Embed Size (px)
Citation preview

CSE494 - Information Retrieval, Mining and Integration on the Internet
Database Concepts - A Refresher
30th March 2004

Slides adapted from Rao (ASU) & Franklin (Berkeley)
This Day in History• 1867 – US purchases Alaska from Russia for
$7.2 million (2 cents/acre)• 1953 – Einstein announces revised unified
field theory• 1954 – Test Cricket debut of Sir Garry Sobers
vs. England • 1981 – President Reagan shot & wounded by
John W Hinckley Jr• 2004 – The “first ever” regular class of Rao
taught by someone other than Rao

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Concepts covered so far …
• Information Retrieval– Text retrieval– Hyper-linked text retrieval– Improvements…
• Information Mining– Clustering techniques to improve result presentation– Classification and filtering techniques

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Structured data..
• Focus on “text” data till date.
• However, a lot of the data available on the web is actually from (semi-)structured databases !!!!– They do their best to look like they are text sources
• What are the issues and opportunities brought up by the presence of such sources on the web?

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Databases !!!??? you may have used

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Is the a DBMS?
• Fairly sophisticated search available– crawler indexes pages on the web– Keyword-based search for pages
• But, currently– data is mostly unstructured and untyped– search only:
• can’t modify the data• can’t get summaries, complex combinations of data
– Web sites typically have a DBMS in the background to provide these functions.• They dynamically convert (wrap) the structured data into readable English
– <India, New Delhi> => The capital of India is New Delhi.– So, if we can “unwrap” the text, we have structured data!– Note also that such dynamic pages cannot be crawled...
• The (coming) Semi-structured web• Most pages are at least “semi”-structured• XML standard is expected to ease the presentation/on-the-wire transfer of such pages. (BUT…..)
• The Services• Travel services, mapping services
• The SensorsStock quotes, current temperatures, ticket prices…

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Structure
• How will search and querying on these three types of data differ?
A genericweb page
containing text
A movie review
[English]
[SQL]
[XML]
Semi-Structured
An employee record
Slides adapted from Rao (ASU) & Franklin (Berkeley)
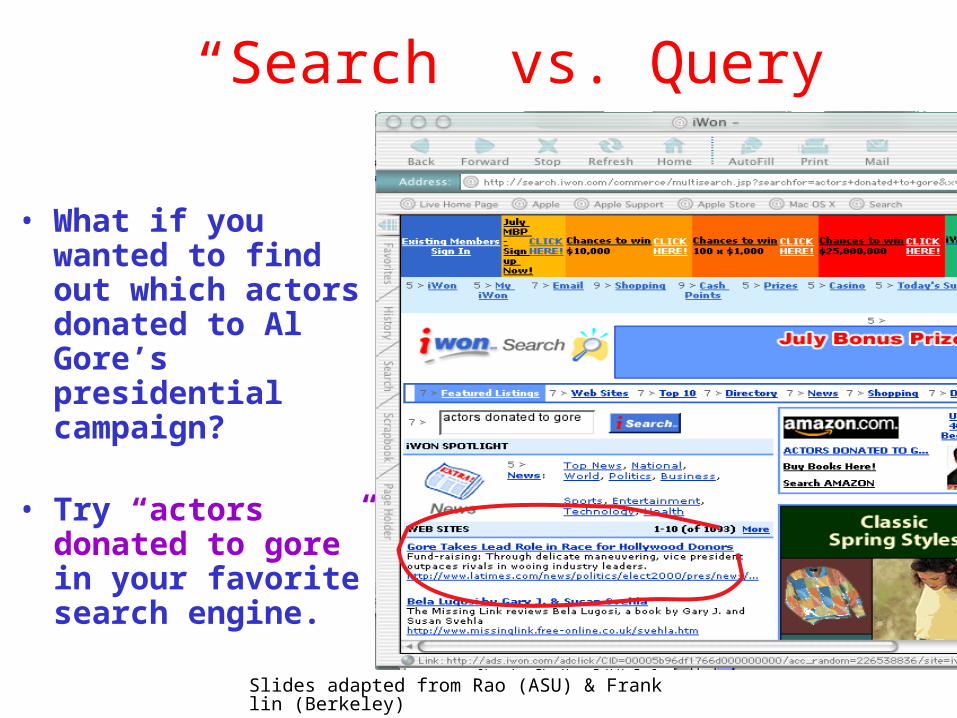
“Search” vs. Query
• What if you wanted to find out which actors donated to Al Gore’s presidential campaign?
• Try “actors donated to gore” in your favorite search engine.

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Structure helps querying
• Expressive queries– Give me all pages that have key words “Get Rich Quick”– Give me the social security numbers of all the employees who have
stayed with the company for more than 5 years, and whose yearly salaries are three standard deviations away from the average salary
– Give me all mails from people from ASU written this year, which are
relevant to “get rich quick”
• Efficient searching – equality vs. “similarity”– range-limited search

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Why use a DBMS in your website?
Suppose we are building web-based music distribution site.
Several questions arise:– How do we store the data? (file organization, etc.)– How do we query the data? (write programs…)– Make sure that updates don’t mess things up?– Provide different views on the data? (registrar versus students)– How do we deal with crashes?
Way too complicated! Buy a database system!

Slides adapted from Rao (ASU) & Franklin (Berkeley)
What Is a Database System?• Database:
a very large, integrated collection of data.• Models a real-world enterprise
– Entities (e.g., teams, games)– Relationships
(e.g., The Patriots are playing in The Superbowl)
– More recently, also includes active components , often called “business logic”. (e.g., the BCS ranking system)
• A Database Management System (DBMS) is a software system designed to store, manage, and facilitate access to databases.

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Functionality of a DBMS• Data Dictionary Management• Storage management
– Data storage Definition Language (DDL)• High level query and data manipulation language
– SQL/XQuery etc.– May tell us what we are missing in text-based search
• Efficient query processing– May change in the internet scenario
• Transaction processing• Resiliency: recovery from crashes,• Different views of the data, security
– May be useful to model a collection of databases together• Interface with programming languages
Slides adapted from Rao (ASU) & Franklin (Berkeley)
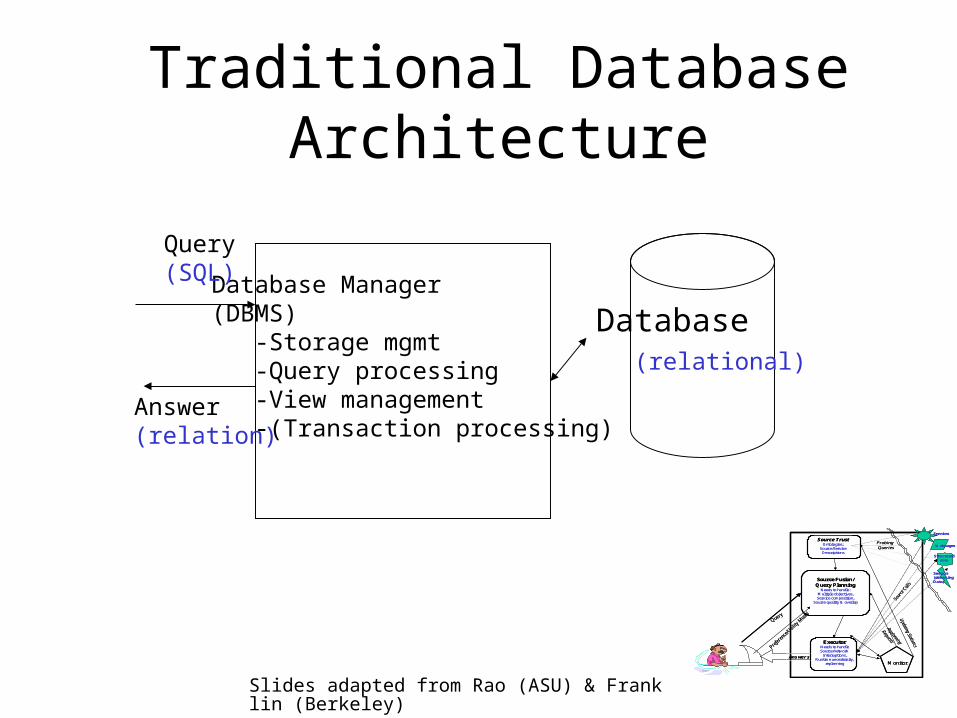
Database (relational)
Database Manager(DBMS) -Storage mgmt -Query processing -View management -(Transaction processing)
Query(SQL)
Answer(relation)
Traditional Database Architecture
Services
Webpages
Structureddata
Sensors(streamingData)
Services
Webpages
Structureddata
Sensors(streamingData)
ExecutorNeeds to handleSource/network
Interruptions,Runtime uncertainity,
replanning
Source Fusion/Query Planning
Needs to handle:Multiple objectives,Service composition,
Source quality & overlap
Source TrustOntologies;
Source/ServiceDescriptions
Answers
ProbingQueries
Monitor
ExecutorNeeds to handleSource/network
Interruptions,Runtime uncertainity,
replanning
Source Fusion/Query Planning
Needs to handle:Multiple objectives,Service composition,
Source quality & overlap
Source TrustOntologies;
Source/ServiceDescriptions
Answers
ProbingQueries
Monitor

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Building an Application with a Database System
• Requirements modeling (conceptual, pictures)– Decide what entities should be part of the application and
how they should be linked.• Schema design and implementation
– Decide on a set of tables, attributes.– Define the tables in the database system.– Populate database (insert tuples).
• Write application programs using the DBMS– Now much easier, with data management API
Slides adapted from Rao (ASU) & Franklin (Berkeley)
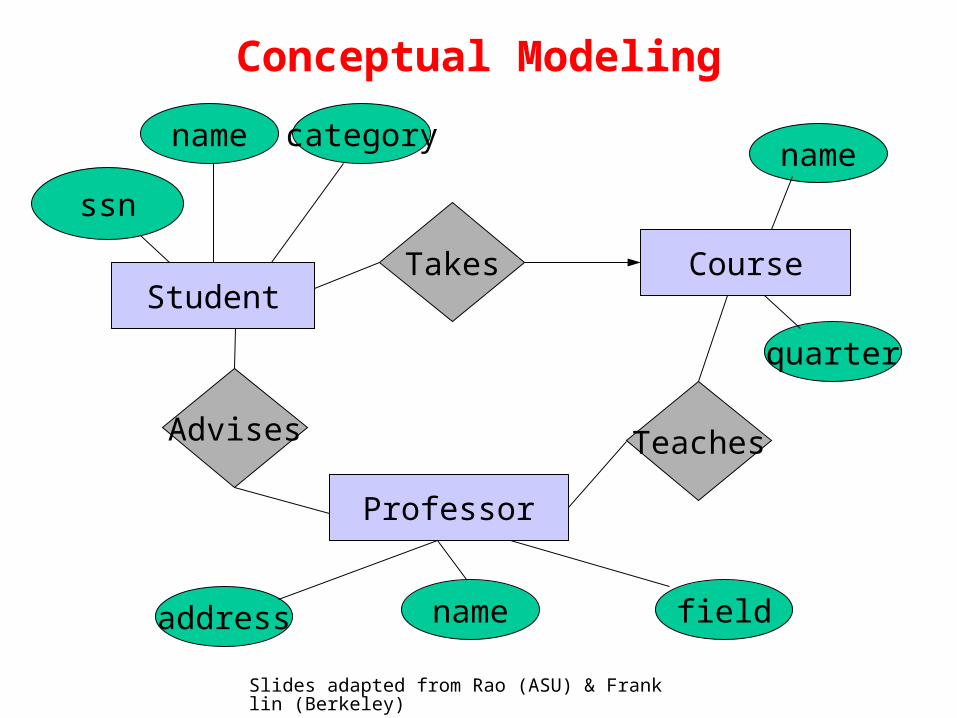
ssn
address name field
Professor
Advises
Takes
Teaches
CourseStudent
name category
quarter
name
Conceptual Modeling

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Data Models• A data model is a collection of concepts for
describing data.
• A schema is a description of a particular collection of data, using a given data model.
• The relational model of data is the most widely used model today.– Main concept: relation, basically a table with rows and
columns.– Every relation has a schema, which describes the columns, or
fields.

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Levels of Abstraction
• Views describe how users see the data.
• Conceptual schema
defines logical structure
• Physical schema describes the files and indexes used.
Physical Schema
Conceptual Schema
View 1 View 2 View 3
DB

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Example: University Database
• Conceptual schema: – Students(sid: string, name: string,
login: string, age: integer, gpa:real)
– Courses(cid: string, cname:string, credits:integer)
• External Schema (View): – Course_info(cid:string,enrollment:int
eger)
• Physical schema:– Relations stored as unordered files. – Index on first column of Students.
Physical Schema
Conceptual Schema
View 1 View 2 View 3
DB
Slides adapted from Rao (ASU) & Franklin (Berkeley)
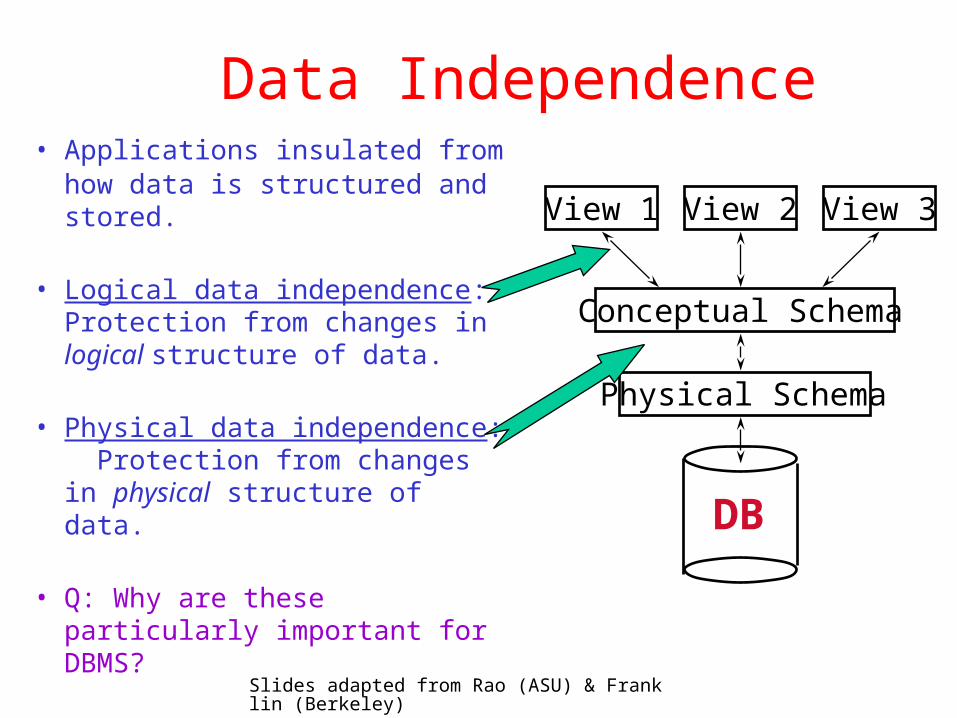
Data Independence• Applications insulated from
how data is structured and stored.
• Logical data independence: Protection from changes in logical structure of data.
• Physical data independence: Protection from changes in physical structure of data.
• Q: Why are these particularly important for DBMS?
Physical Schema
Conceptual Schema
View 1 View 2 View 3
DB

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Schema Design & Implementation
• Table Students
• Separates the logical view from the physical view of the data.
Student Course Quarter
Charles CS 444 Fall, 1997
Dan CS 142 Winter,1998
… … …
Slides adapted from Rao (ASU) & Franklin (Berkeley)
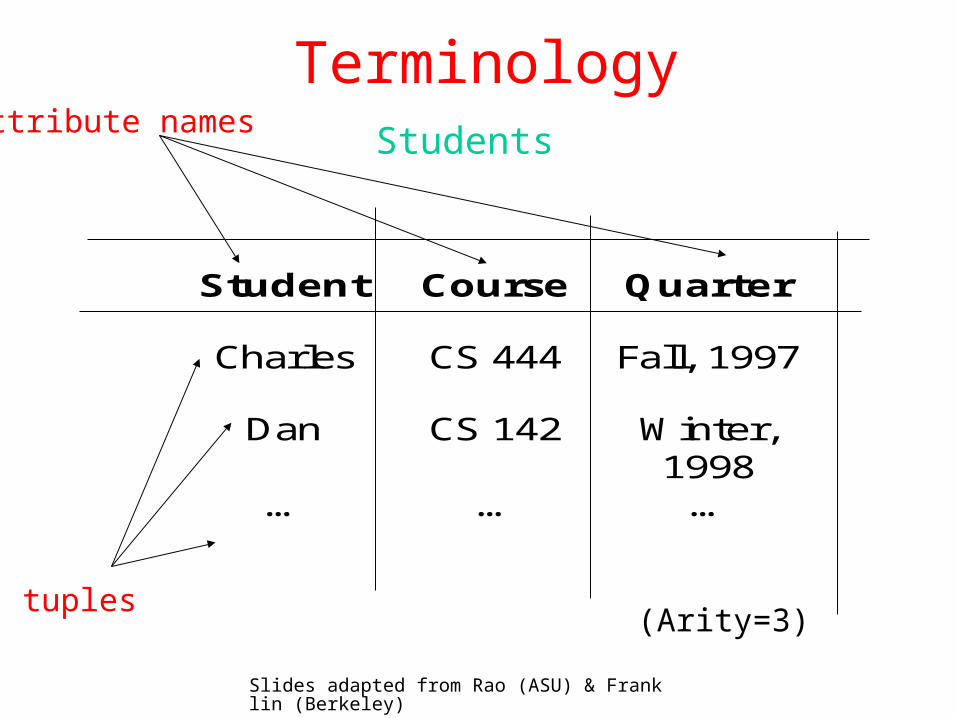
Terminology
tuples
Attribute namesStudents
(Arity=3)
Student Course Quarter
Charles CS 444 Fall, 1997
Dan CS 142 Winter,1998
… … …

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Querying a Database
• Find all the students taking CSE594 in Q1, 2004
• S(tructured) Q(uery) L(anguage)select E.namefrom Enroll Ewhere E.course=CS490i and E.quarter=“Winter, 2000”
• Query processor figures out how to answer the query efficiently.

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Relational Algebra• Operators
– tuple sets as input, new set as output
• Basic Binary Set Operators– Result is table (set) with same attributes
• Sets must be compatible!– R1(A1,A2,A3) R2(B1,B2,B3) Domain(Ai) = Domain(Bi)
– Union• All tuples in either R1 or in R2
– Intersection• All tuples in both R1 and R2
– Difference• All tuples in R1 but not in R2
– Complement• All tuples not in R1
• Selection, Projection, Cartesian Product, Join

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Selection
• Grab a subset of the tuples in a relation that satisfy a given condition– Use and, or, not, >,
<… to build condition
• Unary operation… returns set with same attributes, but ‘selects’ rows
3/19/2001 12:14 PM 10Copyright © 2000 D.S.Weld (modified by Rao)
EmployeeSSN Name DepartmentID Salary999999999 John 1 30,000777777777 Tony 1 32,000888888888 Alice 2 45,000
Selection Example
SSN Name DepartmentID Salary888888888 Alice 2 45,000
Select (Salary > 40000)

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Projection • Unary operation, selects
columns• Returned schema is
different, – So returned tuples are not
subset of original set– Contrast with selection
• Eliminates duplicate tuples
3/19/2001 12:12 PM 12Copyright © 2000 D.S.Weld (modified by Rao)
Example: Projection Onto SSN, Name
EmployeeSSN Name DepartmentID Salary999999999 John 1 30,000777777777 Tony 1 32,000888888888 Alice 2 45,000
SSN Name999999999 John777777777 Tony888888888 Alice

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Cartesian Product X
• Binary Operation• Result is set of tuples
combining all elements of R1 with all elements of R2, for R1 R2
• Schema is union of Schema(R1) & Schema(R2)
• Notice we could do selection on result to get meaningful info!
3/19/2001 12:13 PM 14Copyright © 2000 D.S.Weld (modified by Rao)
EmployeeName SSNJohn 999999999Tony 777777777DependentsEmployeeSSN Dname999999999 Emily777777777 Joe
Employee_DependentsName SSN EmployeeSSN DnameJohn 999999999 999999999 EmilyJohn 999999999 777777777 JoeTony 777777777 999999999 EmilyTony 777777777 777777777 Joe
Cartesian Product Example

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Join
• Most common (and exciting!) operator…• Combines 2 relations
– Selecting only related tuples• Result has all attributes of the two relations• Equivalent to
– Cross product followed by selection followed by Projection• Equijoin
– Join condition is equality between two attributes• Natural join
– Equijoin on attributes of same name– result has only one copy of join condition attribute

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Example: Natural JoinEmployeeName SSNJohn 999999999Tony 777777777DependentsSSN Dname999999999 Emily777777777 Joe
Employee DependentsEmployee_DependentsName SSN DnameJohn 999999999 EmilyTony 777777777 Joe

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Exercises
Product ( pname, price, category, maker)Purchase (buyer, seller, store, prodname)Company (cname, stock price, country)Person( per-name, phone number, city)
Ex #1: Find people who bought telephony products.Ex #2: Find names of people who bought American productsEx #3: Find names of people who bought American products and did not buy French productsEx #4: Find names of people who bought American products and they live in Seattle.Ex #5: Find people who bought stuff from Joe or bought products from a company whose stock prices is more than $50.

Slides adapted from Rao (ASU) & Franklin (Berkeley)
SQL Introduction
Standard language for querying and manipulating data
Structured Query Language
Many standards out there: SQL92, SQL2, SQL3, SQL99Vendors support various subsets of these
(but we’ll only discuss a subset of what they support)Basic form = syntax on relational algebra (but many other features too)
Select attributes From relations (possibly multiple, joined) Where conditions (selections)

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Selections
SELECT * FROM Company WHERE country=“USA” AND stockPrice > 50
You can use: Attribute names of the relation(s) used in the FROM. Comparison operators: =, <>, <, >, <=, >= Apply arithmetic operations: stockprice*2 Operations on strings (e.g., “||” for concatenation). Lexicographic order on strings. Pattern matching: s LIKE p Special stuff for comparing dates and times.

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Projection
SELECT name AS company, stockprice AS price FROM Company WHERE country=“USA” AND stockPrice > 50
SELECT name, stock price FROM Company WHERE country=“USA” AND stockPrice > 50
Select only a subset of the attributes
Rename the attributes in the resulting table

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Ordering the Results
SELECT name, stock price FROM Company WHERE country=“USA” AND stockPrice > 50 ORDERBY country, name
Ordering is ascending, unless you specify the DESC keyword.
Ties are broken by the second attribute on the ORDERBY list, etc.

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Join
SELECT name, store FROM Person, Purchase WHERE per-name=buyer AND city=“Seattle” AND product=“gizmo”
Product ( pname, price, category, maker)Purchase (buyer, seller, store, product)Company (cname, stock price, country)Person( per-name, phone number, city)

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Disambiguating Attributes
SELECT Person.name FROM Person, Purchase, Product WHERE Person.name=buyer AND product=Product.name AND Product.category=“telephony”
Product ( name, price, category, maker)Purchase (buyer, seller, store, product)Person( name, phone number, city)
Find names of people buying telephony products:

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Tuple Variables
SELECT product1.maker, product2.maker FROM Product AS product1, Product AS product2 WHERE product1.category = product2.category AND product1.maker <> product2.maker
Product ( name, price, category, maker)
Find pairs of companies making products in the same category

Views

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Defining Views(Virtual) Views are relations, except that they are not physically stored.
They are used mostly in order to simplify complex queries andto define conceptually different views of the database to differentclasses of users.
View: purchases of telephony products:
CREATE VIEW telephony-purchases AS SELECT product, buyer, seller, store FROM Purchase, Product WHERE Purchase.product = Product.name AND Product.category = “telephony”

Slides adapted from Rao (ASU) & Franklin (Berkeley)
A Different ViewCREATE VIEW Seattle-view AS
SELECT buyer, seller, product, store FROM Person, Purchase WHERE Person.city = “Seattle” AND Person.name = Purchase.buyer
We can later use the views: SELECT name, store FROM Seattle-view, Product WHERE Seattle-view.product = Product.name AND Product.category = “shoes”
What’s really happening when we query a view??

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Updating Views
How can I insert a tuple into a table that doesn’t exist?
CREATE VIEW bon-purchase AS SELECT store, seller, product FROM Purchase WHERE store = “The Bon Marche”
If we make the following insertion:
INSERT INTO bon-purchase VALUES (“the Bon Marche”, Joe, “Denby Mug”)
We can simply add a tuple (“the Bon Marche”, Joe, NULL, “Denby Mug”)to relation Purchase.

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Materialized Views• Views whose corresponding queries have been executed
and the data is stored in a separate database– Uses: Caching
• Issues– Using views in answering queries
• Normally, the views are available in addition to database– (so, views are local caches)
• In information integration, views may be the only things we have access to. – An internet source that specializes in woody allen movies can be seen as a view
on a database of all movies. Except, there is no database out there which contains all movies..
– Maintaining consistency of materialized views

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Non-Updatable Views
CREATE VIEW Seattle-view AS SELECT seller, product, store FROM Person, Purchase WHERE Person.city = “Seattle” AND Person.name = Purchase.buyer
How can we add the following tuple to the view?
(Joe, “Shoe Model 12345”, “Nine West”)
Given Purchase (buyer, seller, store, product) Person( name, phone-num, city)

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Issues w.r.t. Databases on the Web
• Information Extraction (invert the tuple to text transformation)
• Support lay user queries– More flexible queries
• Exact (SQL) vs Approximate/Similar (Text search?)– On “semi-structured” databases
• Joins over text attributes?– Exact (SQL) vs Approximate/Similar !!!!!
• Support integration/aggregation of multiple databases – Take a query from the user and send it to all relevant databases…– TONS of challenges…

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Imprecise Queries
• Increasing number of Web accessible databases– E.g. bibliographies, reservation systems, department catalogs etc– Support for precise queries only – exactly matching tuples
• Difficulty in extracting desired information– Limited query capabilities provided by form based query interface– Lack of schema/domain information– Increasing complexity of types of data e.g. hyptertext, images etc
• Often times user wants ‘about the same’ instead of ‘exact’– Bibliography search — find similar publications
Solution: Provide answers closely matching query constraints

Query Optimization

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Query Optimization
Imperative query execution plan:Declarative SQL query
Ideally: Want to find best plan. Practically: Avoid worst plans!
Goal:
(Simple Nested Loops)
Purchase Person
Buyer=name
City=‘seattle’ phone>’5430000’
buyer
(Table scan) (Index scan)
SELECT S.buyerFROM Purchase P, Person QWHERE P.buyer=Q.name AND Q.city=‘seattle’ AND Q.phone > ‘5430000’
Inputs:• the query• statistics about the data (indexes, cardinalities, selectivity factors)• available memory

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Optimizing Joins• Q(u,x) :- R(u,v), S(v,w), T(w,x)
– R S T• Many ways of doing a single join R S
– Symmetric vs. asymmetric join operations• Nested join, hash join, double pipe-lined hash join etc.
– Processing costs alone vs. processing + transfer costs• Get R and S together vs, get R, get just the tuples of S that will join with R (“semi-
join”)
• Many orders in which to do the join– (R join S) join T– (S join R) join T– (T join S) join R etc.
• All with different costs
Slides adapted from Rao (ASU) & Franklin (Berkeley)
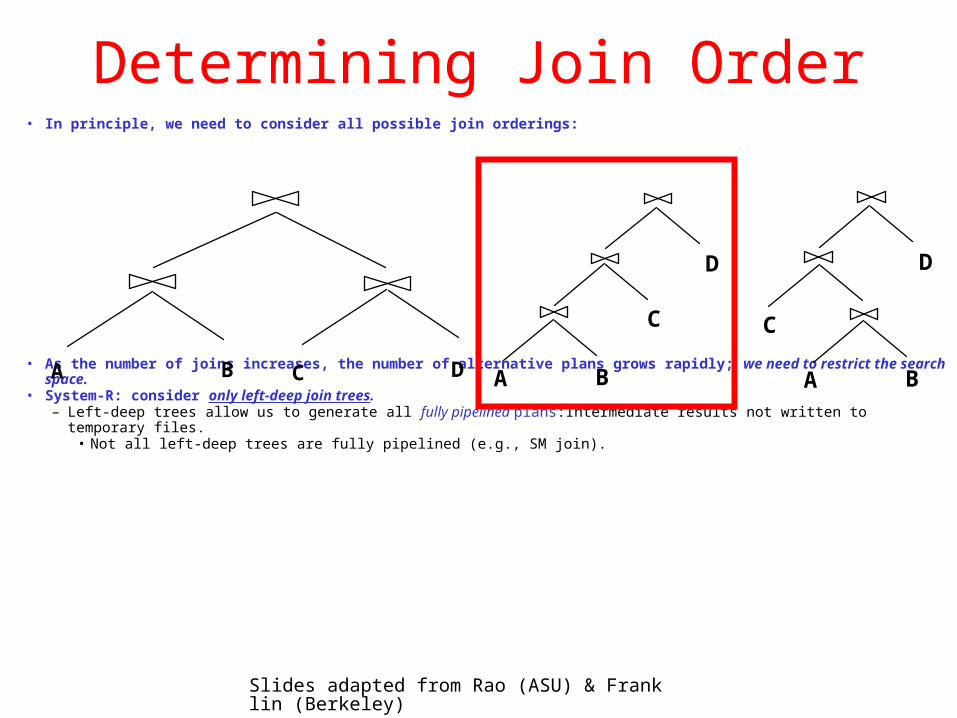
Determining Join Order• In principle, we need to consider all possible join orderings:
• As the number of joins increases, the number of alternative plans grows rapidly; we need to restrict the search space.
• System-R: consider only left-deep join trees.– Left-deep trees allow us to generate all fully pipelined plans:Intermediate results not written to temporary files.
• Not all left-deep trees are fully pipelined (e.g., SM join).
BA
C
D
BA
C
D
C DBA

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Query Optimization Process(simplified a bit)
• Parse the SQL query into a logical tree:– identify distinct blocks (corresponding to nested sub-
queries or views). • Query rewrite phase:
– apply algebraic transformations to yield a cheaper plan.– Merge blocks and move predicates between blocks.
• Optimize each block: join ordering.• Complete the optimization: select scheduling
(pipelining strategy).

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Cost Estimation
• For each plan considered, must estimate cost:– Must estimate cost of each operation in plan tree.
• Depends on input cardinalities.– Must estimate size of result for each operation in tree!
• Use information about the input relations.• For selections and joins, assume independence of predicates.
• System R cost estimation approach.– Very inexact, but works ok in practice.– More sophisticated techniques known now.

Slides adapted from Rao (ASU) & Franklin (Berkeley)
Key Lessons in Optimization
• There are many approaches and many details to consider in query optimization– Classic search/optimization problem!– Not completely solved yet!
• Main points to take away are:– Algebraic rules and their use in transformations of
queries.– Deciding on join ordering: System-R style (Selinger
style) optimization.– Estimating cost of plans and sizes of intermediate
results.





























