Embed Size (px)
Citation preview

CS6913: Web Search EnginesLecture on
Advanced Search Engine Architecture and Query Processing
Torsten Suel
Computer Science and EngineeringNYU Tandon School of Engineering, Brooklyn

Content of this lecture:
• Discussion of Search Engine Evolution and Scaling• Parallel Query Processing• Index Sharding• Load Balancing and Service-Level Agreements• Large Distributed Search Architectures• Index Tiering• Early Termination for Fast Candidate GenerationTop-k Document Retrieval Using Block-Max Indexes. With S. Ding. 34th Annual ACM SIGIR Conference, July 2011.

Content of this lecture:
• Discussion of Search Engine Evolution and Scaling• Parallel Query Processing• Index Sharding• Load Balancing and Service-Level Agreements• Large Distributed Search Architectures• Index Tiering• Early Termination for Fast Candidate GenerationTop-k Document Retrieval Using Block-Max Indexes. With S. Ding. 34th Annual ACM SIGIR Conference, July 2011.

Recall: Basic Search Engine Architecture
Crawler
disks
Index
indexing
SearchInterfaceQuery: “computer”
look up

Main Tasks in a Large Search Engine
Component Details
Data acquisition (web crawling)
Web crawling, refresh, data extraction, other data sources
Data analysis(web mining)
Pagerank, spam detection, log and click-through analysis, index and
crawl optimizations
Index building Index build and maintenance
Query processing Query analysis and rewriting, routing, tiering, execution, final
ranking, snippet generation

Main Tasks in a Large Search Engine
Component Details Setup
Data acquisition (web crawling)
Web crawling, refresh, data extraction, other data sources
1,000s of cpu, custom
code
Data analysis (web mining)
Pagerank, spam detection, log and click-through analysis, index and
crawl optimizations
100,000s ofcpus,
mapreduce
Index building Index build and maintenance (part of DA&QP)
Query processing Query analysis and rewriting, routing, tiering, execution, final ranking,
snippet generation
100,000sof cpus,custom code

Main Tasks in a Large Search Engine
Component Details Scaling
Data acquisition (web crawling)
Web crawling, refresh, data extraction, other data sources
size & rate
Data analysis(web mining)
Pagerank, spam detection, log and click-through analysis, index and
crawl optimizations
size, rate & # tasks
Index building Index build and maintenance size & rate
Query processing Query analysis and rewriting, routing, tiering, execution, final
ranking, snippet generation
size &load

Main Tasks in a Large Search Engine
Component Details B’necks
Data acquisition (web crawling)
Web crawling, refresh, data extraction, other data sources
network& cpu
Data analysis(web mining)
Pagerank, spam detection, log and click-through analysis, index and
crawl optimizations
cpu, lan, i/o & ram
Index building Index build and maintenance (cpu & disk?)
Query processing Query analysis and rewriting, routing, tiering, execution, final
ranking, snippet generation
cpu & ram

Main Tasks in a Large Search Engine
Component Details B’necks
Data acquisition (web crawling)
Web crawling, refresh, data extraction, other data sources
network& cpu
Data analysis(web mining)
Pagerank, spam detection, log and click-through analysis, index and
crawl optimizations
cpu, lan, i/o & ram
Index building Index build and maintenance (cpu & disk?)
Query processing
Query analysis and rewriting, routing, tiering, execution, final
ranking, snippet generation
cpu & ram
Note: queries need to be done in real time

Another View: Main Systems in a Large Engine
Component Details Size
Data acquisition (web crawling)
Web crawling, refresh, data extraction, other data sources
1,000s of nodes
Data analysis(web mining)
Pagerank, spam detection, log and click-through analysis, index and
crawl optimizations
100,000s of nodes
Index building Index build and maintenance part of a DA or QP
Query processing
Query analysis and rewriting, routing, tiering, execution, final
ranking, snippet generation
100,000s of nodes
Data Serving Fetch docs (snippets), user profiles, and other data, before or after qp
>1,000s of nodes

Search Engine Architecture (1995)(handful of people)
data acquisitiondata analysis
index buildingquery processing

(dozens of people)
data acquisitiondata analysisindex building
query processing
Search Engine Architecture (2000)

(hundreds of people)
data acquisition
data analysisindex building
query processing
Search Engine Architecture (2010+)

Search Engine Query Processing
• How do large engines execute queries?• 50,000 queries per seconds over tens of billions of
documents in fractions of a second• Significant costs: hardware, energy, engineering• Also, traffic acquisition (ads, browser deals)• Search business:
• A few cents per query income (advertising)• Less than a cent per query costs (hardware, energy)• If you are #1 – otherwise more cost and less income/q
Document Retrieval Using Block-Max Indexes. With S. Ding. 34th Annual ACM SIGIR Conference, July 2011.

Images (c) Google


Summary:• QP is the major performance challenge in large SEs• Billions of queries per day• Evaluated of hundreds of billions of documents• Results needed in < 100ms• Huge hardware and energy cost, large data centers• QP efficiency matters, saves many millions
• In following, will discuss how to scale QP

Content of this lecture:
• Discussion of Search Engine Evolution and Scaling• Parallel Query Processing• Index Sharding• Load Balancing and Service-Level Agreements• Large Distributed Search Architectures• Index Tiering• Early Termination for Fast Candidate GenerationTop-k Document Retrieval Using Block-Max Indexes. With S. Ding. 34th Annual ACM SIGIR Conference, July 2011.

Index Partitioning Techniques:
• Local versus global index organization• Local index organization (also called horizontal)
- each machine has subset of documents- builds index on this subset- returns top-k results on this subset- query integrator merges results from nodes
- Global index organization (also called vertical)- each machine has subset of the inverted lists- e.g., node A has list for “dog”, node B has list for “cat”- lists need to be transmitted between nodes- network traffic needs to be minimized
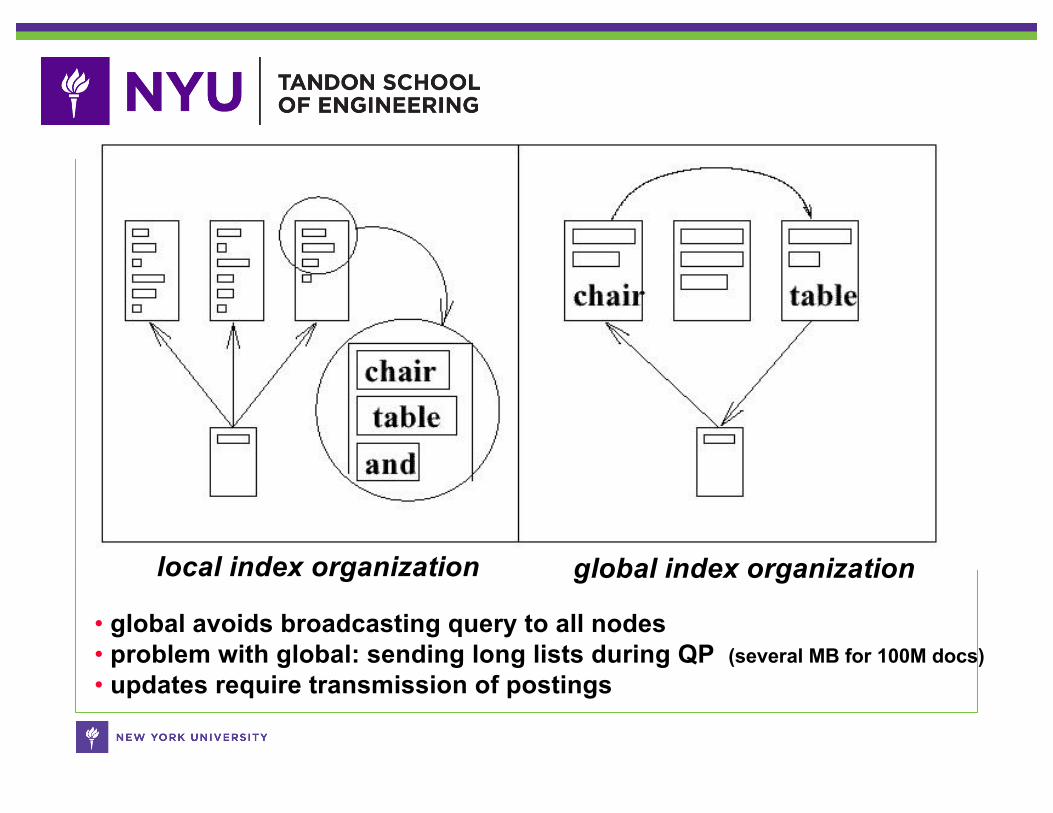
• global avoids broadcasting query to all nodes• problem with global: sending long lists during QP (several MB for 100M docs)• updates require transmission of postings
local index organization global index organization

• for small collections and short lists, global index org. better?• probably not used in large engines• but some engines use hybrid schemes: global for short lists and
for phrase and pairwise (specialized) index structures
global index organization
• to build index: build local indexes, then exchange lists over network
• problem: query processing alsorequires sending lists over network
• there are some tricks to save onnetwork transmissions (e.g., BloomFilters, early termination, others)
• but usually not a good idea

local index organization
• symmetrical and simple: every node just builds its own SE
• problem: every query requiressome work by every node
• this is OK if lists are long• but bad if lists are shorts, esp.
if index is on HDD
• general principle in parallel computation: not a good idea to split asmall amount of work among many machines (especially disk I/O)
• but in large search engines, there is a lot of work, and we can splitthis onto hundreds machines and more with little overhead
• large search engines use local index organizations (or hybrids)

How to Scale for Performance and Resilience?

How to Scale for Performance and Resilience?
What is the problem with this approach?

Parallel Query Processing Summary:• Global versus local index organization• Most engines use global or hybrids• Scaling and fault tolerance via replication• But simple replication schemes do not work well• Lesson #1: replicating entire machines not a good a
approach to fault tolerance• Lesson #2: mapping data directly onto machines
also not a good idea (general lesson in distributed systems)

Mapping Data to Machines• Suppose 1 billion data items need to be distributed
over 1000 nodes• Approach #1: hash items to nodes• Approach #2: direct assignment of items to nodes,
then keep track of items using a global table

Mapping Data to Machines• Suppose 1 billion data items need to be distributed
over 1000 nodes• Approach #1: hash items to nodes• Approach #2: direct assignment of items to nodes,
then keep track of items using a global table • Both of these approaches have problems• Better solution: hash or split items into, say, 20000
buckets (also called chunks, extends, shards)• Then assign and replicate shards to machines

Content of this lecture:
• Discussion of Search Engine Evolution and Scaling• Parallel Query Processing• Index Sharding• Load Balancing and Service-Level Agreements• Large Distributed Search Architectures• Index Tiering• Early Termination For Fast Candidate GenerationTop-k Document Retrieval Using Block-Max Indexes. With S. Ding. 34th Annual ACM SIGIR Conference, July 2011.

Index Sharding:
• documents assigned to index shards, not machines• each shard replicated on several machines• and each machine has several shards• route each query to one copy of each shard• when machine goes down, redistribute its load• and make an additional copy of the lost shards
• related work on large graphs: graph sharding

Index Sharding:• example: 5 shards over 4 machines• same color == same shard• integrator (not shown) has full view, might have
routing table for how to spread load

Index Sharding:
• example: 5 shards over 4 machines• same color == same shard• if machine 1 goes down, spread load over others

Index Sharding Summary:
• documents assigned to index shards, not machines• global table keeping track of locations of all replicasof every shard
• query integrator might have a query routing table,stating for each shard, what percentage of load should go to each shard replica
• tables are adjusted when nodes fail or shards move• large systems have multiple aggregator levels (tree)

Content of this lecture:
• Discussion of Search Engine Evolution and Scaling• Parallel Query Processing• Index Sharding• Load Balancing and Service-Level Agreements• Large Distributed Search Architectures• Index Tiering• Early Termination for Fast Candidate GenerationTop-k Document Retrieval Using Block-Max Indexes. With S. Ding. 34th Annual ACM SIGIR Conference, July 2011.

Service Level Agreements (SLAs)• A service level agreement specifies level of service• E.g., call center: 95% of calls answered in 5 min• Airline: 95% of flights arrive on time• Usually not just based on one maximum delay

Service Level Agreements (SLAs)• A service level agreement specifies level of service• E.g., call center: 95% of calls answered in 5 min• Airline: 95% of flights arrive on time• Usually not just based on one maximum delay
• Search engine architecture: 90% of all queries complete in 100ms, 99% in 500ms.
• delay seen by end user, or for one part of system • Dual SLA: 90% in 100ms, and also 95% of all results
are run with best quality, and 99% with 80% quality

Load Balancing and SLAs• A rough model: 4 levels of load balancing:
- document-to-shard assignment- shard-replica-to-machine assignment- query-load-to-shard-replica assignment- dynamic rerouting of query, based on current load & delay
• first level: rough balance, fairly static assignment• further levels more dynamic, to even out imbalances
remaining after previous levels• SLAs: based on delay, quality• how to reduce/shed load during peak times?

Content of this lecture:
• Discussion of Search Engine Evolution and Scaling• Parallel Query Processing• Index Sharding• Load Balancing and Service-Level Agreements• Large Distributed Search Architectures• Index Tiering• Early Termination for Fast Candidate GenerationTop-k Document Retrieval Using Block-Max Indexes. With S. Ding. 34th Annual ACM SIGIR Conference, July 2011.

Query Execution Steps:
• Parsing and rewriting (user query != backend query)
• Query routing and tiering(collections, data centers, tiers, nodes)
• Ranking: get top-k results
• Snippet generation, result fusion

Query Execution Steps:
• Parsing and rewriting (user query != backend query)
• Query routing and tiering(collections, data centers, tiers, nodes)
• Ranking: get top-k results
• Snippet generation, result fusionDocument Retrieval
Using Block-Max Indexes. With S. Ding. 34th Annual ACM
SIGIR Conference, July 2011.
get top-2000 (e.g.)rerank + get top-200rerank + diversity

Special collections and classes of queries:
• Large search engines really consist of several different sub-engines covering different collections
• E.g., news, images, video, blogs, social, recipes?• Some queries directly to sub-engines, some not• Queries an be categorized in ontologies/classes• News, people, product, geo queries, ....• News: newsiness Geo: geographic references• Route and/or process based on type of query• Special features for special classes of queries

Query Execution:
news Images … ads
hourlydailytier 1 tier 2
frontend
parsing &routing
QI websearch
QI
QI QIQI QI
QI QI
web search
c
c c
c
c
cc
query
(cache)
see [Risvik/Aaasheim/Lidal, LAWEB 2003]

Query Execution:
news Images … ads
hourlydailytier 1 tier 2
frontend
parsing &routing
QI websearch
QI
QI QIQI QI
QI QI
web search
c
c c
c
c
cc
query
(cache)
see [Risvik/Aaasheim/Lidal, LAWEB 2003]

Query Execution:
news Images … ads
hourlydailytier 1 tier 2
frontend
parsing &routing
QI websearch
QI
QI QIQI QI
QI QI
web search
c
c c
c
c
cc
query
(cache)
see [Risvik/Aaasheim/Lidal, LAWEB 2003]

Query Execution:
news Images … ads
hourlydailytier 1 tier 2
frontend
parsing &routing
QI websearch
QI
QI QIQI QI
QI QI
web search
c
c c
c
c
cc
query
(cache)
see [Risvik/Aaasheim/Lidal, LAWEB 2003]

Query Execution:
news Images … ads
hourlydailytier 1 tier 2
frontend
parsing &routing
QI websearch
QI
QI QIQI QI
QI QI
web search
c
c c
c
c
cc
query
(cache)
see [Risvik/Aaasheim/Lidal, LAWEB 2003]

• earlier: separate index for docs crawled every 12 hours, 2 days, 10 days• but most SEs have moved to fully dynamic indexes (e.g., Google Caffeine)
From: Risvig, Aasheim, Lidal, 2004.Used in AllTheWeb search engine.
Recrawling and Index Updates

Query Execution Steps:
• Complicated architecture• Many steps and machines• Routing has significant impact on latency
• But: this architectures parallelizes the problemnicely onto large numbers of machines
• Throughput depends on efficiency inside node• Single-node case matters Retrieval Using Block-Max
Indexes. With S. Ding. 34th Annual ACM SIGIR Conference, July 2011.

Content of this lecture:
• Discussion of Search Engine Evolution and Scaling• Parallel Query Processing• Index Sharding• Load Balancing and Service-Level Agreements• Large Distributed Search Architectures• Index Tiering• Early Termination for Fast Candidate GenerationTop-k Document Retrieval Using Block-Max Indexes. With S. Ding. 34th Annual ACM SIGIR Conference, July 2011.

Index Tiering (Risvik, Assheim, Lidal, LAWEB 2003)
• not all pages have the same importance and quality• most searches are focused on a relatively small subset of pages• idea: partition documents into good and bad pages• evaluate all queries on the good pages, and only if there are not
enough good results, also evaluate on the bad pages:
• extends to 3 tiers: “the good, the bad, and the ugly”• tiering: simple idea, works in practice, easy to manage & deploy
good pages(20%)
bad pages(80%)
20% of queriesall queries

Index Tiering: Technical Challenges
• Decide which pages to put into which tier• Decide when to “fall through” to 2nd and 3rd tiers• Can decide before or after executing on first tier• Note: these are both machine learning problems• Training data obtained by always falling through
• First tier can be replicated in several local markets• But then each market should have different pages• Also, compare the Selective Search

Content of this lecture:
• Discussion of Search Engine Evolution and Scaling• Parallel Query Processing• Index Sharding• Load Balancing and Service-Level Agreements• Large Distributed Search Architectures• Index Tiering• Early Termination for Fast Candidate GenerationTop-k Document Retrieval Using Block-Max Indexes. With S. Ding. 34th Annual ACM SIGIR Conference, July 2011.

Recall: Two Perspectives on Ranking:
1. Simple Ranking Functions• Cosine, BM25, or based on language modeling• Plus maybe positions or Pagerank• Fast inverted list traversal to get top-k results
2. Highly Complex Ranking Functions• Used by all major engines• Hundreds of features• Often machine-learned ranking functions + NN

First View: Simple Ranking Functions
• Basically, your HW#3• Fast to evaluate• Main challenge: data size• Many millions of postings per query• Optimizations:
• Index compression (uncompress > 1 billion ints/sec/core)
• Caching (results, lists, subqueries)
• Parallelism (a few million docs per node)
• Early Termination (don’t evaluate everything)

2nd View: Highly Complex Ranking Functions
• Hundreds of features!!• Term frequencies, positions, pagerank, but also
spam score, newsiness, click scores, etc• Often computed in Data Analysis phase
• May now include ranking using BERT etc
• Often special purpose (e.g., person search, local, news)
• Machine-learned ranking functions (or not?)
à simple ranking functions useless? No!

Recall: Cascading Query Execution• Main challenge: evaluation is slow• We need initial winnowing of the field• Cascading approach (e.g., Wang/Lin/Metzler, SIGIR 2011)
• Each cascade trained on output of previous• Simple ranking function = cascade #0 (candidate generation)
invertedlists for
query termtop
2000top100 result
BM25 orsimilar
cascade#1
cascade#2

Building Optimized Cascades [Wang/Lin/Metzler 2011]
• Given a complex ranking function that is too slow• Due to rank computation, and cost of getting features• How to design intermediate functions and cutoffs• Assumption: those use subset of features• Goal: almost same result as complex but faster
invertedlists for
query termtop
2000top100 result
BM25 orsimilar
cascade#1
cascade#2

Definition: Early Termination• An algo is exhaustive if it fully evaluates all docs passing the
Boolean filter. An algo uses early termination (ET) otherwise
• An ET algo is safe if it returns exactly the same top-k results (same docs, order, and scores) as an exhaustive algo
Early Termination Techniques• Ranking: Boolean filter + simple scoring of docs passing filter• Top-k queries: return the k highest scoring documents• Common case: top-k disjunction for candidate generation

• Also “lower levels of safety”:• same results but maybe in different order• mostly the same results (e.g., for 95% of queries or results)• or same quality according to IR measures (e.g., p@10)
• We already know two ET techniques: tiering and sel. search• Both are unsafe (but how about cascading?)
• In fact, most techniques used in real engines are unsafe• Usually, ET techniques designed for simple RFs in cascade 0• We focus on speeding up disjunctive queries in cascade 0
Early Termination Techniques (ctd.)

• Assume a “simple” ranking function rf(d, q) (d doc, q query)• Simple: sum of term-wise impact scores• E.g., BM25, cosine, LM, or precomputed impact scores
• Given a query q, the top-k disjunctive query processing problem requires us to return the k documents with the highest scores for rf(q, d) that contain at least one term in q
• Recall: safe means always returning the correct top k docs• Unsafe otherwise
Early Termination for Disjunctive Queries: Setup

Intuitions/Opportunities for Early Termination:
• Only (fully) traverse a prefix of the inverted list• Skip postings within the list (but go up to end)• Only partially evaluate some postings• (Ignore some terms completely)
pangolin
penguin
panda
porcupine

Some Previous Work on ET:
• A lot of related work in DB and IR (over 25 years)
• Databases: Fagin’s set of algorithms (PODS 1996)• FA, TA, and NRA• A lot of follow-up work
• IR: work starting in (at least) early 1980s• Safe ET for disjunctive queries:
- MaxScore (Turtle/Flood 1995)
- WAND (Broder et al 2003) versus SC (Strohman/Croft, SIGIR 2007)- Block-Max WAND (Ding/Suel 2011) (“BMW”)

Fagin’s Algorithms:• Keep each inverted list sorted by impact scores• Impact-sorted index (lists not sorted by docID)• During query execution, access lists from left to right• Stop when you have found the top-k
• Need random lookups (FA and TA)
pangolin
penguin
panda
porcupine

• two operations:- scan next element in a list: this returns the ID and score of this element- lookup score of element with given ID in a list: this returns the score
• algorithm given a query on k attributes:- read on element at a time from each of the k lists list, until there are k
elements that have occurred in every of the k lists list- now stop scanning, and perform lookups of the remaining attribute values
of all elements that have only occurred in some of the lists• claim: this is guaranteed to find correct top-k results
Fagin’s Algorithm (FA) (Ronald Fagin, PODS 1996)

• is this algorithm correct? (yes)• how long until the algorithm will finish?• claim: if each list is ordered independently at random, the
algorithm will stop after scanning about steps• example: on two lists, top-1 after expected O(sqrt(n)) steps• in reality, attributes often correlated: better performance!• two issues:
- is this the best possible algorithm?- can we avoid (some of) the random lookups into the lists?
Fagin’s Algorithm (FA) (ctd)
kN mmm 11
⋅−

• algorithm given a query on k attributes:- read on element at a time from each of the k lists list, and for each
element immediately look up its value in the other list, …- until there are k complete scores higher than the combination of the
last values read in each list (i.e., the values at the scan frontier)• example below: stop after 4 elements if k elements > “d+a”• claim: this is essentially the best possible• but asymptotically, same complexity • requires more random lookups
Threshold Algorithm (TA)
kN mmm 11
⋅−

• example: for query {student life, reputation}L = (NYU, 0.99) (Yale, 0.89) (UCLA, 0.87) (Cornell, 0.84) (MIT, 0.1)L = (MIT, 0.85) (Yale, 0.79) (NYU, 0.78) (Cornell, 0.77) (UCLA, 0.5)
• goal: return results with highest sum of scores
• FA, top-2: stop after scanning 3 from each list• TA, top-2: stop after scanning 2 from each list
• Theorem: TA never stops later than FA• but might use more random lookups …• note that complexity grows with degree of query:
Setup:
student lifereputation
kN mmm 11
⋅−

• read sequentially in each list, as before• but do not perform random lookup into other lists• instead, keep partially resolved candidates in data struct.• if you run into candidate you have previously seen in
another list, update that entry• stop when sure no candidate in data struct can be top-k• ... but this often stops much later than FA/TA!
No Random Access Algorithm (NRA)

• Random lookups usually unacceptable if index on disk• Random lookups even bad if in main memory!• NRA requires data structures to keep track of stuff seen
only in some but not all lists (slow!)• Inverted lists sorted by score, not docID: leads to very
bad compression• Other ranking factors such as Pagerank and term distance
in documents?• Note: approach requires score = sum of term scores
• Overall: needs reengineering to be useful in SE
FA/TA/NRA: Applicable to Search Engines?

Early Termination in Search Engines:• ET used in all large engines• Safe or unsafe early termination?• Most engines use unsafe ET• High level ET: tiering, cascading, skipping shards• Low level ET: within each node, within cascade 0• Basic ideas used in low level ET:
- impact-sorted and impact-layered indexes- or skipping on docID-sorted indexes- assigning docIDs based on global ranks- phrase, pairwise, etc. structures to get good candidates- blending/cooking approach to result quality

• “fancy lists” optimization in Google• create extra shorter inverted list for “fancy matches”
(matches that occur in URL, anchor text, title, bold face, etc.)
• note: fancy matches can be generalized as“postings with relatively high impact scores”
• no details given or numbers published, unsafe• also related to Persin/Zobel/Sacks-Davis 1993/96
- divide into larger number of chunks, from highest to lowest cosine- impact-layered index structure- in each chunk, sort by docID to achieve good compression
Simple Example: Google prototype (Brin/Page 1998)
chair
table
fancy list
fancy list
rest of list with other matches
rest of list with other matches

SC Algorithm: (Strohman/Croft, SIGIR 2007)
• Impact-layered index structure • First layer has highest scores, last layer lowest • But docID-sorted within a layer! • Engineering effort to speed up the candidate updates
apple
pear
High score
High Score
Low Score
Low Score

Maxscore (Turtle/Flood 1995)
• Store the max score for each term’s posting list• Have one pointer into each list, moving left to right• Suppose current threshold for top-k is 4.9• non-essential lists: their maxscores add up to less than 4.9• perform OR on essential lists, lookups into non-essentials
dog
cat
monkey
kangaroo
max = 1.8
max = 2.3
max = 3.3
max = 4.3
NE

WAND: “Weak And” (Broder et al, CIKM 2003)
• Store the max score for each term’s posting list• Have one pointer into each list, moving left to right• Keep the lists pointers sorted by their current docIDs• Pivoting to find the smallest candidate that could be top-k

Block-Max Wand (BMW) (Ding/Suel 2011)
• Remember: posting lists are compressed in blocks• say 128 postings per block• for each block, store maximum term score in block• in separate structure, as the last docIDs and block sizes• Use this is accelerate WAND, by getting more skipping• Also, version for Maxscore: BMM (Ganti et al 2011)• Version with va-size blocks: VBMW (Mallia et al 2017)• BMW part of Lucene 8.0

Another Approach: Limited Access Depth • Uses a global ordering of documents by “quality”• Using Pagerank, or # past clicks or displays, or ML-based• assign docIDs based on this ordering• Stop query in middle of list (say if intersection > 10000)
dog
cat
monkey
kangaroo
high document quality low

Another Approach: Static Pruning
• Normal index: one posting for each distinct word ineach distinct document (full-text index)
• But maybe some postings are never useful?
• “nobody will search for this page using this term”
• Throw away useless postings
• Smaller index, shorter lists
• Like tiering, but throw away second tier?(but note: tiering usually document-oriented)

Summary: Early Termination
• Used in all major search engines, crucial for speed
• Many methods, many are undocumented
• Safe, unsafe
• Higher-level shard-based vs. lower-level list-based ET





















