Embed Size (px)
Citation preview

Data Streams, Data Streams, Message Brokers, Message Brokers, Sensor Nets, and Other Sensor Nets, and Other StrangeStrange Places to Run Places to Run Database QueriesDatabase Queries
Michael FranklinMichael FranklinUC BerkeleyUC Berkeley
July 2003July 2003

Data EverywhereData Everywhere
Increasingly ubiquitous networking at all scales. ad hoc sensor nets, wireless, global Internet
Explosion in numbernumber, typestypes, and locationslocations of data sources and sinks. mobile devices, P2P networks, data centers
Emerging software infrastructure to put it all together. pub/sub, XML, web services, …

Data Management in a Data Management in a Networked WorldNetworked World
Data is thethe crucial resource for emerging networked applications.
Database techniques are all about data organization and access. They can be adapted for network-centric environments. In particular, query processingquery processing can play a central role in
a number of non-traditional settings.
““When processing, storage, and transmission cost When processing, storage, and transmission cost micro-dollars, the the only real value is the data and its micro-dollars, the the only real value is the data and its organization.”organization.” (Jim Gray’s 1998 Turing Award Paper)

Networked Data Management Networked Data Management Projects @UCB-DB GroupProjects @UCB-DB Group
GridDB - Relational interaction model for Scientific Grid Computing. [SIGMOD 03 Demo]
MobiScopeMobiScope - Distributed processing for Location-based Services [MDM 03]
PIERPIER - P2P Data Management [VLDB 03]
TelegraphCQTelegraphCQ - Adaptive Dataflow Processing for Data Streams. [CIDR 03; SIGMOD 03 Demo]
TinyDBTinyDB - Sensor Networks for environmental monitoring [OSDI 02;SIGMOD 03]
YFilterYFilter - XML Message Brokering [ICDE 02 Demo; VLDB 03]

Why Database Queries?Why Database Queries? Declarative approach.
Programmer productivity. Robustness to change. Let the system manage efficiency.
Semantics and High-level operators. Framework for correctness criteria. Pushing semantics down enables smarter
implementations, code re-use.
Natural mapping of dataflow processing. Query plans are networks of operators. Query/Data duality enables intelligent routing.
TheseTheseare theare the
traditionaltraditionalargumentsarguments
Here’sHere’swhy thewhy the
techniquestechniquescarry overcarry over
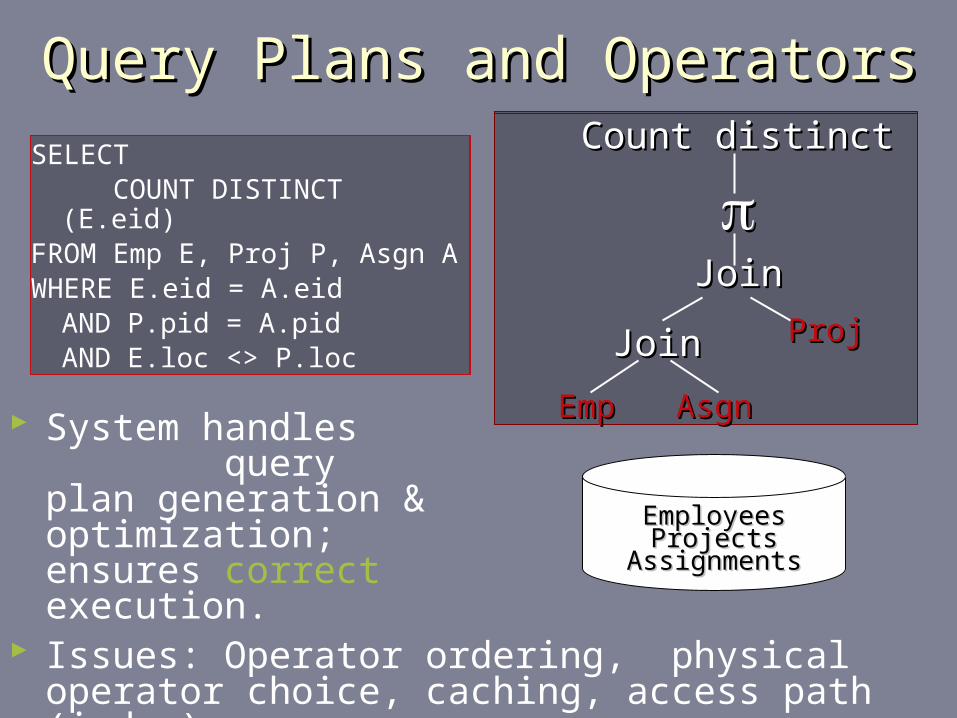
Query Plans and OperatorsQuery Plans and Operators
System handles query plan generation & optimization; ensures correct execution.
SELECT eid, ename, title
FROM Emp EWHERE E.sal > $50K
SELECT E.loc, AVG(E.sal)
FROM Emp EGROUP BY E.locHAVING Count(*) > 5
SELECT COUNT DISTINCT (E.eid)FROM Emp E, Proj P, Asgn AWHERE E.eid = A.eid
AND P.pid = A.pidAND E.loc <> P.loc
Issues: Operator ordering, physical operator choice, caching, access path (index) use, …
EmployeesEmployeesProjectsProjects
AssignmentsAssignments
EmpEmp
SelectSelect
EmpEmp
Group(agg)Group(agg)
HavingHaving
EmpEmp
Count distinctCount distinct
AsgnAsgn
JoinJoin
JoinJoin
ProjProj
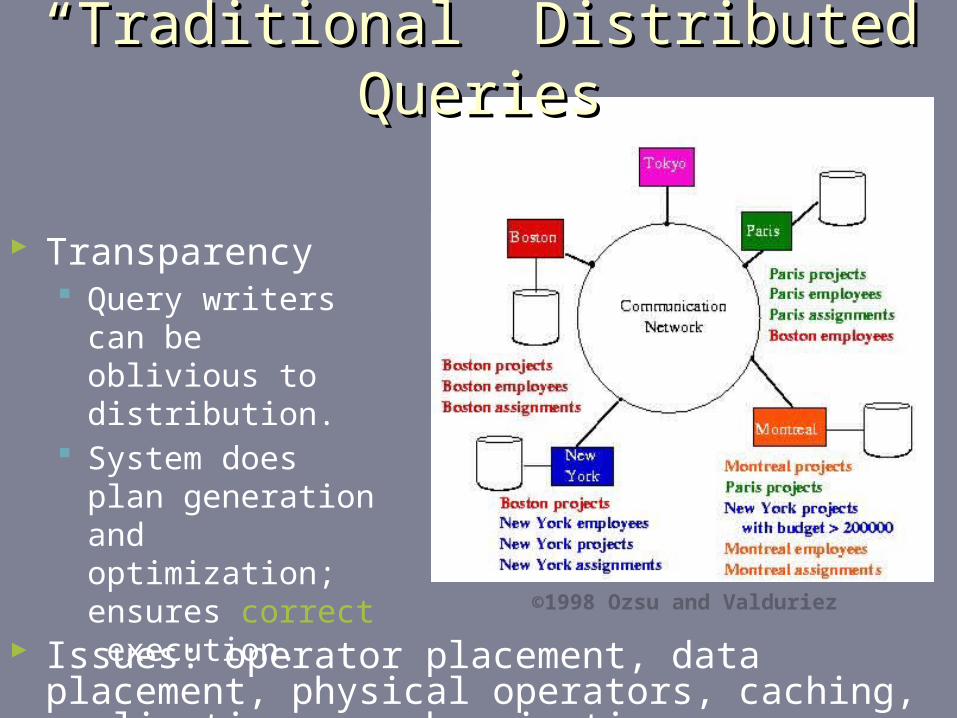
““Traditional” Distributed QueriesTraditional” Distributed Queries
Transparency Query writers can be
oblivious to distribution.
System does plan generation and optimization; ensures correct execution.
©1998 Ozsu and Valduriez
Issues: operator placement, data placement, physical operators, caching, replication, synchronization,…

Beyond Emps and DeptsBeyond Emps and Depts
In emerging networked data environments, queries can also be used for: Monitoring Real-time Analysis Actuation Routing Transformation Service Composition Definition,Naming, and Access Rights

New QP ScenariosNew QP Scenarios
Sensor Networks Message Brokers Data Streams Information/Application Integration

New QP ScenariosNew QP Scenarios
Sensor NetworksSensor Networks Message Brokers Data Streams Information/Application Integration
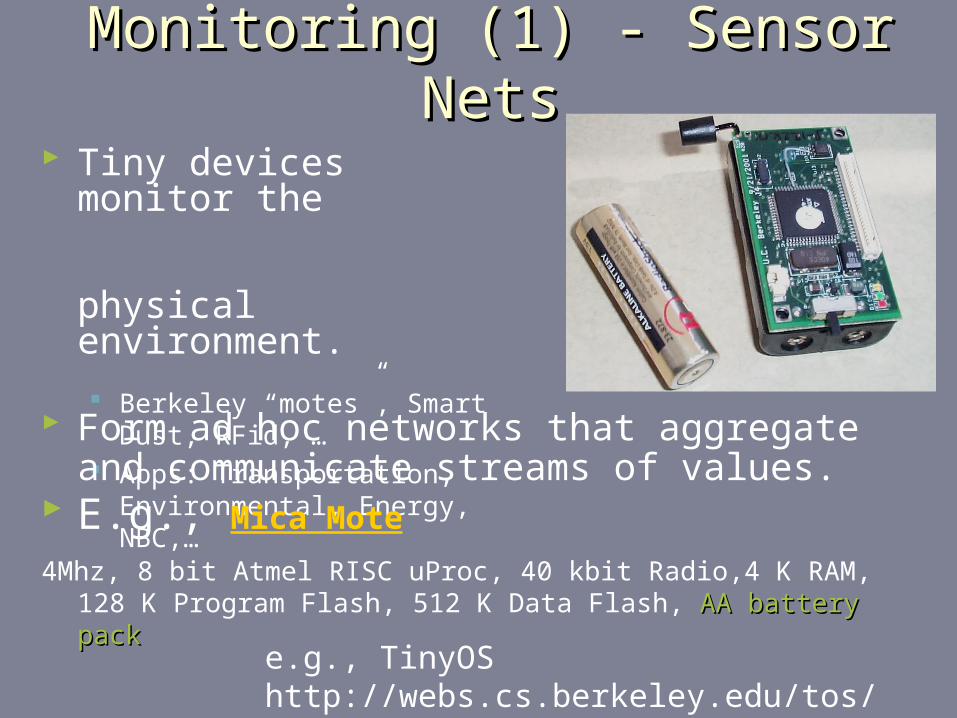
Monitoring (1) - Sensor NetsMonitoring (1) - Sensor Nets
Tiny devices monitor the physical environment.
Berkeley “motes”, Smart Dust, RFid, …
Apps: Transportation, Environmental, Energy, NBC,…
e.g., TinyOS http://webs.cs.berkeley.edu/tos/TinyDB http://telegraph.cs.berkeley.edu/tinydb
Form ad hoc networks that aggregate and communicate streams of values.
E.g., Mica Mote
4Mhz, 8 bit Atmel RISC uProc, 40 kbit Radio,4 K RAM, 128 K Program Flash, 512 K Data Flash, AA battery packAA battery pack

Sensor Net Sample AppsSensor Net Sample Apps
Traditional monitoring apparatus.
Earthquake shake-tests.
Vehicle detection: sensors along a road, collect data about passing vehicles.
Habitat Monitoring: Storm petrels on great duck island, microclimates on James Reserve.
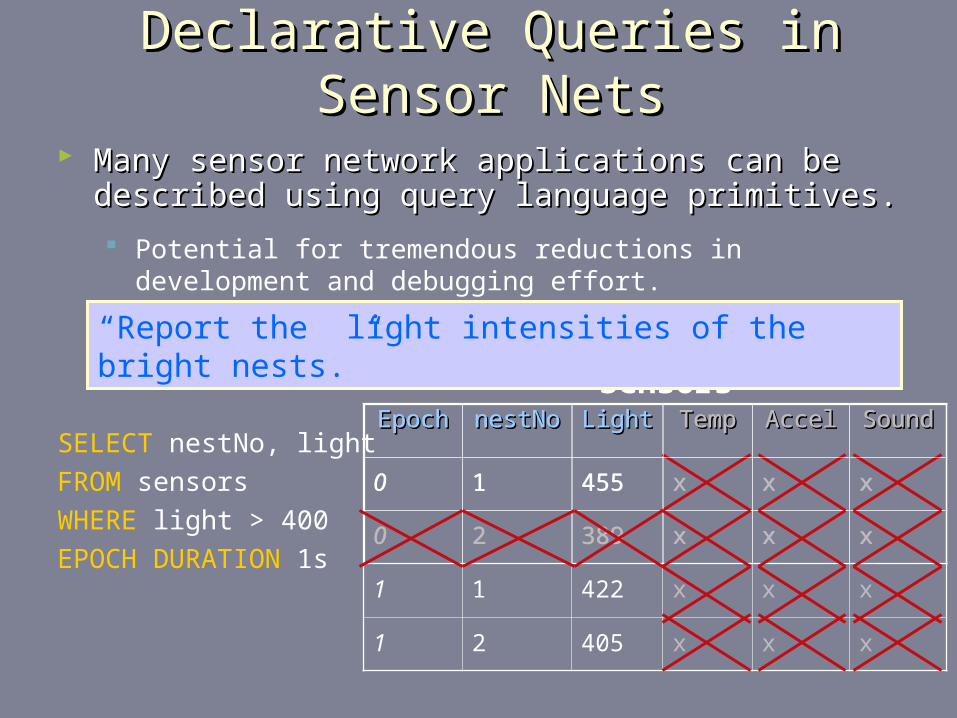
Declarative Queries in Sensor NetsDeclarative Queries in Sensor Nets
SELECT nestNo, light
FROM sensors
WHERE light > 400
EPOCH DURATION 1s
EpochEpoch nestNonestNo LightLight TempTemp AccelAccel SoundSound
0 1 455 x x x
0 2 389 x x x
1 1 422 x x x
1 2 405 x x x
Sensors
“Report the light intensities of the bright nests.”
EpochEpoch nestNonestNo LightLight TempTemp AccelAccel SoundSound
0 1 455 x x x
0 2 389 x x x
Many sensor network applications can be described using Many sensor network applications can be described using query language primitives.query language primitives. Potential for tremendous reductions in development and
debugging effort.

Aggregation Query ExampleAggregation Query Example
Epoch region CNT(…) AVG(…)
0 North 3 360
0 South 3 520
1 North 3 370
1 South 3 520
“Count the number occupied nests in each loud region of the island.”
SELECT region, CNT(occupied) AVG(sound)
FROM sensors
GROUP BY region
HAVING AVG(sound) > 200
EPOCH DURATION 10sRegions w/ AVG(sound) > 200
A
B C
D
FE
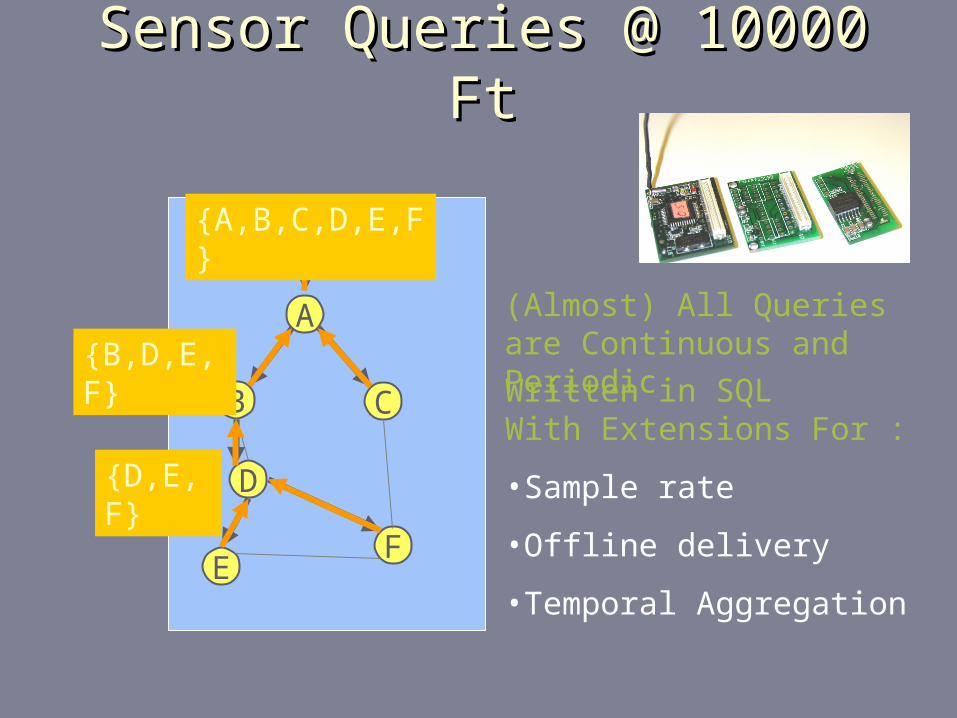
Sensor Queries @ 10000 FtSensor Queries @ 10000 Ft
Query
{D,E,F}
{B,D,E,F}
{A,B,C,D,E,F}
Written in SQLWith Extensions For :
•Sample rate
•Offline delivery
•Temporal Aggregation
(Almost) All Queries are Continuous and Periodic

TAG: Tiny AGgregation TAG: Tiny AGgregation (Sam Madden)(Sam Madden)
In-network processing Reduces costs depending on type of aggregates Supports “spatial aggregation”
Exploitation of operator, functional semantics Part of “TinyDBTinyDB” system
available at http://telegraph.cs.berkeley.edu/tinydb
Tiny AGgregation (TAG), Madden, Franklin, Hellerstein, Hong. OSDI 2002.

Aggregation FrameworkAggregation Framework• As in extensible databases, we support any
aggregation function conforming to:
Aggn={fmerge, finit, fevaluate}
Fmerge{<a1>,<a2>} <a12>
finit{a0} <a0>
Fevaluate{<a1>} aggregate value
(Merge: associative, commutative!)
Example: Average
AVGmerge {<S1, C1>, <S2, C2>} < S1 + S2 , C1 + C2>
AVGinit{v} <v,1>
AVGevaluate{<S1, C1>} S1/C1
Partial Aggregation
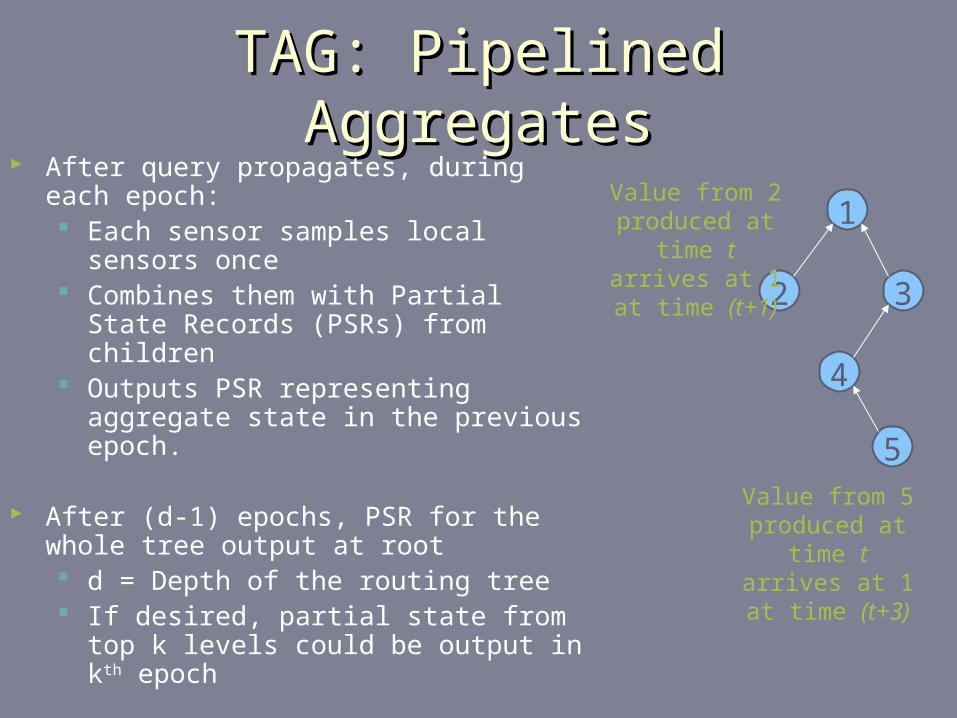
TAG: Pipelined AggregatesTAG: Pipelined Aggregates After query propagates, during each epoch:
Each sensor samples local sensors once Combines them with Partial State
Records (PSRs) from children Outputs PSR representing aggregate
state in the previous epoch.
After (d-1) epochs, PSR for the whole tree output at root d = Depth of the routing tree If desired, partial state from top k levels
could be output in kth epoch
To avoid combining PSRs from different epochs, sensors must cache values from children
1
2 3
4
5Value from 5 produced at
time t arrives at 1 at time
(t+3)
Value from 2 produced at
time t arrives at 1 at time
(t+1)
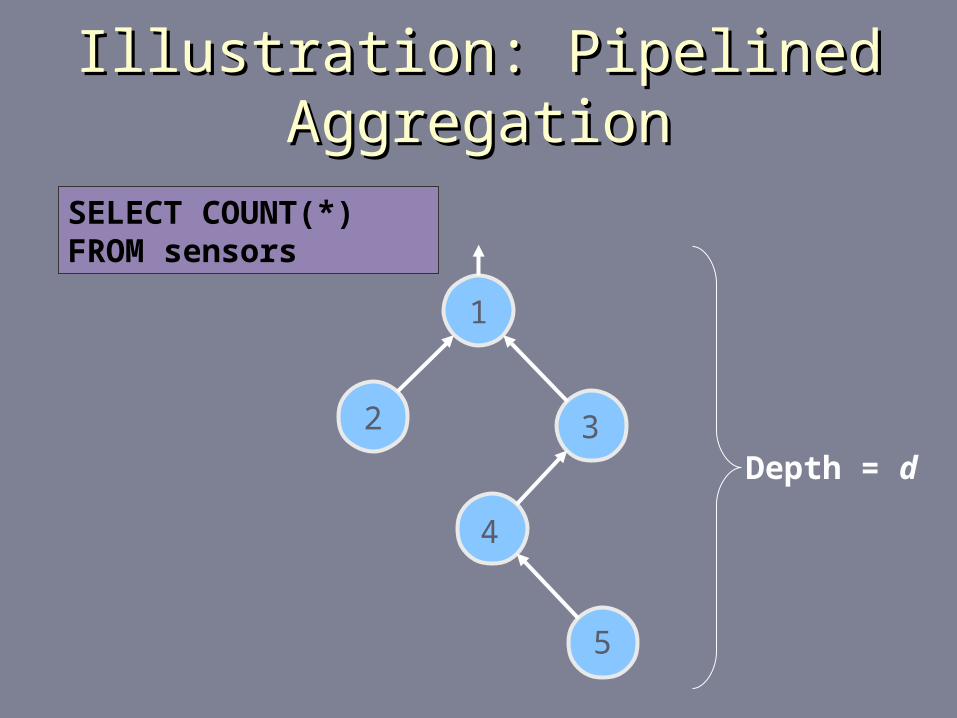
Illustration: Pipelined AggregationIllustration: Pipelined Aggregation
1
2 3
4
5
SELECT COUNT(*) FROM sensors
Depth = d
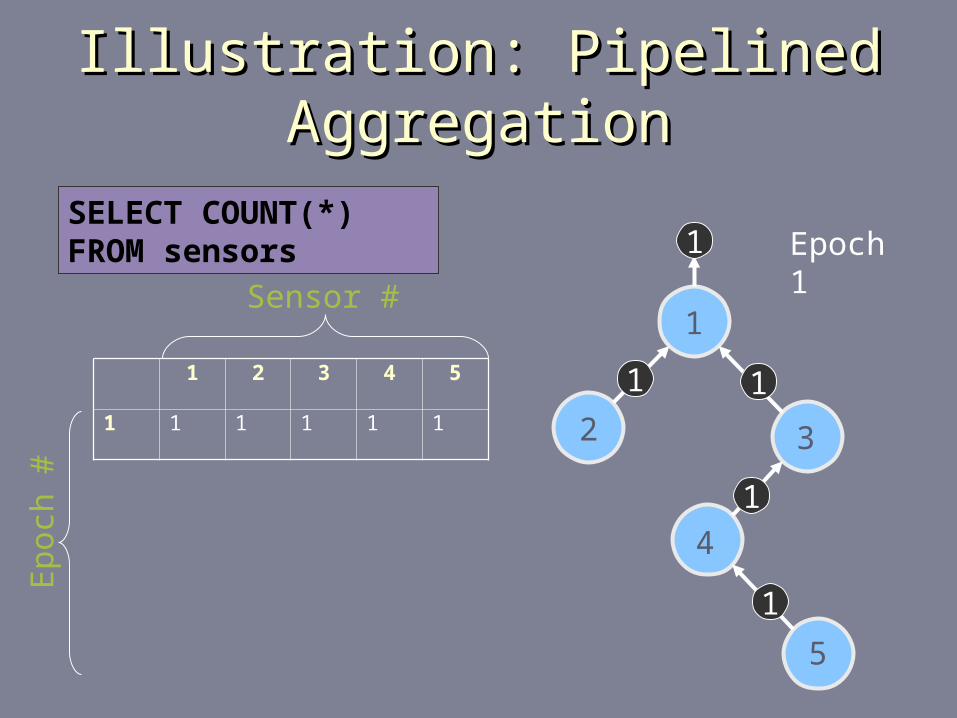
Illustration: Pipelined AggregationIllustration: Pipelined Aggregation
1 2 3 4 5
1 1 1 1 1 1
1
2 3
4
5
1
1
11
1
Sensor #
Ep
och
#
Epoch 1SELECT COUNT(*) FROM sensors
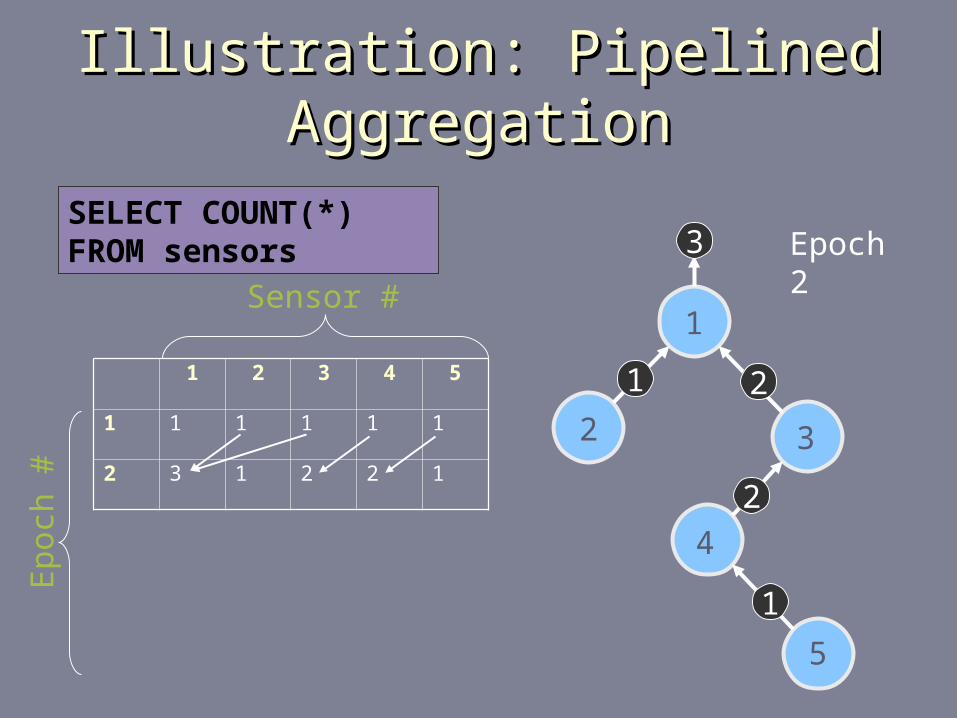
Illustration: Pipelined AggregationIllustration: Pipelined Aggregation
1 2 3 4 5
1 1 1 1 1 1
2 3 1 2 2 1
1
2 3
4
5
1
2
21
3
Sensor #
Ep
och
#
Epoch 2SELECT COUNT(*) FROM sensors
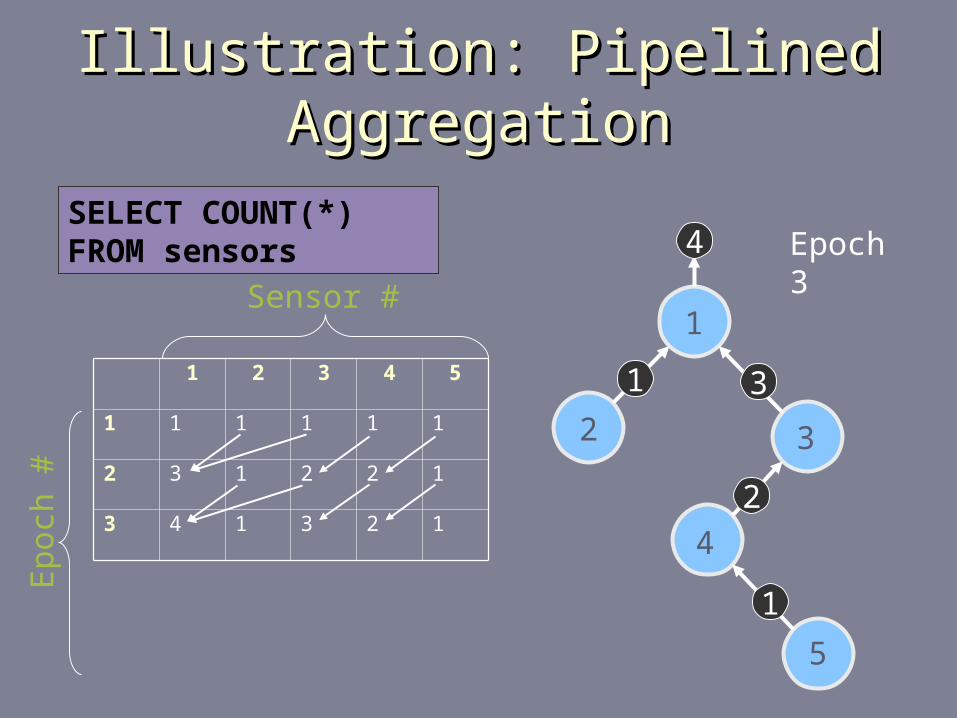
Illustration: Pipelined AggregationIllustration: Pipelined Aggregation
1 2 3 4 5
1 1 1 1 1 1
2 3 1 2 2 1
3 4 1 3 2 1
1
2 3
4
5
1
2
31
4
Sensor #
Ep
och
#
Epoch 3SELECT COUNT(*) FROM sensors
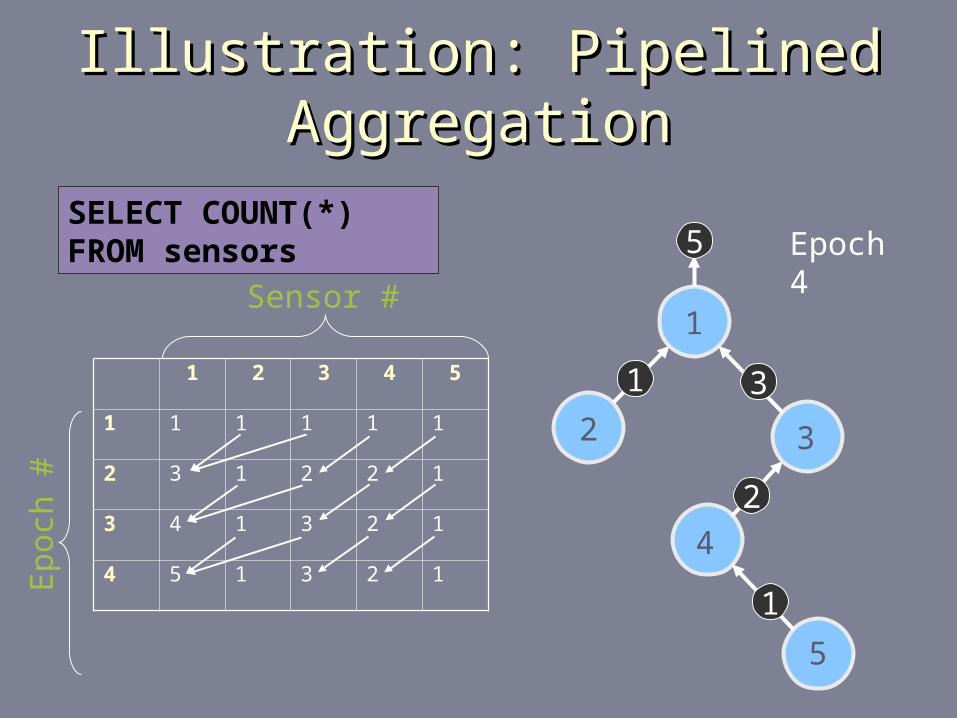
Illustration: Pipelined AggregationIllustration: Pipelined Aggregation
1 2 3 4 5
1 1 1 1 1 1
2 3 1 2 2 1
3 4 1 3 2 1
4 5 1 3 2 1
1
2 3
4
5
1
2
31
5
Sensor #
Ep
och
#
Epoch 4SELECT COUNT(*) FROM sensors
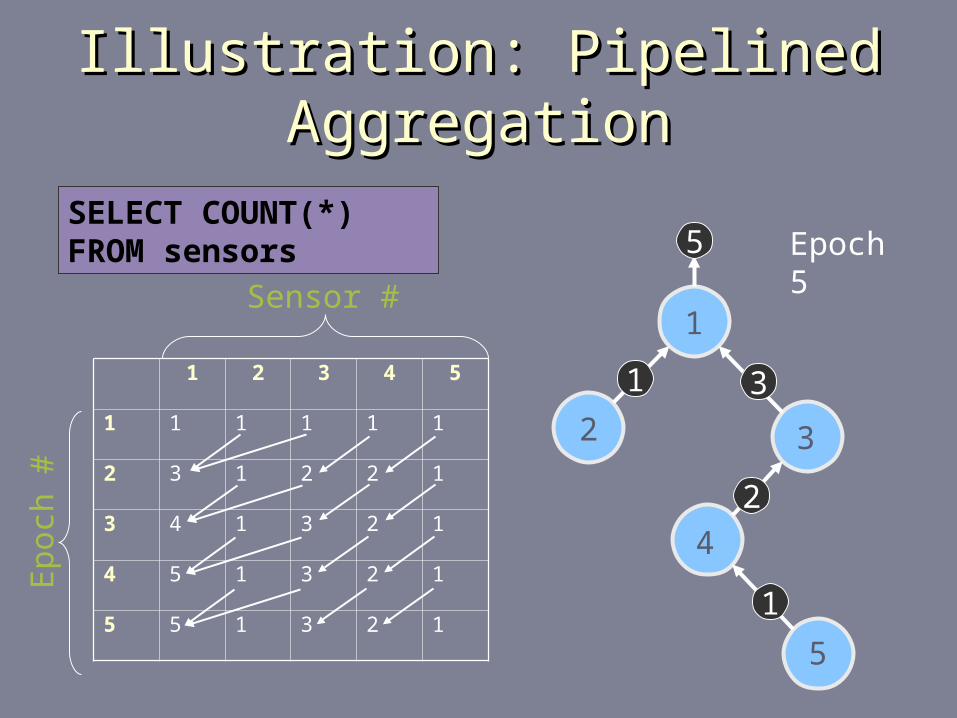
Illustration: Pipelined AggregationIllustration: Pipelined Aggregation
1 2 3 4 5
1 1 1 1 1 1
2 3 1 2 2 1
3 4 1 3 2 1
4 5 1 3 2 1
5 5 1 3 2 1
1
2 3
4
5
1
2
31
5
Sensor #
Ep
och
#
Epoch 5SELECT COUNT(*) FROM sensors
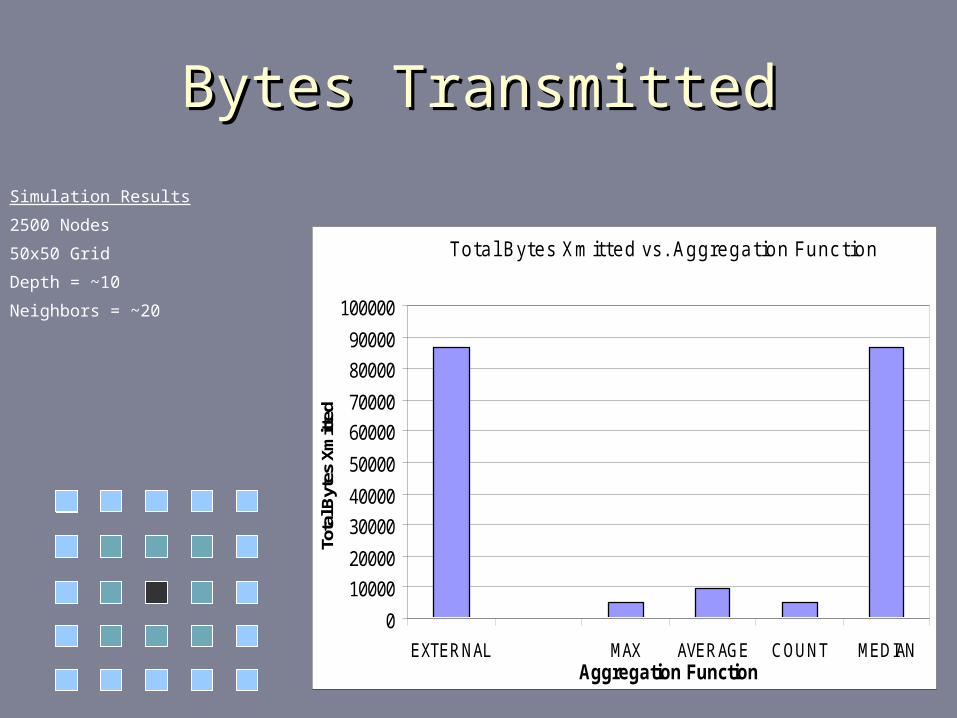
Bytes TransmittedBytes Transmitted
Total Bytes Xmitted vs. Aggregation Function
0
10000
20000
30000
40000
50000
60000
70000
80000
90000
100000
EXTERNAL MAX AVERAGE COUNT MEDIANAggregation Function
Tota
l Byt
es X
mitt
ed
Simulation Results
2500 Nodes
50x50 Grid
Depth = ~10
Neighbors = ~20

Optimization: “Snooping”Optimization: “Snooping”
Insight: Shared channel enables optimizations Suppress messages that won’t affect aggregate
E.g., in a MAX query, sensor with value v hears a neighbor with value ≥ v, so it doesn’t report
Applies to all exemplary, monotonic aggregates
Learn about query advertisements it missed If a sensor shows up in a new environment, it can learn about
queries by looking at neighbors messages. Root doesn’t have to explicitly rebroadcast query!

Optimization: Hypothesis TestingOptimization: Hypothesis Testing
Insight: Root can provide information that will suppress readings that cannot affect the final aggregate value. E.g. Tell all the nodes that the MIN is definitely < 50;
nodes with value ≥ 50 need not participate. Depends on monotonicity
How is hypothesis computed? Blind guess Statistically informed guess Observation over first few levels of tree / rounds of aggregate
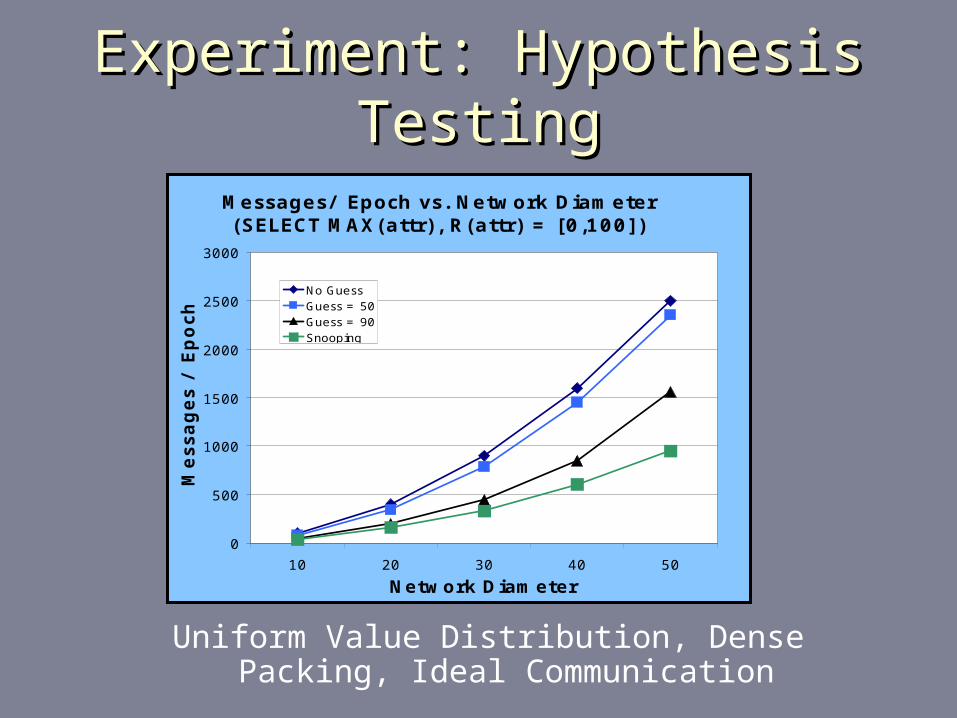
Experiment: Hypothesis TestingExperiment: Hypothesis Testing
Uniform Value Distribution, Dense Packing, Ideal Communication
Messages/ Epoch vs. Network Diameter(SELECT MAX(attr), R(attr) = [0,100])
0
500
1000
1500
2000
2500
3000
10 20 30 40 50
Network Diameter
Messages /
Epoch
No GuessGuess = 50Guess = 90Snooping

Taxonomy of AggregatesTaxonomy of Aggregates
TAG insight: classify aggregates according to various functional properties Yields a general set of optimizations that can automatically
be applied
PropertyProperty ExamplesExamples AffectsAffects
Partial State MEDIAN : unbounded, MAX : 1 record
Effectiveness of TAG
Duplicate Sensitivity MIN : dup. insensitive,AVG : dup. sensitive
Routing Redundancy
Exemplary vs. Summary
MAX : exemplaryCOUNT: summary
Applicability of Sampling, Effect of Loss
Monotonic COUNT : monotonicAVG : non-monotonic
Hypothesis Testing, Snooping

ACQPACQPData collection aware query processing
“acquisitional query processing”
Issues addressed: How does the user control acquisition?
Rates or lifetimes Event-based triggers
How should the query be processed? Sampling as a first class operation Events – join duality
Which nodes have relevant data? Which samples should be transmitted?Madden, Franklin, Hellerstein, and Hong. The Design of
An Acqusitional Query Processor. SIGMOD 2003.

Sensor Query Processing SummarySensor Query Processing Summary Higher-level programming abstractions for
sensor networks are necessary. Aggregation is a fundamental operation
Semantically aware optimizationsSemantically aware optimizations Close integration with networkClose integration with network
ACQP: Languages, indices, approximations that give user control over which data enters the system.
Wealth of open research problems: Error tolerance, topologies, heterogeneity, spatial
processing, routing strategies, operators, actuation,.. Combines database, network, and device issues

New QP ScenariosNew QP Scenarios
Sensor Networks Message Brokers Data Streams Information/Application Integration

New QP ScenariosNew QP Scenarios
Sensor Networks Message BrokersMessage Brokers Data Streams Information/Application Integration

Web Services/Message BrokersWeb Services/Message Brokers•A platform for dynamic, loosely-coupleddynamic, loosely-coupled integration of enterprise applications and data.•Interaction accomplished through exchange of messages in the wide area.
(e.g., Adam Bosworth’s VLDB 02 keynote: http://www.cs.ust.hk/vldb2002/VLDB2002-proceedings/slides/S01P01slides.pdf)
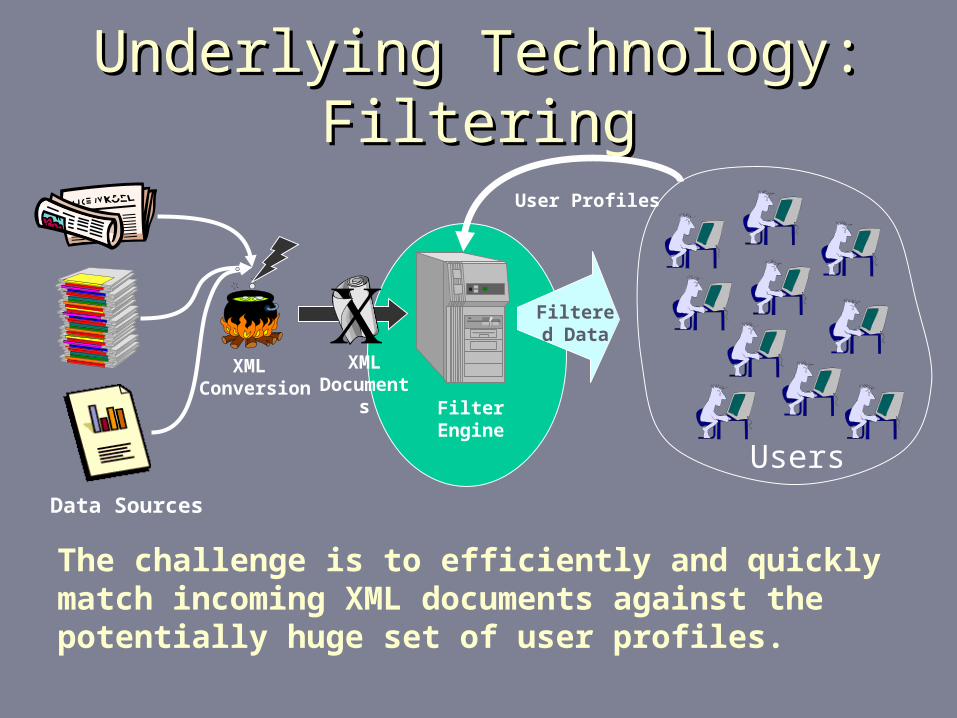
The challenge is to efficiently and quickly match incoming XML documents against the potentially huge set of user profiles.
Underlying Technology: FilteringUnderlying Technology: Filtering
XML Conversion
XML Documen
ts Filter Engine
User Profiles
Users
Filtered Data
Data Sources

Message BrokersMessage Brokers Message Brokers perform three main
tasks: FilteringFiltering - matching of interests. TransformationTransformation - format conversion for app
integration and preferences. DeliveryDelivery - moving bits through the overlay
network Must be lightweight and scalable.
Effectively they are high-function routers. Large-scale deployments may entail handling
10’s or 100’s of thousands of queries (subscriptions)
XML is a natural substrate.
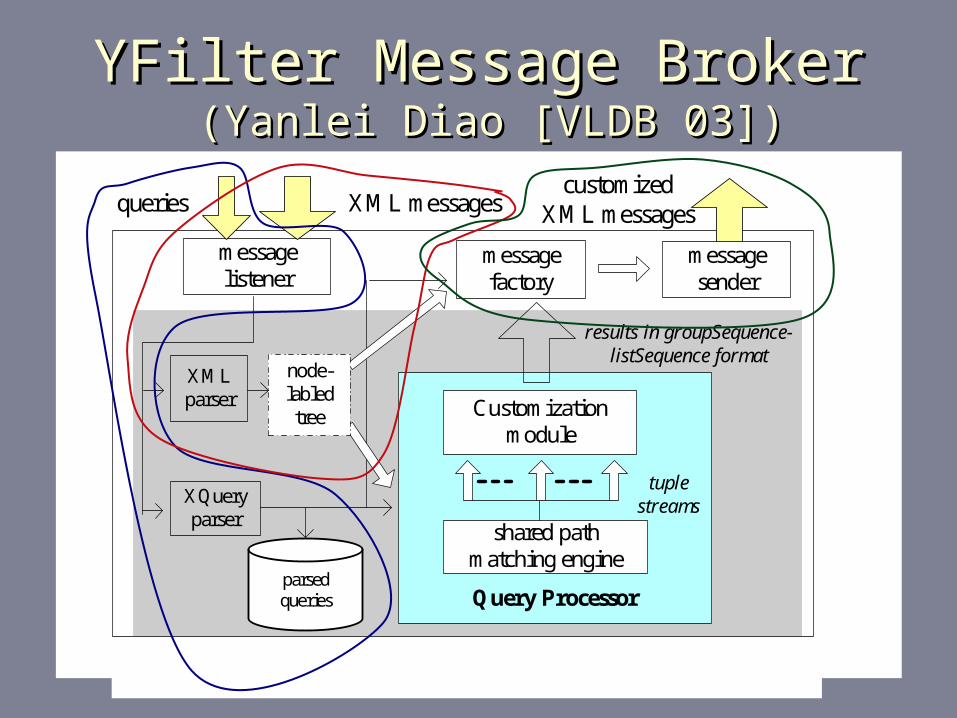
parsed queries
messagesender
messagefactory
messagelistener
XMLparser
node-labledtree
XQueryparser
Query Processor
shared pathmatching engine
Customizationmodule
tuplestreams
results in groupSequence-listSequence format
XML messagesqueriescustomized
XML messages
Figure 1: XML message broker architecture
YFilter Message BrokerYFilter Message Broker (Yanlei Diao [VLDB 03]) (Yanlei Diao [VLDB 03])
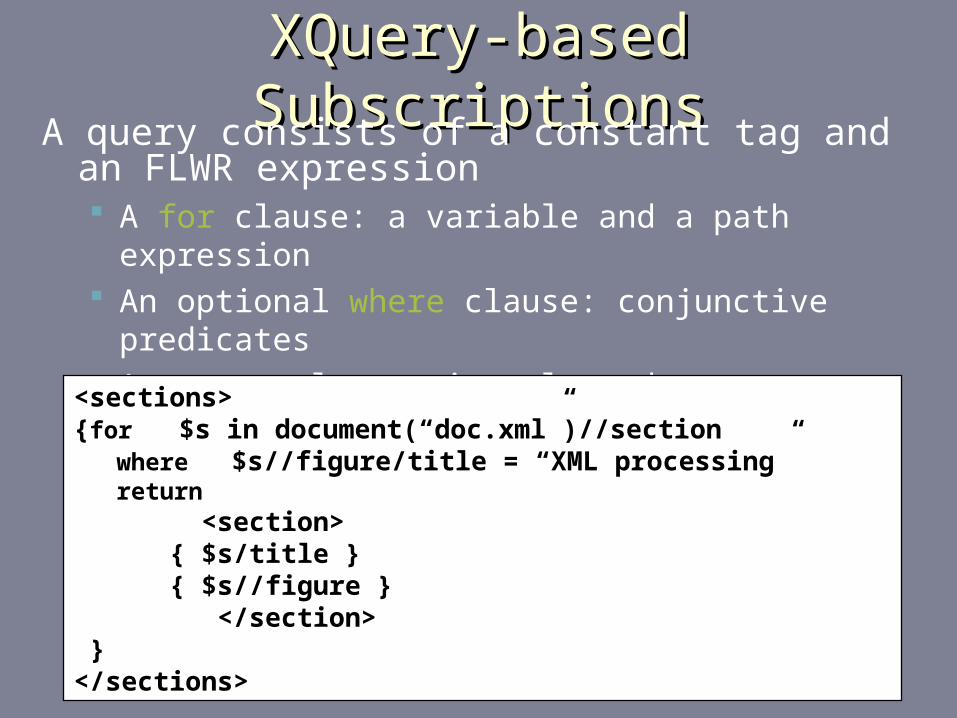
XQuery-based SubscriptionsXQuery-based SubscriptionsA query consists of a constant tag and an FLWR
expression A for clause: a variable and a path expression An optional where clause: conjunctive predicates A return clause: interleaved constant tags and path
expressions where and return clause paths are relativerelative<sections>{for $s in document(“doc.xml”)//section where $s//figure/title = “XML processing” return <section>
{ $s/title }{ $s//figure }
</section> }</sections>

YFilter:Shared Path MatchingYFilter:Shared Path Matching
For large-scale systems, shared processingshared processing is essential.
YFilter uses an NFA-based approach to share path matching work among queries.
Location steps
/a
//a
/*
//*
NFA fragments
a
*a
*
**
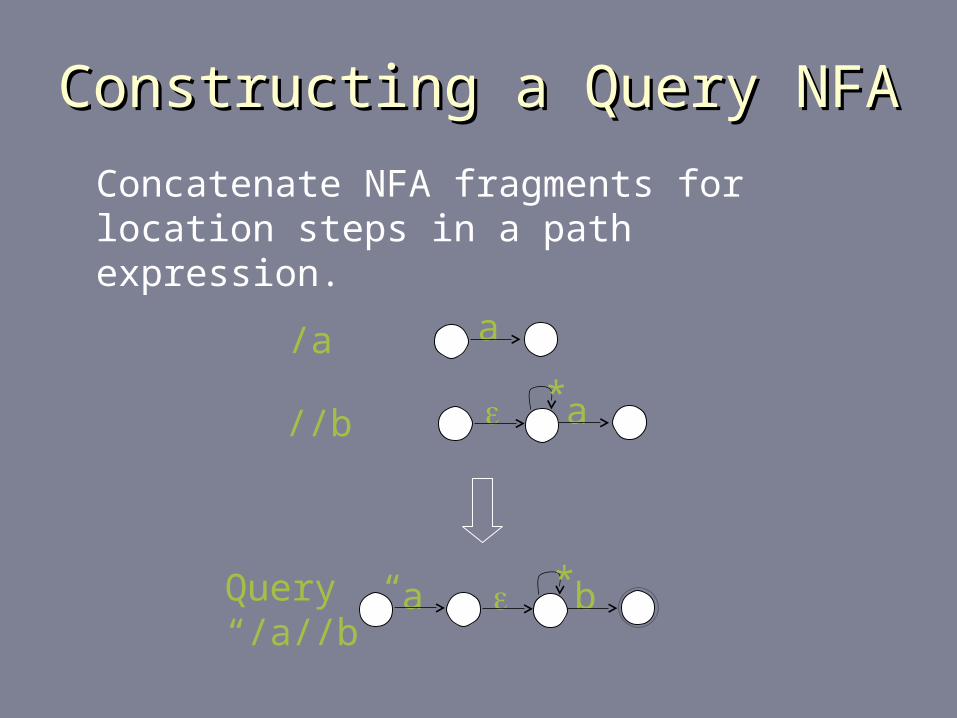
Constructing a Query NFAConstructing a Query NFA
Concatenate NFA fragments for location steps in a path expression.
/a a
//b*a
Query “/a//b”
a *b
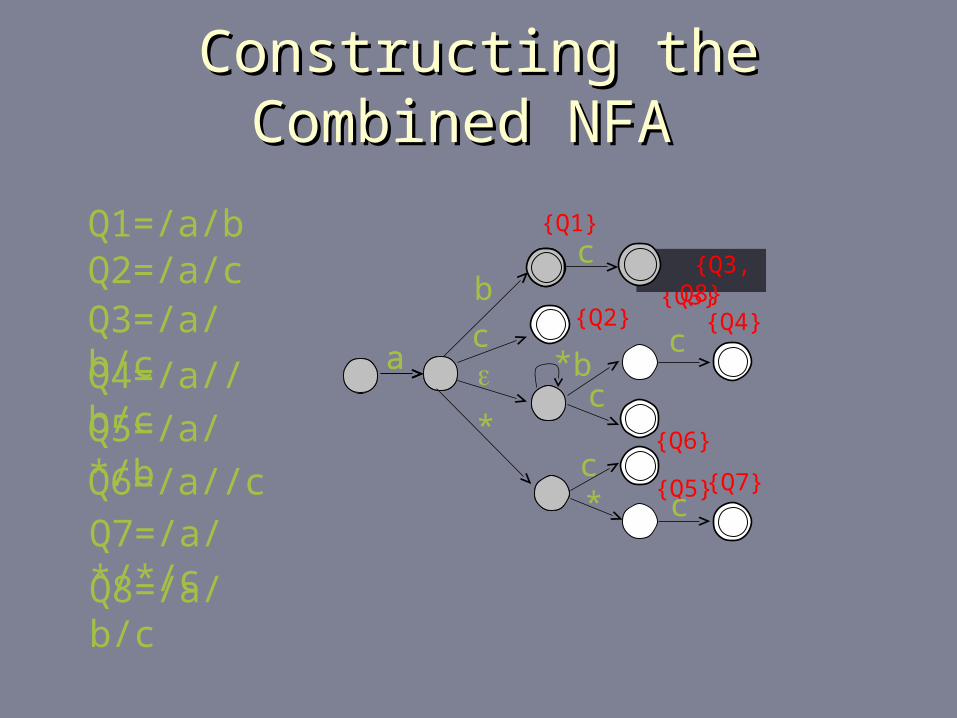
Constructing the Combined NFA Constructing the Combined NFA
a
{Q1}
b
Q1=/a/bQ2=/a/cQ3=/a/b/c
Q4=/a//b/c
Q5=/a/*/b
Q6=/a//c
Q7=/a/*/*/c
Q8=/a/b/c
a {Q2}
c
c {Q3}
{Q4}c
b*
*c {Q5}
c {Q6}
* c{Q7}
{Q3, Q8}
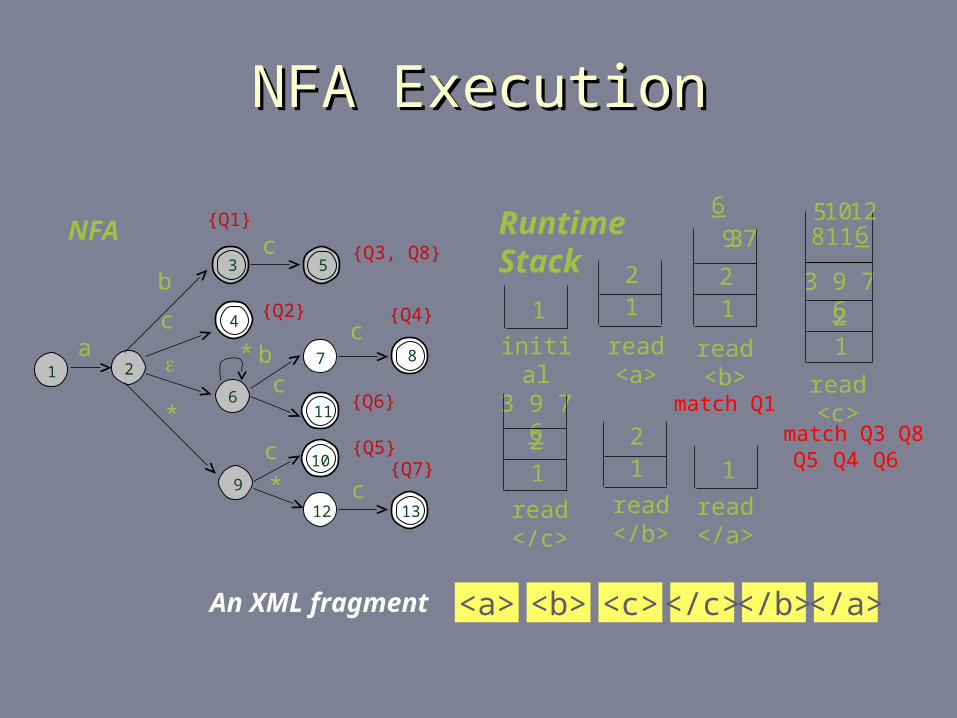
NFA ExecutionNFA Execution
read <a>
21
match Q1
read <b>
3
21
match Q3 Q8
read <c>
5
3 9 7 6
21
read </c>
3 9 7 6
21
read </b>
21
read </a>
1
initial
1
Runtime Stack
NFA
An XML fragment <a> <b> <c> </c> </b> </a>
c
cb
{Q1}
{Q3, Q8}
{Q2} {Q4}
{Q6}
{Q5}{Q7}
a *
c
c
* c
c
*
b
1
4
3 5
8
6
12
10
27
11
13
9
9 7
6 10128 11 6
Q5 Q6Q4
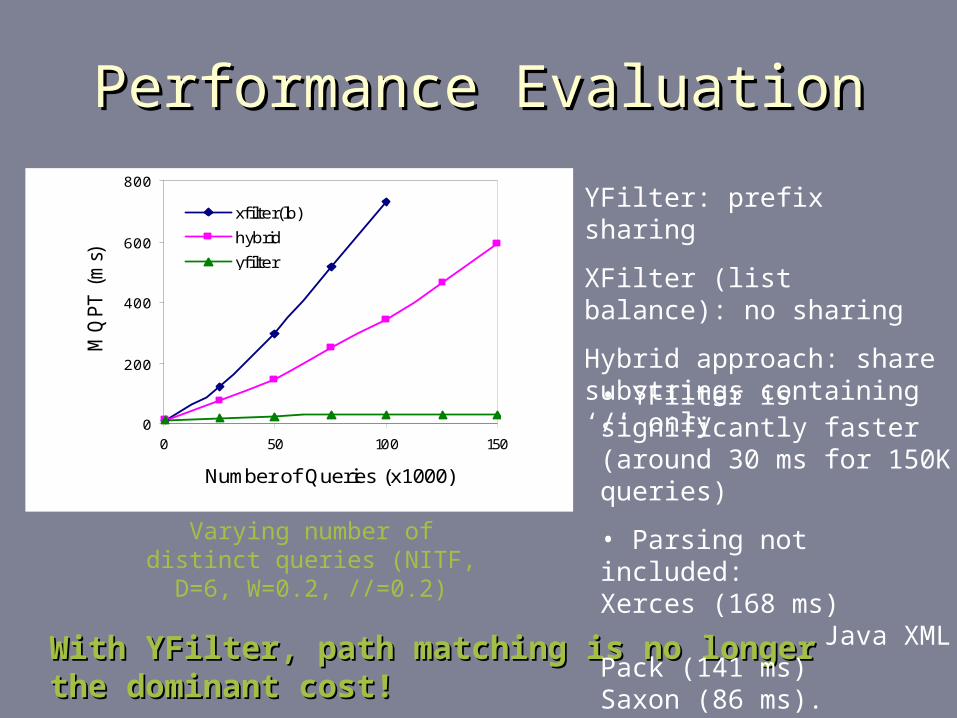
Performance EvaluationPerformance Evaluation
0
200
400
600
800
0 50 100 150
Number of Queries (x1000)
MQ
PT
(m
s)
xfilter(lb)
hybrid
yfilter
Varying number of distinct queries (NITF, D=6, W=0.2, //=0.2)
With YFilter, path matching is no longer the dominant cost!With YFilter, path matching is no longer the dominant cost!
YFilter: prefix sharing
XFilter (list balance): no sharing
Hybrid approach: share substrings containing ‘/’ only
• YFilter is significantly faster (around 30 ms for 150K queries)
• Parsing not included: Xerces (168 ms) Java XML Pack (141 ms) Saxon (86 ms).

Message TransformationMessage Transformation Change YFilter to output streams of “path tuples”.
Each path tuple contains a sequence of node ids representing the elements that matched the path.
This output is post-processed using relational-style operators to produce customized messages.
Three approaches (differ in the extent to which they push work to the engine) PathSharing-FPathSharing-F: For clause paths only PathSharing-FWPathSharing-FW: For & Where clause paths PathSharing-FWRPathSharing-FWR: For, Where & Return
Inherent tension between path sharing and result customization!

Message Broker – Wrap UpMessage Broker – Wrap UpSharing is the key to performance
NFA provides excellent scalability/performance PathSharing-FWR performs best, when combined with
optimizations based on the queries and DTD. When the post-processing is shared, even more scalability
can be achieved. This sharing is facilitated by using relational-like query plans.
On-going work - How to deploy in the wide area?: Distributed Filtering and Content Delivery Network
Combining distributed query processing and state-of-the-art application-level multicast protocols.
What semantics can/should be provided?
For more information see: www.cs.berkeley.edu/~daioyl/yfilter

New QP ScenariosNew QP Scenarios
Sensor Networks Message Brokers Data Streams Information/Application Integration
New QP ScenariosNew QP Scenarios
Sensor Networks Message Brokers Data StreamsData Streams Information/Application Integration

Monitoring (2) : Data StreamsMonitoring (2) : Data Streams Streaming Data
Network monitors news feeds stock tickers
B2B and Enterprise apps Supply-Chain, CRM Trade Reconciliation, Order Processing etc.
(Quasi) real-time flow of events and data Must manage these flows to drive business (and
other) processes. Mine flows to create and adjust business rules. Can also “tap into” flows for on-line analysis.

TelegraphCQ OverviewTelegraphCQ Overview An adaptive system for large-scale shared
dataflow processing.
Based on an extensible set of operators:1) IngressIngress (data access) (data access) operators
Screen Scraper, Napster/Gnutella readers, File readers, Sensor Proxies
2) Non-Blocking Data processingData processing operators Selections (filters), XJoins, …
3) Adaptive RoutingAdaptive Routing Operators Eddies, STeMs, FLuX, etc.
Operators connected through “Fjords” [MF02] queue-based framework unifying push&pull.
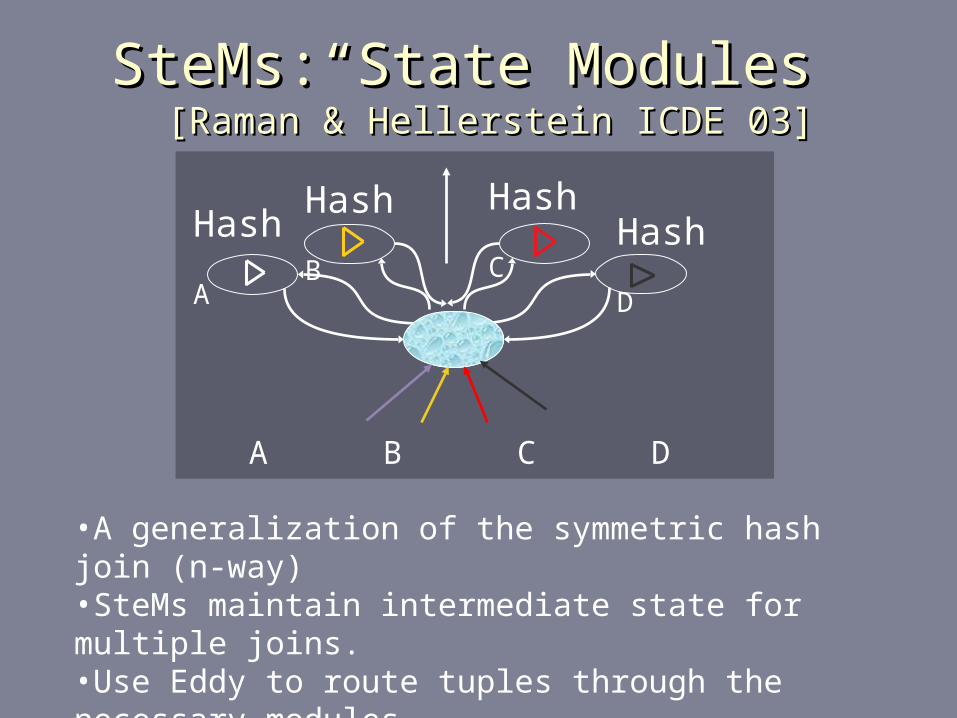
SteMs:“State Modules”SteMs:“State Modules” [Raman & Hellerstein ICDE 03] [Raman & Hellerstein ICDE 03]
•A generalization of the symmetric hash join (n-way)•SteMs maintain intermediate state for multiple joins.•Use Eddy to route tuples through the necessary modules.•SteMs + Eddy reduce need for optimizer, increasing adaptivity in volatile streaming environments.
A B C D
HashAHashB HashC
HashD
A B C D
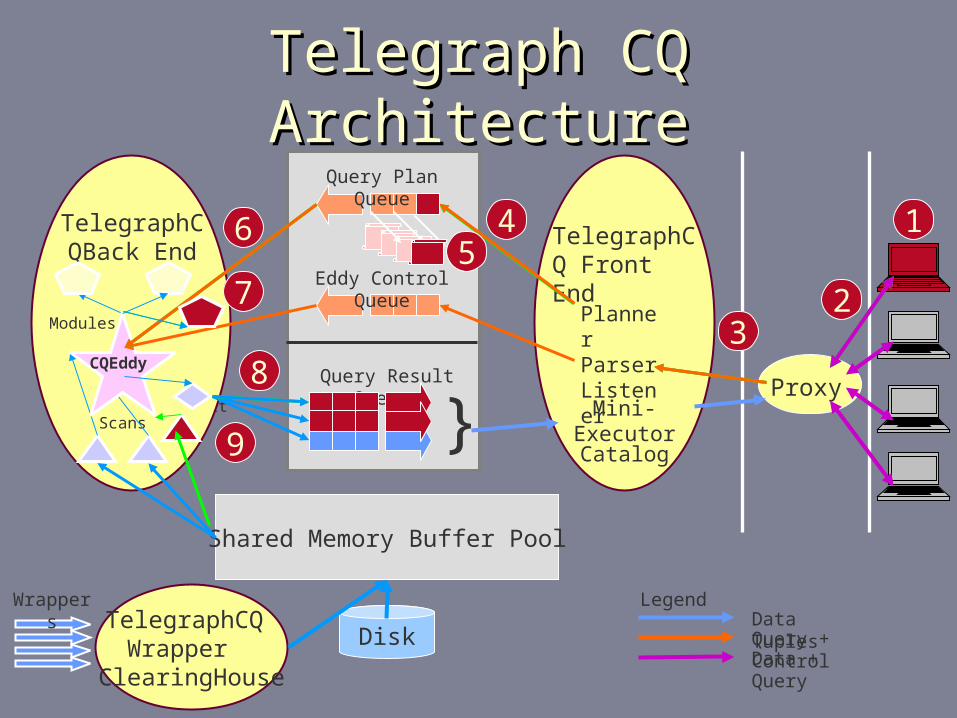
Telegraph CQ ArchitectureTelegraph CQ Architecture
TelegraphCQ Front End
Planner Parser Listener
Mini-Executor
Catalog
Split
TelegraphCQBack End
Modules
Scans
CQEddy
TelegraphCQ Wrapper
ClearingHouse
Shared Memory Buffer Pool
Disk
Query Plan Queue
Eddy Control Queue
Query Result Queues
}
LegendData TuplesQuery + ControlData + Query
Wrappers
Proxy
1
23
45
6
7
8
9

1 {t1,t2,t3
2 {t2,t3,t4
3 {t3,t4,t5
4 {t4,t5,t6
5 {t5,t6,t7
Time Tuple sets
Semantics of data streamsSemantics of data streams Different notions of data streams
Ordered sequence of tuples Bag of tuple/timestamp pairs [STREAM] Mapping from time to sets of tuplesMapping from time to sets of tuples
Data streams are unbounded Windows: restrict data for a queryWindows: restrict data for a query
A stream can be transformed by: Moving a window across it A window can be moved by
Shifting its extremities Changing its size

The StreaQuel LanguageThe StreaQuel Language
An extension of SQL Operates exclusively on streams Is closed under streams Supports different ways to “create” streams
Infinite time-stamped tuple sequence Traditional stable relations
Flexible windows: sliding, landmark, and more Supports logical and physical time When used with a cursor mechanism, allows clients
to do their own window-based processing. Target language for TelegraphCQ

Example – Landmark queryExample – Landmark query
0 105 15 20 25 30 35 40 45 50 55 60
NOW = 40 = t
TimelineSTWindow
TimelineSTWindow
TimelineSTWindow
TimelineSTWindow
NOW = 41 = t
...
...
NOW = 45 = t
NOW = 50 = t

Current Status - TelegraphCQCurrent Status - TelegraphCQ System has been developed by modifying
PostgreSQL: Re-used a lot of code:
Expression evaluator, semaphores, parser, planner
Sucessfully Demonstrated at SIGMOD 2003. Performance studies underway. Beta Version to be released Aug 03
Open Source (PostgreSQL license) Shared joins with windows and aggregates Archived/unarchived streams
A “hot” area: Several major streaming systems under development in the database community
Beyond Emps and DeptsBeyond Emps and Depts MonitoringMonitoring
TinyDB, TelegraphCQ, YFilter Real-time AnalysisReal-time Analysis
TinyDB and TelegraphCQ ActuationActuation
TinyDB, GridDB RoutingRouting (queries and/or data),
TransformationTransformation, Service CompositionService Composition all of the projects
Definition,Naming, and Access RightsDefinition,Naming, and Access Rights TelegraphCQ, but all should

ConclusionsConclusions Data is the crucial resource in emerging
networked environments.
Database query processing techniques and insights can provide tremendous leverage.
Huge research opportunities for databasedatabase, networkingnetworking, and distributed systemsdistributed systems researchers.
Breakthroughs will come from projects that span these areas.





























