Embed Size (px)
Citation preview

CUHKCUHK
Learning-Based Power Management for Multi-Core Processors
YE Rong
Nov 15, 2011
CUHKCUHK
Background
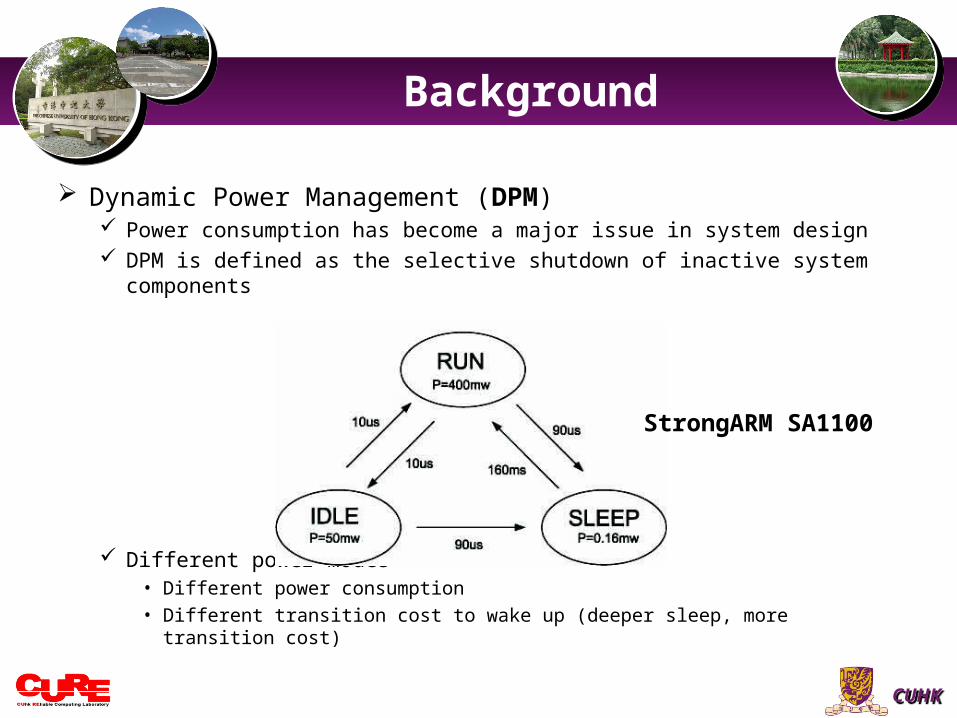
Dynamic Power Management (DPM) Power consumption has become a major issue in system design DPM is defined as the selective shutdown of inactive system components
Different power modes• Different power consumption• Different transition cost to wake up (deeper sleep, more transition cost)
StrongARM SA1100

CUHKCUHK
Background
Dynamic Power Management (DPM) The key point in DPM is how to utilize the idle periods of system
components• Difficult to choose the opportune moment to turn off inactive components• Difficult to select proper sleep mode
Sleep mode
Running mode
idle mode
running mode
The idle period is unknown in general-purpose processors.

CUHKCUHK
Related Work
Existing DPM policies Heuristic policies
• Timeout Policy
Predict the length of idle period (e.g., regression)• Input: past idle periods• Output: current idle period
Stochastic policies• Markov decision process• Semi-Markov decision process
CUHKCUHK
Motivation
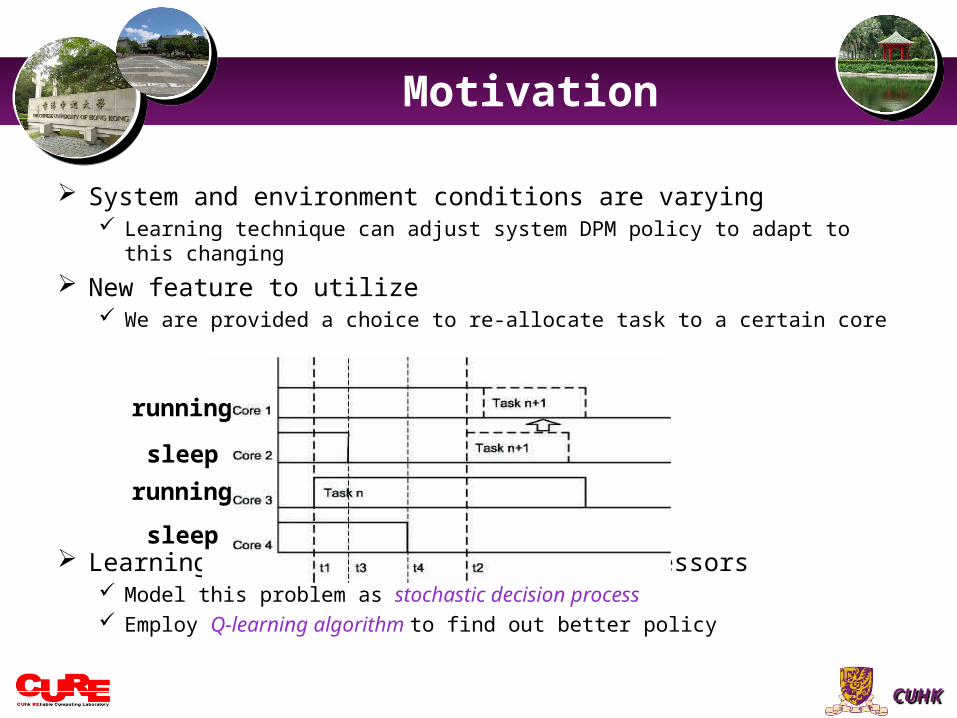
System and environment conditions are varying Learning technique can adjust system DPM policy to adapt to this changing
New feature to utilize We are provided a choice to re-allocate task to a certain core
Learning-based DPM for Multi-Core Processors Model this problem as stochastic decision process Employ Q-learning algorithm to find out better policy
sleep
running
sleep
running
CUHKCUHK
Q-learning
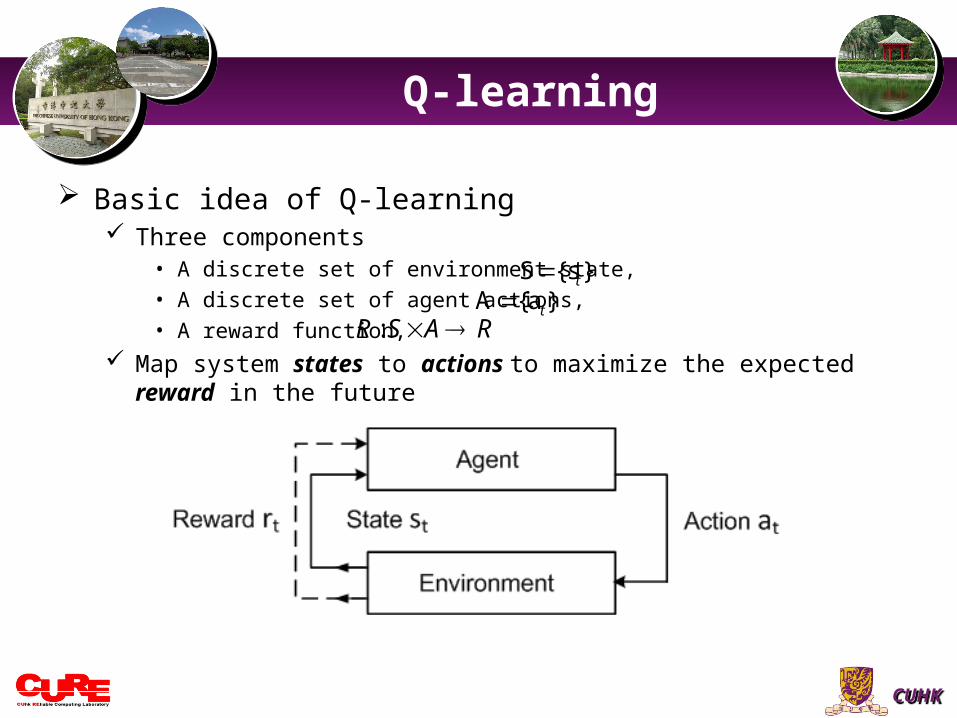
Basic idea of Q-learning Three components
• A discrete set of environment state, • A discrete set of agent actions, • A reward function,
Map system states to actions to maximize the expected reward in the future
:R S A R A {a }t
S {s }t

CUHKCUHK
Reward Function
Proposed reward function Weighted sum of power consumption and response time
R: reward; P: average power dissipation; RT: average response time
β: coefficient for the tradeoff between power and performance
( , , ) ( , ) ( , )t t t t t tR s a P s a RT s a

CUHKCUHK
Neural Network
Neural network to tackle new problem in multi-core case System state and action numbers are increased exponentially
• System state number• Action number• Solution space: the composition of system state space and action space
For example,• Core with 3 power modes: running, idle, and sleep mode• Queue with 2 queue states: 0 for no task, otherwise 1• A multi-core processor with 8 cores• Then, the space size is
Use neural network to approximate Q-value, instead of Q table in standard Q-learning
( ) ( )n ncn qn m n
( )nm n( )ncn qn
8 8(3 2) (3 8) 88,159,684,608
CUHKCUHK
Neural Network
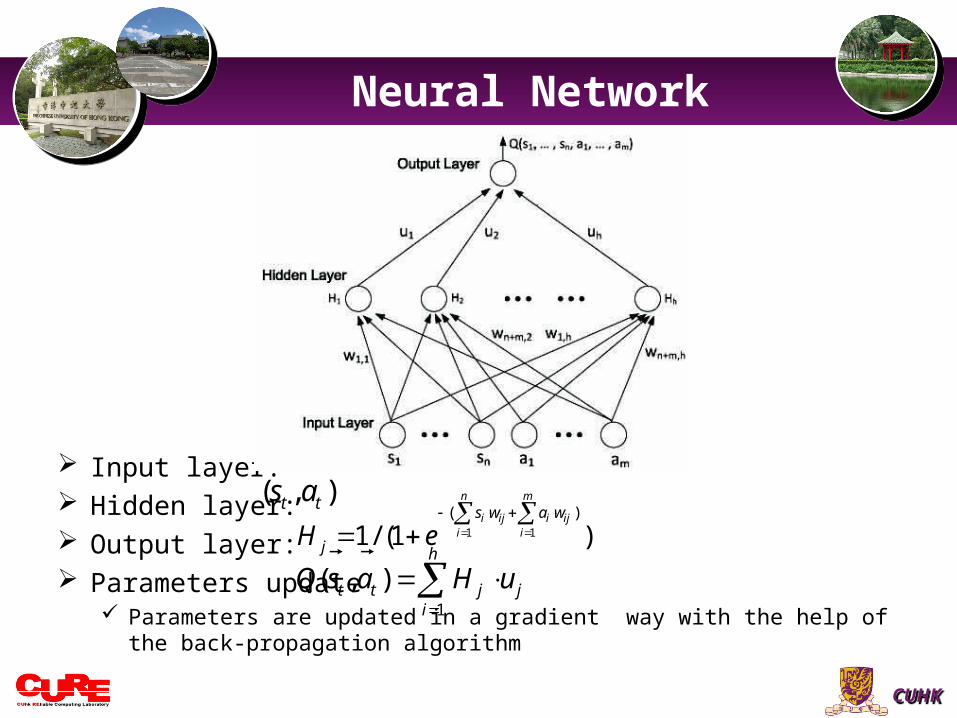
Input layer: Hidden layer: Output layer: Parameters update
Parameters are updated in a gradient way with the help of the back-propagation algorithm
1
( , )h
t t j ji
Q s a H u
( , )t ts a
1 1
( )
1/ (1 )
n m
i ij i iji i
s w a w
jH e

CUHKCUHK
Experimental Setup
Our experiments are based on synthetic workloads Homogeneous multi-core processors with 4 cores or 8 cores Processor parameters
• Exactly the same with StrongARM SA1100
A set of tasks• Task number: 10,000• Task service time: hyper exponential distribution• Task arrival time: exponential distribution
DPM techniques for comparison Timeout policy with T = (TVLSI, 1996) Reinforcement learning-based policy
(ICCAD, 2009)
beT
CUHKCUHK
Results
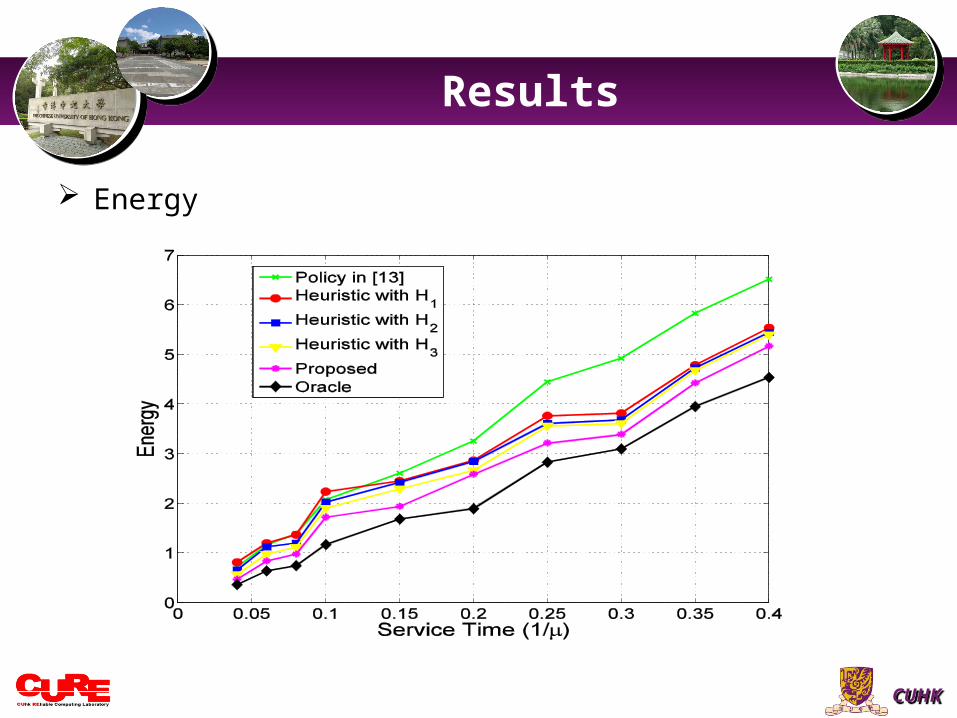
Energy
CUHKCUHK
Results
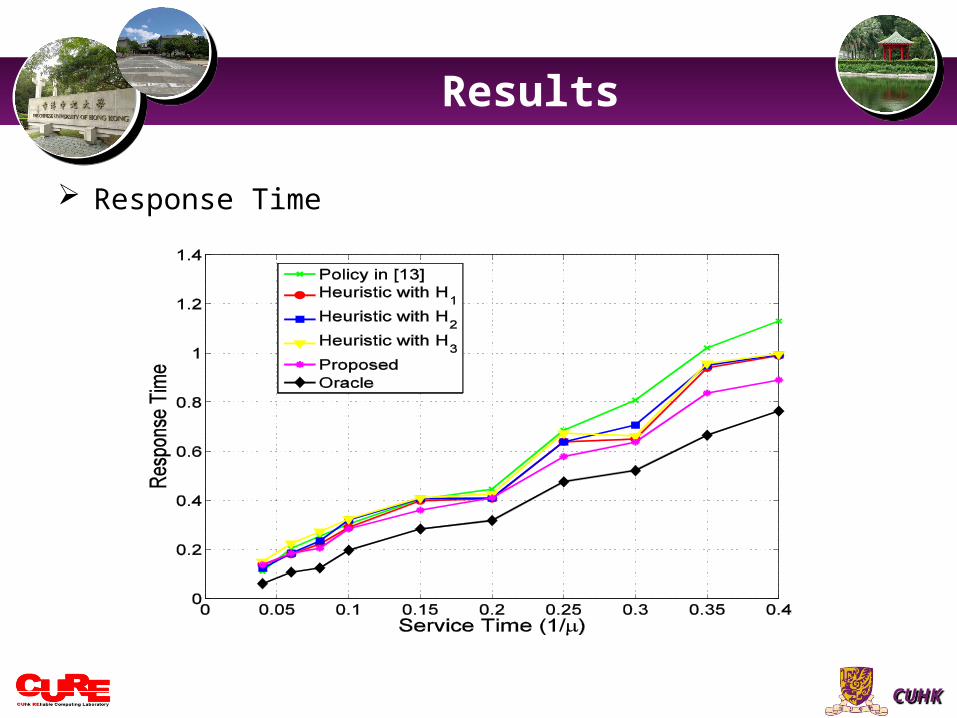
Response Time

CUHKCUHK
Conclusion
In this work, We extend DPM problem to multi-core case
• Present a novel DPM model to utilize the distinctive features of multi-core processors, to obtain global power benefits;
We develop a learning-based algorithm• Use neural network to solve the huge solution space problem that is different
from single-core case• Employ ε-greedy to avoid local maximum of power optimization
The experimental results show that • Our proposed methodology can greatly reduce power dissipation with
reasonable performance penalty or even obtain benefits in both power and performance
Power is a critical issue Related to temperature, lifetime reliability, etc.
This framework can be utilized to optimize reliability issues

CUHKCUHK
Thanks for Your Attention!
YE Rong
Nov 15, 2011





























