Embed Size (px)
Citation preview

Prof. Dr. José Antonio de Frutos RedondoDr. Raúl Durán DíazCurso 2010-2011
Departamento de AutomáticaArquitectura e Ingeniería de Computadores
Tema 4Arquitecturas Paralelas

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 2V1.4
Tema 4. Arquitecturas Paralelas
Arquitecturas paralelas.¿En qué consiste una arquitectura paralela?Evolución y convergencia de las arquitecturas paralelas.
Redes de interconexión.Redes de interconexión estáticas.Redes de interconexión dinámicas.
Coherencia en memoria cache.Fuentes de incoherencia.Protocolos basados en escucha.Protocolos basados en directorios.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 3V1.4
Sistemas vectoriales instalados (85-93)

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 4V1.4
Base instalada de Crays (76-85)

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 5V1.4
Arquitecturas Paralelas
Comparativa Vectoriales-MPPLI
NPA
CK
(GFL
OP
S)
CRAY peakMPP peak
Xmp /416(4)
Ymp/832(8) nCUBE/2(1024)iPSC/860
CM-2CM-200
Delta
Paragon XP/S
C90(16)
CM-5
ASCI Red
T932(32)
T3D
Paragon XP/S MP�(1024)
Paragon XP/S MP�(6768)
0.1
1
10
100
1,000
10,000
1985 1987 1989 1991 1993 1995 1996
Crayvectoriales (paralelos) :
X-MP (2-4) Y-MP (8)C-90 (16)T94 (32)
Desde 1993, Cray produce también MPP (T3D, T3E)

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 6V1.4
Sistemas vectoriales por fabricante
0 200 400 600
Cray
CDC
Fujitsu
Hitachi
NEC
Total
1992199119901989198819871986

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 7V1.4
Lista TOP500 de los computadores más rápidos
Num
ber o
f sys
tem
s
11/93 11/94 11/95 11/960
50
100
150
200
250
300
350
PVPMPP
SMP
319
106
284
239
63
187
313
198
110
10673
Arquitecturas Paralelas

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 8V1.4
Tipos de CPU en la lista TOP500

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 9V1.4
Arquitecturas en la lista TOP500

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 10V1.4
Siglas en “Arquitecturas Paralelas”
SMP: Symmetric Multiprocessor.MPP: Massively Parallel Processor. Típicamente el número de procesadores es superior a 100.Cluster: Conjunto de computadores completos conectados por una red comercial.Cluster Beowulf: Cluster de sistema operativo libre y componentes comerciales ordinarios.Constellation: Cluster de nodos donde cada uno de ellos es de tipo SMP.Grid: Colección de recursos autónomos geográficamente distribuidos, acoplados mediante la infraestructura de comunicaciones, y débilmente acoplados.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 11V1.4
Familias de CPUs en la lista TOP500

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 12V1.4
Rendimiento de los sistemas en TOP500
En la siguiente gráfica, se muestra el rendimiento de los sistemas colocados en la posiciones 1, 10, 100, 500 de la lista TOP500.También se muestra el crecimiento acumulado.La curva del sistema número 500 crece con un factor de 1,9 anual.El resto de curvas muestran un crecimiento anual en un factor de 1,8.¡Es una especie de “ley de Moore”!

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 13V1.4
Rendimiento de los sistemas en TOP500

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 14V1.4
Criterios antiguos
Aplicaciones
SistemaSoftware SIMD
Paso de mensajesMemoria compartidaFlujo de datos
ArraysSistólicos Arquitectura
• Arquitecturas paralelas ligadas a modelos de programa-ción.
• Arquitecturas divergentes, sin ningún patrón de crecimien-to.
Arquitecturas Paralelas

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 15V1.4
Criterios actualesExtensión de la arquitectura de computadores para soportar comunicaciones y cooperación.
ANTES: Conjunto de instrucciones.AHORA: Comunicaciones.
Hay que definir: Abstracciones, fronteras, primitivas (interfaces)Estructuras que implementan los interfaces (hw o sw)
Compiladores, librerías y OS son cuestiones importantes en nuestros días.
Arquitecturas Paralelas

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 16V1.4
Arquitecturas Paralelas
Recordemos queUn computador paralelo es un conjunto de elementos de proceso que se comunican y cooperan para resolver rápidamente grandes problemas.Podemos decir que la “Arquitectura Paralela” es:
Arquitectura convencional+
Arquitectura de comunicación

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 17V1.4
Arquitecturas Paralelas
Arquitectura de comunicaciónUser/System Interface + Implementación
User/System Interface:Primitivas de comunicación a nivel de usuario y a nivel de sistema.
Implementación:Estructuras que implementan las primitivas: hardware o OSCapacidades de optimización. Integración en los nodos de proceso.Estructura de la red.
Objetivos:RendimientoAmplia aplicaciónFácil programaciónAmpliableBajo coste

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 18V1.4
Modelos de programaciónEspecifica las comunicaciones y la sincronización.Ejemplos:
Multiprogramación: no hay comunicación o sincronismo. Paralelismo a nivel de programa.Memoria compartida: como un tablón de anuncios.Paso de mensajes: como cartas o llamadas telefónicas, punto a punto.Paralelismo de datos: varios agentes actúan sobre datosindividuales y luego intercambian información de control antes de seguir el proceso.
El intercambio se implementa con memoria compartida o con pasode mensajes.
Arquitecturas Paralelas

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 19V1.4
CAD
Multiprogramming Sharedaddress
Messagepassing
Dataparallel
Database Scientific modeling Parallel applications
Programming models
Communication abstractionUser/system boundary
Compilationor library
Operating systems support
Communication hardware
Physical communication medium
Hardware/software boundary
Arquitecturas Paralelas
Niveles de abstracción en la comunicación

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 20V1.4
Arquitecturas Paralelas
Evolución de los modelos arquitectónicosModelo de programación, comunicación y organización de la máquina componen la arquitectura.
Espacio de memoria compartida.Paso de mensajes.Paralelismo de datos.Otras:
Flujo de datos.Arrays sistólicos.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 21V1.4
Memoria Compartida
Cualquier procesador puede referenciar directamente cualquier posición de memoria.
La comunicación se realiza implícitamente por medio de cargas y almacenamientos.
Ventajas: Localización transparente.Programación similar a tiempo compartido en uniprocesadores.
Excepto que los procesos se ejecutan en diferentes procesadores.Buen rendimiento en distribución de carga.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 22V1.4
Memoria Compartida
Proporcionado en un amplio rango de plataformas.
Históricamente sus precursores datan de los años 60.
Desde 2 procesadores a cientos de procesadores.
Conocidas como máquinas de memoria compartida.
Ambigüedad: la memoria puede estar distribuida en los procesadores.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 23V1.4
Memoria Compartida
Proceso: espacio de direcciones virtuales más una o varias hebras.
Parte de las direcciones son compartidas por varios procesos.
Las escrituras en posiciones compartidas son visibles a las otras hebras (también en otros procesos).Es la extensión natural del modelo uniprocesador: memoria convencional; operaciones atómicas especiales para la sincronización.El sistema operativo usa la memoria compartida para coordinar procesos.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 24V1.4
Memoria Compartida
Store
P1P2
Pn
P0
Load
P0 pr i vat e
P1 pr i vat e
P2 pr i vat e
Pn pr i vat e
Espacio de direcciones virtuales.Conjunto de procesos con comunicaciónpor medio de memoria compartidas
Direcciones Físicas en la máquina
Espacio de direcciones compartidas
Espacio de direcciones privadas
DireccionesFísicascompartidas

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 25V1.4
Memoria Compartida
I/O ctrlMem Mem Mem
Interconnect
Mem I/O ctrl
Processor Processor
Interconnect
I/Odevices
Hardware de comunicación
Aumento independiente de capacidades de memoria, de I/O o de proceso añadiendo módulos, controladores o procesadores.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 26V1.4
Memoria Compartida
P
P
C
C
I/O
I/O
M MM M
Estrategia de comunicaciones en “Mainframe”:
•Red de barras cruzadas.•Inicialmente limitado por el coste de los procesadores. Después, por el coste de la red.•El ancho de banda crece con p.•Alto coste de ampliación; uso de redes multietapa.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 27V1.4
Memoria Compartida
PP
C
I/O
M MC
I/O
$ $
Estrategia de comunicaciones en “Minicomputer”:
•Casi todos los sistemas con microprocesadores usan bus. •Muy usados para computación paralela.•Llamados SMP, symmetricmultiprocessor.•El bus puede ser un cuello de botella.•Problema de la coherencia en cache.•Bajo coste de ampliación

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 28V1.4
Memoria Compartida
Ejemplo: Intel Pentium Pro Quad.
Coherencia y multiproceso integrados en el modulo procesador.
P-Pro bus (64-bit data, 36-bit address, 66 MHz)
CPU
Bus interface
MIU
P-Promodule
P-Promodule
P-Promodule256-KB
L2 $Interruptcontroller
PCIbridge
PCIbridge
Memorycontroller
1-, 2-, or 4-wayinterleaved
DRAM
PC
I bus
PC
I busPCI
I/Ocards

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 29V1.4
Ejemplo: SUN Enterprise. 16 tarjetas de cualquier tipo: procesadores + memoria, o I/O.El acceso a la memoria es por bus, simétrico.
Gigaplane bus (256 data, 41 addr ess, 83 MHz)
SB
US
SB
US
SB
US
2 Fi
berC
hann
el
100b
T, S
CS
I
Bus interface
CPU/memcardsP
$2
$P
$2
$
Mem ctrl
Bus interface/switch
I/O car ds
Memoria Compartida

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 30V1.4
Otras opciones en comunicación:
Problemas de interconexión: coste (barras cruzadas) o ancho de banda (bus).Dance-hall: ampliable a menor coste que en barras cruzadas.
Latencia en acceso a memoria uniforme, pero alta.NUMA (non-uniform memory access):
Construcción de un simple espacio de memoria con latencias diferentes.COMA: Arquitectura de memoria a base de caches compartidas.
M M M° ° °
° ° ° M ° ° °M M
NetworkNetwork
P
$
P
$
P
$
P
$
P
$
P
$
UMA o Dance hall NUMA
Memoria Compartida

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 31V1.4
Ejemplo: Cray T3E
Ampliable a 1024 procesadores, enlaces de 480MB/s. El controlador de memoria genera las peticiones para posiciones no locales.No tiene mecanismo de hardware para coherencia (SGI Origin y otros sí lo proporcionan)
Switch
P$
XY
Z
Exter nal I/O
Memctrl
and NI
Mem
Memoria Compartida

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 32V1.4
Construidos por medio de computadores completos, incluyendo I/O.
Comunicación por medio de operaciones explícitas de I/O.
Modelo de programación: acceso directo sólo a direcciones privadas (memoria local), comunicación por medio de mensajes (send/receive)Diagrama de bloques similar al NUMA
Pero las comunicaciones se integran a nivel de I/O.Como redes de workstations (clusters), pero mayor integración.Más fáciles de construir y ampliar que los sistemas NUMA.
Modelo de programación menos integrado en el hardware.Librerías o intervención del sistema operativo.
Paso de Mensajes

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 33V1.4
Paso de Mensajes
send especifica el buffer a transmitir y el proceso receptor.recv especifica el proceso emisor y el buffer de almacenamiento.Son copias memoria-memoria, pero se necesitan los nombres de procesos.Opcionalmente se puede incluir el destino en el envío y unas reglas de identificación en el destino.En la forma simple, el emparejamiento se consigue por medio de la sincronización de sucesos send/recv.
Existen múltiples variantes de sincronización.Grandes sobrecargas: copia, manejo de buffer, protección.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 34V1.4
Paso de Mensajes
Proceso P Proceso Q
Direcciones Y
Dir X
Send X, Q, t
Receive Y,P, t ,Match
Espacio localdel proceso
Espacio localdel proceso

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 35V1.4
Evolución en las máquinas de Paso de Mensajes
Primeras máquinas: FIFO en cada enlace.
Modelo de programación muy próximo al hw; operaciones simples de sincronización.Reemplazado por DMA, permitiendo operaciones no bloqueantes.
Buffer de almacenamiento en destino hasta recv.
Disminución de la influencia de la topología (enrutado por hw).
Store&forward routing: importa la topología.Introducción de redes multietapa. Mayor coste: comunicación nodo red.Simplificación de la programación
000001
010011
100
110
101
111
Paso de Mensajes

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 36V1.4
Memory bus
Micr oChannel bus
I/O
i860 NI
DMA
DR
AM
IBM SP-2 node
L2 $
Power 2CPU
Memorycontr oller
4-wayinterleaved
DRAM
General inter connectionnetwork formed fr om8-port switches
NIC
Ejemplo: IBM SP-2
Realizado a base de estaciones RS6000.
Paso de Mensajes

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 37V1.4
Memory bus (64-bit, 50 MHz)
i860
L1 $
NI
DMA
i860
L1 $
Driver
Memctrl
4-wayinterleaved
DRAM
IntelParagonnode
8 bits,175 MHz,bidir ectional2D grid network
with pr ocessing nodeattached to every switch
Sandia’ s Intel Paragon XP/S-based Super computer
Ejemplo Intel Paragon.
Paso de Mensajes

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 38V1.4
La evolución y el papel del software ha difuminado las fronteras entre memoria compartida y paso de mensajes.
send/recv soporta memoria compartida vía buffers.Se puede construir un espacio global de direcciones en Paso de Mensajes.
También converge la organización del hardware.Mayor integración para Paso de Mensajes (menor latencia, mayor ancho de banda)A bajo nivel, algunos sistemas de memoria compartida implementan paso de mensajes en hardware.
Distintos modelos de programación, pero también en convergencia.
La Convergencia de las Arquitecturas

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 39V1.4
Modelo de programación:Las operaciones se ejecutan en paralelo en cada elemento de la estructura.Una hebra de control, ejecución paralela.
Un procesador asociado a cada elemento.
PE PE PE° ° °
PE PE PE° ° °
PE PE PE° ° °
° ° ° ° ° ° ° ° °
Contr olprocessor
Paralelismo de Datos
Modelo arquitectónico: Array de muchos procesadores simples, baratos y con poca memoria.Asociados a un procesador de control que emite las instrucciones.Fácil sincronización de comunicaciones.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 40V1.4
EVOLUCIONRígida estructura de control (SIMD en la taxonomía de Flynn)Populares cuando el coste ahorrado con la centralización era alto.
En los 60, cuando la CPU era un armario.Reemplazados por vectoriales a mediados de los 70.
Más flexibles y fáciles de manejarRevivido en los 80 cuando aparecen 32-bit datapath slices. Aniquilados por los modernos microprocesadores.
Más razones para su desaparición:Las aplicaciones regulares son fáciles de ejecutar por su localidad en otro tipo de procesadores.MIMD son eficaces y más generales en el paralelismo de datos.
El modelo de programación converge con SPMD (single program multiple data).
Paralelismo de Datos

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 41V1.4
1 b
a
+ − ×
×
×
c e
d
f
Dataflow graph
f = a × d
Network
Token�stor e
Waiting�Matching
Instruction�fetch
Execute
Token queue
Form�token
Network
Network
Program�store
a = (b +1) × (b − c)��d = c × e��
Flujo de Datos

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 42V1.4
Flujo de Datos
EVOLUCIÓNClaves:
Capacidad para el nombramiento de instrucciones, sincronización,planificación dinámica.
Problemas:Manejo de complejas estructuras de datos, como arrays.Complejidad de la memoria de emparejamiento y la unidades de memoria.
Convergencia al uso de procesadores y memoria convencional.Soporte para conjuntos de hebras ejecutadas en distintos procesadores.Uso de memoria compartida.Progresiva separación entre el modelo de programación y el HW.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 43V1.4
Interconexión de sistemas paralelos
La misión de la red en una arquitectura paralela es transferir información desde cualquier fuente a cualquier destino minimizando la latencia y con coste proporcionado.La red se compone de:
nodos;conmutadores;enlaces.
La red se caracteriza por su:topología: estructura de la interconexión física;enrutado: que determina las rutas que los mensajes pueden o deben seguir en el grafo de la red;estrategia de conmutación: de circuitos o de paquetes;control de flujo: mecanismos de organización del tráfico.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 44V1.4
Interconexión de sistemas paralelos
Clasificación de las redes por su topología.Estáticas:
conexiones directas estáticas punto a punto entre los nodos;fuerte acoplamiento interfaz de red-nodo;los vértices del grafo de la red son nodos o conmutadores;se clasifican a su vez:
simétricas: anillo, hipercubo, toro;no simétricas: bus, árbol, malla.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 45V1.4
Interconexión de sistemas paralelos
Clasificación de las redes por su topología.Dinámicas:
los conmutadores pueden variar dinámicamente los nodos que interconectan.Se clasifican a su vez:
monoetapa;multietapa:
bloqueante (línea base, mariposa, baraje);reconfigurable (Beneš);no bloqueante (Clos).

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 46V1.4
Interconexión de sistemas paralelos
Parámetros característicos de una red:Tamaño de la red: número de nodos que la componen.
Grado de un nodo: número de enlaces que inciden en el nodo.
Diámetro de la red: es el camino mínimo más largo que se puede encontrar entre dos nodos cualesquiera de la red.
Simetría: una red es simétrica si todos los nodos son indistinguibles desde el punto de vista de la comunicación.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 47V1.4
Red lineal
Anillo Estrella
Arbol Malla Red sistólica
Totalmente conexa Anillo cordalCubo-3
Redes estáticas

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 48V1.4
sínN/2nnhipercubo n
no2N − 2r2(r − 1)4malla - 2D (r x r)
noN − 12N − 1estrella
noN − 12(h − 1)3arbol (h = log2 N + 1)
síN(N − 1)/21N − 1totalmente conexa
síNN/22anillo
noN − 1N − 12lineal
simetríaenlacesdiámetrogradoTipo de red
Redes estáticas

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 49V1.4
Hipercubo 3D ciclo-conexo
Redes estáticas

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 50V1.4
000 001
010 011
101
111110
100
000 010001 011 100 110101 111
Conexión de nodos que se diferencian en el bit menos significativo
Conexión de nodos que se diferencian en el segundo bit
000 010001 011 100 110101 111
Conexión de nodos que se diferencian en el bit más significativo
000 010001 011 100 110101 111
Ejemplo de conexiones en un hipercubo 3
Redes estáticas

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 51V1.4
Redes dinámicas: son redes cuya configuración puede modificarse. Hay dos tipos:
monoetapa.multietapa.
Las redes monoetapa realizan conexiones entre elementos de proceso en una sola etapa.
Puede que no sea posible llegar desde cualquier elemento a cualquier otro, por lo que puede ser necesario recircular la información (=>redes recirculantes)
Las redes multietapa realizan conexiones entre los elementos de proceso en más de una etapa.
Redes dinámicas

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 52V1.4
Redes dinámicas
Redes de interconexión monoetapa

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 53V1.4
Redes dinámicas
EP0
EP1
EPn
EP0 EP1 EPn
EP0
EP1
EPn
M0 M1 Mm
Red de barras cruzadas: permite cualquier conexión.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 54V1.4
Redes de interconexión (multietapa)
Las cuatro configuraciones posibles de una caja de conmutación de 2 entradas.
Cajas de conmutación
a 0
a 1
b 0
b 1
a 0
a 1
b 0
b 1
a 0
a 1
b 0
b 1
a 0
a 1
b 0
b 1
Paso directo Cruce
Difusión superiorDifusión inferior
Redes dinámicas

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 55V1.4
Redes dinámicas bloqueantes
Redes multietapa bloqueantes.Se caracterizan porque no es posible establecer siempre una nueva conexión entre un par fuente/destino libres, debido a conflictos con las conexiones en curso.Generalmente existe un único camino posible entre cada par fuente/destino.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 56V1.4
Redes dinámicas bloqueantes
Red de línea base:
Red de línea base 8 x 8

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 57V1.4
Redes dinámicas bloqueantes
Red mariposa:
© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 58V1.4
Redes dinámicas bloqueantes
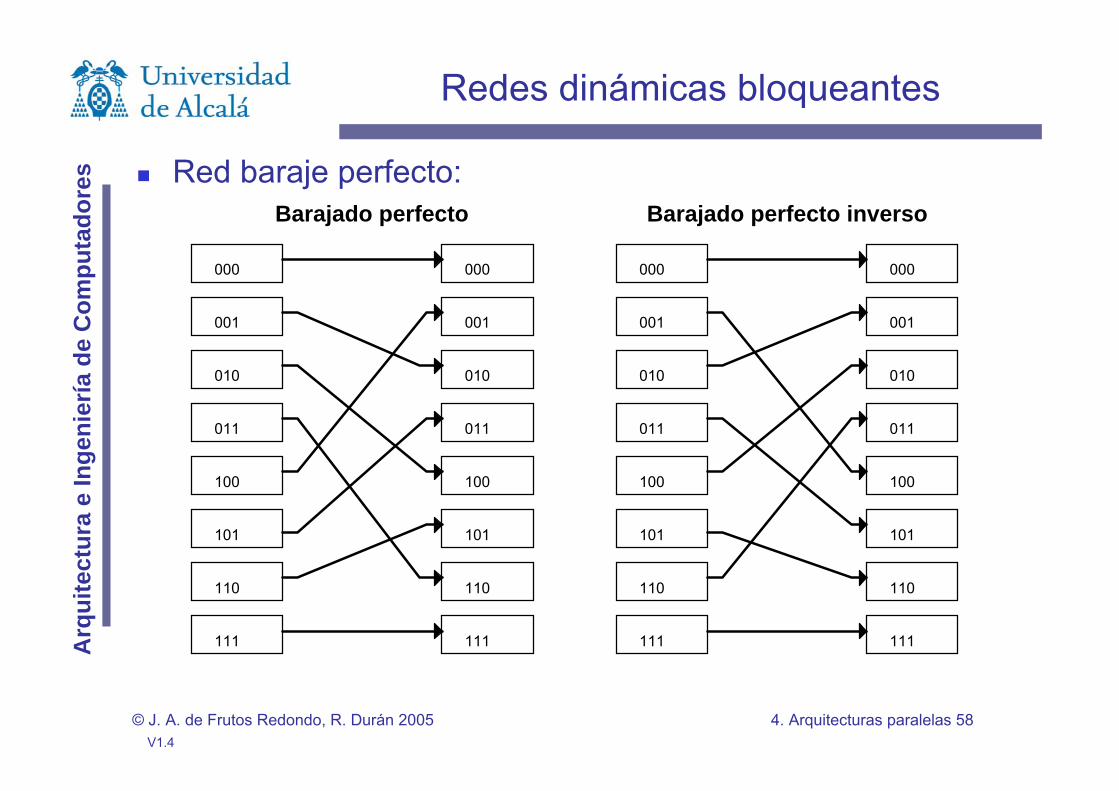
Red baraje perfecto:
000
001
010
011
100
101
110
111
000
001
010
011
100
101
110
111
Barajado perfecto
000
001
010
011
100
101
110
111
000
001
010
011
100
101
110
111
Barajado perfecto inverso

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 59V1.4
Redes dinámicas reconfigurables
Redes multietapa reconfigurables.Se caracterizan porque es posible establecer siempre una nueva conexión entre un par fuente/destino libres, aunque haya conexiones en curso, pero puede hacerse necesario un cambio en el camino usado por alguna(s) de ellas (reconfiguración).Interesante en procesadores matriciales, en donde se conoce simultáneamente todas las peticiones de interconexión.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 60V1.4
Redes dinámicas reconfigurables
Red de Beneš:
Red de Benes 8 x 8

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 61V1.4
Redes dinámicas reconfigurables
La red de Beneš se puede construir recursivamente:
Red de Benes 8 x 8
Red de Benes 4 x 4
Red de Benes 4 x 4

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 62V1.4
Redes dinámicas no bloqueantes
Redes dinámicas no bloqueantes.Se caracterizan porque es posible establecer siempre una nueva conexión entre un par fuente/destino libres sin restricciones.Son análogas a los conmutadores de barras cruzadas, pero pueden presentar mayor latencia, debido a las múltiples etapas.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 63V1.4
Redes dinámicas no bloqueantes
Red de Clos:
1
2
r
1
2
m
1
2
r
n x m r x r m x n
1
n
1
n
Red de Clos

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 64V1.4
Coherencia en Memoria Cache
Estructuras comunes de la jerarquía de memoria en multiprocesadores
Memoria cache compartida.Memoria compartida mediante bus.Interconexión por medio de red (dance-hall)Memoria distribuida.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 65V1.4
Coherencia en Memoria Cache
P1 Pn
Memoria principal(Entrelazada)
Memoria cache(Entrelazada)
Cache compartidaPequeño número de procesadores (2-8)Fue común a mediados de los 80 para conectar un par de procesadores en placa.Posible estrategia en chip multiprocesadores.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 66V1.4
Compartición por medio de bus.Ampliamente usada en multiprocesadores de pequeña y mediana escala (20-30)Forma dominante en las máquinas paralelas actuales.Los microprocesadores modernos están dotados para soportar protocolos de coherencia en esta configuración.
P1 Pn
Memoria principal
Memoriacache
Memoriacache
bus
Coherencia en Memoria Cache

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 67V1.4
Salón de baileFácilmente escalable.Estructura simétrica UMA.Memoria demasiado lejana especialmente en grandes sistemas.
P1 Pn
Memoria principal
Memoriacache
Memoriacache
Red de interconexión
Memoria principal
Coherencia en Memoria Cache

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 68V1.4
Pn
MemoriacacheMemoria
principal
Red de interconexión
P1
MemoriacacheMemoria
principal
Coherencia en Memoria Cache
Memoria distribuida•Especialmente atractiva par multiprocesadores escalables.•Estructura no simétrica NUMA.•Accesos locales rápidos.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 69V1.4
El problema de la coherencia
Datos actualizados en memoria principal y las caches particulares.Monoprocesadores:
Incoherencia en distintos niveles.Operaciones de I/O.
Multiprocesadores:Incoherencia en distintos nivelesIncoherencia en el mismo nivel
Coherencia en Memoria Cache

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 70V1.4
Fuentes de incoherencia:
Los datos compartidos.La migración de procesos.Las operaciones de entrada-salida.
Coherencia en Memoria Cache

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 71V1.4
P0 P1 P2 Pn
Memoria principal
Memoriacache
Fuentes de incoherencia
Datos compartidosen caches de escritura directa.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 72V1.4
Memoria principal
P0 P1 P2 Pn
Memoriacache
Datos compartidosen caches de post-escritura.
Fuentes de incoherencia

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 73V1.4
P0 P1 P2 Pn
Memoria principal
Memoriacache
P2P0
Migración de procesosen caches de escritura directa.
Fuentes de incoherencia

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 74V1.4
P0 P1 P2 Pn
Memoria principal
Memoriacache
P2P0
Migración de procesosen caches de post-escritura.
Fuentes de incoherencia

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 75V1.4
Operaciones de entrada salida
Salida (post-escritura)
Memoria principal
Memoriacache
P0 P1 P2 Pn
Entrada
Fuentes de incoherencia

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 76V1.4
Posibles soluciones
Caches locales.Memoria cache compartida.Caches privadas con protocolos de escucha.Caches privadas con directorio compartido.
Coherencia en Memoria Cache

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 77V1.4
P
X
P
X
P
X
P
X
X
P
X'
P
I
P
I
P
I
X'
P
X'
P
X'
P
X'
P
X'
X'
Invalidar Actualizar
Políticas de mantenimiento de coherenciaInvalidar.Actualizar.
Coherencia en Memoria Cache

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 78V1.4
Protocolos de escucha
Protocolos snoopy
Sistemas de memoria basados en bus.Escucha de las operaciones (snoop)Se deben transmitir las operaciones de lectura y escritura.Las operaciones de cambio de bloque no influyen en el estado del bloque en otros procesadores.

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 79V1.4
Protocolos snoopyCaches de escritura directa.
inválido válidoR(j)W(j)
R(i), W(i)
W(j)
R(j)W(i)
R(i)
Protocolos de escucha

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 80V1.4
R(i)R(j)
R(j), W(j)
M S
I
R(j)
W(i)R(i)W(i)
W(j)
W(i)
W(j)
R(i)
Protocolos snoopyCaches de post-escritura MSI.
Protocolos de escucha

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 81V1.4
W(j)R(j)
R(i) S
R(i)R(j)
W(i) W(j)R(j)
R(i)R(i)W(i) M E
S I
W(j)
R(i) S
W(i)
W(j)
R(j) S
W(i)
Protocolos snoopyCaches de post-escritura MESI.
Protocolos de escucha

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 82V1.4
Protocolos basados en directorios
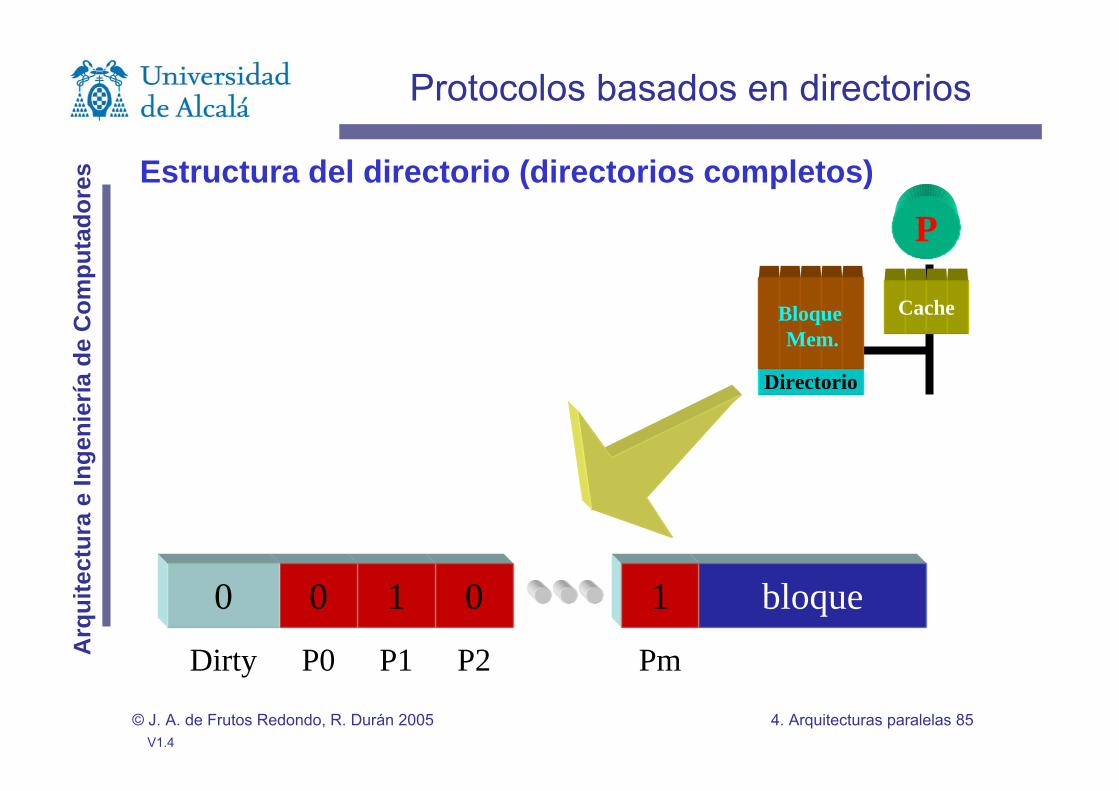
Multiprocesadores con red de interconexión.Dificultades de broadcast y su escalabilidad.Directorio: guarda la información relativa al estado del bloque de cache.Directorios centralizados y directorios distribuidos.
Protocolos basados en directorios

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 83V1.4
Fallo de lectura en estado modificado.
Directorio
P1
CacheBloque Mem. Directorio
P2
CacheBloque Mem.
Directorio
P3
CacheBloque Mem.
Protocolos basados en directorios
1
2
3
4
4

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 84V1.4
Fallo de escritura en estado compartido.
Directorio
P1
CacheBloque Mem. Directorio
P2
CacheBloque Mem.
Directorio
P3
CacheBloque Mem.
Directorio
P4
CacheBloque Mem.
Protocolos basados en directorios
4 4
3 3
1
2
© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 85V1.4
bloque1010
Directorio
P
CacheBloque Mem.
0
P0 P1 PmP2Dirty
Estructura del directorio (directorios completos)
Protocolos basados en directorios

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 86V1.4
Estructura del directorio (directorios limitados)
bloque
Directorio
P
CacheBloque Mem.
0
I1 InI2Dirty
log2 P
Protocolos basados en directorios

© J. A. de Frutos Redondo, R. Durán 2005
Arq
uite
ctur
a e
Inge
nier
ía d
e C
ompu
tado
res
4. Arquitecturas paralelas 87V1.4
Estructura del directorio (directorios encadenados)
bloqueDirectorio
P
CacheBloque Mem.0
PDirty
log2 P
Directorio
P
CacheBloque Mem.
Directorio
P
CacheBloque Mem.
Directorio
P
CacheBloque Mem.
FC FC FC
Protocolos basados en directorios











![Clinical Predictors of Dynamic Lower Extremity Stiffness ... · -----[ RESEARCH REPORT ]----- JONATHAN S. GOODWIN, PT, PhD, DPT1 • J. TROY BLACKBURN, PhD, ATC2 TODD A. SCHWARTZ,](https://img.pdfslide.us/doc/110x75/605c4d5d4f769748a016a568/clinical-predictors-of-dynamic-lower-extremity-stiffness-research-report.jpg)

















