Embed Size (px)
DESCRIPTION
DirectCompute Accelerated Separable Filtering. Separable Filters. Much faster than executing a box filter Classically performed by the Pixel Shader Consists of a horizontal and vertical pass Source image over-sampling increases with kernel size Shader is usually TEX instruction limited. - PowerPoint PPT Presentation
Citation preview


DirectCompute Accelerated Separable Filtering
28th February 2011 2AMD‘s Favorite Effects

Separable Filters• Much faster than executing a box filter• Classically performed by the Pixel Shader• Consists of a horizontal and vertical pass • Source image over-sampling increases with
kernel size– Shader is usually TEX instruction limited
28th February 2011 AMD‘s Favorite Effects 3

Separable? – Who Cares • In many cases developers use this technique
even though the filter may not actually be separable– Results are often still acceptable– Much faster than performing a real box filter– Accelerates many bilateral cases
28th February 2011 AMD‘s Favorite Effects 4
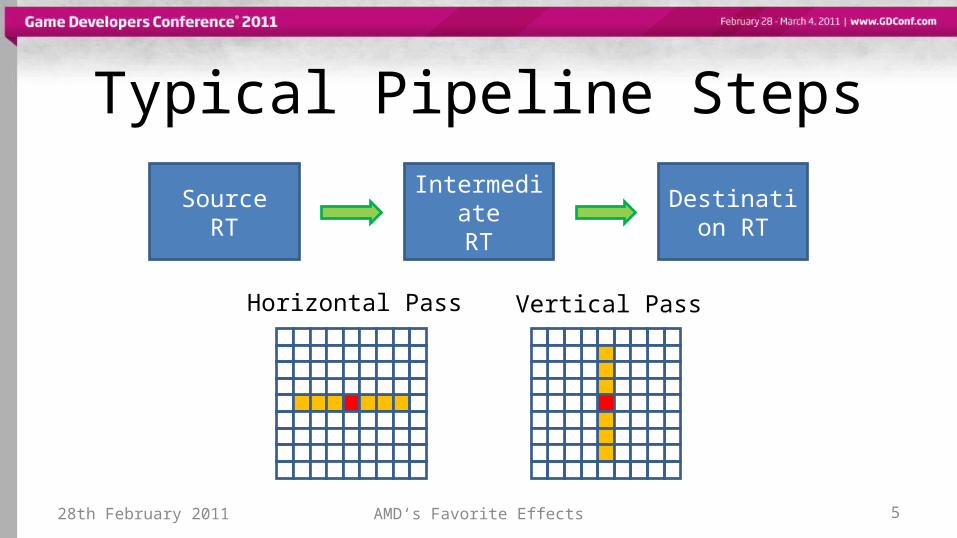
Typical Pipeline Steps
28th February 2011 AMD‘s Favorite Effects 5
SourceRT
IntermediateRT
Destination RT
Horizontal Pass Vertical Pass

Use Bilinear HW filtering?• Bilinear filter HW can halve the number of
ALU and TEX instructions– Just need to compute the correct sampling offsets
• Not possible with more advanced filters– Usually because weighting is a dynamic operation– Think about bilateral cases...
28th February 2011 AMD‘s Favorite Effects 6

Where to start with DirectCompute
• Is the Pixel Shader version TEX or ALU limited?– You need to know what to optimize for!– Use IHV tools to establish this
• Achieving peak performance is not easy – so write a highly configurable kernel– Will allow you to easily experiment and fine tune
28th February 2011 AMD‘s Favorite Effects 7

Thread Group Shared Memory (TGSM)• TGSM can be used to reduce TEX ops• TGSM can also be used to cache results
– Thus saving ALU ops too
• Load a sensible run length – base this on HW wavefront/warp size (AMD = 64, NVIDIA = 32) – Choose a good common factor (multiples of 64)
28th February 2011 AMD‘s Favorite Effects 8
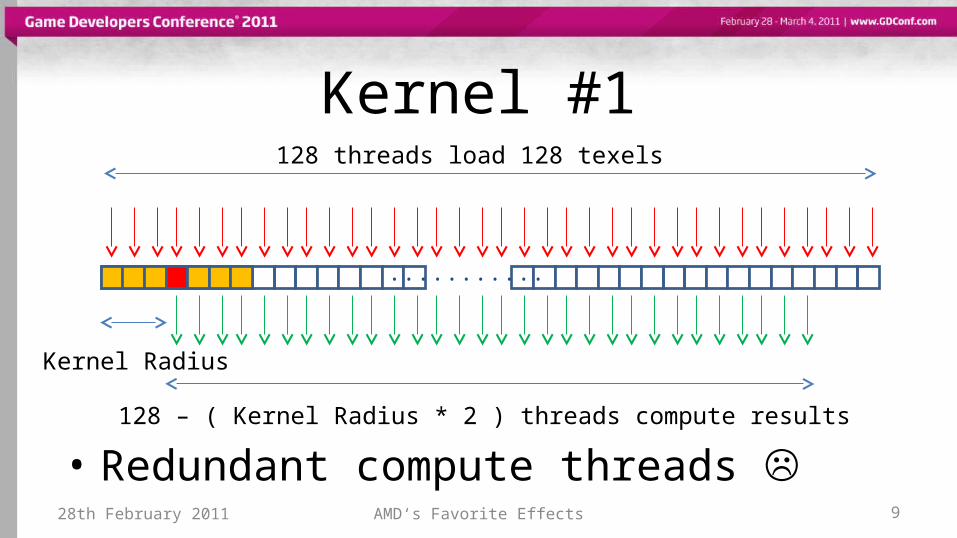
Kernel #1
• Redundant compute threads 28th February 2011 AMD‘s Favorite Effects 9
...........
128 threads load 128 texels
128 – ( Kernel Radius * 2 ) threads compute results
Kernel Radius

Avoid Redundant Threads• Should ensure that all threads in a group have
useful work to do – wherever possible• Redundant threads will not be reassigned
work from another group• This would involve alot of redundancy for a
large kernel diameter28th February 2011 AMD‘s Favorite Effects 10

Kernel #2
28th February 2011 AMD‘s Favorite Effects 11
...........
128 threads load 128 texels
128 threads compute results
Kernel Radius
• No redundant compute threads
Kernel Radius * 2 threadsload 1 extra texel each

Multiple Pixels per Thread• Allows for natural vectorization
– 4 works well on AMD HW– Doesn‘t hurt performance on scalar HW
• Possible to cache TGSM reads on General Purpose Registers (GPRs)– Quartering TGSM reads - absolute winner!!
28th February 2011 AMD‘s Favorite Effects 12
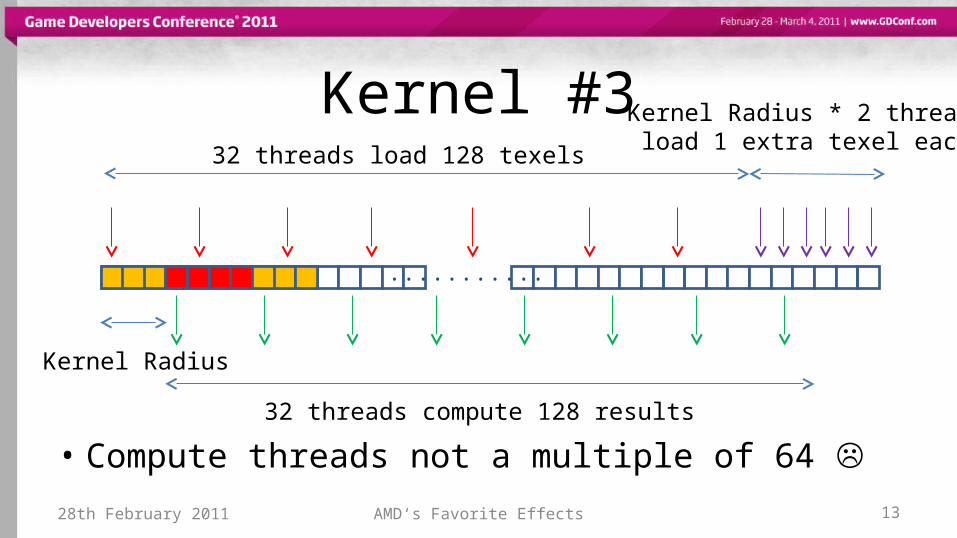
Kernel #3
• Compute threads not a multiple of 64 28th February 2011 AMD‘s Favorite Effects 13
...........
32 threads compute 128 results
Kernel Radius
32 threads load 128 texels
Kernel Radius * 2 threadsload 1 extra texel each

Multiple Lines per Thread Group• Process multiple lines per thread group
– Better than one long line– 2 or 4 works well
• Improved texture cache efficiency• Compute threads back to a multiple of 64
28th February 2011 AMD‘s Favorite Effects 14
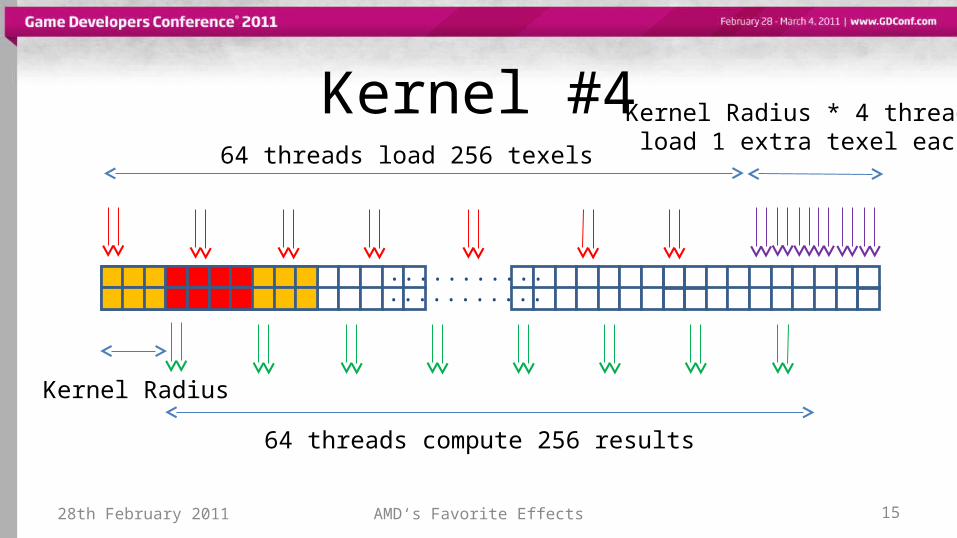
Kernel #4
28th February 2011 AMD‘s Favorite Effects 15
...........
...........
Kernel Radius
64 threads compute 256 results
64 threads load 256 texels
Kernel Radius * 4 threadsload 1 extra texel each

Kernel Diameter• Kernel diameter needs to be > 7 to see a
DirectCompute win– Otherwise the overhead cancels out the
advantage
• The larger the kernel diameter the greater the win
28th February 2011 AMD‘s Favorite Effects 16

Use Packing in TGSM• Use packing to reduce storage space required in
TGSM– Only have 32k per SIMD
• Reduces reads/writes from TGSM• Often a uint is sufficient for color filtering• Use SM5.0 instructions f32tof16(), f16tof32()28th February 2011 AMD‘s Favorite Effects 17

High Definition Ambient Occlusion
28th February 2011 AMD‘s Favorite Effects 18
Depth + Normals
HDAO buffer
* =
Original Scene Final Scene

Perform at Half Resolution• HDAO at full resolution is expensive• Running at half resolution captures more
occlusion – and is obviously much faster• Problem: Artifacts are introduced when
combined with the full resolution scene
28th February 2011 AMD‘s Favorite Effects 19

Bilateral Dilate & Blur
28th February 2011 AMD‘s Favorite Effects 20
HDAO buffer doesn‘t match with scene
A bilateral dilate & blur fixes the issue

New Pipeline...
28th February 2011 AMD‘s Favorite Effects 21
Bilinear Upsample Intermediate UAV Dilated & Blurred
Horizontal Pass Vertical Pass
½ Res Still much faster than performing at full res!
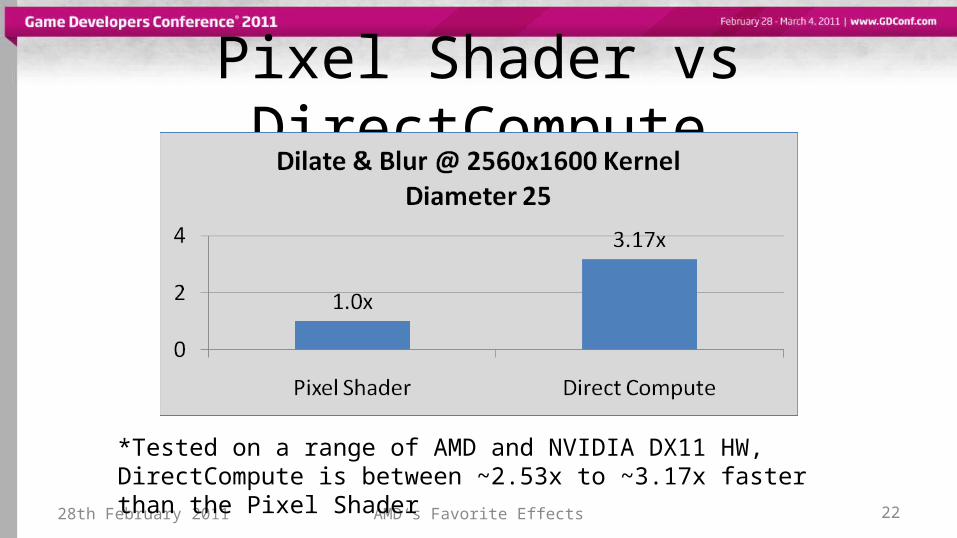
Pixel Shader vs DirectCompute
28th February 2011 AMD‘s Favorite Effects 22
*Tested on a range of AMD and NVIDIA DX11 HW, DirectCompute is between ~2.53x to ~3.17x faster than the Pixel Shader

Depth of Field• Many techniques exist to solve this problem• A common technique is to figure out how
blurry a pixel should be– Often called the Cirle of Confusion (CoC)
• A Gaussian blur weighted by CoC is a pretty efficient way to implement this effect
28th February 2011 AMD‘s Favorite Effects 23
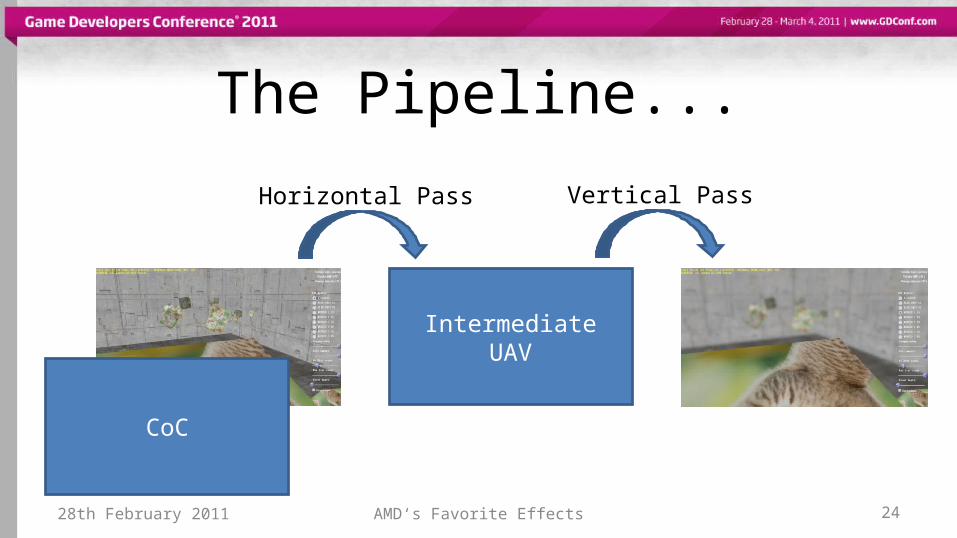
The Pipeline...
28th February 2011 AMD‘s Favorite Effects 24
Intermediate UAV
CoC
Horizontal Pass Vertical Pass
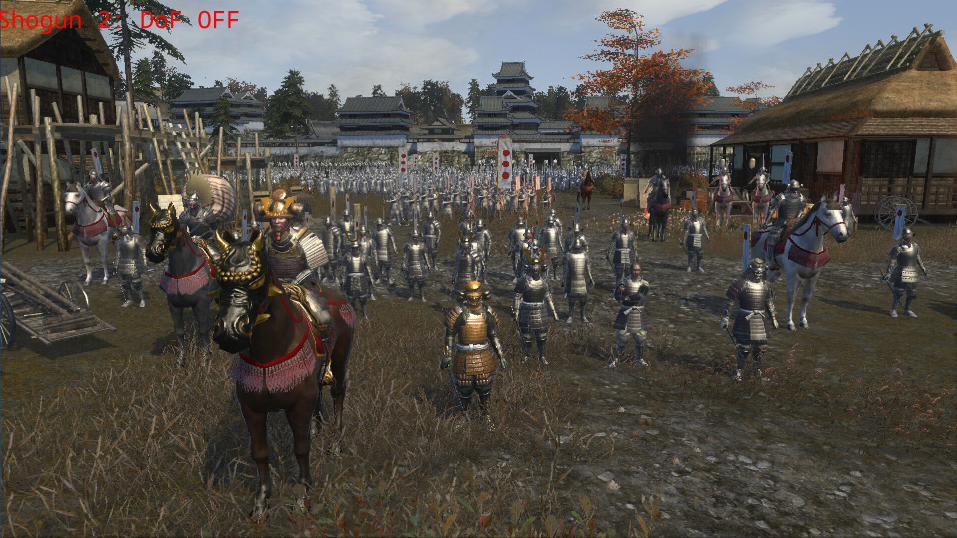
28th February 2011 AMD‘s Favorite Effects 25
Shogun 2: DoF OFF
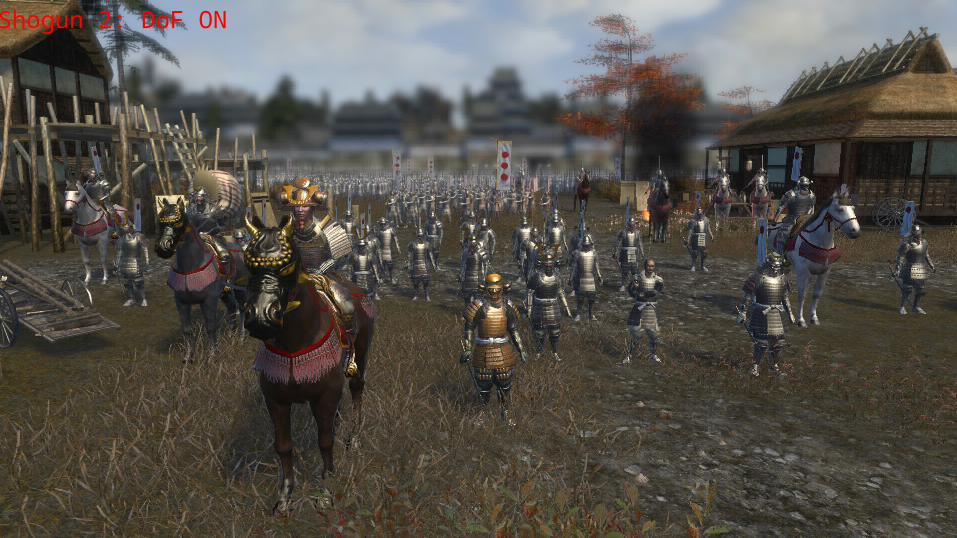
28th February 2011 AMD‘s Favorite Effects 26
Shogun 2: DoF ON
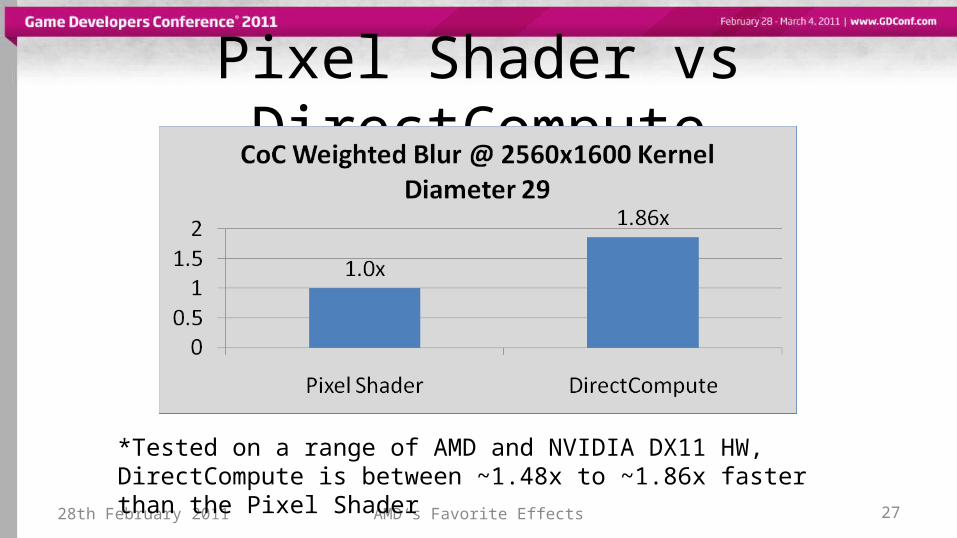
Pixel Shader vs DirectCompute
28th February 2011 AMD‘s Favorite Effects 27
*Tested on a range of AMD and NVIDIA DX11 HW, DirectCompute is between ~1.48x to ~1.86x faster than the Pixel Shader

Summary• DirectCompute greatly accelerates larger kernel diameter
filters• Allows for filtering at full resolution• For access to source code:
– HDAO11: [email protected]– DoF11: [email protected]
28th February 2011 AMD‘s Favorite Effects 28
[email protected]@amd.com
Please fill in the feedback forms!28th February 2011 29AMD‘s Favorite Effects





























