Embed Size (px)
Citation preview

WhatisDeepLearning?
• Deeplearningisasubfieldofmachinelearning– BuildsonRepresenta7onLearningtoautoma7callylearngoodfeatures/representa7ons
– DeepLearningalgorithmlearnsmul7plelevelsoffeaturerepresenta7onsinincreasinglevelsofcomplexityorabstrac7on
• Deeplearningcan– Notonlyautoma7callylearngoodfeatures– Butdosobyusingvastamountsofunlabeleddata
Overviewmaterialadaptedfrom:RS-RichardSocher,StanfordCourseNotes,DeepLearningforNLP,2016andMS-ManningandSocher,tutorialnotesonDeepLearning,NAACL2013. 2

CurrentMachineLearning
• Mostcurrentmachinelearningworkswellbecausehumansdesigngoodinputfeatures– Example:featuresforfindingnameden77esororganiza7onnames(Finkel,2010)
• Machinelearningsolvesanop7miza7onproblemthatlearnsweightsforthefeaturesfromlabeleddata,inordertomakegoodpredic7onsonnewdata
DiagramRS 3
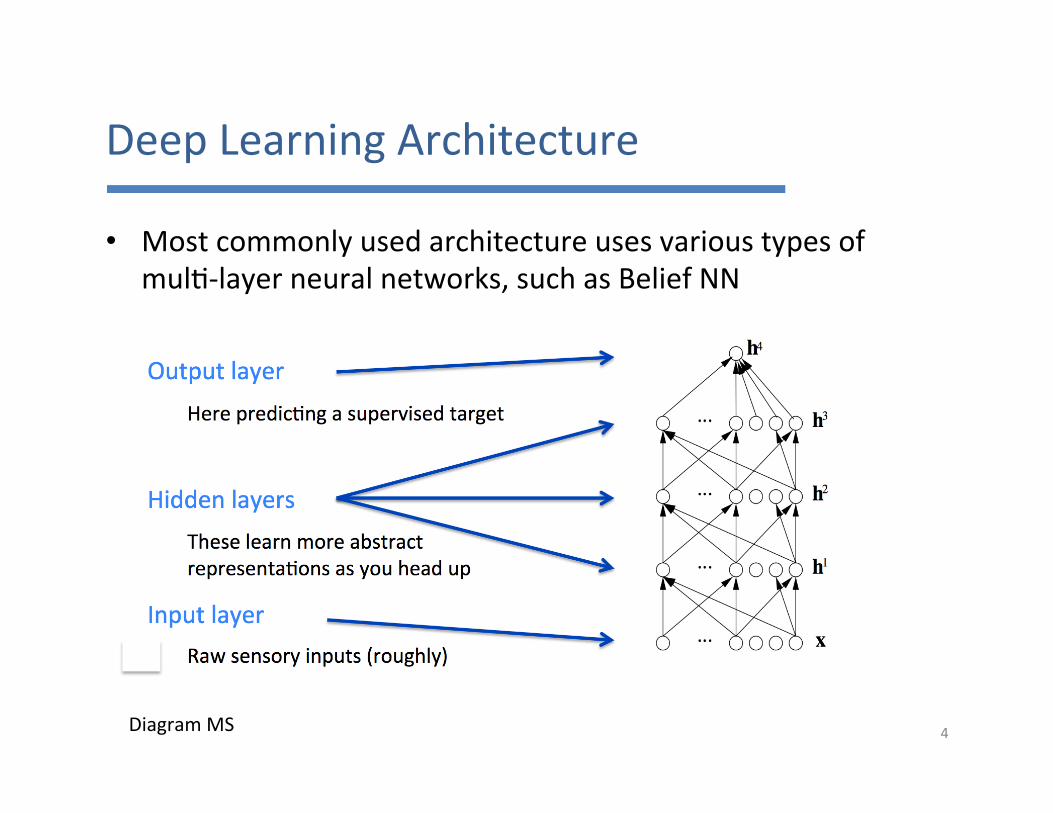
DeepLearningArchitecture
• Mostcommonlyusedarchitectureusesvarioustypesofmul7-layerneuralnetworks,suchasBeliefNN
DiagramMS 4
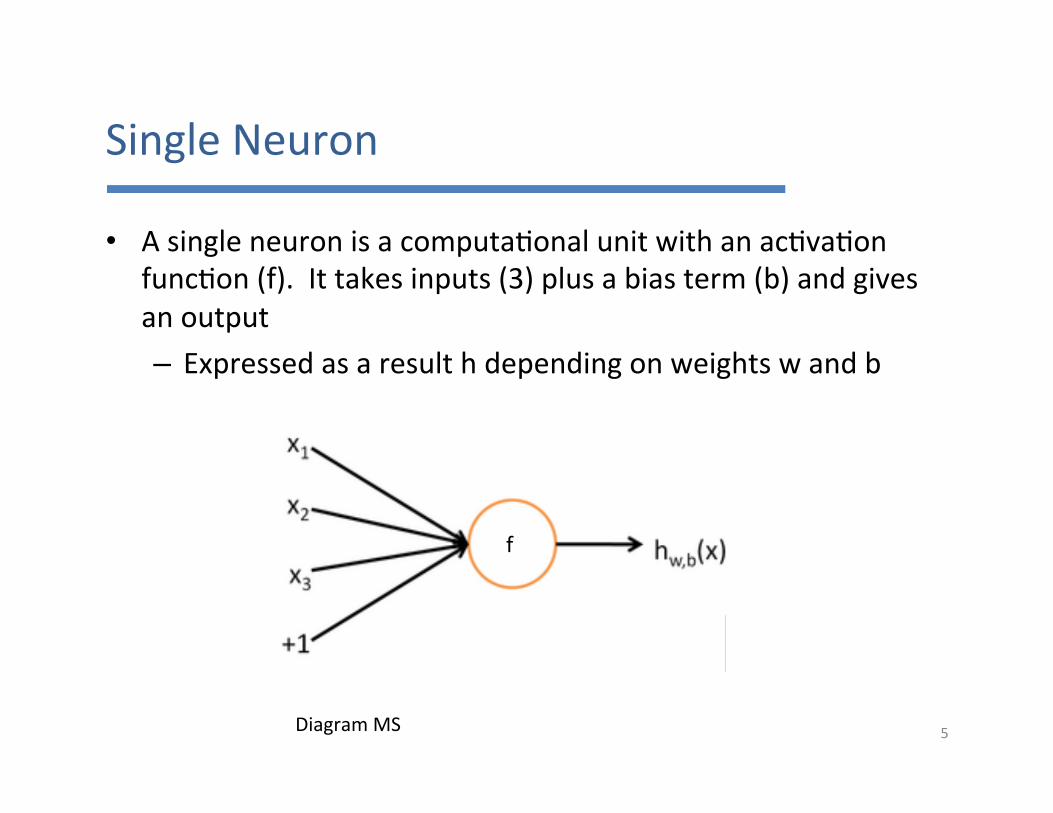
SingleNeuron
• Asingleneuronisacomputa7onalunitwithanac7va7onfunc7on(f).Ittakesinputs(3)plusabiasterm(b)andgivesanoutput– Expressedasaresulthdependingonweightswandb
f
DiagramMS 5
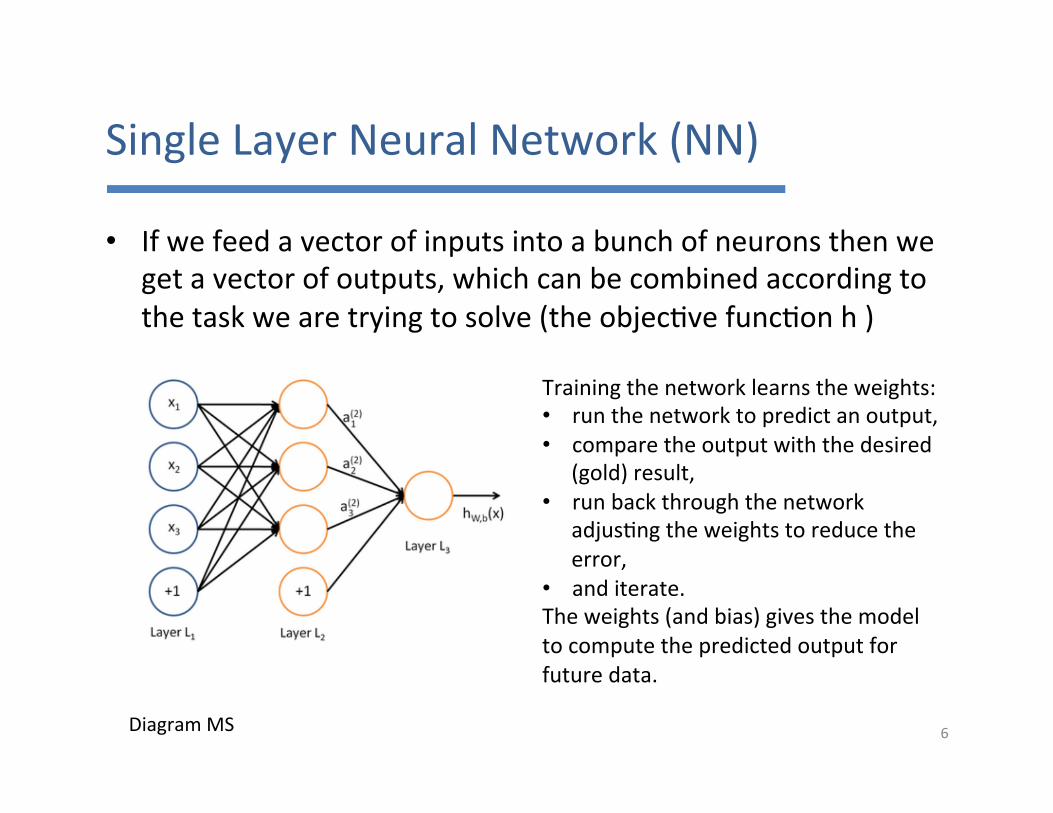
SingleLayerNeuralNetwork(NN)
• Ifwefeedavectorofinputsintoabunchofneuronsthenwegetavectorofoutputs,whichcanbecombinedaccordingtothetaskwearetryingtosolve(theobjec7vefunc7onh)
Trainingthenetworklearnstheweights:• runthenetworktopredictanoutput,• comparetheoutputwiththedesired
(gold)result,• runbackthroughthenetwork
adjus7ngtheweightstoreducetheerror,
• anditerate.Theweights(andbias)givesthemodeltocomputethepredictedoutputforfuturedata.
DiagramMS 6
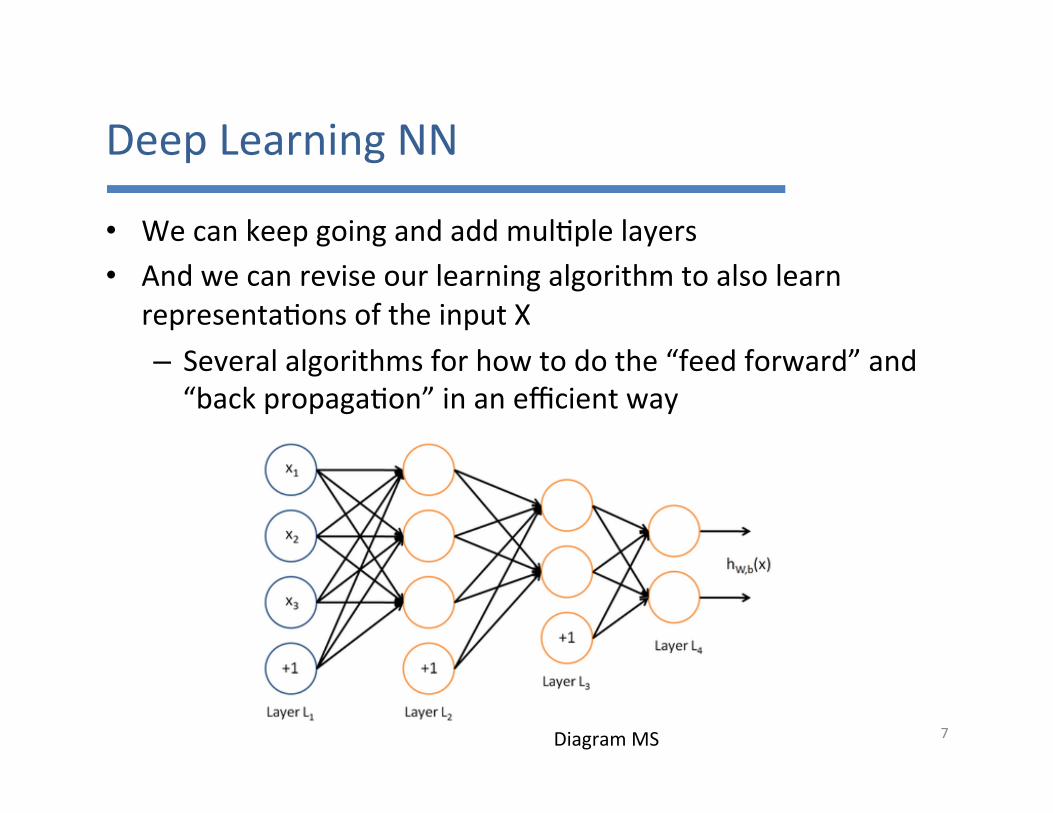
DeepLearningNN
• Wecankeepgoingandaddmul7plelayers• Andwecanreviseourlearningalgorithmtoalsolearn
representa7onsoftheinputX– Severalalgorithmsforhowtodothe“feedforward”and“backpropaga7on”inanefficientway
DiagramMS 7

ReasonsforDeepLearning
• Breakthebocleneckofmanuallydesignedfeaturestoautoma7callylearnthem– Easytoadaptandtouse
• Canuselargeamountsofunsuperviseddata(e.g.rawtext)tolearnfeaturesandthenusesuperviseddata(withlabels,likeposi7veandnega7ve)tolearnatask
• Deeplearningideashavebeenknownbutonlyrecentlyoutperformingothertechniques– Benefitfromlotsofdata– Mul7-coremachineswithfasterprocessors– Newmodelsandalgorithms
8

DeepLearningforSpeech
• Thefirstbreakthroughresultsofdeeplearningonlargedatasetshappenedinspeechrecogni7on
• Context-dependentPre-trainedDeepNeuralNetworksforLargeVocabularySpeechRecogni7on(Dahletal2010)
DiagramRS9
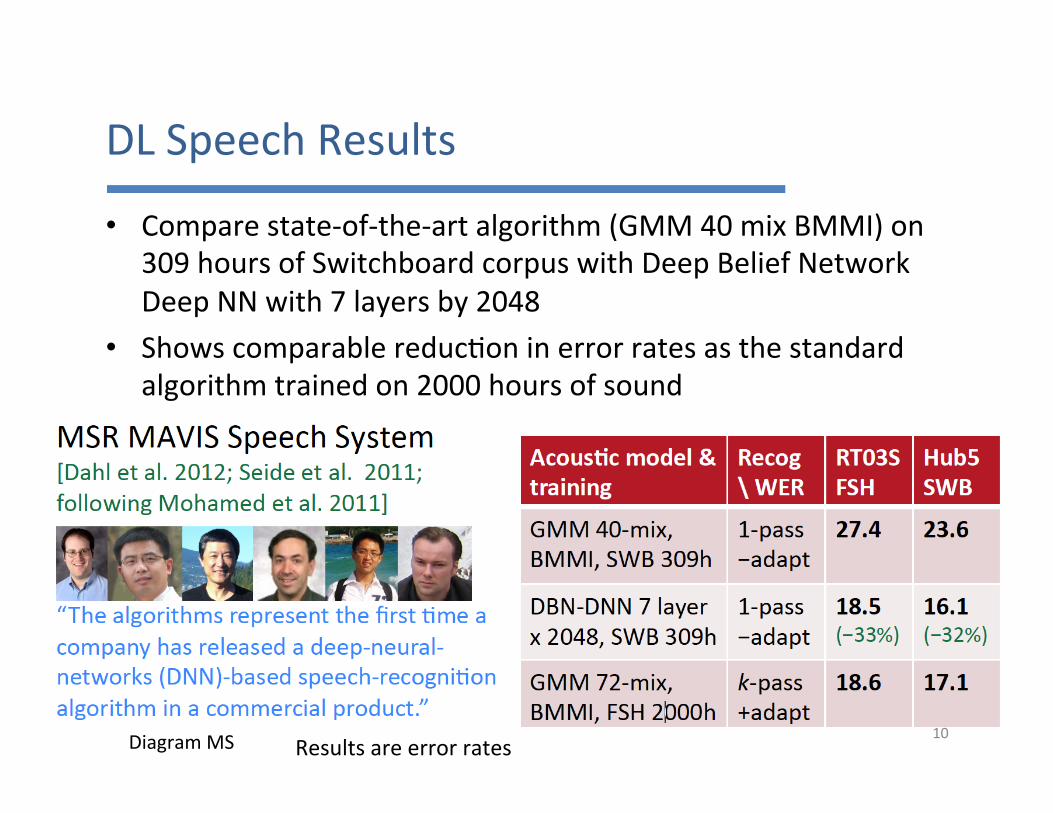
DLSpeechResults
• Comparestate-of-the-artalgorithm(GMM40mixBMMI)on309hoursofSwitchboardcorpuswithDeepBeliefNetworkDeepNNwith7layersby2048
• Showscomparablereduc7oninerrorratesasthestandardalgorithmtrainedon2000hoursofsound
DiagramMS 10Resultsareerrorrates
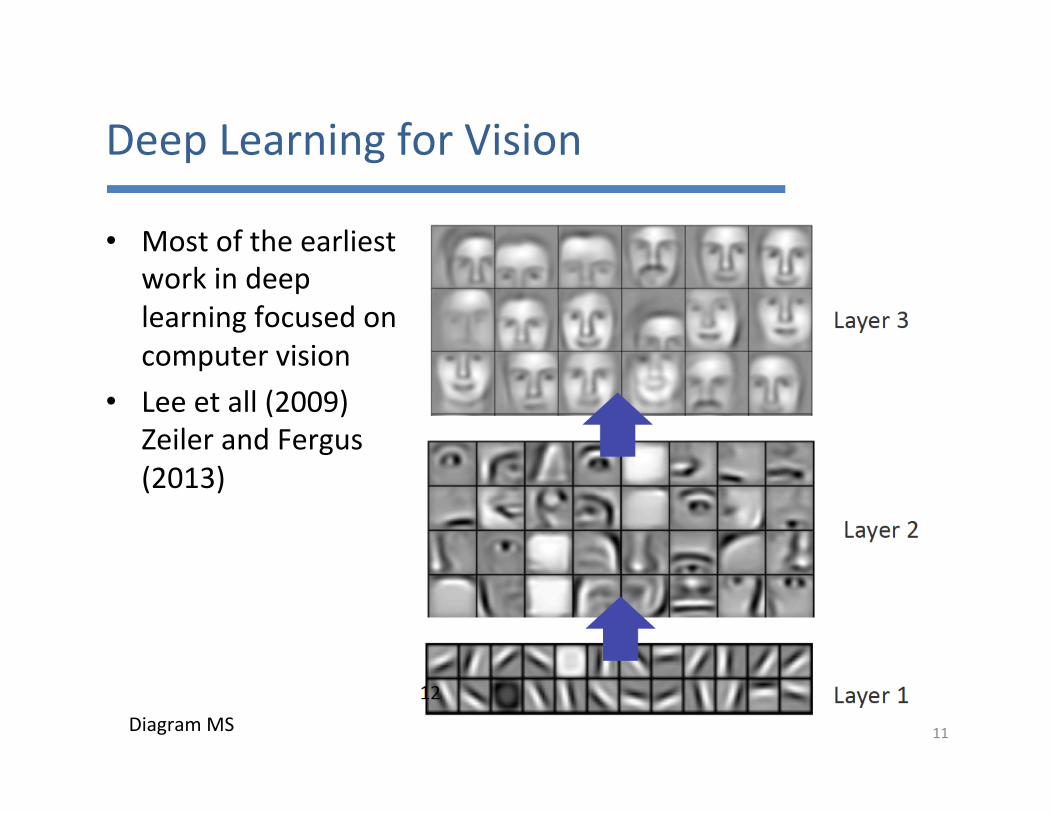
DeepLearningforVision
• Mostoftheearliestworkindeeplearningfocusedoncomputervision
• Leeetall(2009)ZeilerandFergus(2013)
DiagramMS 11

DLVisionResults
• Breakthroughpaper:ImageNetClassifica7onwithDeepConvolu7onalNeuralNetworksbyKrizhevskyetal2012
12
Resultsareerrorrates

NLPWordRepresenta7ons
• Distribu7onalsimilaritybasedrepresenta7ons– Represen7ngawordbymeansofitsneighbors
• “Youshallknowawordbythecompanyitkeeps.”(J.R.Firth1957)• Orlinguis7citemswithsimilardistribu7onshavesimilarmeanings
• Oneofthemostsuccessfulideasofmodernsta7s7calNLP
DiagramMS 13

NNDenseWordVectors
• Combinevectorspaceseman7cswithprobabilis7cmodelstopredictvectorsofcontextwords– (Bengioetal2003,Collobert&
Weston2008,Turianetal2010)
• Awordisrepresentedasadensevector
• Olderrelatedideasare– SVDonterm-contextmatrix– Brownclusters
DiagramMS
14

NNLearningDenseWordVectors
• Setupaclassifica7ontaskfromunsuperviseddatawherewehaveposi7vetrainingexamplesdirectlyfromthedata,andnega7veexamplesobtainedbysubs7tu7ngarandomwordinthecontext(asdescribedinCollobertetalJMLR2011)
– Posi7veexample:“catsitsonthemat”
– Nega7veexample:“catsitsjejuthemat”
• Classifywhichcontextsarenoise
DiagramTensorFlowtutorial 15

Word2Vec
• Thewordvectorclassifiergivesasimplerandfasterimplementa7onofa(shallow)RNN,(Mikolov2013)with2algorithms– CBOW(con7nuousbagofwords)predictsthecurrentwordw,giventheneighboringwordsinthewindow
– SkipGrampredictstheneighboringwords,givenw• AllowstheNNtobeappliedtolargeamountsofdata• Hyperparameters– Windowsize–thenumberofcontextwords– Networksize–thenumberofneuronsinthehiddenlayer– Otherparameterssuchasnega7vesubsamplingnumber
16

DenseWordVectorSpace
• Intheresul7ngspace,similarwordsshouldbeclosertogether– Syntac7csimilari7es,suchaswordtenseorplurals– Seman7csimilari7es
Length1000vectorsprojectedto2D,diagramfromMikolovetal2013(NIPS) 17
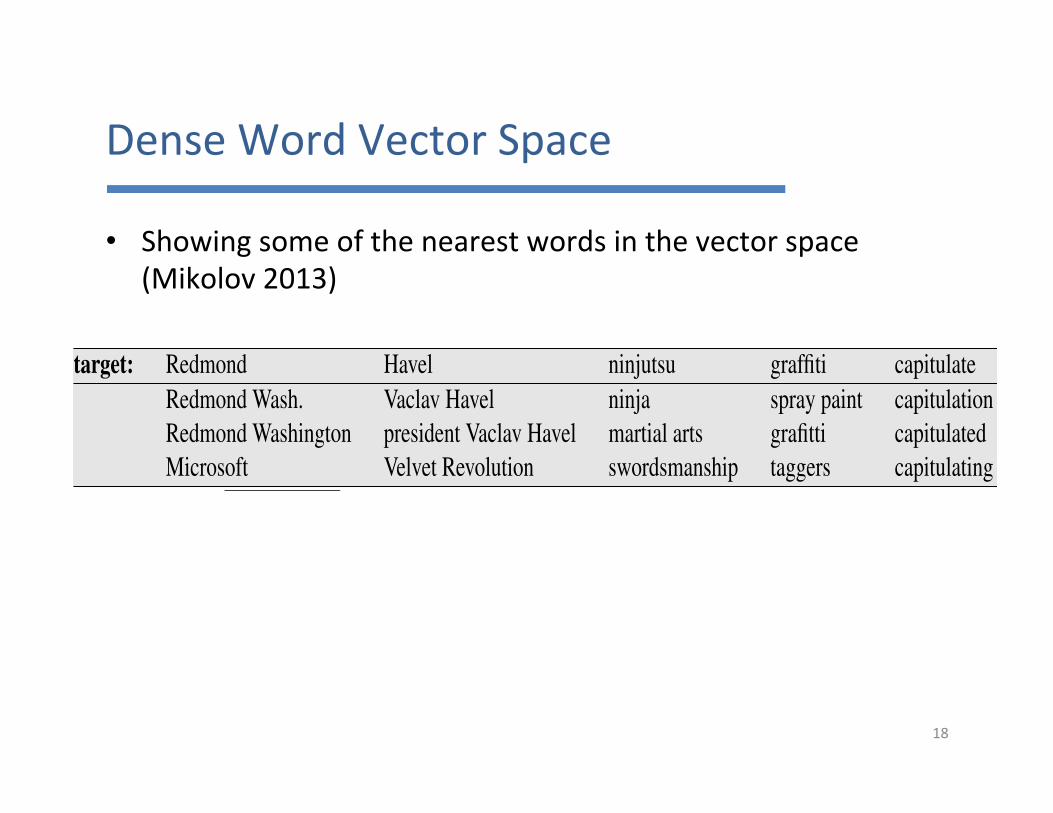
DenseWordVectorSpace
• Showingsomeofthenearestwordsinthevectorspace(Mikolov2013)
18
18 CHAPTER 19 • VECTOR SEMANTICS
matrix is repeated between each one-hot input and the projection layer h. For thecase of C = 1, these two embeddings must be combined into the projection layer,which is done by multiplying each one-hot context vector x by W to give us twoinput vectors (let’s say vi and v j). We then average these vectors
h = W · 12C
X
�c jc, j 6=0
v( j) (19.31)
As with skip-grams, the the projection vector h is multiplied by the output matrixW 0. The result o = W 0h is a 1⇥ |V | dimensional output vector giving a score foreach of the |V | words. In doing so, the element ok was computed by multiplyingh by the output embedding for word wk: ok = v0kh. Finally we normalize this scorevector, turning the score for each element ok into a probability by using the soft-maxfunction.
19.5 Properties of embeddings
We’ll discuss in Section 17.8 how to evaluate the quality of different embeddings.But it is also sometimes helpful to visualize them. Fig. 17.14 shows the words/phrasesthat are most similar to some sample words using the phrase-based version of theskip-gram algorithm (Mikolov et al., 2013a).
target: Redmond Havel ninjutsu graffiti capitulateRedmond Wash. Vaclav Havel ninja spray paint capitulationRedmond Washington president Vaclav Havel martial arts grafitti capitulatedMicrosoft Velvet Revolution swordsmanship taggers capitulating
Figure 19.14 Examples of the closest tokens to some target words using a phrase-basedextension of the skip-gram algorithm (Mikolov et al., 2013a).
One semantic property of various kinds of embeddings that may play in theirusefulness is their ability to capture relational meanings
Mikolov et al. (2013b) demonstrates that the offsets between vector embeddingscan capture some relations between words, for example that the result of the ex-pression vector(‘king’) - vector(‘man’) + vector(‘woman’) is a vector close to vec-tor(‘queen’); the left panel in Fig. 17.15 visualizes this by projecting a representationdown into 2 dimensions. Similarly, they found that the expression vector(‘Paris’)- vector(‘France’) + vector(‘Italy’) results in a vector that is very close to vec-tor(‘Rome’). Levy and Goldberg (2014a) shows that various other kinds of em-beddings also seem to have this property. We return in the next section to theserelational properties of embeddings and how they relate to meaning compositional-ity: the way the meaning of a phrase is built up out of the meaning of the individualvectors.
19.6 Compositionality in Vector Models of Meaning
To be written.

AnalogiesTask
• Howcanweevaluatewhetherthedensewordvectorsrepresentgoodwordsimilari7es?
• Solveproblemsofthetype:– “aistobascisto__”
• Mikolovetal(HLT2013)constructedatestsetof8ksyntac7crela7ons– Nounpluralsandpossessives,verbtenses,adjec7valcompari7vesandsuperla7ves
• Seman7ctestsetfromSemeval-2012Task2
19

WordRela7onships
• Mikolov’sresultsarethatanalogiestes7ngdimensionsofsimilaritycandoquitewelljustbydoingvectorsubtrac7ons– Syntac7cally–plurals,verbtenses,adjec7veforms
– Seman7cally(analogiesfromSemeval2012task2)
DiagramRS 20

WordAnalogies
• ResultsfromMikolovetal2013(HLT)usingword2vec– Trainedon320Mwordsofbroadcastnewsdata– With82kwordvocabulary
DiagramMS 21

NLPWordLevelClassifiers
• Similartowordvectorlearning,butreplacessinglevectoroutputwithaclassifierlayerforthetask,S
• Diagramissimilartoaconven7onalclassifier,exceptthatitincludeslearningfortheinputvectorsfromunsuperviseddata
DiagramMS 22
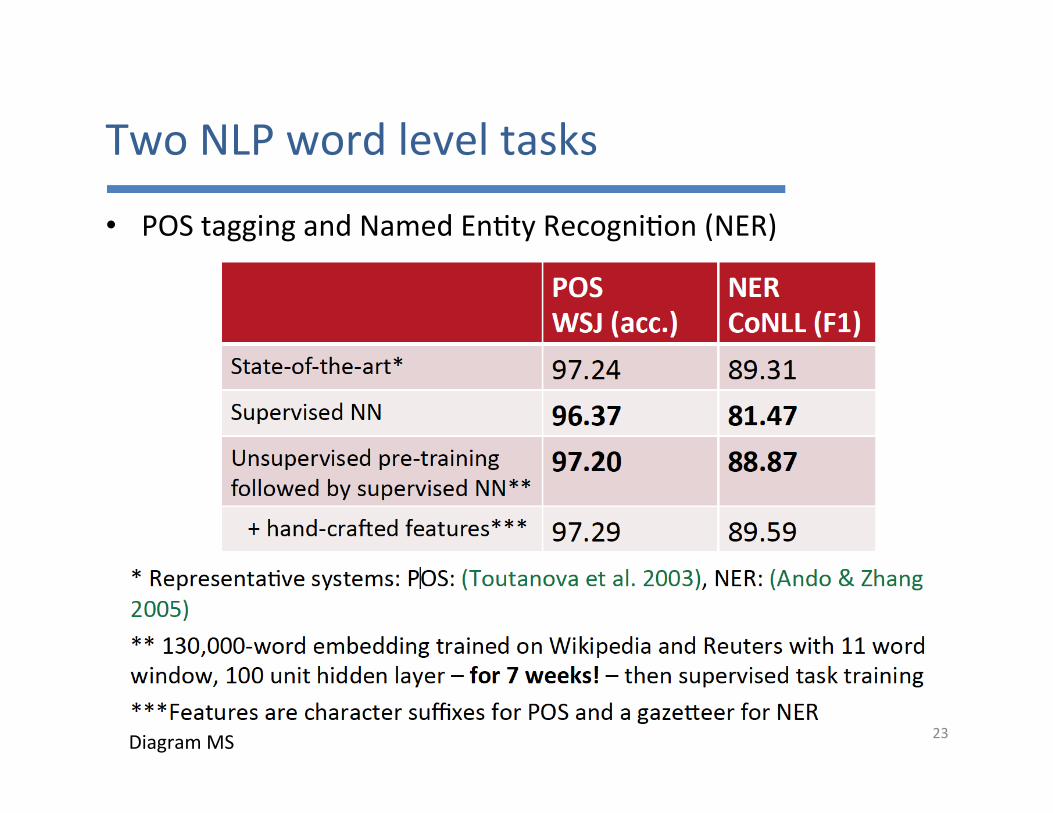
TwoNLPwordleveltasks
• POStaggingandNamedEn7tyRecogni7on(NER)
DiagramMS 23
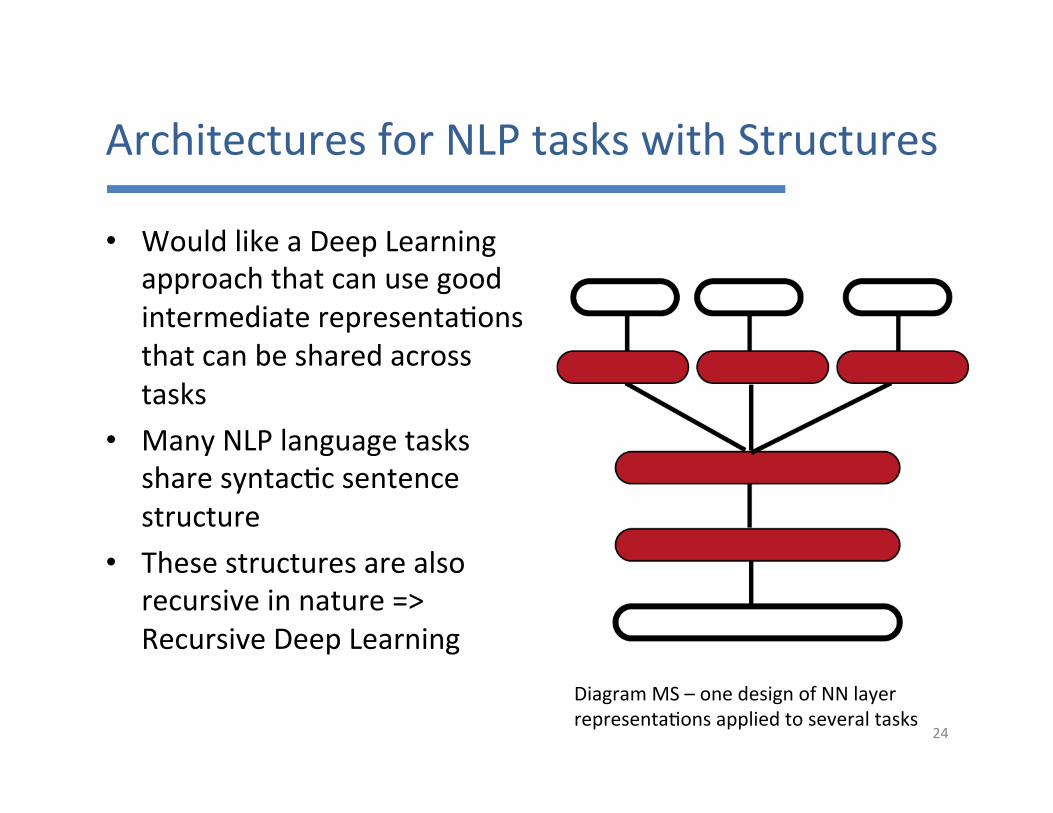
ArchitecturesforNLPtaskswithStructures
• WouldlikeaDeepLearningapproachthatcanusegoodintermediaterepresenta7onsthatcanbesharedacrosstasks
• ManyNLPlanguagetaskssharesyntac7csentencestructure
• Thesestructuresarealsorecursiveinnature=>RecursiveDeepLearning
DiagramMS–onedesignofNNlayerrepresenta7onsappliedtoseveraltasks
24
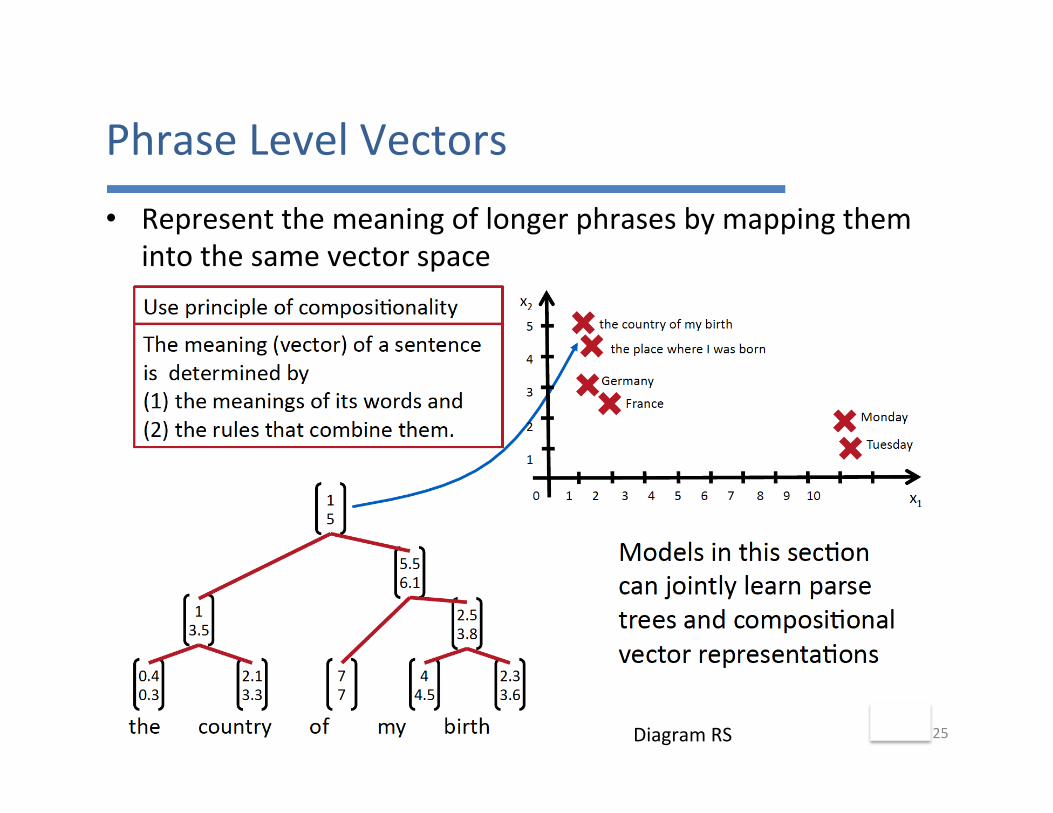
PhraseLevelVectors• Representthemeaningoflongerphrasesbymappingthem
intothesamevectorspace
25DiagramRS
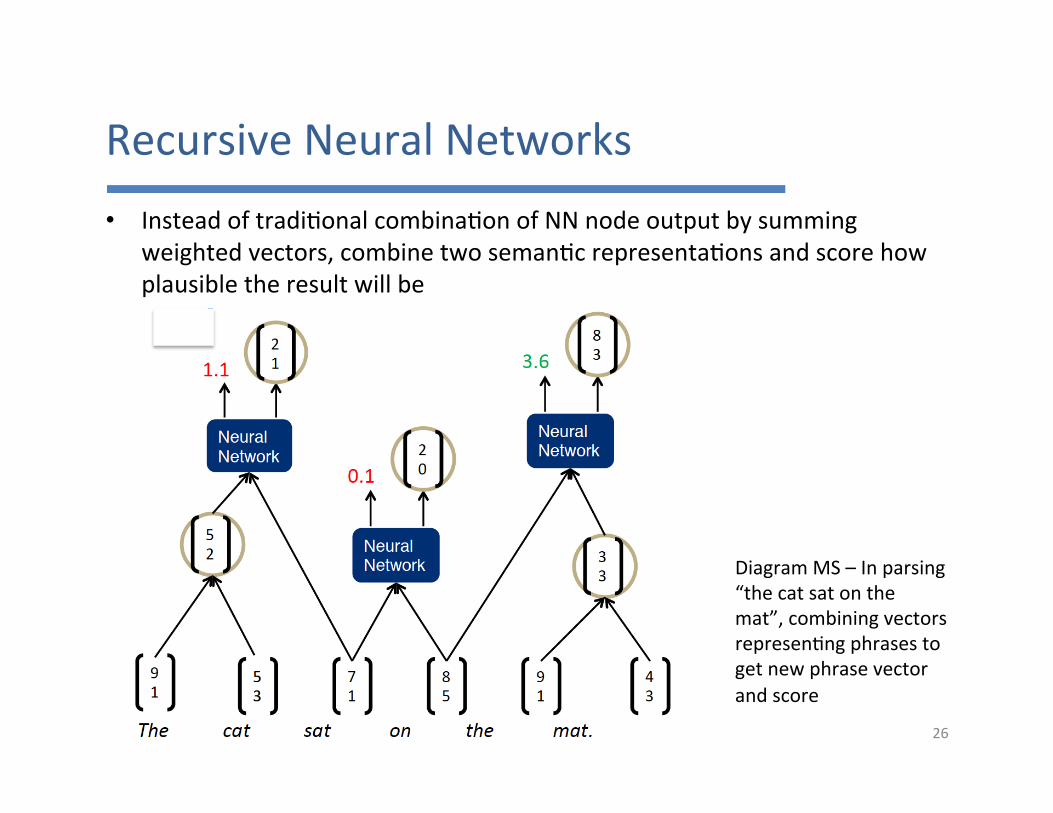
RecursiveNeuralNetworks• Insteadoftradi7onalcombina7onofNNnodeoutputbysumming
weightedvectors,combinetwoseman7crepresenta7onsandscorehowplausibletheresultwillbe
DiagramMS–Inparsing“thecatsatonthemat”,combiningvectorsrepresen7ngphrasestogetnewphrasevectorandscore
26
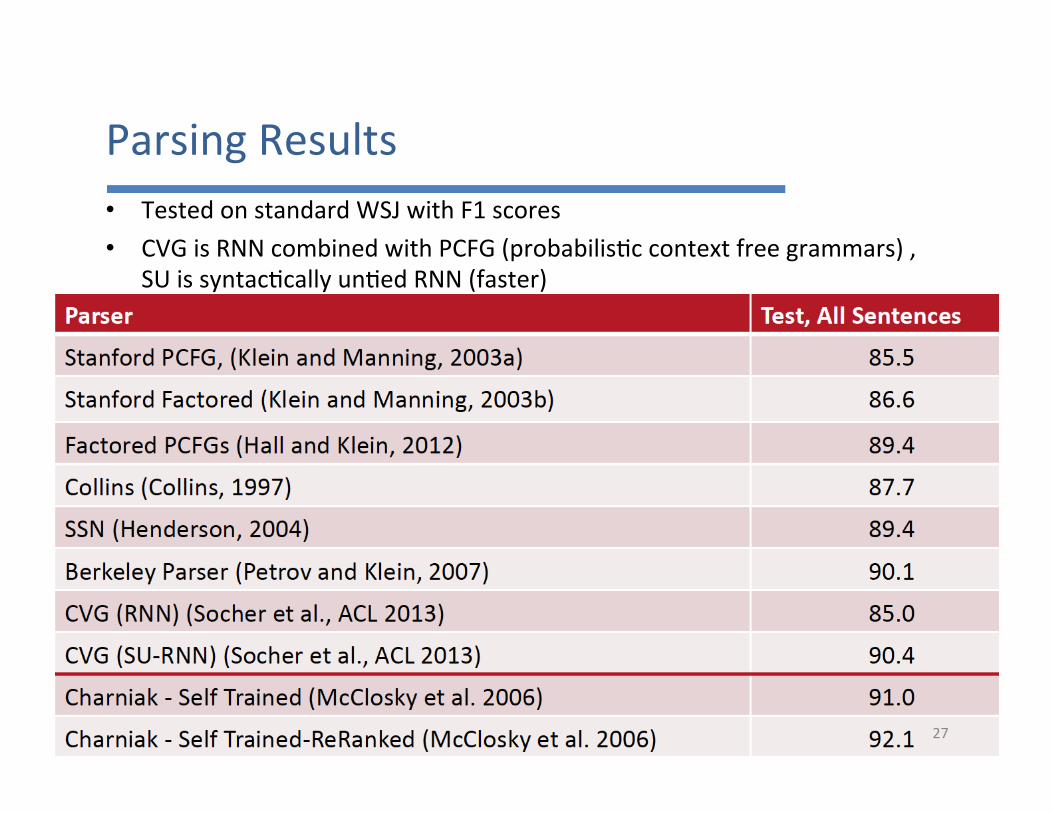
ParsingResults• TestedonstandardWSJwithF1scores• CVGisRNNcombinedwithPCFG(probabilis7ccontextfreegrammars),
SUissyntac7callyun7edRNN(faster)
27
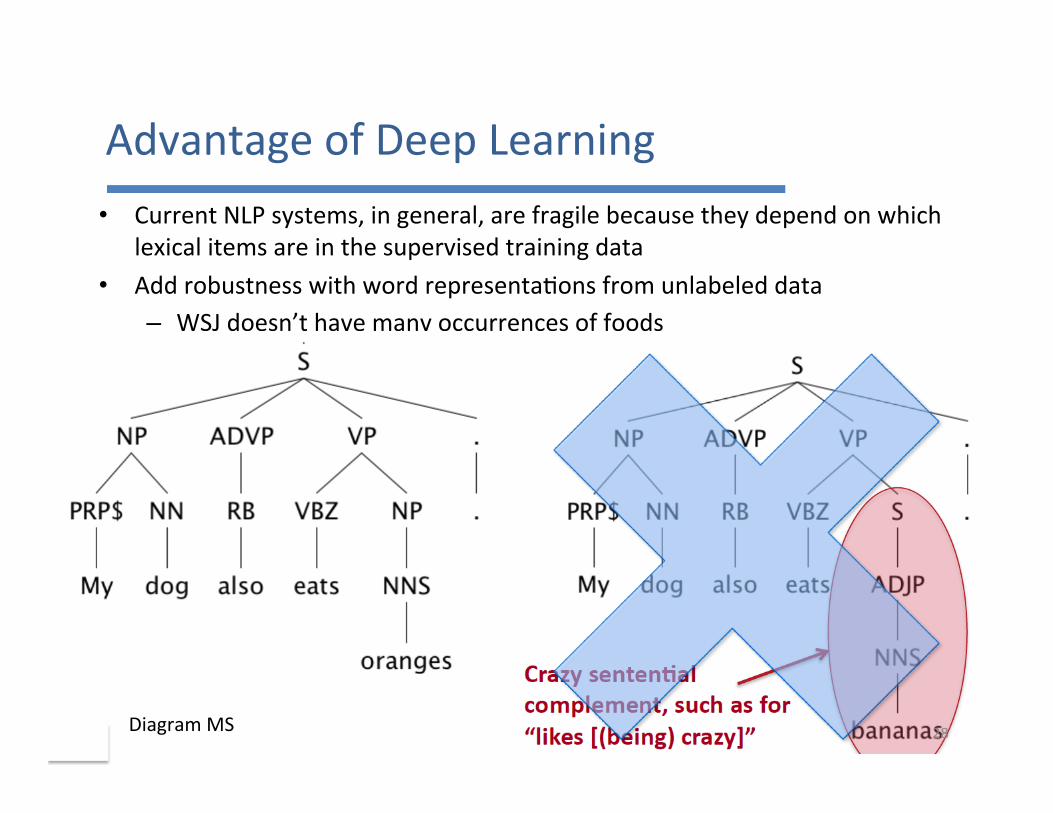
AdvantageofDeepLearning• CurrentNLPsystems,ingeneral,arefragilebecausetheydependonwhich
lexicalitemsareinthesupervisedtrainingdata• Addrobustnesswithwordrepresenta7onsfromunlabeleddata
– WSJdoesn’thavemanyoccurrencesoffoods
28DiagramMS

ParaphraseDetec7on
• Taskistocomparesentencestoseeiftheyhavethesameseman7cs
• Examples– Pollacksaidtheplain7ffsfailedtoshowthatMerrillandBlodget
directlycausedtheirlosses– Basically,theplain7ffsdidnotshowthatomissionsinMerrill’s
researchcausedtheclaimedlosses– Theini7alreportwasmadetoModestoPoliceinDecembr28– ItstemsfromaModestopolicereport
• Solu7onisaRNNcalledRecursiveAutoencoderstocomparevectorrepresenta7onsofsentences
29
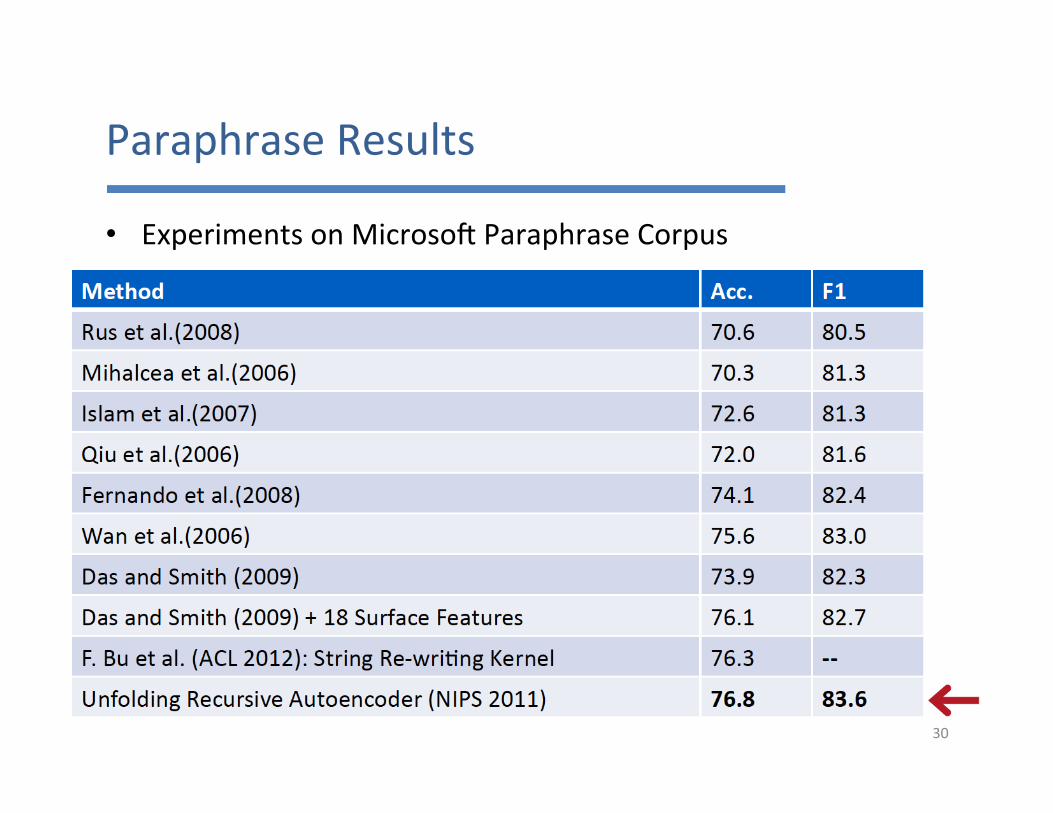
ParaphraseResults
• ExperimentsonMicrosouParaphraseCorpus
30

Sen7mentAnalysisonMovies
• Labelmoviereviewsentencesforposi7veornega7vesen7ment
• Examples– StealingHarvarddoesn’tcareaboutcleverness,wit,oranyotherkind
ofintelligenthumor.– Thereareslowandrepe77veparts,butithasjustenoughspiceto
keepitgoing.• Solu7on:
– Newsen7mentphrasetreebanktoprovidesupervisedmeansofcombiningsen7mentphrases(availablefromSocherandKaggle)
– RecursiveNeuralTensorNetwork–mostpowerfulmethodsofarandprovidesmoreinterac7onofvectorsinthecomposi7onofphrases(Socheretal2013)
31
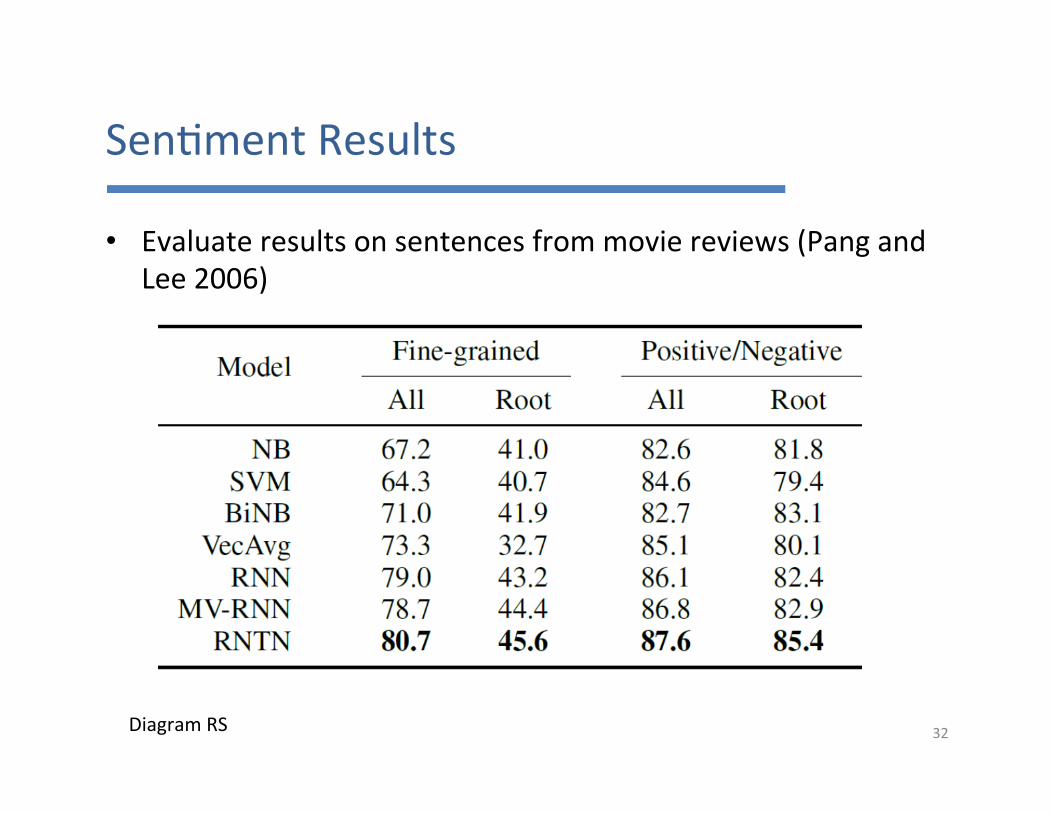
Sen7mentResults
• Evaluateresultsonsentencesfrommoviereviews(PangandLee2006)
32DiagramRS
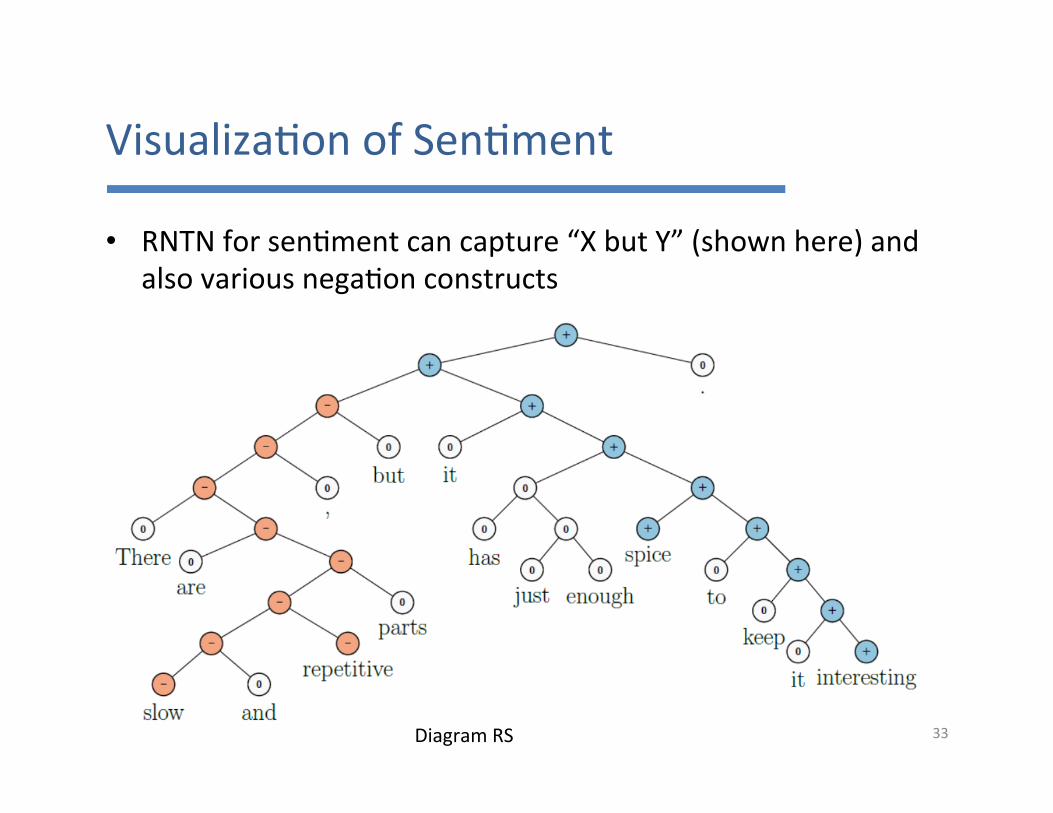
Visualiza7onofSen7ment
• RNTNforsen7mentcancapture“XbutY”(shownhere)andalsovariousnega7onconstructs
33DiagramRS

SummaryofDeepLearningonNLPtasks
• AlsoRNNfor– Rela7onshiplearning– Ques7onanswering– Objectdetec7oninimages
• ExcellentrecentresultsonMachineTransla7onshouldsoonbegoingintoproducts– SequencetoSequenceLearningwithNN– Sutskeveretal2014,Luongetal2016
• OngoingresearchintotypesofNNandhowtoapplythemtotasks
34

HowcanweuseDeepLearninginNLP?• (IntheACL2013tutorial,ManningandSochergaveadviceonhowto
writeyourownneuralnetworkcode!)• Codeavailableforsen7mentandrela7onanalysis:www.socher.org
• Toolsforwordrepresenta7ons– word2vec,availablefromGoogleinC– gensim(python),opensourcebyRadimRehurek– Deeplearning4j(java)
• Usewordvectorsasfeaturesincurrentclassifiers– doc2vec
• Googletrainedwordmodel–trainedon100Bwordsnewsdataresul7ngin3Mphraseswithlayersize300
• MoreadvancedtypesofNN– TensorFlow,availablefromGoogle 35

gensimpackageWord2vec• FromRaRetechnologies,RadimRehurek
– hcps://rare-technologies.com/word2vec-tutorial/
• Createageneratortogetsentencesaslistsoftokens– Dowhateverpreprocessingandtokenizingyouneed
• CreateamodelwithWord2vec– Setminimumwordfrequencyforvocabulary– Setwindowsize(surroundingcontextwordsize)– Setlayersize(sizeofhiddenlayerandlengthofvectors)– Setnumberofcoresforparallelprocessing– Recommendedtotrywindowsizesfrom5to20,andlayersizesfrom50
to300– RecommendCBOWforsmallerdatasets,Skipgramforlarger
• EvaluateanalogieswithGoogle’sfile:ques7ons-words.txt• Otherfunc7onsshowsimilar,anddis-similar,words 36

Word2veconcompaignsocialmedia(inprogress!)
• Icreatedaword2vecmodelon114kcombinedtwicerandfacebookmessages(unlabeled)– UsedNLTKsocialmediatokenizer;didn’tcleanurls,hashtagsor
men7ons– Modelhaswindowsize8andlayersize200
• Vocabularyissize30,342withminimumcount=3– Examples:['benefits','twenty','according','will','Steps','@obrienc2','@HoustonChron',
'Balloon','#ac7onsnotwords','owe','hcp://t.co/adp2vJr5u7','Texan','possibility','ini7a7ng','!','humble','@anniekarni','7:40','chip-in','shou7ng','@masslivenews','Timothy','strategically','racist','10/8','reigni7ng','Jimmie','Too','@Teamsters',
• Similari7es:– modelg.most_similar(['pollster']):‘groups’,‘acended’,‘@NancyPelosi’– modelg.doesnt_match(["candidate""pollster"“wives""paper”):‘paper’– modelg.similarity('candidate','pollster')):0.06– modelg.similarity('paper','pollster'): -0.08
37
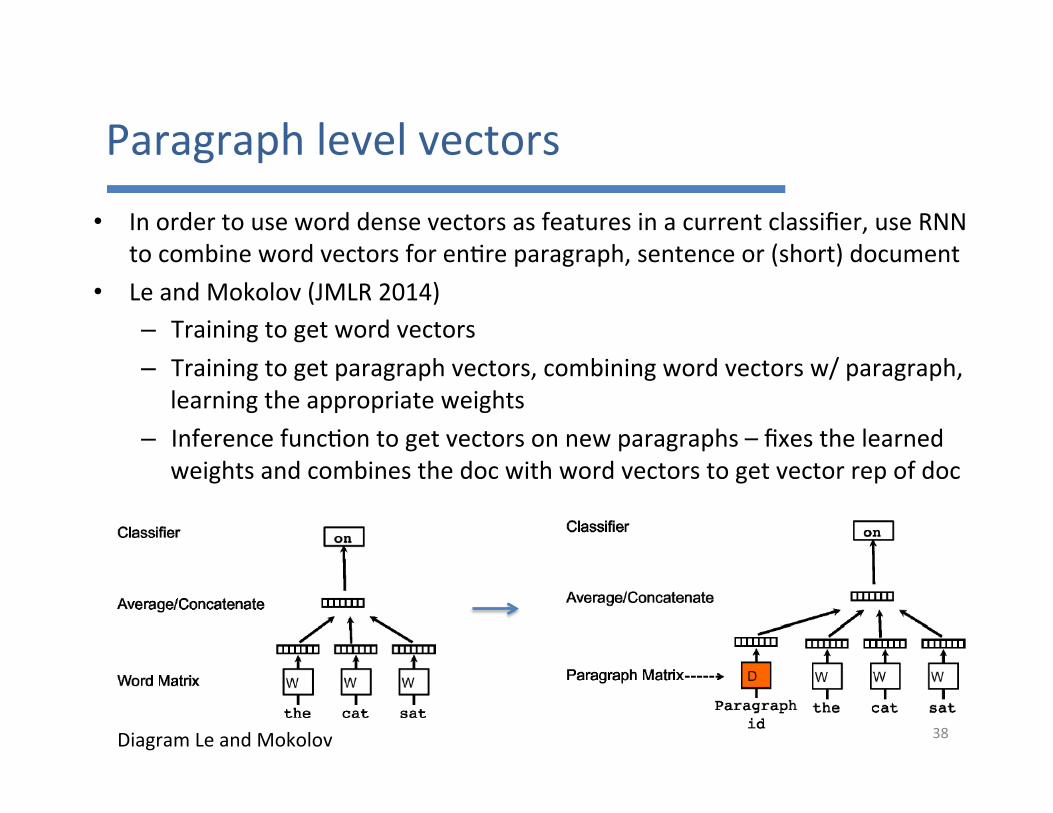
Paragraphlevelvectors• Inordertouseworddensevectorsasfeaturesinacurrentclassifier,useRNN
tocombinewordvectorsforen7reparagraph,sentenceor(short)document• LeandMokolov(JMLR2014)
– Trainingtogetwordvectors– Trainingtogetparagraphvectors,combiningwordvectorsw/paragraph,
learningtheappropriateweights– Inferencefunc7ontogetvectorsonnewparagraphs–fixesthelearned
weightsandcombinesthedocwithwordvectorstogetvectorrepofdoc
38DiagramLeandMokolov

gensimpackageDoc2vec
• FromRaRetechnologies,RadimRehurek– hcps://radimrehurek.com/gensim/models/doc2vec.html
• Createageneratorthatpairsidswithsentences• CreateamodelwithDoc2vec– SimilarparametersasWord2vec– Savethemodel
• Inyourclassifiersetup,loadthemodel– Calltheinfer_vectorfunc7ononthetokenlisttogeta(dense)vectorrepresenta7on
– Addthesenumberstoyourfeaturesandclassify
39
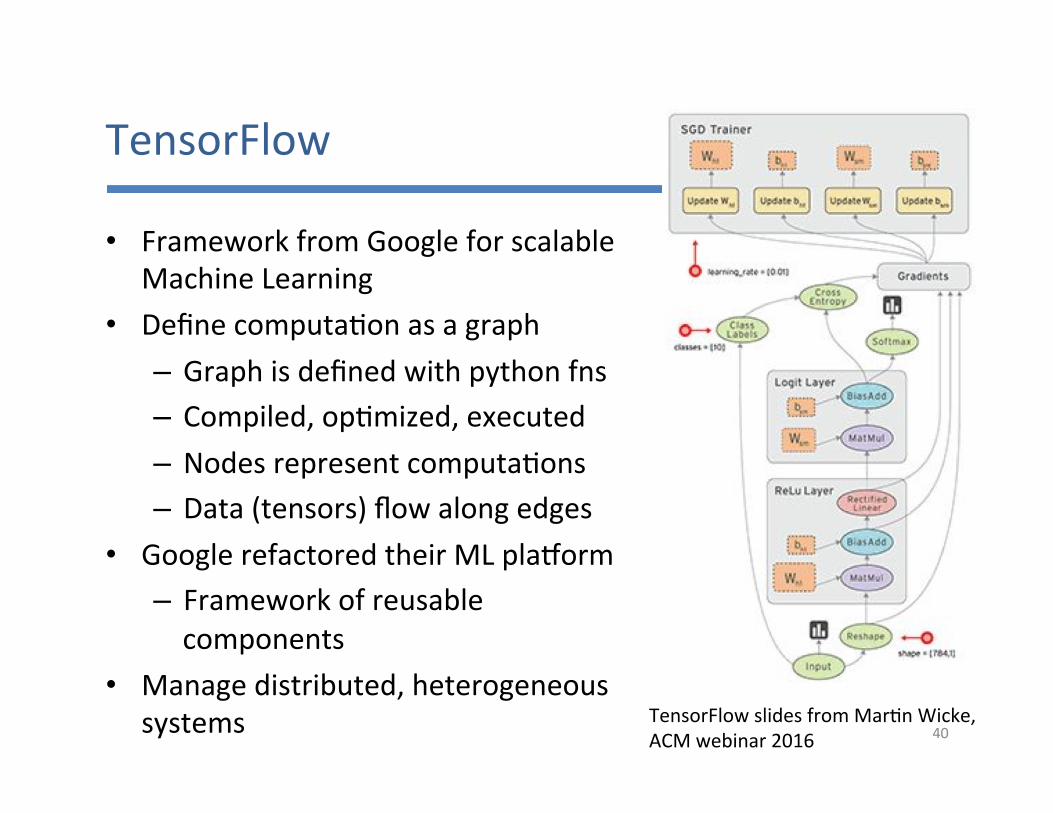
TensorFlow
• FrameworkfromGoogleforscalableMachineLearning
• Definecomputa7onasagraph– Graphisdefinedwithpythonfns– Compiled,op7mized,executed– Nodesrepresentcomputa7ons– Data(tensors)flowalongedges
• GooglerefactoredtheirMLpla�orm– Frameworkofreusablecomponents
• Managedistributed,heterogeneoussystems TensorFlowslidesfromMar7nWicke,
ACMwebinar2016 40

What’savailableinTensorFlownow
• Tutorialsontensorflow.org:• Imagerecogni7on(convolu7onalNN):– hcps://www.tensorflow.org/tutorials/image_recogni7on
• Wordembeddings:– hcps://www.tensorflow.org/versions/word2vec
• LanguageModeling:– hcps://www.tensorflow.org/tutorials/recurrent
• Transla7on:– hcps://www.tensorflow.org/versions/seq2seq
41

Conclusion
• DeeplearningispromisingareaforNLP– Learningfeaturesofclassifica7onfromunlabeleddata– ButmaynottotallyfreeusfromdesigningmanualfeaturesandusinglabeleddatatomakeNLPrepresenta7ons
• LotsofresearchonwhataretherightNNalgorithmsandtextrepresenta7ons
• Future:– MoresouwarepackagestomakeiteasiertoapplyDLtoyourownNLPtask
– Possibili7esforimprovementsinsomeofthehardertasksofNLP
42

References• Ando,RieKubotaandTongZhang.2005.Aframeworkforlearningpredic7ve
structuresfrommul7pletasksandunlabeleddata.J.MachineLearningResearch6:1817–1853.
• Bengio,Yoshua,RejeanDucharme,PascalVincent,andChris7anJauvin.2003.Aneuralprobabilis7clanguagemodel.J.MachineLearningResearch3:1137–1155.
• Collobert,R.andJ.Weston.2008.Aunifiedarchitecturefornaturallanguageprocessing:Deepneuralnetworkswithmul7tasklearning.InICML’2008.
• Collobert,Ronan,JasonWeston,LeonBocou,MichaelKarlen,KorayKavukcuoglu,andPavelKuksa.2011.Naturallanguageprocessing(almost)fromscratch.JournalofMachineLearningResearch12:2493–2537.
• Dahl,GeorgeE.,DongYu,LiDeng,andAlexAcero.2012.Context-dependentpre-traineddeepneuralnetworksforlargevocabularyspeechrecogni7on.IEEETransac7onsonAudio,Speech,andLanguageProcessing20(1):33–42.
• Finkel,JennyRoseandChristopherD.Manning.2010.HierarchicalJointLearning:ImprovingJointParsingandNamedEn7tyRecogni7onwithNon-JointlyLabeledData,HLT
43

References• Firth,J.R.1957.Asynopsisoflinguis7ctheory1930–1955.InStudiesinLin-guis7c
Analysis,pages1–32.Oxford:PhilologicalSociety.ReprintedinF.R.Palmer(ed),SelectedPapersofJ.R.Firth1952–1959,London:Longman,1968.
• Krizhevsky,A.,Sutskever,I.andHinton,G.E.,ImageNetClassifica7onwithDeepConvolu7onalNeuralNetworks,NIPS2012:NeuralInforma7onProcessingSystems,LakeTahoe,Nevada
• Le,QV,TMikolov,DistributedRepresenta7onsofSentencesandDocuments,ICML14,1188-1196
• Luong,Minh-Thang,IlyaSutskever,QuocV.Le,OriolVinyals,andLukaszKaiser.Mul7-taskSequencetoSequenceLearning.ICLR’16.
• Manning,ChristopherandSocher,Richard,DeepLearningforNLPwithoutMagic,TutorialforHLTNAACL2013.
• Mikolov,Tomas.WYih,GZweig,Linguis7cRegulari7esinCon7nuousSpaceWordRepresenta7ons,HLT-NAACL13,746-751
• Mikolov,T.,ISutskever,KChen,GSCorrado,JDean,Distributedrepresenta7onsofwordsandphrasesandtheircomposi7onality,Advancesinneuralinforma7onprocessingsystems,3111-3119
44

References• Seide,Frank,GangLi,andDongYu.2011.Conversa7onalspeechtranscrip7on
usingcontext-dependentdeepneuralnetworks.InInterspeech2011,pages437–440
• Socher,R.,APerelygin,JYWu,JChuang,CDManning,AYNg,CPPocs,RecursiveDeepModelsforSeman7cComposi7onalityOveraSen7mentTreebank,EMNLP2013.
• Socher,Richard,DeepLearningforNLPclass,hcp://cs224d.stanford.edu/• Sutskever,Ilya,OriolVinyals,andQuocLe,SequencetoSequenceLearningwith
NeuralNetworks,NIPS2014• Toutanova,Kris7na,DanKlein,ChristopherD.Manning,andYoramSinger.2003.
Feature-richpart-of-speechtaggingwithacyclicdependencynetwork.InHumanLanguageTechnologyConferenceoftheNorthAmericanChapteroftheAssocia7onforComputa7onalLinguis7cs(HLT-NAACL2003),pages252–259.
• Turian,Joseph,LevRa7nov,andYoshuaBengio.2010.Wordrepresenta7ons:Asimpleandgeneralmethodforsemi-supervisedlearning.InProc.ACL’2010,pages384–394.Associa7onforComputa7onalLinguis7cs.
• Zeiler,MachewD.andRobFergus,VisualizingandUnderstandingConvolu7onalNetwords,ECCV2014. 45






























