Embed Size (px)
Citation preview

8/14/2019 Depth Limited Search
http://slidepdf.com/reader/full/depth-limited-search 1/18
The Journal of Real-Time Systems, 2, 7 -24 (1990)
9 1990 Kluwer Academic Publishers. Manufactured in The N etherlands.
Depth-Limited Search for Real-Time Problem Solving
RICHARD E. KORF*
Computer Science Department, Un iversity o f California, Los Angeles, Los Angeles, CA 90024
Ab str ac t. We propose depth-limited heuristic search as a general paradigm for real-time problem solving in a
dynamic environment. When com bined with iterative-deepening, t provides the ability to commit to an action
almost instantaneously, but allow s the quality of that decision to improve as long as time is available. Once a
deadline is reached, the best decision arrived at is executed. We illustrate the paradigm in three different settings,
corresponding to single-agent search, two-playergames, and multi-agent problem so lving. First we review two-
player minimax search with alpha-beta pruning. M inimax can be extended to the m axn algorithm for more than
two players ,which admitsa much weakerform of alpha-betapruning. Finally,we explore real-time earch algorithms
for single-agentproblems.Minimax s specialized o minimin,which allowsa very powerfulalphapruningalgorithm.
In addition,real-time-A*allows backtrackingwhile still guaranteeinga solutionand making ocallyoptimaldecisions.
1. Introduction
1.1 . Search in AI
S e a r c h h a s a l o n g a n d d i s t i n g u i s h e d h i s t o r y i n A r t i f i c i a l I n t e ll i g e n c e. T h e e a r l i e s t A I p r o -
grams, such as the Logic Th eor is t of Newel l , S imo n and Shaw (1963), and Sam uel ' s checkers
p laye r (1963) , w ere heur i s t i c s ea rch p rogram s . The r eason beh ind th i s i s t ha t h ighe r l eve l
p r o b l e m s o l v in g , s u c h a s t h e o r e m p r o v i n g a n d g a m e p l a y i n g , w a s th e f i r st a sp e c t o f i n-
t e l l i gence to r ece ive the a t t en t ion o f A I r e sea rche r s .
A c l a s s i ca l exam ple o f a p rob lem -so lv in g t a sk i s t he Trave ll i ng Sa le spe r son Prob lem (TSP).
The p rob lem i s t o p l an a t r i p am on g a se t o f c i ti e s so tha t eve ry c i ty is v i s i t ed exac tly
once , and end ing a t t he s t a r t i ng c i ty . A n op t im a l so lu t ion to t h i s p rob lem accom pl i shes
the t a sk in t he m in i m u m to ta l d i s t ance poss ib l e . A l l know n so lu t ions to t hi s p rob lem am oun t
to som e so r t o f sys t em a t i c t r i a l - a nd-e r ro r exp lo ra t ion o f d i f f e ren t c i t y sequences , s ea rch ing
f o r o n e o f m i n i m u m d i s t a n ce .
I n g e n e r a l , A I d e a l s w i t h p r o b l e m s t h a t a r e s u f f i c i e n tl y c o m p l e x t h a t t h e c o r r e c t n e x t
s t e p t o b e t a k e n i n t h e i r s o l u t i o n c a n n o t b e d e t e r m i n e d a p r i o r i . A s a r e s u l t , s o m e t y p e
o f s e a r c h a l g o r i t h m i s e m p l o y e d t o f i n d a s o l u t i o n .
W hi l e sea rch i s a ve ry ge ne ra l p rob lem -so l v in g t echn ique , i t s e f f i c i ency l im i t s it s p r ac -
t i c al a p p l i c a t i o n . F o r e x a m p l e , t h e s i m p l e s t a l g o r i t h m f o r T S P w o u l d b e t o e n u m e r a t e a l l
*This research was supported by an NSF Presidential Young Investigator Award, NSF Grant IRI-8801939, and
an equipment grant from Hewlett-Packard. Thanks to V alerie Aylett for drawing the figures.

8/14/2019 Depth Limited Search
http://slidepdf.com/reader/full/depth-limited-search 2/18
8 R.E. KORF
possible tours, calculate their distances, and return a shortest one. Unfortunately, the run-
ning time o f this algorithm is proportional to the factorial of the n umbe r o f cit ies. Even
with the most efficient algorithms known for this problem , the largest supercomputers areincapable of finding optimal solutions to problems with as few as a hundre d cit ies, w ithin
practical time limits.
If an optimal solution is not strictly required, however, there are algorithms that can
find very good tours very quickly. In general, there is a trade off between the quality of
solution found, measured in miles, versus the amount of computation necessary to find
it , measure d in t ime. Th e nature of this tradeof f is such that small sacrifices in solution
quality often yield huge savings in comp utation time. Real-time problem solving often places
severe constraints on the com putation available for each decision. Th e challenge is to make
the best decisions possible within those constraints.
1.2. Real-time search
The most successful artificial intell igence systems, m easured by perform ance relative to
humans in a complex domain, are state-of-the-art, two-player game programs. For exam-
ple, the chess machine Deep Thought was recently rated at 2551, placing it among the
top 30 players in the United States (Berliner 1989).
Gam e programs mee t most of the usual criteria for real-time systems. Actions (moves)
must be irrevocably comm itted to in constant t ime. Games are dyna mic in that the strategic
and tactical situation changes over time. Finally, there are at least two different sources
of uncertainty in such games. O ne is uncertainty in predicting the opponent 's moves, and
the other is uncertainty in the value of a position due to the size of the search space.
The basic algorithm employed by these program s is fixed-depth lookahead search. Fro m
the current gam e situation, a tree o f possible moves and possible responses is generated.
The tree is generated only to a fixed depth, depending on the computational resources and
time available pe r move. Th en, based o n a heuristic evaluation f unctio n applied to the frontier
nodes of the tree, the best move from the current situation is decided upon and executed.
The key property o f fixed-depth search that makes it amenab le to real-time problem solving
is that both computational com plexity and decision quality is a function of search depth.
With a very shallow depth, a decision can be made very quickly. As the search depth in-creases, decision quality improves, but at the cost of increased time. Thus, given a t ime
deadline for a move, a search h orizon is chosen so that the best possible mo ve can be mad e
before the deadline.
Since it is generally difficult to predict exactly how long a search to a given depth will
take, i terative deepening is used to set the search horizon. Th e idea o f i terative deepening
is that a series of searches is perfo rme d, each to a greater depth than the previous. Then ,
when the deadline is reached, typically in the middle of a search, the move reco mm ende d
by the last completed iteration is made. Thus, even with com pletely unpredictable deadlines,
a plausible mo ve is always available an d ca n be exec uted. Fo r a de tailed discussion of iterative
deepening, see (Korf 1985).
Fixed-depth search com bined with i terative deepening forms the basic structure of real-
t ime search programs. Th e rem ainder of this paper w ill describe the application of these
ideas in three different settings: two-player games, multi-player games, and single-agent

8/14/2019 Depth Limited Search
http://slidepdf.com/reader/full/depth-limited-search 3/18
DEPTH-LIMITED SEARCH FOR REAL-TIMEPROBLEM SOLVING 9
problem solving. While the material on two-player games will be familiar to many, the
latter two areas constitute recent results. S ince they have been repor ted on in detail elsewhere
(Korf 1988; Korf 1990; Korf 1990), we will only briefly survey their highlights.
2. Two-player games
One of the original challenges of AI, which in fact predates A I by a few years, was to
build a progr am that could play chess at the level of the best human players. As such, chess
is the canonical two-player game in AI.
2.1. Minimax Search
The standard algorithm for two-player games is called m inimax search with static evalua-
tion (Shannon 1950). The algorithm searches forward to some fixed depth in the game
tree, l imited by the amount of computation available per m ove. Figure 1 shows a two-level
game tree for t ic-tac-toe, starting fr om the initial state of the gam e and taking advantage
of board symmetries. At this search horizon, a heuristic static evaluation function is ap-
plied to the frontier nodes. In the case of a two-player game, a heuristic evaluator is a
function that takes a boa rd position and returns a num ber that indicates how favorable that
position is to one player or the other. Fo r example, a very simple heu ristic evaluator for
chess would count the total number of pieces on the board for one player, appropriately
weighted by their relative strength, and subtract the w eighted sum of the opponent 's pieces.
Thus, large positive values would corre spond to strong positions for one player whereas
large negative values would represent advantageous situations for the opponent.
Figure I. Two-LevelTic-Ihc-ToeGame Tree.

8/14/2019 Depth Limited Search
http://slidepdf.com/reader/full/depth-limited-search 4/18
]0 R.E. KORF
Give n the static evaluations of the frontier nodes, values for the interior nodes in the
tree are compu ted according to the minim ax rule. The player for whom large positive values
are advantageous is cal led MA X, and conversely the opponent is refer red to as MIN. Thevalue of a node where it is MA X's turn to move is the m axi mu m of the values of its children,
while the value of a node where M IN is to move is the min im um of the values of its children.
Thus, a t a l ternate levels of the t ree , the minim um and the m axi mu m values of the ch i ldren
are backed up. Th is continues until the values of the imm ediate children of the current
position are computed, at which point one move to the child with the ma xim um or minim um
value is made, depending on the p layer to move. Figure 2 shows a minimax tree where
square nodes represent posi t ions where M AX is to move and circu lar nodes correspond
to MIN 's moves . Th e values above the bot tom row are compute d f rom the f ront ier values
using the minimax ru le .
2.2. Alpha-beta pruning
One of the mo st e legant ideas in a l l o f heur is tic search is the alpha-beta pruning algor ithm.
John M cC arthy cam e up with the original idea (Pearl 1984), an d it f irst appeare d in print
in a m em o by Hart and Edw ards (1963). The n otion is that an exact mi nim ax search ca n
be performed without examining all the nodes at the search frontier .
Figure 3 shows an example of a lpha-beta pruning applied to the t ree o f Figure 2 . The
search proceeds depth-f ir s t to minimize the memory requirement , and only evaluates anode when necessary. After statically evaluating nodes d and e to 6 and 5, respectively,
we back up their m ax im um value, 6, as the value of node c. After statically evaluating
node g as 8, we know that the backe d up value of node f must be greater than or equal
to 8, since it is the maximum of 8 and the unknown value of node w. The value of node
b must be 6 then , bec ause i t is the mi nimu m of 6 and a value which m ust be greater than
or equal to 8. Since we have exactly determined the value of node b, we do not need to
evaluate or even generate node w. This is called an a lpha cutoff . Similarly, af ter statically
evaluating nodes j and k to 2 and 1, the backe d up value of node i is their m axi mu m or
2. T his tells us that the backed up value of node h m ust be less than or eq ual to 2, since
Figure 2. Minimax game tree.

8/14/2019 Depth Limited Search
http://slidepdf.com/reader/full/depth-limited-search 5/18
DEPTH-LIMITED SEARCH FOR REAL-TIME PROBLEM SOLVING 11
b (6~ I'~
c l 6 1 f Z l 8 1 i
g (8 ) w ( ) j (2 ) k (1 ) y
Figure 3. Alpha-beta pruning.
it is the minimum of 2 and the unknown value of node x. Since the value of node a is
the max imum of 6 and a value that must be less than or equal to 2, i t must be 6, and henc e
we have evaluated the roo t of the tree w ithout generating or evaluating nodes x, y, o r z.
This is called a beta cutoff.
Since alpha-beta pruning allows us to per form a m inimax s earch while evaluating fewer
nodes, i ts effect is to allow us to search deep er with the sam e am ount of computation.
This raises the question of how mu ch deeper, or how mu ch does alpha-beta improve per-
formance? This proble m has bee n carefully studied by a num ber of researchers and finally
solved by Pearl (Knath an d M oor e 1975; Pearl 1982). T he best way to characterize theefficiency of a pruning algorithm is in terms of i ts effective branching factor. Th e effective
branching factor is the d th root of the numb er of fro ntier nodes that must b e evaluated in
a search to depth d.
Th e efficiency of alpha-beta pruning depends upon the orde r of the nod e values at the
search frontier. For any set of frontier node values, there exists some ordering of the values
such that alpha-beta will not perform any cutoffs at all . In that case, all frontier nodes
must be evaluated and the effective branching factor is b, the b rute-force branching factor.
On the other hand, there is an optimal or perfect ordering in which every possible cutoff
is realized. In that case, the eff ective branc hing factor is red uce d fr om b to b '/~, whi ch
is the square r oot of the brute-force branching factor. Another way of reviewing the perfectordering ca se is that for the same amo unt of computation, on e can search tw ice as deeply
with alpha-beta pruning as without. Since the searc h tree grows exponentially with depth,
doubling the search horizon is quite a dramatic improvement.
In between worst-possible ordering and perfect ordering is random ordering, which is
the average case. Unde r rand om ord ering of the frontier nodes, alpha-beta pruning reduces
the effective branching factor to approximately b ~. This m eans that one ca n search 4 /3
as deep with alpha-beta, yielding a 33 % im provem ent in search depth.
2.3. Node ordering, quiescence, and iterative-deepening
In practice, however, the effective branching factor of alpha-beta is close r to b ~ du e to
node ordering. The idea of node ordering is that instead of generating the nodes of the

8/14/2019 Depth Limited Search
http://slidepdf.com/reader/full/depth-limited-search 6/18
12 R.E. KORF
tree strictly left-to-right, the or der in w hich paths are ex plored can b e based on static evalua-
t ions of the inter ior nodes in the tree . In other w ords , the chi ldren o f M AX nodes can
be expanded in decreas ing order of their s ta t ic values while the chi ldren of MIN nodeswould be ex panded in increas ing o rder of their s tat ic values.
Ano ther im portan t notion is quiescence. The idea of quiescence is that the static evaluator
should not be appl ied to pos i t ions wh ose values are uns table , such as those occu rr ing in
the middle o f a piece t rade . In those pos i tions , a sm al l secondary search is conducted unt i l
the static evaluation becomes more stable.
I tera t ive-deepening is used to solve the pro blem of how to se t the search horizon, as
previous ly ment ioned. In a tournam ent gam e, there is a l imit on the amoun t of time a l lowed
for moves. Unfortunately, i t is very difficult to accurately predict how long it will take
to perf orm a com plete search to a given depth. I f one picks too shal low a depth, then t ime
which could be used to improve the move choice is was ted. A lternat ively, i f the search
depth is too deep, t ime wil l run out in the middle o f a search, and a mo ve based on an
incomplete search is l ikely to be very unrel iable . The solut ion is to perform a ser ies of
complete searches to success ively increas ing depths . W hen t ime runs out , the move recom-
mended by the las t completed search is made.
I tera t ive-deepening and node ordering can be co mbin ed as fol lows. Ins tead of ordering
inter ior nodes base d on their s ta tic values, the front ier values fro m the previous i tera t ion
.of the search can be used to order the nodes in the next i tera t ion. This produ ces m uch
better ordering than the static values alone.
Vir tual ly a l l perfor man ce chess progra ms in exis tence today use ful l -width, f ixed-depth,
a lpha-beta min imax search with node ordering, quiescence, and i terat ive-deepening. They
make very high qual i ty move decis ions under rea l- t ime cons tra ints .
3. Multi-player game trees
We now cons ider games with mult iple players . For example , Chinese Checkers can in-
volve up to six different players mov ing alternately. As anoth er exam ple, Othello can easily
be extended to an arbi t rary num ber of players by having different colored p ieces for each
player, and modifyin g the rules such that whenever a mixed row of opposing pieces is flanked
on both s ides by two pieces of the same player , then a l l the pieces are captured by the
flanking player.
3 . 1 . M a x n A l g o r i t h m
Luckh ardt and Irani (1986) extended m inima x to mult i -player games , ca l l ing the resul t ing
algori thm m a x n . We assum e that the players a l ternate moves , that each player t r ies to max-
imize his return, and is indifferent to the returns o f the rema ining players. At the leaf nodes,
an evaluat ion funct ion is appl ied that re turns an N-tuple of values , wi th each component
correspond ing to the es t imated meri t of the pos i t ion with respec t to one of the players.
Then, the value of each inter ior node where player i i s to move is the ent i re N -tuple of
the child for which the i h comp onent is a maxim um . F igure 4 shows a max n t ree for three
players , wi th the corresponding maxn values .

8/14/2019 Depth Limited Search
http://slidepdf.com/reader/full/depth-limited-search 7/18
DEPTH-LIMITEDEARCH ORREAL-TIMEROBLEM OLVING 13
~ ( 1 , 7, 2) ~ , 5, 4) ~ , 3, 6) ~ , 1, 8)
(2, 8, 1) (1, 7, 2) (5, 6, 3) (6, 5, 4) (a, 4, 5) (7, 3, 6) (4, 2, 7) (3, 1, 8)
Figure 4. Example f maxn or three-player ame.
For example , in Chinese Checkers , the value of each comp onen t of the evaluat ion func-
t ion might be the negat ive of the minimum number of individual moves required to move
all of the corres pon ding player 's piece s to their go al positions. Similarly, an evaluation
funct ion for mult i -player Othel lo m ight re turn the n um ber o f pieces for each player on
the board a t any given point .
Two-player minima x can be viewed as a specia l case of ma xn in which the evaluat ion
func tion re tu rns an o rde red pa i r o f x and -x , and each p laye r maximizes h i s componentat his moves.
3. 2. Alpha -beta p runin g in mult i -pla yer g am e trees
Luckh ardt and Irani (1986) observ ed that a t nodes w here player i i s to move, only the i th
com pone nt of the chi ldren need be evaluated. At bes t , th is can produce a cons tant fac tor
improv ement , but i t may be no less expens ive to compute a l l compon ents than to compute
only one. Th ey correct ly concluded that without fur ther assum ptions on the values of thecomponents , pruning of ent i re branches is not poss ible with more than two players .
If , however , there is an upp er bound on the sum of a ll compon ents of a tuple , and there
is a lower bound on the values of each co mpo nent , then a form o f a lpha-beta pruning is
poss ible. Th e f i rs t condi tion is a weaker f orm of the s tandard cons tant-sum assumption,
which is in fac t , required for two-player a lpha-beta pruning. The second is equivalent to
assuming a lower bound o f zero on each com ponen t , s ince any other lower bound ca n be
shif ted to zero by subtract ing i t f rom every component . Most pract ica l evaluat ion func-
tions will satisfy both these conditions, s ince violating either one implies that the value
of an individual com pon ent can be unbounde d in at leas t one direct ion. F or example , in
the piece-count evaluat ion funct ion describ ed above for mult i -player Othello , no player can
have less than zero pieces on the board, and the tota l number of pieces on the board is
the sam e for a l l nodes a t the sam e level in the ga me t ree , s ince exact ly one piece is added
at each move.

8/14/2019 Depth Limited Search
http://slidepdf.com/reader/full/depth-limited-search 8/18
14 R.E. KORF
3.2.1. Imm ediate pruning . The s i mples t k i nd o f p run i ng pos s i b le u nde r t hese a s sumpt i ons
occurs when player i i s to move, and the i h comp onen t o f one o f h is ch i l d r en equa l s t he
upp er bou nd o n the sum of a l l comp onents . In tha t case , a ll remaining chi ldren can be
pruned, s ince no chi ld ' s i h componen t can exceed t he uppe r bound on t he sum. We w i l l
refer to this as immediate pruning.
3.2.2. Shallow pruning. A mo re com plex s i tua tion i s ca l led shallow pruning in the a lpha-
beta l iterature. Figu re 5 shows an examp le of shal low prunin g in a three-player game , w here
the sum o f each c om pon ent i s 9 . Evaluat ing node a result s in a lower bou nd of 3 on the
f i rs t com pon ent of the root , s ince p layer one is to move. This impl ies an upp er bo und on
each o f t he r ema i n ing componen t s o f 9 - 3 = 6 . Eva l ua t ing nod e fp rod uc es a l ow er bound
of 7 on the seco nd co mp one nt of node e , s ince p layer two is to move. Simi lar ly , th i s im-
pl ies an upp er bound on the remaining co mpo nents of 9 - 7 = 2 . Since the uppe r bou nd
(2) on the f i rs t com pon ent o f node e i s l ess than or equal to the lower bou nd on the f i r st
comp onen t o f t he roo t (3 ) , p l aye r one w on ' t choose no de e and i ts r ema i n i ng ch i l d r en can
be pruned. Simi lar ly , evalua t ing node h causes i t s remaining brothers to be pruned. This
i s s imi lar to the pruning in Figure 3 .
3.2.3. Failure o f deep pruning. In a two-player game, a lpha-beta pruning a l lows an addi -
t iona l t ype o f p run i ng know n as deep pruning. In deep p run i ng , nodes a r e p runed based
on bounds inher i ted f rom the i r grea t -grea t -grandparents . Surpr i s ingly , deep pruning does
not genera l ize to more than two players .Figure 6 i l lus t ra tes the problem. Again , the sum o f each com pon ent i s 9. Evaluat ing
node b p roduces a l ow er bound o f 5 on t he f i rs t compon en t o f node a and hence an upp e r
bou nd of 9 - 5 = 4 on the remaining com ponen ts . Evaluat ing node e result s in a lower
bound o f 5 on the t h ird compon en t o f node d and hence an uppe r bound o f 9 - 5 = 4
on t he r ema i n ing com ponen t s . S i nce t he uppe r bound o f 4 on t he f ir st compo nen t o f node
d i s l ess than the lower bou nd o f 5 on the f i r s t compo nen t of node a , the va lue of node
fc an no t bec om e t he va lue o f node a . I n a tw o-p l aye r game , t h i s w ou l d a ll ow us to p rune
node f .
(3
, , (~
d E(3,3,3) (4,2,3) (3,1,5) (1,7,1)
( < 3 , ~
(1,6,2)
Figure 5. Shallow pruning in three-player game tree.

8/14/2019 Depth Limited Search
http://slidepdf.com/reader/full/depth-limited-search 9/18
DEP TH-L IMITE D SEARC H FOR REAL-TIME PROBLEM SOLVING 15
(2, 2, 5) (2, 3, 4) or (3, O, 6)
Figure 6 Failure of deep pruning for three players.
With three players, however, the value of nod ef co ul d effect the value of the root, depend-
ing on the value of node g . If the value of node f w e r e (2 ,3 ,4) for example, the value of
e would be propagated to d, the value of d w ould be propagated to c, and the value of
b would be propagated to a, giving a value of (5,2,2). O n the other hand , if the value of
node f were (3,0,6) for example, then the value of f would be propagated to d, the value
of g would be propagated to c, and the value of c would be propagated to a, producing
a value of (6,1,2). Even thoug h the value o f node f cannot be the maxn value of the root ,
it can effect i t . Hence, i t cannot be pruned.In general, shallow pruning, which is understood to include immediate pruning as a special
case, is the best we can do, as expressed by the following theorem:
THEOREM 1. Eve ry directional algorithm that compu tes the max n value of a ga me tree with
more than two players must evaluate every terminal node evaluated by shallow pruning.
By a directional algorithm we mean one in which the order of node evaluation is in-
depend ent of the value of the nodes, and on ce a nod e is prun ed it can never be revisited.
For example, a strictly left-to-right order would be directional. Th e main idea of the proof
amounts to a generalization of the above example to variable values, arbitrary depths, and
any number of players greater than two.
3.2.4. Performance of shallow pruning. How effective is shallow pruning? The best-
case analysis of shallow pruning is independent of the num ber o f players and was done by
Knuth and M oore (1975) for two players. The best-case effective branching factor is
(1 + ~ - 3)/2. For large values of b, this approache s , ~ w hich is the best-case perfor-
mance of full two-player alpha-beta pruning.
Knuth and M oore (1975) also determine d that in the average case, the asymptotic branch-
ing factor of two-player shallow pruning is approxima tely b/log b. In the case of multiple-
players, however, the average-case asymptotic branching factor of shallow pruning is simply
b, the brute-force branching factor. Thus, pruning does not produce an asymptotic improve-
ment in the average case with mor e than two players. Similarly, in the worst case, ever y
terminal node would have to be evaluated and no pruning would take place.

8/14/2019 Depth Limited Search
http://slidepdf.com/reader/full/depth-limited-search 10/18
16 R.E. KORF
As in the case of two-player minimax , i terative deepening can b e applied to multi-player
gam e trees as well . Mu ltiple i terations to successively deep er search depths are per form ed
and the move recommended by the last completed i teration at the deadline is made.
4. Single-agent problem solving
We now turn our attention to real-t ime problem solving by a single agent. Common ex-
amples of s ingle-agent search problems are the Eight Puzzle and i ts larger relatives, the
Fifteen and Twenty-four Puzzles (see Figure 7). The Eight Puzzle consists of a 3 x 3 square
fram e containing eight num bered square t i les and an em pty posit ion called the blank. T he
legal operators s l ide any t ile horizontally or vert ically adjacent to the blank into the blank
posit ion. The task is to rearrange the t i les from some random init ial configuration intoa part icular desired goal configuration.
In a s ingle-agent prob lem , a he urist ic function estimates the cost of a path from a given
node to a go al node. A com mo n heuristic function for sliding tile puzzles is called Manhattan
Distance. It is computed by counting, for each t i le not in i ts goal posit ion, the number
of moves along the grid i t is away from its goal posit ion, and summing these values over
all tiles, excluding the blank.
A real-world example is the task of autonom ous vehicle navigation in a netw ork of roads,
or arbitrary terrain, from an init ial location to a desired goal location. The problem is
typically to find a shortest path betw een the initial and g oal states. A typical heuristic evalua-
tion function for this problem is the Euclidean or airl ine distance from a given location
to the goal location.
Mo st of the wo rk in single-agent search has not addressed real-t ime constraints. For ex-
ample, the best known a lgorithm is A* (Hart , N ilsson and R aphael 1968). A* is a best-firs t
search a lgori thm where the meri t of a node, f (n), is the sum of the actual cost in reaching
that no de fr om the initial state, g(n), and the estimated co st of reaching the g oal s tate from
that node, h(n). A* has the pr oper ty that i t will always find an optimal solution to a prob -
lem if the heurist ic function never overestimates the actual solution cost .
1 2 1 2 3 1 2 3 4
3 4 5 4 5 6 7 5 6 7 8 9
6 7 8 8 9 10 11 10 11 12 13 14
1 2 1 3 1 4 1 5 1 5 1 6 1 7 1 8 1 9
2 0 2 1 2 2 2 3 2 4
Figure 7. Eight, fifteen, and twenty-four puzzles.

8/14/2019 Depth Limited Search
http://slidepdf.com/reader/full/depth-limited-search 11/18
DEPTH-LIMITED SEARCH FOR REAL-TIME PROBLEM SOLVING 17
A serious drawback of A* however, is that it takes exponential time to run in practice.
This is an unavoidable cost of obtaining optima l solutions, and restr icts the applicability
of the algorithm to relatively small proble ms in practice. F or exam ple, while A* with theManha ttan Distanc e heuristic function can solve the Eight Puzzle, and a linear-spac e varia-
tion called IDA* (Korf 1985) can solve the Fif teen Puzzle, any larger puzzl e is intractable
on curren t ma chines. A related draw back o f A* and IDA* is that they must search all the
way to a solution in a planning or simulation phase before executing even the f irst move
in the solution.
In th is sect ion we apply the real- t ime assum ptions of l imited search hor izon , and co m-
mitment to moves in constant time, to single-agent heuristic searches. A limited search
horizon ma y be the result of computational or informational limitations. For example, larger
vers ions of the Fif teen Puzzle impose a computat ional l imit on the prob lem solver. Alter -
natively, in the case of autonomous vehicle navigation without the benefit of completely
detailed map s, the sea rch horizon is due to the inform ation limit of how far the vehicle
sensors can see ahead . The com mitm ent to moves in constant t ime is a fur ther constraint .
This means that af ter a constant amount o f t ime w e com mit to a physical act ion , such as
sliding a tile or moving the vehicle. If we later decide to slide the sa me tile bac k to where
it was, or drive the vehicle back, both moves are counted in the solution cost.
4.1. Minimin lookahead search
The f irs t s tep is to special ize the mini max algor i thm for two-player gam es to the case o f
a single problem-solving agent. The resulting algorithm, which we call minimin search,
was originally developed by Rosenberg and Kestner (1972) in the context of A* At f irst
we will assume that all edges have the same cost.
The algor i thm searches forward f rom the current s ta te to a f ixed-depth determined by
the computational or information resources available for a single move, and applies the
heuristic evaluation function to the nodes at the search frontier . Whereas in a two-player
game, these values are minimaxed up the t ree to account for a l ternate moves among the
players, in the single-agent setting, the backed-up value of each node is the minimum ofthe values of its children, since the single agent has control over all moves. Once the backed-
up values of the children of the current state are determ ined, a single move is actually ex-
ecuted in the d irect ion of the bes t ch i ld , and the en t ire process is repeated . The reason
for not moving directly to the frontier node with the m inim um value is to emp loy a strategy
of leas t commitme nt , under the assumption that af ter committ ing the f i rs t move, addit ional
information f rom an expanded search f ront ier may resu l t in a d if ferent choice for the sec-
ond move than was anticipated by the f irst search.
In the more general case where the operators have non-uniform cost , w e mu st take into
account the cost of the path from the current state to the frontier, in addition to the heuristic
es t imate of the remaining cost . To do this we adopt the A* cost function of f ( n) = g(n)+ h(n). The algor i thm looks forward a f ixed numbe r of moves , and backs up the minim um
f ( n ) value of each f ront ier node.

8/14/2019 Depth Limited Search
http://slidepdf.com/reader/full/depth-limited-search 12/18
18 R.E. KORF
4.2. Alph a pruning
Does there exist an analog of alpha-beta pruning that would allow the sa me decisions tobe m ade while explor ing substant ial ly fewer nodes? I f our a lgor i thm uses only f rontier
node evaluations, then a simple adversary argument establishes that no such pruning
algor i thm can exist , s ince to determine the m inim um cost f ront ier node requires examin-
ing every one.
However, if we allow heuristic evaluations of interior nodes, then substantial pruning
is possible if the cost function is monotonic. A co st function f is monotonic if i t never
decreases a long a path away f rom the root . S ince m onotonici ty o f f is equivalent to h obey-
ing the tr iangle inequality cha racteristic of all metrics, i t is satisf ied by all naturally occur-
r ing heuristic functions including Manhattan Distance and Euclidean Distance. Thus,
monotonici ty of f is not a res tr ic t ion in pract ice .A mon otonic f function allows us to apply branc h-and- bound to signif icantly decreas e
the numbe r of nodes examined without effecting the decisions made. The a lgorithm, which
we call alpha pruning by analogy to alpha-beta pruning, is as follows: In the course of
generating the tree, mainta in in a va riable c~ the lowest f value of any node encounte red
on the search hor izon so far . As each in ter ior node is generated , c ompute i ts fv al ue and
terminate search o f the correspond ing branc h w hen its f va lue equals or exceeds ~. The
reason is that s in ce f i s monotonic , th ef va lu es of the f ront ier nodes below that node can
only be greater than or equal to the cost of that node, and hence cannot be lower than
the value of the frontier node resp onsible for the current value of a. As each frontier node
is generated , compute i ts fv al ue as well and if i t is less than a , rep lace et with th is lower
value and continue the search.
4.2.1. Efficiency o f Alpha pruning. Figure 8 shows a compar ison of the to tal number of
nodes examined as a function of search horizon for several different sliding tile puzzles,
including the Eight, Fif teen, T wenty-F our and 10 • 10 Ninety -Nine Puzzle. T he straight
lines on the left represent brute-force search with no pruning and indicate branching fac-
tors of 1.732, 2.130, 2.368, and 2.790 respectively. The curved lines to the right represent
the numbe r of nodes generated with alpha pruning us ing the M anhattan D is tance heur ist ic
function. In each case, the values are the averages of 1000 rand om solvable initial states.One remarka ble aspect o f th is data is the ef fect iveness of a lpha pruning. For example,
if we f ix the available compu tation at one m illion nodes per move, requiring about a minute
of CPU t ime on a one m il l ion ins truct ion per second m achine, then alpha pruning extends
the reachable Eight Puzzle search hor izon a lmost 50 percent f~om 24 to 35 m oves , more
than doubles the Fif teen Puzzle horizon from 18 to 40 moves, and tr iples the Twenty-four
Puzzle horizon from 15 to 45 moves. Fixing the am ount of compu tation at 100,000 nodes
per move, the reachable Ninety-Nine Puzzle search hor izon is mult ip l ied by a factor of
f ive from 10 to 50 moves. By com paris on, even under p erfect ordering, a lpha-beta pruning
only doubles the effective search horizon.
Even m ore surprising, however, is the fact that given a sufficiently large amoun t of com-putation, the search horizon achievable with alpha pruning actually increaseswith increasing
branching factor! In other words, we can search signif icantly deeper in the Fif teen Puzzle
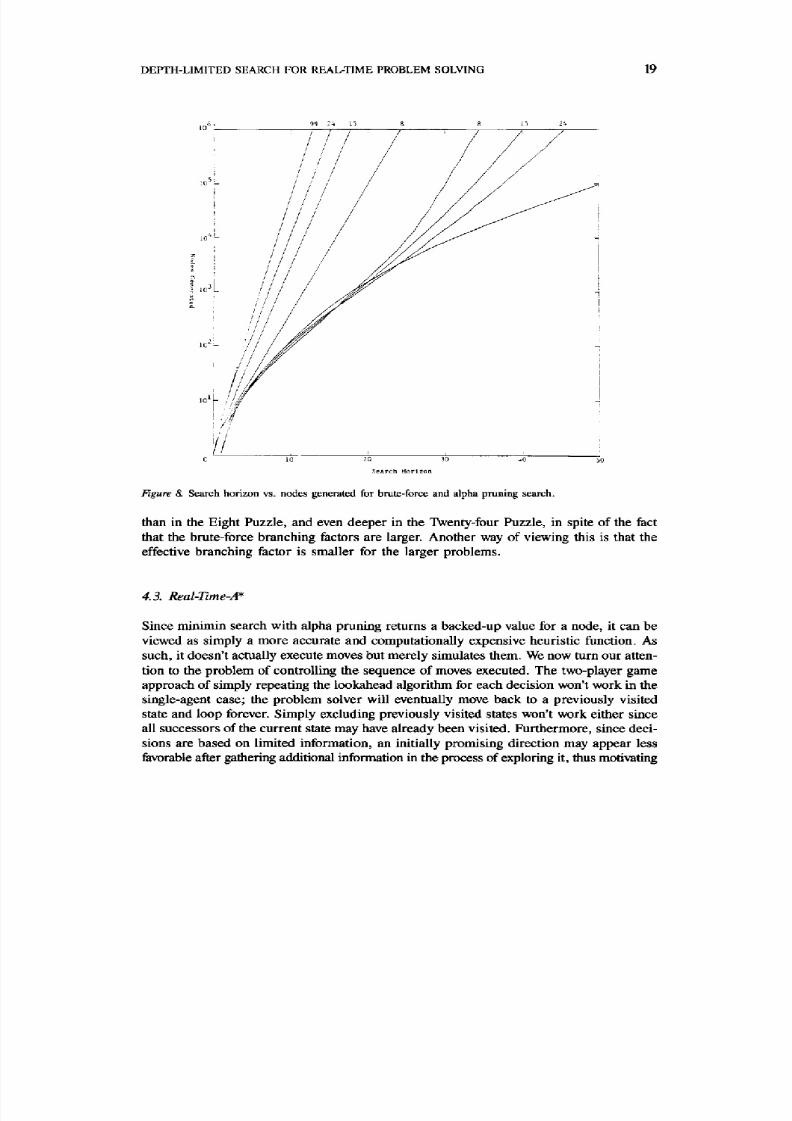
8/14/2019 Depth Limited Search
http://slidepdf.com/reader/full/depth-limited-search 13/18
DEPTH-LIMITED SEARCH FOR REAL-TIME PROBLEM SOLVING 19
106. ~ 9 9& t5 8 8 L5 24
tO
i0 L
o3i
to L1
14 ///
i /
//0
Search Horizon
Figure & Search horizon vs. nodes generated for brute-force and alpha pruning search.
than in the Eight Pu zzle, and even dee per in the T wenty-four Puzzle, in spite of the fact
that the brute-force branching factors are larger. Another way of viewing this is that the
effective branchin g fac tor is smaller for the larger problem s.
4.3. Real-Time-A*
Since minimin search wi th a lpha pruning re turns a backed-up value for a node, i t can be
viewed as s imply a m ore accurate and computat ional ly expens ive heuris tic funct ion. As
such, i t doesn 't actually execute move s but mere ly simulates them. W e now turn o ur atten-
t ion to the problem of controll ing the sequence of moves executed. T he two-player game
approach o f s imply repeat ing the lookahead a lgori thm for each decis ion won' t work in the
single-agent case; the problem solver will eventually move back to a previously visi ted
state and loop forever. Simp ly excluding previously visi ted states won't wo rk either s inceall successors of the curre nt s tate ma y have already bee n visi ted. Fur therm ore, s ince deci-
sions are based on l imited information, an init ial ly promising direction may appear less
favorable a fter gathering additional informa tion in the pro cess of exploring it, thus motivating

8/14/2019 Depth Limited Search
http://slidepdf.com/reader/full/depth-limited-search 14/18
20 R.E. KORF
a return to a previous choice point. T he challenge is to prevent infinite loops while perm it-
ting backtracking when it appears favorable, resulting in a form of single-tr ial learning
through explorat ion of the problem space.The basic principle of rationality is quite simple. One should backtrack to a previously
visited state when the estima te of solving the proble m fr om that state plus the c ost of return-
ing to that state is less than the estimated cost of going forward from the current state.
Real-Time-A* (RTA*) is an efficient algorithm for implementing this basic strategy. While
the minimin lookahead algor i thm is an algor i thm for contro l l ing the p lanning phase o f the
search, RTA* is an algorithm for controlling the execution phase. As such, it is indepen-
dent of the planning algorithm chosen.
In RTA* the merit of a node n is f ( n ) = g ( n ) + h ( n ) , as in A* However, unlike A*
the interpretation of g ( n ) in RTA* is the actual distance o f node n from the current state
of the probl em solver, rather than f rom the original initial state. The key difference between
RTA* and A* is that in RTA* the merit of every node is measured relative to the current
position of the prob lem solver, and the initial state is irrelevant. RTA* is a best-f irst search
given this different cost function.
The algorithm maintains in a hash table a list of those nodes that have been visited by
an actual move of the problem solver, together with an h value for those nodes. At each
cycle of the algorithm, the current state is expande d, generating its neighbors, and the
heuristic function, possibl y augment ed by lookahe ad search, is applied to each state which
is not in the hash table. For those states in the table, the stored value of h is used instead.
In addition, the cost of the edge to each neighboring state is added to this value, resulting
in an f value for each ne ighbor of the current state. T he node with the m inim um f value
is chosen for the new current state and a move to that state is executed. At the sam e time,
the previous current state is stored in the hash table, and associated with it is the second
best f value. T he second bes t f value is the best o f the alternatives that w ere not cho sen,
and represents the estim ated h cost of solving the probl em by returning to this state, fr om
the perspective of the new cu rrent state. I f there is a tie amon g the best values, then the
second best will equal the best. The algorithm continues until a goal state is reached.
RTA* only requires a single list of previously visited nodes. The size of this list is linear
in the num ber of move s actually mad e, since the lookahea d search saves only the value
of its root node. Furtherm ore, the running time is also linear in the num ber o f moves made.The reason for this is that even though the lookahead requires time that is exponential in
the search depth, the search depth is bounded by a constant.
For example, consider the graph in Figure 9, where the initial state is node a, all the
edges have unit cost, and the values at each node represe nt the original heuristic estim ates
of those nodes. Since lookahead only mak es the example more com plicated, we will assume
that no lookahea d is done to comp ute the h values. Starting at node a, nodes b, c, and d are
generated and evaluated at f ( b ) = g (b ) + h (b ) = 1 + 1 = 2 , f ( c ) = g (c ) + h (c ) =
1 + 2 = 3, an df (d ) = g ( d ) + h ( d ) = 1 + 3 = 4. The refore, the pro ble m solver move s
to node b, and stores node a in the hash table with the inform ation that h(a ) = 3, the second
bes tfva lue . Next , nodes e and i are generated and evaluated at f ( e) = g(e) + h(e) = 1 +
4 = 5 , f ( i ) = g( i ) + h( i ) = 1 + 5 = 6, and using the stored h value of node a , f ( a )
= g(a) + h(a) = 1 + 3 = 4. Thus, the prob lem solver mov es bac k to node a, and stores
h(b ) = 5 with node b. At this point, f ( b ) = g (b ) + h (b ) = 1 + 5 = 6 , f ( c ) = g (c ) +

8/14/2019 Depth Limited Search
http://slidepdf.com/reader/full/depth-limited-search 15/18
DEPTH-LIMITED SEARCH FOR REAL-TIMEPROBLEM SOLVING 21
b 1
9 a
3 2
8 7
Figure 9. Real-timeA* example.
h(c) = 1 + 2 = 3, an d f ( d) = g(d) + h(d) = 1 + 3 = 4, caus ing the prob lem solver
to move to node c , s tor ing h(a) = 4 with node a . The reader is urged to cont inue the exam-
ple to see that the problem solver cont inues to backtrack over the same ter ra in, unt i l a
goal node is reached. The reason it is not in an inf inite loop is that each time it changes
direct ion, i t goes one s tep fur ther than the previous t ime, and gathers more information
about the space . This seemingly i r ra t ional behavior is produced by a ra t ional pol icy in
the presence of a l imited search horizon, and a some what pathological set of heuristic values.
4.3.L Completeness an d Correctness of RTA* Note that whi le mono tonic i ty of the cos t
funct ion is required for a lpha pruning in minimin loo kahead search, RTA* places no such
constra int on the values re turned by the heur is t ic funct ion. O f course , the mo re accurate
the heur is tic funct ion, the bet ter the per fo rman ce of RTA* but even with no heur is t ic in-
form ation at all , RTA* will ev entually f ind a solution , as indicated b y the following result:
THEOREM 2. In a f inite pro ble m spac e with f inite positive edg e costs and f inite heuristic
values, in w hich a goal s tate is reach able f rom every state, RTA* will f ind a solution.
S ince RTA* is mak ing d ecis ions based on l imited information, the bes t we can say about
the qual i ty of decis ions m ade by the a lgo r i thm is that RTA* mak es local ly op t imal moves
relative to the part of the search spa ce that i t has seen so far .
THEOREM 3. Each mo ve m ade by RTA* on a tree is along a path wh ose estim ated c ost of
reaching a goal is a minimum, based on the cumulat ive search f ront ier a t the t ime.
4.3.2. Solution quality. In addi t ion to ef fic iency and co mpleten ess of the a lgor i thm, the
qual i ty of solut ions generated by RTA* is of centra l concern. The most impor tant fac tor
affecting solution quality is the accuracy o f the heu ristic function itself. In addition, for
a given heur is t ic funct ion, solut ion qual i ty increases with increas ing search hor izon.
One thousand solvable ini t ia l s ta tes were random ly g enerated for each of the Eight, F if-
teen, and Twenty-Fou r Puzzles . For e ach ini tia l s ta te , RTA* with minim in search and a lpha
8/14/2019 Depth Limited Search
http://slidepdf.com/reader/full/depth-limited-search 16/18
22 R.E. KORF
pruning was run for various search depths using the Manhattan Distance heuristic func-
tion. Th e search depths ranged from one to twenty-five moves. Ties were broken randomly,
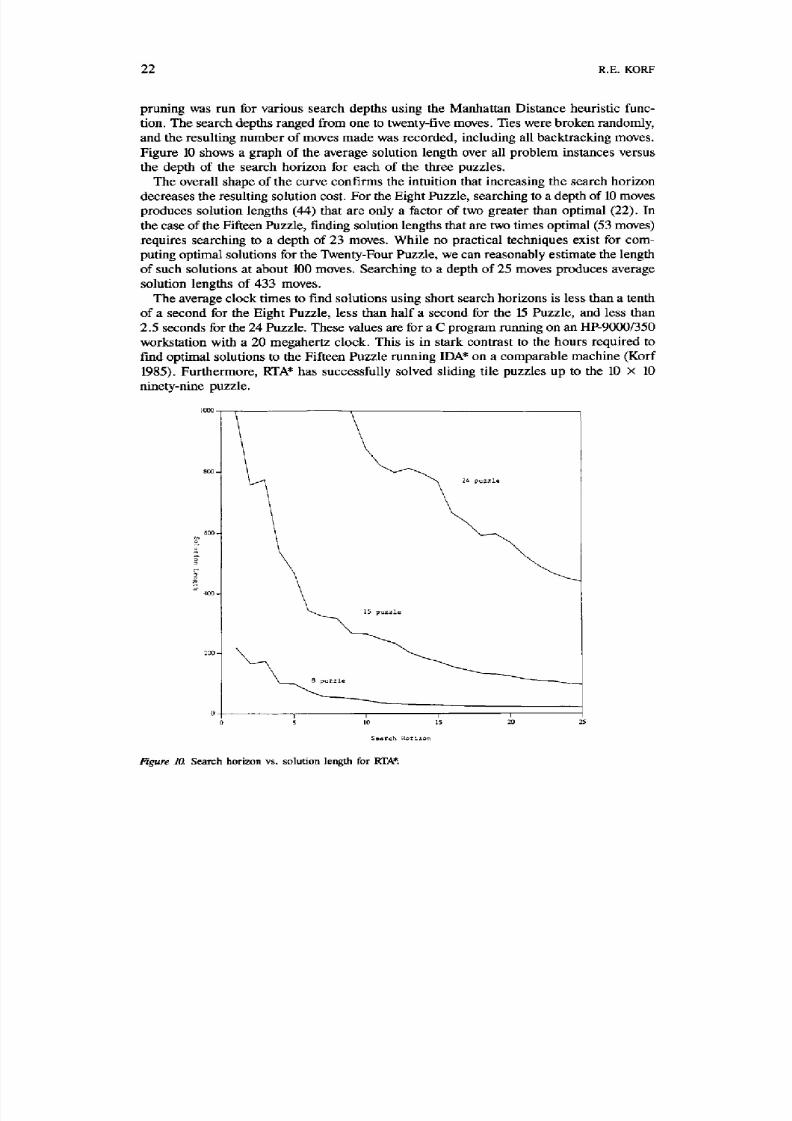
and the resu l t ing n um ber of moves made was recorded , including al l backtracking moves .Figure 10 shows a graph of the average solution length over all problem instances versus
the depth of the search horizon for each of the three puzzles.
The overall shape of the curve confirms the intuition that increasing the search horizon
decreases the resulting solution cost. F or the Eight Puzzle, searching to a depth o f 10 moves
produces solution lengths (44) that are only a factor of two greate r than optim al (22). In
the case of the Fifteen Puzzle, finding solution lengths that are two times optim al (53 moves)
requires searching to a depth of 23 move s. While no practic al techniques exist for com -
puting optimal solutions for the Twenty-Four Puzzle, we can rea sonably estima te the length
of such solutions at abou t 100 moves. Searching to a depth of 25 moves produce s average
solution lengths o f 433 moves.Th e average clock times to f ind solutions using sh ort search horizons is less than a tenth
of a second for the Eigh t Puzzle, less than half a second for the 15 Puzzle, and less than
2.5 seconds for the 24 Puzzle. These values are for a C program running on an HP-9000/350
workstation with a 20 megahertz clock. This is in stark contrast to the hours required to
find optimal solutions to the Fif teen Puzzle running IDA* on a comparable machine (Korf
1985). F urth erm ore , RTA* has succes sfully solved sliding tile puzzles up to the 10 x 10
ninety-nine puzzle.
800-
600-
=.
7- ~oo-
200-
15 puzzle
8 puzzle
1000
;0 ;~ ~'0
Se a rc h Hor i z on
Figure 10. Search horizon vs. solution length for RTA*.

8/14/2019 Depth Limited Search
http://slidepdf.com/reader/full/depth-limited-search 17/18
DEPTH-LIMITED SEARCH FOR REAL-TIME PROBLEM SOLVING 23
Iterative-deepening can easily be applied to RTA* as well. Instead of a fixed sea rch hor izon
for minimin and alpha pru ning, successive i terations to dee per thresholds are executed un-
ti l the move deadline is reached. At that point the move recommended by the last com-pleted i teration is executed.
5. Conclus ions
We have examined f ixed-depth lookahead search as a paradigm for real - time problem solv-
ing in three different sett ings: two-player games, multi-player games, and single-agent
problems.
Fixed-depth minimax search is the basic two-player game algorithm. Alpha-beta prun-
ing can double the achievable search horiz on w ithout effecting the q uali ty o f decisions made.
Wh en co mbin ed with node ordering, quiescence, and i terative-deepening, these techniques
have been rem arkably successful in producing v ery high perform ance programs u nder real -
t ime constraints .
Allowing mo re than two players leads to a generalization of the minim ax algorithm called
maxn. I f we fur ther assume that there i s a lower bound o n each c omp onen t of the evalua-
t ion funct ion, and an upp er bound on the sum of a l l components , then shal low alpha-beta
prunin g is possible, but n ot deep pruning. In the best case, this results in s ignificant sav-
ings in computation, but in the average case i t does not reduce the asymptotic branching
factor.
Most s ingle-agent heurist ic search algorithms cannot be used in real-t ime applications,due to thei r com putat ional cos t and the fact that they cannot com mit to an act ion before
its ultimate outcom e is known . Min imin lookahead search is an effective algorithm for such
problems. Alpha pruning dramat ical ly improves the eff ic iency of the a lgori thm without
affecting the decisions made, and the achievable search horizon with this algorithm in-
creases w ith increasing branc hing factor. Real-Time-A* efficiently solves the pro blem of
when to abandon the current path in favor of a more promis ing one, and is guaranteed
to eventually find a solution. In addit ion, RTA* mak es locally optima l decisions on a tree.
Extensive simulations on three different s izes of s l iding t i le puzzles show that increasing
search depth increases solution quali ty, and that solution lengths comparable to optimal
ones a re achievable in practice. T hese algorithms effectively solve larger s ingle-agent prob-lems than have previously been solvable using heurist ic evaluation functions.
In each case, fixed-dep th search comb ined w ith i terative-deepening allows the problem
solver to execute a decision at any po int in t ime, while continuing to refine i ts decisions
as long as a com mitm ent i s not required. Fu rtherm ore, i t focuses the a t tent ion of the prob-
lem solver on the m ost imm ediate consequences of i ts ac tions , and o nly cons iders la ter
ramifications as t ime permits .
In general , we have model led the com putat ional cons t ra ints of a real - t ime problem as
simply a strict deadline on each decision. In more complex si tuations, there may not be
strict deadlines, b ut rathe r increasing cost with t ime of delay, a nd/o r a pro blem of allocating
fixed computational resources over multiple decisions. These si tuations call for more
sophisticated resource managem ent, and is being pursued by several groups (Horvitz, Coo per
and He cke rm an 1989; Bo ddy and De an 1989; Russell and Wefald 1989) un der the general
model of decis ion-theoret ic control of computat ion.

8/14/2019 Depth Limited Search
http://slidepdf.com/reader/full/depth-limited-search 18/18
24 R.E. KORF
References
Newell, A ., H.A . Simon, and J.C . Shaw. 1963. Emp irical explorations with the logic theory machin e: A casestudy in heuristics. In Computers and Thought, E. Feigenbaum and J. Feldman (Eds.). New York: McGraw-HiU.
Samuel, A.L . 1963. Some studies in machine learning using the gam e of checkers. In Computers and Thought,
E. Feige nbaum and J. Feldman (Eds.), New York: McGraw-Hill.
Berliner, H. 1989. Deep-Thought w ins Fredkin Intermediate Prize. A /M aga zin e, 10, 2, (Summer).
Korf, R .E. 1985. Depth- first iterative-deepening: An optim al adm issible tree search. Artificial Intelligence, 27,
1:97-109.
Korf, R .E. 1988. Search in AI: A survey of recent results. In Exploring Artificial Intelligence. Los Altos, CA:
Morgan-Kaufmann.
Korf, R.E. 1990. Mult-player alp ha-beta prun ing. Artificial Intelligence (to appea r).
Korf, R.E. 1990. Real-time heuristic search. Artificial Intelligence (to appear).
Shannon, C.E. 1980. Programming a Com puter for Playing C hess. Philosophical Magazine, 41:256-275.
Pearl, J. 1984. Heuristics. Reading, MA: Addison-Wesley.
Hart, T.P., an d D .J. Edwards. 1963. The alph a-beta heuristic. M.I.T, Artificial Intelligence Project Memo,
Massachusetts Institute of Technology, Camb ridge, M A, October.
Knu th, D.E., and R .E. Moore. 1975. An analysis of Alpha-b eta pruning. Artificial Intelligence, 6,4:293-326.
Pearl, J. 1982. The solution for the b ranching factor o f the Alpha-Beta prun ing algorithm and its optimality. Com-
munications of the Association of Computing Machinery, 25, 8:559-564.
Luckhardt, C.A ., a nd K.B. Irani. 1986. An algorithm ic solution of N-perso n games. Proceedings o f the National
Conference on Artificial Intelligence (AAAI-86), Philadelphia, PA, (Aug):158-162.
Hart, RE . N.J. Nilsson , and B. Raphael. 1968. A form al basis for the heuristic determination of minim um cost
paths. IEEE Transactions on Systems Science and Cybernetics, SSC-4, 2:100-107.
Rosenberg, R.S., and J. Kestner. 1972. Look-ahead and one -perso n games. Journal of Cybernetics, 2, 4:27-42.
Horvitz, E .J., G .E Cooper, and D.E. Heckerman. 1989. Reflection and action un de r scarce resources: Theoreticalprinciples and empirical study. In Proceedings of the International Conference on Artificial Intelligence (1JCA1-89),
Detroit, Michigan, (Aug):l121-1127.
Boddy, M ., and T. Dean. 1989. Solving time-d epende nt plann ing problems. In Proceedings of the International
Conference on Artificial Intelligence (IJCAI-89), Detroit, Michigan, (Aug): 979-984.
Russell, S ., and E. W efald. 1989. On optimal game -tree search using rational meta-reasoning. In Proceedings
of the International Conference on Artificial Intelligence (IJCAI-89), Detroit, Michigan, (Aug):334-340.