Embed Size (px)
Citation preview

CSC 4320/6320
Operating Systems
Lecture 13
Distributed Coordination
Saurav Karmakar

Chapter 18 Distributed Coordination
• Event Ordering• Mutual Exclusion • Atomicity• Concurrency Control• Deadlock Handling• Election Algorithms• Reaching Agreement

Chapter Objectives
• To describe various methods for achieving mutual exclusion in a distributed system
• To explain how atomic transactions can be implemented in a distributed system
• To show how some of the concurrency-control schemes discussed in Chapter 6 can be modified for use in a distributed environment
• To present schemes for handling deadlock prevention, deadlock avoidance, and deadlock detection in a distributed system

Event Ordering
• Happened-before relation (denoted by )
– If A and B are events in the same process, and A was executed before B, then A B
– If A is the event of sending a message by one process and B is the event of receiving that message by another process, then A B
– If A B and B C then A C
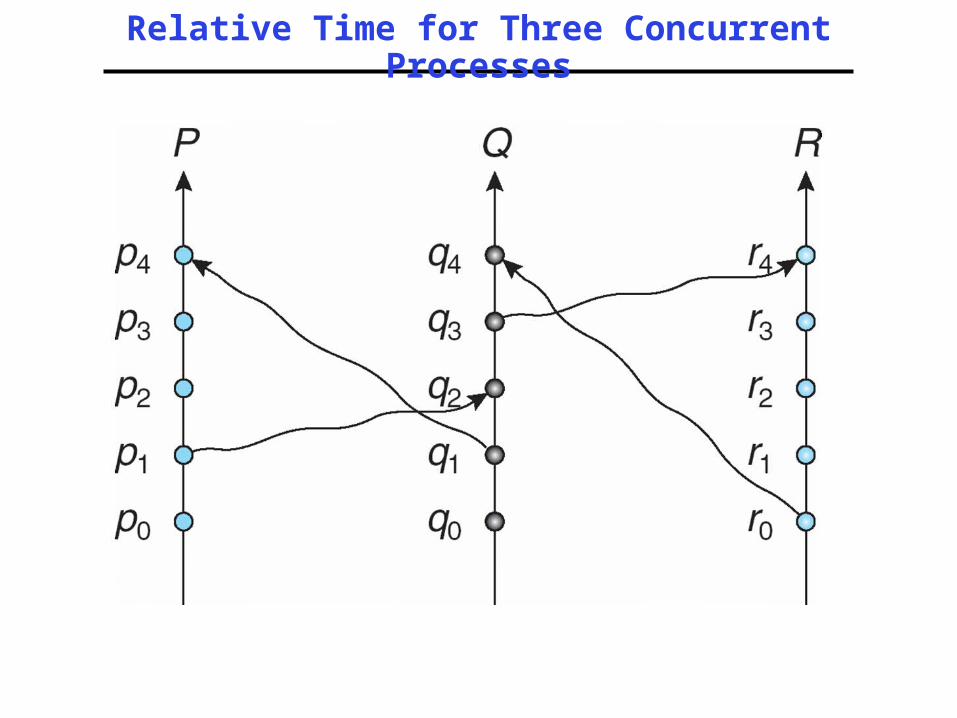
Relative Time for Three Concurrent Processes

Implementation of
• Associate a timestamp with each system event– Require that for every pair of events A and B, if A B,
then the timestamp of A is less than the timestamp of B
• Within each process Pi a logical clock, LCi is associated– The logical clock can be implemented as a simple counter
that is incremented between any two successive events executed within a process » Logical clock is monotonically increasing
• A process advances its logical clock when it receives a message whose timestamp is greater than the current value of its logical clock
• If the timestamps of two events A and B are the same, then the events are concurrent– We may use the process identity numbers to break ties
and to create a total ordering

Distributed Mutual Exclusion (DME)
• Assumptions– The system consists of n processes; each
process Pi resides at a different processor– Each process has a critical section that
requires mutual exclusion
• Requirement– If Pi is executing in its critical section, then
no other process Pj is executing in its critical section
• We present two algorithms to ensure the mutual exclusion execution of processes in their critical sections

DME: Centralized Approach
• One of the processes in the system is chosen to coordinate the entry to the critical section
• A process that wants to enter its critical section sends a request message to the coordinator
• The coordinator decides which process can enter the critical section next, and its sends that process a reply message
• When the process receives a reply message from the coordinator, it enters its critical section
• After exiting its critical section, the process sends a release message to the coordinator and proceeds with its execution
• This scheme requires three messages per critical-section entry:– request – reply– release

DME: Fully Distributed Approach
• When process Pi wants to enter its critical section, it generates a new timestamp, TS, and sends the message request (Pi, TS) to all other processes in the system
• When process Pj receives a request message, it may reply immediately or it may defer sending a reply back
• When process Pi receives a reply message from all other processes in the system, it can enter its critical section
• After exiting its critical section, the process sends reply messages to all its deferred requests

DME: Fully Distributed Approach (Cont)
• The decision whether process Pj replies immediately to a request(Pi, TS) message or defers its reply is based on three factors:– If Pj is in its critical section, then it defers its
reply to Pi
– If Pj does not want to enter its critical section, then it sends a reply immediately to Pi
– If Pj wants to enter its critical section but has not yet entered it, then it compares its own request timestamp with the timestamp TS» If its own request timestamp is greater than
TS, then it sends a reply immediately to Pi (Pi asked first)
» Otherwise, the reply is deferred

Desirable Behavior of Fully Distributed Approach
• Freedom from Deadlock is ensured• Freedom from starvation is ensured, since
entry to the critical section is scheduled according to the timestamp ordering– The timestamp ordering ensures that
processes are served in a first-come, first served order
• The number of messages per critical-section entry is
2 x (n – 1)
This is the minimum number of required messages per critical-section entry when processes act independently and concurrently

Three Undesirable Consequences
• The processes need to know the identity of all other processes in the system, which makes the dynamic addition and removal of processes more complex
• If one of the processes fails, then the entire scheme collapses– This can be dealt with by continuously monitoring
the state of all the processes in the system
• Processes that have not entered their critical section must pause frequently to assure other processes that they intend to enter the critical section
• This protocol is therefore suited for small, stable sets of cooperating processes

Token-Passing Approach
• Circulate a token among processes in system– Token is special type of message– Possession of token entitles holder to enter
critical section
• Processes logically organized in a ring structure
• Unidirectional ring guarantees freedom from starvation
• Two types of failures– Lost token – election must be called– Failed processes – new logical ring
established

Timestamping
• Generate unique timestamps in distributed scheme:– Each site generates a unique local
timestamp– The global unique timestamp is obtained by
concatenation of the unique local timestamp with the unique site identifier
– Use a logical clock defined within each site to ensure the fair generation of timestamps
• Timestamp-ordering scheme
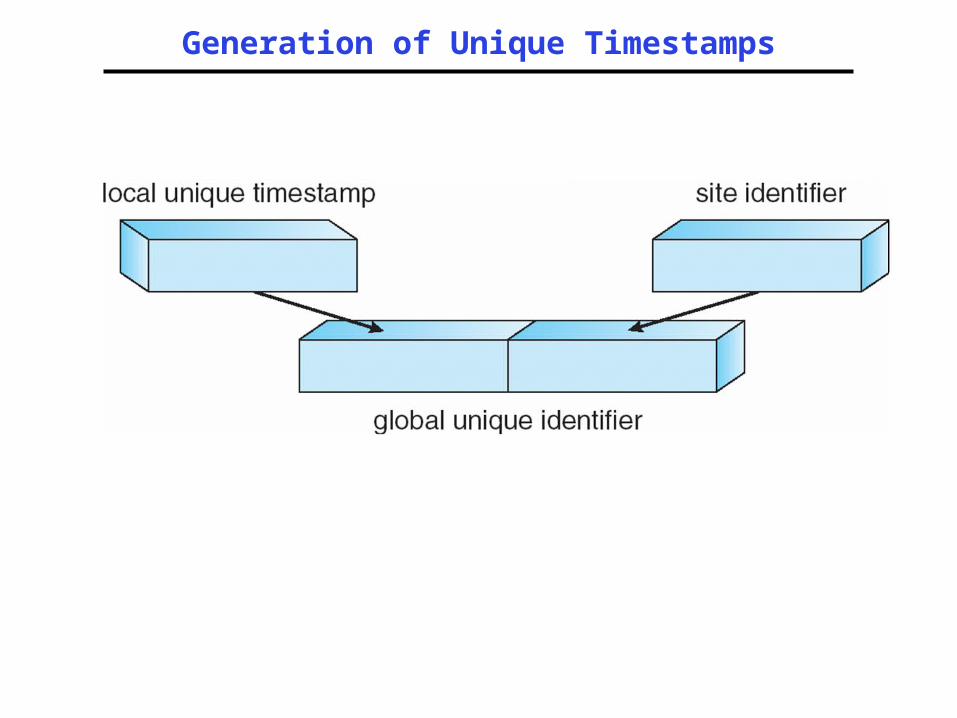
Generation of Unique Timestamps

Deadlock Prevention
• Resource-ordering deadlock-prevention – define a global ordering among the system resources– Assign a unique number to all system
resources– A process may request a resource with unique
number i only if it is not holding a resource with a unique number grater than i
– Simple to implement; requires little overhead
• Banker’s algorithm – designate one of the processes in the system as the process that maintains the information necessary to carry out the Banker’s algorithm– Also implemented easily, but may require too
much overhead

Timestamped Deadlock-Prevention Scheme
• Each process Pi is assigned a unique priority number
• Priority numbers are used to decide whether a process Pi should wait for a process Pj; otherwise Pi is rolled back
• The scheme prevents deadlocks – For every edge Pi Pj in the wait-for graph,
Pi has a higher priority than Pj
– Thus a cycle cannot exist

Wait-Die Scheme
• Based on a nonpreemptive technique
• If Pi requests a resource currently held by Pj, Pi is allowed to wait only if it has a smaller timestamp than does Pj (Pi is older than Pj)– Otherwise, Pi is rolled back (dies)
• Example: Suppose that processes P1, P2, and P3 have timestamps 5, 10, and 15 respectively– if P1 request a resource held by P2, then P1 will
wait
– If P3 requests a resource held by P2, then P3 will be rolled back

Wound-Wait Scheme
• Based on a preemptive technique; counterpart to the wait-die system
• If Pi requests a resource currently held by Pj, Pi is allowed to wait only if it has a larger timestamp than does Pj (Pi is younger than Pj). Otherwise Pj is rolled back (Pj is wounded by Pi)
• Example: Suppose that processes P1, P2, and P3 have timestamps 5, 10, and 15 respectively– If P1 requests a resource held by P2, then the
resource will be preempted from P2 and P2 will be rolled back
– If P3 requests a resource held by P2, then P3 will wait

Deadlock Detection
• Use wait-for graphs– Local wait-for graphs at each local site.
The nodes of the graph correspond to all the processes that are currently either holding or requesting any of the resources local to that site
– May also use a global wait-for graph. This graph is the union of all local wait-for graphs.
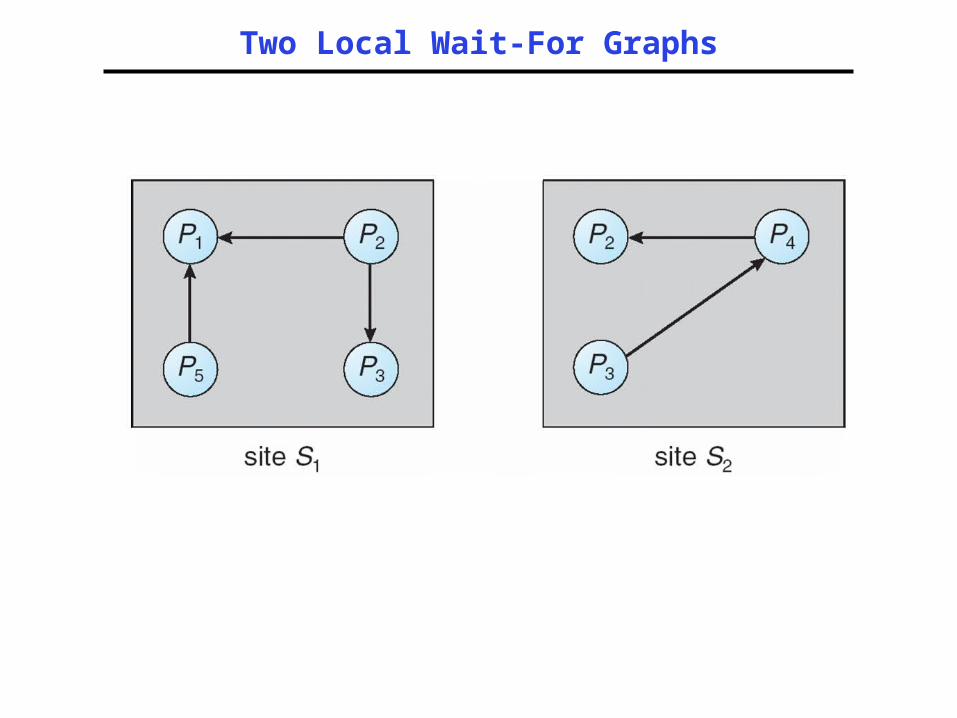
Two Local Wait-For Graphs
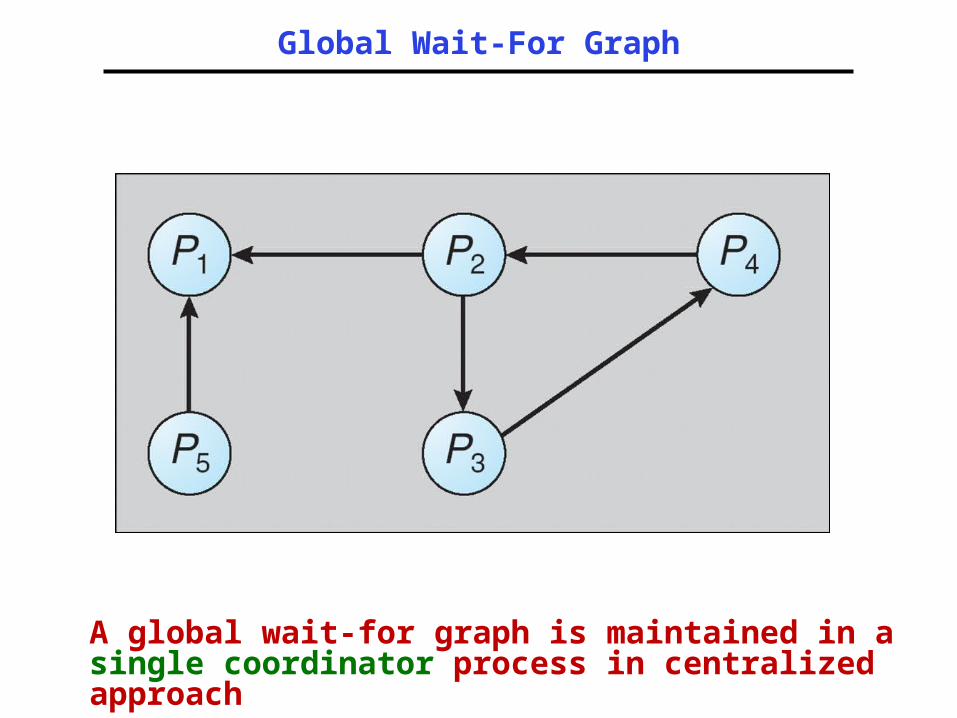
Global Wait-For Graph
A global wait-for graph is maintained in a single coordinator process in centralized approach

Election Algorithms
• Determine where a new copy of the coordinator should be restarted
• Assume that a unique priority number is associated with each active process in the system, and assume that the priority number of process Pi is i
• Assume a one-to-one correspondence between processes and sites
• The coordinator is always the process with the largest priority number. When a coordinator fails, the algorithm must elect that active process with the largest priority number
• Two algorithms, the bully algorithm and a ring algorithm, can be used to elect a new coordinator in case of failures

Bully Algorithm
• Applicable to systems where every process can send a message to every other process in the system
• If process Pi sends a request that is not answered by the coordinator within a time interval T, assume that the coordinator has failed; Pi tries to elect itself as the new coordinator
• Pi sends an election message to every process with a higher priority number, Pi then waits for any of these processes to answer within T

Bully Algorithm (Cont)
• If no response within T, assume that all processes with numbers greater than i have failed; Pi elects itself the new coordinator
• If answer is received, Pi begins time interval T´, waiting to receive a message that a process with a higher priority number has been elected
• If no message is sent within T´, assume the process with a higher number has failed; Pi should restart the algorithm

Bully Algorithm (Cont)
• If Pi is not the coordinator, then, at any time during execution, Pi may receive one of the following two messages from process Pj
– Pj is the new coordinator (j > i). Pi, in turn, records this information
– Pj started an election (j > i). Pi, sends a response to Pj and begins its own election algorithm, provided that Pi has not already initiated such an election
• After a failed process recovers, it immediately begins execution of the same algorithm
• If there are no active processes with higher numbers, the recovered process forces all processes with lower number to let it become the coordinator process, even if there is a currently active coordinator with a lower number

Ring Algorithm
• Applicable to systems organized as a ring (logically or physically)
• Assumes that the links are unidirectional, and that processes send their messages to their right neighbors
• Each process maintains an active list, consisting of all the priority numbers of all active processes in the system when the algorithm ends
• If process Pi detects a coordinator failure, It creates a new active list that is initially empty. It then sends a message elect(i) to its right neighbor, and adds the number i to its active list

Ring Algorithm (Cont)
• If Pi receives a message elect(j) from the process on the left, it must respond in one of three ways:
1. If this is the first elect message it has seen or sent, Pi creates a new active list with the numbers i and j It then sends the message elect(i), followed by
the message elect(j)
2. If i j, then the active list for Pi now contains the numbers of all the active processes in the system Pi can now determine the largest number in the
active list to identify the new coordinator process
3. If i = j, then Pi receives the message elect(i) The active list for Pi contains all the active
processes in the system Pi can now determine the new coordinator
process.

• General’s paradox: – Constraints of problem:
» Two generals, on separate mountains» Can only communicate via messengers» Messengers can be captured
– Problem: need to coordinate attack» If they attack at different times, they all die» If they attack at same time, they win
– Named after Custer, who died at Little Big Horn because he arrived a couple of days too early
• Can messages over an unreliable network be used to guarantee two entities do something simultaneously?– Remarkably, “no”, even if all messages get through
– No way to be sure last message gets through!
Yeah, but what if you
Don’t get this ack?
General’s Paradox
11 am ok?
So, 11 it is?
Yes, 11 works

Two-Phase Commit
• Since we can’t solve the General’s Paradox (i.e. simultaneous action), let’s solve a related problem– Distributed transaction: Two machines agree to do
something, or not do it, atomically • Two-Phase Commit protocol does this
– Use a persistent, stable log on each machine to keep track of whether commit has happened» If a machine crashes, when it wakes up it first checks
its log to recover state of world at time of crash– Prepare Phase:
» The global coordinator requests that all participants will promise to commit or rollback the transaction
» Participants record promise in log, then acknowledge» If anyone votes to abort, coordinator writes “Abort” in
its log and tells everyone to abort; each records “Abort” in log
– Commit Phase:» After all participants respond that they are prepared,
then the coordinator writes “Commit” to its log» Then asks all nodes to commit; they respond with ack» After receive acks, coordinator writes “Got Commit” to
log– Log can be used to complete this process such that
all machines either commit or don’t commit

Two phase commit example• Simple Example: AWellsFargo Bank, BBank of
America– Phase 1: Prepare Phase
» A writes “Begin transaction” to logAB: OK to transfer funds to me?
» Not enough funds:BA: transaction aborted; A writes “Abort” to log
» Enough funds:B: Write new account balance & promise to commit to logBA: OK, I can commit
– Phase 2: A can decide for both whether they will commit» A: write new account balance to log» Write “Commit” to log» Send message to B that commit occurred; wait for ack» Write “Got Commit” to log
• What if B crashes at beginning? – Wakes up, does nothing; A will timeout, abort and retry
• What if A crashes at beginning of phase 2?– Wakes up, sees that there is a transaction in progress;
sends “Abort” to B• What if B crashes at beginning of phase 2?
– B comes back up, looks at log; when A sends it “Commit” message, it will say, “oh, ok, commit”

Distributed Decision Making Discussion• Why is distributed decision making desirable?
– Fault Tolerance!– A group of machines can come to a decision even if one or
more of them fail during the process» Simple failure mode called “failstop” (different modes later)
– After decision made, result recorded in multiple places• Undesirable feature of Two-Phase Commit: Blocking
– One machine can be stalled until another site recovers:» Site B writes “prepared to commit” record to its log, sends a
“yes” vote to the coordinator (site A) and crashes» Site A crashes» Site B wakes up, check its log, and realizes that it has voted
“yes” on the update. It sends a message to site A asking what happened. At this point, B cannot decide to abort, because update may have committed
» B is blocked until A comes back– A blocked site holds resources (locks on updated items,
pages pinned in memory, etc) until learns fate of update• Alternative: There are alternatives such as “Three Phase
Commit” which don’t have this blocking problem• What happens if one or more of the nodes is malicious?
– Malicious: attempting to compromise the decision making
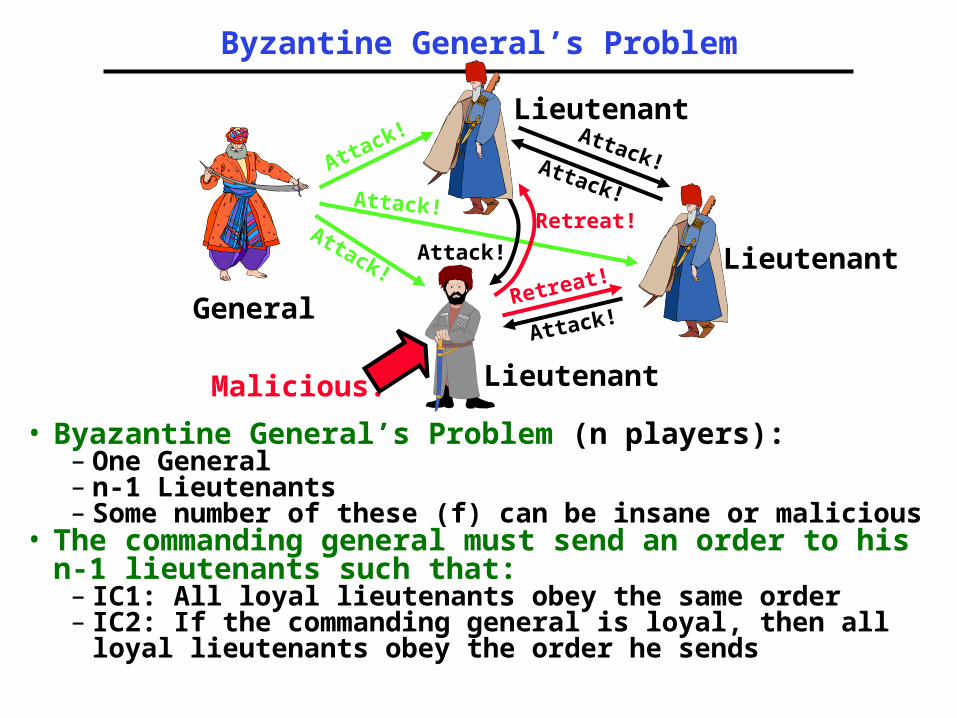
Byzantine General’s Problem
• Byazantine General’s Problem (n players):– One General– n-1 Lieutenants– Some number of these (f) can be insane or
malicious• The commanding general must send an order to
his n-1 lieutenants such that:– IC1: All loyal lieutenants obey the same order– IC2: If the commanding general is loyal, then all
loyal lieutenants obey the order he sends
General
Attack!
Attack!
Attack!Retreat!
Attack!
Retreat!
Attack!
Attack!Attack!
Lieutenant
Lieutenant
LieutenantMalicious!
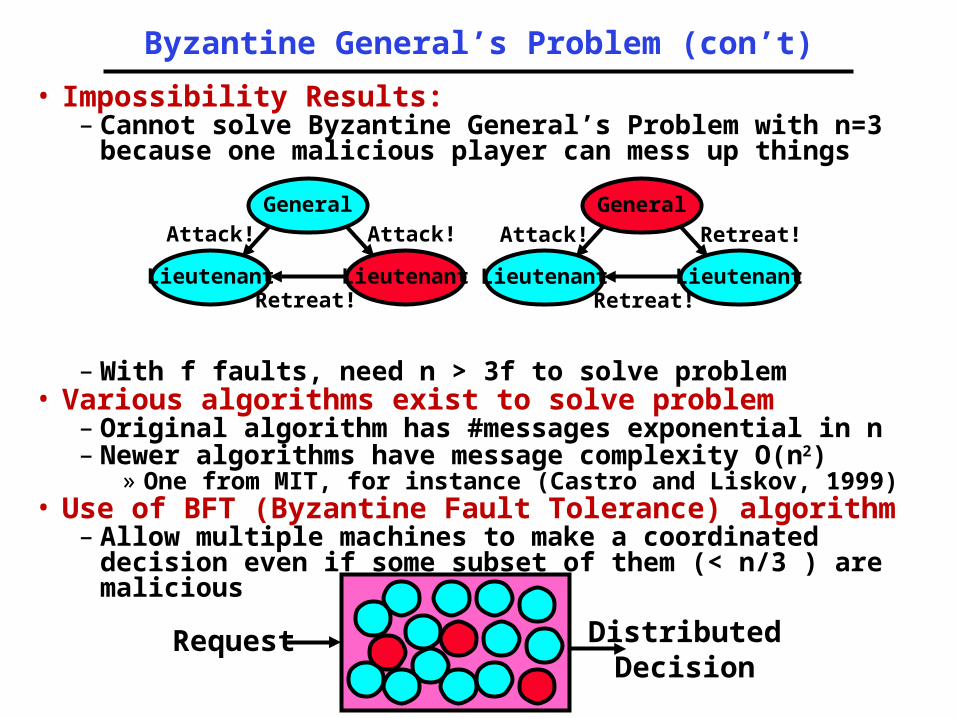
Byzantine General’s Problem (con’t)
• Impossibility Results:– Cannot solve Byzantine General’s Problem with
n=3 because one malicious player can mess up things
– With f faults, need n > 3f to solve problem• Various algorithms exist to solve problem
– Original algorithm has #messages exponential in n– Newer algorithms have message complexity O(n2)
» One from MIT, for instance (Castro and Liskov, 1999)• Use of BFT (Byzantine Fault Tolerance)
algorithm– Allow multiple machines to make a coordinated
decision even if some subset of them (< n/3 ) are malicious
General
LieutenantLieutenant
Attack! Attack!
Retreat!
General
LieutenantLieutenant
Attack! Retreat!
Retreat!
Request DistributedDecision

End of Lecture 13





![SAURAV ADMIT CRD[2].docx](https://img.pdfslide.us/doc/110x75/55cf859c550346484b8fef55/saurav-admit-crd2docx.jpg)























