Embed Size (px)
Citation preview

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
IEEE TRANSACTIONS ON NEURAL NETWORKS 1
Data-Based System Modeling Using a Type-2 FuzzyNeural Network with a Hybrid Learning Algorithm
Chi-Yuan Yeh, Wen-Hau Roger Jeng, and Shie-Jue Lee, Member, IEEE
Abstract— We propose a novel approach for building a type-2neural-fuzzy system from a given set of input–output trainingdata. A self-constructing fuzzy clustering method is used to par-tition the training dataset into clusters through input-similarityand output-similarity tests. The membership function associatedwith each cluster is defined with the mean and deviation ofthe data points included in the cluster. Then a type-2 fuzzyTakagi-Sugeno-Kang IF-THEN rule is derived from each clusterto form a fuzzy rule base. A fuzzy neural network is constructedaccordingly and the associated parameters are refined by ahybrid learning algorithm which incorporates particle swarmoptimization and a least squares estimation. For a new input,a corresponding crisp output of the system is obtained bycombining the inferred results of all the rules into a type-2 fuzzyset, which is then defuzzified by applying a refined type reductionalgorithm. Experimental results are presented to demonstrate theeffectiveness of our proposed approach.
Index Terms— Fuzzy clustering, Karnik–Mendel algorithm,least squares estimation, particle swarm optimization, type reduc-tion, type-2 fuzzy set.
I. INTRODUCTION
THE purpose of system modeling is to model the operationof an unknown system from a given set of input–output
training data. Through the simulated model, one can easilyunderstand the underlying properties of the unknown systemand handle it properly. However, this problem can be verydifficult when the unknown system is highly nonlinear andcomplex. Many approaches have been proposed for systemmodeling. Quantitative approaches based on conventionalmathematics tend to be more accurate, but they are not suitablewhen the underlying system is complex, ill defined, or uncer-tain. The fuzzy modeling approach was proposed to deal withthe uncertainty [1]. However, this approach lacks an effectivelearning algorithm to refine the membership functions to min-imize output errors. Another approach using neural networkshas been proposed [2]. This approach is capable of learningand can obtain high-precision results. However, it usuallyencounters problems of slow convergence and low understand-ability of the associated numerical weights. Recently, neural-
Manuscript received January 4, 2011; revised September 19, 2011; acceptedSeptember 20, 2011. This work was supported in part by the National ScienceCouncil under Grant NSC-97-2221-E-110-048-MY3 and Grant NSC-98-2221-E-110-052, and the Aim for the Top University Plan of the National SunYat-Sen University and Ministry of Education.
The authors are with the Department of Electrical Engineering, NationalSun Yat-Sen University, Kaohsiung 80424, Taiwan (e-mail: [email protected]; [email protected]; [email protected]).
Color versions of one or more of the figures in this paper are availableonline at http://ieeexplore.ieee.org.
Digital Object Identifier 10.1109/TNN.2011.2170095
fuzzy modeling has attracted a lot of attention [3]–[6]. Thisapproach involves two major phases, structure identificationand parameter identification, as shown in Fig. 1. Fuzzy andneural network techniques are usually adopted in the twophases. Consequently, neural-fuzzy modeling possesses theadvantages of both modeling approaches. In the structureidentification phase, fuzzy rules are developed from the givenset of input–output training data. For the purpose of highprecision, the parameters associated with the rules are thenrefined through learning in the parameter identification phase.
Type-1 fuzzy sets, which represent uncertainties by numbersin the range [0, 1], have been widely adopted in neural-fuzzysystems [7]. However, the membership functions of type-1fuzzy sets are often overly precise, requiring each element ofthe universal set to be assigned a particular real number [8].Type-2 fuzzy sets were proposed for dealing with this difficulty[8]. A type-2 fuzzy set allows its associated membershipdegrees to be uncertain and expressed as type-1 fuzzy sets[9]–[16]. The theory of type-2 fuzzy logic systems was studiedin [9], [10], [12], [13], [16], and [17]. However, most of thedeveloped type-2 fuzzy logic systems adopted interval type-2fuzzy sets which are a special type of type-2 fuzzy sets. Thismay be partly due to the fact that the inference involving type-2 fuzzy sets is much more complex and time consuming thanthat involving interval type-2 fuzzy sets. Liang and Mendeldeveloped interval type-2 Takagi-Sugeno-Kang (TSK) fuzzylogic systems [11], [18]. Sepúlveda et al. [19] proposedan efficient implementation of interval type-2 fuzzy logicsystems. Many successful applications of interval type-2 fuzzylogic systems have been published, such as automatic control[19]–[26], function approximation [27]–[30], data classifica-tion [31]–[37], and medical diagnosis [38], [39].
To apply type-2 fuzzy systems, defuzzifying a type-2 fuzzyset is often required. Two steps are usually involved in thistask. Firstly, type reduction is performed, which reduces atype-2 fuzzy set to a type-1 fuzzy set. Secondly, defuzzificationis applied to the resulting type-1 fuzzy set to get the desiredcrisp number. Liu [40] proposed a centroid type-reductionstrategy using α-cuts to decompose a type-2 fuzzy set intoa collection of interval type-2 fuzzy sets, called α-planes [17],and then applying the Karnik–Mendel algorithm [41], [42]for each interval type-2 fuzzy set. Yeh et al. [43] proposeda refined type-reduction algorithm which employs the resultobtained in the previous iteration to initialize the values in thecurrent iteration. Convergence in each iteration speeds up andtype reduction for type-2 fuzzy sets is done faster. Couplandand John [44] proposed a geometric-based defuzzification
1045–9227/$26.00 © 2011 IEEE

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
2 IEEE TRANSACTIONS ON NEURAL NETWORKS
Structureidentification
Input–outputtraining data
Parameteridentification
Initialfuzzy rules Final
fuzzy rules
Fig. 1. Two phases in neuro-fuzzy modeling.
method for type-2 fuzzy sets. However, it has a limitation onthe form of fuzzy sets being used. Rotationally symmetricalmembership functions are to be avoided in a practical system.Lucas et al. [34] calculated a centroid for each verticalslice, which is a type-1 fuzzy set. The calculated centroidsare then combined to form a type-reduced set. Tan and Wu[45] proposed type-reduction strategies for type-2 fuzzy logicsystems using genetic algorithms (GAs). By replacing a type-2 fuzzy set with a collection of equivalent type-1 fuzzy sets,type reduction is simplified to deciding which equivalent type-1 fuzzy set to employ in a particular situation. A GA is used forselecting the equivalent type-1 fuzzy set through an evolutionprocess.
For structure identification, Lin et al. [46] proposed amethod of fuzzy partitioning to extract initial fuzzy rules,but it is hard to decide the locations of cuts and the timecomplexity is high. Wong and Chen [47] proposed a clusteringalgorithm for the job. However, convergence is very slowespecially when the amount of the training data is huge.Thawonmas and Abe [48] also proposed a method for extract-ing fuzzy rules from a set of training patterns. To improvethe approximation accuracy, the method needs to resolvethe problem of overlapping among hyperboxes of differentclasses. Each time, two hyperboxes are considered and newhyperboxes are created for the overlapping area between them.The process iterates until no overlapping occurs between anytwo classes. For parameter identification, several methods forrefining the parameters of type-2 fuzzy rules were proposed.Wang et al. [49] proposed a neural network for interval type-2 fuzzy rules. Gradient descent was adopted for refinement.Hagras [50] corrected some equations for it. Lee et al.[51] proposed a recurrent neural network for interval type-2fuzzy rules using asymmetric Gaussian principal membershipfunctions. The corresponding refining algorithm was derivedfrom gradient descent. Juang and Tsao [52] proposed a self-evolving neural network for interval type-2 fuzzy rules usingsymmetric Gaussian principal membership functions and ahybrid learning algorithm which combines gradient descentand the rule-order Kalman filter. Castro et al. [53] proposedthree interval type-2 fuzzy neural network architectures fortime-series forecasting. Gradient descent backpropagation andgradient descent with adaptive learning rate backpropagationwere adopted for refining the parameters.
We propose a novel approach for constructing a type-2neural-fuzzy system from a given set of input–output trainingdata. In the structure identification phase, a self-constructingfuzzy clustering method is used to partition the training datasetinto clusters through input-similarity and output-similaritytests. The membership function associated with each clusteris defined with the mean and deviation of the data pointsincluded in the cluster. Then a type-2 fuzzy TSK IF-THEN
rule is developed from each cluster to form a fuzzy rule base.In the parameter identification phase, a fuzzy neural networkis constructed for the rules and the associated parameters arerefined by a hybrid learning algorithm which incorporatesparticle swarm optimization (PSO) [54] and least squaresestimation (LSE) [55]. For a new input, a corresponding crispoutput of the system is obtained by combining the inferredresults of all the rules into a type-2 fuzzy set, which is thendefuzzified by applying a refined type reduction algorithm.
The rest of this paper is organized as follows. Section IIintroduces some basic fuzzy concepts. Section III concernsdefuzzification of type-2 fuzzy sets. Fuzzy inference for type-2 fuzzy systems is outlined in Section IV. The derivation oftype-2 fuzzy rules from a given set of input–output trainingdata is described in Section V. Applying learning techniques torefine the parameters associated with the rules is described inSection VI. Experimental results are presented in Section VII.Finally, a conclusion is given in Section VIII.
II. BASIC FUZZY CONCEPTS
A type-2 fuzzy set A on a given universal set X is charac-terized by the membership function μ A(x, u), where x ∈ Xand u ∈ Jx ⊆ [0, 1], and can be represented as [41]
A = {((x, u), μ A(x, u)) | ∀x ∈ X,∀u ∈ Jx } (1)
=∫
x∈X
[∫u∈Jx
μ A(x,u)
u
]
x(2)
in which 0 ≤ μ A(x, u) ≤ 1. We refer to μ A(x) =∫u∈Jx
μ A(x, u)/u as a secondary membership function, which
is a type-1 fuzzy set. Obviously, A can also be represented asA = {(x, μ A(x)) | ∀x ∈ X}. If μ A(x) is an interval for allx ∈ X , then A is an interval type-2 fuzzy set. Furthermore,if μ A(x) is a number in the range [0, 1], A reduces to atype-1 fuzzy set. Also, the principal membership function ofA is defined to consist of all the points whose secondarymembership degree is equal to one [12], [31].
When X is discretized into n points, x1, x2, . . . , xn , (2)becomes
A =n∑
i=1
[∫u∈Jxi
μ A(xi ,u)
u
]
xi(3)
=n∑
i=1
μ A(xi )
xi. (4)
The centroid of A can then be defined as follows [41]:C( A) =
∫u1∈Jx1
· · ·∫
un∈Jxn[μ A(x1, u1)�· · ·�μ A(xn, un)
]∑n
i=1 xi ui∑ni=1 ui
(5)
where � is the minimum t-norm operator. Note that, if A isa type-1 fuzzy set, C( A) is a scalar [7]. If A is an intervaltype-2 fuzzy set, C( A) is an interval set [41], [42], [56], [57].If A is a type-2 fuzzy set, C( A) is a type-1 fuzzy set [40],[41], [44].
This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
YEH et al.: DATA-BASED SYSTEM MODELING USING A TYPE-2 FUZZY NEURAL NETWORK 3
2 4 6 8 100
0.2
0.4
0.6
0.8
1
x
0
0.2
0.4
0.6
0.8
1
0 0.5μ
Ã(x)
1
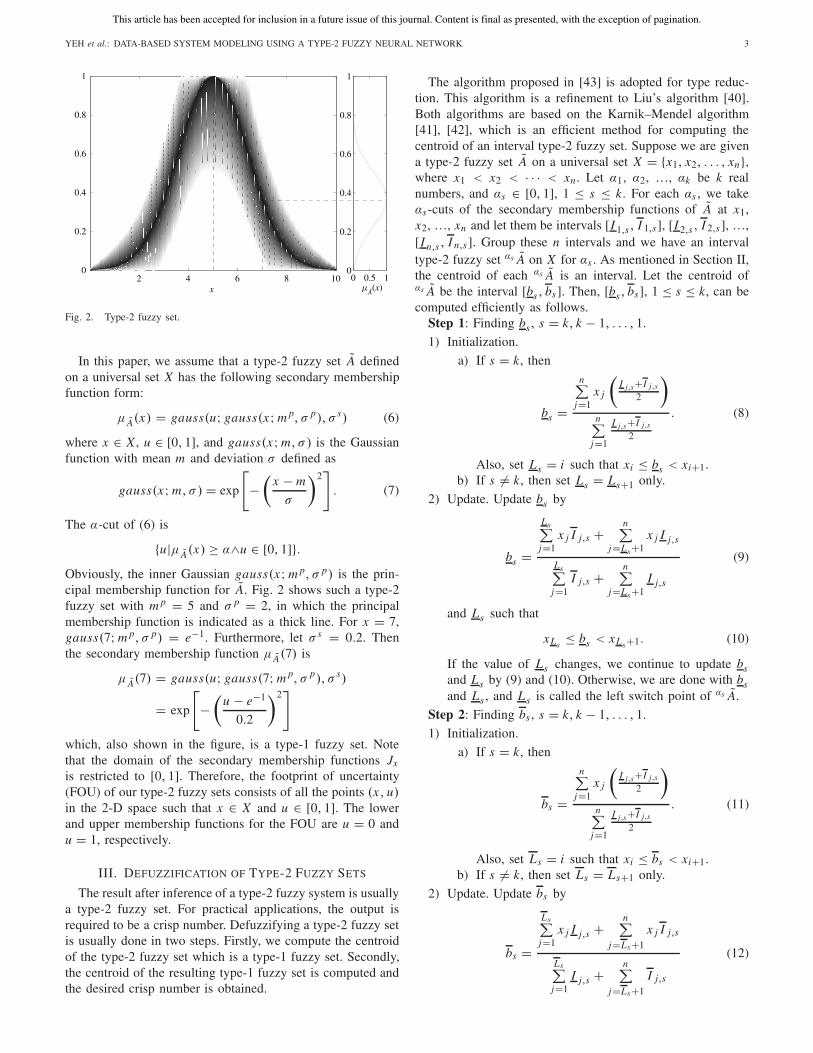
Fig. 2. Type-2 fuzzy set.
In this paper, we assume that a type-2 fuzzy set A definedon a universal set X has the following secondary membershipfunction form:
μ A(x) = gauss(u; gauss(x; m p, σ p), σ s) (6)
where x ∈ X , u ∈ [0, 1], and gauss(x; m, σ ) is the Gaussianfunction with mean m and deviation σ defined as
gauss(x; m, σ ) = exp
[−(
x − m
σ
)2]
. (7)
The α-cut of (6) is
{u|μ A(x) ≥ α∧u ∈ [0, 1]}.Obviously, the inner Gaussian gauss(x; m p, σ p) is the prin-cipal membership function for A. Fig. 2 shows such a type-2fuzzy set with m p = 5 and σ p = 2, in which the principalmembership function is indicated as a thick line. For x = 7,gauss(7; m p, σ p) = e−1. Furthermore, let σ s = 0.2. Thenthe secondary membership function μ A(7) is
μ A(7) = gauss(u; gauss(7; m p, σ p), σ s)
= exp
[−(
u − e−1
0.2
)2]
which, also shown in the figure, is a type-1 fuzzy set. Notethat the domain of the secondary membership functions Jx
is restricted to [0, 1]. Therefore, the footprint of uncertainty(FOU) of our type-2 fuzzy sets consists of all the points (x, u)in the 2-D space such that x ∈ X and u ∈ [0, 1]. The lowerand upper membership functions for the FOU are u = 0 andu = 1, respectively.
III. DEFUZZIFICATION OF TYPE-2 FUZZY SETS
The result after inference of a type-2 fuzzy system is usuallya type-2 fuzzy set. For practical applications, the output isrequired to be a crisp number. Defuzzifying a type-2 fuzzy setis usually done in two steps. Firstly, we compute the centroidof the type-2 fuzzy set which is a type-1 fuzzy set. Secondly,the centroid of the resulting type-1 fuzzy set is computed andthe desired crisp number is obtained.
The algorithm proposed in [43] is adopted for type reduc-tion. This algorithm is a refinement to Liu’s algorithm [40].Both algorithms are based on the Karnik–Mendel algorithm[41], [42], which is an efficient method for computing thecentroid of an interval type-2 fuzzy set. Suppose we are givena type-2 fuzzy set A on a universal set X = {x1, x2, . . . , xn},where x1 < x2 < · · · < xn . Let α1, α2, …, αk be k realnumbers, and αs ∈ [0, 1], 1 ≤ s ≤ k. For each αs , we takeαs -cuts of the secondary membership functions of A at x1,x2, …, xn and let them be intervals [I 1,s, I 1,s], [I 2,s , I 2,s ], …,[I n,s , I n,s ]. Group these n intervals and we have an intervaltype-2 fuzzy set αs A on X for αs . As mentioned in Section II,the centroid of each αs A is an interval. Let the centroid ofαs A be the interval [bs , bs ]. Then, [bs, bs], 1 ≤ s ≤ k, can becomputed efficiently as follows.
Step 1: Finding bs , s = k, k − 1, . . . , 1.
1) Initialization.
a) If s = k, then
bs =
n∑j=1
x j
(I j,s+I j,s
2
)
n∑j=1
I j,s+I j,s
2
. (8)
Also, set Ls = i such that xi ≤ bs < xi+1.b) If s �= k, then set Ls = Ls+1 only.
2) Update. Update bs by
bs =
Ls∑j=1
x j I j,s +n∑
j=Ls+1x j I j,s
Ls∑j=1
I j,s +n∑
j=Ls+1I j,s
(9)
and Ls such that
xLs≤ bs < xLs+1. (10)
If the value of Ls changes, we continue to update bsand Ls by (9) and (10). Otherwise, we are done with bsand Ls , and Ls is called the left switch point of αs A.
Step 2: Finding bs , s = k, k − 1, . . . , 1.
1) Initialization.
a) If s = k, then
bs =
n∑j=1
x j
(I j,s+I j,s
2
)
n∑j=1
I j,s+I j,s
2
. (11)
Also, set Ls = i such that xi ≤ bs < xi+1.b) If s �= k, then set Ls = Ls+1 only.
2) Update. Update bs by
bs =
Ls∑j=1
x j I j,s +n∑
j=Ls+1
x j I j,s
Ls∑j=1
I j,s +n∑
j=Ls+1
I j,s
(12)

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
4 IEEE TRANSACTIONS ON NEURAL NETWORKS
and Ls such that
xLs≤ bs < xLs+1. (13)
If the value of Ls changes, we continue to update bs
and Ls by (12) and (13). Otherwise, we are done withbs and Ls , and Ls is called the right switch point ofαs A.
Obviously, (9) and (12) hold for the centroid [bs, bs ], the leftswitch point Ls , and the right switch point Ls of αs A, 1 ≤ s ≤k. When all the centroids of αs A are computed, the centroidof A can then be derived as
C( A) ≈k⋃
s=1
αs
[bs, bs](14)
by the first decomposition theorem of type-1 fuzzy sets [7].Note that (14) is a type-1 fuzzy set. To get a crisp defuzzi-
fied value y as the system output, we approximate the centroidof (14)
y =∫
C( A)xdx∫C( A)dx
by [58]
y ≈
k∑s=1
αs · bs+bs2
k∑s=1
αs
=
k∑s=1
αs(bs + bs)
2k∑
s=1αs
. (15)
Using (15) instead of a mathematically correct centroid allowsus to apply LSE in the parameter identification phase, asdescribed in Section VI-B.
IV. TYPE-2 FUZZY INFERENCE
Let x1, x2, …, xn be the input variables and y be the outputvariable. A type-2 fuzzy system we are concerned with in thispaper contains a rule base of J rules, R1, R2, …, and RJ ,and each rule R j , 1 ≤ j ≤ J , takes the following TSK-basedform [11], [18]:
R j : IF x1 IS A1, j AND x2 IS A2, j AND · · ·AND xn IS An, j
THEN y IS c j = β0, j + β1, j x1 + · · · + βn, j xn (16)
where β0, j , β1, j , …, βn, j are real-valued parameters andA1, j , A2, j , …, An, j are type-2 fuzzy sets for x1, x2, …, xn ,respectively.
Based on the J rules, a four-layer fuzzy neural network canbe constructed as shown in Fig. 3. For a set of input values,x = [p1, p2, . . . , pn], a crisp output y can be obtained throughthe operation of the fuzzy neural network as follows.
1) Layer 1 contains J groups. Group j corresponds torule R j and contains n nodes. Node i of group jproduces its output, o(1)
i, j , by computing the value of thecorresponding membership function
o(1)i, j = μ Ai, j
(pi) (17)
p1
pi
pn
O(3) O(4)
c1
cj
cJ
y
(2)O1
(1)O1,1
(1)Oi, j
(1)Oi, j
(1)On, j
(1)O1, j
(1)O1, j
(1)Oi, J
(1)On, J
(1)On,1
(2)OJ
(2)OJmn,J, σn,J, σn,J
spp ()
m1,1, σ1,1, σ1,1 spp ()
Fig. 3. Architecture of the fuzzy neural network.
for 1 ≤ i ≤ n and 1 ≤ j ≤ J . Note that each o(1)i, j is a
type-1 fuzzy set.2) Layer 2 contains J nodes. Node j produces its output,
o(2)j , by computing the firing strength of rule R j
o(2)j = o(1)
1, j×o(1)2, j×· · ·×o(1)
n, j (18)
for 1 ≤ j ≤ J , where we adopt the arithmetic product“×” for “AND.” For two type-1 fuzzy sets A and B ,A×B is defined as [7]
A×B =⋃
α∈[0,1]
αα(A×B)
(19)
α(A×B) = α A×α B
= [α Al×α Bl ,
α Ar×α Br]
(20)
where α A and α B are α-cuts of A and B , respectively,α Al and α Bl denote the lower bound of α A and α B ,respectively, and α Ar and α Br denote the upper boundof α A and α B , respectively. The product operation in(19) produces the same result as the more commonlyused meet operation [13]. However, (19) involves lesscomputation. Besides, the way using α-cuts matches theway type reduction of a type-2 fuzzy set is done. Notethat A×B is also a type-1 fuzzy set. Obviously, eacho(2)
j is a type-1 fuzzy set.3) Layer 3 contains only one node whose output, o(3), is
the result of performing type reduction on its input. Inthis layer, the consequent value c j of each rule R j iscomputed as
c j = β0, j + β1, j p1 + · · · + βn, j pn (21)
for 1 ≤ j ≤ J . Next, c1, c2, …, cJ are sorted inascending order, and let the resulting sequence be c j1 ,c j2 , …, c jJ . Obviously, the set
D =J∑
i=1
o(2)ji
c ji(22)
is a type-2 fuzzy set defined on the discrete universalset {c j1, c j2, . . . , c jJ }. Then type reduction, as presented

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
YEH et al.: DATA-BASED SYSTEM MODELING USING A TYPE-2 FUZZY NEURAL NETWORK 5
Input–outputtraining data
Fuzzyclusters Initial
fuzzy rules
Using self-constructing
clustering to groupthe training patternsinto fuzzy clusters
Convertingclusters into type-2
fuzzy TSK IF-THENrules
Fig. 4. Structure identification phase.
in Section III, is carried out on D and o(3) becomes theresult of (14).
4) Layer 4 contains only one node which performs defuzzi-fication on its input, o(3). Its output, o(4), is the resultof (15).
The crisp system output y corresponding to the input x =[p1, p2, . . . , pn] is then set to be the output o(4).
V. STRUCTURE IDENTIFICATION
As usual, our approach to system modeling based on agiven set of input–output training data consists of two stages,structure identification and parameter identification. In thestructure identification phase, as shown in Fig. 4, initial fuzzyrules are developed from the given set of input–output trainingdata. First, a self-constructing fuzzy clustering algorithm isemployed to partition the training data into a collection offuzzy clusters. Second, the clusters are converted into a rulebase of type-2 fuzzy TSK IF-THEN rules. For the purpose ofhigh precision, the parameters associated with the rules arethen refined through learning in the parameter identificationphase, to be presented later.
Assume the system to be modeled has n inputs, x1, x2, …,xn and one output y. The given training dataset contains �patterns < p(1), d(1) >, < p(2), d(2) >, …, < p(�), d(�) >
where p(r) = [p(r)1 , p(r)
2 , . . . , p(r)n ] denotes the n input values
and d(r) denotes the corresponding desired output value of ther th pattern, 1 ≤ r ≤ �. The self-constructing fuzzy clusteringmethod partitions the training dataset into clusters throughinput-similarity and output-similarity tests. A cluster containsa certain number of training patterns, and is characterized bythe product of n 1-D Gaussian functions. Gaussian functionsare adopted because of their superiority over other functionsin performance [59], [60]. In addition, each cluster keeps aheight which is the average of the desired outputs of thepatterns contained in the cluster. The clustering algorithm isan incremental self-constructing learning approach. Trainingpatterns are considered one by one. No clusters exist at thebeginning, and clusters can be created if necessary. For eachpattern, the similarity of this pattern to each existing clusteris calculated to decide whether it is combined into an existingcluster or a new cluster is created. When all training patternshave been considered, we get a number of clusters that arethen converted to type-2 fuzzy TSK IF-THEN rules. Detailsare described below.
Let k be the number of currently existing clusters,denoted by G1, G2, …, Gk , respectively. Each cluster G j
has mean m j = [m1, j , m2, j , . . . , mn, j ], deviation σ j =[σ1, j , σ2, j , . . . , σn, j ], and height h j . Let Sj be the size ofcluster G j , i.e., the number of training patterns contained inG j . Initially, we have k = 0. So, no clusters exist at the
beginning. For pattern r , i.e., < p(r), d(r) >, 1 ≤ r ≤ �,we calculate the input similarity of pattern r to each existingcluster G j as follows:
μG j (p(r)) =
n∏i=1
exp
⎡⎣−
(p(r)
i − mi, j
σi, j
)2⎤⎦ (23)
for 1 ≤ j ≤ k. Notice that 0 ≤ μG j (p(r)) ≤ 1. If p(r) is close
to the mean m j of cluster G j , then μG j (p(r)) ≈ 1. On the
contrary, If p(r) is far away from the mean m j of cluster G j ,then μG j (p
(r)) ≈ 0. We say that pattern r passes the inputsimilarity test on cluster G j if
μG j (p(r)) ≥ ρ (24)
where ρ, 0 ≤ ρ ≤ 1, is a predefined threshold. If the userintends to have larger clusters, then he/she can give a smallerthreshold. Otherwise, a bigger threshold can be given. Asthe threshold increases, the number of clusters also increases.Furthermore, we calculate the output similarity of pattern r toeach existing cluster G j as follows:
e j = |d(r) − h j | (25)
where h j is the height of G j . Let dmax and dmin denote themaximum and minimum of the desired outputs
dmax = max1≤i≤�
d(i), dmin = min1≤i≤�
d(i).
We say that pattern r passes the output-similarity test oncluster G j if
e j ≤ τ (dmax − dmin) (26)
where τ , 0 ≤ τ ≤ 1, is another predefined threshold. Asτ decreases, the test gets tighter and more clusters will beproduced.
Two cases may occur. First, there are no existing clusters onwhich pattern r has passed both the input-similarity test andthe output-similarity test. In this case, we assume that patternr is not similar enough to any existing cluster. We increase kby 1. A new cluster is created by setting its mean to be p(r)
itself, its deviation to be a default vector σ 0 = [σ0, . . . , σ0],and its height to be d(r)
k = k + 1, mk = p(r), σ k = σ 0, hk = d(r). (27)
Note that the deviation of this new cluster Gk is 0 since itcontains only one member. We cannot use zero deviation inthe calculation of fuzzy similarities. Therefore, we initializethe deviation σ k of Gk to be σ 0. On the other hand, if thereare existing fuzzy clusters on which pattern r has passed boththe input-similarity test and the output-similarity test, let G j1 ,G j2 , …, G j f be such clusters and let the cluster with thegreatest input similarity be cluster t
t = arg maxj= j1,..., j f
μG j (p(r)). (28)
In this case, we assume that pattern r is closest to cluster Gt .Now the mean mt , the deviation σ t , the height ht , and thesize St of Gt are modified to include pattern r as its member.Let the superscripts o and n denote the values before and after

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
6 IEEE TRANSACTIONS ON NEURAL NETWORKS
—————————————————————————-Algorithm—————————————————————————-procedure Self-Constructing-Clusteringfor r = 1 to �
Calculate the input and output similarities betweenpattern r and each currently existing cluster by(23) and (25);
if there is no cluster on which pattern r haspassed both the input- and output-similaritytests of (24) and (26)
Create a new cluster by (27);else
Combine pattern r to the cluster to which patternr is most similar by (29)–(33);
endifendforendprocedure—————————————————————————-
modification. For example, Sot and Sn
t indicate the size of Gt
before and after, respectively, p(r) is included. Then we have
mni,t =
∑Snt
v=1 p(v)i
Snt
= Sot ×mo
i,t + p(r)i
Sot + 1
(29)
σ ni,t =
√√√√∑Snt
v=1(p(v)i − mn
i,t )2
Snt − 1
(30)
= √A − B (31)
hnt =
∑Snt
v=1 d(v)
Snt
= Sot ×ho
t + d(r)
Sot + 1
(32)
for 1 ≤ i ≤ n, where A = ((Sot − 1)(σ o
i,t )2 + So
t ×(moi,t )
2+(p(r)
i )2/Sot ) and B = (Sn
t /Sot (mn
i,t )2), and
Snt = So
t + 1 (33)
which increases the size of Gt by 1. The aforementionedprocess is iterated until all the training patterns have beenprocessed. The algorithm can be summarized as shown above.
Note that the order in which the training patterns are fedin influences the clusters obtained. We apply a heuristic todetermine the order. We sort all the patterns, in decreasingorder, by their largest input values. Then the patterns arefed in this order. For example, let < [0.1, 0.3, 0.6], 0.7 >,< [0.3, 0.3, 0.4], 0.9 >, and < [0.8, 0.1, 0.1], 0.5 > be threetraining patterns. The largest input values in these patterns are0.6, 0.4, and 0.8, respectively. The sorted list is 0.8, 0.6, 0.4.So the order of feeding is pattern 3, pattern 1, and pattern 2.In this way, more significant patterns will be fed in first andlikely become the core of the underlying cluster.
Suppose we have J clusters after clustering. Then weconvert each cluster to a type-2 fuzzy rule and we have aset of J rules, R1, R2, …, RJ . Each rule R j is in the form of(16), where the membership function of Ai, j , 1 ≤ i ≤ n, is
μ Ai, j(xi ) = gauss(u; gauss(xi; m p
i, j , σp
i, j ), σsi, j ) (34)
where u ∈ [0, 1]. The antecedent parameters of rule R j includem p
i, j , σp
i, j , and σ si, j , 1 ≤ i ≤ n, which are initialized according
to the mean and deviation of cluster G j as follows:m p
i, j = mi, j (35)
σp
i, j = σi, j (36)
σ si, j = κσi, j (37)
for 1 ≤ i ≤ n, where κ is a small user-defined constant,e.g., κ = 0.1. The consequent parameters of rule R j includeβ0, j , β1, j , …, βn, j which are initialized as follows. Let the Sj
training patterns included in cluster G j be < p( j1), d( j1) >,
< p( j2), d( j2) >, …, < p( jS j ), d( j S j ) >. Then β0, j , β1, j , …,βn, j are set to be the least squares solution of
minβ
‖Y − Xβ‖ (38)
where
Y =[d( j1) d( j2) · · · d( jS j )
]T
X =
⎡⎢⎢⎢⎢⎣
1 p( j1)1 p( j1)
2 · · · p( j1)n
1 p( j2)1 p( j2)
2 · · · p( j2)n
......
......
...
1 p( jS j )
1 p( jS j )
2 · · · p( jS j )
n
⎤⎥⎥⎥⎥⎦ (39)
β = [β0, j β1, j β2, j . . . βn, j
]T. (40)
An iterative divide-and-merge-based least squares estimator[55], designed for solving large problems efficiently, is adoptedfor finding an optimal β in (38).
VI. PARAMETER IDENTIFICATION
After the set of J initial fuzzy rules is obtained in thestructure identification phase, we proceed to improve theprecision of these rules, by refining the antecedent andconsequent parameters involved, through the application ofa hybrid learning algorithm. Since we have J rules andeach rule has 3n antecedent parameters, we have 3n J suchparameters in total, i.e., m p
1,1, σp
1,1, σ s1,1, …, m p
n,1, σp
n,1, σ sn,1,
…, m p1,J , σ
p1,J , σ s
1,J , …, m pn,J , σ
pn,J , σ s
n,J . Also, each rulehas n + 1 consequent parameters, so we have (n + 1)J suchparameters in total, i.e., β0,1, β1,1, …, βn,1, …, β0,J , β1,J , …,βn,J . In PSO is used to optimize the antecedent parametersand LSE is used to optimize the consequent parameters. Aniteration of learning involves the presentation of all trainingpatterns. In each iteration of learning, both PSO and LSE areapplied. We first treat all the consequent parameters as fixedand use PSO to refine the antecedent parameters. Then wetreat all the antecedent parameters as fixed and use LSE torefine the consequent parameters. The process is iterated, asshown in Fig. 5, until the desired approximation precision isachieved.
A. Refining Antecedent Parameters
As mentioned earlier, we treat all the consequent para-meters as fixed and use PSO to refine the antecedent para-meters. PSO is a population-based global search algorithm

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
YEH et al.: DATA-BASED SYSTEM MODELING USING A TYPE-2 FUZZY NEURAL NETWORK 7
Initialfuzzy rules
Using PSOto refine theantecedentparameters
Using LSEto refine theconsequentparameters
Requiredprecisionachieved?
Finalfuzzy rules
No
Yes
Fig. 5. Parameter identification phase.
for problem solving, proposed by Kennedy and Eberhart in1995 [54]. Given a problem, it starts with a swarm of Sparticles. Each particle is associated with a position, which isa candidate solution, and a velocity within the search space.In each iteration, the positions of all particles are updated.Let the position and velocity of particle i in iteration t bedenoted by P(i)
t and V(i)t , respectively. In iteration t + 1,
we update the velocity of particle i , 1 ≤ i ≤ S, asfollows:
V(i)t+1 = w × V(i)
t + k1 × rand1 × (Pbest(i) − P(i)t )
+ k2 × rand2 × (Gbest − P(i)t ) (41)
where w, k1, and k2 are the coefficients of inertia, cognitive,and social, respectively, rand1 and rand2 are uniformlydistributed random numbers in [0, 1], Pbest(i) is the bestprevious position of particle i , and Gbest is the overall bestparticle position so far. Then the position of particle i isupdated by
P(i)t+1 = P(i)
t + V(i)t+1 (42)
for 1 ≤ i ≤ S. When all the particles in the swarm have gottheir positions updated, the current iteration is done and theswarm is ready for the next iteration. For more details aboutPSO, refer to [54].
In our case, the objective function to be optimized by PSOis the mean square error (MSE) with respect to the trainingpatterns. The position of particle i in iteration t consists ofthe 3n J antecedent parameters as follows:
P(i)t =
[m p
1,1, σp
1,1, σs1,1, ..., m p
n,1, σp
n,1, σsn,1, . . . ,
m p1, j , σ
p1, j , σ
s1, j , . . . , m p
n, j , σp
n, j , σsn, j , . . . ,
m p1,J , σ
p1,J , σ s
1,J , . . . , m pn,J , σ
pn,J , σ s
n,J
]. (43)
We set P(1)0 as consisting of the initial values of the consequent
parameters as shown in (35)–(37). The positions of the otherparticles, P(i)
0 , 2 ≤ i ≤ S, are set to be randomly generatedvariants of P(1)
0 . The best position of a particle or all theparticles is determined as having the smallest MSE betweenthe system output and the desired output of all the trainingpatterns. The velocity of particle i in iteration t , V(i)
t , is alsoa vector of 3n J components. Initially, we set each componentin V(i)
0 , 1 ≤ i ≤ S to be a random number between −0.5 and0.5.
B. Refining Consequent Parameters
To refine consequent parameters, we treat all antecedentparameters as fixed (Fig. 3). For training pattern r , i.e.,(p(r), d(r)), 1 ≤ r ≤ �, let o(1)
i, j (r), o(2)j (r), and o(4)(r) denote
the actual output of layers 1, 2, and 4, respectively, for thispattern. We have
o(1)i, j (r) = μ Ai, j
(p(r)i )
= gauss(u; gauss(p(r)i ; m p
i, j , σp
i, j ), σsi, j ) (44)
o(2)j (r) = o(1)
1, j (r)×o(1)2, j (r)×· · ·×o(1)
n, j (r). (45)
By (15), we have
o(4)(r) =
k∑s=1
αs
(b(r)
s + b(r)s
)
2k∑
s=1αs
(46)
where, by (9) and (12)
b(r)s =
L(r)s∑
j=1c(r)
j I(r)j,s +
J∑j=L(r)
s +1
c(r)j I (r)
j,s
L(r)s∑
j=1I(r)j,s +
J∑j=L(r)
s +1
I (r)j,s
(47)
b(r)s =
L(r)s∑
j=1c(r)
j I (r)j,s +
J∑j=L
(r)s +1
c(r)j I
(r)j,s
L(r)s∑
j=1I (r)
j,s +J∑
j=L(r)s +1
I(r)j,s
(48)
with c(r)j = ∑n
t=0 βt, j p(r)t being the consequent part of rule
R j for p(r). For convenience, we add the component p(r)0 and
set p(r)0 = 1 for 1 ≤ r ≤ �. Note that
[I (r)
j,s, I(r)j,s
]is the αs -cut
of o(2)j (r) for 1 ≤ r ≤ �, 1 ≤ j ≤ J , and 1 ≤ s ≤ k. Let
H (r)t, j,s =
⎧⎨⎩
p(r)t I
(r)j,s, if j ≤ L(r)
s
p(r)t I (r)
j,s, if j > L(r)s
(49)
K (r)t, j,s =
⎧⎨⎩
p(r)t I (r)
j,s, if j ≤ L(r)s
p(r)t I
(r)j,s, if j > L
(r)s
(50)
W (r)s =
L(r)s∑
j=1
I(r)j,s +
J∑j=L(r)
s +1
I (r)j,s (51)
Z (r)s =
L(r)s∑
j=1
I (r)j,s +
J∑j=L
(r)s +1
I(r)j,s . (52)

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
8 IEEE TRANSACTIONS ON NEURAL NETWORKS
Then (46) becomes
o(4)(r) =
k∑s=1
αs
[J∑
j=1
n∑t=0
(H (r)
t, j,s
W (r)s
+ K (r)t, j,s
Z (r)s
)βt, j
]
2k∑
s=1αs
=
J∑j=1
n∑t=0
[k∑
s=1αs
(H (r)
t, j,s
W (r)s
+ K (r)t, j,s
Z (r)s
)]βt, j
2k∑
s=1αs
. (53)
Let
x (r)t, j =
k∑s=1
αs
(H (r)
t, j,s
W (r)s
+ K (r)t, j,s
Z (r)s
)
2k∑
s=1αs
. (54)
We have
o(4)(r) =J∑
j=1
n∑t=0
x (r)t, j βt, j (55)
for 1 ≤ r ≤ �. Letting d(r) = o(4)(r), we have
d(r) =J∑
j=1
n∑t=0
x (r)t, j βt, j (56)
for 1 ≤ r ≤ �, resulting in the following linear system:Y = Xβ (57)
where
Y = [d(1) d(2) · · · d(�)
]T
X =
⎡⎢⎢⎢⎢⎣
x (1)0,1 x (1)
1,1 · · · x (1)n,1 · · · x (1)
n,J
x (2)0,1 x (2)
1,1 · · · x (2)n,1 · · · x (2)
n,J...
......
......
...
x (�)0,1 x (�)
1,1 · · · x (�)n,1 · · · x (�)
n,J
⎤⎥⎥⎥⎥⎦ (58)
β = [β0,1 β1,1 · · · βn,1 · · · βn,J
]T (59)
with the sizes �×1, �×(n+1)J , and (n+1)J×1, respectively.Again, the iterative divide-and-merge-based least squares esti-mator is adopted to find an optimal β in (57).
VII. EXPERIMENTAL RESULTS
We demonstrate the performance of our approach by show-ing the results of several experiments. In Experiment I, we usea simple function to illustrate how our approach works. In thesubsequent two experiments, we run on another function and areal-world dataset, respectively. A comparison with two othermethods, adopting type-1 fuzzy sets [5] and interval type-2fuzzy sets [52], respectively, is presented. For convenience,in the following our approach is abbreviated as T2FNN andthe other two as T1FNN and IT2FNN, respectively. We usea computer with Intel(R) Xeon(TM) CPU X5420 2.50 GHzand 4 GB of RAM to conduct the experiments. The operatingsystem is CentOS 5.3. The programming language used isJAVA 1.6.
In T1FNN, the fuzzy sets involved in the antecedent partof a fuzzy rule are type-1 fuzzy sets and have Gaussianmembership functions. That is, all the Ai, j , 1 ≤ i ≤ n, 1 ≤j ≤ J , in (16) are type-1 fuzzy sets having the membershipfunction in the form as shown in (7). In IT2FNN, the fuzzysets involved in the antecedent part of a fuzzy rule are intervaltype-2 fuzzy sets. The principal membership function of eachinterval type-2 fuzzy set is bound by two Gaussian functionswith distinct means. The consequent part in both T1FNNand IT2FNN has the same form as that shown in (16). ForT1FNN, the antecedent parameters to be refined include themean and the deviation of each type-1 fuzzy set. For IT2FNN,the antecedent parameters to be refined include two means andtwo deviations associated with each interval type-2 fuzzy set.The consequent parameters to be refined for both T1FNN andIT2FNN are totally the same as for T2FNN.
A. Experiment I
The first experiment concerns the modeling of the followingnonlinear function
y = x21 × sin(x2π) (60)
where x1 and x2 are the inputs, x1, x2 ∈ [−1, 1], and y is theoutput. The function is shown graphically in Fig. 6(a).
We take 15 samples randomly in x1 and x2, respectively,and have 15×15 = 225 training patterns, i.e., � = 225.
Step 1. Structure identification phase.We run the self-constructing fuzzy clustering algorithm on thetraining patterns with ρ = 0.0001, τ = 0.4, and σ0 = 0.1. Sixclusters G1, G2, G3, G4, G5, and G6 are obtained as shownin Table I.
According to theses clusters, the following initial type-2fuzzy rules are developed.
1) R1: IF x1 is gauss(u; gauss(x1; −0.7009, 0.4523),0.04523)AND x2 is gauss(u; gauss(x2; −0.6518, 0.4762),0.04762)THEN y is c1 = −0.1796 + 0.6368x1 − 0.4315x2.
2) R2: IF x1 is gauss(u; gauss(x1; −0.0849, 0.6968),0.06968)AND x2 is gauss(u; gauss(x2; 0.2728, 0.7179), 0.07179)THEN y is c2 = 0.0508 − 0.0792x1 + 0.1204x2.
3) R3: IF x1 is gauss(u; gauss(x1; 0.3786, 0.3486),0.03486)AND x2 is gauss(u; gauss(x2; −0.6143, 0.4275),0.04275)THEN y is c3 = −0.0090 − 0.5690x1 − 0.1706x2.
4) R4: IF x1 is gauss(u; gauss(x1; 0.8435, 0.3348),0.03348)AND x2 is gauss(u; gauss(x2; −0.6122, 0.4898),0.04898)THEN y is c4 = 0.1248 − 1.0475x1 − 0.4992x2.
5) R5: IF x1 is gauss(u; gauss(x1; 0.9184, 0.2923),0.02923)AND x2 is gauss(u; gauss(x2; 0.4694, 0.5040), 0.05040)THEN y is c5 = −0.5280 + 1.0188x1 + 0.2667x2.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
YEH et al.: DATA-BASED SYSTEM MODELING USING A TYPE-2 FUZZY NEURAL NETWORK 9
−1−0.5
00.5
1
−1
−0.5
0
0.5
1−1
−0.5
0
0.5
1
(a)
−1−0.5
00.5
1
−1
−0.5
0
0.5
1−1
−0.5
0
0.5
1
(b)
−1−0.5
00.5
1
−1
−0.5
0
0.5
1−1
−0.5
0
0.5
1
(c)
Fig. 6. Experiment I. (a) Output of the desired function. (b) Output of thesix initial rules. (c) Output of the six refined rules.
6) R6: IF x1 is gauss(u; gauss(x1; −0.8857, 0.3195),0.03195)AND x2 is gauss(u; gauss(x2; 0.6286, 0.3629), 0.03629)THEN y is c6 = −0.6621 − 1.9206x1 − 0.5515x2.
Note that u ∈ [0, 1]. These rules provide an approximationto the original function, as shown in Fig. 6(b), with a MSE
TABLE I
SIX CLUSTERS OBTAINED FOR EXPERIMENT I
Mean m j Standard deviation σ j Height h j
G1 [ -0.7009 -0.6518 ] [ 0.4523 0.4762 ] −0.3447
G2 [ -0.0849 0.2728 ] [ 0.6968 0.7179 ] 0.0904
G3 [ 0.3786 -0.6143 ] [ 0.3486 0.4275 ] −0.1196
G4 [ 0.8435 -0.6122 ] [ 0.3348 0.4898 ] −0.4532
G5 [ 0.9184 0.4694 ] [ 0.2923 0.5040 ] 0.5329
G6 [ −0.8857 0.6286 ] [ 0.3195 0.3629 ] 0.6924
of 0.0259 with respect to the training patterns. For example,when x1 = 0.57143 and x2 = −0.71429, the desired y valueis −0.25529 by (60). Using the six rules, a fuzzy network inthe form of Fig. 3 is built and we can approximate the y valueas follows. Layer 1 computes the values of the correspondingmembership functions. For example, o(1)
1,1 and o(1)2,1 have the
following values:o(1)
1,1 = gauss(u; gauss(0.57143; −0.7009, 0.4523), 0.04523)
o(1)2,1 = gauss(u; gauss(−0.71429; −0.6518, 0.4762),
0.04762).
Layer 2 computes the firing strength of each rule. For example,the firing strength of R1 is
o(2)1 = o(1)
1,1 × o(1)2,1
which is a type-1 fuzzy set. Layer 3 performs type reductionon its input, which is a type-2 fuzzy set, and produces outputo(3) which is a type-1 fuzzy set. Finally, layer 4 performsdefuzzification on o(3) and its output o(4) is −0.16285. There-fore, the inferred output for x1 = 0.57143 and x2 = −0.71429from the above six rules is y = o(4) = −0.16285. The squareerror induced is (y − y)2 = 0.00855.
Step 2. Parameter identification phase.We improve the precision of the rules through the applicationof the hybrid learning algorithm. For PSO, the population sizeis set as 10, and the parameters w, k1, and k2 are set as 0.5, 1.0,and 1.0, respectively. The refined type-2 fuzzy rules obtainedare as follows.
1) R1: IF x1 is gauss(u; gauss(x1; −0.2133, 1.2042),0.0001)AND x2 is gauss(u; gauss(x2; 0.5924, 1.1628), 0.0118)THEN y is c1 = 0.0722 + 0.2398x1 + 0.0337x2.
2) R2: IF x1 is gauss(u; gauss(x1; −1.0801, 0.4464),0.0022)AND x2 is gauss(u; gauss(x2; −0.7499, 0.4334), 0.0013)THEN y is c2 = −2.0984 + 0.6210x1 − 2.5029x2.
3) R3: IF x1 is gauss(u; gauss(x1; 0.7509, 0.4421),0.0013)AND x2 is gauss(u;gauss(x2;−0.1818, 0.4888),0.0007)THEN y is c3 = 2.4349 − 4.9684x1 + 1.2439x2.
4) R4: IF x1 is gauss(u; gauss(x1; 0.3829, 0.4691),0.1992)AND x2 is gauss(u;gauss(x2;−0.6381, 0.8518),0.1709)THEN y is c4 = −0.7471 + 0.1108x1 − 0.7452x2.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
10 IEEE TRANSACTIONS ON NEURAL NETWORKS
TABLE II
RESULTS FOR EXPERIMENT II WITH THE VERSION 1 TRAINING DATA
No. of rules Training MSE Testing MSE Time
T1FNN 6 0.00173 0.00111 1.806
IT2FNN 6 0.00095 0.00066 3.332
T2FNN 6 0.00056 0.00040 3.448
TABLE III
RESULTS FOR EXPERIMENT II WITH THE VERSION 2 TRAINING DATASET
No. of rules Training MSE Testing MSE Time
T1FNN 6 0.04762 0.01085 1.569
IT2FNN 6 0.04185 0.00781 3.924
T2FNN 6 0.03936 0.00541 4.489
5) R5: IF x1 is gauss(u; gauss(x1; 0.9167, 0.3129),0.2120)AND x2 is gauss(u; gauss(x2; 0.7078, 0.8724), 0.0004)THEN y is c5 = 2.3696 + 0.9077x1 − 3.2286x2.
6) R6: IF x1 is gauss(u; gauss(x1; −0.8344, 0.4774),0.0008)AND x2 is gauss(u;gauss(x2; 0.5073, 0.3346), 0.2629)THEN y is c6 = −0.4988 − 2.3208x1 + 0.1153x2.
The output of these refined rules is shown in Fig. 6(c) withan MSE of 0.0012 with respect to the training patterns.Apparently, the refined rules give a better approximation tothe original function than the initial rules. For example, whenx1 = −0.5714 and x2 = −0.7143, the inferred output fromthe refined rules is y = −0.25472. The square error inducedis (y − y)2 = 3.25 × 10−7.
B. Experiment II
This experiment investigates the noise resistance of eachmethod. Consider the following nonlinear function [5], [47]:
y = sin(x1π) · sin(x2π) (61)
where x1 and x2 are the inputs, y is the output, and x1 ∈[−1, 1] and x2 ∈ [0, 1]. The input–output training data pairs,< [p1, p2], d >, are taken by sampling x1 and x2 with thesampling interval being 0.1. As a result, there are totally 231input–output training patterns, i.e., � = 231. We also take200 samplings in random for testing. The values of ρ, τ , andσ0 are set to be 0.012, 0.2, and 0.15, respectively, for theself-constructing fuzzy clustering algorithm. We consider threeversions of the training dataset. Version 1 contains uncorrupteddata, i.e., no noise added. In Version 2, the training data arecorrupted by adding a noise which is a normal distributionwith zero mean and standard deviation being 0.2. In Version3, the noise added is a normal distribution with zero mean andstandard deviation being 0.3. Note that noise is added to allof the patterns in Version 2 and Version 3.
Table II shows the results for the Version 1 trainingdataset. Note that 6 rules are obtained. The column “TrainingMSE” indicates the induced error with respect to the training
TABLE IV
RESULTS FOR EXPERIMENT II WITH THE VERSION 3 TRAINING DATASET
No. of rules Training MSE Testing MSE Time
T1FNN 6 0.08074 0.01943 2.672
IT2FNN 6 0.08422 0.01626 5.694
T2FNN 6 0.07856 0.00997 6.364
TABLE V
RESULTS FOR EXPERIMENT II WITH THE POPULATION SIZE BEING 20
Version 1 Version 2 Version 3
Training MSE 0.00058 0.03918 0.07555
Testing MSE 0.00039 0.00510 0.00951
patterns, while the column “Testing MSE” indicates theinduced error with respect to the testing patterns. The column“Time” indicates the CPU time, in seconds, spent in modeling,i.e., the time spent in structure and parameter identificationphases. From this table, we can see T2FNN achieves the besttraining and testing MSE. For example, T2FNN gets 0.00056in training MSE and 0.00040 in testing MSE, while T1FNNgets 0.00173 and 0.00111 and IT2FNN gets 0.00095 and0.00066, respectively. However, T1FNN runs faster, taking1.806 s in this case. T2FNN and IT2FNN run comparablyslow. Note that computation time is not an importantissue when systems are not going to be run in real time.Table III shows the results for the Version 2 training dataset.Apparently, T2FNN achieves the best training and testingMSE. For example, T2FNN gets 0.03936 in training MSEand 0.00541 in testing MSE, while T1FNN gets 0.04762 and0.01085 and IT2FNN get 0.04185 and 0.00781, respectively.Table IV shows the results for the Version 3 training dataset.Obviously, T2FNN achieves the best training and testingMSE for this case. For example, T2FNN gets 0.07856 intraining MSE and 0.00997 in testing MSE, while T1FNNgets 0.08074 and 0.01943, and IT2FNN gets 0.08422 and0.01626, respectively. Note that IT2FNN has a worse trainingerror than T1FNN for this case. T1FNN runs faster, taking2.672 s in this case, and T2FNN and IT2FNN run slower.
For PSO, the population size is set as 10. Changing thesize does not make much difference in the results. Table Vshows the results obtained with the population size being 20for the three versions of the training data. The testing MSEsare only slightly better than those shown in Tables II–IV. Forexample, for the Version 1 training dataset the testing MSEis 0.00040 with size being 10 and is 0.00039 with size being20. The difference between them is small, within 3%. Thisindicates that the initial fuzzy rules obtained from the clus-tering algorithm already provide a pretty good approximation.Therefore, a small population size, e.g., 10, in PSO is sufficientin parameter identification.
A standard neural network provided in MATLAB [61] isalso tried for the above three cases. The number of hiddennodes is set to be 6, gradient descent is applied for trainingwith 0.1 as the learning rate, and 1000 epochs are done before

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
YEH et al.: DATA-BASED SYSTEM MODELING USING A TYPE-2 FUZZY NEURAL NETWORK 11
TABLE VI
RESULTS FOR EXPERIMENT III WITH DIFFERENT ρ VALUES
No. of T1FNN IT2FNN T2FNN
ρ rules MSE Time MSE Time MSE Time
0.17 2.7 0.0091 3.037 0.0088 4.071 0.0070 5.290
0.27 3.0 0.0093 3.570 0.0089 4.493 0.0080 6.133
0.37 4.7 0.0111 7.037 0.0066 9.150 0.0057 9.437
TABLE VII
p-VALUES FOR EXPERIMENT III WITH DIFFERENT ρ VALUES
ρ T2FNN versus T1FNN T2FNN versus IT2FNN
0.17 0.0019 0.0032
0.27 0.0002 0.0008
0.37 0.0006 0.0006
termination. For each case, we run 200 times and choose thebest performance for comparison. The testing MSE for theversion of uncorrupted training data is 0.0028. For the othertwo versions, they are 0.0236 and 0.0296, respectively.
C. Experiment III
The last experiment concerns a real-world dataset, milesper gallon (MPG), taken from UCI Repository of MachineLearning Databases [62]. The MPG dataset is used for evalu-ating the city-cycle fuel consumption in miles per gallon. Thisdataset contains 392 patterns, each pattern consisting of seveninput values and one output value. Tenfold cross-validationis applied, i.e., nine-tenths of the patterns are used for train-ing and the remaining one-tenth for testing. Ten runs wereconducted and the outcomes of these 10 runs are averaged.Table VI shows the results with τ = 0.5, σ0 = 0.2, and threedifferent ρ values. Note that ρ is a user-defined thresholdfor input similarity test in the self-constructing clusteringalgorithm. The setting of ρ may affect the number of clustersobtained. As ρ increases, the patterns in a cluster are requiredto be more similar to each other and thus the number of clus-ters obtained also increases. The column “MSE” in Table VIindicates the induced error with respect to the testing patterns.As seen from the table, T2FNN achieves the best MSE for thetesting data. For example, T2FNN gets 0.0070 in MSE, whileT1FNN and IT2FNN get 0.0091 and 0.0088, respectively, with2.7 rules. However, T2FNN runs slower than the other twomethods. For example, T1FNN and IT2FNN require 3.037and 4.071 s, respectively, in modeling, while T2FNN requires5.290 s in this case. To rule out random effects in comparisons,paired samples t-tests were conducted for two pairs of com-petitors, T2FNN versus T1FNN and T2FNN versus IT2FNN.A paired sample t-test [63] can be used to compare the meansof two variables. It computes the difference between the twovariables and tests to see if the average difference is signif-icantly different from zero. In this experiment, we comparedifferent methods by using the same sets of training and testingdata each time. By regarding each method as a variable, wecan apply a paired sample t-test to test if there is a significant
TABLE VIII
RESULTS FOR EXPERIMENT III WITH DIFFERENT τ VALUES
No. of T1FNN IT2FNN T2FNN
τ rules MSE Time MSE Time MSE Time
0.4 3.0 0.0090 3.792 0.0097 4.707 0.0079 6.852
0.5 2.7 0.0091 3.037 0.0088 4.071 0.0070 5.290
0.6 2.4 0.0097 2.508 0.0082 3.386 0.0076 4.143
TABLE IX
p-VALUES FOR EXPERIMENT III WITH DIFFERENT τ VALUES
τ T2FNN versus T1FNN T2FNN versus IT2FNN
0.4 0.0045 0.0032
0.5 0.0019 0.0032
0.6 0.0001 0.0002
TABLE X
RESULTS FOR EXPERIMENT III WITH DIFFERENT σ0 VALUES
No. of T1FNN IT2FNN T2FNN
σ0 rules MSE Time MSE Time MSE Time
0.15 3.5 0.0109 4.620 0.0084 7.023 0.0070 7.478
0.20 2.7 0.0091 3.037 0.0088 4.071 0.0070 5.290
0.25 2.4 0.0090 2.699 0.0082 3.730 0.0076 5.091
difference between the means obtained from the involved twomethods. Since we run 10-fold cross validation, 10 pieces ofdata are collected for each variable in a paired sample t-test.The p-values of the tests are shown in Table VII. Note thatthe lower the p-value, the more significant the result in thesense of statistical significance. In this case, if the p-value isless than 0.05, then there is a significant difference between thetwo competitors. Apparently, the p-values show that T2FNN issignificantly better than T1FNN and IT2FNN in terms of MSE.
Table VIII shows the results with ρ = 0.17, σ0 = 0.2, andthree different τ values. Note that τ is a user-defined thresholdfor output similarity test in the self-constructing clusteringalgorithm. The setting of τ may affect the number of clustersobtained. As τ decreases, the outputs of the patterns in acluster are required to be closer to each other and thus thenumber of clusters obtained increases. Apparently, T2FNNachieves the best MSE for the testing data. For example,T2FNN gets 0.0079 in MSE, while T1FNN and IT2FNNget 0.0090 and 0.0097, respectively, with 3.0 rules. However,T2FNN runs slower than the other two methods. For example,T1FNN and IT2FNN require 3.792 and 4.707 s, respectively,in modeling, while T2FNN requires 6.852 s in this case.The p-values of paired samples t-tests for the two pairs,T2FNN versus T1FNN and T2FNN versus IT2FNN, are shownin Table IX. Obviously, the p-values show that T2FNN issignificantly better than T1FNN and IT2FNN in terms of MSE.
Table X shows the results with ρ = 0.17, τ = 0.5, andthree different σ0 values. Note that σ0 is the initial value forthe deviation in the self-constructing clustering algorithm.The setting of σ0 may affect the number of clusters. As σ0

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
12 IEEE TRANSACTIONS ON NEURAL NETWORKS
TABLE XI
p-VALUES FOR EXPERIMENT III WITH DIFFERENT σ0 VALUES
σ0 T2FNN versus T1FNN T2FNN versus IT2FNN
0.15 0.0001 0.0152
0.20 0.0019 0.0032
0.25 0.0001 0.0001
decreases, the patterns in a cluster are required to be moresimilar to each other and thus the number of clusters obtainedincreases. Again, T2FNN achieves the best MSE for thetesting data. For example, T2FNN gets 0.0076 in MSE, whileT1FNN and IT2FNN get 0.0090 and 0.0082, respectively,with 2.4 rules. However, T2FNN runs slower than the othertwo methods. For example, T1FNN and IT2FNN require2.699 and 3.730 s, respectively, in modeling, while T2FNNrequires 5.091 s in this case. The p-values of paired samplest-tests for the two pairs, T2FNN versus T1FNN and T2FNNversus IT2FNN, are shown in Table XI. Again, the p-valuesshow that T2FNN is significantly better than T1FNN andIT2FNN in terms of MSE.
VIII. CONCLUSION
We have presented a novel approach for developing type-2 fuzzy rules from a given set of input–output training data.A self-constructing fuzzy clustering method is used to partitionthe training dataset into clusters through input-similarity andoutput-similarity tests. The membership functions of the result-ing clusters are defined with statistical means and deviations.One type-2 fuzzy TSK-rule is derived from each cluster.A fuzzy neural network is constructed accordingly and theassociated parameters are refined by a hybrid learning algo-rithm which incorporates PSO and LSE. For a new input,a corresponding crisp output of the system is obtained bycombining the inferred results of all the rules into a type-2fuzzy set which is then defuzzified by applying a refinedtype reduction algorithm. The effectiveness of the proposedapproach was demonstrated through several experiments.
Fuzzy clustering and type reduction are two topics we havebeen working on in our machine learning research. In thispaper, we applied them to building a type-2 neural-fuzzysystem from a given set of input–output training data. We arealso applying them to other problems, such as image segmen-tation, data sampling, feature reduction, web mining, etc. Onerestriction of our type reduction algorithm is that the secondarymembership functions of a type-2 fuzzy set are required tobe convex. A type-1 fuzzy set is convex if its every α-cut,α > 0, is a continuous interval. We are working on efficienttype reduction algorithms for non-convex cases. Besides, weare seeking more applications of type-2 fuzzy systems.
ACKNOWLEDGMENT
The authors would like to thank the anonymous reviewersfor their comments, who were very helpful in improving thequality and presentation of this paper.
REFERENCES
[1] L. A. Zadeh, “Fuzzy sets,” Inf. Control, vol. 8, no. 3, pp. 338–353, Jun.1965.
[2] T. Poggio and F. Girosi, “Networks for approximation and learning,”Proc. IEEE, vol. 78, no. 9, pp. 1481–1497, Sep. 1990.
[3] J.-S. R. Jang, “ANFIS: Adaptive-network-based fuzzy inference system,”IEEE Trans. Syst., Man, Cybern., vol. 23, no. 3, pp. 665–685, Jun.1993.
[4] J.-S. R. Jang and C.-T. Sun, “Neuro-fuzzy modeling and control,” Proc.IEEE, vol. 83, no. 3, pp. 378–406, Mar. 1995.
[5] S.-J. Lee and C.-S. Ouyang, “A neuro-fuzzy system modeling withself-constructing rule generationand hybrid SVD-based learning,” IEEETrans. Fuzzy Syst., vol. 11, no. 3, pp. 341–353, Jun. 2003.
[6] C.-S. Ouyang, W.-J. Lee, and S.-J. Lee, “A TSK-type neurofuzzynetwork approach to system modeling problems,” IEEE Trans. Syst.,Man, Cybern., Part B: Cybern., vol. 35, no. 4, pp. 751–767, Aug. 2005.
[7] G. J. Klir and B. Yuan, Fuzzy Set and Fuzzy Logic. Englewood Cliffs,NJ: Prentice-Hall, May 1995.
[8] L. A. Zadeh, “The concept of a linguistic variable and its application toapproximate reasoning–I,” Inf. Sci., vol. 8, no. 3, pp. 199–249, Jan. 1975.
[9] N. N. Karnik, J. M. Mendel, and Q. Liang, “Type-2 fuzzy logic systems,”IEEE Trans. Fuzzy Syst., vol. 7, no. 6, pp. 643–658, Dec. 1999.
[10] Q. Liang and J. M. Mendel, “Interval type-2 fuzzy logic systems: Theoryand design,” IEEE Trans. Fuzzy Syst., vol. 8, no. 5, pp. 535–550, Oct.2000.
[11] J. M. Mendel, UNCERTAIN Rule-Based Fuzzy Logic Systems: Introduc-tion and New Directions. Englewood Cliffs, NJ: Prentice-Hall, Jan. 2001.
[12] N. N. Karnik and J. M. Mendel, “Operations on type-2 fuzzy sets,”Fuzzy Sets Syst., vol. 122, no. 2, pp. 327–348, Sep. 2001.
[13] J. M. Mendel and R. I. B. John, “Type-2 fuzzy sets made simple,”IEEE Trans. Fuzzy Syst., vol. 10, no. 2, pp. 117–127, Apr. 2002.
[14] J. M. Mendel, “Computing derivatives in interval type-2 fuzzy logicsystems,” IEEE Trans. Fuzzy Syst., vol. 12, no. 1, pp. 84–98, Feb. 2004.
[15] J. M. Mendel, “Type-2 fuzzy sets and systems: An overview [correctedreprint],” IEEE Comput. Intell. Mag., vol. 2, no. 1, pp. 20–29, Feb. 2007.
[16] J. M. Mendel, “Advances in type-2 fuzzy sets and systems,” Inf. Sci.,vol. 177, no. 1, pp. 84–110, Jan. 2007.
[17] J. M. Mendel, F. Liu, and D. Zhai, “α-plane representation for type-2fuzzy sets: Theory and applications,” IEEE Trans. Fuzzy Syst., vol. 17,no. 5, pp. 1189–1207, Oct. 2009.
[18] Q. Liang and J. M. Mendel, “Equalization of nonlinear time-varyingchannels using type-2 fuzzy adaptive filters,” IEEE Trans. Fuzzy Syst.,vol. 8, no. 5, pp. 551–563, Oct. 2000.
[19] R. Sepúlveda, O. Castillo, P. Melin, and O. Montiel, “An efficientcomputational method to implement type-2 fuzzy logic in controlapplications,” Anal. Design Intell. Syst. Soft Comput. Tech., vol. 41, pp.45–52, Jun. 2007.
[20] H. A. Hagras, “A hierarchical type-2 fuzzy logic control architecturefor autonomous mobile robots,” IEEE Trans. Fuzzy Syst., vol. 12, no. 4,pp. 524–539, Aug. 2004.
[21] R. Sepúlveda, O. Castillo, P. Melin, A. Rodríguez-Díaz, and O. Montiel,“Experimental study of intelligent controllers under uncertainty usingtype-1 and type-2 fuzzy logic,” Inf. Sci., vol. 177, no. 10, pp. 2023–2048,May 2007.
[22] F.-J. Lin and P.-H. Chou, “Adaptive control of two-axis motion controlsystem using interval type-2 fuzzy neural network,” IEEE Trans. Ind.Electron., vol. 56, no. 1, pp. 178–193, Jan. 2009.
[23] R. Martínez, O. Castillo, and L. T. Aguilar, “Optimization of intervaltype-2 fuzzy logic controllers for a perturbed autonomous wheeledmobile robot using genetic algorithms,” Inf. Sci., vol. 179, no. 13, pp.2158–2174, Jun. 2009.
[24] N. R. Cázarez-Castro, L. T. Aguilar, and O. Castillo, “Fuzzy logiccontrol with genetic membership function parameters optimization forthe output regulation of a servomechanism with nonlinear backlash,”Expert Syst. Appl., vol. 37, no. 6, pp. 4368–4378, Jun. 2010.
[25] N. R. Cázarez-Castro, L. T. Aguilar, and O. Castillo, “Hybrid genetic-fuzzy optimization of a type-2 fuzzy logic controller,” in Proc. 8th Int.Conf. Hyb. Intell. Syst., Barcelona, Spain, Sep. 2008, pp. 216–221.
[26] R. Martínez-Soto, A. R. Díaz, O. Castillo, and L. T. Aguilar, “Type-2fuzzy logic controllers optimization using genetic algoritms and particleswarm optimization,” in Proc. IEEE Int. Conf. Granular Comput., SanJose, CA, Aug. 2010, pp. 724–727.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
YEH et al.: DATA-BASED SYSTEM MODELING USING A TYPE-2 FUZZY NEURAL NETWORK 13
[27] Q. Liang and J. M. Mendel, “Designing interval type-2 fuzzy logicsystems using an SVD-QR method: Rule reduction,” Int. J. Intell. Syst.,vol. 15, no. 10, pp. 939–957, Oct. 2000.
[28] O. Castillo and P. Melin, “Comparison of hybrid intelligent systems,neural networks and interval type-2 fuzzy logic for time seriesprediction,” in Proc. Int. Joint Conf. Neural Netw., Orlando, FL, Aug.2007, pp. 3086–3091.
[29] M. H. F. Zarandi, B. Rezaee, I. B. Turksen, and E. Neshat, “A type-2fuzzy rule-based expert system model for stock price analysis,” ExpertSyst. Appl., vol. 36, no. 1, pp. 139–154, Jan. 2009.
[30] C.-S. Ouyang and S.-L. Liu, “An approach for construction and learningof interval type-2 TSK neuro-fuzzy systems,” in Proc. IEEE Int. Conf.Fuzzy Syst., Aug. 2009, pp. 1517–1522.
[31] Q. Liang and J. M. Mendel, “MPEG VBR video traffic modeling andclassification using fuzzy technique,” IEEE Trans. Fuzzy Syst., vol. 9,no. 1, pp. 183–193, Feb. 2001.
[32] H. B. Mitchell, “Pattern recognition using type-II fuzzy sets,” Inf. Sci.,vol. 170, nos. 2–4, pp. 409–418, Feb. 2005.
[33] J. Zeng and Z.-Q. Liu, “Type-2 fuzzy Markov random fields and theirapplication to handwritten chinese character recognition,” IEEE Trans.Fuzzy Syst., vol. 16, no. 3, pp. 747–760, Jun. 2008.
[34] L. A. Lucas, T. M. Centeno, and M. R. Delgado, “General type-2 fuzzyclassifiers to land cover classification,” Int. J. Fuzzy Syst., vol. 10, no. 3,pp. 207–216, Sep. 2008.
[35] D. Hidalgo, O. Castillo, and P. Melin, “Type-1 and type-2 fuzzyinference systems as integration methods in modular neural networksfor multimodal biometry and its optimization with genetic algorithms,”Inf. Sci., vol. 179, no. 13, pp. 2123–2145, Jun. 2009.
[36] O. Mendoza, P. Melin, and O. Castillo, “Interval type-2 fuzzy logicand modular neural networks for face recognition applications,” Appl.Soft Comput., vol. 9, no. 4, pp. 1377–1387, Sep. 2009.
[37] P. Melin, O. Mendoza, and O. Castillo, “An improved method for edgedetection based on interval type-2 fuzzy logic,” Expert Syst. Appl.,vol. 37, no. 12, pp. 8527–8535, Dec. 2010.
[38] R. I. John, P. R. Innocent, and M. R. Barnes, “Neuro-fuzzy clusteringof radiographic tibia image data using type 2 fuzzy sets,” Inf. Sci.,vol. 125, nos. 1–4, pp. 65–82, Jun. 2000.
[39] L. D. Lascio, A. Gisolfi, and A. Nappi, “Medical differential diagnosisthrough type-2 fuzzy sets,” in Proc. IEEE Int. Conf. Fuzzy Syst., Reno,NV, May 2005, pp. 371–376.
[40] F. Liu, “An efficient centroid type-reduction strategy for generaltype-2 fuzzy logic system,” Inf. Sci., vol. 179, no. 9, pp. 2224–2236,Apr. 2008.
[41] N. N. Karnik and J. M. Mendel, “Centroid of a type-2 fuzzy set,” Inf.Sci., vol. 132, nos. 1–4, pp. 195–220, Feb. 2001.
[42] D. Wu and J. M. Mendel, “Enhanced Karnik–Mendel algorithms,”IEEE Trans. Fuzzy Syst., vol. 17, no. 4, pp. 923–934, Aug. 2009.
[43] C.-Y. Yeh, W.-H. R. Jeng, and S.-J. Lee, “An enhanced type-reductionalgorithm for type-2 fuzzy sets,” IEEE Trans. Fuzzy Syst., vol. 19,no. 2, pp. 227–240, Apr. 2011.
[44] S. Coupland and R. John, “A fast geometric method for defuzzificationof type-2 fuzzy sets,” IEEE Trans. Fuzzy Syst., vol. 16, no. 4, pp.929–941, Aug. 2008.
[45] W.-W. Tan and D. Wu, “Design of type-reduction strategies for type-2fuzzy logic systems using genetic algorithms,” Adv. Evolut. Comput.Syst. Design. Studies Comput. Intell., vol. 66, pp. 169–187, 2007.
[46] Y. Lin, G. A. Cunningham, III, and S. V. Coggeshall, “Using fuzzypartitions to create fuzzy systems from input-output data and set theinitial weights in a fuzzy neural network,” IEEE Trans. Fuzzy Syst.,vol. 5, no. 4, pp. 614–621, Nov. 1997.
[47] C.-C. Wong and C.-C. Chen, “A hybrid clustering and gradient descentapproach for fuzzy modeling,” IEEE Trans. Syst., Man, Cybern., PartB: Cybern., vol. 29, no. 6, pp. 686–693, Dec. 1999.
[48] R. Thawonmas and S. Abe, “Function approximation based on fuzzyrules extracted from partitioned numerical data,” IEEE Trans. Syst.,Man, Cybern., Part B: Cybern., vol. 29, no. 4, pp. 525–534, Aug. 1999.
[49] C.-H. Wang, C.-S. Cheng, and T.-T. Lee, “Dynamical optimal trainingfor interval type-2 fuzzy neural network (T2FNN),” IEEE Trans.Syst., Man, Cybern., Part B: Cybern., vol. 34, no. 3, pp. 1462–1477,Jun. 2004.
[50] H. Hagras, “Comments on dynamical optimal training for interval type-2 fuzzy neural network (T2FNN),” IEEE Trans. Syst., Man, Cybern.,Part B: Cybern., vol. 36, no. 5, pp. 1206–1209, Oct. 2006.
[51] C.-H. Lee, T.-W. Hu, C.-T. Lee, and Y.-C. Lee, “A recurrent intervaltype-2 fuzzy neural network with asymmetric membership functions fornonlinear system identification,” in Proc. IEEE Int. Conf. Fuzzy Syst.,Hong Kong, Jun. 2008, pp. 1496–1502.
[52] C.-F. Juang and Y.-W. Tsao, “A self-evolving interval type-2 fuzzyneural network with online structure and parameter learning,” IEEETrans. Fuzzy Syst., vol. 16, no. 6, pp. 1411–1424, Dec. 2008.
[53] J. R. Castro, O. Castillo, P. Melin, and A. Rodríguez-Díaz, “A hybridlearning algorithm for a class of interval type-2 fuzzy neural networks,”Inf. Sci., vol. 179, no. 13, pp. 2175–2193, Jun. 2009.
[54] J. Kennedy and R. C. Eberhart, “Particle swarm optimization,” in Proc.IEEE Int. Conf. Neural Netw., Perth, Australia, Nov.–Dec. 1995, pp.1942–1948.
[55] Y.-T. Peng, C.-Y. Yeh, and S.-J. Lee, “A hierarchical SVD-based leastsquares method for parameter estimation,” in Proc. Int. Conf. DataEng. Internet Technol., Mar. 2011, pp. 219–222.
[56] S. Greenfield, F. Chiclana, S. Coupland, and R. I. John, “The collapsingmethod of defuzzification for discretised interval type-2 fuzzy sets,”Inf. Sci., vol. 179, no. 13, pp. 2055–2069, Jun. 2009.
[57] S. Greenfield, F. Chiclana, and R. I. John, “Type-reduction of thediscretised interval type-2 fuzzy set,” in Proc. IEEE Int. Conf. FuzzySyst., Aug. 2009, pp. 738–743.
[58] C. Wagner and H. Hagras, “zSlices based general type-2 FLC for thecontrol of autonomous mobile robots in real world environments,” inProc. IEEE Int. Conf. Fuzzy Syst., Aug. 2009, pp. 718–725.
[59] J. Yen and R. Langari, Fuzzy Logic: Intelligence, Control, andInformation. Upper Saddle River, NJ: Prentice-Hall, Dec. 1999.
[60] J.-S. Wang and C. S. G. Lee, “Self-adaptive neuro-fuzzy inferencesystems for classification applications,” IEEE Trans. Fuzzy Syst.,vol. 10, no. 6, pp. 790–802, Dec. 2002.
[61] Neural Network Toolbox User’s Guide, The MathWorks Inc., Natick,MA, 2008.
[62] A. Asuncion and D. Newman. (2007). UCI Machine LearningRepository [Online]. Available: http://www.ics.uci.edu/∼mlearn/MLRepository.html
[63] H. Motulsky, Intuitive Biostatistics. New York: Oxford Univ. Press,Oct. 1995.
Chi-Yuan Yeh was born in Tainan, Taiwan, in 1971.He received the B.S. and M.S. degrees in busi-ness administration from Shu-Te University, Kaoh-siung, Taiwan, in 2002 and 2004, respectively, andthe Ph.D. degree in electrical engineering fromNational Sun Yat-Sen University, Kaohsiung, in2011.
His current research interests include machinelearning, data mining, and soft computing.
Dr. Yeh received the Best Paper Award at theInternational Conference on Machine Learning and
Cybernetics in 2008.
Wen-Hau Roger Jeng was born in Taipei, Taiwan,in 1978. He received the B.S. degree from NationalChengchi University, Taipei, and the M.S.E.E.degree from National Sun Yat-Sen University,Kaohsiung, Taiwan, in 2001 and 2009, respectively.
His current research interests include machinelearning and data mining.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
14 IEEE TRANSACTIONS ON NEURAL NETWORKS
Shie-Jue Lee (M’88) was born in Kin-Men onAugust 15, 1955. He received the B.S. and M.S.degrees in electrical engineering from NationalTaiwan University, Taipei, Taiwan, in 1977 and1979, respectively, and the Ph.D. degree in computerscience from the University of North Carolina,Chapel Hill, in 1990.
He joined the faculty of the Department ofElectrical Engineering, National Sun Yat-SenUniversity, Kaohsiung, Taiwan, in 1983, and hasbeen a Professor in the department since 1994. His
current research interests include artificial intelligence, machine learning,data mining, information retrieval, and soft computing.
Prof. Lee is a member of the IEEE Society of Systems, Man, and Cyber-netics, the Association for Automated Reasoning, the Institute of Informationand Computing Machinery, the Taiwan Fuzzy Systems Association, and theTaiwanese Association of Artificial Intelligence. He was the recipient ofthe Outstanding M.S. Thesis Supervision Award by the Chinese Institute ofElectrical Engineering for 1997, and also the Best Paper Award in several
international conferences. Among the other awards won by him are theDistinguished Teachers Award of the Ministry of Education, Taiwan, in 1993,the Distinguished Research Award of National Sun Yat-Sen University in1998, the Distinguished Teaching Award of National Sun Yat-Sen Univer-sity in 1993 and 2008, and the Distinguished Mentor Award of NationalSun Yat-Sen University in 2008. He served as the Program Chair for theInternational Conference on Artificial Intelligence, Kaohsiung, Taiwan, inDecember 1996, the International Computer Symposium and Workshop onArtificial Intelligence, Tainan, Taiwan, in December 1998, and the 6th Con-ference on Artificial Intelligence and Applications, Kaohsiung, in November2001. He served as the Director of the Center for TelecommunicationsResearch and Development from 1997 to 2000, the Director of the SouthernTelecommunications Research Center, National Science Council, from 1998to 1999, the Chair of the Department of Electrical Engineering from 2000to 2003, and the Deputy Dean of the Academic Affairs from 2008 to2011. He is now the Director of the Library and Information Servicesand the Director of the NSYSU-III Research Center, National Sun Yat-SenUniversity.





























