Embed Size (px)
Citation preview

Deep Transfer Across Domains for Face Anti-spoofing
Xiaoguang Tu1∗, Hengsheng Zhang1, Mei Xie1, Yao Luo1, Yuefei Zhang2, Zheng Ma11University of Electronic Science and Technology of China, 2Chongqing Institute of Public Security Science and Technology
Abstract
A practical face recognition system demands not onlyhigh recognition performance, but also the capability ofdetecting spoofing attacks. While emerging approaches offace anti-spoofing have been proposed in recent years, mostof them do not generalize well to new database. The gen-eralization ability of face anti-spoofing needs to be signif-icantly improved before they can be adopted by practicalapplication systems. The main reason for the poor gener-alization of current approaches is the variety of materialsamong the spoofing devices. As the attacks are producedby putting a spoofing display (e.t., paper, electronic screen,forged mask) in front of a camera, the variety of spoof-ing materials can make the spoofing attacks quite different.Furthermore, the background/lighting condition of a newenvironment can make both the real accesses and spoofingattacks different. Another reason for the poor generaliza-tion is that limited labeled data is available for training inface anti-spoofing. In this paper, we focus on improvingthe generalization ability across different kinds of datasets.We propose a CNN framework using sparsely labeled datafrom the target domain to learn features that are invari-ant across domains for face anti-spoofing. Experiments onpublic-domain face spoofing databases show that the pro-posed method significantly improve the cross-dataset testingperformance only with a small number of labeled samplesfrom the target domain.
1. IntroductionIn biometric based face recognition systems, spoofing at-
tacks are usually perpetrated using photographs, replayedvideos or forged masks. Despite continuous works on faceanti-spoofing over the years [1, 2, 3, 4, 5, 6, 7], most ofthem limit to the non-realistic intra-database testing scenar-ios instead of the cross database testing scenarios. In prac-tical scenario, the environments are not fixed, differencesin light conditions, backgrounds and camera resolutions ofa new environment may make the images captures differ-ently. Besides, as the spoofing displays can be produced
using different kinds of materials, such as paper, electronicscreen and forged mask, the distributions of spoofing sam-ples are widely varied. Therefore, it is extremely hard thatan approach trained on one dataset performs well on otherdatasets.
Among the numerous published literatures, most of themfocused on hand-crafted features and tried to capture texturedifferences between live and spoofing face images from theperspective of surface reflection and material differences,such as LBP [3], LBP-TOP [4] and HOG [8]. However,methods in this category may suffer from poor generaliz-ability since the texture varies with the spoofing devices.In [5, 7], the researchers used CNNs to automatically learnfeatures for face anti-spoofing and have achieved promis-ing performance. Nevertheless, the CNNs need a largenumber of various types of spoofing data to guarantee itsgeneralization ability. Even the traditional approach foradapting deep models, fine-tuning, may require hundredsor thousands of labeled examples for each category thatneed to be adapted [9]. Unfortunately, the current publiclyavailable face spoofing datasets, such as Replay Attack [3],CASIA-FASD [10], MSU-MFSD [11] and NUAA [2] aretoo limited to train a generalized network compared withthe datasets of image classification and face recognition.
However, in the practical application of a face anti-spoofing product, it is reasonable to assume that the prod-uct’s new owner will be able to label a handful of exam-ples for a few types of training samples. Given this cir-cumstance, we proposed a domain transfer network, aimingat learning domain-invariant features across two differentdatasets for robust face anti-spoofing. We propose to learna shared feature subspace where the distributions of the realaccess samples (genuine) from different domains, and thedistributions of different types of spoofing attacks (fake)from different domains are drawn close, respectively. In theproposed framework, the sufficient labeled source data areused to learn discriminative representations that distinguishthe genuine samples and the fake samples, meanwhile thesparsely labeled target samples are fed to the network to cal-culate the feature distribution distance between the genuinesamples from the source and the target domain, and between
1
arX
iv:1
901.
0563
3v1
[cs
.CV
] 1
7 Ja
n 20
19

the fake samples from the source and the target domains,corresponding to their materials. The kernel approach isadopted to map the features output from the CNN into acommon kernel space, and the Maximum Mean Discrep-ancy (MMD) is adopted to measure the distribution distancebetween the samples from the source and target domains.This feature distribution distance is treated as a domain lossterm added to the objective function and minimized alongwith training of the network. We provide a comprehen-sive evaluation on some popular datasets with the proposedmethod and show significant performance improvements.
2. Related WorkExisting face anti-spoofing approaches are mainly based
on two cues for the purpose of liveness face detection, thetexture differences between live and spoofing face imagesand the fine-grained motions such as eye blinking, mouthmovement and head movement across video frames.
In [12], the researchers utilized the difference of struc-tural texture between the 2D images and 3D images to de-tect spoofing attacks based on the analysis of Fourier spec-tra, where the reflections of light on 2D and 3D surfaces re-sult in different frequency distributions. Tan et al. [2] useda variational retinex-based method and the Difference-of-Gaussian (DoG) filters to extract latent reflectance featureson face images to distinguish fake images from real images.In [13], Maatta et al. extracted the texture of 2D imagesusing the multi-scale local binary pattern (LBP) to gener-ate a concatenated histogram which was fed into a SVMclassifier for genuine/fake face classification. In the laterwork, Chingovska et al. [3] applied the LBP operator andits variation to capture the textural properties of the inputimage. However, these method analyze each frame in isola-tion, not considering the temporal motion cues across videoframes. To make use of the temporal information, Pereira etal [4]. proposed the LBP-TOP, considering three orthogo-nal planes intersecting the center of a pixel in theXY direc-tion, XT direction and Y T direction, where T is the timeaxis. According to their experimental results, this multi-resolution LBP-TOP with SVM classifier achieved the bestHTER of 7.6% on the Replay-Attack dataset.
Though promising performance can be achieved with theabove mentioned hand-crafted features in intra-dataset pro-tocol, a new dataset of different domain may result in severeperformance degradation, since many hand-crafted featuresare designed specifically and can not be easily transferred tonew conditions [14]. In order to obtain features with bettergeneralization ability, quite a few researchers used the deepconvolutional neural network (CNN) for face anti-spoofing[5, 15, 16, 17]. The CNNs can automatically learn fea-tures and obtain discriminative cues between genuine andfake faces. If sufficient data from various domains is avail-able, the CNN-based methods can achieve performance
Figure 1: The distributions of genuine samples and twotypes of fake samples (print and video) from the databaseof MSU-MFSD (a) and Replay-Attack (b).
with fairly good generalization ability. Unfortunately, thecurrent publicly available face anti-spoofing datasets are toolimited to train a generalized network due to the difficultyin obtaining labeled training samples, the variety of materi-als of spoofing devices also enhance the domain shift in thedistribution of data representations.
To bridge the gap between two different distributions,many approaches have been proposed based on the ideasof domain adaptation [18, 19, 20, 21]. Multimodal deeplearning architectures have been proposed to learn domaininvariant representations in [22]. However, this method per-formed primarily in a generative context and did not lever-age the full representation power of supervised CNN rep-resentations. In [23], Ghifary et al. proposed pre-trainingwith a denoising auto encoder, then train a two-layer net-work simultaneously with the MMD domain confusion loss.Nevertheless, the learned network is relatively shallow andtherefore lacks the strong semantic representation which islearned by directly optimizing with a supervised deep CNN.In [20], Tzeng et al. proposed a new CNN architecturewhich introduces an adaptation layer and an additional do-main confusion loss for classification. They use MMD bothto select the depth and width of the architecture while usingit as a regularizer during fine-tuning, and achieved state-of-the-art performance on the standard visual domain adapta-tion benchmark.
3. Deep Domain Transfer Network
The idea of domain adaptation have been success-fully applied in many other fields [18, 24], similar ideas,however, have never been used in the study of faceanti-spoofing, even current face anti-spoofing approachesseverely suffered from the problem of dataset bias. In or-der to remove the dataset bias and bridge the gap betweendistributions from different domains with the limited train-ing samples, we proposed a deep domain transfer frame-work for face anti-spoofing with kernel based metric. Ker-nel based metric has already been used in many works for

Figure 2: The flowchart of the proposed framework, where every input batch contains half the source images and half thetarget images. Features of the two domains output from the last pooling layer are used to calculate the distribution distancewith kernel based MMD. The network is trained using the classification loss along with the distribution distance which istaken as domain loss.
the measurement of distribution distance [25, 26, 27]. If asuitable kernel is found, the input data can be mapped into aconvenient feature space, and the distance between differentdistributions will be better quantified.
We propose to use deep Convolutional Neural Networkto extract the discriminative features of input images. Weargue that the feature distributions of different datasets aredifferent in feature subspace that learned by the shared fea-ture extraction layer. Figure 1 illustrates the feature distri-butions of three principal components with respect to twodifferent datasets, the features are learned by CNN hiddenlayer. It is shown that the distributions of the genuine sam-ples and the two types of fake smaples in the learned fea-ture subface are vary from dataset to dataset. The proposedframework is outlined in Figure 2.
Let x ∈ Rd be a d-dimension column vector. xs ∈ Rd
and xt ∈ Rd are the data points in the source and the targetdatasets, respectively. Suppose that the source-domain dataDs = {(xs1, ys1), ..., (xsns , ysns)} and the target-domain dataDt ={(xt1, yt1), ..., (xtnt , ytnt)}, where ns and nt are the numbersof the data points. We denote the representation of thelast pooling layer as φ(·). Therefore, the representations ofsource-domain points, xs ∈ Rd, and target-domain pointsxt ∈ Rd, can be represented as φ(xs) and φ(xt), respec-tively. Suppose K is the kernel of a reproduction Hilbertspace Hk of functions. Then the MMD in Hk between thedistributions of P and Q is [28]:
MMD2K(P,Q) := Exp,x
′p[K(xp, x
′
p)] + Exq,x′q[K(xq, x
′
q)]
− 2Exp,xq[K(xp, xq)]
(1)where xp, x
′p
iid∼ P and xq, x′q
iid∼ Q. Many kernels,such as the Gaussian RBF, are characteristic [29, 30],which indicates the MMD is a metric, and in particular
that MMDK(P,Q) = 0 if and only if P = Q. GivenXp = {X1
p , ..., Xmp }
iid∼ P and Xq = {X1q , ..., X
mq }
iid∼ Q,one estimator of MMDK(Xp, Xq) is:
ˆMMDK2(Xp, Xq) :=
1
m/2
∑i 6=i′
K(Xip, X
i′
p )
+1
m/2
∑j 6=j′
K(Xjq , X
j′
q )
− 1
m/2
∑i 6=j′
K(Xip, X
jq )
(2)
This estimator is unbiased, and has nearly minimum vari-ance among unbiased estimators [28]. Just take the featurerepresentations φ(xs) and φ(xt) as P and Q, respectively,the kernel based MMD between the features of source-domain and target-domain samples can be calculated ac-cordingly. In our experiments, the mixture of RBF kernelswere chosen for the computation of distribution distancebased MMD.
As Figure 2 shows, the proposed framework minimizesthe distance between different domains, as well as the clas-sification errors among genuine and fake samples. The fea-tures learned should be domain-invariant across domains toachieve good classification results on dataset of either thesource domain or the target domain. If no labeled targetdomain data are available, the objection loss is defined as:
Luns = LC(XS , y) + λMMD2K(XS , XT ) (3)
where XS , XT denotes the source-domain data and target-domain data, respectively, y denotes the labels of source-domain data. LC(XS , y) is the classification loss on thelabeled source-domain data, and MMD2
K(XS , XT ) is thedomain loss between the source data XS and target data

Table 1: The training, testing and development sets contained in databases of Replay-Attack and MSU-MFSD.
Replay-Attack-fixed MSU-MFSDAdverse Controlled
Genuine Attack Genuine Attack Genuine AttackVideo Paper Video Paper Video Paper
Train 30 30*4 30 30 30*4 30 30 30*2 30Test 40 40*4 40 40 40*4 40 20 20*2 20
Devel 30 30*4 30 30 30*4 30 20 20*2 20
XT . The regulation parameter λ determines how stronglywe would like to confuse the domains.
In the situation of face anti-spoofing, spoofing imageswere usually obtained using different types of devices thathave different materials of surfaces, i.e., print photo, elec-tronic screen, forged mask, which we named spoofingmodality in this paper. If sparsely labeled data from thetarget domain is available, we could define the objectionfunction by a intra-modality way. Specifically, the sourcesamples and target samples are divided into several subsetscorresponding to the material of their spoofing surfaces (e.t,print paper, video screen, mask). Then, the MMD is cal-culated between different modalities. Therefore, the semi-supervised objection loss is:
Lsemis = LC(XS , y) + λMMD2K(Xreal
S , XrealT )
+ λ
N∑i=1
MMD2K(Xi
S , XiT )
(4)
where XrealS and Xreal
T represent the real samples from thesource and target domain, respectively, and N is the num-ber of spoofing modalities in the database. This objectivefunction can be optimized by Adam algorithm [31]. TheAdam offers a computationally way for gradient-based op-timization of stochastic objective functions, aiming at to-wards machine learning problems with large datasets and/orhigh-dimensional parameter spaces. It is robust and well-suited to a wide range of non-convex optimization problems[31].
We build the proposed Convnet based on AlexNet [32],which contains five convolutional and max pooling layers,and three fully connected layers. A ”Two-Half” strategyis proposed for the training of the proposed framework.Specifically, in every training batch, one half is the sourcedata and the other half is the target data, as illustrated inFigure 2. Since only a few target samples are available,we randomly picked and copied these target samples to en-sure the two domains have the same number of samples.During the training process, the labeled samples from thesource domain are used to learn discriminative features forthe distinguish of genuine and fake images, while the tar-get samples are used to shrink the domain variance against
the source domain, corresponding to the modalities, respec-tively. Owning to the two terms of joint loss, the pro-posed deep domain adaptation network could learn repre-sentations that are effectively discriminative between gen-uine and fake samples due to the classification loss, whilestill remaining invariant to domain shift due to the domainloss.
4. ExperimentsIn this section, we first give a brief description of two
benchmark datasets, Replay-Attack [3] and MSU-MFSD[11]. After that, we report the performance evaluation ofthe proposed method on the two datasets. We follow theprotocols provided by these two datasets.
4.1. Experimental Settings and Datasets
To avoid any influences from the background, only theface region of each image was cropped based on eye coor-dinates and used as input. The eye coordinates were ob-tained by a facial landmarks detection algorithm availableon the internet. All the input face images were resized to224 × 224, and the regulation parameter λ was set as 0.5.Batch normalization layer was used to overcome internalcovariate shift. The mixture of Gaussian RBF kernels werechosen for the calculation of the domain loss. The mixedkernel function is a sum of Gaussian RBF kernels with fixedbandwidths 2, 5, 10, 20, 40 and 80.
MSU-MFSD: This dataset consists of 280 video record-ings of genuine and attack faces. The recordings were takenfrom 35 individuals using two types of cameras, with differ-ent resolutions (640× 480 and 720× 480). For the real ac-cesses, each subject has two video recordings captured withthe Android and Laptop cameras. For the video attacks,a high definition video was taken for each subject using aCanon camera and a iPhone camera. The videos taken withthe Canon camera were then replayed on iPad Air screen togenerate the HD replay attacks while the videos recordedby the iPhone mobile were replayed itself to generate themobile replay attacks. For the printed attacks, the pictureswere printed on A3 Paper using an HP colour printer. The35 subjects (280 videos) of the MSU-MFSD dataset weredivided into training (120 videos) and testing (160 videos)
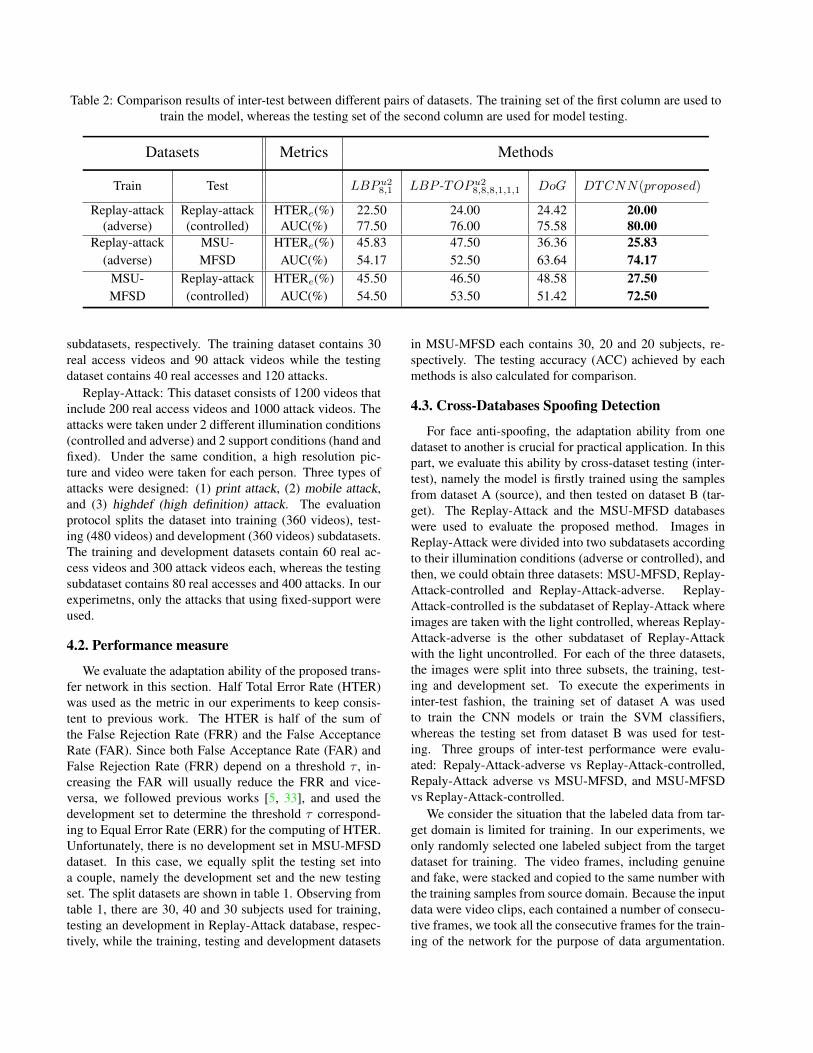
Table 2: Comparison results of inter-test between different pairs of datasets. The training set of the first column are used totrain the model, whereas the testing set of the second column are used for model testing.
Datasets Metrics Methods
Train Test LBPu28,1 LBP -TOPu2
8,8,8,1,1,1 DoG DTCNN(proposed)
Replay-attack Replay-attack HTERe(%) 22.50 24.00 24.42 20.00(adverse) (controlled) AUC(%) 77.50 76.00 75.58 80.00
Replay-attack MSU- HTERe(%) 45.83 47.50 36.36 25.83(adverse) MFSD AUC(%) 54.17 52.50 63.64 74.17
MSU- Replay-attack HTERe(%) 45.50 46.50 48.58 27.50MFSD (controlled) AUC(%) 54.50 53.50 51.42 72.50
subdatasets, respectively. The training dataset contains 30real access videos and 90 attack videos while the testingdataset contains 40 real accesses and 120 attacks.
Replay-Attack: This dataset consists of 1200 videos thatinclude 200 real access videos and 1000 attack videos. Theattacks were taken under 2 different illumination conditions(controlled and adverse) and 2 support conditions (hand andfixed). Under the same condition, a high resolution pic-ture and video were taken for each person. Three types ofattacks were designed: (1) print attack, (2) mobile attack,and (3) highdef (high definition) attack. The evaluationprotocol splits the dataset into training (360 videos), test-ing (480 videos) and development (360 videos) subdatasets.The training and development datasets contain 60 real ac-cess videos and 300 attack videos each, whereas the testingsubdataset contains 80 real accesses and 400 attacks. In ourexperimetns, only the attacks that using fixed-support wereused.
4.2. Performance measure
We evaluate the adaptation ability of the proposed trans-fer network in this section. Half Total Error Rate (HTER)was used as the metric in our experiments to keep consis-tent to previous work. The HTER is half of the sum ofthe False Rejection Rate (FRR) and the False AcceptanceRate (FAR). Since both False Acceptance Rate (FAR) andFalse Rejection Rate (FRR) depend on a threshold τ , in-creasing the FAR will usually reduce the FRR and vice-versa, we followed previous works [5, 33], and used thedevelopment set to determine the threshold τ correspond-ing to Equal Error Rate (ERR) for the computing of HTER.Unfortunately, there is no development set in MSU-MFSDdataset. In this case, we equally split the testing set intoa couple, namely the development set and the new testingset. The split datasets are shown in table 1. Observing fromtable 1, there are 30, 40 and 30 subjects used for training,testing an development in Replay-Attack database, respec-tively, while the training, testing and development datasets
in MSU-MFSD each contains 30, 20 and 20 subjects, re-spectively. The testing accuracy (ACC) achieved by eachmethods is also calculated for comparison.
4.3. Cross-Databases Spoofing Detection
For face anti-spoofing, the adaptation ability from onedataset to another is crucial for practical application. In thispart, we evaluate this ability by cross-dataset testing (inter-test), namely the model is firstly trained using the samplesfrom dataset A (source), and then tested on dataset B (tar-get). The Replay-Attack and the MSU-MFSD databaseswere used to evaluate the proposed method. Images inReplay-Attack were divided into two subdatasets accordingto their illumination conditions (adverse or controlled), andthen, we could obtain three datasets: MSU-MFSD, Replay-Attack-controlled and Replay-Attack-adverse. Replay-Attack-controlled is the subdataset of Replay-Attack whereimages are taken with the light controlled, whereas Replay-Attack-adverse is the other subdataset of Replay-Attackwith the light uncontrolled. For each of the three datasets,the images were split into three subsets, the training, test-ing and development set. To execute the experiments ininter-test fashion, the training set of dataset A was usedto train the CNN models or train the SVM classifiers,whereas the testing set from dataset B was used for test-ing. Three groups of inter-test performance were evalu-ated: Repaly-Attack-adverse vs Replay-Attack-controlled,Repaly-Attack adverse vs MSU-MFSD, and MSU-MFSDvs Replay-Attack-controlled.
We consider the situation that the labeled data from tar-get domain is limited for training. In our experiments, weonly randomly selected one labeled subject from the targetdataset for training. The video frames, including genuineand fake, were stacked and copied to the same number withthe training samples from source domain. Because the inputdata were video clips, each contained a number of consecu-tive frames, we took all the consecutive frames for the train-ing of the network for the purpose of data argumentation.

However, in the testing phase, the output probabilities of theconsecutive frames with respect to the same subject wereaveraged to determine the categorization of each video clip.Three popular methods, LBPu2
8,1 [3], LBP -TOPu28,8,8,1,1,1,
[4] and DoG [10], were implemented to compare with theproposed method. The features captured by the three meth-ods are all fed into SVM to obtain the final classificationresults. For the LBP method, all the consecutive framesof each video clip of the training set were used to extractthe 59-dimensional holistic features, and to train the SVMclassifier. The final results were achieved on the test set byaveraging the probabilities of all the consecutive frames pervideo clip. The features of LBP-TOP were extracted pervideo clip, as this method involved the spatio-temporal in-formation from video sequences. For the Dog operator, 30frames of each video clip were randomly selected to trainthe SVM classifier to avoid high dimensionality of the DoGfeatures, followed by the procedures of the original liter-ature [10]. The standard CNN (stdCNN) was also imple-mented to compared with the three methods, the stdCNNhas the same architecture with the proposed framework onlywithout the domain loss layer.
The inter-test results regarding these methods are firstsummarized in table 2 to evaluate their generalization abil-ity on the three datasets. For Replay-Attack-adverse andReplay-Attack-controlled datasets, only the illuminationcondition is different, other factors like individuals andspoofing materials are keep unchanged, therefore the do-main shift is not serious between these two datasets. Thisis the reason why all the four approaches achieved the bestperformance by testing across these two datasets. However,the MSU-MSFD database is totally different from Replay-Attack database, where the individuals, spoofing materialsand illumination conditions are all different. As a result,the domain shift between these two databases are quite seri-ous. The performances achieved by the four approaches arerelatively lower across there two databases.
4.4. Intra-test vs. Inter test
To illustrate the effectiveness of the proposed method,we compared the intra-test performance with inter-test per-formance regarding the same method, LBP, LBP-TOP, DoGand stdCNN. Suppose we evaluate the performance acrossdataset A and dataset B, then the intra-test was executed byusing the training and testing set from A for the training andtesting of the model. However, for the inter-test procedure,we used the training set from A and the testing set from Bto train and test the model, respectively.
Figure 3 reports the accuracy of intra-test and inter-testby LBP, LBP-TOP, DoG, stdCNN and the proposed method(DTCNN), respectively. As can be seen, all of the meth-ods obtained satisfying performance in the fashion of intra-test, the CNN even achieved nearly perfect performance
(99.68%) on Replay-Attack database. However, when intra-test on MSU-MFSD, we observed the training accuracy isnearly 100%, while the testing accuracy degraded signifi-cantly to 87.62%. The main reason for such a performancedecline is over-fitting due to short of training samples.
The best inter-test performances were still achievedwhen testing across Replay-Attack-adverse and Replay-Attack-controlled (Adver vs. Contrl). Compared with theresults of intra-test, there was a significant degeneration ofthe performance of inter-test by the standard CNN (blue vs.green bar graph in Figure 3(d)). The declined accuracy evenreached up to 49.52% when testing across Replay-Attack-adverse and MSU-MFSD (Adver vs. MFSD). However,when using the proposed method (DTCNN) for inter-test(blue vs. yellow bar graph in Figure 3(d)), there was a con-siderably boost of the performance compared with the stan-dard CNN. The improved accuracy are 12.51%, 24.87% and14.1% for Adver vs. Contrl, Adver vs. MFSD and MFSDvs. Contrl, respectively.
Overall, the results of LBP, LBP-TOP, DoG and thestandard CNN show that they are not able to well handlethe cross-database challenge. This is because LBP, LBP-TOP and DoG are hand-crafted features which are designedspecifically and can not be easily transferred to new condi-tion. For the standard CNNs, the features learned are spe-cific to the training dataset provided, it may achieve superbperformance on the data from the training domain, however,the performance may degrade considerably if testing on atotal different dataset. Different from the standard CNNs,the proposed method can make use of the domain informa-tion from the target dataset, bridging the gap between thefeature distributions and hence obtaining satisfying perfor-mance on the target set, only with a very few labeled sam-ples provided from the target domain.
5. Summary and ConclusionCross-database face anti-spoofing replicates real appli-
cation scenarios, and is a challenge for biometrics anti-spoofing. Although many of the existing methods pro-posed can achieve excellent performance in the way of non-realistic intra-database testing, few of them can achievecomparable performance on the dataset of other domain. Tobridge the gap between the datasets from different domains,we proposed a CNN framework that effectively adapts toa new domain with sparsely labeled target domain data forface anti-spoofing. The proposed network can learn a in-variant feature space for the source and target samples byoptimizing an objective that simultaneously minimizes clas-sification loss and the domain loss. As a result, the modeltrained with the labeled source data can also achieve satis-factory performance on the target dataset. Experiments onthe datasets of Replay-Attack and MSU-MFSD showed theproposed framework greatly enhance the performance by

Figure 3: The accuracy of intra- and inter test achieved by LBP (a), LBP-TOP (b), DoG (c) and stdCNN vs. DTCNN (d),where stdCNN stands for the standard CNN, and DTCNN represents for the domain transferred CNN.
cross-dataset testing, with only a few labeled samples fromthe target domain. The proposed method could open newperspectives for the future research of face anti-spoofing.
References
[1] G. Pan, L. Sun, Z. Wu, S. Lao, Eyeblink-based anti-spoofingin face recognition from a generic webcamera, in: ComputerVision, 2007. ICCV 2007. IEEE 11th International Confer-ence on, IEEE, 2007, pp. 1–8. 1
[2] X. Tan, Y. Li, J. Liu, L. Jiang, Face liveness detection froma single image with sparse low rank bilinear discriminativemodel, Computer Vision–ECCV 2010 (2010) 504–517. 1, 2
[3] I. Chingovska, A. Anjos, S. Marcel, On the effectiveness oflocal binary patterns in face anti-spoofing, in: BiometricsSpecial Interest Group, 2012, pp. 1–7. 1, 2, 4, 6
[4] T. D. F. Pereira, A. Anjos, J. M. D. Martino, S. Marcel,Lbp-top based countermeasure against face spoofing attacks,in: International Conference on Computer Vision, 2012, pp.121–132. 1, 2, 6
[5] J. Yang, Z. Lei, S. Z. Li, Learn convolutional neural networkfor face anti-spoofing, Computer Science 9218 (2014) 373–384. 1, 2, 5
[6] A. Pinto, W. R. Schwartz, H. Pedrini, A. D. R. Rocha, Us-ing visual rhythms for detecting video-based facial spoof at-tacks, IEEE Transactions on Information Forensics and Se-curity 10 (5) (2015) 1025–1038. 1

[7] L. Li, X. Feng, Z. Boulkenafet, Z. Xia, M. Li, A. Hadid,An original face anti-spoofing approach using partial convo-lutional neural network, in: Image Processing Theory Toolsand Applications (IPTA), 2016 6th International Conferenceon, IEEE, 2016, pp. 1–6. 1
[8] J. Komulainen, A. Hadid, M. Pietikainen, Context based faceanti-spoofing, in: Biometrics: Theory, Applications and Sys-tems (BTAS), 2013 IEEE Sixth International Conference on,IEEE, 2013, pp. 1–8. 1
[9] E. Tzeng, J. Hoffman, T. Darrell, K. Saenko, Simultane-ous deep transfer across domains and tasks, in: Proceedingsof the IEEE International Conference on Computer Vision,2015, pp. 4068–4076. 1
[10] Z. Zhang, J. Yan, S. Liu, Z. Lei, A face antispoofing databasewith diverse attacks, in: Iapr International Conference onBiometrics, 2012, pp. 26–31. 1, 6
[11] D. Wen, H. Han, A. Jain, Face Spoof Detection with ImageDistortion Analysis, IEEE Trans. Information Forensic andSecurity 10 (4) (2015) 746–761. 1, 4
[12] J. Li, Y. Wang, T. Tan, A. K. Jain, Live face detection basedon the analysis of fourier spectra, in: Defense and Secu-rity, International Society for Optics and Photonics, 2004,pp. 296–303. 2
[13] J. Maatta, A. Hadid, M. Pietikainen, Face spoofing detectionfrom single images using micro-texture analysis, in: Biomet-rics (IJCB), 2011 international joint conference on, IEEE,2011, pp. 1–7. 2
[14] Y. Bengio, A. Courville, P. Vincent, Representation learning:A review and new perspectives, IEEE transactions on patternanalysis and machine intelligence 35 (8) (2013) 1798–1828.2
[15] A. Alotaibi, A. Mahmood, Deep face liveness detectionbased on nonlinear diffusion using convolution neural net-work, Signal, Image and Video Processing 4 (11) (2016)713–720. 2
[16] K. Patel, H. Han, A. K. Jain, Cross-database face antispoof-ing with robust feature representation., in: CCBR, 2016, pp.611–619. 2
[17] E. Valle, R. Lotufo, Transfer learning using convolutionalneural networks for face anti-spoofing, in: Image Analy-sis and Recognition: 14th International Conference, ICIAR2017, Montreal, QC, Canada, July 5–7, 2017, Proceedings,Vol. 10317, Springer, 2017, p. 27. 2
[18] R. Gopalan, R. Li, R. Chellappa, Domain adaptation forobject recognition: An unsupervised approach, in: Com-puter Vision (ICCV), 2011 IEEE International Conferenceon, IEEE, 2011, pp. 999–1006. 2
[19] B. Fernando, A. Habrard, M. Sebban, T. Tuytelaars, Un-supervised visual domain adaptation using subspace align-ment, in: Proceedings of the IEEE international conferenceon computer vision, 2013, pp. 2960–2967. 2
[20] E. Tzeng, J. Hoffman, N. Zhang, K. Saenko, T. Darrell, Deepdomain confusion: Maximizing for domain invariance, arXivpreprint arXiv:1412.3474. 2
[21] Y. Ganin, E. Ustinova, H. Ajakan, P. Germain, H. Larochelle,F. Laviolette, M. Marchand, V. Lempitsky, Domain-adversarial training of neural networks, Journal of MachineLearning Research 17 (59) (2016) 1–35. 2
[22] J. Ngiam, A. Khosla, M. Kim, J. Nam, H. Lee, A. Y. Ng,Multimodal deep learning, in: Proceedings of the 28th inter-national conference on machine learning (ICML-11), 2011,pp. 689–696. 2
[23] M. Ghifary, W. B. Kleijn, M. Zhang, Domain adap-tive neural networks for object recognition, arXiv preprintarXiv:1409.6041. 2
[24] Q. Chen, J. Huang, R. Feris, L. M. Brown, J. Dong, S. Yan,Deep domain adaptation for describing people based on fine-grained clothing attributes, in: Proceedings of the IEEE con-ference on computer vision and pattern recognition, 2015,pp. 5315–5324. 2
[25] D. Comaniciu, V. Ramesh, P. Meer, Kernel-based objecttracking, IEEE Transactions on pattern analysis and machineintelligence 25 (5) (2003) 564–577. 3
[26] F. Xiong, M. Gou, O. Camps, M. Sznaier, Person re-identification using kernel-based metric learning methods,in: European conference on computer vision, Springer, 2014,pp. 1–16. 3
[27] D. J. Sutherland, H.-Y. Tung, H. Strathmann, S. De, A. Ram-das, A. Smola, A. Gretton, Generative models and modelcriticism via optimized maximum mean discrepancy, arXivpreprint arXiv:1611.04488. 3
[28] A. Gretton, K. M. Borgwardt, M. J. Rasch, B. Scholkopf,A. Smola, A kernel two-sample test, Journal of MachineLearning Research 13 (Mar) (2012) 723–773. 3
[29] K. Fukumizu, A. Gretton, X. Sun, B. Scholkopf, Kernel mea-sures of conditional dependence, in: Advances in neural in-formation processing systems, 2008, pp. 489–496. 3
[30] B. K. Sriperumbudur, A. Gretton, K. Fukumizu,B. Scholkopf, G. R. Lanckriet, Hilbert space embed-dings and metrics on probability measures, Journal ofMachine Learning Research 11 (Apr) (2010) 1517–1561. 3
[31] D. Kingma, J. Ba, Adam: A method for stochastic optimiza-tion, arXiv preprint arXiv:1412.6980. 4
[32] A. Krizhevsky, I. Sutskever, G. E. Hinton, Imagenet clas-sification with deep convolutional neural networks, in: Ad-vances in neural information processing systems, 2012, pp.1097–1105. 4
[33] Z. Xu, S. Li, W. Deng, Learning temporal features us-ing lstm-cnn architecture for face anti-spoofing, in: PatternRecognition (ACPR), 2015 3rd IAPR Asian Conference on,IEEE, 2015, pp. 141–145. 5
![Local Remote Photoplethysmography Signal Analysis · a face, it is possible to detect whether the whole face is covered or not. In [LKZ 17], a robust anti-spoofing method is proposed](https://img.pdfslide.us/doc/110x75/601f3f02b968fa49e800e345/local-remote-photoplethysmography-signal-analysis-a-face-it-is-possible-to-detect.jpg)



![Abstract arXiv:2006.16028v1 [cs.CV] 29 Jun 2020 · 2020. 6. 30. · VisionLabs o.grinchuk@visionlabs.ai Abstract Special cameras that provide useful features for face anti-spoofing](https://img.pdfslide.us/doc/110x75/6053d3faa9969a508560e03c/abstract-arxiv200616028v1-cscv-29-jun-2020-2020-6-30-visionlabs-ogrinchukvisionlabsai.jpg)


![Spoofing Faces Using Makeup: An Investigative Studyantitza.com/ChenFaceMakeupSpoof_ISBA2017.pdf · videos [1, 19, 21] or 2D and 3D-masks to a face recogni-tion system [13] (as seen](https://img.pdfslide.us/doc/110x75/5f6d5e299de4eb3c2f3d4f1b/spooing-faces-using-makeup-an-investigative-videos-1-19-21-or-2d-and-3d-masks.jpg)






![arXiv:1410.1980v3 [cs.CV] 29 Jan 2015 · In this section, we review anti-spoofing related work for iris, face, and fingerprints, our focus in this paper. A. Iris Spoofing Daugman](https://img.pdfslide.us/doc/110x75/603d48f6dc696c0c5155a636/arxiv14101980v3-cscv-29-jan-2015-in-this-section-we-review-anti-spooing.jpg)









![TABULA RASA Trusted Biometrics under Spoofing AttacksTABULA RASA [257289] D2.2: Specifications of Biometric Databases and Systems 2 2D face biometrics Face recognition is a preferred](https://img.pdfslide.us/doc/110x75/60dee65c26f12d0fac6f5557/tabula-rasa-trusted-biometrics-under-spooing-tabula-rasa-257289-d22-speciications.jpg)
![Can Your Face Detector Do Anti-spoofing? Face Presentation ...due to the vulnerability against presentation attacks (a.k.a spoofing attacks) [2], [3]. Presenting artifacts like a](https://img.pdfslide.us/doc/110x75/6005c09e2597ff5cbd58f009/can-your-face-detector-do-anti-spooing-face-presentation-due-to-the-vulnerability.jpg)



![arXiv:1410.1980v3 [cs.CV] 29 Jan 20151410.1980v3 [cs.CV] 29 Jan 2015. 2 Deep Representations for Iris, Face, and Fingerprint Spoofing Detection](https://img.pdfslide.us/doc/110x75/5b39c2087f8b9a1a678cd1e6/arxiv14101980v3-cscv-29-jan-2015-14101980v3-cscv-29-jan-2015-2-deep-representations.jpg)