Embed Size (px)
Citation preview

Derived Sentiment Analysis Using JMP ProMichael D. Anderson, Ph.D., Christopher Gotwalt, Ph.D.
October 20, 2017
JMP 13 introduced Text Explorer. The new platform provides userswith the ability to curate freeform text and generate insights into themes andimportant terms. While incredibly useful, text exploration is really only a firststep in answering the problem at hand. Often what we really want to do isidentify the key words in a set of documents that are strongly associated witha particular response when, for example, evaluating purchasing behavior orcustomer reviews. Typically this is done using traditional Sentiment Analysis,which relies on word lists supplied by third party vendors that do not takeinto consideration specific contexts or audience. An alternative approach,sometimes called "Supervised Learning Sentiment Analysis," combines textanalysis with predictive modeling to determine which words and phrasesare most relevant to the problem at hand. It uses data to determine boththe direction and strength of the term association via a fairly approachablemodeling exercise. Using JMP Pro 13 for Supervised Learning SentimentAnalysis is now easier than ever; we aim to demonstrate why with a series ofcase studies arising from consumer research and social media contexts.
Introduction
"You Keep Using That Word, I Do Not Think It Means What You Think It Means. . . "- Inigo Montoya, From The Princess Bride, MGM Studios, 1987
Lets start off with a simple question: "What do you meanwhen you say something?" The concepts of thought, language andmeaning are so intertwined that it is hard to disentangle them. Hu-mans use language as a method for conveying emotion, informationand even entertainment. The study of sentiment, as it is used in theliterature, "seeks to determine the general sentiments, opinions, andaffective states of people reflected in a corpus of text.1" Since the 1 Practical Text Mining and Statistical
Analysis for Non-Structured Text Data Ap-plications., Elder, et al., 2012, AcademicPress
early 1980s there have been there have been a number of papersaddressing the concept of sentiment. But, the topic really startedgaining momentum with the introduction of data mining techniquesand machine learning algorithms around the turn of the 21
st century.Sentiment analysis still has significant challenges because of the wayin which we use language. Local dialects, idioms and trends towardhyperbole or sarcasm all provide challenges to someone attemptingto study sentiment with data mining techniques.

derived sentiment analysis using jmp pro 2
Why did it take so long for the field of text analytics to
get off the ground? There are two main factors that appear tohave contributed. First, the aforementioned computational powerand methods necessary for text analytics haven’t been made availableuntil only recently. Recall back to the early part of this century whendesktop PC’s with 512 MB of RAM were common and multicoreprocessors were in limited production. Most entry-level smartphonestoday now exceed these capabilities. In the past 10 years there hasbeen an explosion in the processing capabilities available to scientists,both in server- and desktop-scale applications. It has therefore onlybeen within in the past few years that we have had the hardwareneeded to analyze language effectively.
The second factor is the issue of available data. In text analyticsthese data sets are called corpora (singularly, a corpus). Each itemwithin a corpus is called a document2. Because of the extensive vari- 2 In JMP, and many other cases, these
documents are arranged one docu-ment per row in a data table or otherdatabase that acts as the corpus.
ability present in spoken and written language, the corpora for anal-ysis must be quite large, usually several thousand documents. Thesedocuments must then be curated into a compendium that can beprimed for analysis. Until recently there just haven’t been many gooddata sets to analyze. Now it is possible to search social media siteslike Twitter or Facebook to generate a corpus with a million docu-ments without issue. Sites such as Amazon have also provided accessto their user-generated product reviews which provide both text anda favorability rating. Moreover, many government agencies in the USand abroad now maintain sites dedicated to publishing survey datawhich often includes free text and comment fields. This all meansthat we now have the corpora we need to finally start looking at thesetopics in detail.
The Problem
The real problem with sentiment analysis is how to go
about doing it. There are three general schools of thought onhow to approach sentiment analysis: using a dictionary, using aperson, using a machine. To better understand these groups, it isfirst important to review a standard sentiment analysis workflow.In simplified form, all sentiment analysis methods require someelement of predictive modeling. First, a corpus is edited to cleanup mismatches related to spelling, slang or other typos; this willserve as a training set. This training data is then used to generate amodel that determines a score for each sentiment thought to be in thedata set. Models created from a training set are then applied to newdocuments.

derived sentiment analysis using jmp pro 3
The three methods each approach score generation differently.The dictionary method uses keywords and phrases that have beenassociated with a set of sentiments. These associations are aggregatedto produce the final scores for each sentiment. Using a person (i.e.,supervised learning) involves having a panel score each document inthe training corpus in isolation with the scores then being aggregatedand checked for agreement. Machine learning algorithms then try todetermine those factors that caused scorers to assign a certain senti-ment. Using a machine (i.e., unsupervised learning) applies machinelearning algorithms to evaluate sentiment.
Each of these methods have their drawbacks. The dictionarymethod presumes that a word embodies a given sentiment regard-less of context. Supervised learning is labor intensive and requirescare in making sure that there is agreement between scores for thetraining corpus. Unsupervised learning requires large corpora withrich supplemental data and large computational resources to attempt.All three methods are susceptible to inaccuracies brought about bygrammatical inconsistencies, e.g., sarcasm or regional idioms. In thispaper we will apply a blend of self-reported sentiment in the form ofscoring and contextual data along with generalized regression as avariable selection technique. We propose that these two components,when applied together, provide a faster work flow and more accurateassessment of the sentiment in a corpus than the more traditionalmethods detailed earlier.
Derived Sentiment Analysis
Using a model to determine sentiment requires both a
response and variables. In the work flow that we propose re-sponses are self-reported or extracted from the documents in thecorpus. Examples of this self-reporting include: stars provided witha written review, Likert Scale scores in a survey, or even (as we willdemonstrate later) emoji. Leveraging the data that is already presentin a corpus resolves a number of problems traditionally associatedwith sentiment analysis. First, the respondents themselves are pro-viding their sentiment scores. This saves on time and costs associatedwith curating the corpora. Second, it removes any ambiguity aboutrespondent sentiment, which should make the results more accu-rate. The variables in this case come from a curated list of words andphrases from the corpus called a Document Term Matrix (DTM). TheDTM takes the form of a collection of indicator columns that showwhen (and how many times) a given word or phrase is present in adocument.

derived sentiment analysis using jmp pro 4
The method for developing a sentiment model from the corpus isbroken into two steps. First, the DTM is created using the Text Ex-plorer. This is accomplished using the Text Explorer Platform in JMP.Within the Text Explorer, terms that should be excluded from con-sideration are excluded using a stop word list. Regular Expressionsare also used to remove formatting, URLs, unnecessary punctuation,etc. Terms are also stemmed to remove the influence of tense andpart-of-speech usage. Lastly, a recoding operation is used to clean upspelling errors and change terms when needed. After the curationprocess is complete, the DTM is exported back to the data table.
Once the DTM has been exported, it is used with the self-reportedresponses in Generalized Regression with an Elastic Net penalization.Generalized Regression and the Elastic Net Penalty were chosen dueto the ability of the Elastic net to function both as a variable selectiontool and as a method for dealing with covariance. The model reportprovides insights into the important terms in a given document thatindicate a specific sentiment. The model can also be used to predictsentiment for new documents that may not include the scoring infor-mation.
Case Study 1: The Toronto Casino Survey
You’ve got to know when to hold ’em, Know when to fold ’em. . .- From The Gambler, Kenny Rodgers
Background
In 2012, the City of Toronto conducted an online survey
to gauge public reaction to a proposed casino project. The surveywas designed and conducted between November 2012 and January2013. Approximately 18,000 responses were submitted. The resultswere posted online for public consumption3 by the City of Toronto 3 http://www.toronto.ca/
casinoconsultation/in a set of Excel files. The survey instrument was composed of 11
questions in multiple parts with most questions having both a ratingcomponent and a comment section. The application of a derivedsentiment analysis to the first question in the survey, "Please indicateon the scale below how you feel about having a new casino in Toronto", willbe used for this case study.

derived sentiment analysis using jmp pro 5
Analysis and Results: Proof of Concept
Casinos tend to be polarizing topics. We found that this sur-vey was no exception. Looking at the distribution of responses(Figure1) respondents were generally divided between two groups: stronglyopposed or strongly in favor of the proposal. The middle responsesrepresented only 11% of the corpus. We chose to exclude the neutralresponses from the analysis (3%) and regroup the response data intoa simple binary response (Figure 2).
Strongly Opposed
Neutral or Mixed
Strongly in Favor
Figure 1: Distribution of survey re-sponses as found in the corpus.
Opposed
0
In favor
Figure 2: Distribution of survey re-sponses binned into a binary response.
Next, the corpus must be curated for modeling. At the timeof the original survey, respondents had the opportunity to use a web-form or submit a paper copy. Both of these routes have potential fortypographical and spelling errors. The corpus was analyzed usingText Explorer with stemming to help reduce some of the variabil-ity in word use. We worked with recode and stop words to removewords and terms that didn’t appear significant using a word cloud toassist with the curation process. Before removing terms we createda word cloud to help with curation process. The word cloud afterthe curation process, colored using the recoded response variable, isshown in Figure 3. While constructing the word cloud JMP catego-rized "In Favor" as "1" and "Against" as "2". Simple inspection of thecloud provides a number of insights. The color scaling is centeredon a value of 1.6 indicating that the majority of respondents opposea casino. The word usage is also interesting. Terms like "Toronto"and "revenu·" tend to be used in a context more favorable to a casino,whilst terms like "gambling" and "crime·" are associated with lessfavorable opinions. This empirical correlation between the terms andthe responses suggests that a sentiment model for the corpus is possi-ble. Using Text Explorer a DTM including all terms that appeared inthe corpus more than 500 times was exported. We used the Ternarysetting to account for multiple appearances in a document.
torontogambling
peoplerevenu·money· increas·
crime·
addict·
social·
business
creat·
famili·
traffic· attract·
benefit·downtown·
already
problem·
negat·impact·
communiti·
entertain· tourism
local·
econom·gambling addict·
tourist·
generat·cultur·
congest·health·
cost·
locat·
public·citi·place·
need·
issu·
gambler·
think·
economi·
support·
develop·
better·neighbourhood·
woodbin·
enoughconcern· financi·
provid·
activ·
effect·
encourag·
believ·
exist·
incom·
niagara·
social· problem·
gamble
caus·
infrastructur·
waterfront·
park·
space·
build·
govern·
live·
imag·
great·
destroy·
employ·
surround·
promot·
opportun·
ontario·
societi·
potenti·
world· class·
profit·
problem· gambling
afford·
crimin·spend·
addit·
valu·
servic·
resid·
wrong·
becom· make·
affect·
area·
access·
take·
rais·
larg·
citizen·
around
toronto's
fall·
posit·
facil·tax·
small
industri·
venu·
major·
organ·
dollar·
transit·
another
associ·
restaur·
vegas
close·
creation·
fund·
thing·
game·go·
casino's
relat·
prostitut·
individu·
wast·
contribut·
improv·
person·
rather
downtown· toronto
project·
oppos·
someth·
without
outweigh·
mental·
especially
sourc·
result·
provinc· interest·
built·
polic·least
element·
destin·
behaviour·
healthy
poverty
properti·
current·
damag·
visitor·
propos·
moral·drive·
encourag· gambling
addict· to gambling
urban·
strong·
alcohol·
qualiti·
vulner·
like·
pay·
number·
ad·
within
torontonian·
popul·
oper·
general·
nothing
reason· friend·
option·
centr·
includ·
sustain·
instead
windsor·
little
possibl·
outsid·
invest·
transport·
drug·
enjoy·
come·
destruct·
travel·
establish·
detriment·
suffer·
ruin·
chang·
really
spent
construct·
hous·
depend·racetrack·
residential
lead·
studi·
children·
safety
right·
signific·
direct·
crowd·
visit·
environ·
short·
harm·
complex·
amount·
serious·
offer·
world·
rate·
hotel·
futur·
often
boost·
lower·
owner·
gambling problem·
consequ·
tacki·
growth
level·
resourc·
avail·
higher
exploit·
desper·
prey·
drain·
requir·
leav·
evid·
advantag·program·
wors·
nearby
focus·
every
alway·
street·
never
hors·
slots
undesir·
race·
privat·
reput·
favour·
limit·
taxpay·
mean·
gridlock·
promis·
suicid·
promot· gambling
plan·
corrupt·
based
might
atlantic
work·
class·
advers·
extra
enhanc·
convent·
unhealthy
theatr· youth·
consid·
violence
municip·
lose·
influenc·
event·
gain·
greater
system·
product·
expens·
divers·
import·
habit·
vibrant
gambling is addict·
show·
canada·
fabric
depress·
burden·
Binary Sentiment
1.21.31.41.51.61.71.81.92.0
Figure 3: Word Cloud for the curatedcorpus colored by the binary responsevariable. Note that while constructingthe word cloud JMP categorized "InFavor" as "1" and "Against" as "2".
derived sentiment analysis using jmp pro 6
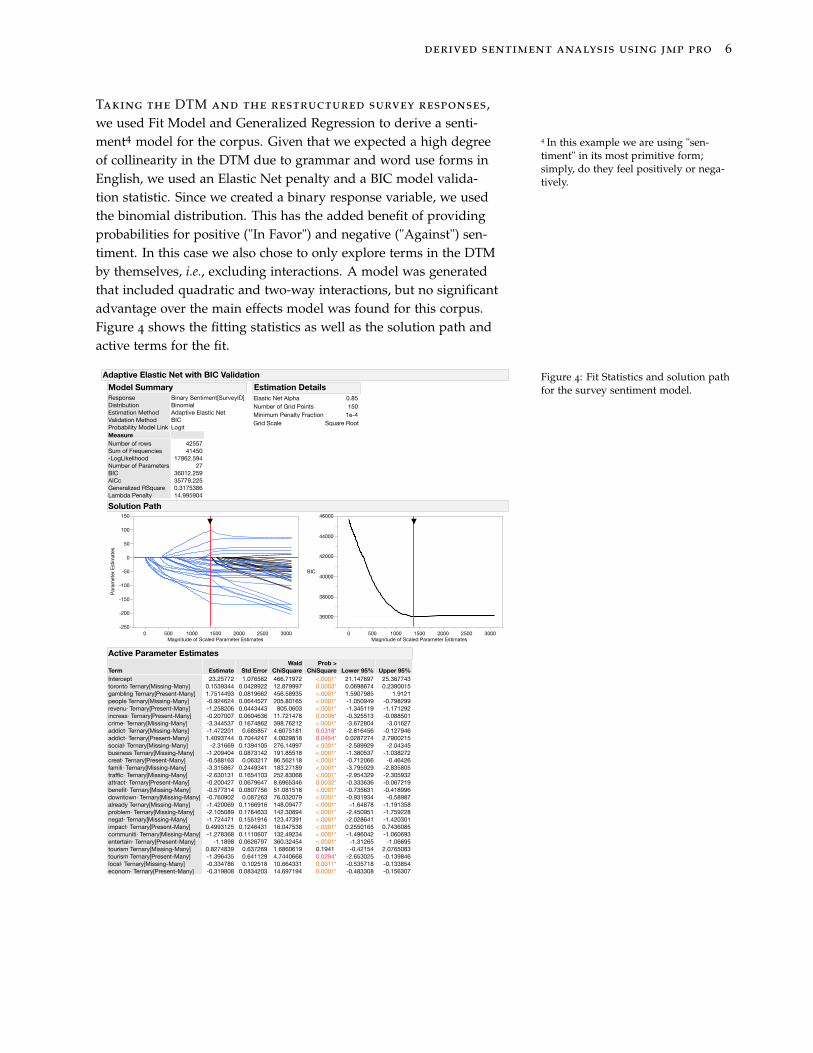
Taking the DTM and the restructured survey responses,we used Fit Model and Generalized Regression to derive a senti-ment4 model for the corpus. Given that we expected a high degree 4 In this example we are using "sen-
timent" in its most primitive form;simply, do they feel positively or nega-tively.
of collinearity in the DTM due to grammar and word use forms inEnglish, we used an Elastic Net penalty and a BIC model valida-tion statistic. Since we created a binary response variable, we usedthe binomial distribution. This has the added benefit of providingprobabilities for positive ("In Favor") and negative ("Against") sen-timent. In this case we also chose to only explore terms in the DTMby themselves, i.e., excluding interactions. A model was generatedthat included quadratic and two-way interactions, but no significantadvantage over the main effects model was found for this corpus.Figure 4 shows the fitting statistics as well as the solution path andactive terms for the fit.
Adaptive Elastic Net with BIC ValidationModel SummaryResponseDistributionEstimation MethodValidation MethodProbability Model Link
Binary Sentiment[SurveyID]BinomialAdaptive Elastic NetBICLogit
MeasureNumber of rowsSum of Frequencies-LogLikelihoodNumber of ParametersBICAICcGeneralized RSquareLambda Penalty
4255741450
17862.59427
36012.25935779.2250.317538614.995904
Estimation DetailsElastic Net Alpha 0.85Number of Grid Points 150Minimum Penalty Fraction 1e-4Grid Scale Square Root
Solution Path
-250
-200
-150
-100
-50
0
50
100
150
Para
met
er E
stim
ates
0 500 1000 1500 2000 2500 3000Magnitude of Scaled Parameter Estimates
36000
38000
40000
42000
44000
46000
BIC
0 500 1000 1500 2000 2500 3000Magnitude of Scaled Parameter Estimates
Active Parameter Estimates
TermIntercepttoronto Ternary[Missing-Many]gambling Ternary[Present-Many]people Ternary[Missing-Many]revenu· Ternary[Present-Many]increas· Ternary[Present-Many]crime· Ternary[Missing-Many]addict· Ternary[Missing-Many]addict· Ternary[Present-Many]social· Ternary[Missing-Many]business Ternary[Missing-Many]creat· Ternary[Present-Many]famili· Ternary[Missing-Many]traffic· Ternary[Missing-Many]attract· Ternary[Present-Many]benefit· Ternary[Missing-Many]downtown· Ternary[Missing-Many]already Ternary[Missing-Many]problem· Ternary[Missing-Many]negat· Ternary[Missing-Many]impact· Ternary[Present-Many]communiti· Ternary[Missing-Many]entertain· Ternary[Present-Many]tourism Ternary[Missing-Many]tourism Ternary[Present-Many]local· Ternary[Missing-Many]econom· Ternary[Present-Many]
Estimate23.25772
0.15393441.7514493-0.924624-1.258206-0.207007-3.344537-1.4722011.4093744
-2.31669-1.209404-0.588163-3.315867-2.630131-0.200427-0.577314-0.760902-1.420069-2.105089-1.7244710.4993125-1.278368
-1.18980.8274839-1.396435-0.334786-0.319808
Std Error1.076562
0.04289220.08196620.06445270.04434430.06046360.1674862
0.6858570.70442470.13941050.0873142
0.0632170.24493410.16541030.06796470.0807756
0.0872630.11669160.17646330.15519160.12464310.11106070.0626797
0.6372690.6411290.102518
0.0834203
WaldChiSquare466.7197212.879997456.58935205.80165
805.060311.721478398.762124.60751814.0029818276.14997191.8551886.562118183.27189252.830688.696534651.08151876.032079148.09477142.30894123.4739116.047538132.49234360.324541.68606194.744066810.66433114.697194
Prob >ChiSquare
<.0001*0.0003*<.0001*<.0001*<.0001*0.0006*<.0001*0.0318*0.0454*<.0001*<.0001*<.0001*<.0001*<.0001*0.0032*<.0001*<.0001*<.0001*<.0001*<.0001*<.0001*<.0001*<.0001*0.19410.0294*0.0011*0.0001*
Lower 95%21.1476970.06986741.5907985-1.050949-1.345119-0.325513-3.672804-2.8164560.0287274-2.589929-1.380537-0.712066-3.795929-2.954329-0.333636-0.735631-0.931934
-1.64878-2.450951-2.0286410.2550165-1.496042
-1.31265-0.42154
-2.653025-0.535718-0.483308
Upper 95%25.3677430.2380015
1.9121-0.798299-1.171292-0.088501
-3.01627-0.1279462.7900215
-2.04345-1.038272
-0.46426-2.835805-2.305932-0.067219-0.418996
-0.58987-1.191358-1.759228-1.4203010.7436085-1.060693
-1.066952.0765083-0.139846-0.133854-0.156307
Figure 4: Fit Statistics and solution pathfor the survey sentiment model.

derived sentiment analysis using jmp pro 7
The model has what most would consider a poor r2 (Gener-alized RSquare in the Model Summary); however, all the terms exceptone appear to be significant. The low r2 in this case has less to dowith the quality of the model and more to do with the noise in thedata set. Since spoken and written language have significant flexi-bility in word usage we expect that real world corpora will be noisy.This will depress r2. Examination of how the model fit the data usingthe Solution Path and the Active Parameters indicate that our modelis near the optimal for this corpus. We can take confidence in the al-gorithm removing approximately half of the proposed terms in theDTM from the model. Further, the proposed optimal model sits inthe general minimum for the fitting statistic.
econom·local·
tourismentertain·
communiti·impact·negat·
problem·already
downtown·benefit·attract·traffic·famili·creat·
businesssocial·addict·crime·
increas·revenu·people
gamblingtoronto
Figure 5: Distribution of terms used byopponents to the casino measure.
econom·local·
tourismentertain·
communiti·downtown·
benefit·attract·creat·
businessincreas·revenu·peopletoronto
Figure 6: Distribution of terms used byproponents of the casino measure.
Specifically considering the Solution Path we can make inferencesabout general features of the model and how given terms impactthe sentiment it predicts. During the set up we chose to target thepositive, i.e., in favor of the casino, sentiment response. This make itpossible to use a Solution Path as a tool for understanding whichterms influence the sentiment and by how much. Each term in themodel is represented in a line in the Solution Path. Lines in blue areactive in the model whilst those in black are excluded. The displace-ment of a line away from zero on the y-axis is representative of thecoefficient estimate for that model term. Qualitatively, it’s possible tosee that most of the language used in the surveys project a negativesentiment, while a few key terms show a positive sentiment.
We used tools in JMP to generate findings from the model.We were first able to determine the primary pro and con argumentsby optimizing the profile for positive and negative sentiment. Thosewho view the proposal positively discussed the proposal from aneconomic standpoint, citing increased revenues to the city and localbusinesses. Those opposed to the casino cited social issues such ascrime, addiction and the presence of similar facilities near by. Thesetwo view points can be seen by examination of the histograms pro-vided in Figures 5 and 6, which were created by filtering for propo-nents and opponents as predicted by the sentiment model.

derived sentiment analysis using jmp pro 8
Case Study 2: The Rains of Castamere
A coat of gold, a coat of red, A lion still has claws, And mine are long and sharp, myLord, As long and sharp as yours. . . "
- From The Rains of Castamere, A Storm of Swords, George R.R. Martin
Figure 7: Geographic distribution oftweets in the corpus.
Background
We will do our best to avoid spoilers in this discussion,but if you read on, on your own head be it.
One of the most pivotal scenes in George R.R. Martin’sGame of Thrones series is The Red Wedding. The scene occursduring the episode, "The Rains of Castamere." It aired on June 2, 2013
and is viewed as a very intense point in the narrative. We obtained acorpus containing documents (tweets) that used hashtags related tothe program during and immediately after the first broadcast of theepisode from around the world. The corpus contains approximately27,000 tweets and includes 35 different languages. The tweets forwhich there was location data available are shown in Figure 7. Ap-proximately 24,000 documents (about 90%) are in English and 640 ofthose contain emoji.

derived sentiment analysis using jmp pro 9
Analysis: The Red Wedding
The initial curation process, shown as a word cloud in Figure8, showed the significant presence of an unexpected term, "ud83d."Initially, we thought this term was part of a url that was not scrubbedby our regular expression filtering. However, after a little investiga-tion, we discovered that this was the way that Twitter recorded emojiand other unicode characters. This realization presented an interest-ing avenue for sentiment analysis provided that the emoji could beextracted and recoded into a useful form.
#redwed·watch·
flip·
justud83d
last·night·kill·
wed·
still·shock·book·
nowread·like·
oh
charact·just happen·
crapknow·
tonight·
go·come·
red
george r· r· martin·happen·
holi·
think· see·one·omg·
wow
reaction·
stark·cri·
feel·
need·
gad
end·well·
say·
even·
never
peopl·
make·ever
use·
spoiler·
anyon·
time·
140
everyon·
spoil·
good·
show·
tvwtf·
ude2d
week·
heck
#therainsofcastamere
actual·
knew
best
believ·
really
lannist·
day·
guy·
die·
want·
seen
fan·
ude31
much
season·
love·
frankieboyle
thing·
wait·
o
right·sorry
thronecastlatest
amaz·
new
many
rain·tweet·
emot·
speechless
man·
word·
next
though
robb·
today·
way·
3
tywin·
little
final·expect·
dwarf
castamere
start·
sad·
hbo·
hate·
brutal·
made
seri·
talk·
yet
stop·
hope·
game·
frey·
life·
scene·
serious·dont
okjoffrey·
sit·
2
via
heart·look·
gonna
ruin·
9
bit·nice·
upset·depress·
play·
ingloriousclos
better
lol·
bad·
someon·
take·
thought·
intense
something
omfg
king·
left
yeah
bloody
thank·
damn·
doneface·
saw
react·
edsheeran
epic·
happi·
sure·
death·
pretty
always
minut·
rob·dark·
credit·s03e09
recov·
dead·
quit·
mind·
quiet·
absolut·
year·
tell·
first
im
pleas·
youtub·keep·
everyth·
1
jesus
tear·
back
u
sick·
tri·
crazy
getting
finish· real·
tomorrow·
miss·
great·
worse
liter·
work·
uk·
must
rememb·
ep·
catch·
walder·
martin·
cant awesom·
everybodi·
george
5
lot·
mad·
felt
anything
break·
lord·
music·
ned·
every
hour·
north
ciarabaxendale
uswin·
live·
total·
mean·
traumatis·
name·
call·
compilation
world·
laugh·
bed·
catelyn·
video·
seem·
piss·
hodor·
worst
surpris·
silenc·
prepar·
battl·
christ
trend·
throne·
guess·
since
went
ago
noth·moment·
told
sleep·
stun·
head·
d
reader·
find·
internet·
rr·
pain·
filch
might
friend·
10
lost
said
richard·
famili·
give·
complet·
also
difficult
far
glad
gunnarbharmless
lasers
mech
post·
ashens
s
redweddingtear·
event·
least
put·
snow·
drink·
anymore
wit·
help·
hug·
sound·author·
televis·
jon·
Figure 8: Word Cloud for the corpusduring the process of curation witharbitrary coloring. Note the large"ud83d" (middle left) indicating a largenumber of unicode in the corpus. Alsonote that strong language was recodedinto less offensive terms.
During the curation process, we noted a significant volume ofprofane language. For the figures in this document we have chosentho employ the Recode feature in Text Explorer to change them toless offensive terms. The word cloud for the curated corpus (Figure9) shows that viewers were taken aback by the episode.
#redwed·watch·
flip·
justlast·
night·kill·wed· still·
shock·
book·
now
read·like·ohcharact·
just happen·
crap
know·
tonight·
go·
come· red
george r· r· martin· happen·
holi·
think·
see·
one· omg·
wow
reaction·
stark·
cri·
feel·
need·
gad
end·
well·
say·
even·
never
peopl·
make·ever
use·spoiler·
anyon·
time·
140everyon·
spoil·
good·
show·tv
wtf·week·
heck
#therainsofcastamere
actual·
knew
best
believ·
really
lannist·day·
guy·
die·
want·
seen fan·
muchseason· love·
frankieboylething·
wait·
o
right·sorrythronecast
latest amaz·
new
many
rain·
tweet·
emot·
speechless
man·
word·
nextthough
robb·
today· way·
3
tywin·
little
final·expect·
dwarfcastamere
start·
sad·
hbo·
hate·
brutal· made
seri·
talk·
yet
stop·
hope·
game·
frey·
life·
scene·serious·
dont
ok
joffrey·
sit·
2
via
heart·
look·
gonna
ruin·
9bit·
nice·
upset·
depress·
play·
ingloriousclos
better
lol·
bad·
someon·
take·
thought·
intense
something
omfg
king·
left
yeah
bloody
thank·
damn·done
face·
saw
react·edsheeran
epic·
happi·
sure·
death·
pretty
always
minut·
rob·
dark·
credit·
s03e09recov· dead·
quit·
mind·
quiet·
absolut·
year·
tell·
first
im
pleas·
youtub·keep·
everyth·1
jesus
tear·
back
usick·
tri·crazy
getting
finish·
real·
tomorrow·
miss·
great·
worse
liter·
work·
uk·
must
rememb·
ep·
catch·
walder·
martin·
cant
awesom·
everybodi·
george
5
lot·
mad·
felt
anything
break·
lord·
music·
ned·
every
hour·
north
ciarabaxendale
us
win·
live· total·
mean·
traumatis·
name·
call·compilation
world·
laugh·
bed·
catelyn·
video·
seem·
piss·
hodor·
worst
surpris·
silenc·
prepar·
battl·
christ
trend·
throne·
guess·
since
went
ago
noth·
moment·
told
sleep·
stun·
head·
d
reader·
find·
internet·
rr·
pain·
filch
might
friend·
10
lost
said
richard·
famili·
give·
complet·
also
difficult
far
glad
gunnarbharmless
lasers
mech
post· ashens
s
redweddingtear·
event·
least
put·
snow·
drink·
anymore
wit·
help·
hug·
sound·
author·
televis·
jon·
traumat·
long·
folk·
Figure 9: Word Cloud for the curatedcorpus with arbitrary coloring. Notethat strong language was recoded intoless offensive terms.

derived sentiment analysis using jmp pro 10
Analysis: The Issue with Emoji
Today emoji5 ,6
are commonplace. To digital natives, emoji are 5 Emoji are ideograms and smileys usedin electronic messages and Web pages.Emoji are used much like emoticons andexist in various genres, including facialexpressions, common objects, placesand types of weather, and animals.Originally meaning pictograph, theword emoji comes from Japanese e("picture") + moji ( "character").6 en.wikipedia.org/wiki/Emoji
becoming a form of pidgin language with which to express senti-ment; emoji thus serve as an important response variable for derivedsentiment analysis. From a data perspective, emoji are stored in Twit-ter feeds as java source encodings of their unicode values - not asthe pictograms we have come to expect. For instance, the emoji fora "grinning face with smiley eyes" ( ) would appear as "\uE415" inthe text. This can be further complicated in cases where non-Englishlanguage documents are included in the corpus. In many cases, thesedocuments will also include unicode for decorated letters, ı.e., alower-case "a" with an umlaut (ä) which would appear as "\u00E4" ina tweet. To deal with these complications we first limited ourselvesto English tweets. Furthermore, the data set was processed using ascript that would parse emoji to create columns with occurrence fre-quency for each, translating them from java source notation to textdescription. By considering not just whether an emoji was used, buthow often it was used, we sought insight into the intensity of theunderlying sentiment expressed by the emoji.
:sob
::screa
m:
:flus
hed:
:perse
vere:
:cry:
:rage
::tired_
face
::w
eary:
:ang
uish
ed:
:ope
n_mou
th:
:fearful:
:broke
n_he
art:
:joy:
:aston
ished
::re
lieve
d::cold_
swea
t::frow
ning
::see
_no_
evil:
:dizz
y_face
::pen
sive:
Others
Figure 10: Emoji present in the corpusand their frequency of occurrence.
When we examined the frequency of occurrence for the emojipresent in the corpus, we found that a small fraction of the emojirepresented the bulk of the frequency data. A histogram, binned toput the bottom 20% of the emoji used into a single category, is shownin Figure 10. This category, "Others," represents approximately 70
emoji that were used a combined 588 times. Examining the other20 emoji it is easy to see there is significant overlap in sentiment;therefore it might be possible to perform factor analysis and extract asmall number of latent factors to use in a sentiment analysis in placeof the emoji themselves.

derived sentiment analysis using jmp pro 11
The results of the factor analysis (Figure 11) demonstrate that thereare probably 7 latent factors described by these emoji. The rotatedfactor loading show that factor analysis successfully grouped emojiinto new factors that are mostly orthogonal (Figure 12). Examinationof the emoji present in these rotated factors shows that the factorsfollow general emotional themes as indicated in the table (Figure 13).
Factor AnalysisEigenvalues
Number123456789
10111213
Eigenvalue7.09414.87302.82622.16201.29711.16981.00001.00001.00001.00000.26410.11180.0576
Percent35.47024.36514.13110.810
6.4865.8495.0005.0005.0005.0001.3210.5590.288
20 40 60 80 Cum Percent35.47059.83573.96684.77791.26297.111
102.111107.111112.111117.111118.432118.991119.279
Scree Plot
Eige
nval
ue
-1
0
1
2
3
4
5
6
7
8
0 5 10 15 20Number of Components
Figure 11: Word Cloud for the curatedcorpus colored by the binary responsevariable.
Meaning:dizzy_face::anguished::frowning::astonished::open_mouth::scream::cold_sweat::relieved::fearful::tired_face::pensive::cry::sob::rage::broken_heart::persevere::weary::flushed::joy::see_no_evil:
Emoji!"☹$%&'()*+,-./01234
100%100%94%91%85%81%
.
.
.
.
.
.
.
.
.
.
.
.
.
.
F1
.
.
.
.
.71%
100%97%95%88%
.
.66%
.
.
.
.67%
.
.
F2
.
.
.
.
.54%
.
.
.
.100%84%
.
.
.
.
.
.
.
.
F3
.
.
.
.
.
.
.
.
.
.
.
.100%82%81%
.
.
.
.
.
F4
.
.
.
.
.37%
.
.
.58%
.50%
.
.
.
.100%
.
.
.
F5
.
.
.62%68%
.
.
.
.
.
.
.
.
.
.
.
.100%
.
.
F6
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.100%
.
F7 Figure 12: Word Cloud for the curatedcorpus colored by the binary responsevariable.
Factor1234567
SentimentShockDistressSadnessHeartbreakDepressedAmazementAmusement
Emoji☹ ," ,# ,$ ,% ,&' ,( ,) ,* ,+ ,$ ,,- ,. ,$/ ,0 ,*. ,1 ,) ,$# ,% ,,2
Figure 13: Sentiments and their emoji asdetermined by factor analysis.
Using the DTM for emoji-containing tweets and createdsentiment factors, we ran ran an analysis similar to that of the firstcase study with the following exceptions. First we modeled all ofthe sentiment factors simultaneously. We also treated the sentimentfactors as continuous variables, thus enabling us to predict intensityof sentiment for each emotional state. The results showed a similarnoise level and fitting statistics as were seen in the Toronto corpus.

derived sentiment analysis using jmp pro 12
We then exported the model back to the main corpus and used itto predict sentiments for the tweets that did not contain emoji. Thescores for each sentiment factor were rescaled to between 0 and 1
for comparison purposes. The maximum score for any given tweet’ssentiment factor was interpreted as an overall intensity score.
Red Wedding Sentiment Profile
0.00
0.25
0.50
0.75
1.00
Shock Distress Sadness Heart Break Depressed Amazement AmusementGeneral Sentiments
Intensity
min (55%)-1sd (62%)
mean (66%)+1sd (70%)max (100%)
Figure 14: Profile of sentiments presentin the corpus colored by intensity ofsentiment.
Red Wedding Sentiment Profile
0.00
0.25
0.50
0.75
1.00
Shock Distress Sadness Heart Break Depressed Amazement AmusementGeneral Sentiments
Intensity
min (55%)-1sd (62%)
mean (66%)+1sd (70%)max (100%)
Figure 15: Profile of sentiments presentin the corpus focusing in on those witha high amusement score.
Figure 14 shows a parallel plot depicting how each of thetweets in the corpus scored on the different sentiment scales. Thelines are colored based on overall intensity score. Overall, the trendsappear to make sense. We see the overall sentiment, based on thedensity of lines to be elevated in Shock, Sadness and Amazement.

derived sentiment analysis using jmp pro 13
These sentiments are consistent with the intense nature of the episodeand the Red Wedding scene in particular. Shock and Distress appearto be inversely correlated. We would expect that, while they maybe shocked, viewers will generally not experience Distress in anysignificant degree from a fictional TV show.
The fact that Amusement shows up in the corpus at all
is an extremely interesting result. Because of the nature ofthe episode, "amusement" is not a sentiment that would generally beexpected to come up. This sentiment factor was built specifically onthe "Face With Tears of Joy" emoji ( ). Initially, we theorized thatthis was malapropism7. The emoji for "Face With Tears of Joy" ( ) 7 malaprop (also malapropism): the
mistaken use of a word in place of a similar-sounding one, often with unintentionallyamusing effect, as in, for example, ?dance aflamingo? (instead of flamenco).
Origin: mid 19th century: from thename of the character Mrs. Malaprop inSheridan’s play The Rivals (1775)
and "sob" ( ) or even "tired face" ( ) could appear very similar ona smart phone screen. It would not be unreasonable to expect usersto appropriate emoji to express emotions other than what they aretechnically meant to represent. If the evidence supports such misuse,it would not be unreasonable to bin the misused emoji in with theircorrect sentiment. However, looking at the tweets in the corpus moreclosely, this turned out to be an incorrect hypothesis. The documentsthat scored highly on the Amusement scale were actually retweets8 8 Reposting of a tweet by another user
to share with their followers.of a joke, "Why doesn’t George R.R. Martin use Twitter? Because he killedall 140 characters." Users would occasionally use the " " emoji aspart of the retweet, creating a separate sentiment in the corpus. Thisbrings up an interesting application of derived sentiment analysis inJMP. If someone were to have simply assumed the malapropism andrecoded the emoji, they would have introduced further noise into analready noisy analysis. By being able to find the emoji in questionand isolate the tweets containing that emoji in Text Explorer, wewere able to understand something that might have otherwise beenmissed.
Conclusions and Final Thoughts
Using Text Explorer and Generalized Regression we havedemonstrated that it is possible to do exploratory sentiment anal-ysis in JMP. We presented two case studies showing the method ofconstructing a sentiment model and how it might be applied to gainunique insights from free text data. In the first case study we showedthat a derived sentiment model could be used to extract underlyingthemes driving positive and negative feeling toward a proposal. Inthe second case study we demonstrated that emoji could be used togenerate a response for a sentiment model that could then be used togain insights from a larger corpus of documents.





























