Embed Size (px)
Citation preview

1
NamingPart IICS403/534
Distributed SystemsErkay Savas
Sabanci University

2
Overview• Naming versus locating objects• Simple solutions• Home-based approaches• Hierarchical approaches• Removing unreferenced objects

3
Naming & Locating Entities (1)• Location service: aimed at providing the addresses of
the current locations of moving entities• Assumption: Entities are mobile, so that their current
address may change frequently• Naming service: aimed at providing the contents of
nodes in a name space, given a name. • Assumption: Node contents at global and administrational
levels are relatively stable.• Observation: As long as an entity moves within
managerial layer, the update can be effectively done considering that the global and administrational layers remain the same.

4
Naming & Locating Entities (2)• What happens if ftp.cs.vu.nl (currently in soling.cs.vu.nl) were to move to a machine named blum.sabanciuniv.edu which is in completely a different domain?
• Record the address of the new machine in the DNS database for cs.vu.nl?
• Use symbolic link (name of the new machine)?• What happens if the ftp server moves again.• Result: DNS cannot cope well with mobile entities since it
provides a direct mapping between human-friendly names and the addresses of entities.
• Solution: Use identifiers and Name service + Location service together
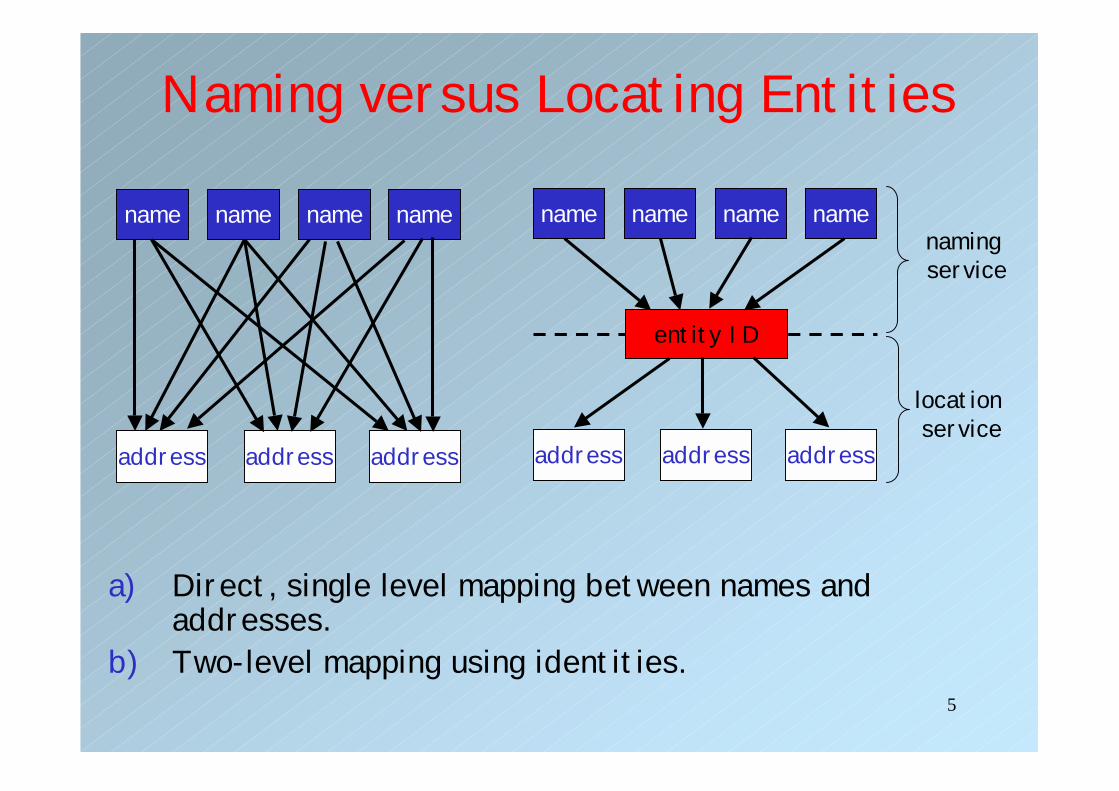
5
Naming versus Locating Entities
a) Direct, single level mapping between names and addresses.
b) Two-level mapping using identities.
name
address address address
name name name name name name name
entity ID
address address address
naming service
location service

6
Location Service: Simple Solutions• Broadcasting and Multicasting:
– Simply broadcast the ID of an entity, requesting the entity to return its current address
– Can never scale beyond LAN (Think of ARP)– Requires all entities to listen to all incoming requests– Ethernet networks support data-link level multicasting
directly in hardware• Forwarding Pointers:
– Each time an entity moves, it leaves behind a reference (pointer) to its new location
– Locating an entity can be made transparently to the user in the presence of pointer by following the chain of pointers
– Update a reference to an entity as soon as present location has been found

7
Forwarding Pointers• Drawbacks:
1. Chains can get too long2. All intermediate locations must maintain their part of
the chain of reference3. Long chains are not fault tolerant. Broken links �
lost entity
• Example: SSP Chains for mobile objects– SSP (Stub-Scion Pairs)– Whenever an object moves from address space A to
B, it leaves behind a proxy in A, and installs a skeleton in B.
– Completely transparent
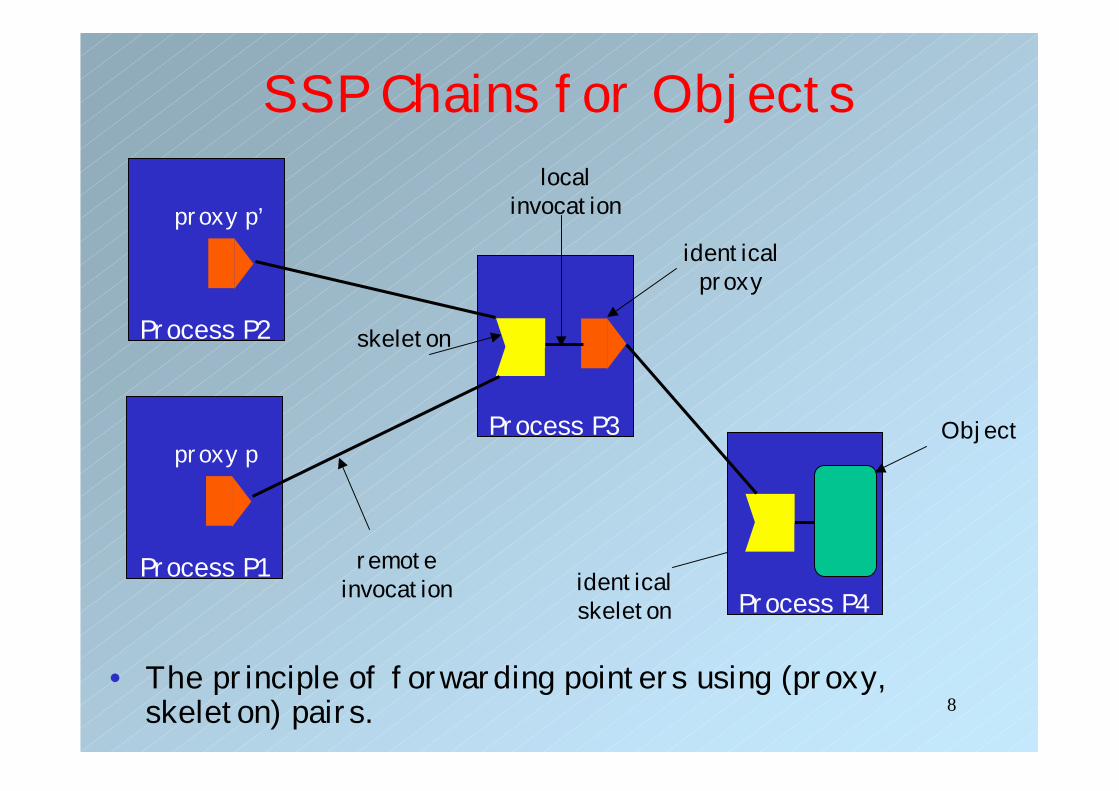
8
Process P3
SSP Chains for Objects
• The principle of forwarding pointers using (proxy, skeleton) pairs.
Process P1
proxy p
skeleton
identicalproxy
localinvocation
identicalskeleton
remoteinvocation
Process P2
proxy p’
Process P4
Object
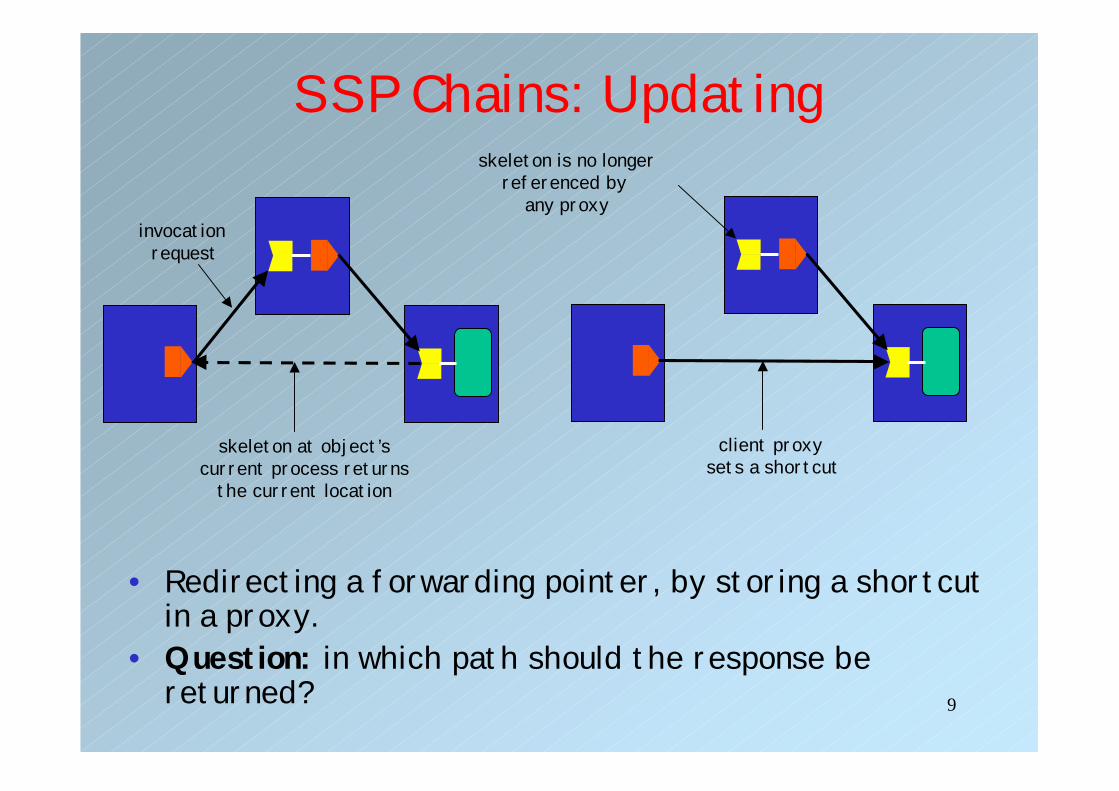
9
SSP Chains: Updating
• Redirecting a forwarding pointer, by storing a shortcut in a proxy.
• Question: in which path should the response be returned?
invocation request
skeleton at object’scurrent process returns
the current location
client proxy sets a shortcut
skeleton is no longerreferenced by
any proxy

10
Home-Based Approaches (1)• Single-tiered scheme
– home location keeps track of where the entity is– Home address is registered at a naming service– The home address can be used as a fall-back
mechanism for schemes based on forwarding pointers• Mobile IP
– Each mobile host uses a fixed IP address– All communication to that IP address is initially
directed to the mobile host’s home agent located in the home network
– Whenever a mobile host moves to another network, it asks for a temporary (care-of-) address that is registered at the home agent

11
Home-Based Approaches (2)
• The principle of Mobile IP.

12
Home-Based Approaches (3)• Two-tiered scheme:
– A client first checks if the entity is available locally– If not, connect to the home location
• Problems with home-based approaches:– The home address has to be supported as long as the
entity lives– The home address is fixed, which means an
unnecessary burden when an entity permanently moves to another location
• Question: How can we solve the “permanent move” problem?

13
Hierarchical Location Services (HLS)• Basic idea:
– A network is divided into a collection of domains, similar to the hierarchical organization of DNS
• Domains– A single top-level domain spans the entire network– Each domain can be subdivided into multiple, smaller
domains– A lowest-level domain, called leaf domain, typically
corresponds to a LAN or a cell in a mobile telephone network
– Each domain D has an associated directory node dir(D) that maintains information about the entities currently in the domain
– Root node knows about all entities
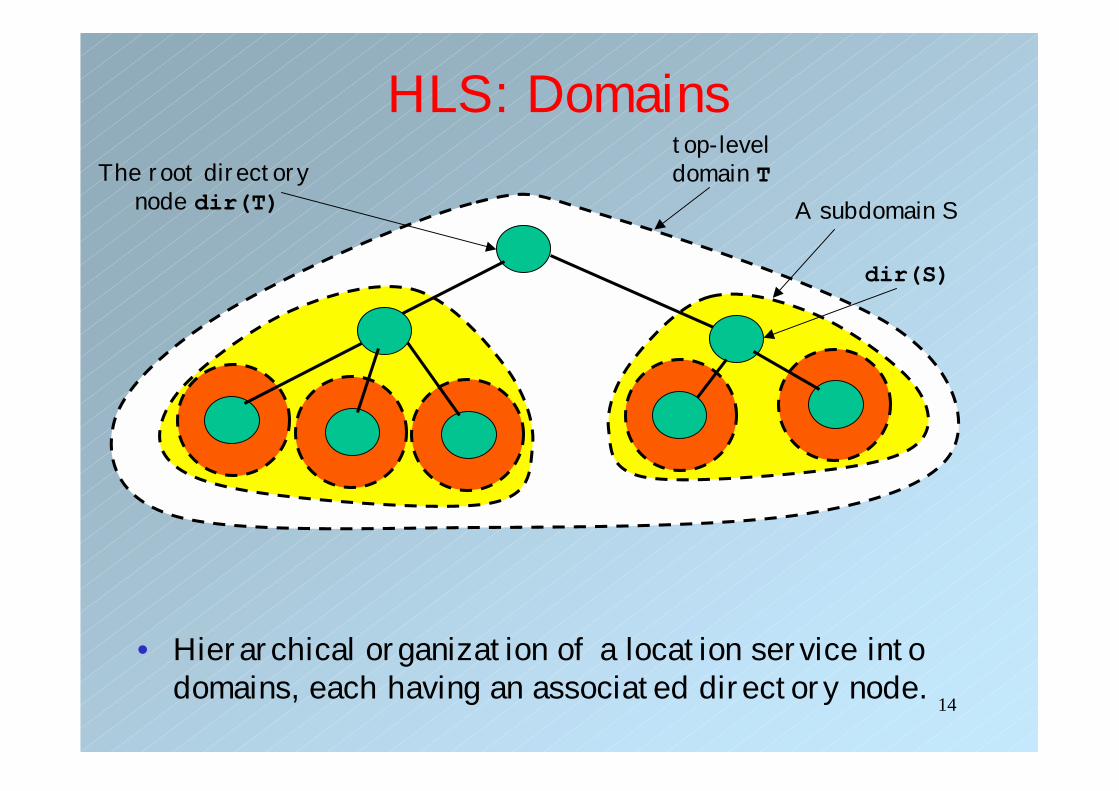
14
HLS: Domains
• Hierarchical organization of a location service into domains, each having an associated directory node.
top-leveldomain TThe root directory
node dir(T) A subdomain S
dir(S)

15
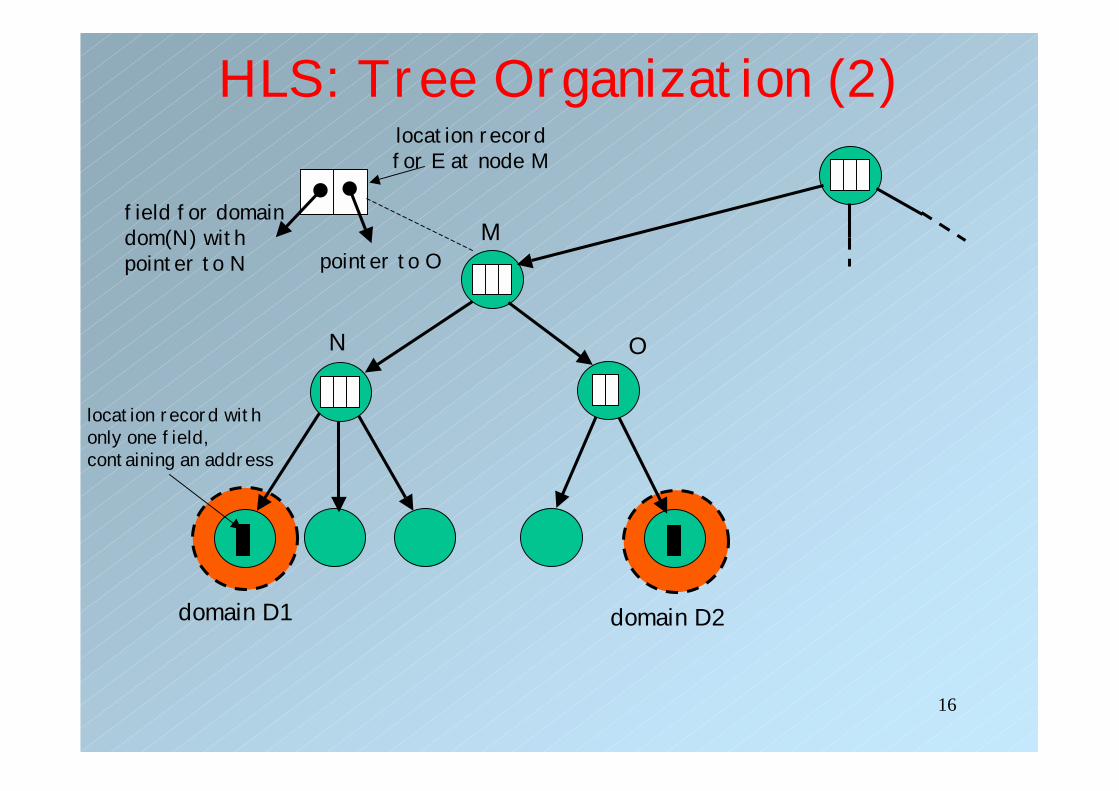
HLS: Tree Organization• Each entity, say E, currently located in a domain
D, is represented by a location record in the directory node dir(D).
• Location record in directory node of a leaf domain, D, is the current address of the entity
• A directory node dir(D’)for the next higher level domain D’ that contains D as a subdomain, will have a location record for E, containing only a pointer to dir(D).
• An entity may exist in two different domains (in form of replicas) leading to a two different address
16
domain D1 domain D2
HLS: Tree Organization (2)
location record withonly one field, containing an address
location recordfor E at node M
field for domaindom(N) with pointer to N
M
N O
pointer to O
17
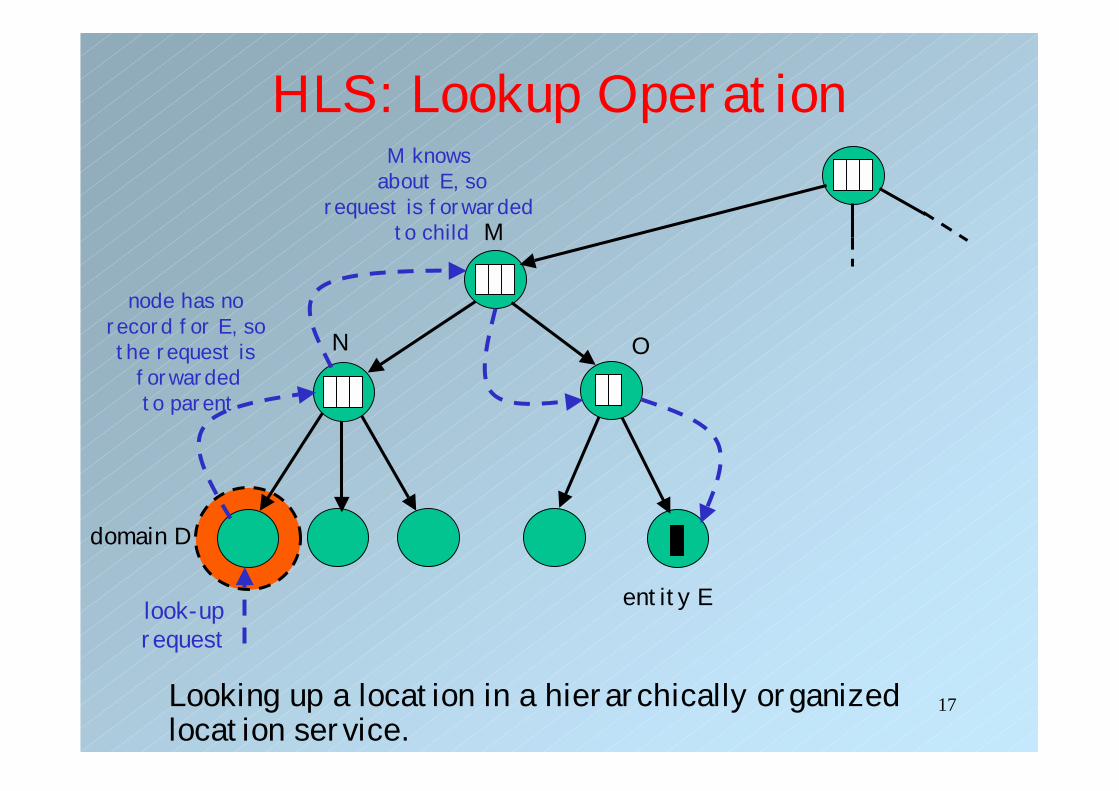
HLS: Lookup Operation
Looking up a location in a hierarchically organized location service.
domain D
M
N O
look-uprequest
node has no record for E, so the request is
forwardedto parent
M knows about E, so
request is forwarded to child
entity E
18
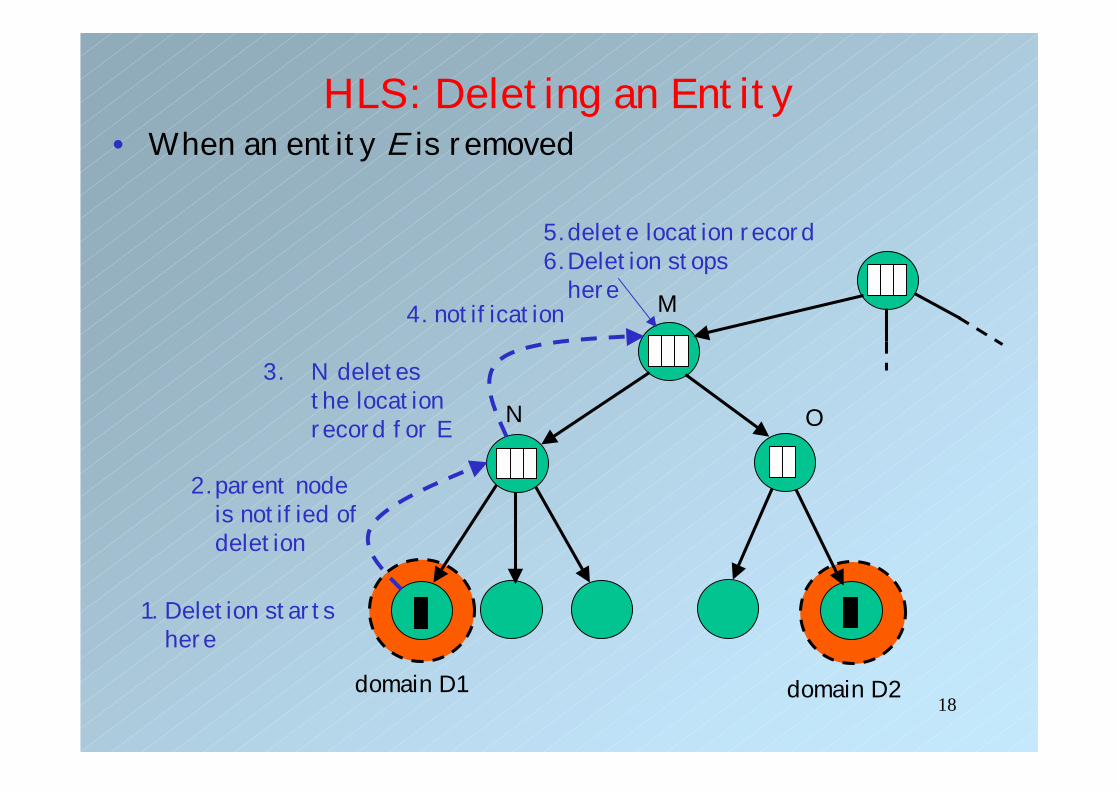
HLS: Deleting an Entity• When an entity E is removed
domain D1 domain D2
M
N O
1. Deletion starts here
2. parent node is notified ofdeletion
3. N deletesthe location record for E
4. notification
5.delete location record6.Deletion stops
here

19
Pointer Caches• It is not efficient to cache the address of an
entity, E, for future reference if the entity moves regularly
• However, if the entity move within a domain, say D, the path of pointers from the root node to dir(D) does not change.
• Then a direct reference to dir(D) is cached; this is known a pointer caching.
• Further improvement is achieved when dir(D) stores the direct address to E instead of a pointer to a child domain

20
Pointer Caches: Example• Caching a reference to a directory node
M
N
domain D
E moves regularlybetween two sub-domains
Cached pointers to node dir(D)
21
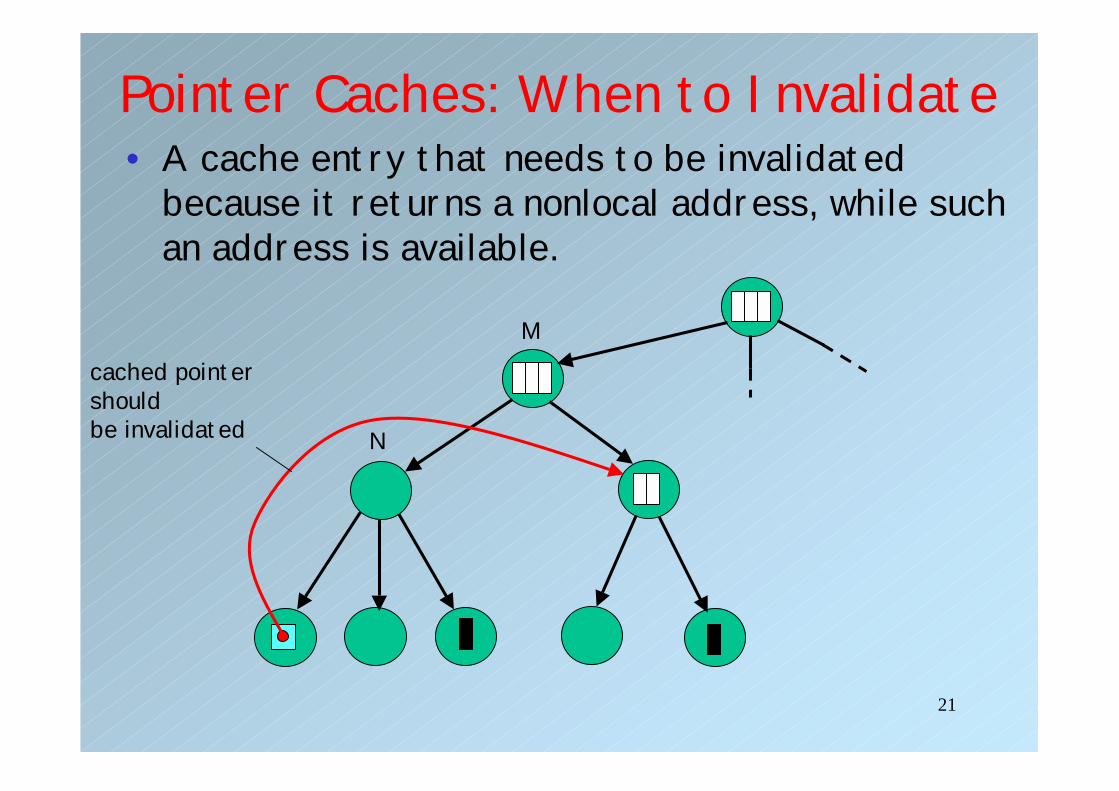
Pointer Caches: When to Invalidate• A cache entry that needs to be invalidated
because it returns a nonlocal address, while such an address is available.
M
N
cached pointer shouldbe invalidated

22
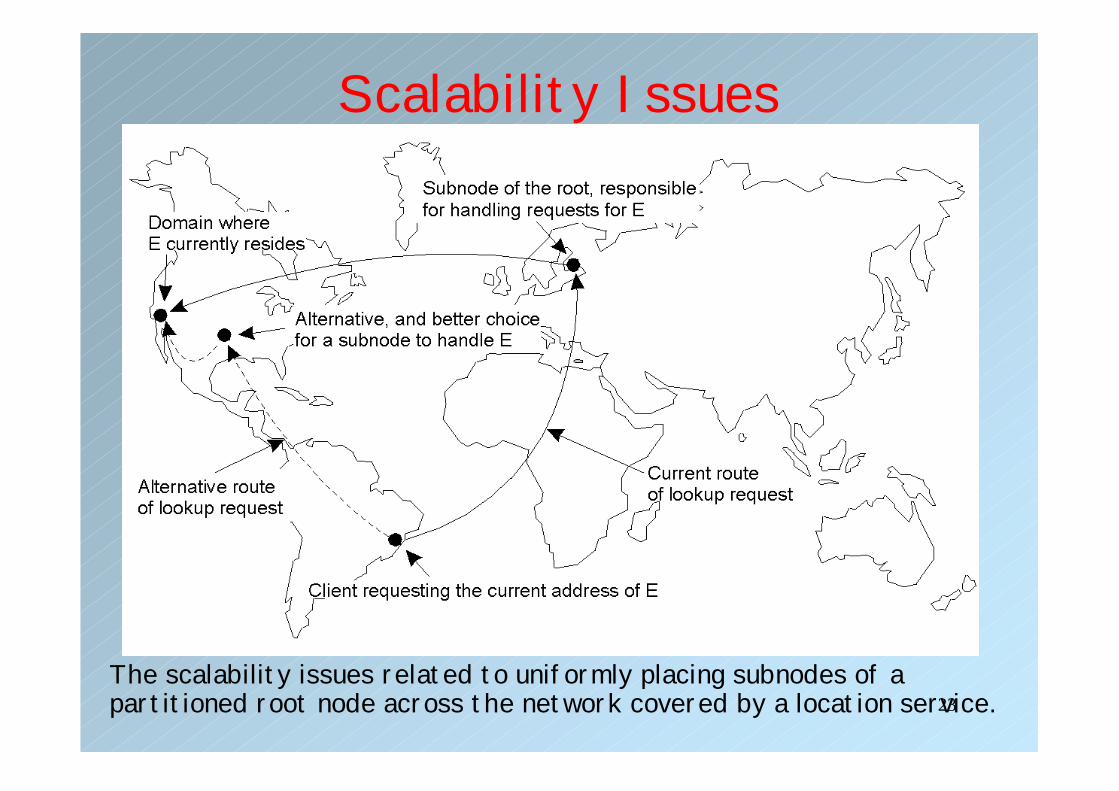
Scalability Issues• Again, we have a problem of overloading higher-
level nodes:– For example, root node has information for each entity
in the system. Too much data and many requests.– Only solution is to partition a node into a number of
subnodes and evenly assign entities to subnodes.– We can evenly distribute subnodes uniformly across
the network.– However, how to assign entities to subnodes is an open
research problem.– For example, assign an entity to a subnode of the root,
which is close to where the entity is originally created.
23
Scalability Issues
The scalability issues related to uniformly placing subnodes of a partitioned root node across the network covered by a location service.

24
Removing Unreferenced Entities• Reference counting• Reference listing• Scalability issues

25
Unreferenced Entities: Problem• Assumption: Entities (for example objects) may
exist only if it is known that they can be accessed.– If no reference to a certain entity exists, it is highly
likely that the entity consumes resources, but is never to be used in the future.
– In order to remove unreferenced entities, many distributed systems offer facilities, commonly known as distributed garbage collectors.

26
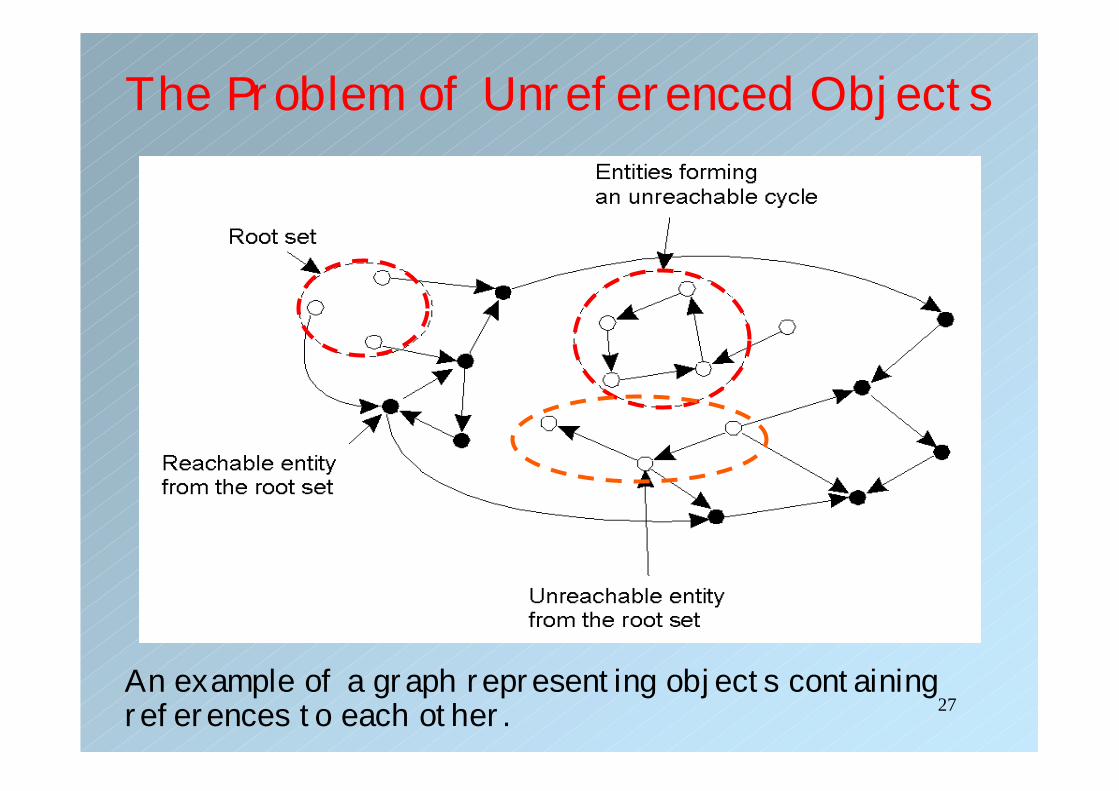
Unreferenced Objects• Assumption:
– An object can be accessed only if there is a remote reference to it.
– If there is no remote reference, the object must be removed
– On the other hand, having a remote reference does not mean that the object will ever be accessed (Think of two objects referencing each other)
• Approach:– Use a graph where each node represents an object. – An edge from node M to node N represents the fact
that M has a reference to N.– The root set needs not be referenced; they typically
represent a systemwide service, a user, and so on
27
The Problem of Unreferenced Objects
An example of a graph representing objects containing references to each other.

28
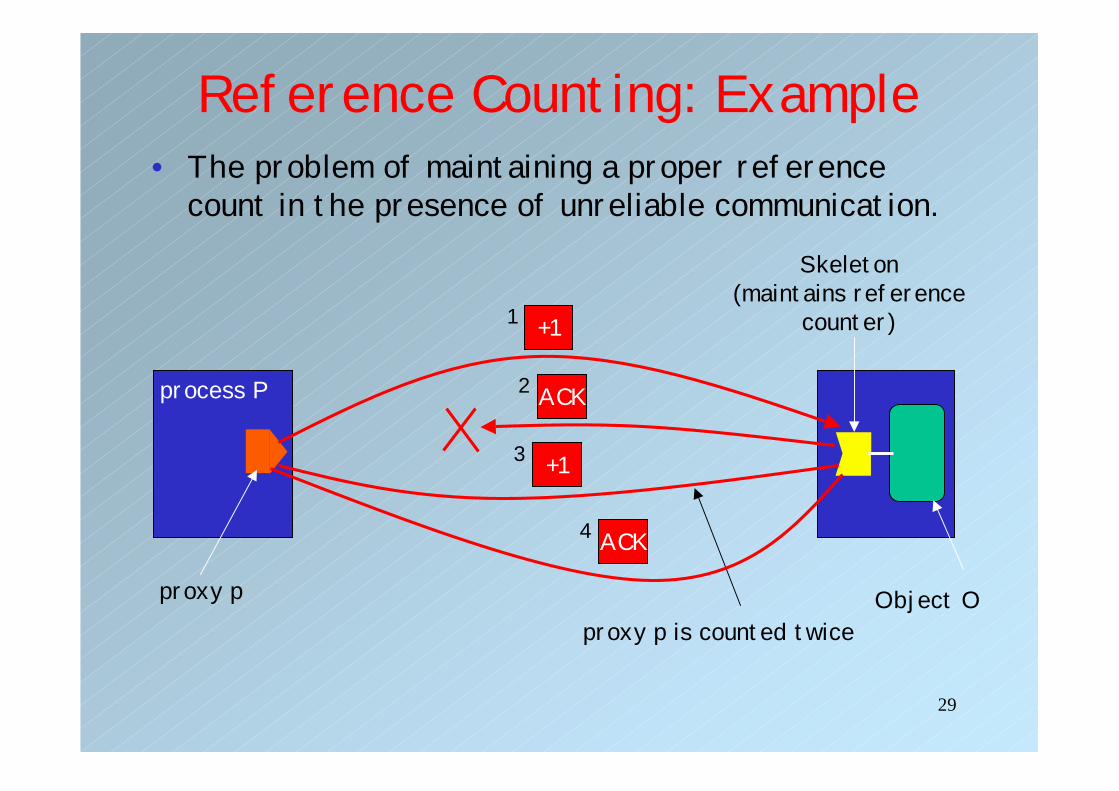
Reference Counting• Principle: Each time a process creates (or
removes) a reference to an object O, a reference counter local to O is incremented (or decremented).
• Problem 1: Dealing with lost (or duplicated) messages:– An increment is lost �the object may be prematurely
removed– An decrement is lost �the object is never removed– An ACK is lost � the increment/decrement is resent
• Solution: Keep track of duplicate request– discard duplicate requests
29
Reference Counting: Example• The problem of maintaining a proper reference
count in the presence of unreliable communication.
process P
proxy p Object O
Skeleton(maintains reference
counter)+11
ACK2
+13
proxy p is counted twice
ACK4

30
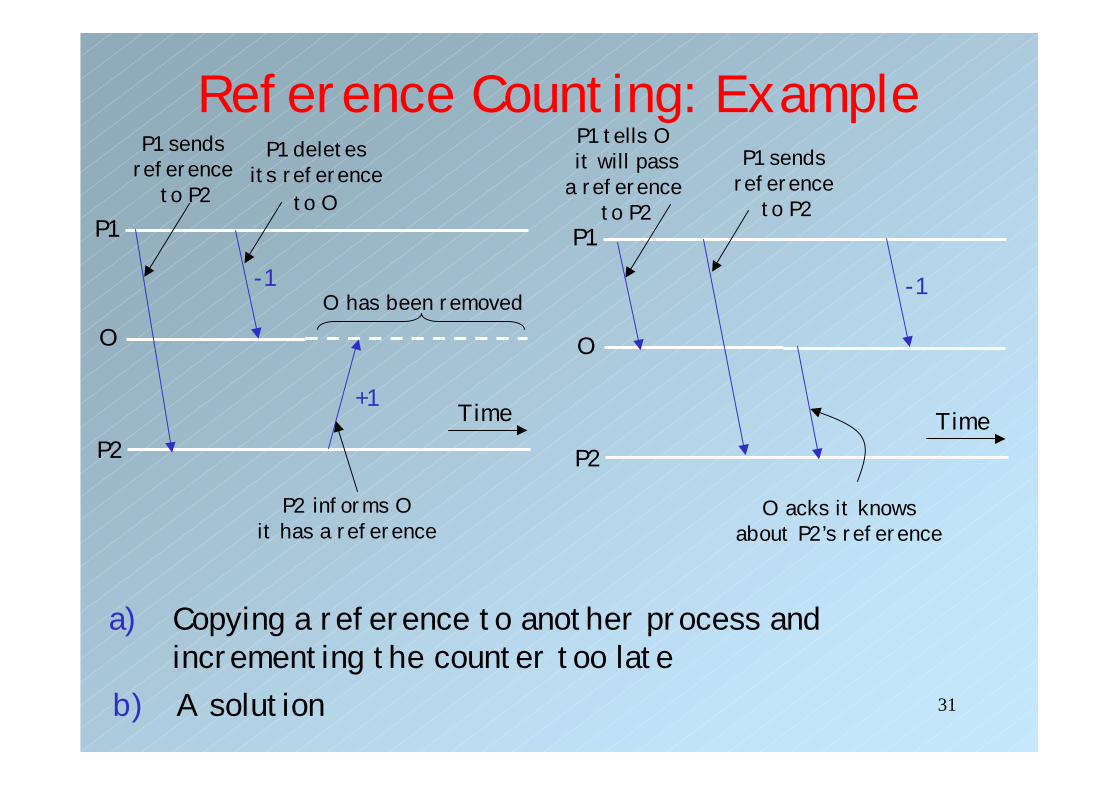
Reference Counting: Synchronization• Problem 2: Dealing with passing object
references; process P1 pass process P2 a reference to object O– P2 creates a reference to O, but informing the
skeleton with this new reference may take too long.– If the last reference known to O is removed before
the new reference is registered, the object may be prematurely removed
• Solution: Ensure that P2 talks to O on time– Let P1 tell O before it will pass a reference to P2
– Let O contact P2 immediately– A process can never remove a reference unless it has
received an ACK from O
31
P1
O
P2Time
Reference Counting: Example
a) Copying a reference to another process and incrementing the counter too late
P1
O
P2
O has been removed-1
+1
P1 sends reference
to P2
P1 deletes its reference
to O
P2 informs Oit has a reference
Time
P1 tells O it will pass
a reference to P2
P1 sends reference
to P2
b) A solution
O acks it knowsabout P2’s reference
-1

32
Weighted Reference Counting (1)• Solutions in simple reference counting may lead to
performance degradation besides race conditions between increment and decrement operations
• Solution: Avoid increment messages– Let O allow a maximum of M references (total weight)– When a new reference to O (proxy p) is created at
process P1, half of partial weight stored in the skeleton (s) of O is assigned to p
– When process P1 pass the reference of O to another process P2, a new proxy p´ is created in the address space of P2. Half of the partial weight of p is assigned to p’.
– A process sends the partial weight (stored in the proxy) back to O, whenever it removes its reference

33
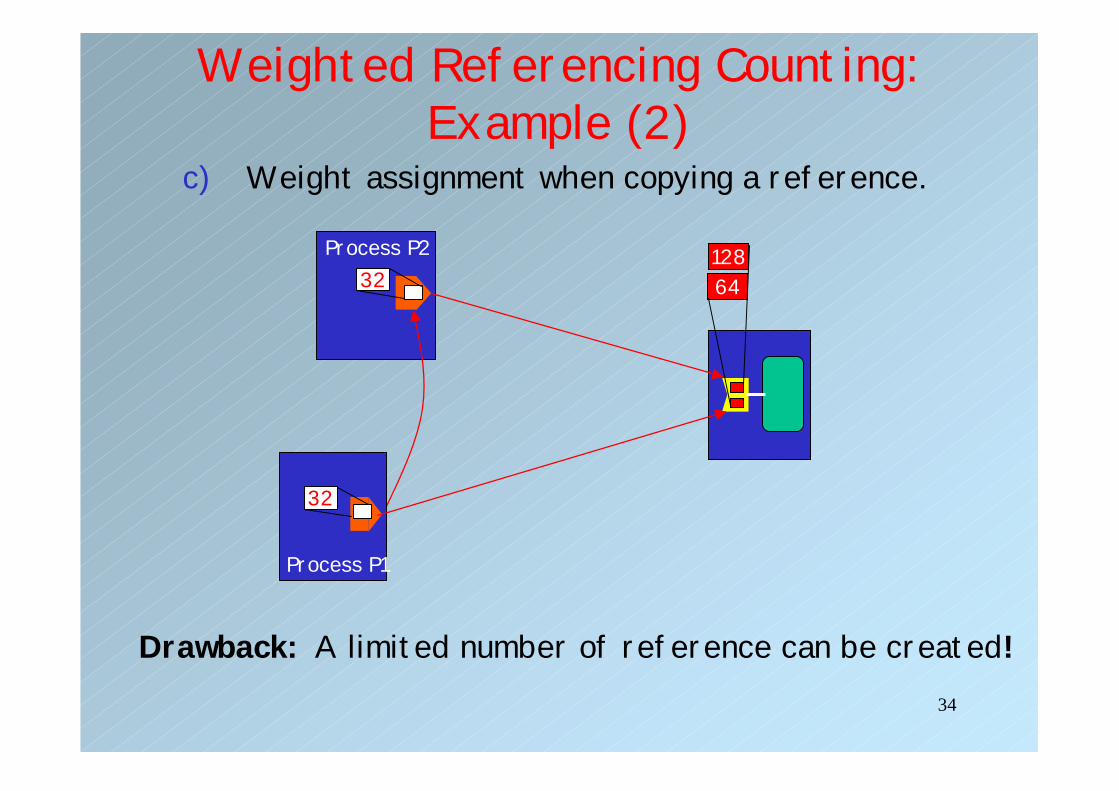
Weighted Referencing Counting: Example (1)
a) The initial assignment of weights in weighted reference countingb) Weight assignment when creating a new reference.
total weightpartial weight
128
128
1286464
34
Process P2
Weighted Referencing Counting: Example (2)
c) Weight assignment when copying a reference.
Drawback: A limited number of reference can be created!
12864
32
32
Process P1
32
35
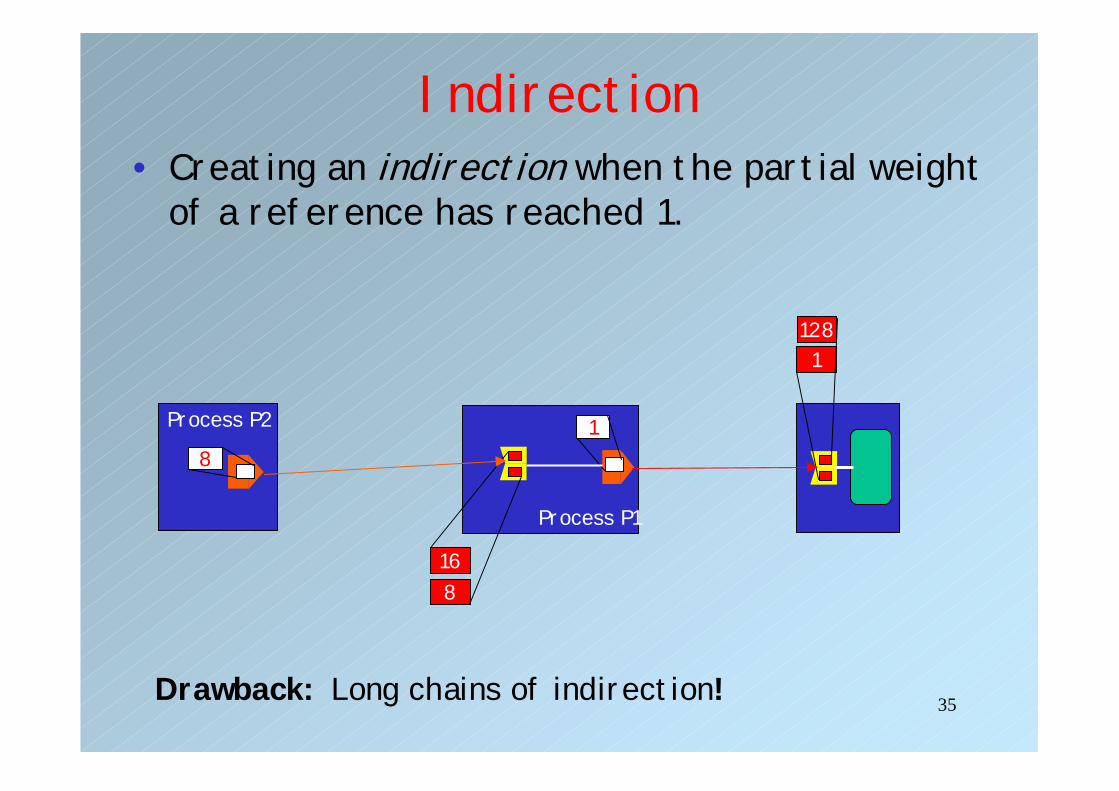
Indirection• Creating an indirection when the partial weight
of a reference has reached 1.
Drawback: Long chains of indirection!
Process P2
1281
Process P1
1
816
8

36
Reference Listing• Observation: We can avoid many problems if we
can tolerate message lost and duplications• Reference Listing: The object skeleton keeps an
explicit list of the proxies– increment operation replaced by idempotent insert– decrement operation replaced by idempotent remove– No need for reliable communication– Scale very poorly – Used in Java RMI
• There are other problems– Race condition can still occur– A process that keeps a reference to O may crash.
• Leases may be used to keep the list small.

37
Identifying Unreachable Entities• Problem: Even though an entity is referenced, it
may not be reachable from the root set – Objects referencing each other in a cycle
• Mark-and-sweep collectors (in uniprocessor systems)– During the mark phase, entities are traced by
following chains of references originating from entities in the root set
– Each entity that is reachable from the root set is marked (e.g. listed in a separate table)
– In the sweep phase, the unmarked entities are removed

38
Tracing in Groups: Basics• Distributed Garbage Collection:
– The processes (holding objects in their address spaces) in distributed systems are organized into groups
– An object usually has a single skeleton that allows remote reference
– In addition, an object may have many proxies to refer to other remote objects through their skeletons
Object
p1
pN
s

39
Tracing in Groups: Algorithm• The skeletons maintain also a reference counter• Marking:
– Skeletons can be marked either soft and hard– Proxies can be marked none, soft, or hard.
• Algorithm: 1. Initial marking, in which only skeletons are marked2.Intraprocess propagation of marks from skeletons to
proxies3.Interprocess propagation of marks from proxies to
skeletons4.Stabilization by repetition of Steps 2 and Step 3.5.Garbage reclamation

40
Tracing in Groups: Marking (1)• Skeletons:
– When marked hard, it means that it is 1. either reachable from a proxy in a process outside
the group2. or reachable from a root object inside the group
– When marked soft, it is reachable from proxies inside the group
– Marking is allowed to change from soft to hard

41
Tracing in Groups: Marking (2)• Proxies:
– When it is reachable from an object in the root set, marked hard
– When marked soft, it is reachable from a skeleton that has been marked soft
– Soft marked proxies potentially lie on a cycle that is not reachable from an object in the root set
– A proxy that is marked none is neither reachable from a skeleton, nor an object in the root set.
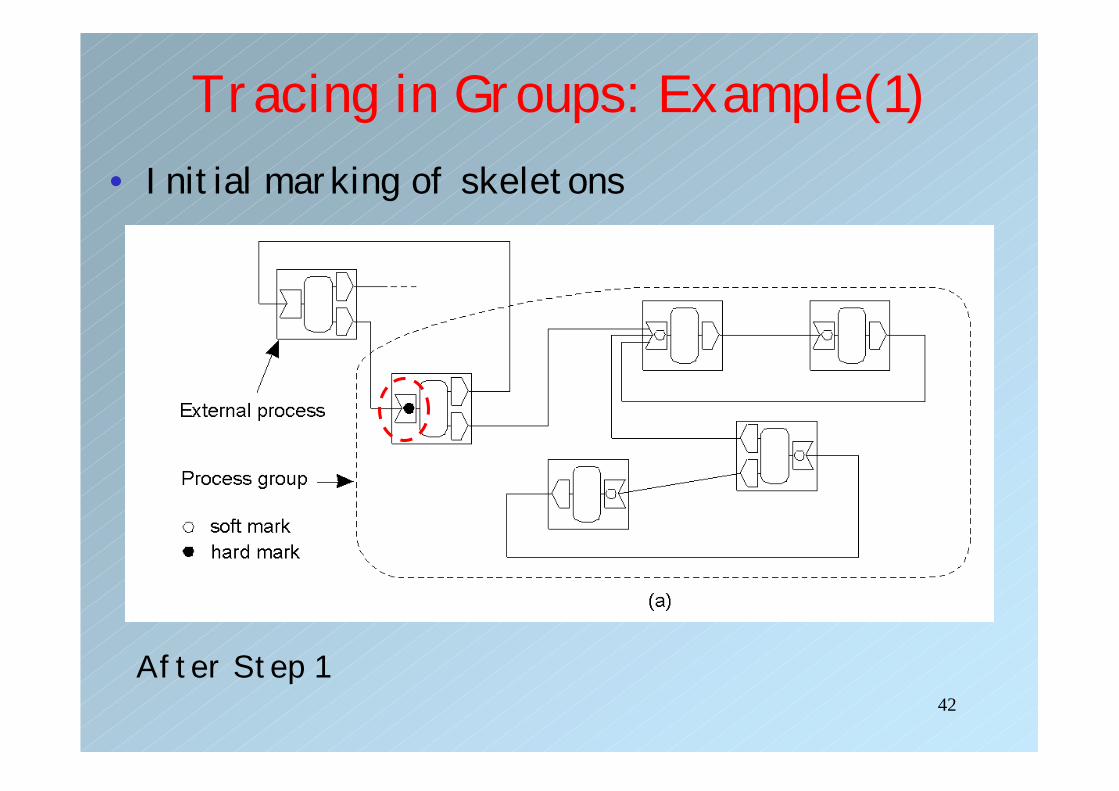
42
Tracing in Groups: Example(1)• Initial marking of skeletons
After Step 1
43
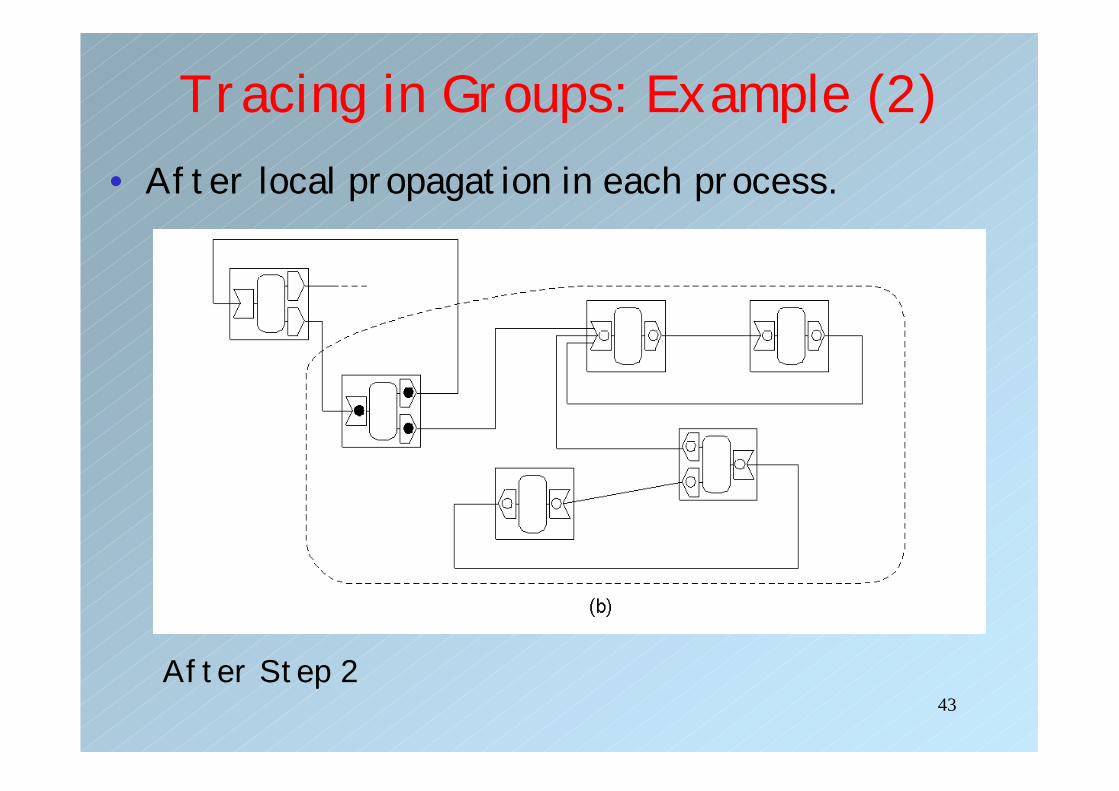
Tracing in Groups: Example (2)• After local propagation in each process.
After Step 2
44
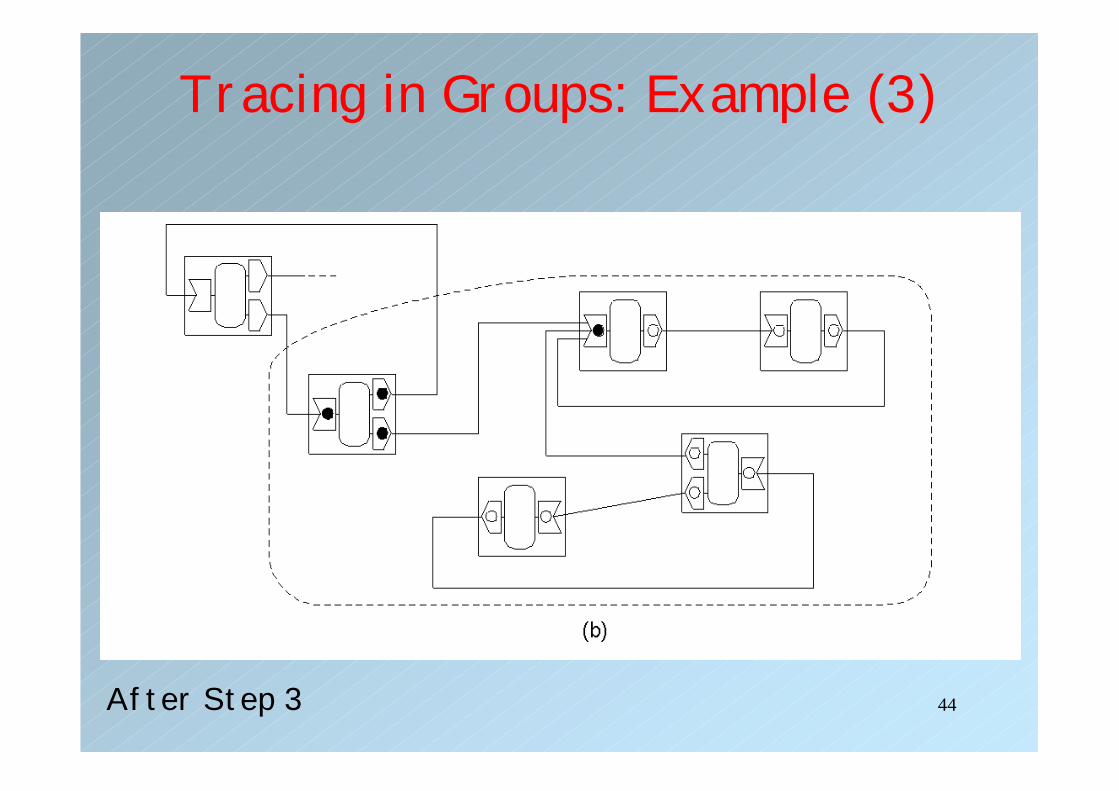
Tracing in Groups: Example (3)
After Step 3
45
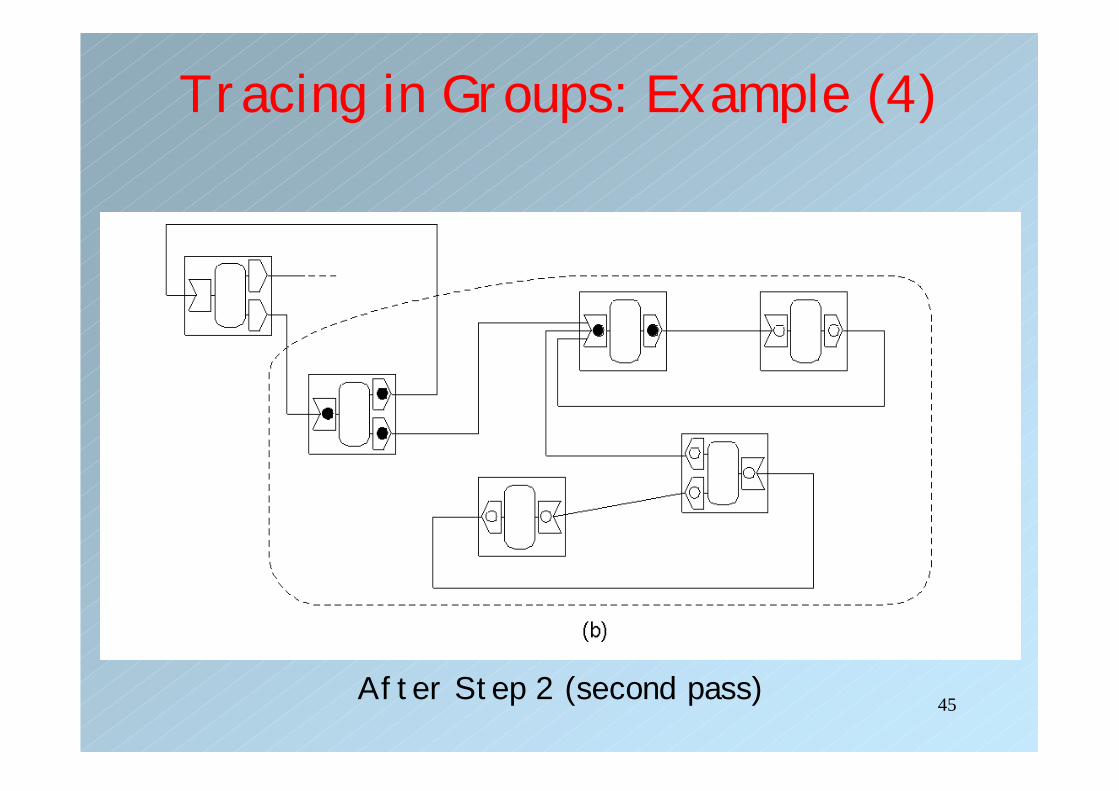
Tracing in Groups: Example (4)
After Step 2 (second pass)
46
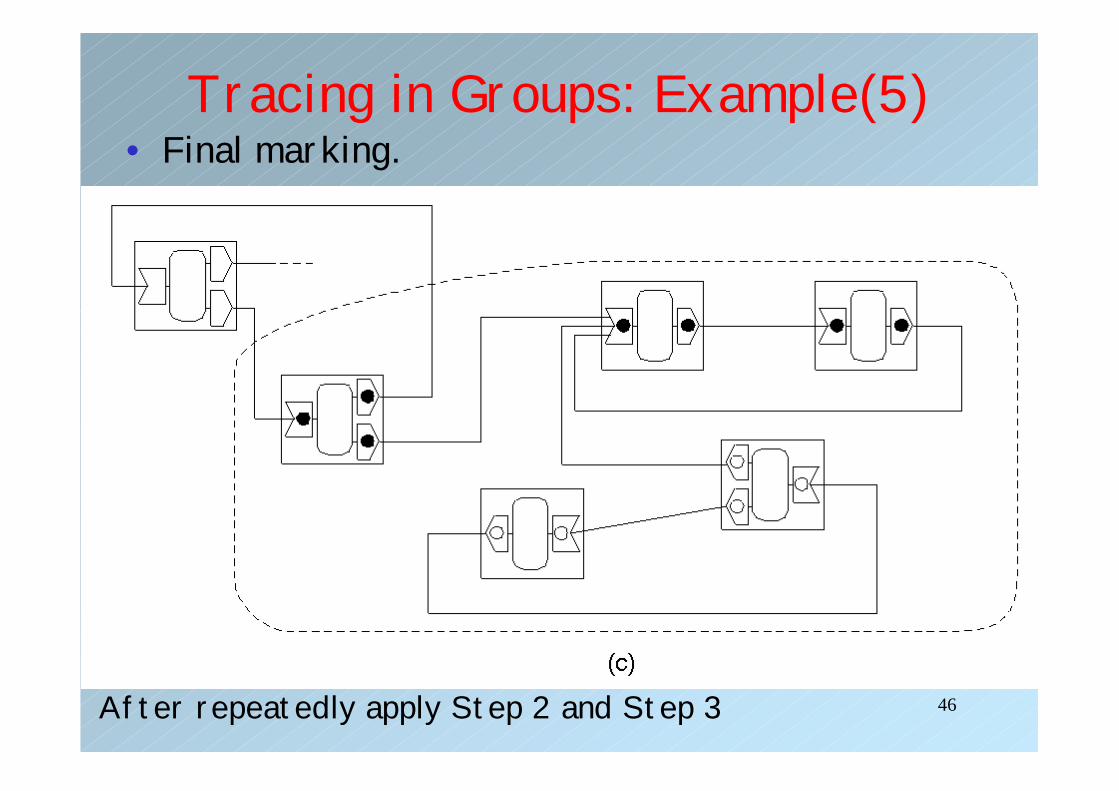
Tracing in Groups: Example(5)• Final marking.
After repeatedly apply Step 2 and Step 3





























