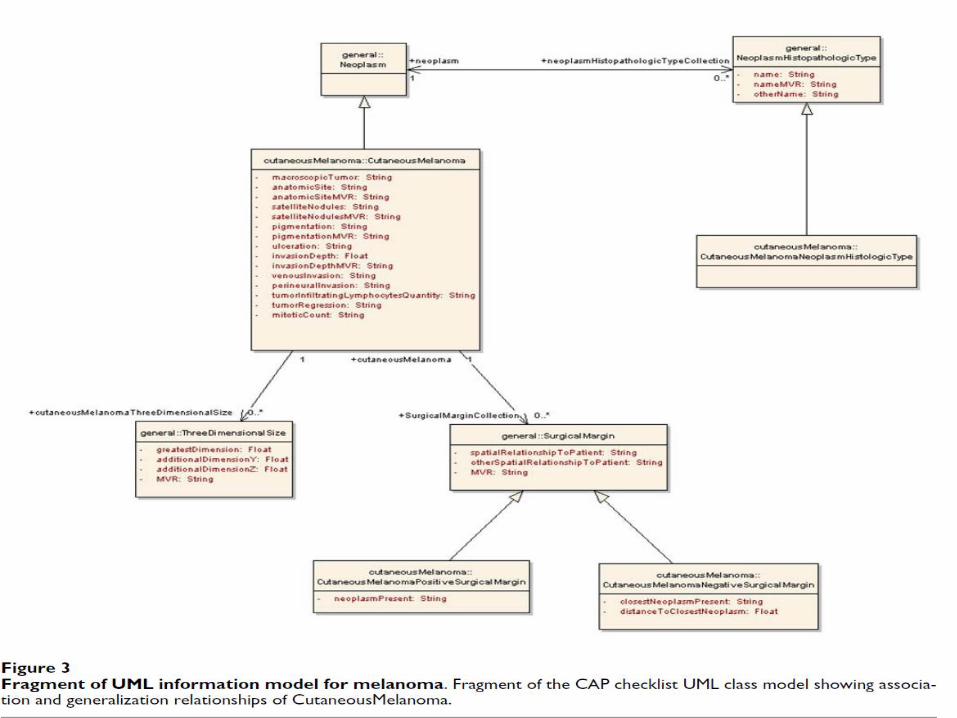

as classes foram agrupadas em pacotes para definir as agregações naturais e espaços de nomes correspondentes que surgem a partir do padrão de papel.
Por exemplo, todas as classes que são relevantes para o -checklist PAC para melanoma cutâneo estão incluídas em um único pacote.
Pacotes de se tornar esquemas de classificação caDSR durante o processo de carregamento UML.

A associação entre um valor e um conceito NCI Thesaurus refina a semântica de dados coletados e ajuda a garantir a sua interoperabilidade Durante o processo de modelagem, notou-se que, em alguns casos atributos herdados de uma superclasse comum a duas subclasses ambos devem herdar o mesmo domínio de valores.
Em paralelo com a criação de elementos de dados, UML as contagens de quantos foram utilizados para expressar os valores válidos para cada um desses elementos de dados.
No primeiro caso, nós sempre usamos o mesmo domínio de valores tanto para superclasse e subclasse durante a curadoria pós-carga (ver abaixo), mas, no segundo caso, usamos domínios de valores distintos.
Nesses casos, nós criamos domínios de valores por referência durante a pós-carga curadoria, como o domínio de valores para a metástase Anatomic Site (domínio de valores ID pública 2433552).

Metadados adicionais, passos curadoria foram realizadas utilizando a ferramenta caDSR Curadoria, incluindo (1) revisão de nomes longos, (2) fixação de domínios de valores aos elementos de dados correspondentes (3), além de regras de derivação de elementos de dados e texto forma de exibição e (4) a inclusão de links para a documentação original.

Implementation of value domains
Expressivity of semantic annotation
Need for more formal semantic annotation guidelines
Asynchronous structures in the multi-tiered models
Advantages of the caCORE approach
Uses of the CAP cancer checklists model and metadata
Future work on the CAP cancer checklists models

A necessidade de um texto descritivo para valores admissíveis está sendo abordado em futuros lançamentos caDSR, elevando o valor significa a um item administrado em caDSR, para o qual curadores pode então especificar alternativo nomes, definições e texto semelhante ao CDEs.
Esta função requer que o modelo descreve tanto um domínio de valores de referência em que os valores estão ligados a um conceito principal na Enciclopédia NCI, com todas as crianças como os valores permissíveis, bem como a capacidade de enumerar explicitamente os valores ligados aos conceitos NCI tesauro na lista de valores permitidos.
O novo processo irá apoiar a anotação dos valores admissíveis com conceitos NCI Thesaurus e a capacidade de usar e criar uma hierarquia de valores reflexivos da hierarquia no vocabulário fonte de dentro do Modelo UML, em vez de criar a anotação e hierarquia de valores na atividade de pós-curadoria.
Outro requisito que descobrimos foi a necessidade de capturar o texto de documento específico para valores admissíveis que devem estar presentes na lista de verificação PAC, exatamente como prescrito pelos autores do protocolo.

Apesar de um modelo recém-desenvolvido pode optar por representar este como dois atributos distintos, modelos de dados existentes, como os baseados nas listas de verificação de câncer CAP não capturam dados a este nível de granularidade e anotação semântica, portanto, deve fornecer um método para expressar tais construções.
Em um pequeno número de casos, o método de anotação semântica não era suficientemente expressivo para transmitir o significado de um dado particular.
Neste caso, não havia maneira de transmitir o status equivalente dos dois conceitos de invasão venosa e linfática emparelhados pela conjuntiva e / ou.

A distinção entre qualificadores e propriedades provou ser um dos aspectos mais difíceis de estabelecer anotações humanos consistentes. Determinar qual o termo deve ser usado com a propriedade e que termos deve ser eliminatórias muitas vezes parece um tanto arbitrário.
Estas decisões humanas poderiam ser mais consistente, estabelecendo mais diretrizes formais para fazer essas escolhas, como os desenvolvidos para outras tarefas de anotação humanos.

O ambiente de modelagem caCORE de multicamadas é projetado para manter o núcleo de conhecimento canônico na camada terminologia/ontologia, enquanto contextualiza significado semântico nos metadados estruturados.
Quando as camadas não são devidamente sincronizadas, pode não ser possível fazer conclusões válidas sobre os significados contextualizados representados nos modelos de informação e metadados estruturados.

Modelo de informação comum
A ligação ao vocabulário controlado
Reutilização em vários sistemas
Potencial para inferência utilizando o NCI Thesaurus

Os modelos da lista de verificação PAC e metadados são destinados a se tornar um padrão de dados caBIG ™ que podem ter várias finalidades.
Há quatro aplicativos atualmente trabalhando na incorporação de metadados CAP - dois produtos caBIG ™, um aplicativo do fornecedor, e aplicação educativa uma pesquisa.
Estas aplicações demonstrar a diversidade de usos que podem ser suportados por essa norma eletrônico de dados semanticamente anotada.
CAE
caTIES
Cerner CoPathPlus caBIG™ Data Extractor
ReportTutor

Com o avanço de trabalho, esperamos movimentar este modelo para a aceitação como um padrão caBIG ™, na sequência de um processo bem descrito concebidas para promover o desenvolvimento de dados padrão .
Os três modelos que desenvolvemos formarão a base para o trabalho futuro a desenvolver todos os checklists 45 da CAP, como parte de um modelo de informação comum.

O CAP checklists câncer modelo fornece um estudo de caso de dados iniciais de implementação padrão usando o metodologia caBIG. Os modelos e associados de metadados estão disponíveis ao público, e são atualmente usado dentro de uma variedade de aplicações. Os resultados do nosso trabalho identifica algumas limitações dos métodos caBIG que ilustrem informar as futuras versões do processos e tecnologias.
Entretanto, nossos resultados também destacam a eficácia e potencial de integração semântica de Sistemas de Informática Biomédica que utilizam uma abordagem de modelagem multicamadas.

1. Buetow K: Cyberinfrastructure: empowering a "third way" in biomedical research. Science 2005, 308(5723):821-824. 2. The Cancer Biomedical Informatics Grid (caBIG) [http://cabig.nci.nih.gov] 3. The caBIG Compatibility Guidelines, Revision 2 [https://cabig.nci.nih.gov/guidelines_documentation] 4. Shared Pathology Informatics Network [http://www.cancerdiagnosis.nci.nih.gov/spin/] 5. Melamed J, Datta MW, Becich MJ, Orenstein JM, Dhir R, Silver S, Fidelia-Lambert M, Kadjacsy-Balla A, Macias V, Patel A, Walden PD, Bosland MC, Berman JJ: The Cooperative Prostate Cancer Tissue Resource: a specimen and data resource for cancer researchers. Clinical Cancer Research 2004, 10(14):4614-4621. 6. Pennsylvania Cancer Alliance Bioinformatics Consortium [http://pcabc.upmc.edu/main.cfm] 7. Grizzle WE, Aamodt R, Clausen K, LiVolsi V, Pretlow TG, Qualman S: Providing human tissues for research: how to establish a program. Archives of Pathology and Laboratory Medicine 1998, 122(12):1065-1076. 8. National Cancer Institute Clinical Trials Cooperative Group Program [http://www.cancer.gov/cancertopics/factsheet/NCI/clinical-trials-cooperative-group] 9. Specialized Programs of Research Excellence (SPORE) [http://spores.nci.nih.gov/index.html] 10. CDE Browser Tool [https://cdebrowser.nci.nih.gov/CDEBrowser/]










![SEJA BEM-VINDO · Bem-vindo • Shelley Row, Engenheira Profissional de Operações de Trânsito (P.E.[Professional Engineer], PTOE [Professional Traffic Operations Engineer])](https://img.pdfslide.us/doc/110x75/5f67ae2b81fe373d865176e9/seja-bem-vindo-bem-vindo-a-shelley-row-engenheira-profissional-de-operaes.jpg)


















