Embed Size (px)
Citation preview

Đây là hướng dẫn tiếng Việt về data warehouse - trái tim của bất cứ dự án nào về Big Data. Mong mọi người đóng góp thêm. Nội dung tham khảo từ Data warehouse của javapoint
Data Warehouse TutorialData warehouse ComponentsThree-Tier Data Warehouse ArchitectureData Warehouse ArchitectureData Warehouse DesignData Warehouse Delivery ProcessMagentoData warehouse - The process from the customer's source to the production tableData Warehouse - Networking Related KnowledgeData warehouse - MOLAP Turtorial - Things to noticeData warehosue Design
Data Warehouse - Tutorial

1. Data Warehouse Tutorial2. What is a Data Warehouse?
Data warehouse (DW) là một cơ sở dữ liệu quan hệ được thiết kế để truy vấn và phân tích
thay vì xử lý giao dịch. Nó bao gồm dữ liệu lịch sử có nguồn gốc từ dữ liệu giao dịch từ
một hay nhiều nguồn datasource khác nhau ( ERP, CRM, files, ... ).
Data warehouse cung cấp dữ liệu lịch sử, toàn doanh nghiệp, tích hợp và tập trung vào
việc cung cấp hỗ trợ cho những người ra quyết định để mô hình hóa và phân tích dữ liệu.
"Data warehouse là kho lưu trữ thông tin theo định hướng, tích hợp và biến đổi theo
thời gian để hỗ trợ cho các quyết định của quản lý doanh nghiệp."
3. Characteristics of Data Warehouse - Đặc điểm của Data warehouse
3.1 Subject-Oriented - Định hướng theo chủ đề
Data Warehouse Tutorial

3.2 Intergrated - Tích hợp
Data warehouse được thiết kế để mô hình hóa, phân tích dữ liệu. Ví dụ, để hiểu rõ hơn về
dữ liệu kinh doanh của công ty, có thể xây dựng data warehouse lưu trữ dữ liệu xúc
tích, cô đọng nhất trong dữ liệu kinh doanh, từ đó có thể giúp nhà quản lý trả lời được
các câu hỏi như “Ai là khách hàng tốt nhất vào năm trước?”, “Ai sẽ là khách hàng tiềm
năng vào năm tiếp theo?
Data warehouse tích hợp các nguồn datasource khác nhau như RDBMS, NoSQL, flat files,
media files ... và các bản ghi giao dịch trực tuyến - online processing records. Dữ
liệu phải thực hiện việc làm sạch và tích hợp trong quá trình lưu trữ dữ liệu để đảm bảo
tính thống nhất trong quy ước đặt tên, loại thuộc tính, v.v., giữa các nguồn datasource
khác nhau.

3.3 Time-Variant - Biến đổi theo thời gian
Dữ liệu trong data warehouse được lưu trữ dạng lịch sử, từ quá khứ đến hiện tại, để đảm
bảo các truy vấn, phân tích dữ liệu trong quá khứ và hiện tại. Data warehouse tập
trung vào những thay đổi theo mốc thời gian, với lượng dữ liệu lớn có tính lịch sử vậy
có thể tìm ra những xu hướng trong kinh doanh.
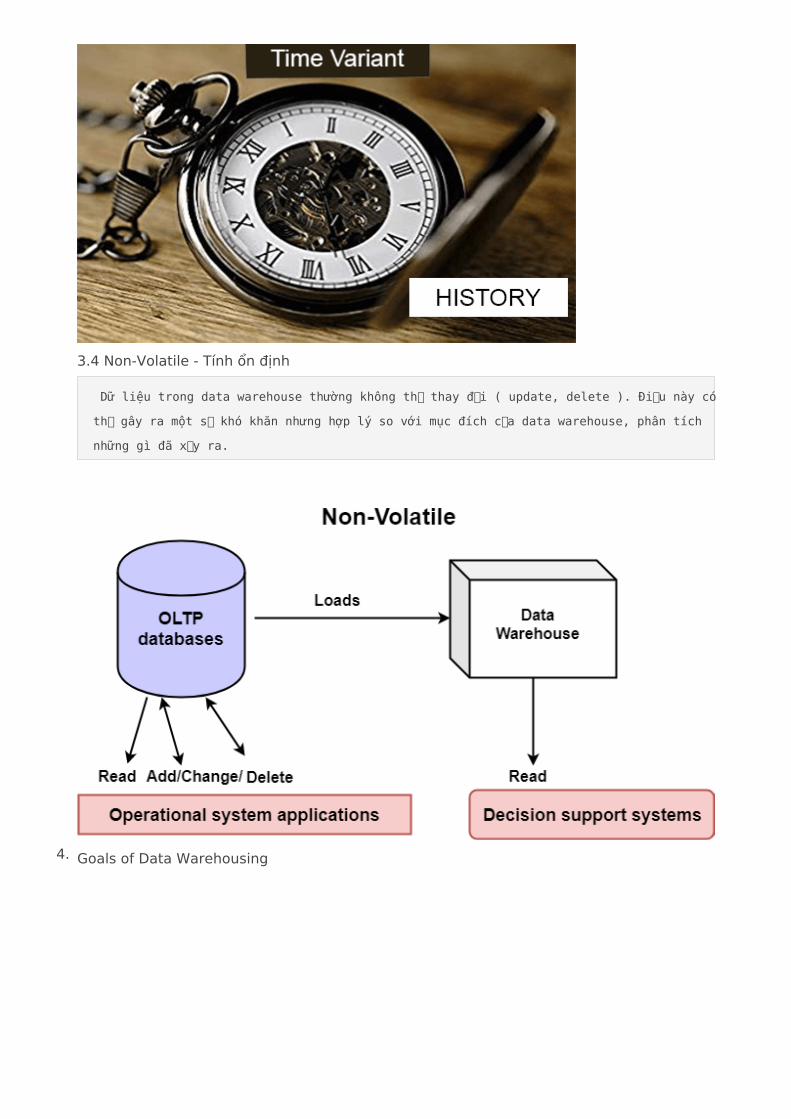
3.4 Non-Volatile - Tính ổn định
Dữ liệu trong data warehouse thường không thể thay đổi ( update, delete ). Điều này có
thể gây ra một số khó khăn nhưng hợp lý so với mục đích của data warehouse, phân tích
những gì đã xảy ra.
4. Goals of Data Warehousing

Mục tiêu của Data warehouse
- Để giúp báo cáo cũng như phân tích
- Duy trì thông tin lịch sử của tổ chức
- Là nền tảng cho việc ra quyết định.
5. Need for Data Warehouse

1. Components or Building Blocks of Data Warehouse
Kiến trúc phần mềm và phần cứng, các thành phần điển hình của một data warehouse bao gồm
Source Data Component - Thành phần nguồn dữ liệu
Dữ liệu được đưa vào data warehouse có thể đến từ 4 nguồn data source : Production Data,
Internal Data, Archived Data, External Data.
Data Staging Component - Thành phần vùng dữ liệu tạm thời
Sau khi dữ liệu được extract từ các hệ thống khác nhau và các nguồn bên ngoài, dữ liệu
cần được chuyển đổi, làm sạch, đưa về cùng tê, ngữ nghĩa, kiểu dữ liệu tại data staging
trước khi được đưa vào data warehouse. Data extraction -> Data Transformation -> Data
Data warehouse Components

Loading ( Trích xuất dữ liệu từ data source -> Chuyển đổi dữ liệu tại staging -> đẩy dữ
liệu từ staging vào data warehouse )
Data Storage - Thành phần lưu trữ dữ liệu
Thành phần lưu trữ dữ liệu của Data warehouse thường được phân chia thành các kho. Các
kho dữ liệu cho các hệ điều hành thường chỉ bao gồm dữ liệu hiện tại. Ngoài ra, các kho dữ
liệu này bao gồm dữ liệu có cấu trúc được chuẩn hóa cao để xử lý nhanh và hiệu quả.
Information Delivery Component
Metadata Component
Metadata trong Data warehouse có thể coi như từ điển dữ liệu hoặc danh mục dữ liệu
trong hệ thống quản lý cơ sở dữ liệu. Trong metadata, lưu trữ dữ liệu về cấu trúc dữ liệu
lôgic, dữ liệu về các bản ghi và địa chỉ, thông tin về các chỉ mục, v.v.
Data Marts

Data Marts - nơi lưu trữ các dữ liệu đã được phân tích cụ thể theo từng chủ đề khác nhau,
phục vụ cho các nhóm quản lý riêng biệt. Các dữ liệu phân tích này được trích xuất từ
data warehouse để tăng performence và giảm dung lượng lưu trữ. Ví dụ về data marts :
Sales, Customer, Inventory ...
Management and Control Component
- Management and Control Component là Các thành phần quản lý và kiểm soát phối hợp các
dịch vụ và chức năng trong Data Warehouse. - Các thành phần này kiểm soát việc chuyển đổi
dữ liệu và chuyển dữ liệu vào Data Warehouse. - Kiểm duyệt việc cung cấp dữ liệu cho
khách hàng. Đồng thời hoạt động với các hệ thống quản lý cơ sở dữ liệu và cho phép dữ liệu
được lưu chính xác trong kho.
- Theo dõi sự chuyển động của dữ liệu vào staging và từ staging vào data warehouse.

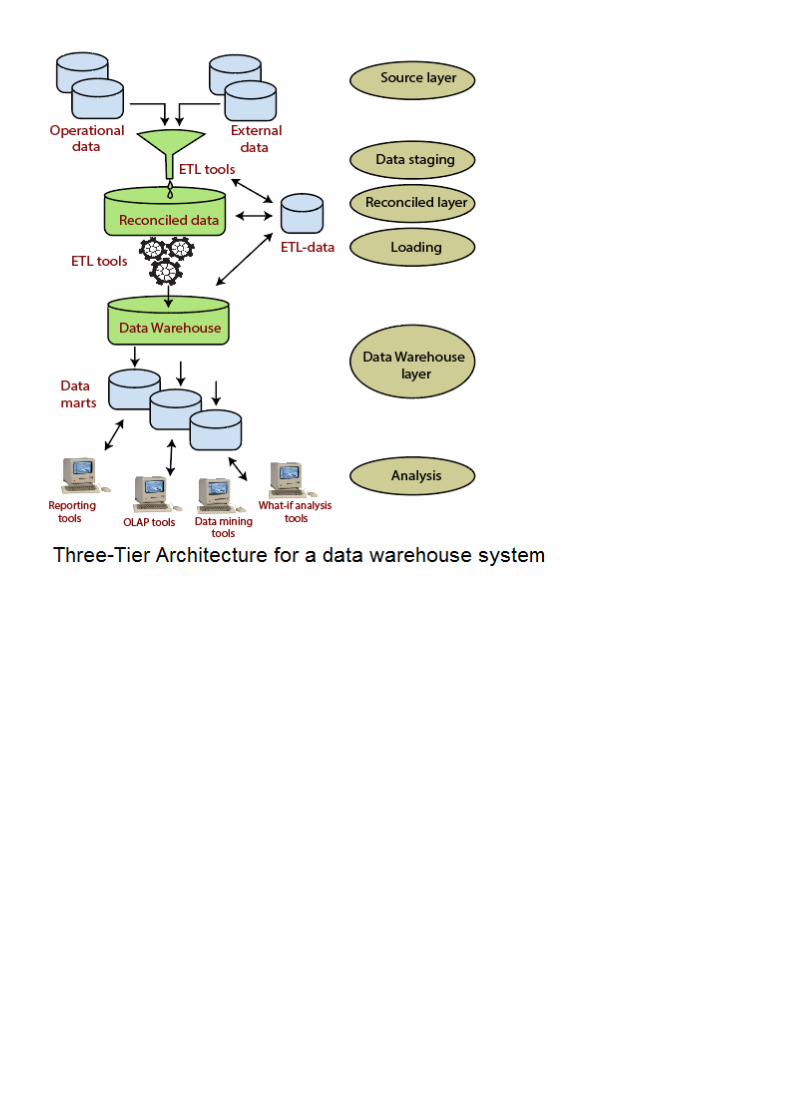
Thông thường một Data Warehouse sẽ có kiến trúc 3 tầng, bao gồm:
Tầng đáy(bao gồm các máy chủ Data warehosue)Tầng giữa(bao gồm các máy chủ OLAPTầng trên(bao gồm các tool front-end)
A picture is worth more than a thousand words
Three-Tier Data Warehouse Architecture
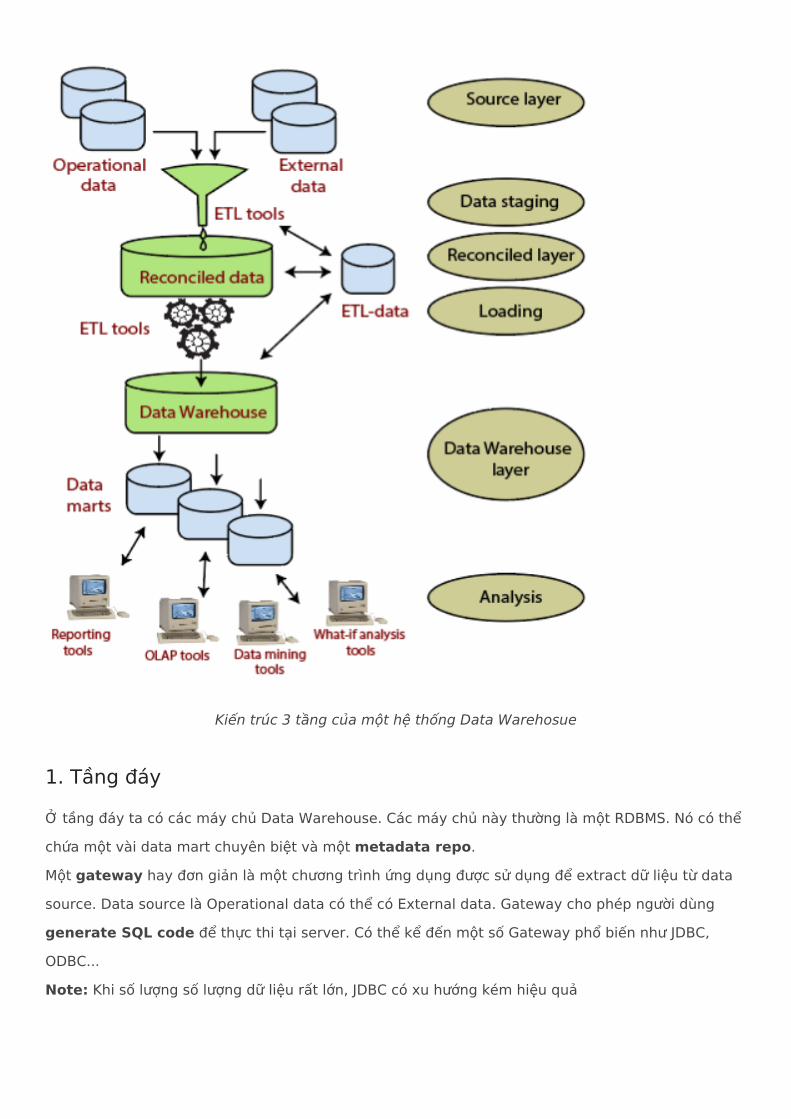
Kiến trúc 3 tầng của một hệ thống Data Warehosue
Ở tầng đáy ta có các máy chủ Data Warehouse. Các máy chủ này thường là một RDBMS. Nó có thể chứa một vài data mart chuyên biệt và một metadata repo. Một gateway hay đơn giản là một chương trình ứng dụng được sử dụng để extract dữ liệu từ data source. Data source là Operational data có thể có External data. Gateway cho phép người dùng generate SQL code để thực thi tại server. Có thể kể đến một số Gateway phổ biến như JDBC, ODBC... Note: Khi số lượng số lượng dữ liệu rất lớn, JDBC có xu hướng kém hiệu quả
1. Tầng đáy

Các máy chủ OLAP ở tầng giữa cần có khả năng truy vấn nhanh và thường được triển khai theo phong cách ROLAP hoặc MOLAP. Thứ nhất, ROLAP là cần phải ánh xạ các phép toán trên dữ liệu đa chiều thành các phép toán quan hệ chuẩn. Tại sao lại cần như vậy? Đó là vì OLAP làm việc với các cube đa chiều, nên rõ ràng ta phải ánh xạ rồi! Thứ hai, mô hình MOLAP có thể trực tiếp triển khai các dữ liệu và thao tác đa chiêu. Note: Nói như thể không phải lúc nào ta cũng chọn MOLAP, việc chọn ROLAP hay MOLAP thì còn tùy, vì mỗi cách sẽ có ưu, nhược điểm riêng.
Tầng trên cùng chịu trách nhiệm hiển thị các kết quả cunug cấp bới OLAP, tầng này có một số tool như Data mining tools, hay Reporting tools..
Ở bên trên, ta thấy có khái niếm "metadata repo", vậy nó là gì? Đúng như tên gọi, nó kho chứa siêu dữ liệu. Metadata repo sẽ chứa các thông tin để định nghĩa nên Data Warehouse Object. Có thể nói, Metadata repo là chất keo để kết nối các thành phần trong một hệ thống Data Warehouse. Metadata repo một số thông tin quan trọng như : Mô tả về cấu trúc của Data Warehouse như lược đồ data warehouse, ví trí data mart, ...Operational metadata những dữ liệu này cho ta lịch sử trạng thái của dữ liệu được lưu trữ như active(hoạt động), archived(được lưu trữ), hay purged(bị xóa) và các thông tin monitor về data warehouse..Thông tin để ánh xạ từ các cơ sở dữ liệu hoạt động, các RDBMS nguồn cũng như nội dụng của chúng, còn có cả các thông tin về luật để làm sạch và transform..Thông tin về chủ sở hữu, định nghĩa và điều khoản kinh doanh
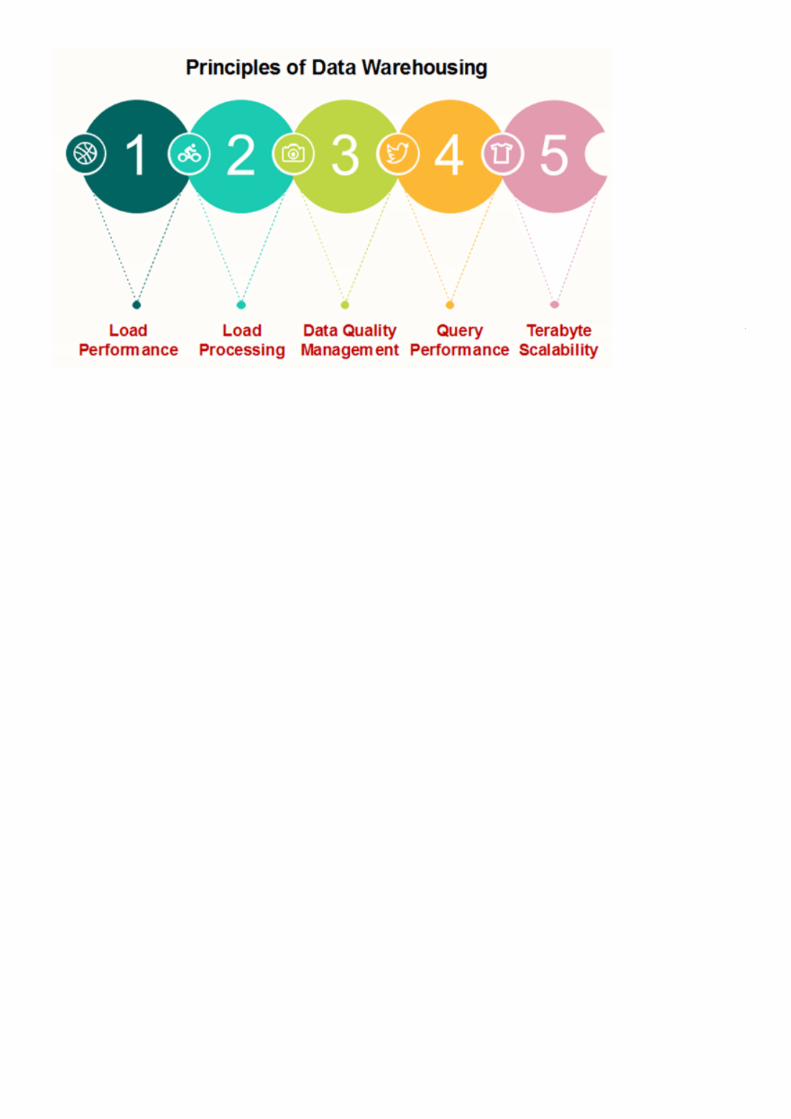
Các principles của Data warehouse cũng chính là các thách thức mà Data warehouse phải giải quyết được trong thực tế
2. Tầng giữa
3. Tầng trên
Principles of Data Warehousing

1. Overview
Kiến trúc data warehouse truyền thống phổ biến gồm 3 loại: - Kiến trúc Data Warehouse cơ
bản
- Kiến trúc Data warehouse với vùng dữ liệu tạm thời Staging - Kiến trúc Data
warehouse với vùng dữ liệu tạm thời Staging và Data Marts
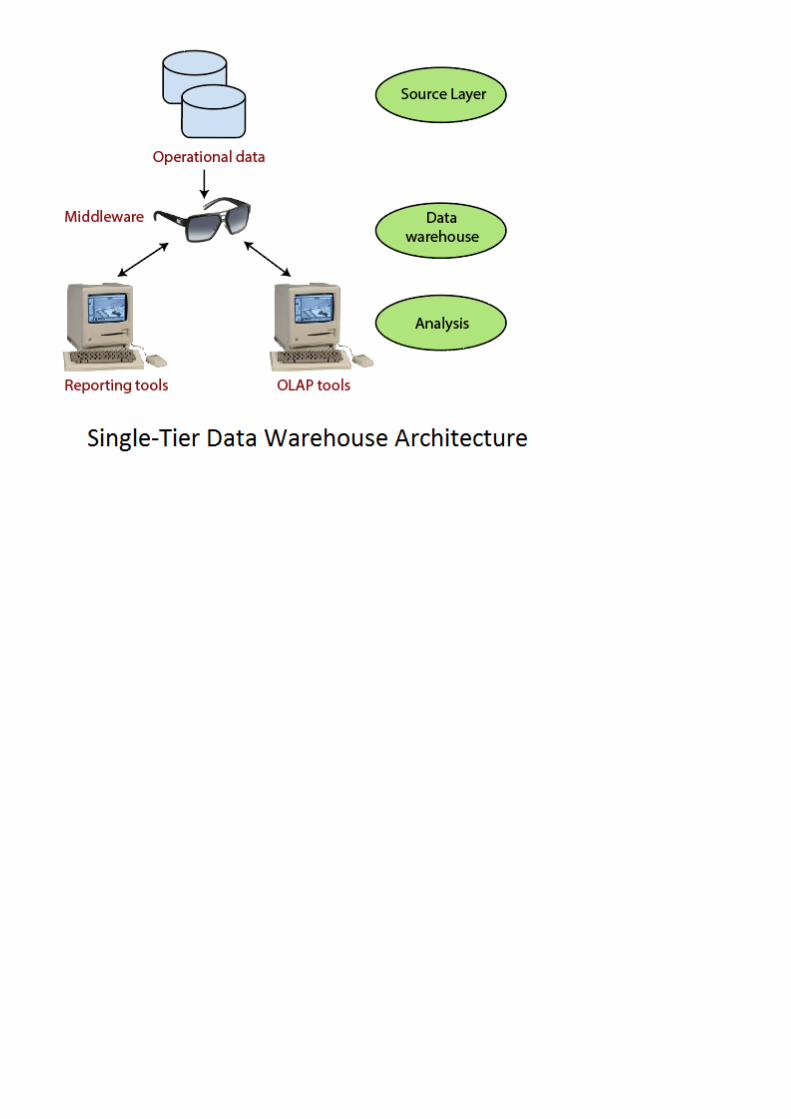
2. Data Warehouse Architecture: Basic
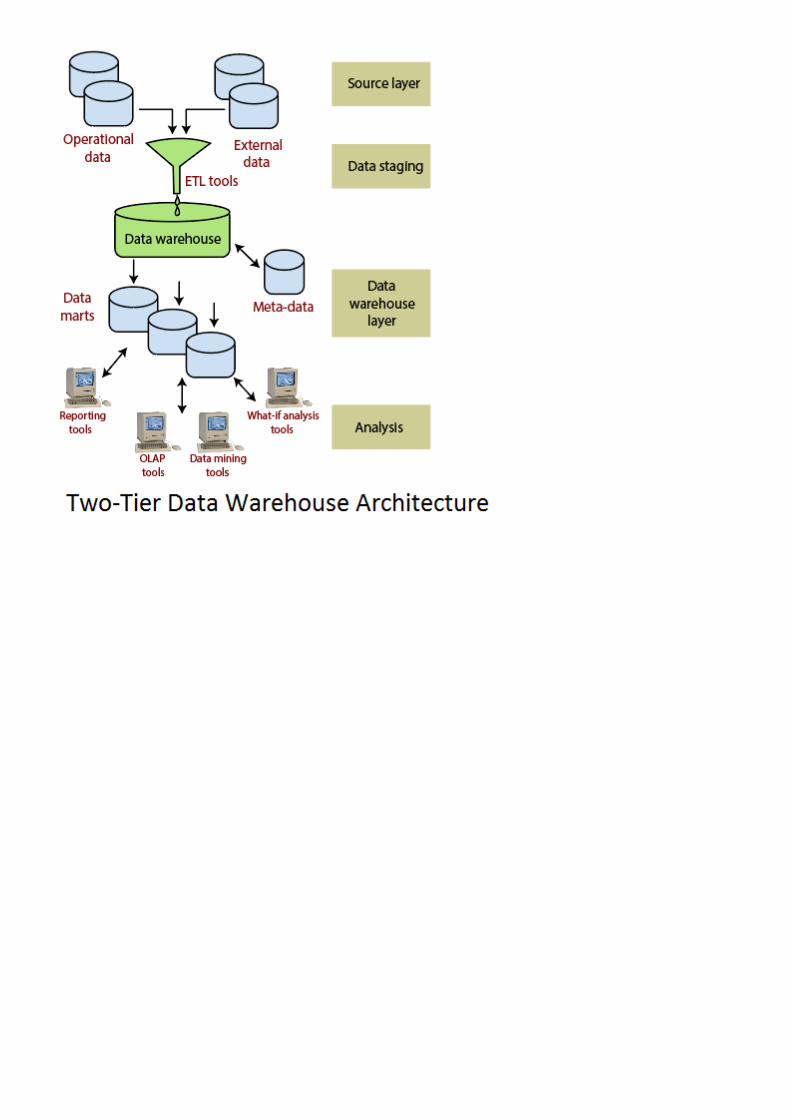
3. Data Warehouse Architecture: With Staging Area
Data Warehouse Architecture
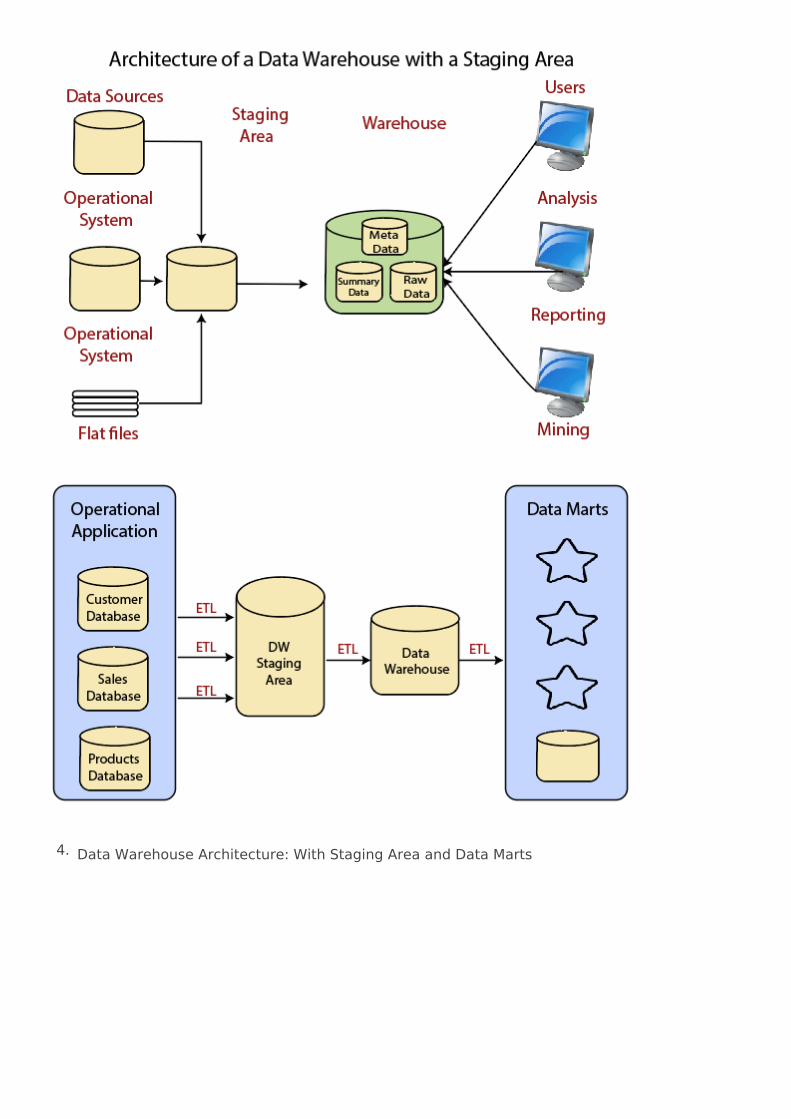
4. Data Warehouse Architecture: With Staging Area and Data Marts

5. Properties of Data Warehouse Architectures
Các thuộc tính kiến trúc cần thiết của một data warehouse
- Separation ( Tách biệt ) : Phân tích và xử lý giao dịch nên được tách ra càng nhiều càng tốt.-
Scalability ( Khả năng mở rộng ) : Kiến trúc phần cứng và phần mềm cần có khả năng mở rộng dễ dàng (

6. Types of Data Warehouse Architectures
Các kiểu kiến trúc Data warehouse phổ biến
Single-Tier Architecture ( kiến trúc 1 tầng )Two-Tier Architecture ( kiến trúc 2 tầng )Three-Tier Architecture ( kiến trúc 3 tầng )
khi khối lượng dữ liệu tăng lên )- Extensibility ( Khả năng kế thừa ) : Kiến trúc có thể thực hiện
các hoạt động và công nghệ mới mà không cần thiết kế lại toàn bộ hệ thống.- Security ( Tính bảo
mật )
- Administerability ( Khả năng quản trị )

Thiết kế Data Warehouse không phải việc làm đơn giản. Để thiết kế được một data warehouse tốt, đáp ứng được nhu cầu nghiệp vụ của người sử dụng, từ khâu thiết kế đến khi vận hành, ta đã phải tính đến các vấn đề như hiệu năng, bảo mật, backup, testing...Quá nhiều vấn đề cần giải quyết. Do đó, trong phần này, ta sẽ cùng nhau tìm hiều các cách tiếp cận trong thiết kế một Data Warehouse.
Có 2 cách tiệp cận chính, đó là:
Top-downBottom-up
Data Warehouse Design
1. Cách tiệp cận Top-down

Cách tiệp cận top-down
Cách tiếp cận này khá đơn giản và dễ hiểu. Đầu tiên, ta xây dựng data warehouse trước, sau đó data mart được xây dựng trên data warehouse bằng cách chọn ra các dữ liệu cần thiết với đôi tượng kinh doanh hoặc phòng ban cụ thể
Với cách tiếp cận này, ta có một số lợi ích như : Dễ phát triển một data mart mới, thích nghi nhanh với sự thay đổi trong môi trường kinh doanhChi phí ban đầu có thể cao, nhưng chi phát triển sau đó thấp
Cung cấp góc nhìn dữ liệu theo chiều nhất quán trên các data mart( vì cùng từ một nguồn là
1.1 Ưu điểm
data warehouse mà ra)
Chi phí, thời gian lớn ( vì dự án implement theo cách này thường lớn)Team cần có kinh nghiệm và kĩ năng tốt để cài đặt
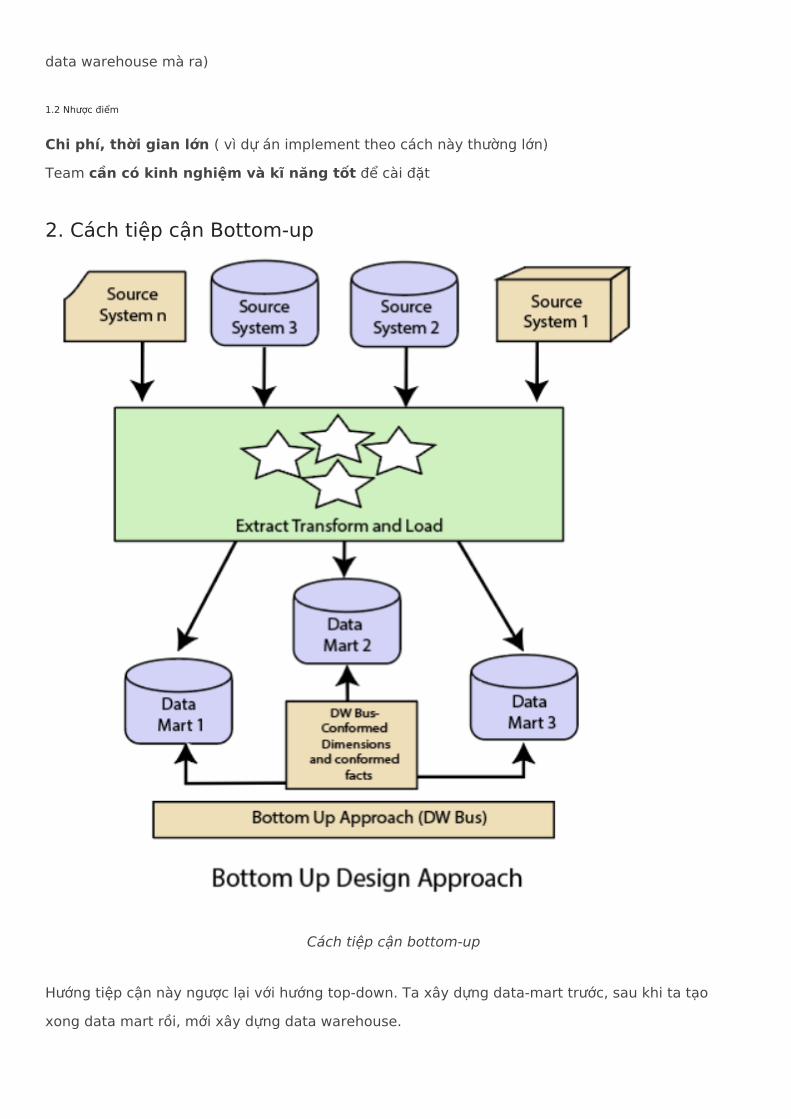
Cách tiệp cận bottom-up
Hướng tiệp cận này ngược lại với hướng top-down. Ta xây dựng data-mart trước, sau khi ta tạo xong data mart rồi, mới xây dựng data warehouse.
1.2 Nhược điểm
2. Cách tiệp cận Bottom-up

Các data mart có thể được deliver nhanh chóng
Có khả năng cung cấp các bản report nhanhMở rộng data warehouse dễ dàng khi có sự thay đối, thêm mới các đơn vị phòng banTiêu tốn thời gian ít hơn, thiết lập ban đầu cũng nhanh hơn
Chi phí ban dầu có thê thấp, nhưng sau đó đắtKhó bảo trì
Rõ ràng việc lựa chọn cách tiếp cận nào tùy thuộc vào nhiều yếu tố, từ nguồn lực về kinh tế, mục tiêu của doanh nghiệp, thời gian tiêu tốn, cho đến kinh nghiệm của đội ngũ phát triển của hệ thống... Sau đây, chúng ta cùng điểm qua một vài lĩnh vực để xem 2 cách tiếp cận này "so găng" với nhau. Bảo hiểm : Với ngành bảo hiểm, ta cần có một bức tranh tổng thể ở nhiểu mặt như nhóm khách hàng, tỉ lệ tử vong, nhân khẩu học, khả năng sinh lời của từng gói bán...Tất cả các khía cạnh này đều có liên quan tới nhau, do đó cách tiếp cận top-down sẽ phù hợp hơnMarketing: Ta có thể thất đây là bộ phận chuyên biệt, chỉ cần data-mart. Vì thế ta nên dùng bottom-up ở đâyChế tạo: Dùng top-down. Đơn giản là bởi các chức năng có sự liên quan với nhauCRM trong ngân hàng: Câu trả lời là top-down hoặc bottom-up . Vì nếu các metric nếu cần chỉ ở cấp độ khác hàng, ta sẽ không cần một bức tranh tổng thể về doanh nghiệp, do đó sử dụng cách tiếp cận bottom-up được ưu tiên, nhưng nếu toàn bộ quy trình và bộ phận trong ngân hàng được liên kết với nhau thì sự lựa chon ở đây là top-down
2.1 Ưu điểm
2.2. Nhược điểm
3. Top-down & Bottom-up Use case

Thích nghi là chìa khóa của tiến hóa. Data Warehouse cũng không phải là ngoại lệ. Khi doanh nghiệp lớn mạnh, và mở rộng, những yêu cầu liên tục được thay đổi, một data warehouse tốt cần đáp ứng được các yêu cầu mới một cách linh hoạt. Ta sẽ cùng tìm hiểu quá trình delivery một kho dữ liệu, từ quá trình hình thành đến trưởng thành như nào.
Data Warehouse Delivery Process

Quá trình delivery data warehouse
Kiến trúc tổng thể của hệ thốngChính sách lưu giữ dữ liệuChiến lược backup và recoveryKiến trúc của máy chủ và data-martKế hoạch về khả năng của phân cứng và cơ sở hạ tầngCác component khi thiết kế database
Ở giai đoạn này, sản phẩm đâu tiên có thể phân phối được sản xuất. Sản phẩm đầu tiên là thành phần nhỏ nhất của data warehouse. Thành phần nhỏ nhất này sẽ gia tăng lợi ích kinh doanh. Đến giai đoạn này, ta cần tạo ra được các yếu tố cơ sở hạ tầng quan trọng để load và transform thông tin.
Phase này ta sẽ chỉ load thêm các dữ liệu lịch sử mà thôi, để có thêm nhiều dữ lệu dùng để phân tích hơn. Ở phase trước, ta mới chỉ load được lịch sử của vài tháng gần đây, điều đó chưa giúp ta khám phá ra mẫu tri thức yêu cầu có dữ liệu lích sử xa hơn như vài năm trở lên. Lúc này dung lượng vật lý phải tăng lên đáng kể để có đủ không gian lưu trữ.
Ở phase này, ta cần cài đặt một công cụ query ad hoc nhằm vận hành data ware house. Những
IT StrategyData warehouse là khoản đầu tư chiến lược của một tổ chức, vì thế nó cần phải đem lại lợi ích cho tổ chức đó. Trong quá trình generate lợi ích, IT Strategy hay chiến lược IT là điều phải có để đầu tư và duy trì nguồn vốn.
Trong phase này ta cần ước tính được lợi ích kinh doanh mà ta thu được từ việc sử dụng data warehouse. Có thể ta không định lượng được những lợi ích này, nhưng ta phải chỉ ra những lợi ích một cách rõ ràng.
Sau khi đã hiểu rõ về lợi ích của Data warehouse, tổ chức lúc này sẽ thử nghiệm các ý tường phân tích dữ liệu và tự educate về giá trị khi có data warehouse. Prototyping sẽ giúp tổ chức hiểu được tính khả thi và lợi ích của data warehouse. Điều này sẽ thúc đẩy quá trình educate
Rõ ràng bước này là bước rất quan trọng, muốn đưa ra các giải pháp phù hợp với doanh nghiệp trong thời gian ngắn hạn, trung hạn, hay dài hạn, việc cần làm của team là lấy được chính xác và hiểu rõ mong muốn khách hàng.
Trong phase này ta cần cung cấp một kiến trúc tổng thể đáp ứng các yêu cầu lâu dài của tổ chức. Đồng thời cũng cần deliver các thành phần cần được implement trong thời gian ngắn hạn để mang lại bất kì lợi ích kinh doanh nào. Một blue-print cần xác định được :
Business case
Education & Prototyping
Business requirement
Technical Blueprint
Buil the Vision
History load
Ad-hoc query

tools này có thể generate ra truy vấn cơ sở dữ liệu.
Mọi quy trình quản lý hoạt động là automate hoàn toàn
Sau phase automation rồi, ta vẫn có thểr phải xử lý những tình huống tổ chức có thẻm các yêu cầu busines vì thể mà scope ban đầu có thể phải mở rộng. Nguồn dữ liệu có thể được mở rộng, hoặc tổ chức muốn có thêm data-mart mới...
Mọi thử luôn tiến hóa thay đổi. Vì thế kiến trúc cần được thiết kế để thích nghi và phát triền phù hợp với các yêu cầu business, những sự chuyển hóa này cần được cập nhật liên tục dựa trên feed back của khách hàng.
Automation
Extending scope
Requirement Evolution

Trước khi tìm hiểu về mô hình lưu trữ sản phẩm của Magento, ta sễ cùng điểm qua một số mô hình lưu trữ có từ trước đó.
Style 1:
Magento
Magento - Mô hình lưu trữ sản phẩm1. Motivation

Kiểu này là kiểu đầu tiên ta có thể nghĩ đến khi thiết kế mô hình lưu trữ sản phẩm. Kiểu này cũng là kiểu khá "ngây thơ" khi chập chững để tạo ra trang web đầu tiên với sinh viên đại học.
Có thẻ nhận thấy kiểu này khá dễ thiết kế và dễ hiểu. Nhưng không có tính
linh hoạt. Khi muốn thêm thuộc tính vào sản phẩm thì lúc đó chỉ có thể gọi anh dev vào can thiếp database mà thôi :))
“

Style 2: Product-Attribute
Bản chất của kiểu này tách thuộc tính vầ sản phẩm ra riêng biệt không để chung vào với nhau như style 1. Rõ ràng là tính linh hoạt, customize cao hơn
nhiều so với style 1. Người quản trị có thể dễ dàng thêm thuộc tính vào, mà không phải phụ thuộc vào anh dev nữa.
“
“
Wowww, như thế này thì cải tiến làm gì nữa nhỉ =))
Vẫn đề vẫn còn đó, và ta vẫn cần phải giải quyết. Ta hãy cùng xem Magento giải quyết vấn đề này thế nào nhé!
Nghe ngầu nhưng thực ra khá style này khá giống với style 2, tuy nhiên vẫn có điểm cải tiến:)
Một vài khái niệm đáng chú ý của mô hình này. attribute: chứa tên của thuộc tính attribute_value : chứa giá trị thuộc tính product_attribute_: chứa mối quan hệ giữa product và attribute_value
Nhưng, nếu ta tỉnh ý một chút , ta có thể nhận thấy ở mô hình trên có một điểm yếu. Ở bảng product_attribute, với cùng một sán phẩm tức product_id là như nhau, giá trị attribute_value_id khác nhau thì sản phẩm đó vẫn có giá tiền giống nhau. Như mua trà sữa size S và L vẫn có giá tiền giống nhau =)).
“
2. Improve
EAV viết tắt của cụm từ Entity-Attribute-Value, Đây là mô hình dữ liệu để giải quyết các entity với attribute có thể mở rộng được.“

catalog_product_entity : chính là entity, hay chính là product. eav-attribute
: chính là thông tin chính của thuộc tính hay attribute catalog_product_entity_attribute_decimal,.. : chứa giá trị của thuộc tính, tương đương với attribute_value ở style 2.
“
Nhìn vào mô hình EAV, ta thấy magento chia catalog_product_entity_attribute_decimal,.. theo kiểu dữ liệu. Hmm.. Why??? Magento làm như vậy là để dễ dàng kiểm soát các attribute.
“
“

OK. giờ ta sẽ lấy một ví dụ để hiểu flow tạo các bảng. Đầu tiền là catalog_product_entity table
id và sku đơn giản chỉ là định danh sản phẩm. Ta có thể nhận thấy các thuộc tính của sản phầm đều bỏ hết. Khi insert dữ liệu thì ta insert như này
Tiếp theo là table eav_attribute
Note : ở bảng eav_attribute ta sẽ định nghĩa các thuộc tính của sản phầm. Khi insert
Và cuối cùng là bảng catalog_product_varchar
Tuy nhiên style này không phải viên đạn bạc. Khi truy vấn, tốc độ truy vấn bị
giảm đi nhiều vì phải tổng hợp, join tử nhiều bảng khác nhau.
catalog_product (entity_id, sku, type_id, is_active, sort_order, visibility, created_at,
updated_at
)
( 'entity_1', 'sku001', 'simple', 1, 0, 1)
<br>
( 'entity_2', 'sku002', 'simple', 1, 0, 1)
eav_attribute (
eav_att_id, code, label, type, is_required, is_unique, note
)
('eav_1', ‘name’, ‘Name’, ‘varchar’, 1, 0),('eav_2', ‘description’, ‘Description’, ‘text’, 0,
0),
('eav_3', ‘price’, ‘Price’, ‘decimal’, 1, 0),
('eav_4', ‘image’, ‘Image’, ‘varchar’, 0, 0)
catalog_product_varchar (
id, attribute_id, store_id, entity_id, value
)

Khi insert
OK, đén đây ta đã biết về mô hình EAV rồi. Khi nãy ta có nói Magento sử dụng EAV, hay cũng có nhưng vẫn có điểm yếu, trade-off thôi mà, đó là query chậm vì join nhiều bảng. Vậy Magento handle nó như nào?
(1, 'eav_1', 1, 'entity_1', ‘Tra sua’),(2, 'eav_2', 1, 'entity_1', ‘Tra sua tran chau vi bac
ha’),
(3, 'eav_3', 1, 'entity_1', 100),
(4, 'eav_4', 1, 'entity_1', ‘img01.jpg’)
Concept : flat tables về bản chất là một bảng lớn, với mỗi hàng chứa tất cả thông tin cần thiết của một sản phầm hay một category. Một flat catalog được cập nhật tự động — mỗi phút hoặc theo cron job. Các flat tables tăng tốc thời gian truy vấn, thay vì phải join nhiều bảng, ta có thể đơn giản chỉ cần 1 câu lệnh select thuẩn túy.
“

Quá trình để đưa dữ liệu từ source của khách hàng đến production trong DW có thể tóm gọn trong các bước sau
Step 1: Dữ liệu từ source của customer được đưa vào Azure Blob Storage hoặc Azure Data Lake. Ở đây dữ liệu được lưu trữ dưới dạng file.Step 2: Dữ liệu từ Azure Blob Storage được đưa bảng raw table của DWStep 3: Dữ liệu cần được clean và transform trước khi được đưa vào bảng staging tableStep 4: Dữ liệu ở bảng staging sau khi được validate, được chuyển sang bảng production trong DW
Detail
Step 1: Khi lưu trữ ở dạng file, ưu tiên sử dụng parquet vì parquet cho ta sự tối ưu về bộ nhớ cũng như thời gian truy xuất, không những thế sử dụng file parquet sẽ giúp ta tránh được các lỗi không mong muốn với dữ liệu varchar, nvarchar. Điển hình với các fields có type varchar hoặc nvarchar, trong đó xuất hiện các kí tự đặc biệt như '\r\n' hay '\n' , việc sử dụng file text hay csv sẽ rất khó khăn Note : Hiện nay Micsrosoft chưa hỗ trợ việc sử dụng file parquet, orc, hay avro khi bulk insert với SQL server. ReferenceKhi đưa dữ liệu từ source của customer vào raw của khách hàng, ta không nên transform dữ liệu rồi đưa vào file. Việc này nhằm giúp ta dễ dàng quản lý luồng dữ liệu, thay vì transform
Data warehouse - The process from the customer's source to the production table

ở nhiều bước lẻ tẻ khác nhau, ta nên transform ở bước duy nhất, vừa giúp hạn chế lỗi, đồng thời giúp ta có thể sửa lỗi và update dễ dàng.Không dùng câu lệnh _SELECT * FROM TABLE_NAME, ta cần select rõ ràng các trường dữ liệu cần thiết. Điều này là bởi khi cơ sở dữ liệu của khách hàng có sự update, thì khi insert vào raw hay staging table xảy ra lỗi ( không missmatch các trường dữ liệu)Step 2: Ở bước này, dữ liệu ở flat files được bulk insert vào bảng raw table. Để buik insert ta cần tạo ra EXTERNAL DATA SOURCE , ở EXTERNAL DATA SOURCE ta cần khai báo location thư mục nơi chứa các file dữ liệu đã được tạo ra ở step 1 . Ví dụ : Một EXTERNAL DATASOURCE có location : https://storage256.blob.core.windows.net/containerdata/outputFolder/umich_database.
Create External Data Source
Step 3: Cần chú ý khi clean và transform trước khi đưa vào staging. Tốt nhất ta nên chuẩn bị 1 file json chứa tên bảng cũng như các câu lệnh query tương ứng với bảng đó.
Kiểm tra kĩ về sự tương ứng giữa các kiểu dữ liệu. Như source của customer sử dụng MySQL server, trong khi ta sử dụng SQL Server.
Mapping data type between MYSQL and SQL
Step 4: ở bảng staging, ta cần viết các thủ tục stored proc để validate dữ liệu đã được extract đúng. Với các key column có bị dulicate không,trong các trường mandatory có bị null không? Để tracking được các lỗi xảy ra, ta có insert các trường bị lỗi vào bảng vật lý.

1. SSH SSH(Secure Socket Shell) là một giao thức tầng application. Được tạo ra như một cách giao tiếp an toàn với dữ liệu được mã hóa. Với ai đã dủng hệ điều hành ubuntu(linux) thì chắc hản đã quá quen với việc sử dụng ssh để login vào các máy ảo thông qua câu lệnh:
ssh user_name@ip_address
Cũng như khi ta cài cụm Hadoop thì ta cũng dùng ssh để auto khởi đồng data node nằm trền các máy khác nhau trong cụm.
Nhưng ngoài khả năng của các remote login program, thì SSH còn cung cấp thêm các tính năng khác như
SSH TunnelingTCP port forwarding ( Part 4 )
SSH protocol xác thực bằng các thuật toán mã hóa như
DSAECDSARSA
Cách đáng tin cậy hơn vẫn là dùng RSA.
Với việc mã hóa dữ liệu, SSH sử dụng 3 kĩ thuật:
Data Warehouse - Networking Related Knowledge

SSH Symmetrical Encryption ( khóa đối xứng)SSH Asymmetrical Encrytion ( khóa bất đối xứng)SSH Hashing ( sử dụng HMAC để xác thực tin nhắn)
2. SQL remote host Ta có thể config cấu hình cho phép máy tính khác truy cập từ xa để quản lý database(remote MSSQL server).
Bằng cách open port 1433( default port của SQL), sau đó allow remote connection cho server
Note: Check state TCP/IP trong SQL Server Configuration Manager nếu disable thì cần enable và để trống TCP Dynamic port.“

3. IP table
IP table là một ứng dụng rất phổ biến trên Linux OS, cho phép ta cấu hình allow/block luồng dữ liệu đi qua mạng.
Dựa trên các tables, chains và rules mà IP table có thể đọc, thay đổi và chuyển hướng allow/block luồng dữ liệu đi qua mạng. Mỗi một table sẽ có chứa nhiều chain chứa các rule khác nhau quyết định cách thức xử lý gói tin (dựa trên giao thức, source, destination …) IP Table gồm có 5 bảng với mục đích và thứ tự xử lý khác nhau.
Filter là bảng được dùng nhiều nhất trong IP table. Bảng này dùng để quyết định xem có nên cho một gói tin tiếp tục đi tới đích hay chặn gói tin này lại. Đây là chức năng quan trọng nhất của IP tables
“
NAT tables: được dùng để phiên dịch địa chỉ mạng, khi các gói tin đi vào bảng này, gói tin sẽ được kiểm tra xem có cần thay đổi và sẽ thay đổi địa chỉ nguồn, đích của gói tin như thế nào
“
Manage table: dùng để điều chỉnh một số trường trong IP header như TTL, TOS(Type of Service) dùng để quản lý chất lượng dịch vụ hoặc dùng để đánh dấu các gói tin để xử lý thêm trong các bảng khác.
“
Raw table: Theo mặc định, IP tables sẽ lưu lại trạng thái kết nối của các gói tin, tính năng này cho phép iptable xem các gói tin rời rạc là một kết nối, một session chung để dễ dang quản lý. Tính năng theo dõi này được sử dụng ngay từ khi được gửi tới hệ thống trong bảng raw Security Table: bảng security dùng để đánh dấu policy của SELinux lên các gói tin, các dấu này sẽ ảnh hưởng đến cách thức xử lý của SELinux. Bảng này có thể đánh dấu theo từng gói tin hoặc
“

Các chains trong iptables:
4. Port forwading
OK, phần này là phần rất thú vị. Như trên ta đã biết SSH cung cấp tính năng Port Forwarding.
theo từng kết nối.
Input: chain này dùng để kiểm soát hành vi của những kết nối tới máy chủ. Ví dụ một user cần kết nối SSH tới máy chủ, iptables sẽ xét xem IP và port của user này có phù hợp với một rule trong chain INPUT không.
“
FORWARD : chain này được dùng cho các kết nối chuyển tiếp sang một máy chủ khác( tương tự như router, thông tin gửi tới router sẽ được forward đi nơi khác). Ta chỉ cần định tuyến hoặc NAT một vài kết nối thì ta mới cần tới chain này
“
OUTPUT: chain này sẽ xử lý các kết nối đi ra ngoài. Ví dụ khi truy cập vào 1 trang web example.com , chain này sẽ kiểm tra xem có rules nào liên quan tới http, https và example.com hay không trước khi quyết định cho phép hoặc chặn kết nối.
“
PREROUTING: header của gói tin sẽ được chỉnh sửa tại đây trước khi khi việc routing được diễn ra POSTROUTING: Header của gói tin sẽ được chỉnh sửa tại dây sau khi việc routing được diễn ra.
“
Port Forwarding là quá trình chuyển tiếp của 1 port cụ thể từ hệ thống này sang “

Ta có 2 kiểu
Local Port Forwarding
Remote Port Forwarding
Ví dụ: Trên thực tế, một trường hợp rất thường xuyên áp dụng “local port forwarding” đó là Mysql tunnelling. Ví dụ từ Desktop A, ta có thể ssh lên Server B, trên B chạy Mysql ở cổng 3306 và chỉ chấp nhận kết nối từ local. Vậy một cách đơn giản, để kết nối Mysql trên B từ A, đó là dùng port forwarding
Sau khi có kết nối ssh, tiếp theo là dùng lệnh mysql trên A để kết nối đến dịch vụ Mysql trên server
một mạng khác. Điều này cho phép người dùng bên ngoài có thể dễ dàng truy cập vào hệ thống mạng nội bộ bên trong thông qua bộ định tuyến NAT.
Local Port Forwarding được sử dụng để chuyển tiếp 1 port từ máy local đến máy server( hoặc ngược lại). Ta có thể sử dụng Local Port Forwarding để: • Kết nối với dịch vụ trong mạng nội bộ từ bên ngoài • Sử dụng để chuyển file qua internet
“
ssh -L 3307:localhost:3306 [email protected]
B
Remote Port Forwarding
SSH remote Port Forwarding cho phép ta chuyển lưu lượng truy cập từ 1 port ở máy ta lên SSH server
Điều này cho phép bất cứ ai truy cập vào máy chủ public.example.com vào port 8080 sẽ đượcc chuyển tiếp đến cổng 80 trên máy ta.
Ví dụ: Khi muốn demo từ xa cho khách hàng. Do code đang nằm trên máy ta, và ta không có thời gian deploy lên server để demo cho khách hàng. Ta có thể sử dụng Remote Port Forwarding để chuyển cổng web trên máy local lên server để demo cho khách hàng
5. Reference
mysql -h 127.0.0.1 -P 3307 -uroot -p
ssh -R 8080:localhost:80 public.example.com
ssh -R 80:localhost:80 user@ip_public
https://viblo.asia/p/ssh-so-luoc-mot-so-cau-lenh-co-ban-phan-1-maGK7JLD5j2ttps://www.sqlshack.com/how-to-connect-to-a-remote-sql-server/https://wiki.matbao.net/kb/cach-enable-remote-sql-server-2/https://viblo.asia/p/ssh-tunneling-local-port-forwarding-va-remote-port-forwarding-07LKXJ3PlV4https://github.com/cloudcraftteam/System-Engineer-Cheat-Sheets/blob/master/Firewall/IPtables_basic.txthttps://viblo.asia/p/ssh-port-forwarding-157G5nalvAje
“
Link turtorial : MOLAP TurtorialTurtorial của Microsoft viết rất chi tiết step by step, nên mình chỉ note lại một số điểm tiên quyết và khiến mình take time Yoo
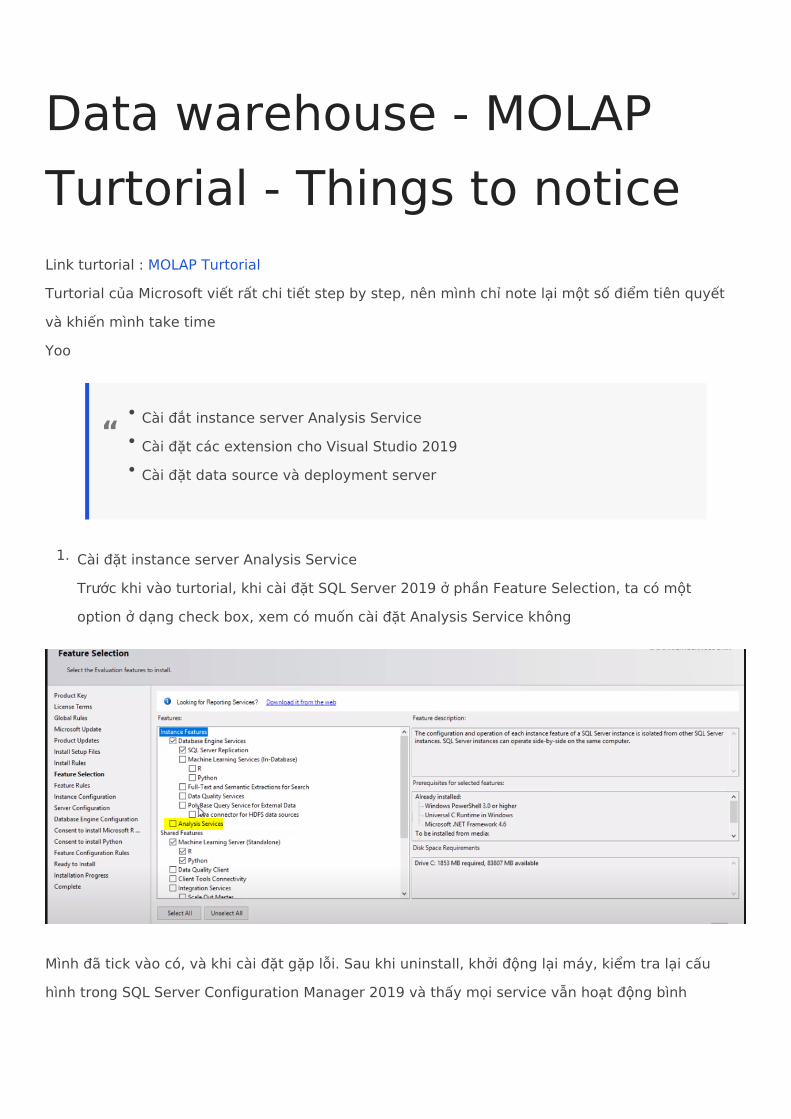
1. Cài đặt instance server Analysis Service Trước khi vào turtorial, khi cài đặt SQL Server 2019 ở phần Feature Selection, ta có một option ở dạng check box, xem có muốn cài đặt Analysis Service không
Mình đã tick vào có, và khi cài đặt gặp lỗi. Sau khi uninstall, khởi động lại máy, kiểm tra lại cấu hình trong SQL Server Configuration Manager 2019 và thấy mọi service vẫn hoạt động bình
Data warehouse - MOLAP Turtorial - Things to notice
Cài đắt instance server Analysis ServiceCài đặt các extension cho Visual Studio 2019Cài đặt data source và deployment server
“
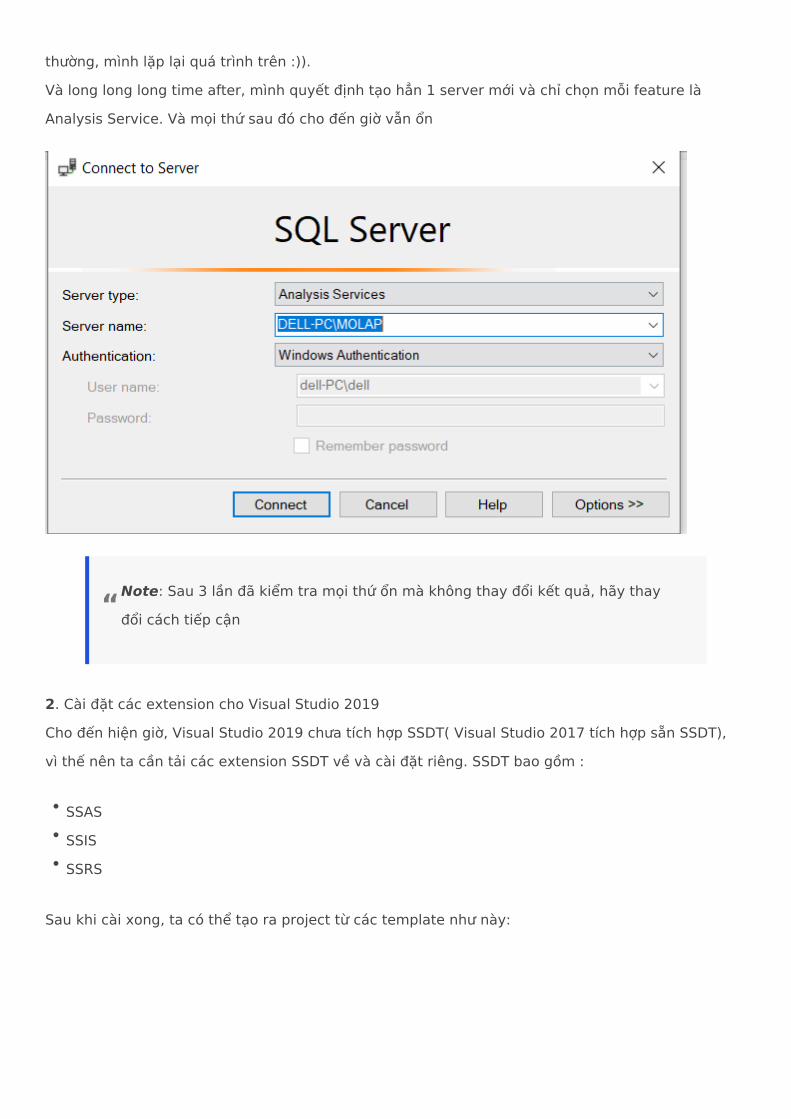
thường, mình lặp lại quá trình trên :)). Và long long long time after, mình quyết định tạo hẳn 1 server mới và chỉ chọn mỗi feature là Analysis Service. Và mọi thứ sau đó cho đến giờ vẫn ổn
2. Cài đặt các extension cho Visual Studio 2019 Cho đến hiện giờ, Visual Studio 2019 chưa tích hợp SSDT( Visual Studio 2017 tích hợp sẵn SSDT), vì thế nên ta cần tải các extension SSDT về và cài đặt riêng. SSDT bao gồm :
SSASSSISSSRS
Sau khi cài xong, ta có thể tạo ra project từ các template như này:
Note: Sau 3 lần đã kiểm tra mọi thứ ổn mà không thay đổi kết quả, hãy thay đổi cách tiếp cận“
3. Cài đặt data source và deployment server Khi bước vào turtorial, ta sẽ cần define data source cũng như server ta sẽ deploy. Trong turtorial, thì default là localhost nhưng hãy thay vào đó bằng server và database.
and

và khi deployment server
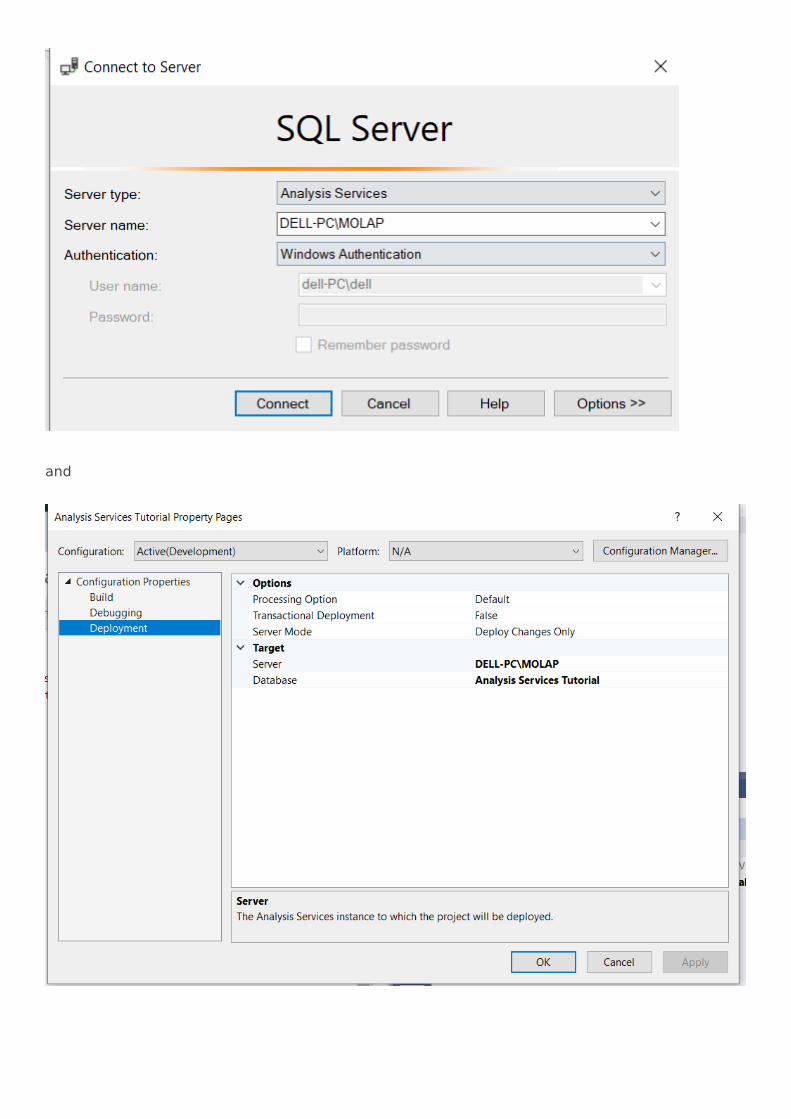
and

Đây chỉ là một vài note nhỏ nhưng có thể khiến ta không take time khi gặp phải !

Data warehouse là một loại data management system được design để có thể hỗ trợ các hoạt động Business intelligence , đặc biệt là analytics. Các data warehouses chỉ nhằm mục địch thực hiện các truy vấn và phân tích. Khả năng phân tích của data warehouse cho phép các tổ chức thu được những business insights có giá trị từ dữ liệu của họ để cải thiện việc đưa ra quyết định
BI(Business Intelligence is a set of a processes, architectures, và technologies chuyển đồi dữ liệu thành các thông tin có ích chuyển hóa thành hoạt động business mang lại lợi ích.
Data warehouse mang lại nhiều lợi ích quan trọng:
Cung cấp thông tin business nâng caoTiết kiệm thời gianNâng cao chất lượng và sự nhất quán của dữ liệu
Data warehosue Design
1. Các khái niệm cơ bản1.1. Định nghĩa Data Warehouse
1.2. Định nghĩa Businness Intellgence
2. Lợi ích của hệ thống Data Warehouse và Business Intelligence

Cung cấp lợi thế cạnh tranhNâng cao trải nghiệm khách hàng
Dữ liệu nguồn đồ vào DW có thể được chia thành 4 nhóm chính:
Production data : Các loại data này đền từ các hệ thống vận hành của doanh nghiệp.Internal data : Trong mỗi tổ chức, khách hàng lưu giữ các báo cáo, progiles của customer, các giữ liệu nội bộ khác.Archived data : Dữ liệu được lưu trữ định kì của hệ thống vận hành hiện tạiExternal data : Dữ liệu này là dữ liệu từ các external source được tạo ra bởi các bộ phận ngoài, các dữ liệu này có thể là các dữ liệu thống kế liên quan đến lĩnh vực doanh vực và hay được các giám đốc sử dụng. Dữ liệu nguồn có thể là bất cứ hệ quản trị cơ sở dữ liệu nào như MySQL, Oracle, MSSQL,...
Một DW như một kho dữ liệu trung tâm, nơi dữ liệu được lưu trữ từ một hoặc nhiều nguồn không đồng nhất. Hệ thống DW lưu trữ cả dữ liệu hiện tại và dữ liệu lịch sử. DW chỉ có thể đọc, không được sử dụng để ghi hay update thông thường. DW có những tính chất điển hình:
Subject-Orieted: Mục tiêu của kho dữ liệu nhằm mô hình hóa và phân tích dữ liệu. Vì thế dữ liệu trong data warehouse cung cấp cái nhìn ngắn gọn và đơn giản về một chủ đề cụ thể như
3. Kiến trúc của hệ thống Data Warehouse và Business Intelligence3.1 Data source – Dữ liệu nguồn
3.2 Data Warehouse – Kho dữ liệu tập trung
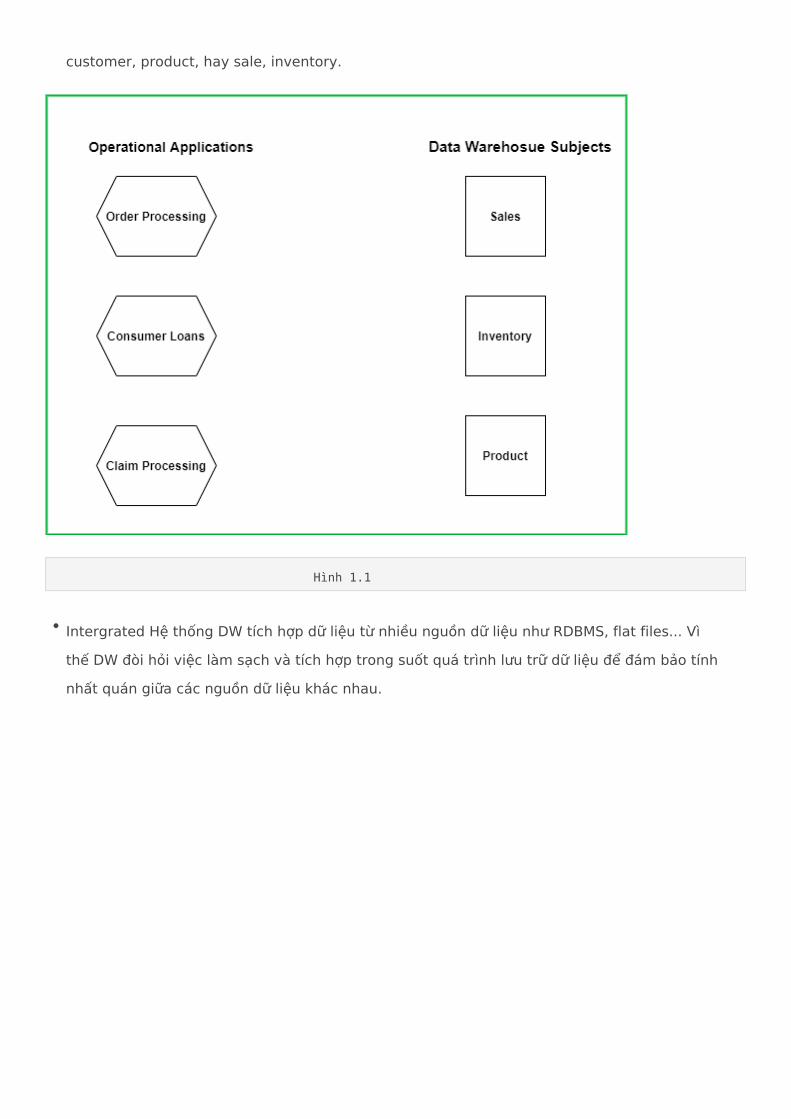
customer, product, hay sale, inventory.
Intergrated Hệ thống DW tích hợp dữ liệu từ nhiều nguồn dữ liệu như RDBMS, flat files... Vì thế DW đòi hỏi việc làm sạch và tích hợp trong suốt quá trình lưu trữ dữ liệu để đám bảo tính nhất quán giữa các nguồn dữ liệu khác nhau.
Hình 1.1
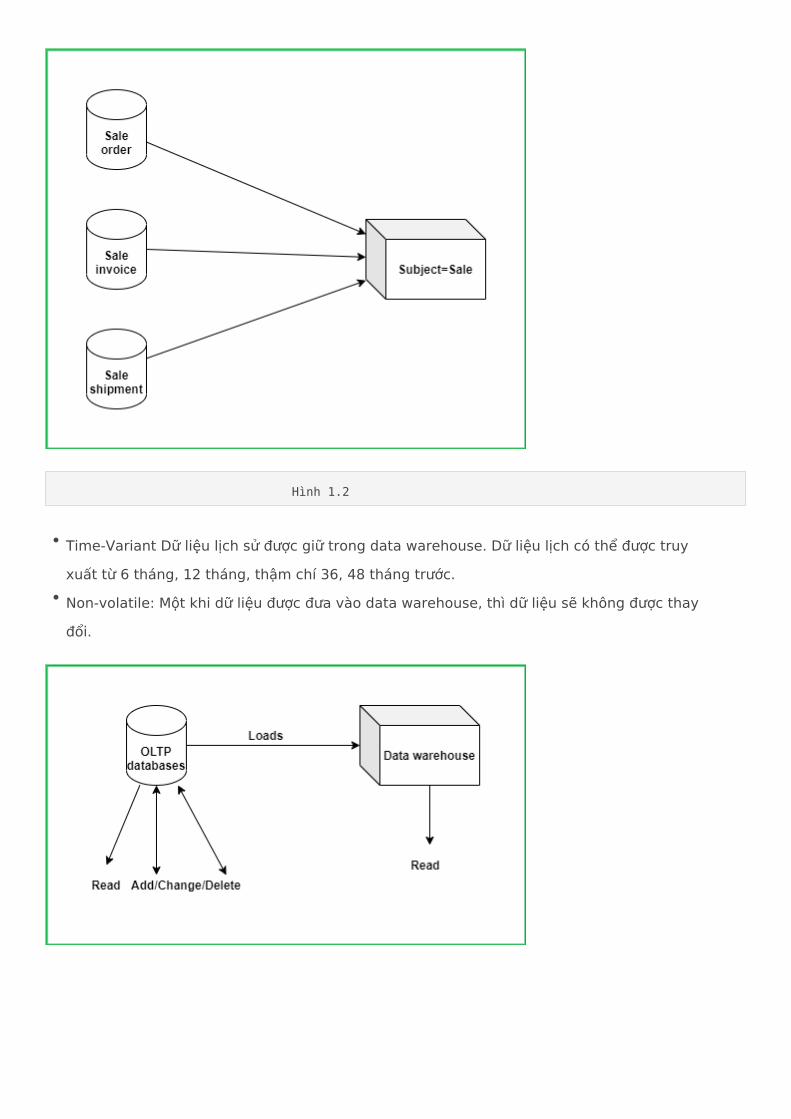
Time-Variant Dữ liệu lịch sử được giữ trong data warehouse. Dữ liệu lịch có thể được truy xuất từ 6 tháng, 12 tháng, thậm chí 36, 48 tháng trước.Non-volatile: Một khi dữ liệu được đưa vào data warehouse, thì dữ liệu sẽ không được thay đổi.
Hình 1.2

BI bao gồm một loạt các công cụ và ứng dụng và phương thức cho phép tổ chức thu thập thông tin từ hệ thống nội bộ và nguồn bên ngoài; chuẩn bị sẵn sàng chp việc phân tích, phát triển và chạy các truy vấn đối với dữ liệul tạo các báo cáo, bảng điều khiển và trực quan hóa dữ liệu
Mô hình hóa Data warehouse là quá trình thiết kế các lược đồ thông tin chi tiết và tóm tắt của DW. Mục tiêu của mô hình hóa DW là phát triển một lược đồ mô tả thực tế mà DW cần hỗ trợ.
Hình 1.3
3.3 Tầng Business Intelligence(BI)
Hình 1.4
4. Thiết kế conceptual hệ thống Data Warehouse4.1. MultiDim model

Mô hình hóa conceptual DW đòi hỏi một mô hình rõ ràng. Vì thế trong hệ thống này, MultiDim model được sử dụng vì model này đủ mạnh để biểu diễn ở mức conceptual tất cả các yếu tố cần thiết trong kho dữ liệu và OLAP applications (dimensions, hierarchies, và facts với measures liên quan). 4.2. Key concepts in MultiDim model Các thành phần cơ bản trong mô hình MultiDim :
Schema : bao gồm một tập hợp các dimensions và một tập các factsDimension : bao gồm 1 level hoặc một hoặc nhiều phân cấpLevel : mức tương đương với một loại thực thể tỏng ER model.Fact : liên quan đến một vài levels(ví dụ: Sales fact liên quan đến Employee, Customer, Order, Product và Time levels)Hierarchy : bao gồm một số levels liên quan. Level thấp hơn được gọi là con, level cao hơn gọi là cha. ( ví dụ lelvel con Product liên quan đến lelvel cha là Category)
Dựa trên cách mà các data cube được lưu trữ, một vài cách tiếp cận phổ biển để implement một mô hình đa chiều, đó là:
Hình 1.5 Phases in data warehouse design
5. Thiết kế logical hệ thống Data Warehouse5.1. Cách tiếp cận trong biểu diễn mô hình MultiDim

Relational OLAP (ROLAP) : lưu trữ dữ liệu trong CSDL quan hệ, hỗ trợ các phần mở rộng cho SQL và các phương pháp truy cập đặc biệt để triển khai hiệu quả mô hình dữ liệu đa chiều và các hoạt động liên quan.Multidimensional OLAP (MOLAP): lưu trữ dữ liệu trong cấu trúc dữ liệu đa chiều chuyện biệt( ví dụ arrays) và triển khai các hoạt động OLAP trên cấu trúc dữ liệu đó.Hybrid OLAP ( HOLAP) : kết hợp cả 2 cách tiếp cận ROLAP và MOLAP Mỗi cách tiếp cận đều có những ưu, nhược điểm riêng. Tuy vào mục đích, yêu cầu mà lựa chọn phù hợp từng cách tiếp cận.
5.2.1. Các lược đồ CSDL trong Data Warehouse Biểu diễn dữ liệu quan hệ của mô hình đa chiều có thể dựa trên các lược đồ :
Star schema: 1 bảng fact trung tâm và 1 set các bảng dimensions.Snowflake schema: tránh được sự dư thừa trong start schemas bằng cách normalize các bảng dimensions. Vì thế mà các bảng dimensions được biểu diễn bằng một vài bảng liên quan bằng các ràng buộc.Starflake schema: kết hợp star và snowflake schema. Một vài abnrg dimensions sẽ được normailize, trong khi một số bảng khác thì không.Constellation schema: có nhiều bảng fact cùng chia sẻ các bảng dimension tables.
Star schema
Là mô hình đơn giàn nhất được sử dụng trong DWH. Star 3w schema được sử dụng rộng rãi trong data marts.
5.2. Thiết kế thành phần Data Warehouse
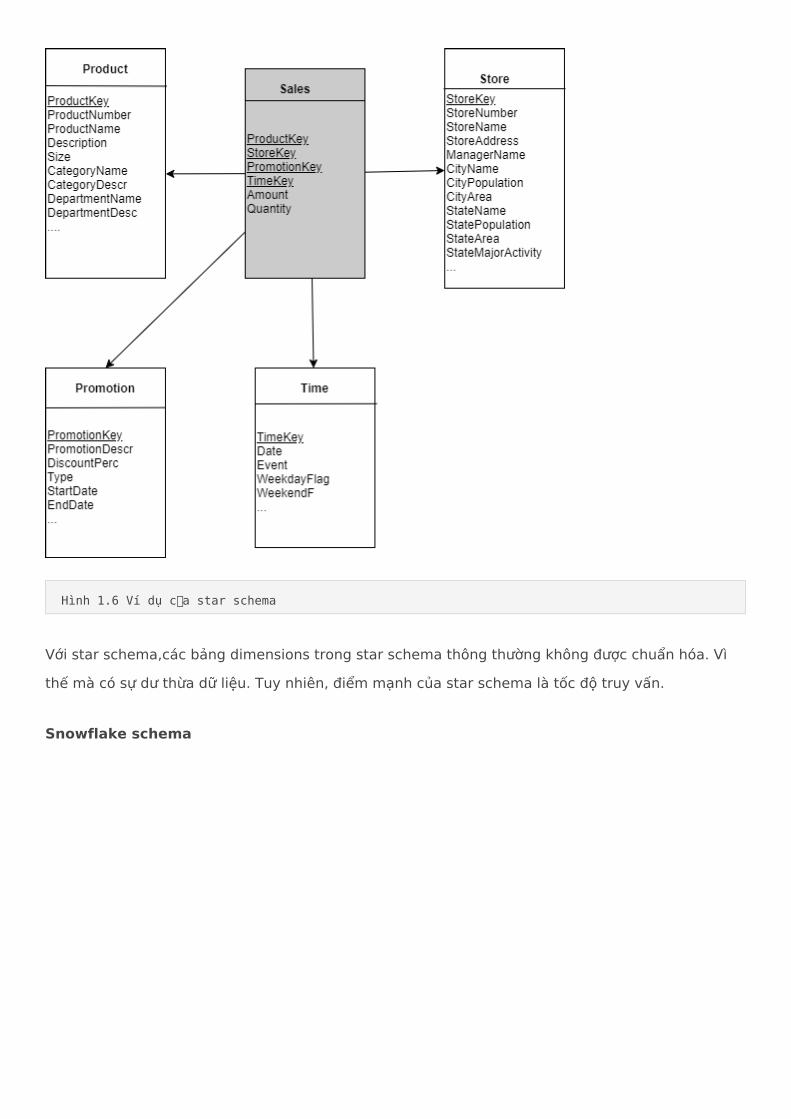
Với star schema,các bảng dimensions trong star schema thông thường không được chuẩn hóa. Vì thế mà có sự dư thừa dữ liệu. Tuy nhiên, điểm mạnh của star schema là tốc độ truy vấn.
Snowflake schema
Hình 1.6 Ví dụ của star schema
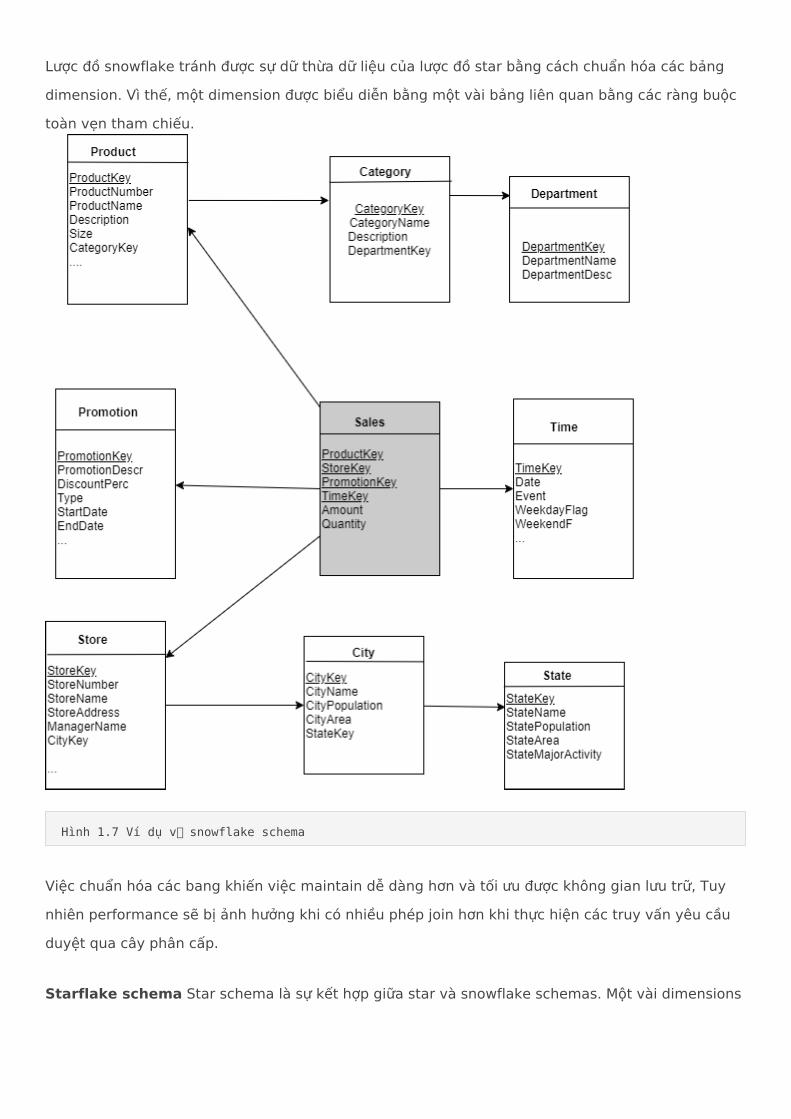
Lược đồ snowflake tránh được sự dữ thừa dữ liệu của lược đồ star bằng cách chuẩn hóa các bảng dimension. Vì thế, một dimension được biểu diễn bằng một vài bảng liên quan bằng các ràng buộc toàn vẹn tham chiếu.
Việc chuẩn hóa các bang khiến việc maintain dễ dàng hơn và tối ưu được không gian lưu trữ, Tuy nhiên performance sẽ bị ảnh hưởng khi có nhiều phép join hơn khi thực hiện các truy vấn yêu cầu duyệt qua cây phân cấp.
Starflake schema Star schema là sự kết hợp giữa star và snowflake schemas. Một vài dimensions
Hình 1.7 Ví dụ về snowflake schema
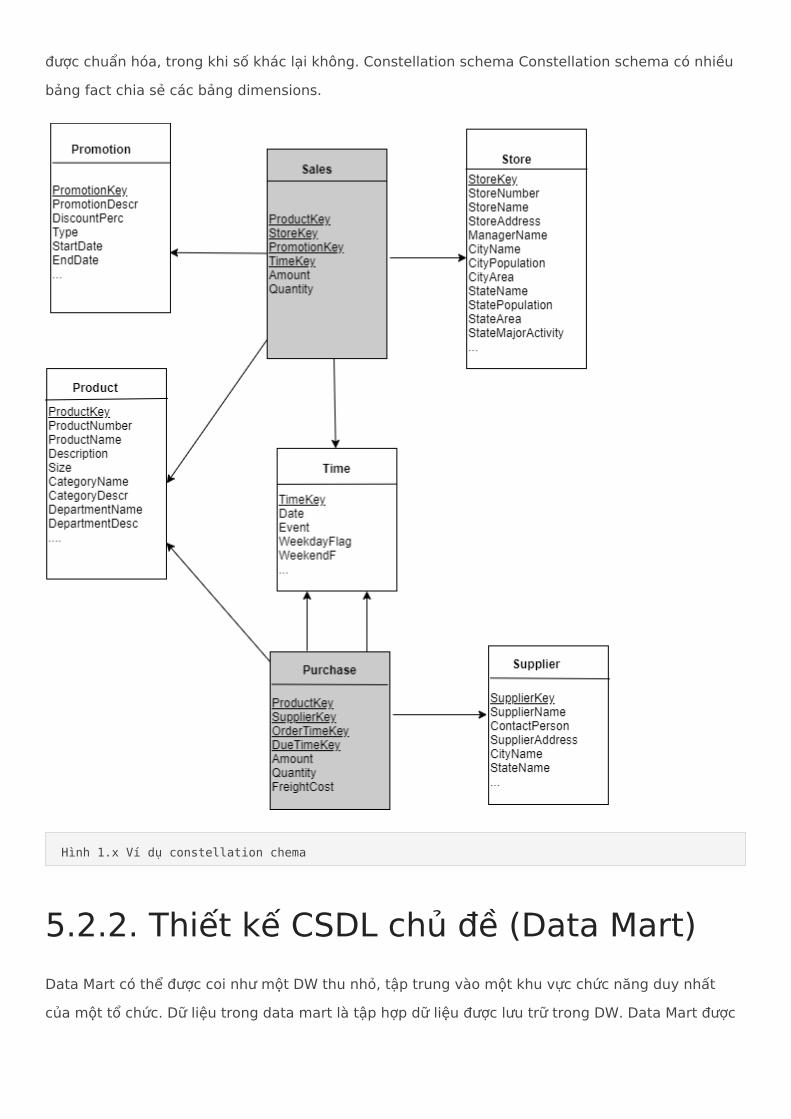
được chuẩn hóa, trong khi số khác lại không. Constellation schema Constellation schema có nhiều bảng fact chia sẻ các bảng dimensions.
Data Mart có thể được coi như một DW thu nhỏ, tập trung vào một khu vực chức năng duy nhất của một tổ chức. Dữ liệu trong data mart là tập hợp dữ liệu được lưu trữ trong DW. Data Mart được
Hình 1.x Ví dụ constellation chema
5.2.2. Thiết kế CSDL chủ đề (Data Mart)

thiết kế để sử dụng cho một bộ phận, đơn vị, hoặc nhóm người dùng cụ thể( như Sales, Marketing, HR hoặc Finance..). Một data mart có thể được tạo từ một data warehouse theo hướng tiếp cận top-down hoặc ngược lại được xây dựng từ data sources trước khi xây dựng DW. Có 3 loại data marts dựa trên mối quan hệ với DW và data sources được sử dụng để tạo ra hệ thống : dependent, independent, và hybrid. Dependent Data Marts
Được tạo ra từ một enterprise DW đã tồn tại. Đây là cách tiếp cận top-down bằng việc lưu trữ tất cả dữ liệu business ở một vị trí trung tâm, sau đó trích xuất sau một phần dữ liệu được xác định rõ ràng để phân tích. Từ DW, một tập hợp dữ liệu cụ thể được tổng hợp, tái cấu trúc và load vào data mart. Nó có thể là một logical view hoặc tập con vật lý của DW • Logical view : một bảng/view virtual được tách biệt riêng về mặt logic, nhưng không về mặt vật lý khỏi kho dữ liệu • Physical subset : dữ liệu được trích xuất vào một cơ sở dữ liệu vật lý riêng biệt với DW
Independent Data Marts
Một independent Data Mart là một hệ thống độc lập, được tạo ra mà không sử dụng DW, tập trung vào 1 chủ đề hoặc một business function. Dữ liệu được extract từ internal hoặc external data source, hoặc cả hai, được xử lý, và load vào data mart repository. Xây dựng và phát triển independent data mart không khó. Chúng có lợi khi đạt dược các mục tiêu ngắn hạn nhưng có thể trở nên cồng kềnh khó quản lý khi nhu cầu kinh doanh mở rộng và trở nên phức tạp hơn.
Hybrid Data Marts
Kết hợp dữ liệu từ DW đã tồn tại và các hệ thống hoạt động khác.
Tương tự như DW, một data mart có thể được tổ chức bằng cách sử dụng star, snowflake, starflake, hoặc các lược đồ khác. Lợi ích của star schema đó là việc sử dụng ít phép join cũng như ít sự phụ thuộc giữa các bảng dimensions.
Việc thiết kế CSDL tích hợp không phải là việc dễ dàng. Có 2 cách tiệp cận để xây dựng nên CSDL
5.2.3. Thiết kế CSDL tích hợp(Enterprise Model-EM)
5.2.3.1 Hướng tiếp cận

tích hợp
Top-down : Xây dựng DW từ rất nhiều data source, đòi hỏi có cái nhìn tổng quan cũng như hiểu biết về nghiệp vụBottom-up : Lây data mart làm trung tâm, kết hợp các data mart lại để có DW. Việc xây dựng nên các data mart là nhanh, tuy nhiên việc kết hợp là không hề đơn giản.
Không có cách tiếp cận nào là tốt hơn cả, tùy vào quy mô, thời gian, nguồn lực của doanh nghiệp mà chọn cách tiếp cận phù hợp.
Top-down
Với cách tiếp cận này, mô hình CSDL được coi là mô hình có tính thích ứng mạnh nhất với sự thay đổi business. Đó là lí do mà các tổ chức lớn thích làm theo cách tiếp cận này Việc tạo ra data mart từ data warehouse rất dễ. Tuy nhiên, cost và time để desig và maintain rất cao, đây chính là điểm yếu với cách tiếp cận này.
Bottom-up
Với cách tiếp cận này, các report được tạo ra nhanh chóng. Cost và time để thiết kể mô hình là tương đối thấp.
Phụ thuộc vào nhiều yếu tố như lượng dữ liệu, độ phức tạp phân tích, vấn đề bảo mật hay ngân sách mà có những options khác nhau để thiết kế hệ thống
Traditional data warehouse
Yêu cầu cung cấp tài nguyên IT như máy chủ, phần mềm on-premise, một DW truyền thống được đặt tại chỗ để thu thập, lưu trữ, và phân tích dữ liệu.
Virtual data warehouse
Được sử dụng như là một sự thay thế cho DW cổ điển. Về cơ bản, là rất nhiều DB được connect ảo với nhau, vì thế mà có truy vấn như trên một hệ thống duy nhất.
Cloud data warehouse
Cloud DW là khái niệm mới và luôn thay đổi. Cloud DW có thể thu thập, lưu trữ và phân tích dữ liệu trong môi trường cloud mà không cần đầu từ vào phần cứng hoặc các nhân viên IT chuyên biệt.
5.2.3.2. Các loại Data Warehouse

Cloud DW có thể được xây dựng để làm việc với dữ liệu rất lớn. Tuy nhiên mỗi DW được xây trên các nền tảng cloud khác nhau sẽ khác nhau như Google, Oracle, Microsoft..
Classic và Cloud DW Analysis“

Kho dữ liệu trung chuyển là nơi dữ liệu sẽ được lưu trữ cũng như làm sạch và thực hiện các bược biến đổi trước khi đưa vào DW. Khu vực này được sử dụng để xử lý dữ liệu trong quá trình trích xuất, biến đổi và tải (ETL).
DSA được thiết kế bởi vì lợi ích mà nó mang lại. Động lực chính khi ta sử dụng DSA đó là tăng hiệu quả của quá trình xử lý ETL, đồng thời đám bảo tính toàn vẹn dữ liệu và hỗ trợ các hoạt động chất lượng dữ liệu. Các chức năng của DSA:
Consolidation
Một trong những chức năng chính của DSA đó là hợp nhất dữ liệu từ nhiều nguồn dữ liệu. Chức năng này của DSA hoạt động như một “bể” lớn trong đó dữ liệu từ nhiều hệ thống nguồn có thể đượcc tạm thời đặt để xử lý thêm.
5.2.4. Thiết kế CSDL trung chuyển (Data Staging Area – DSA)

Recoverability
Dữ liệu cần được phục hồi trong trường hợp bị hỏng. Vì vậy các bước ở DSA đóng vai trò là điểm khôi phục trong trường hợp dữ liệu bị hỏng trong các giai đoạn sau.
Backup
Backup cho phép lưu, nén và lưu trữ dữ liệu xuống cập CSDL.
Auditing
Dữ liệu trong DSA có thể làm quá trình đánh giá trở nên đơn gian hơn nhiều bằng cách so sánh các tệp đầu vào ban đầu( với các quy tắc chuyển đổi) với các dữ liệu đầu ra.
Data quality
Chất lượng dữ liệu đóng vai trò hết sức quan trọng trong DW. DSA là nơi mà dữ liệu sẽ được làm sạch, kiểm tra, hợp nhất trước khi đưa vào DW Điều này làm giảm đi rủi ro về mặt dữ liệu(một số trường dữ liệu unique bị trùng lặp, một số trường mandatory bị NULL ..)
Thông thường, DSA được thiết kế với 2 lớp đó là RAW và STAGE.
Khu vực RAW, là nới mà các dữ liệu nguồn đổ về. Dữ liệu ở đây thực hiện các bước làm sạch và chuyển hóa, sau đó được load vào khu vực STAGE.
Ở khu vực STAGING các bảng dữ liệu có thể được thêm mới, đây là các bảng chứa những dữ liệu được transform và tổng hợp.
Quá trình ETL dữ liệu cũng chính quá trình cơ bản và xuyên suốt từ khi DW được xây dựng. Quá trình ETL gồm 3 bước: Extract – Transform – Load.
Là hoạt động trích xuất dữ liệu từ hệ thống nguồn để sử dụng tiếp trong môi trường DW. Đây cũng là hoạt đọng đầu tiên trong quá trình ETL. Việc thiết kế và tạo quá trình trích xuất thường là một
5.2.5. Thiết kế tiến trình Thu thập, làm sạch và tích hợp dữ liệu(ETL)
5.2.5.1. Extract

trong những tác vụ tiêu tốn nhiều thời gian. Hệ thống nguồn có thẻ rất phức tạp và không có nhiều tài liệu mô tả, chính vì thế việc xác định những dữ liệu gì là cần thiết để trích xuất là điều không hề dễ. Dữ liệu cần được trích xuất bình thường không chỉ một lần mà còn nhiều lần theo cách định kì để có thể cùng cấp tất cả dữ liệu đã thay đổi vào kho dữ liệu và giữ cho nó được cập nhật. Hệ thống nguồn nếu có thay đổi về mặt cấu trúc pahri đảm bảo được luồng dữ liệu và các dữ liệu cần lấy không được thay đổi.
Các phương pháp trích xuất phụ thuộc nhiều vào hệ thống nguồn cũng như nhu cầu trong môi trường kinh doanh. Phương pháp trích xuất có thể được chia thành loại :
Logical ExtractionPhysical Extraction
Logical Extraction
Phương pháp này có 2 loại:
Full extractionIncremental extraction
Full extraction
Dữ liệu được trích xuất hoàn toàn từ hệ thống nguồn. Bởi vì quá trình trích xuất này phản ảnh tất cả dữ liệu hiện có trên hệ thống nguồn, nên không cần theo dõi các thay đổi với nguồn dữ liệu ể từ lần trích xuất thành công cuối cùng.
Incremental extraction
Tại một thời điểm cụ thể, chỉ những dữ liệu có sự thay đổi kề từ một sự kiện được xác định rõ trong lịch sử mới được trích xuất. Sự kiện này có thể là lần cuối cùng dữ liệu được trích xuất hoặc một sự kiện kinh doanh phức tạp hơn. Thông thường các sự kiện này còn được gọi là giá trị watermark. Giá trị watermark có thể là timestamp hoặc có thể là id của thực thể. Incremental extraction đòi hỏi việc cần lưu lại các giá trị sự kiện sau khi dữ liệu được trích xuất.
Physical Extraction
Phụ thuộc vào cách chọn phương pháp trích xuất logical và các khả năng, hạn chế ở phái nguồn dữ

liệu có thẻ được trích xuất vật lý bằng hai cơ chế là online và offline.
Online extraction
Dữ liệu được trích xuất trực tếp từ hệ thống nguồn. Quá trình trích xuất có thể trực tiếp kết nối đến hệ thống nguồn để tự truy cập các bảng ở hệ thống nguồn hoặc đến một hệ thống lưu trữ trung gian dữ liệu trung gian theo cách được cấu hình sẵn.
Offline extraction
Dữ liệu được trích xuất không trực tiếp từ hệ thống nguồn nhưng được xây dựng một cách rõ ràng nằm bên ngoài hệ thống nguồn. Dữ liệu đã có sẵn cấu trúc như : flat files, dump files
Từ góc độ kiến trúc, việc transform dữ liệu có thể được thực hiện theo các cách:
Multistage Data Transform in DWPipelined Data Transform in DW
Multistage Data Transform in DW
Dữ liệu được chuyển đổi qua nhiều bước. Một chiến lược thường được áp dụng đó là thực hiện mỗi chuyển đổi như một hoạt độnn SQL riêng biệt và tạo một bảng tạm thời riêng biệt. Các bảng new_table_step trên hình lưu trữ các kết quả tăng dần sau mỗi bước chuyển đổi. Chiến lược này giúp tạo ra các điểm checkpoint, khiến việc monitor và tải khởi đọng dễ dàng hơn. Tuy nhiên, một
5.2.5.2. Loading and Transform
Hình 1.8 Multistage Data Transform

nhược điểm của chiến lược này là việc tốn thời gian và bộ nhớ. Có thể kết hợp nhiều việc chuyển đổi dữ liệu logic thành một câu lệnh SQL hoặc một SQL procedure. Việc này cung cấp hiệu suất tốt hơn so với việc thực hiện đơn lẻ, độc lập các bước. Nhưng nó cũng có thể gây ra những khó khăn trong việc khôi phục các phép biến đổi không thành công.
Pipelined Data Transform in DW
Chiến lược này có thể hiểu là việc loading có thể diễn ra ngay trong khi loading. Điều này khiến quá trình ETL có được performance cao.
Hình 1.9 Pipelined Data Transform
5.3. Thiết kế tầng khai thác và phân tích thông tin5.3.1. Thiết kế CSDL đa chiều với OLAP
5.3.2. Thiết kế tầng khai thác và phân tích thông tin