Embed Size (px)
Citation preview

19 September 2003 1
CSCI6405 Fall 2003Dta Mining and Data Warehousing
Instructor: Qigang Gao, Office: CS219, Tel:494-3356, Email: [email protected] Assistant: Christopher Jordan,Email: [email protected] Hours: TR, 1:30 - 3:00 PM

19 September 2003 2
Lectures OutlinePat I: Overview on DM and DW
1. Introduction (ch1) Ass1 Due: Sep 23 Tue2. Data preprocessing (ch3)
Part II: DW and OLAP 3. Data warehousing and OLAP (Ch2) Ass2: Sep 23 – Oct 7
Part III: Data Mining Methods/Algorithms4. Data mining primitives (ch4)5. Classification data mining (ch7) Ass3: Oct 7 – Oct 216. Association data mining (ch6) Ass4: Oct 21 – Nov 57. Characterization data mining (ch5)8. Clustering data mining (ch8)
Part IV: Mining Complex Types of Data 9. Mining the Web (Ch9)
10. Mining spatial data (Ch9)Project Presentations
Project Due: Dec 8

19 September 2003 3
Types of Knowledge (DM Functionality)
• Classification
• Association
• Clustering
• Characterization
• Evolution

19 September 2003 4
E.g. 3 Text classificationProblem:
E.g. given a training database: 1000 documents, 700 documents = dislike, 300 documents = like.
How can we classify a new document (with K words) into one of known classes?
Solution: Bayesian Classification (Naïve Bayes classifier)K
c_NB = argmax P(c_j) ∏ P(a_i|c_j)c_j in i=1
{like,dislike}
It maximizes the probability of observing the words that were actually found in the document, subject to the usual naive Bayes independence assumption:P(a1, a2, ...a_k| c_i) = ∏ P(a_j|c_i)

19 September 2003 5
Association Mining(Correlation, linkage Analysis)
The knowledge is for linking two or more data events (or data items) together. Most frequently used for "market basket" types of applications.

19 September 2003 6
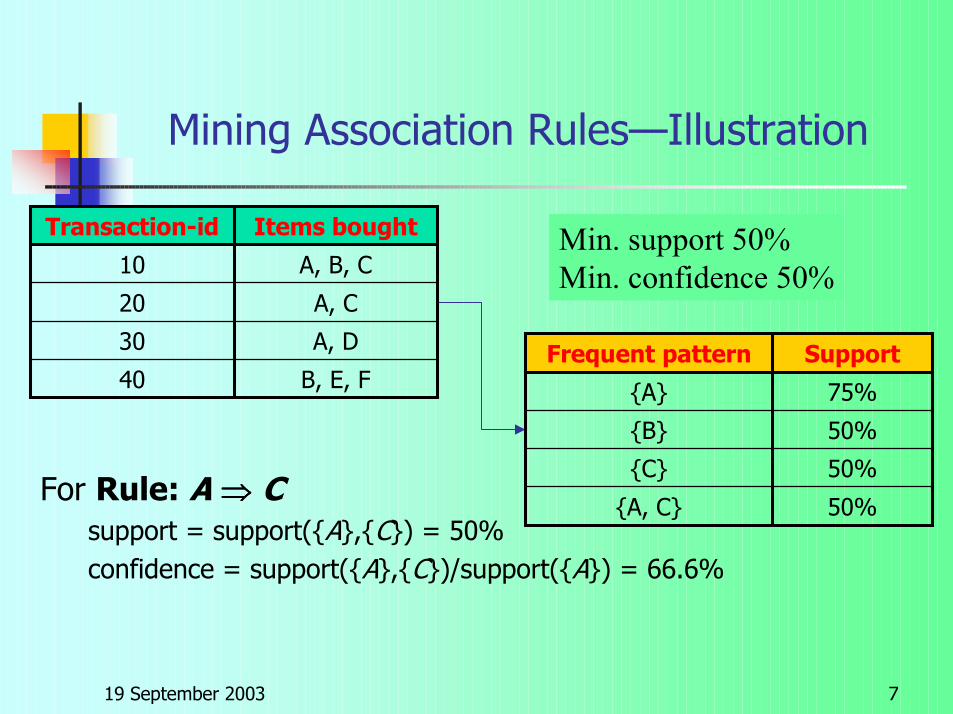
19 September 2003 7
Mining Association Rules—Illustration
For Rule: A ⇒⇒⇒⇒ Csupport = support({A},{C}) = 50%confidence = support({A},{C})/support({A}) = 66.6%
Min. support 50%Min. confidence 50%
B, E, F40
A, D30
A, C20
A, B, C10
Items boughtTransaction-id
50%{A, C}
50%{C}
50%{B}
75%{A}
SupportFrequent pattern

19 September 2003 8
More Examples
E.g.1, www.amazon.com: (CRM)
"Customers who bought this book (book x) also bought:"{book A} => {book B, book C} (supp=20%, conf=60%)
E.g.2, Add costumer data into market basket analysis:
{age(30 ...39), income(42K...48K)} => {buys(DVD player)} (18%, 70%)
E.g.3., The video store database analysis (a CRM application): (~prof6405/Doc/thesisPothier.pdf)
{coupon} => {new_release} (30%, 52%)

19 September 2003 9
Cluster Mining
Find the groups of objects from a DB. The objects are similar in a same cluster and dissimilar in different groups. The clustering knowledge is for partitioning the original DB into sub data sets.

19 September 2003 10
E.g.1: Clusters of a 3D customer DB
age
credit
income
age
credit
income

19 September 2003 11

19 September 2003 12
E.g.2: Finding valuable customer groups of the video store (~prof6405/Doc/ThesisPothier.pdf)
DB instance:
15106$22.237$123.862249166
0000$0.000$0.00049165
4730$37.7010$31.221449164
199119$2.471$58.992949163
NewRelChildAdultReserveCount
LateChgnLateRevenuenRentalsCustID
Sample customer information after data coding/enrichment

19 September 2003 13
E.g.2 (cont): The result with 5 seeds and unit weights

19 September 2003 14
E.g. 3: Text clustering for supporting IRThe application: "Automatic text categorization and text retrieval for PPML archive", MScthesis, Jianhua Guo, 1999 (~prof6405/Doc/thesisGuo.pdf).
Data set:- PPML: Pediatric Pain Mailing List (600 worldwide subscribers) Pediatric: The branch of medicine that deals with the care of infants and children and the treatment of their diseases.
- The archive DB: 7129 files (14MB), in 1999The DB is growing in the rate around 3M per year.
- The goal: develop an information retrieval system of the PPML archive to help people use the PPML more effectively and efficiently.

19 September 2003 15
E.g. 3 (cont): PPML information retrieval system
The system design: It includes two main subsystems: Text categorization, Query.
The system architecture:
PPML Retrieval System
DataOrganization
Query Search System
TextCategorization
system
Result Display
(http://torch.cs.dal.ca/~qiufen/cgi-bin/THESIS/Web/PPML_Retrieval_05-04.cgi)

19 September 2003 16
E.g. 3 (cont) PPML categorization system
The goal:To periodically generate categories of E-mails according to the updating of the database.
The system architecture:
doc-termmatrix
clusters
un-clusteredfiles
clustercentroids
clusterclassification
categories
Clusteringalgorithms ;
Similaritymeasurement

19 September 2003 17
E.g. 3 (cont): PPML categorization system
The goal:To automatically partition the data into natural category groups.
Data preprocessing:Data normalization, term-dictionary generation, doc-term matrix generation.
Clustering method:- Average Agglomerative Clustering (a variation of k-means)
- Similarity measure: Weighted Cosine Similarity Measure
- Instead of setting a set of seeds, the method uses similarity threshold to limit the number of clusters to be generated

19 September 2003 18

19 September 2003 19
Characterization (Concept mining)
The process of discovering the knowledge describing concepts of object groups (or clusters).
The characterization knowledge can be discovered through generalizing the database from specific values to higher-level concepts.
The mined knowledge represents the characteristics of object groups, and can be used for quick comparison among the groups.

19 September 2003 20
E.g. 1: Customer profiling analysis
- Customer profiling- descriptive Data Mining for Financial Institutions, Rong Wang, ECMM project report, 2003 (based on SAS DM tools): (~prof4144/Doc/projectReportWang.pdf)
- How to segment and describe customers from different perspectives which aims to provide a general profile of the Financial Institutions’customers, and modeling for a product campaign that took place at the beginning of 2003
- The databases consist of customer information from the 11 Financial Institutions (FI) across Nova Scotia. There are 19 tables covering personal information, account summarization, and transaction details with different accounts and services for each FI

19 September 2003 21
E.g. 1: Customer profiling analysis (cont)
The analysis procedure:1. Integrate and normalize the data into a large flat file called Customer
Information File2. Use K-means cluster analysis to segment customers by: - 1) Demographic, geographic and behavioral Customer information - 2) Financial product usage patterns - 3) Spending potential on selected items that may impact financial
decisions (e.g., mortgage interest, car purchases).3. Each segment is then profiled. These analyses were aimed at
providing a big picture for the FIs to understand their customers’ profiles and behaviors
4. Apply unsupervised data mining to find out the associations between different products/services and the profile of identified customer groups according to their financial portfolios

19 September 2003 22
E.g. 2: Survey comments analysis
- A company has 50k employees, the company conducts survey analysis each year
- Task:Each record in the DB corresponds to a survey sheet containing 16 questions and the answers.
1) For each question: summaries of positive and negative comments.2) The theme for each of the classes for each question.
- Comments classification for each survey question
- Theme generation (or characterization) for each class

19 September 2003 23
Evolution (Time Series, Trend Analysis)
A time series is a set of attribute values over a period of time. Evolution mining is to discover patterns in the data and predicting future values.
E.g., - Financial analysis frequently attempt to predict interest rate
fluctuations or stock performance based on a series preceding events. Seasonal sales predication, etc.
- Finding trend patterns for forecasting asthma related hospitaladmissions

19 September 2003 24
DM on What Kind of DBs?Relational DBs, Data warehouses
Transactional DBs
Advanced DB and information repositories,
Spatial databases,
Time-series data and temporal data Log files,
Text databases,
Multimedia databases,
Others

19 September 2003 25
DM SystemsExamples (Commercial packages)
IBM Intelligent Miner: http://www.almaden.ibm.com/cs/quest/
SAS Enterprise Miner: http://www.sas.com
Cognos: http://www.cognos.com
DBMiner: http://www.dbminer.com
Clementine: http://www.spss.com/spssbi/clementine/
DataCrusher: http://www.datamindcorp.com
MineSet: http://www.sgi.com
Thought: http://www.4thought.com
Internet resources

19 September 2003 26
• Public domain
Brute (the University of Washington, USA)MCL++ (Stanford University, USA)
• Research prototype
DBMiner (Simon Fraser University, Canada) Mining Kernel System (University of UIster, Northern Irealand)

19 September 2003 27

19 September 2003 28

19 September 2003 29

19 September 2003 30

19 September 2003 31

19 September 2003 32

19 September 2003 33

19 September 2003 34
How to Choose a DM System?
Commercial data mining systems have little in common Different data mining functionality or methodology May even work with completely different kinds of data sets
Need multiple dimensional view in selectionData types: relational, transactional, text, time sequence, spatial?System issues
running on only one or on several operating systems?a client/server architecture?Provide Web-based interfaces and allow XML data as input and/or output?

19 September 2003 35
How to choose a DM system? (cont)Data sources
ASCII text files, multiple relational data sourcessupport ODBC connections (OLE DB, JDBC)?
Data mining functions and methodologiesOne vs. multiple data mining functionsOne vs. variety of methods per function
More data mining functions and methods per function provide the user with greater flexibility and analysis power
Coupling with DB and/or data warehouse systemsFour forms of coupling: no coupling, loose coupling, semi tight coupling, and tight coupling
Ideally, a data mining system should be tightly coupled with a database system

19 September 2003 36
How to choose a DM system? (cont)Scalability
Row (or database size) scalabilityColumn (or dimension) scalabilityCurse of dimensionality: it is much more challenging to make a system column scalable that row scalable
Visualization tools“A picture is worth a thousand words”Visualization categories: data visualization, mining result visualization, mining process visualization, and visual data mining
Data mining query language and graphical user interfaceEasy-to-use and high-quality graphical user interface Essential for user-guided, highly interactive data mining

19 September 2003 37
Trends in Data Mining
Application explorationdevelopment of application-specific data mining systemInvisible data mining (mining as built-in function)
Scalable data mining methodsConstraint-based mining: use of constraints to guide data mining systems in their search for interesting patterns
Integration of data mining with database systems, data warehouse systems, and Web database systems

19 September 2003 38
Trends in Data Mining (cont)Standardization of data mining language
A standard will facilitate systematic development, improve interoperability, and promote the education and use of data mining systems in industry and society
Visual data mining
New methods for mining complex types of dataMore research is required towards the integration of data miningmethods with existing data analysis techniques for the complex types of data
Web mining
Privacy protection and information security in data mining


