Embed Size (px)
Citation preview

CS460/626 : Natural LanguageCS460/626 : Natural Language Processing/Speech, NLP and the Web
(Lecture 4 POS tagging and HMM)(Lecture 4–POS tagging and HMM)
Pushpak BhattacharyyaPushpak BhattacharyyaCSE Dept., IIT Bombay9th J 20129th Jan, 2012
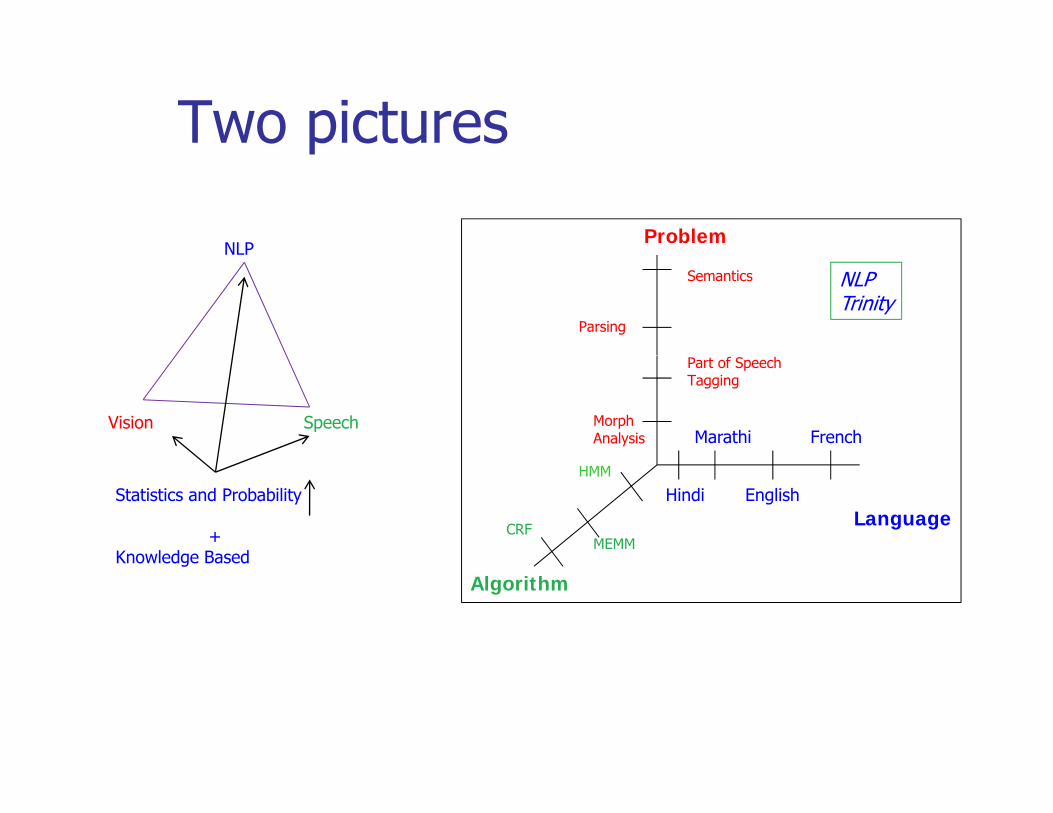
Two picturesp
NLPProblem
NLP
Parsing
Semantics NLPTrinity
Vision SpeechMarathi French
MorphAnalysis
Part of SpeechTagging
LanguageHindi EnglishStatistics and Probability
+Knowledge Based
CRF
HMM
MEMM
AlgorithmKnowledge Based

POS tagging: Definitiongg g
Tagging is the assignment of aTagging is the assignment of a singlepart-of-speech tag to each word ( d i k ) i(and punctuation marker) in a corpus.
“_“ The_DT guys_NNS that_WDT_ _ g y _ _make_VBP traditional_JJ hardware_NNare VBP really RB being VBGare_VBP really_RB being_VBGobsoleted_VBN by_IN microprocessor-based JJ machines NNS ” ” said VBDbased_JJ machines_NNS ,_, _ said_VBDMr._NNP Benton_NNP ._.

Where does POS tagging fit inWhere does POS tagging fit in
Di d C f
Semantics Extraction
Discourse and Corefernce
IncreasedComplexity
fParsing
OfProcessing
Chunking
POS tagging
Morphology

Mathematics of POS taggingMathematics of POS tagging

Argmax computation (1/2)Argmax computation (1/2)Best tag sequence= T*= T= argmax P(T|W)= argmax P(T)P(W|T) (by Baye’s Theorem)
P(T) = P(t0=^ t1t2 … tn+1=.)= P(t0)P(t1|t0)P(t2|t1t0)P(t3|t2t1t0) …0 1 0 2 1 0 3 2 1 0
P(tn|tn-1tn-2…t0)P(tn+1|tntn-1…t0)= P(t0)P(t1|t0)P(t2|t1) … P(tn|tn-1)P(tn+1|tn)
= P(ti|ti-1) Bigram Assumption∏N+1
i = 0

Argmax computation (2/2)P(W|T) = P(w0|t0-tn+1)P(w1|w0t0-tn+1)P(w2|w1w0t0-tn+1) …
P(wn|w0-wn-1t0-tn+1)P(wn+1|w0-wnt0-tn+1)
Assumption: A word is determined completely by its tag. This is inspired by speech recognition
= P(w |t )P(w |t ) P(w |t )= P(wo|to)P(w1|t1) … P(wn+1|tn+1)
= P(wi|ti)∏n+1
i = 0
= P(wi|ti) (Lexical Probability Assumption)∏n+1
i = 1
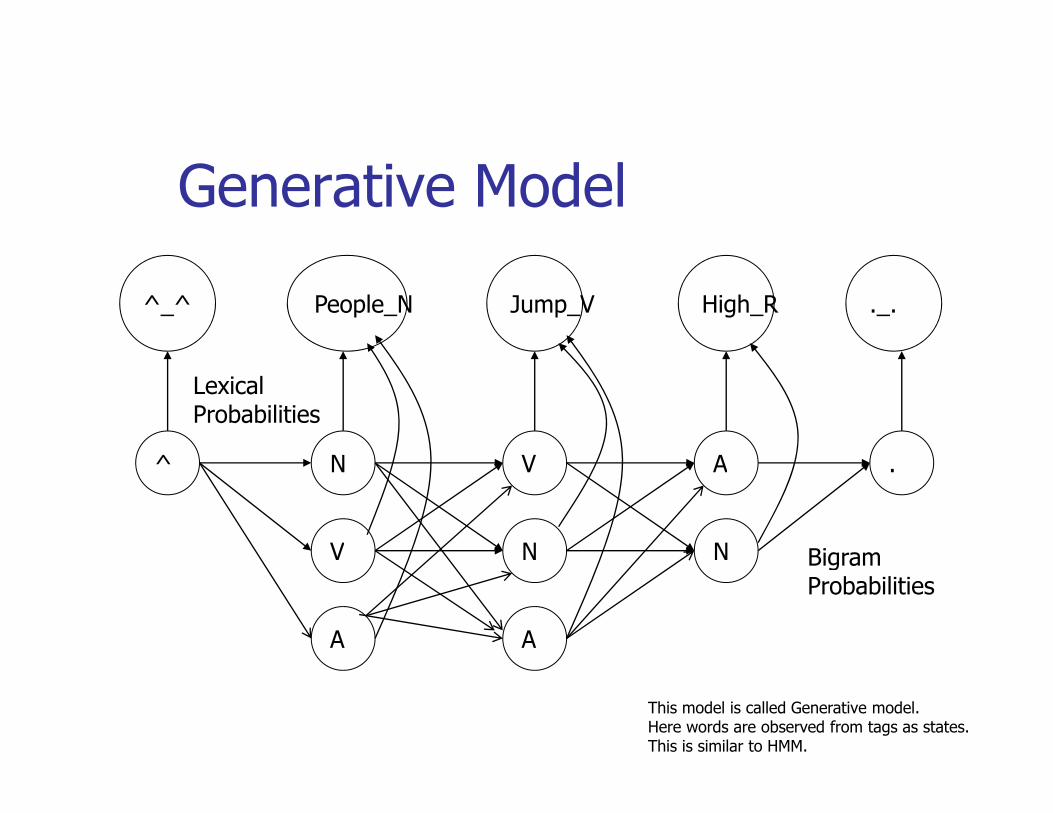
Generative Model
^_^ People_N Jump_V High_R ._.
^ N V A
Lexical Probabilities
^ N
V
V
N
A
N
.
BigramBigramProbabilities
AA
This model is called Generative model. Here words are observed from tags as states.This is similar to HMM.

Observations leading to why probability is neededprobability is needed
Many intelligence tasks are sequence y g qlabeling tasksTasks carried out in layersTasks carried out in layersWithin a layer, there are limited windows of informationwindows of informationThis naturally calls for strategies for dealing with uncertaintydealing with uncertaintyProbability and Markov process give a way

“I went with my friend to the bank to withdraw some money but was disappointed to find itsome money, but was disappointed to find it
closed”
POS
Sense
Bank (N/V) closed (V/ adj)
Bank (financial institution) withdraw (take away)Sense
Pronoun drop
Bank (financial institution) withdraw (take away)
But I/friend/money/bank was disappointed
SCOPE
Co referencing
With my friend
It > bankCo-referencing It -> bank

HMMHMM
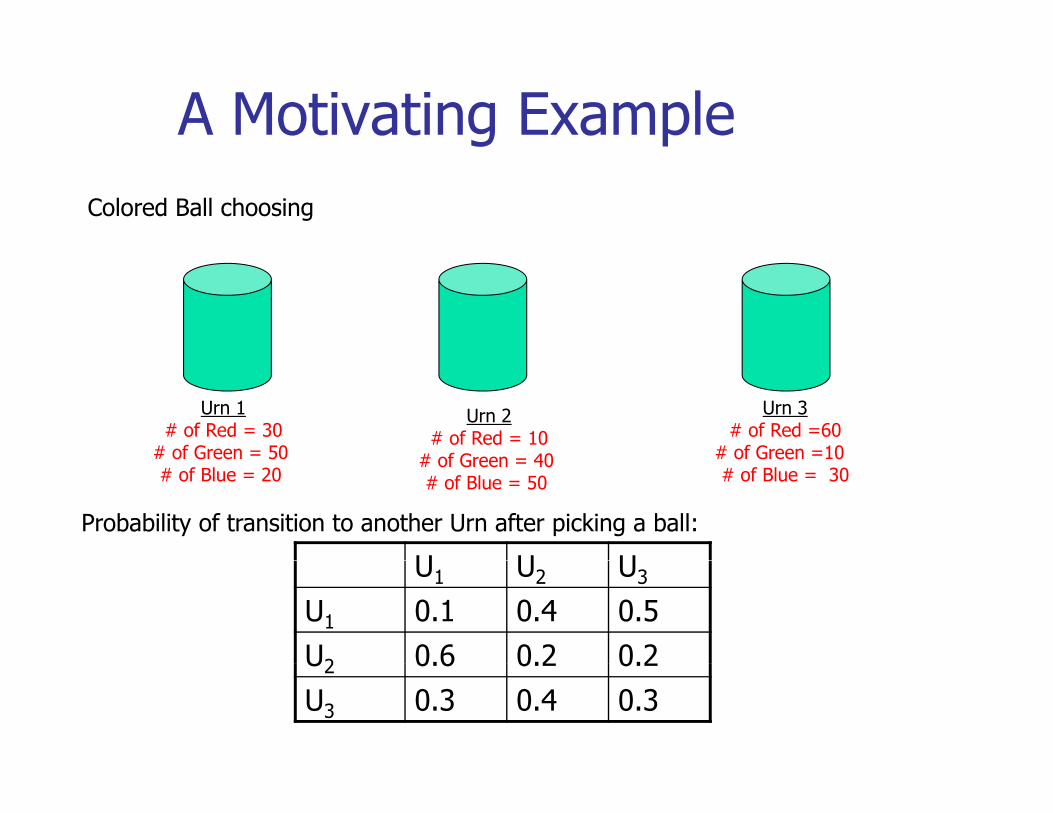
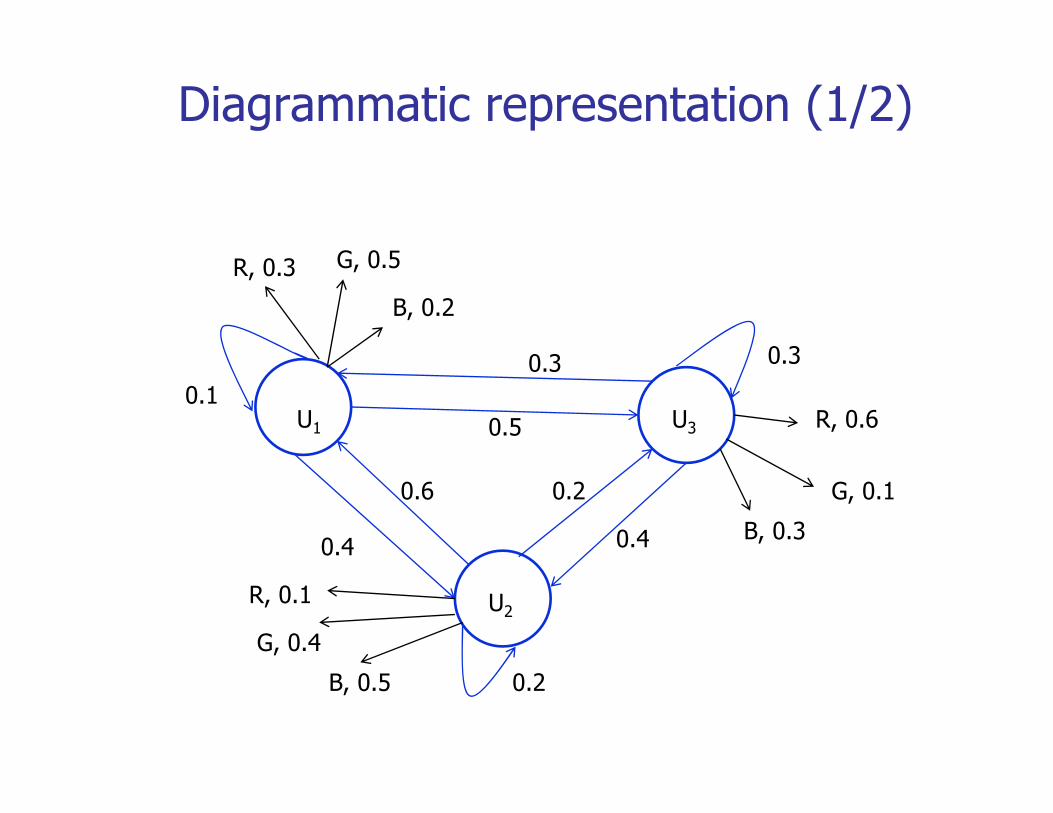
A Motivating ExampleColored Ball choosing
Urn 1# of Red = 30
# of Green = 50
Urn 3# of Red =60
# of Green =10
Urn 2# of Red = 10
# of Green 40# of Green 50 # of Blue = 20
# of Green 10 # of Blue = 30
# of Green = 40 # of Blue = 50
U U UProbability of transition to another Urn after picking a ball:
U1 U2 U3
U1 0.1 0.4 0.5U2 0.6 0.2 0.2U2 0.6 0.2 0.2U3 0.3 0.4 0.3
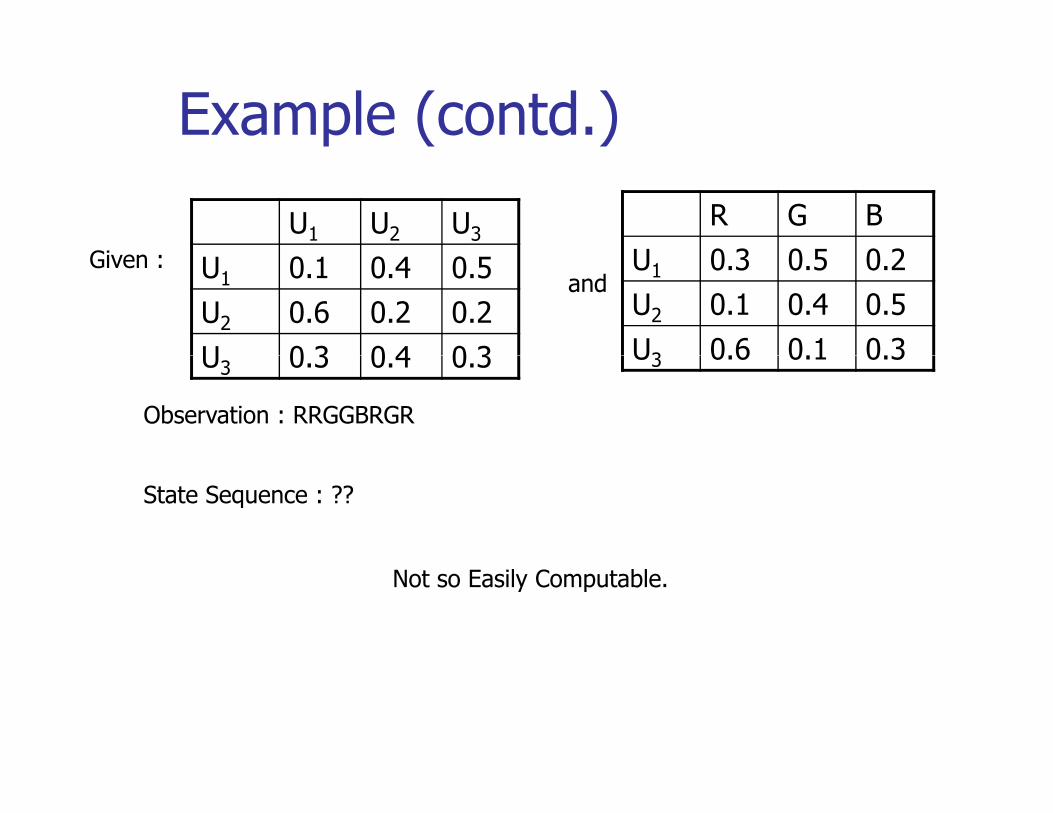
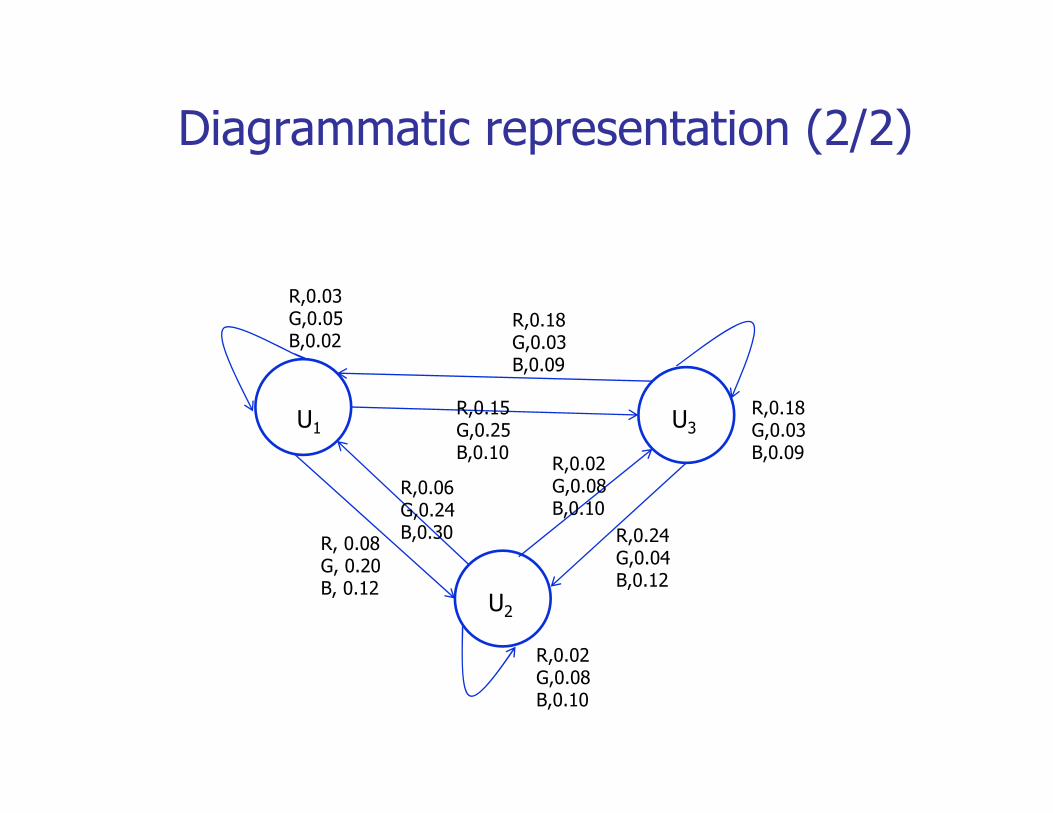
Example (contd.)
U1 U2 U3Gi
R G BU 0 3 0 5 0 2U1 0.1 0.4 0.5
U2 0.6 0.2 0.2U 0 3 0 4 0 3
Given :and
U1 0.3 0.5 0.2U2 0.1 0.4 0.5U3 0.6 0.1 0.3U3 0.3 0.4 0.3
Observation : RRGGBRGR
U3 0.6 0.1 0.3
State Sequence : ??
Not so Easily Computable.
Diagrammatic representation (1/2)
G 0 5
0 3 0 3
B, 0.2
R, 0.3 G, 0.5
U1 U3
0.10.5
0.3 0.3
R, 0.6
0.2
0.4
0.6
0.4
G, 0.1
B, 0.3
U2R, 0.1
G, 0.4
0.2B, 0.5
Diagrammatic representation (2/2)g p ( / )
R,0.18G,0.03
R,0.03G,0.05B,0.02
U1 U3
R 0 02
R,0.15G,0.25B,0.10
B,0.09
R,0.18G,0.03B,0.09R,0.02
G,0.08B,0.10
R,0.24G 0 04
R,0.06G,0.24B,0.30R, 0.08
G 0 20
B,0.10 B,0.09
U2
G,0.04B,0.12
G, 0.20B, 0.12
R,0.02,G,0.08B,0.10
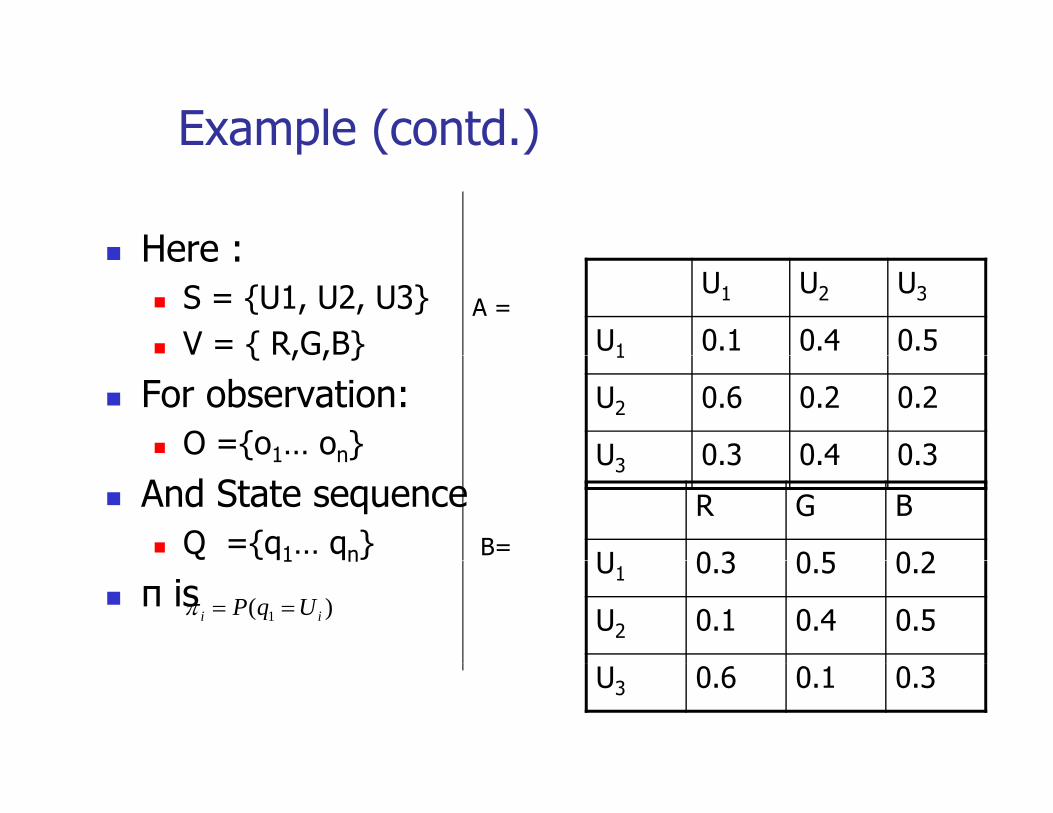
Example (contd.)p ( )
Here :Here : S = {U1, U2, U3}V = { R,G,B}
U1 U2 U3
U1 0.1 0.4 0.5A =
{ , , }
For observation:O ={o1… on}
1
U2 0.6 0.2 0.2
U3 0 3 0 4 0 3{ 1 n}
And State sequenceQ ={q1… qn}
U3 0.3 0.4 0.3
R G B
U 0 3 0 5 0 2B=1 n
π is U1 0.3 0.5 0.2
U2 0.1 0.4 0.5)( 1 ii UqP ==π
U3 0.6 0.1 0.3

Observations and statesO1 O2 O3 O4 O5 O6 O7 O8
O S G G GOBS: R R G G B R G RState: S1 S2 S3 S4 S5 S6 S7 S8
Si = U1/U2/U3; A particular statei 1/ 2/ 3; pS: State sequenceO: Observation sequenceO: Observation sequenceS* = “best” possible state (urn) sequenceGoal: Maximize P(S*|O) by choosing “best” SGoal: Maximize P(S |O) by choosing best S

Goal
Maximize P(S|O) where S is the State Sequence and O is the ObservationSequence and O is the Observation Sequence
))|((maxarg* OSPS S=

False StartO1 O2 O3 O4 O5 O6 O7 O8
OBS: R R G G B R G RSt t S S S S S S S S
)|()|()|()|()|()|()|(
718213121
8181
OSSPOSSPOSSPOSPOSPOSPOSP −−=
State: S1 S2 S3 S4 S5 S6 S7 S8
),|()...,|().,|().|()|( 718213121 OSSPOSSPOSSPOSPOSP −−=
By Markov Assumption (a state y p (depends only on the previous state)
)|()|()|()|()|( 7823121 OSSPOSSPOSSPOSPOSP = ),|()...,|().,|().|()|( 7823121 OSSPOSSPOSSPOSPOSP =

Baye’s Theorem
)(/)|().()|( BPABPAPBAP =
P(A) -: PriorP(B|A) -: LikelihoodP(B|A) : Likelihood
)|().(maxarg)|(maxarg SOPSPOSP SS = )|().(maxarg)|(maxarg SOPSPOSP SS

State Transitions Probability
)|()...|().|().|().()()()(
718314213121
81
−−−
−
==
SSPSSPSSPSSPSPSPSPSP
)|()|()|()|()()(
By Markov Assumption (k=1)
)|()...|().|().|().()( 783423121 SSPSSPSSPSSPSPSP =

Observation Sequence probability
),|()...,|().,|().|()|( 81718812138112811 −−−−−−= SOOPSOOPSOOPSOPSOP
Assumption that ball drawn depends onlyAssumption that ball drawn depends only on the Urn chosen
)|()|()|()|()|( SOPSOPSOPSOPSOP )|()...|().|().|()|( 88332211 SOPSOPSOPSOPSOP =
)|().()|( SOPSPOSP =
)|()...|().|().|().|()...|().|().|().()|(
88332211
783423121
SOPSOPSOPSOPSSPSSPSSPSSPSPOSP =
)|()|()|()|(

Grouping termsO0 O1 O2 O3 O4 O5 O6 O7 O8
Obs: ε R R G G B R G RS S S S S S S S S S
P(S).P(O|S)= [P(O |S ) P(S |S )]
We introduce the statesS d S i i i l
State: S0 S1 S2 S3 S4 S5 S6 S7 S8 S9
= [P(O0|S0).P(S1|S0)].[P(O1|S1). P(S2|S1)].[P(O2|S2). P(S3|S2)].
S0 and S9 as initial and final states respectively.
[P(O3|S3).P(S4|S3)]. [P(O4|S4).P(S5|S4)]. [P(O5|S5).P(S6|S5)].
p yAfter S8 the next state
is S9 with probability 1 i e P(S |S ) 1
[ ( 5| 5) ( 6| 5)][P(O6|S6).P(S7|S6)]. [P(O7|S7).P(S8|S7)].[P(O |S ) P(S |S )]
1, i.e., P(S9|S8)=1O0 is ε-transition
[P(O8|S8).P(S9|S8)].
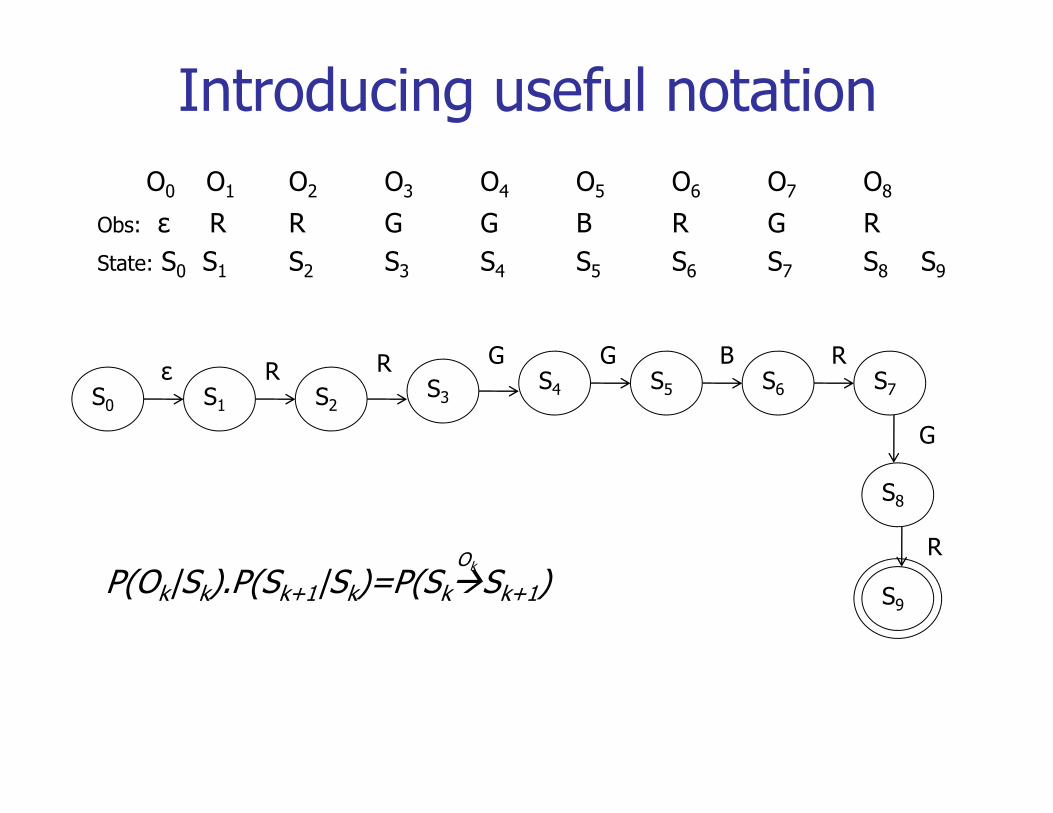
Introducing useful notationO0 O1 O2 O3 O4 O5 O6 O7 O8
Obs: ε R R G G B R G RS S S S S S S S S SState: S0 S1 S2 S3 S4 S5 S6 S7 S8 S9
R G G B R
S0 S1S7S2
S3S4 S5 S6
ε RRG G B R
G
S8
RO
S9P(Ok|Sk).P(Sk+1|Sk)=P(Sk Sk+1)
Ok
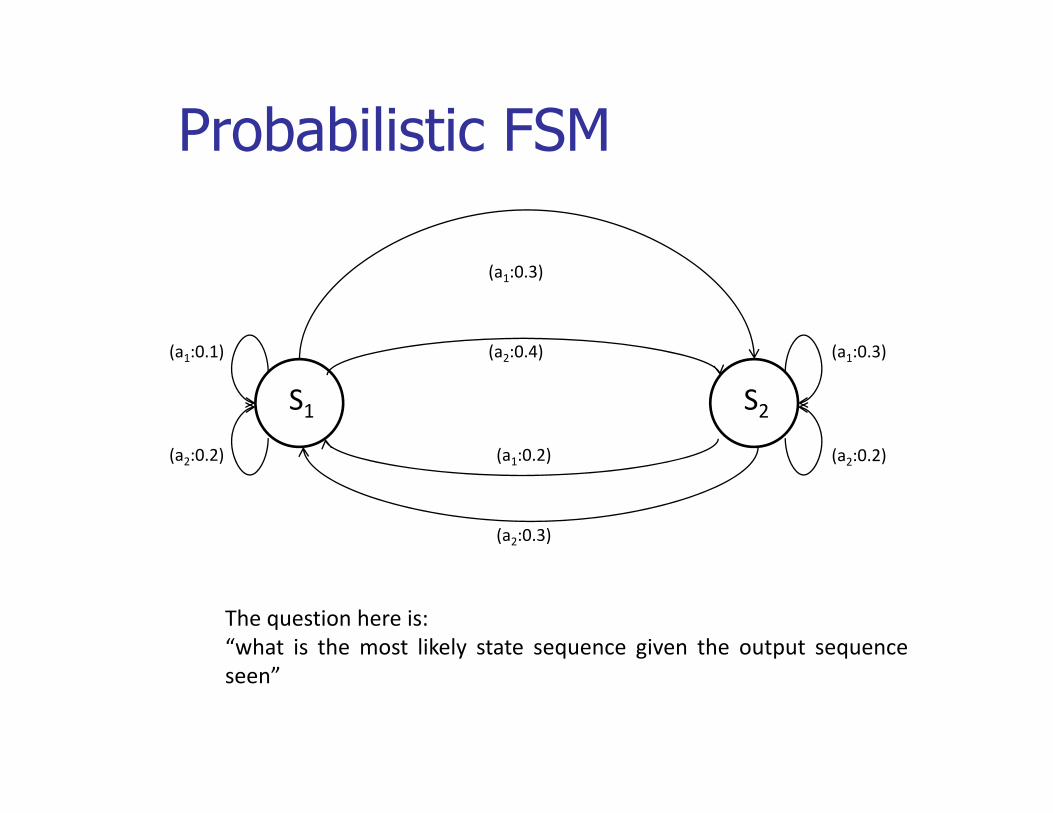
Probabilistic FSMProbabilistic FSM
(a1:0.3)
(a2:0.4)(a1:0.1) (a1:0.3)(a2:0.4)
(a1:0 2)
(a1:0.1)
(a2:0 2)
(a1:0.3)
(a2:0 2)
S1 S2(a1:0.2)
(a2:0.3)
(a2:0.2) (a2:0.2)
The question here is:“what is the most likely state sequence given the output sequenceseen”
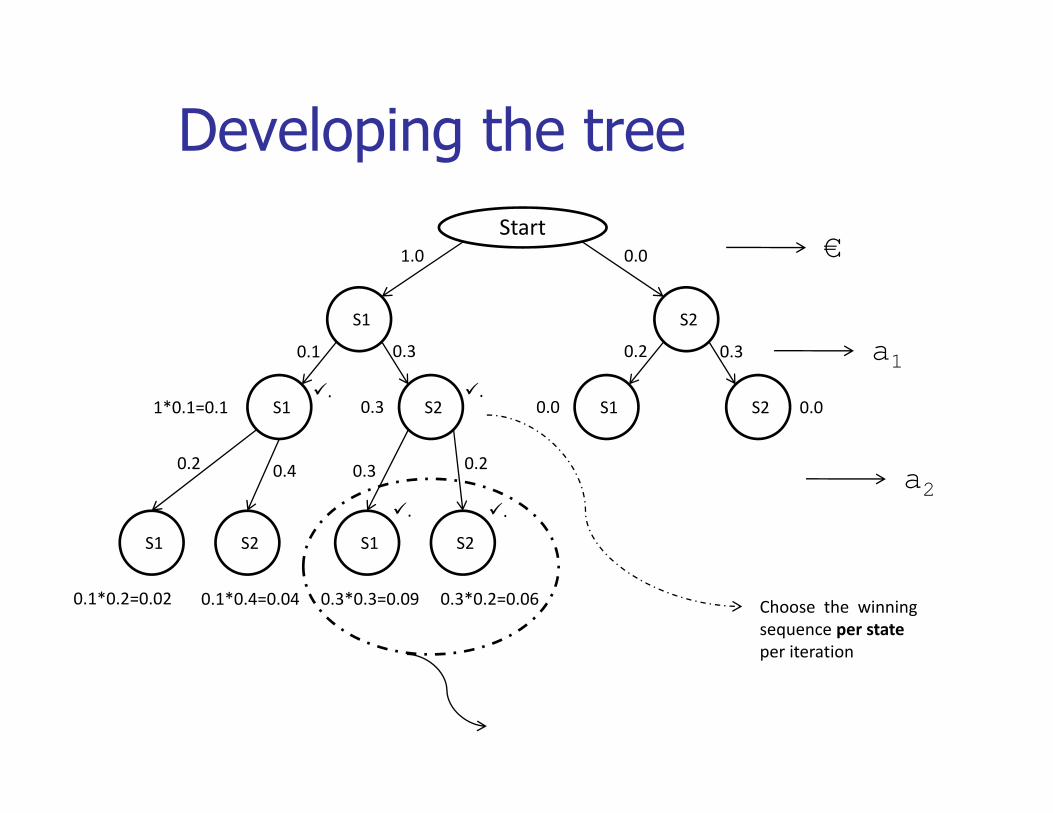
Developing the treeDeveloping the treeStart
1 0 0 0 €
S1 S2
1.0 0.0
0.1 0.3 0.2 0.3
€
a1
S1 S2 S1 S2
0.1 0.3 0.2 0.3
1*0.1=0.1 0.3 0.0 0.0. .
a1
0 2 0 2
S1 S2 S1 S2
. .
a20.2 0.4 0.3 0.2
0.1*0.2=0.02 0.1*0.4=0.04 0.3*0.3=0.09 0.3*0.2=0.06 Choose the winning sequence per stateper iteration
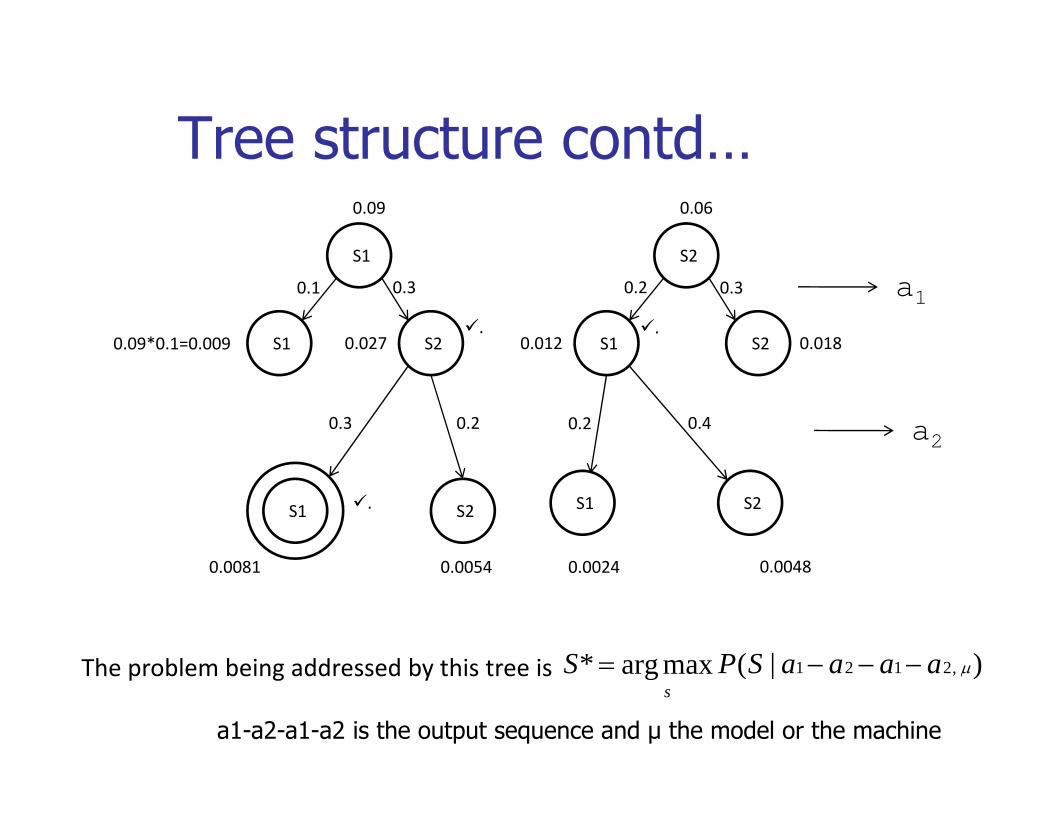
Tree structure contdTree structure contd…
S1 S2
0.09 0.06
S1 S2
S1 S2 S1 S2
0.1 0.3 0.2 0.3
0.027 0.012..
0.09*0.1=0.009 0.018
a1
0.3 0.2 0.40.2 a2
S1 S2 S2
0 00 8
S1.
0.0081 0.0054 0.00480.0024
Th bl b i dd d b thi t i )|(maxarg* 2121 aaaaSPS =The problem being addressed by this tree is )|(maxarg* ,2121 μaaaaSPSs
−−−=
a1-a2-a1-a2 is the output sequence and μ the model or the machine
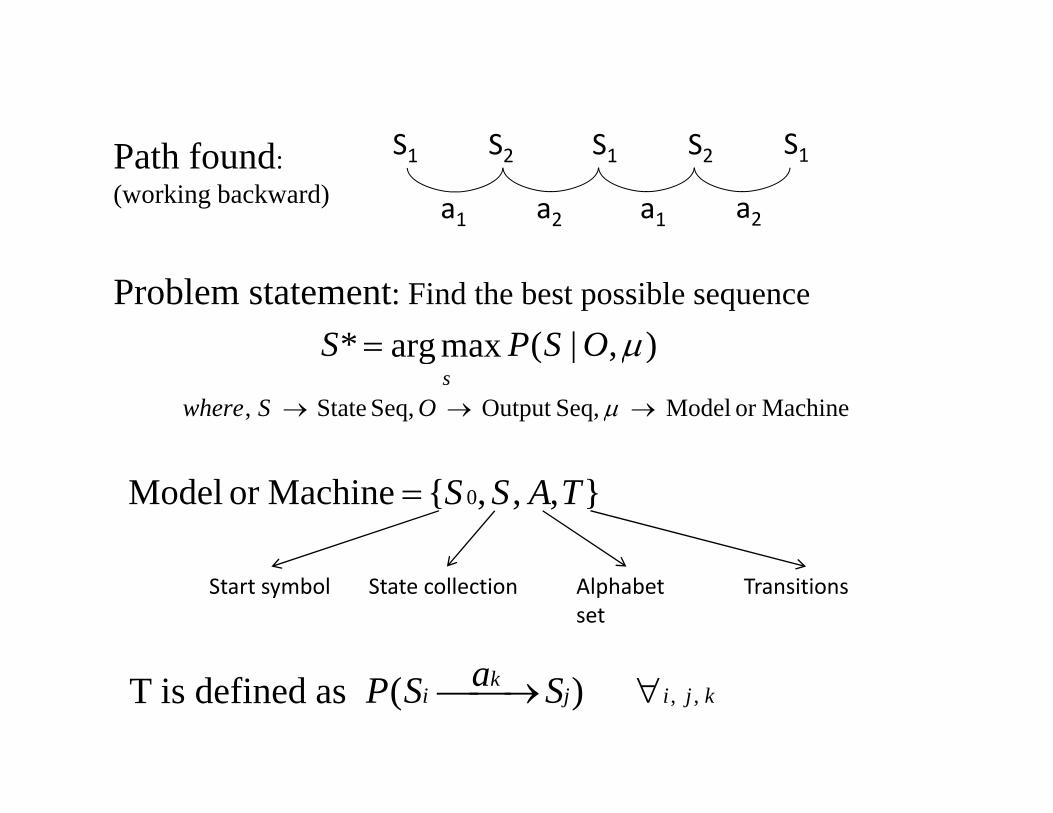
P th f d S1 S2 S1 S2 S1Path found: (working backward)
S1 S2 S1 S2 S1
a2a1a1 a2
Problem statement: Find the best possible sequence ),|(maxarg* μOSPS = ),|(maxarg μOSPS
sMachineor Model Seq,Output Seq, State, →→→ μOSwhere
},,,{Machineor Model 0 TASS=
Start symbol State collection Alphabet set
Transitions
T is defined as kjijk
i SaSP ,, )( ∀⎯→⎯

POS: TagsetPOS: Tagset
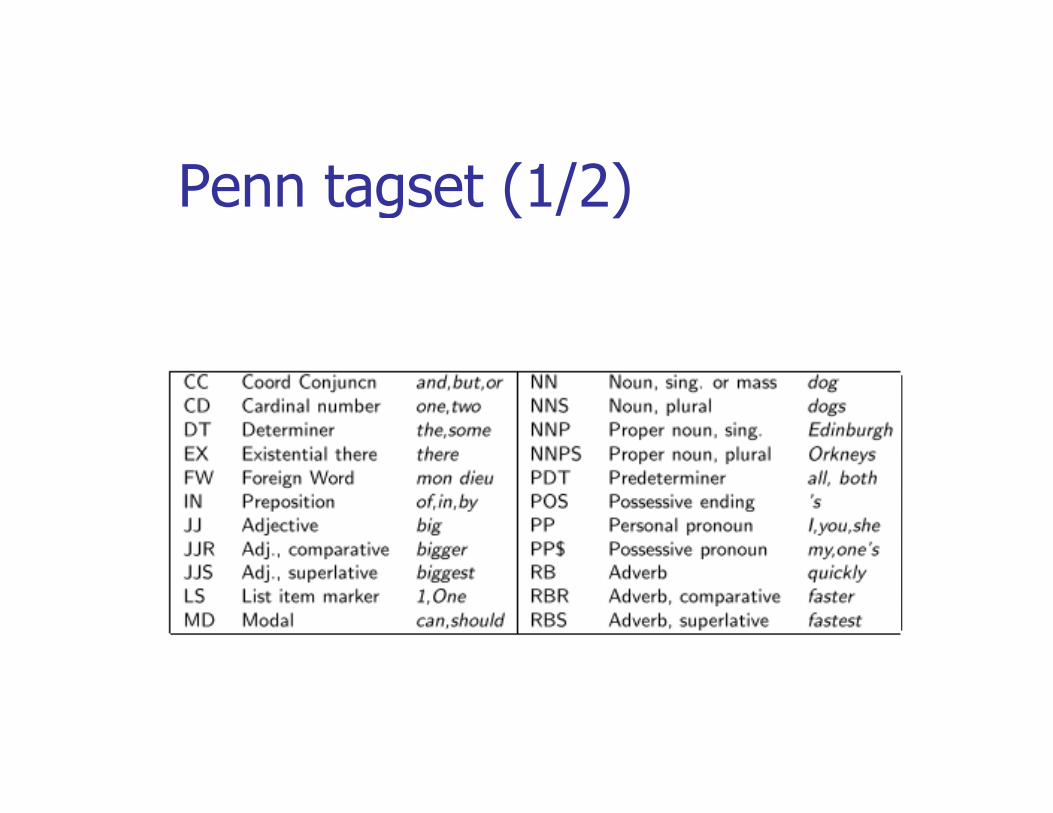
Penn tagset (1/2)
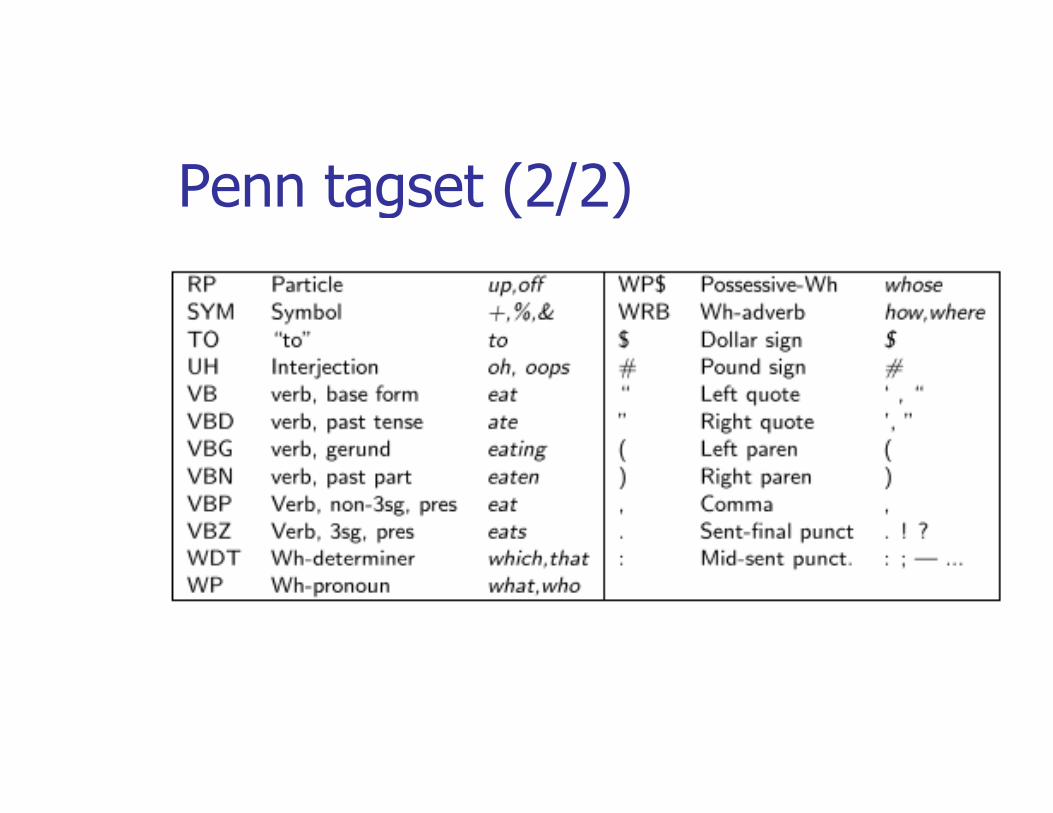
Penn tagset (2/2)

Indian Language Tagset: Noun
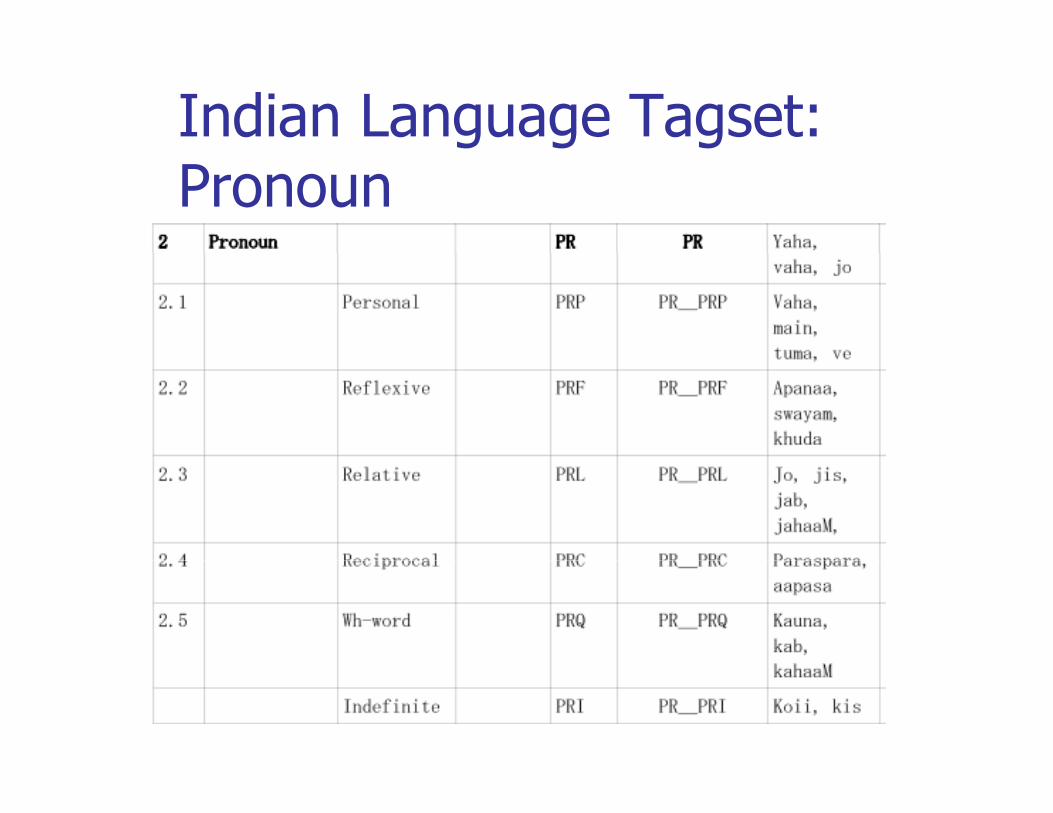
Indian Language Tagset: Pronoun

Indian Language Tagset: Quantifier
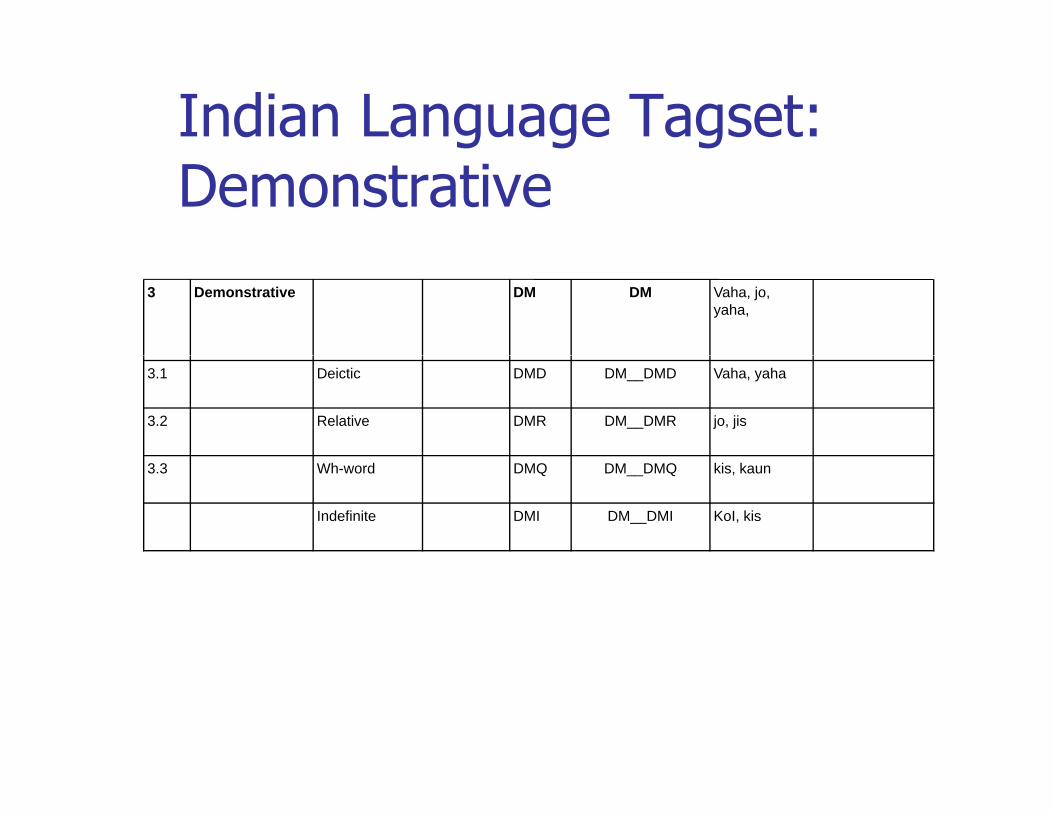
Indian Language Tagset: Demonstrative
3 Demonstrative DM DM Vaha, jo, yaha,
3.1 Deictic DMD DM__DMD Vaha, yaha
3.2 Relative DMR DM__DMR jo, jis
3.3 Wh-word DMQ DM__DMQ kis, kaun
Indefinite DMI DM__DMI KoI, kis
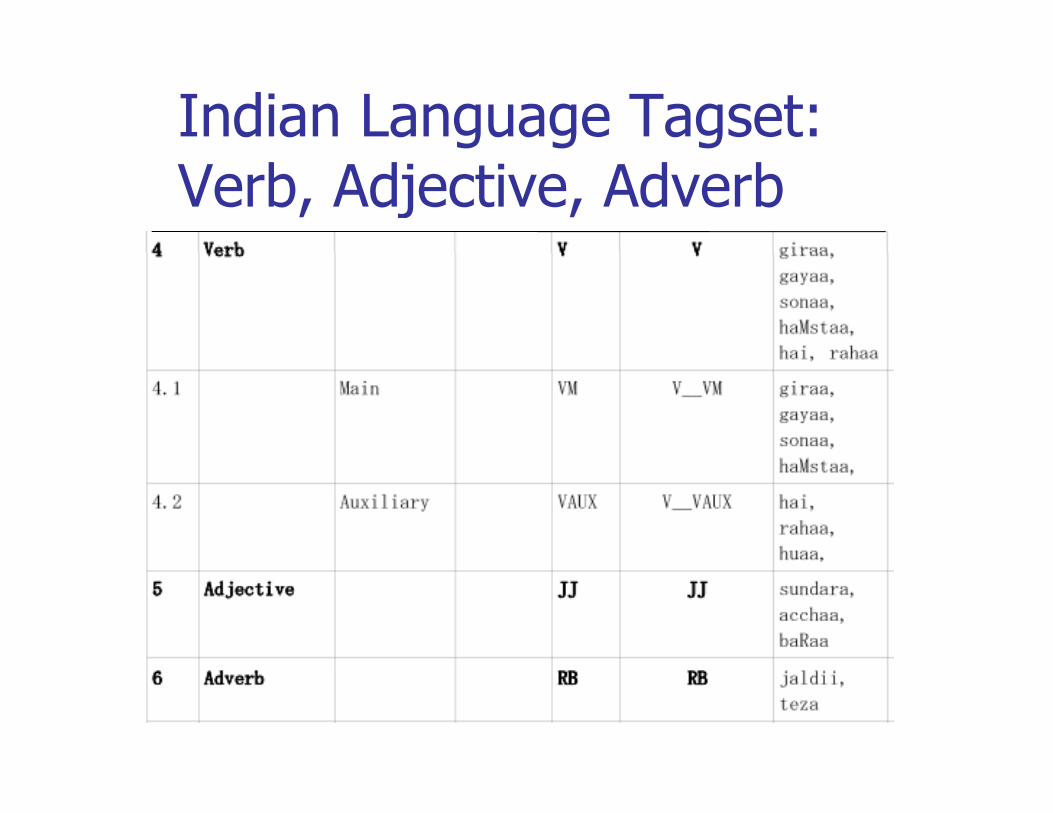
Indian Language Tagset: Verb, Adjective, Adverb
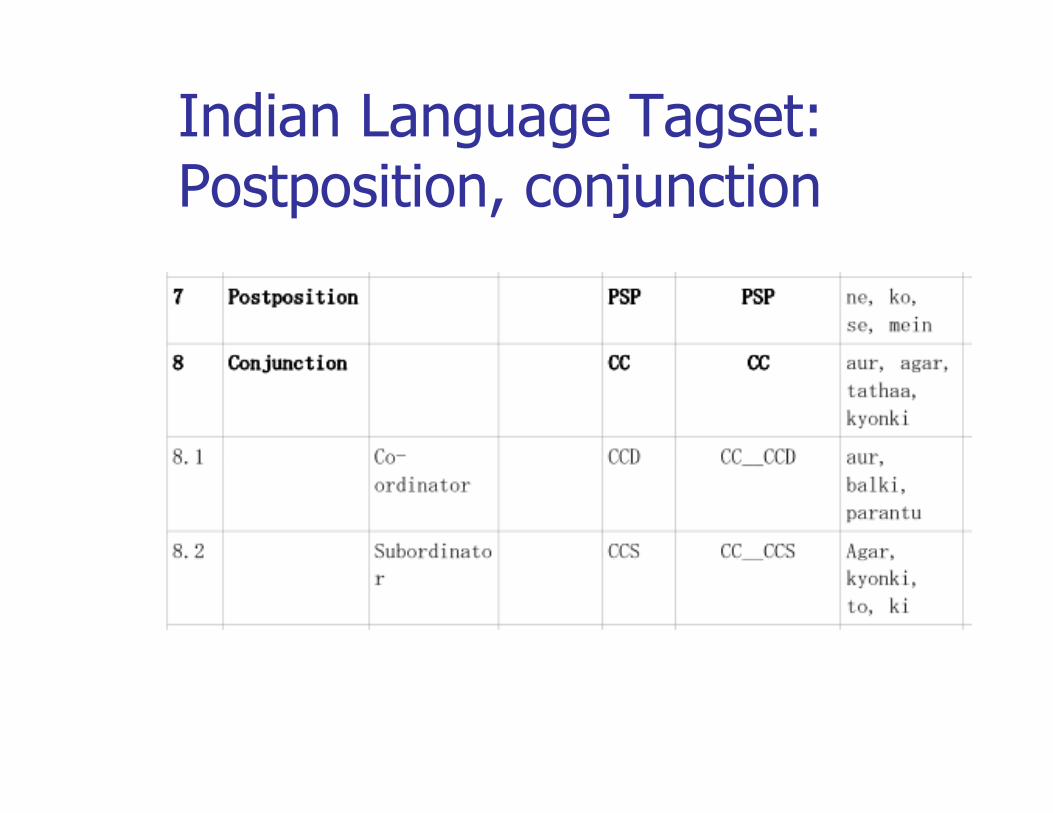
Indian Language Tagset: Postposition, conjunction
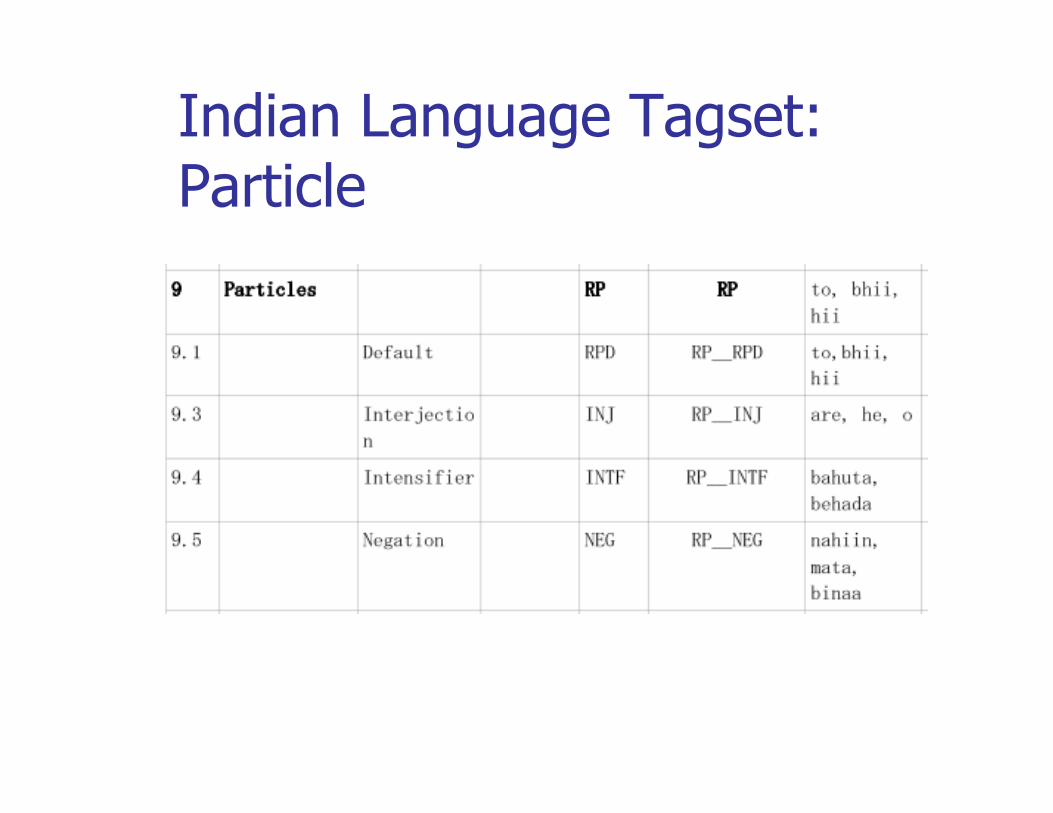
Indian Language Tagset: Particle

Indian Language Tagset: Residuals

Challenge of POS taggingChallenge of POS tagging
Example from Indian Language

Tagging of jo, vaha, kaun and their inflected forms in Hindiinflected forms in Hindi
and their equivalents in multiple languagestheir equivalents in multiple languages

DEM and PRON labels
Jo_DEM ladakaa kal aayaa thaa, vahacricket acchhaa khel letaa haicricket acchhaa khel letaa hai
Jo PRON kal aayaa thaa vaha cricketJo_PRON kal aayaa thaa, vaha cricket acchhaa khel letaa hai

Disambiguation rule-1
If Jo is followed by nounJo is followed by noun
ThenDEM
ElElse……

False Negative
When there is arbitrary amount of text between the jo and the nounbetween the jo and the nounJo_??? bhaagtaa huaa, haftaa huaa, rotaa huaa chennai academy arotaa huaa, chennai academy a koching lenevaalaa ladakaa kal aayaathaa vaha cricket acchhaa khel letaathaa, vaha cricket acchhaa khel letaahai

False Positive
Jo_DEM (wrong!) duniyadariisamajhkar chaltaa hai, …samajhkar chaltaa hai, …Jo_DEM/PRON? manushya manushyoMke biich ristoM naatoM ko samajhkarke biich ristoM naatoM ko samajhkarchaltaa hai, … (ambiguous)

False Positive for Bengali
Je_DEM (wrong!) bhaalobaasaapaay, sei bhaalobaasaa dite paarepaay, sei bhaalobaasaa dite paare(one who gets love can give love)Je DEM (right!) bhaalobaasa tumiJe_DEM (right!) bhaalobaasa tumikalpanaa korchho, taa e jagat e sambhab naysambhab nay(the love that you imagine exits, is
bl h ld)impossible in this world)

Will fail
In the similar situation forJi ji hJis, jin, vaha, us, un
All these forms add to corpusAll these forms add to corpus count

Disambiguation rule-2
If Jo is oblique (attached with ne,Jo is oblique (attached with ne, ko, se etc. attached)
ThenThen It is PRON
ElElse<other tests>

Will fail (false positive)( p )In case of languages that demand agreement between jo-form and the nounagreement between jo form and the noun it qualifiesE.g. SanskritgYasya_PRON (wrong!) baalakasyaaananam drshtyaa… (jis ladake kaa muhadekhkar)Yasya_PRON (wrong!) kamaniyasyab l k d hbaalakasya aananam drshtyaa…

Will also fail forRules that depend on the whether the noun following jo/vaha/kaun or its form isnoun following jo/vaha/kaun or its form is oblique or notBecause the case marker can be far fromBecause the case marker can be far from the noun<vaha or its form> ladakii jise piliya kii<vaha or its form> ladakii jise piliya kiibimaarii ho gayiii thii ko …N d di i lNeeds discussions across languages

DEM vs PRON cannot beDEM vs. PRON cannot be disambiguated IN GENERALIN GENERAL
At the level of the POS taggeri ei.e.
Cannot assume parsingCannot assume semanticsCannot assume semantics





























