Embed Size (px)
Citation preview

CS262 Lecture 9, Win07, Batzoglou
Conditional Random Fields
A brief description
CS262 Lecture 9, Win07, Batzoglou
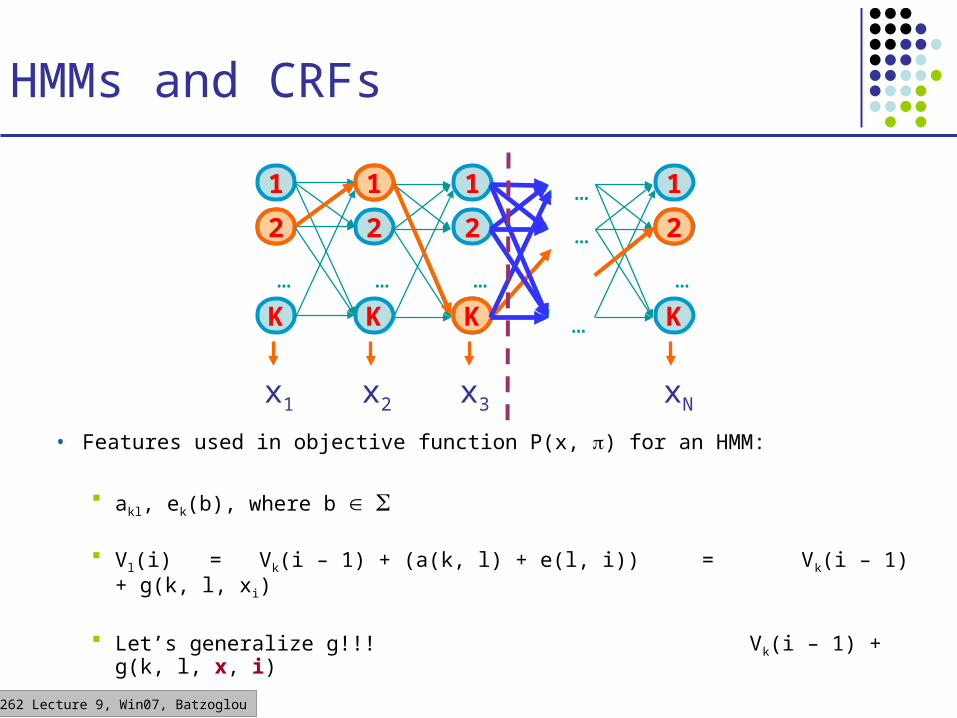
HMMs and CRFs
• Features used in objective function P(x, ) for an HMM:
akl, ek(b), where b
Vl(i) = Vk(i – 1) + (a(k, l) + e(l, i)) = Vk(i – 1) + g(k, l, xi)
Let’s generalize g!!! Vk(i – 1) + g(k, l, x, i)
1
2
K
…
1
2
K
…
1
2
K
…
…
…
…
1
2
K
…
x1 x2 x3 xN
2
1
K
2

CS262 Lecture 9, Win07, Batzoglou
CRFs - Features
1. Define a set of features that may be important
Number the features 1…n: f1(k, l, x, i), …, fn(k, l, x, i)• features are indicator true/false variables
2. Train weights wj for each feature fj
Then, g(k, l, x, i) = j=1…n fj(k, l, x, i) wj
x1 x2 x3 x6x4 x5 x7 x10x8 x9
ii-1
CS262 Lecture 9, Win07, Batzoglou
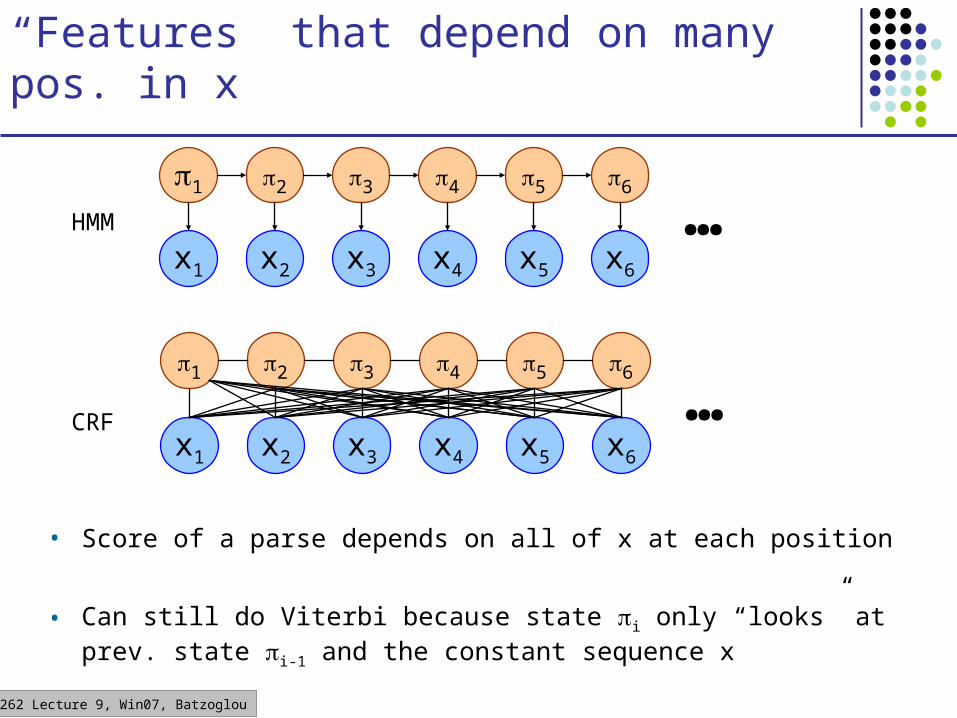
“Features” that depend on many pos. in x
• Score of a parse depends on all of x at each position
• Can still do Viterbi because state i only “looks” at prev. state i-1 and the constant sequence x
1
x1
2
x2
3
x3
4
x4
5
x5
6
x6…
1
x1
2
x2
3
x3
4
x4
5
x5
6
x6…
HMM
CRF

CS262 Lecture 9, Win07, Batzoglou
Conditional Training
• Hidden Markov Model training: Given training sequence x, “true” parse Maximize P(x, )
• Disadvantage:
P(x, ) = P( | x) P(x)
Quantity we care aboutso as to get a good parse
Quantity we don’t care so muchabout because x is always given

CS262 Lecture 9, Win07, Batzoglou
Conditional Training
P(x, ) = P( | x) P(x)P( | x) = P(x, ) / P(x)
Recall
Fj(x, ) = # times feature fj occurs in (x, )
= i=1…N fj(k, l, x, i) ; count fj in x,
In HMMs, let’s denote by wj the weight of jth feature: wj = log(akl) or log(ek(b))
Then,
HMM: P(x, ) = exp[j=1…n wj Fj(x, )]
CRF: Score(x, ) = exp[j=1…n wj Fj(x, )]

CS262 Lecture 9, Win07, Batzoglou
Conditional Training
In HMMs,
P( | x) = P(x, ) / P(x)
P(x, ) = exp[wTF(x, )] P(x) = exp[wTF(x, )] =: Z
Then, in CRF we can do the same to normalize Score(x, ) into a prob.
PCRF( | x) = exp[j=1…n wjF(j, x, )] / Z
QUESTION: Why is this a probability???

CS262 Lecture 9, Win07, Batzoglou
Conditional Training
1. We need to be given a set of sequences x and “true” parses
2. Calculate Z by a sum-of-paths algorithm similar to HMM• We can then easily calculate P( | x)
3. Calculate partial derivative of P( | x) w.r.t. each parameter wj
(not covered—akin to forward/backward)
• Update each parameter with gradient descent
4. Continue until convergence to optimal set of weights
P( | x) = exp[j=1…n wjF(j, x, )] / Z is convex

CS262 Lecture 9, Win07, Batzoglou
Conditional Random Fields—Summary
1. Ability to incorporate complicated non-local feature sets• Do away with some independence assumptions of HMMs
• Parsing is still equally efficient
2. Conditional training• Train parameters that are best for parsing, not modeling
• Need labeled examples—sequences x and “true” parses (Can train on unlabeled sequences, however it is unreasonable to train too many
parameters this way)
• Training is significantly slower—many iterations of forward/backward
DNA Sequencing
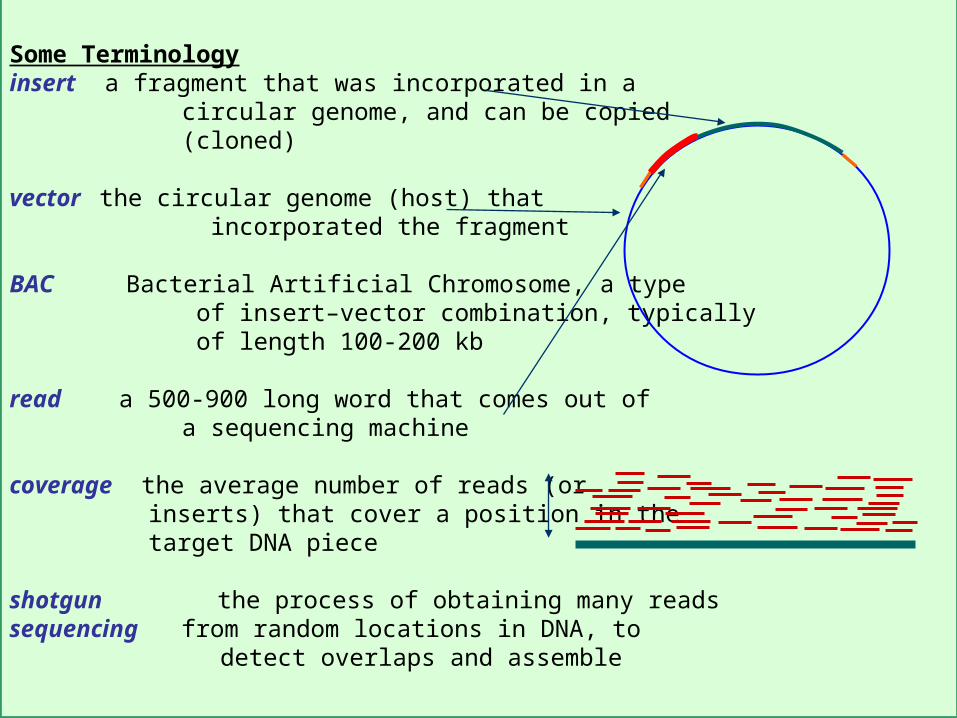
CS262 Lecture 9, Win07, Batzoglou
Some Terminologyinsert a fragment that was incorporated in a circular genome, and can be copied (cloned)
vector the circular genome (host) that incorporated the fragment
BAC Bacterial Artificial Chromosome, a type of insert–vector combination, typically of length 100-200 kb
read a 500-900 long word that comes out of a sequencing machine
coverage the average number of reads (or inserts) that cover a position in the target DNA piece
shotgun the process of obtaining many reads sequencing from random locations in DNA, to
detect overlaps and assemble
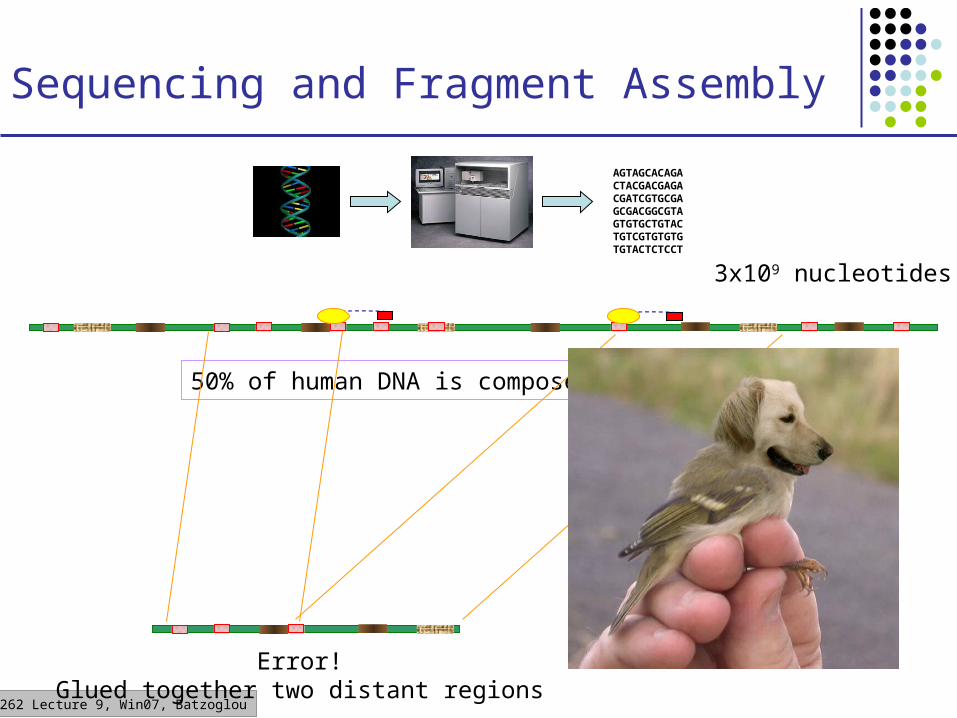
CS262 Lecture 9, Win07, Batzoglou
Sequencing and Fragment Assembly
AGTAGCACAGACTACGACGAGACGATCGTGCGAGCGACGGCGTAGTGTGCTGTACTGTCGTGTGTGTGTACTCTCCT
3x109 nucleotides
50% of human DNA is composed of repeats
Error!Glued together two distant regions
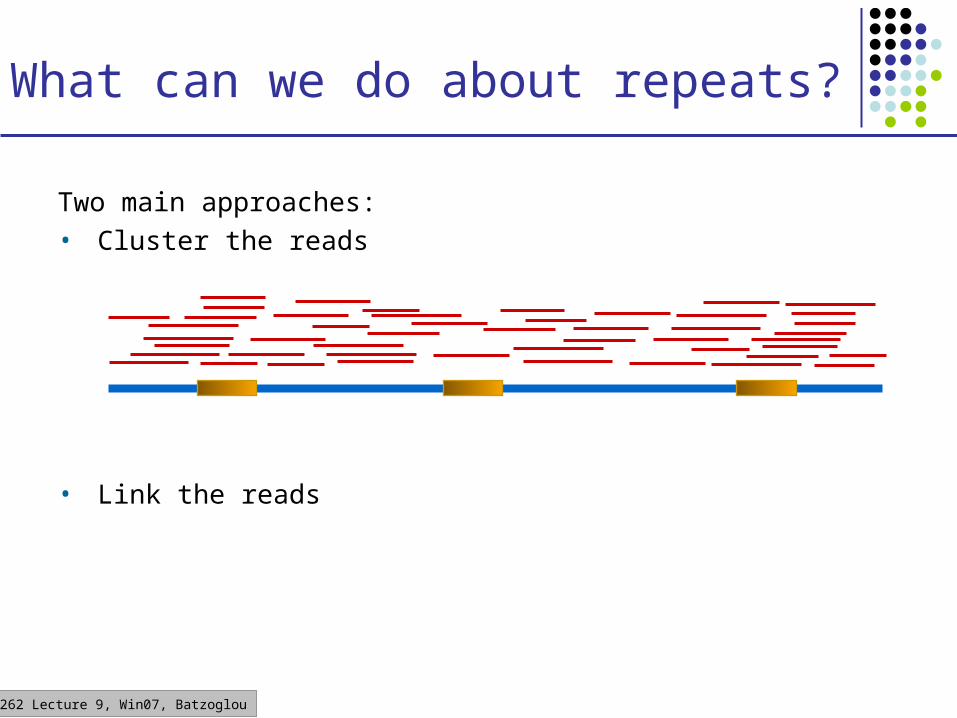
CS262 Lecture 9, Win07, Batzoglou
What can we do about repeats?
Two main approaches:• Cluster the reads
• Link the reads

CS262 Lecture 9, Win07, Batzoglou
What can we do about repeats?
Two main approaches:• Cluster the reads
• Link the reads
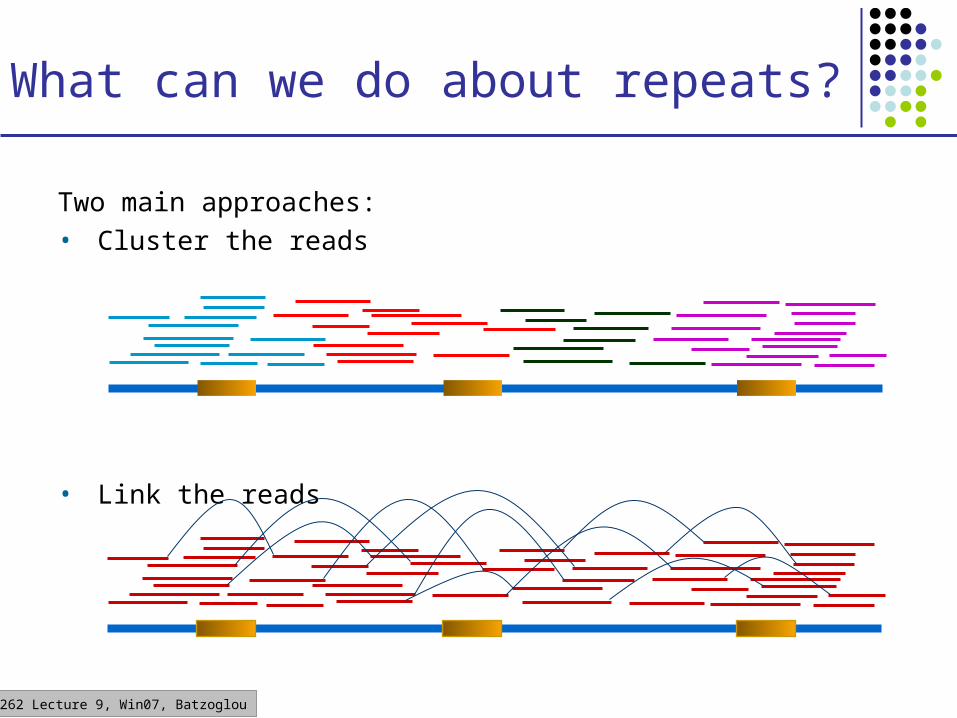
CS262 Lecture 9, Win07, Batzoglou
What can we do about repeats?
Two main approaches:• Cluster the reads
• Link the reads
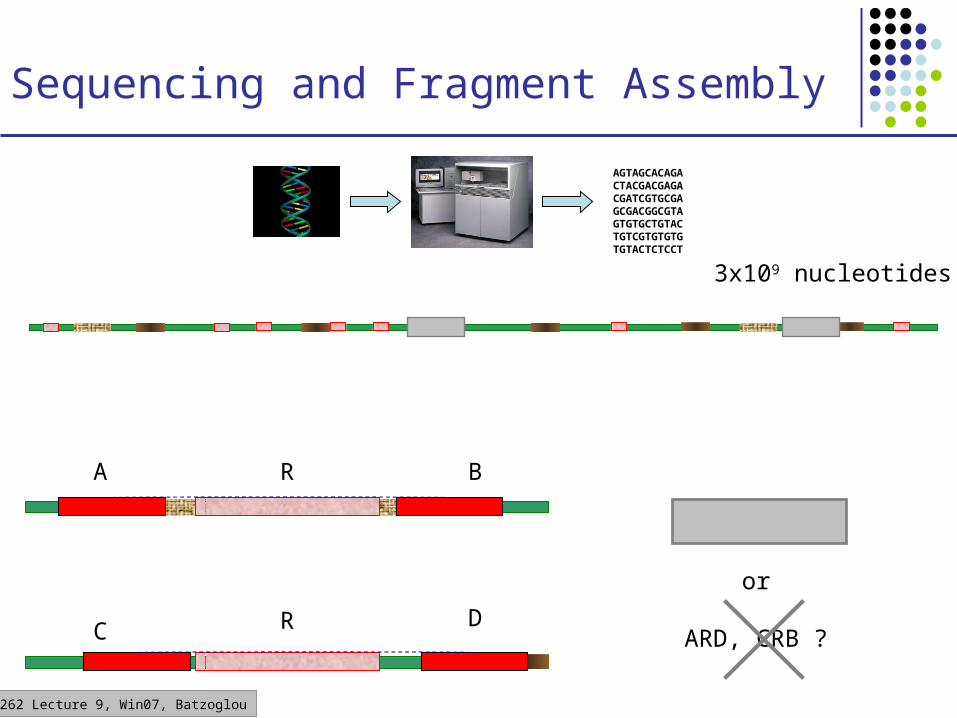
CS262 Lecture 9, Win07, Batzoglou
Sequencing and Fragment Assembly
AGTAGCACAGACTACGACGAGACGATCGTGCGAGCGACGGCGTAGTGTGCTGTACTGTCGTGTGTGTGTACTCTCCT
3x109 nucleotides
C R D
ARB, CRD
or
ARD, CRB ?
A R B
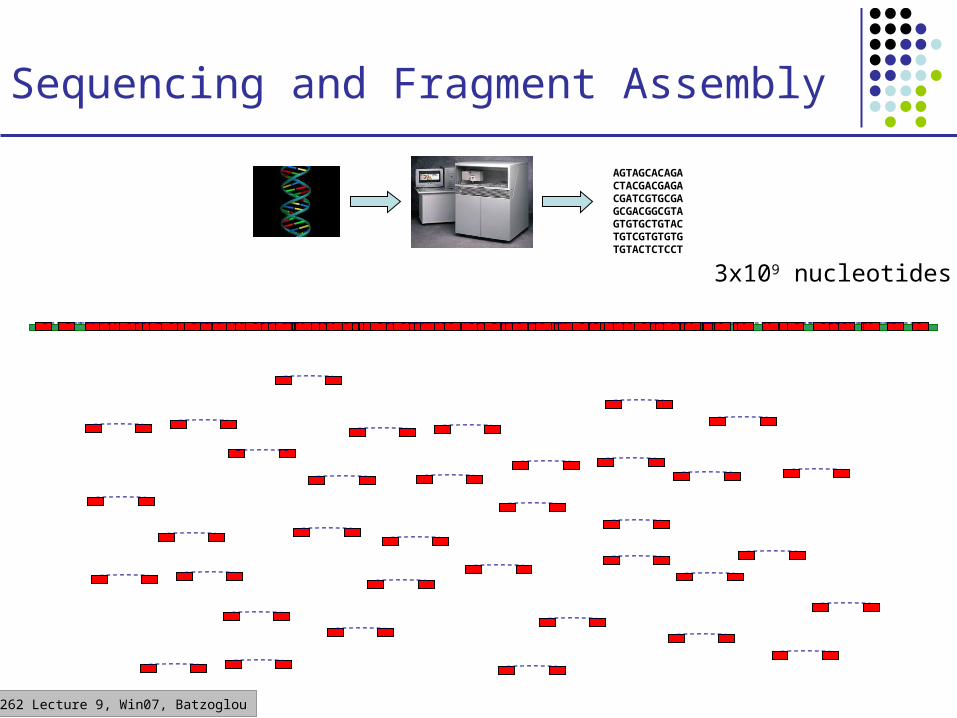
CS262 Lecture 9, Win07, Batzoglou
Sequencing and Fragment Assembly
AGTAGCACAGACTACGACGAGACGATCGTGCGAGCGACGGCGTAGTGTGCTGTACTGTCGTGTGTGTGTACTCTCCT
3x109 nucleotides
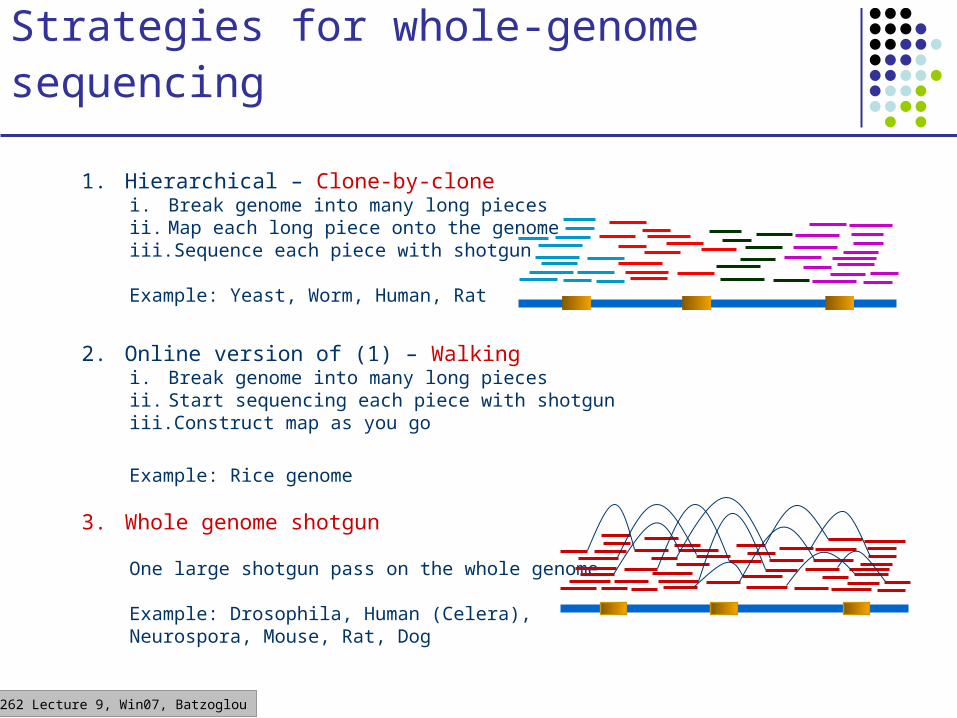
CS262 Lecture 9, Win07, Batzoglou
Strategies for whole-genome sequencing
1. Hierarchical – Clone-by-clonei. Break genome into many long piecesii. Map each long piece onto the genomeiii. Sequence each piece with shotgun
Example: Yeast, Worm, Human, Rat
2. Online version of (1) – Walkingi. Break genome into many long piecesii. Start sequencing each piece with shotguniii. Construct map as you go
Example: Rice genome
3. Whole genome shotgun
One large shotgun pass on the whole genome
Example: Drosophila, Human (Celera), Neurospora, Mouse, Rat, Dog
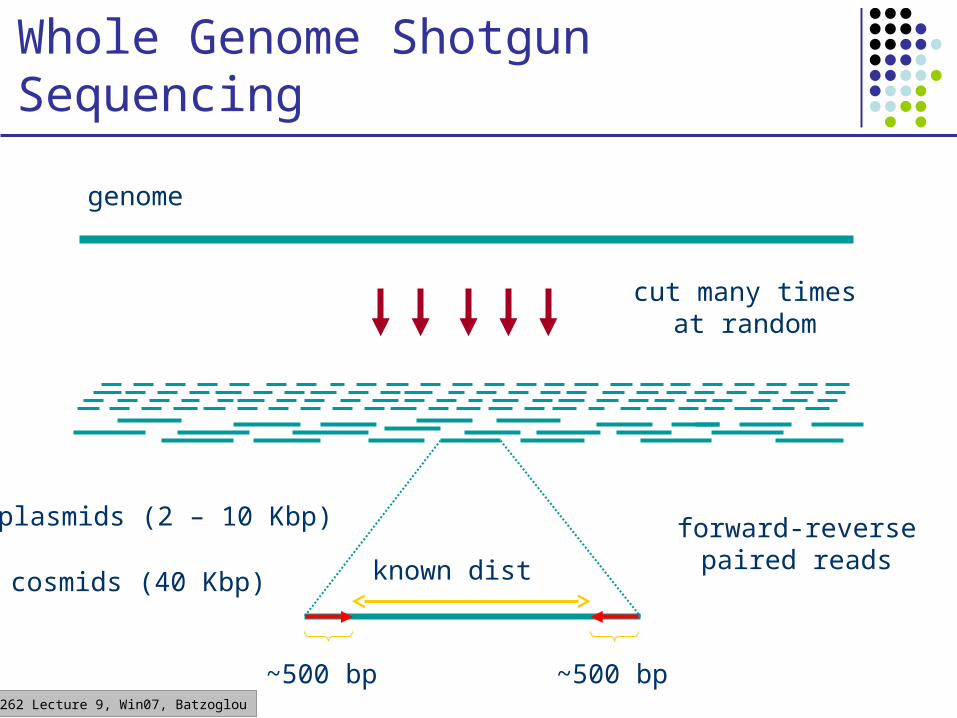
CS262 Lecture 9, Win07, Batzoglou
Whole Genome Shotgun Sequencing
cut many times at random
genome
forward-reverse paired reads
plasmids (2 – 10 Kbp)
cosmids (40 Kbp) known dist
~500 bp~500 bp

CS262 Lecture 9, Win07, Batzoglou
Fragment Assembly(in whole-genome shotgun sequencing)

CS262 Lecture 9, Win07, Batzoglou
Fragment Assembly
Given N reads…Given N reads…Where N ~ 30 Where N ~ 30
million…million…
We need to use a We need to use a linear-time linear-time algorithmalgorithm
CS262 Lecture 9, Win07, Batzoglou
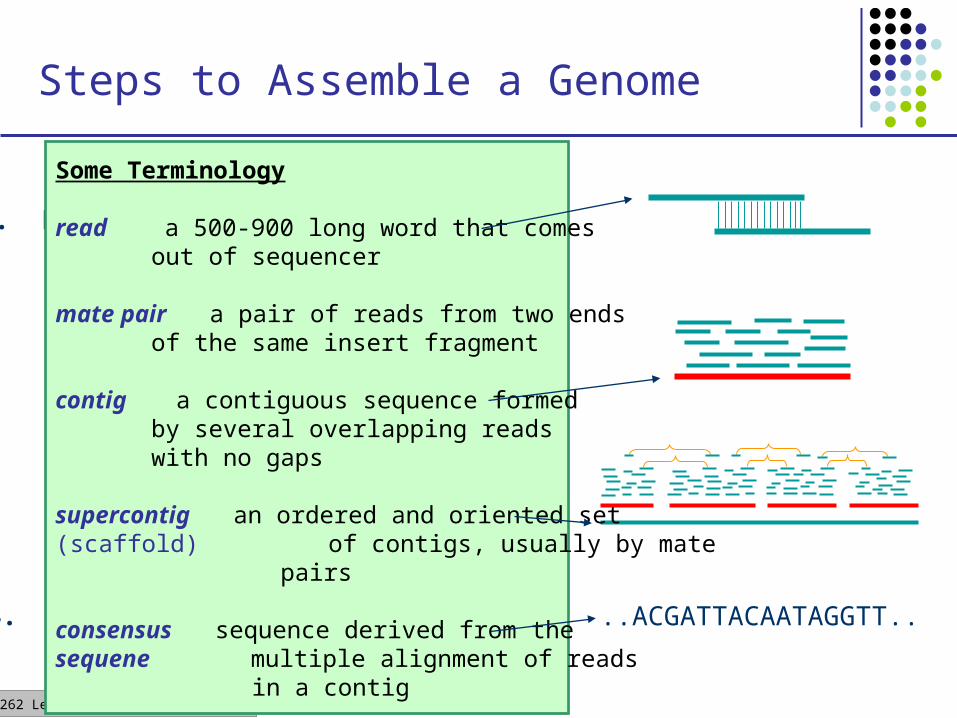
Steps to Assemble a Genome
1. Find overlapping reads
4. Derive consensus sequence ..ACGATTACAATAGGTT..
2. Merge some “good” pairs of reads into longer contigs
3. Link contigs to form supercontigs
Some Terminology
read a 500-900 long word that comes out of sequencer
mate pair a pair of reads from two endsof the same insert fragment
contig a contiguous sequence formed by several overlapping readswith no gaps
supercontig an ordered and oriented set(scaffold) of contigs, usually by mate
pairs
consensus sequence derived from thesequene multiple alignment of reads
in a contig

CS262 Lecture 9, Win07, Batzoglou
1. Find Overlapping Reads
aaactgcagtacggatctaaactgcag aactgcagt… gtacggatct tacggatctgggcccaaactgcagtacgggcccaaa ggcccaaac… actgcagta ctgcagtacgtacggatctactacacagtacggatc tacggatct… ctactacac tactacaca
(read, pos., word, orient.)
aaactgcagaactgcagtactgcagta… gtacggatctacggatctgggcccaaaggcccaaacgcccaaact…actgcagtactgcagtacgtacggatctacggatctacggatcta…ctactacactactacaca
(word, read, orient., pos.)
aaactgcagaactgcagtacggatcta actgcagta actgcagtacccaaactgcggatctacctactacacctgcagtacctgcagtacgcccaaactggcccaaacgggcccaaagtacggatcgtacggatctacggatcttacggatcttactacaca

CS262 Lecture 9, Win07, Batzoglou
1. Find Overlapping Reads
• Find pairs of reads sharing a k-mer, k ~ 24• Extend to full alignment – throw away if not >98% similar
TAGATTACACAGATTAC
TAGATTACACAGATTAC|||||||||||||||||
T GA
TAGA| ||
TACA
TAGT||
• Caveat: repeats A k-mer that occurs N times, causes O(N2) read/read comparisons ALU k-mers could cause up to 1,000,0002 comparisons
• Solution: Discard all k-mers that occur “too often”
• Set cutoff to balance sensitivity/speed tradeoff, according to genome at hand and computing resources available

CS262 Lecture 9, Win07, Batzoglou
1. Find Overlapping Reads
Create local multiple alignments from the overlapping reads
TAGATTACACAGATTACTGATAGATTACACAGATTACTGATAG TTACACAGATTATTGATAGATTACACAGATTACTGATAGATTACACAGATTACTGATAGATTACACAGATTACTGATAG TTACACAGATTATTGATAGATTACACAGATTACTGA

CS262 Lecture 9, Win07, Batzoglou
1. Find Overlapping Reads
• Correct errors using multiple alignment
TAGATTACACAGATTACTGATAGATTACACAGATTACTGATAGATTACACAGATTATTGATAGATTACACAGATTACTGATAG-TTACACAGATTACTGA
TAGATTACACAGATTACTGATAGATTACACAGATTACTGATAG-TTACACAGATTATTGATAGATTACACAGATTACTGATAG-TTACACAGATTATTGA
insert A
replace T with Ccorrelated errors—probably caused by repeats disentangle overlaps
TAGATTACACAGATTACTGATAGATTACACAGATTACTGA
TAG-TTACACAGATTATTGA
TAGATTACACAGATTACTGA
TAG-TTACACAGATTATTGA
In practice, error correction removes up to 98% of the errors
CS262 Lecture 9, Win07, Batzoglou
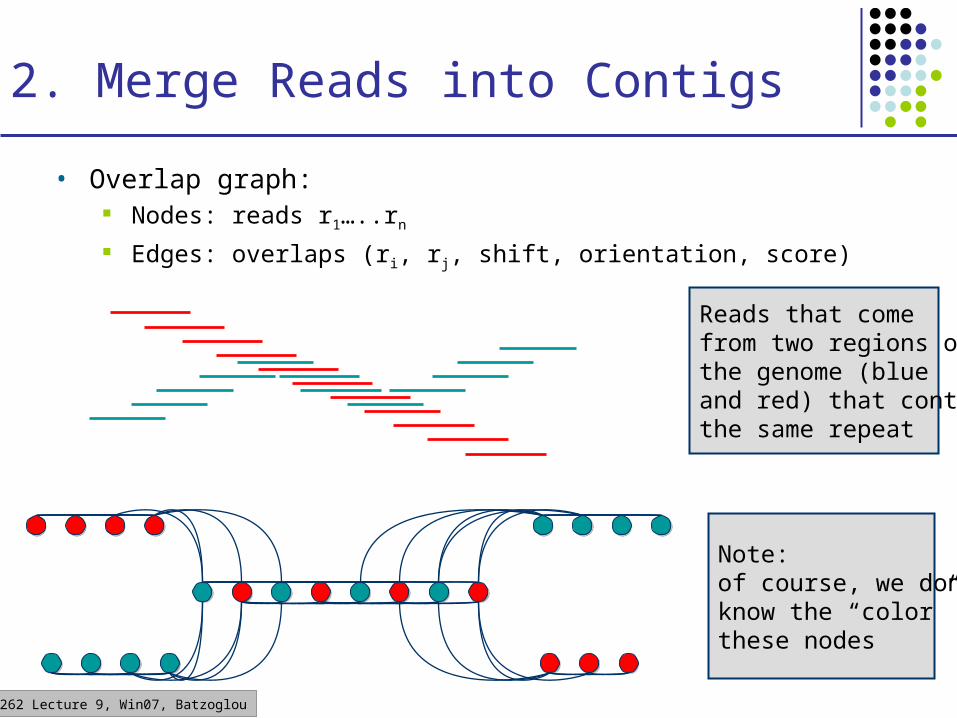
2. Merge Reads into Contigs
• Overlap graph: Nodes: reads r1…..rn
Edges: overlaps (ri, rj, shift, orientation, score)
Note:of course, we don’tknow the “color” ofthese nodes
Reads that comefrom two regions ofthe genome (blueand red) that containthe same repeat
CS262 Lecture 9, Win07, Batzoglou
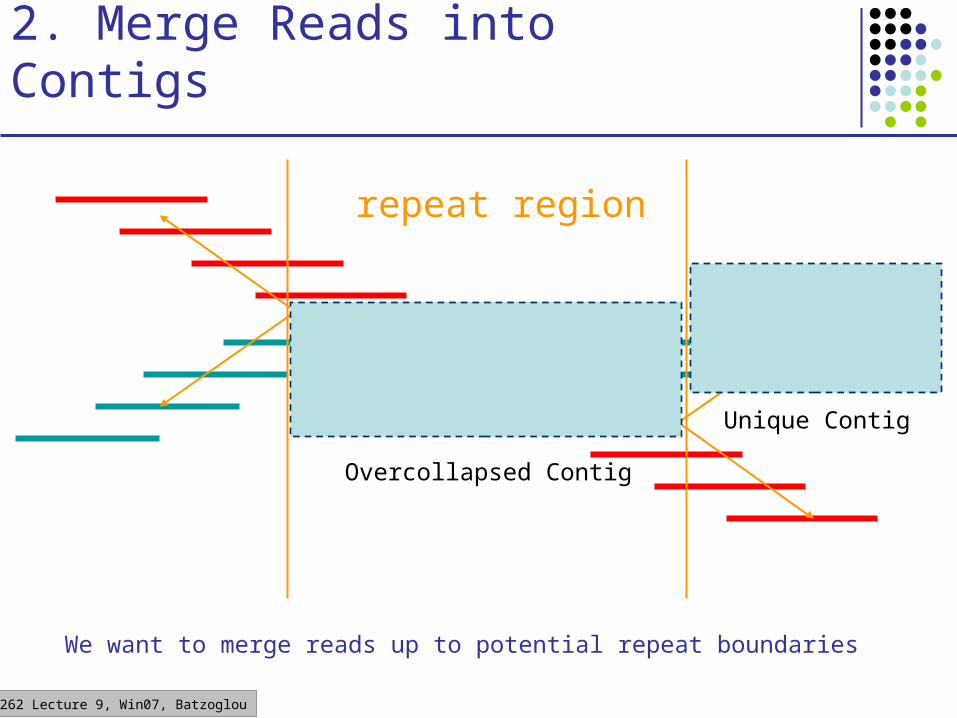
2. Merge Reads into Contigs
We want to merge reads up to potential repeat boundaries
repeat region
Unique Contig
Overcollapsed Contig
CS262 Lecture 9, Win07, Batzoglou
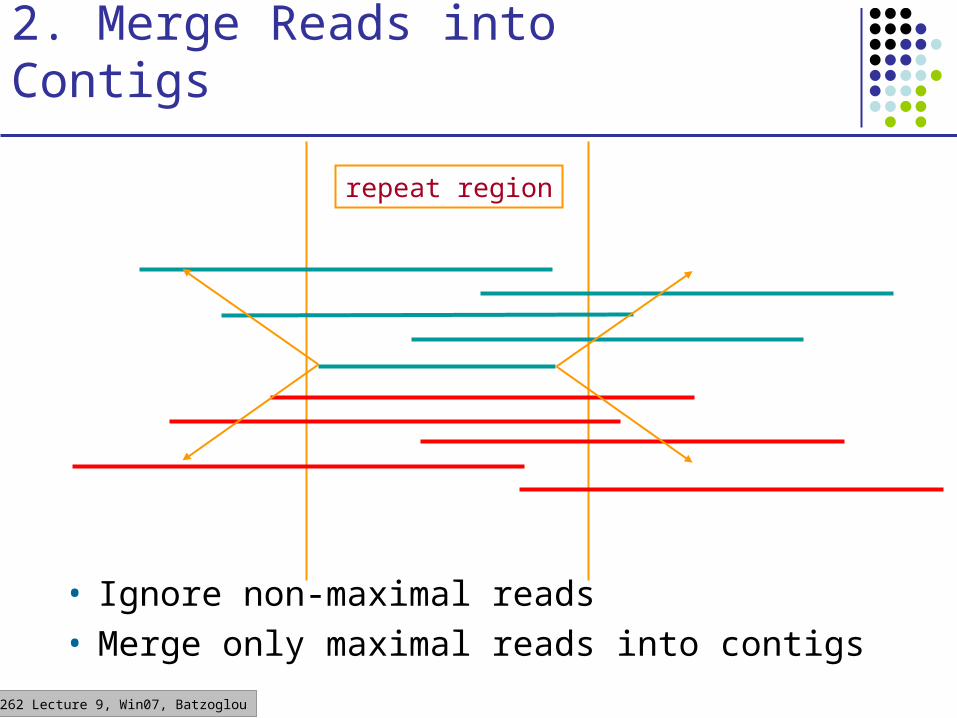
2. Merge Reads into Contigs
• Ignore non-maximal reads• Merge only maximal reads into contigs
repeat region
CS262 Lecture 9, Win07, Batzoglou
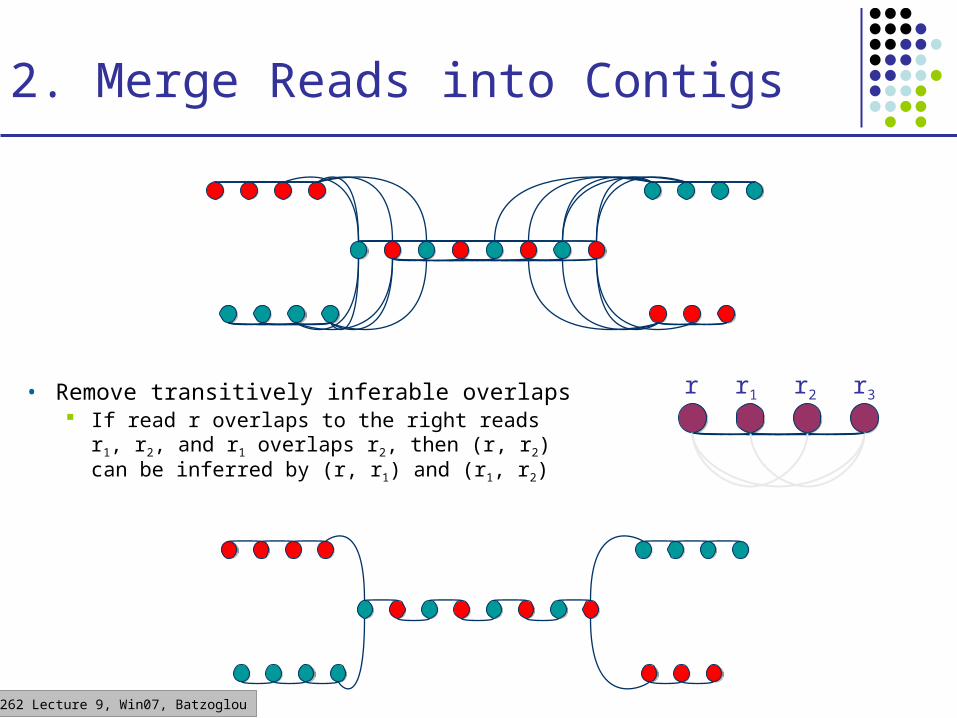
2. Merge Reads into Contigs
• Remove transitively inferable overlaps If read r overlaps to the right reads r1, r2,
and r1 overlaps r2, then (r, r2) can be inferred by (r, r1) and (r1, r2)
r r1 r2 r3
CS262 Lecture 9, Win07, Batzoglou
2. Merge Reads into Contigs
CS262 Lecture 9, Win07, Batzoglou
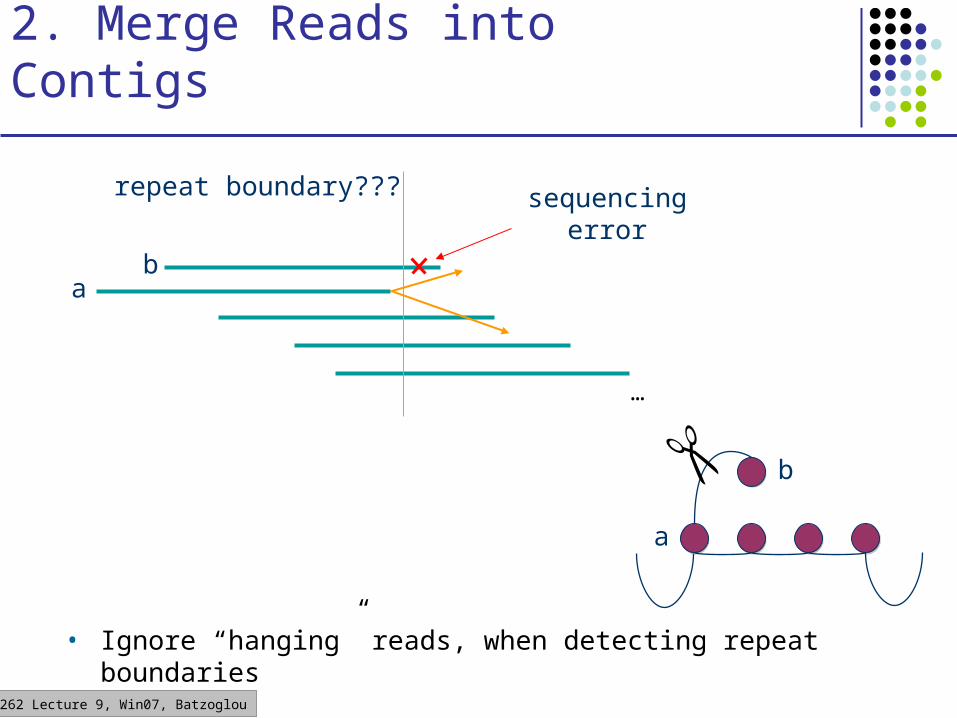
2. Merge Reads into Contigs
• Ignore “hanging” reads, when detecting repeat boundaries
sequencing error
repeat boundary???
ba
a
b
…
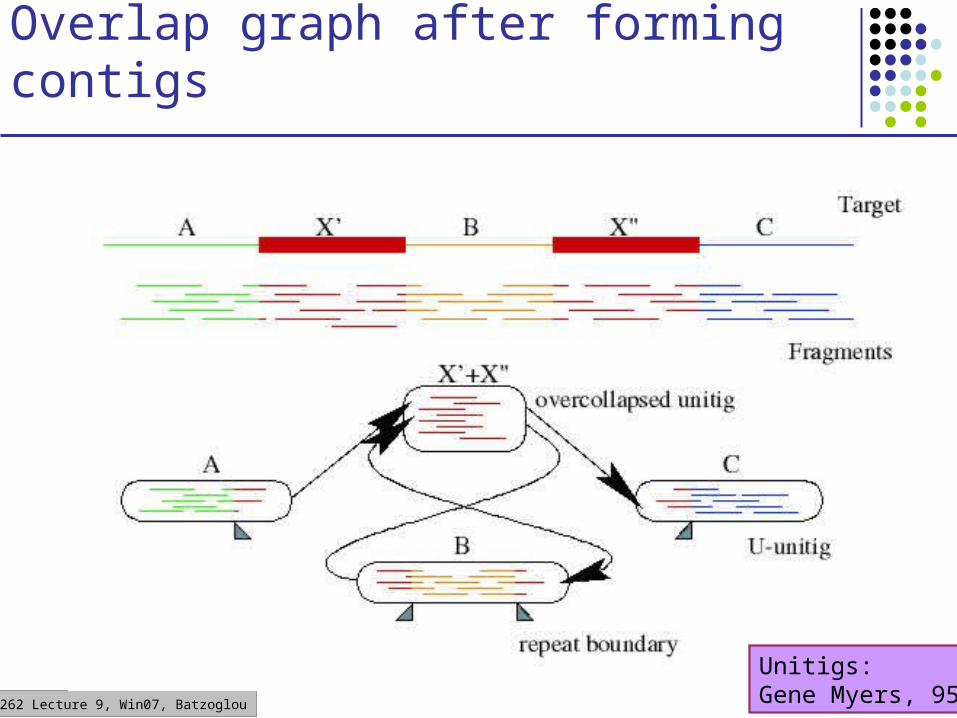
CS262 Lecture 9, Win07, Batzoglou
Overlap graph after forming contigs
Unitigs:Gene Myers, 95

CS262 Lecture 9, Win07, Batzoglou
Repeats, errors, and contig lengths
• Repeats shorter than read length are easily resolved Read that spans across a repeat disambiguates order of flanking regions
• Repeats with more base pair diffs than sequencing error rate are OK We throw overlaps between two reads in different copies of the repeat
• To make the genome appear less repetitive, try to:
Increase read length Decrease sequencing error rate
Role of error correction:Discards up to 98% of single-letter sequencing errors
decreases error rate decreases effective repeat content increases contig length
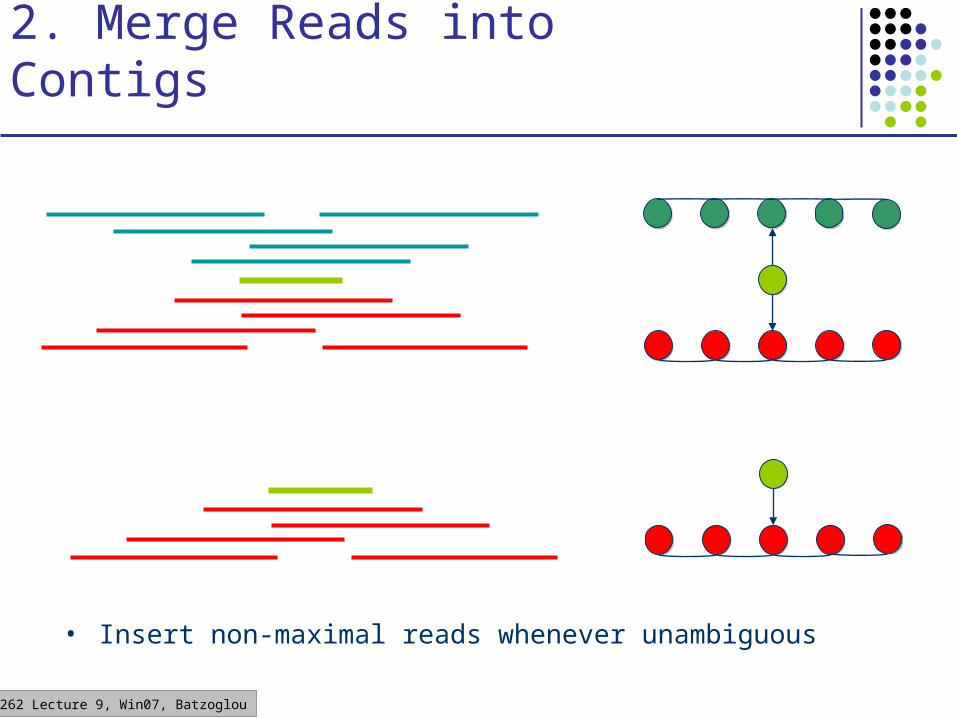
CS262 Lecture 9, Win07, Batzoglou
• Insert non-maximal reads whenever unambiguous
2. Merge Reads into Contigs
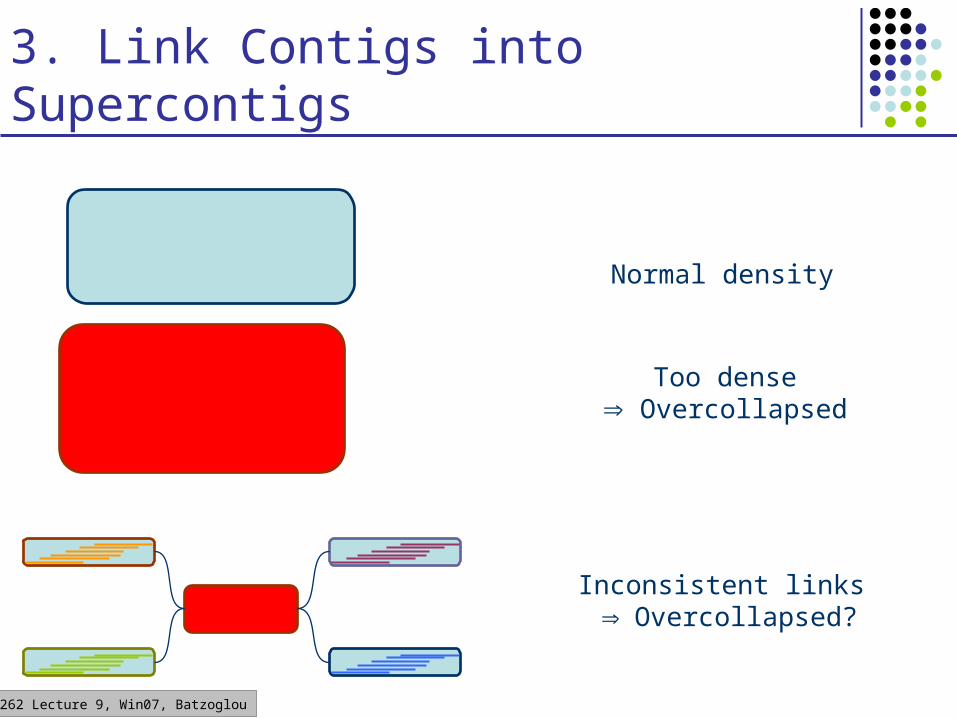
CS262 Lecture 9, Win07, Batzoglou
3. Link Contigs into Supercontigs
Too dense Overcollapsed
Inconsistent links Overcollapsed?
Normal density
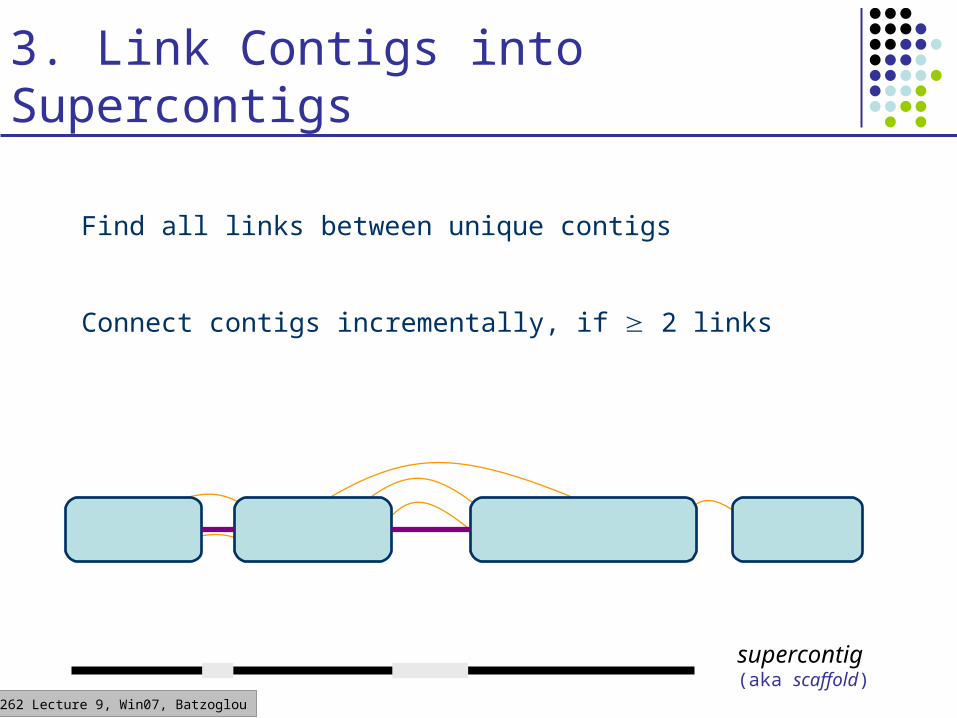
CS262 Lecture 9, Win07, Batzoglou
Find all links between unique contigs
3. Link Contigs into Supercontigs
Connect contigs incrementally, if 2 links
supercontig(aka scaffold)
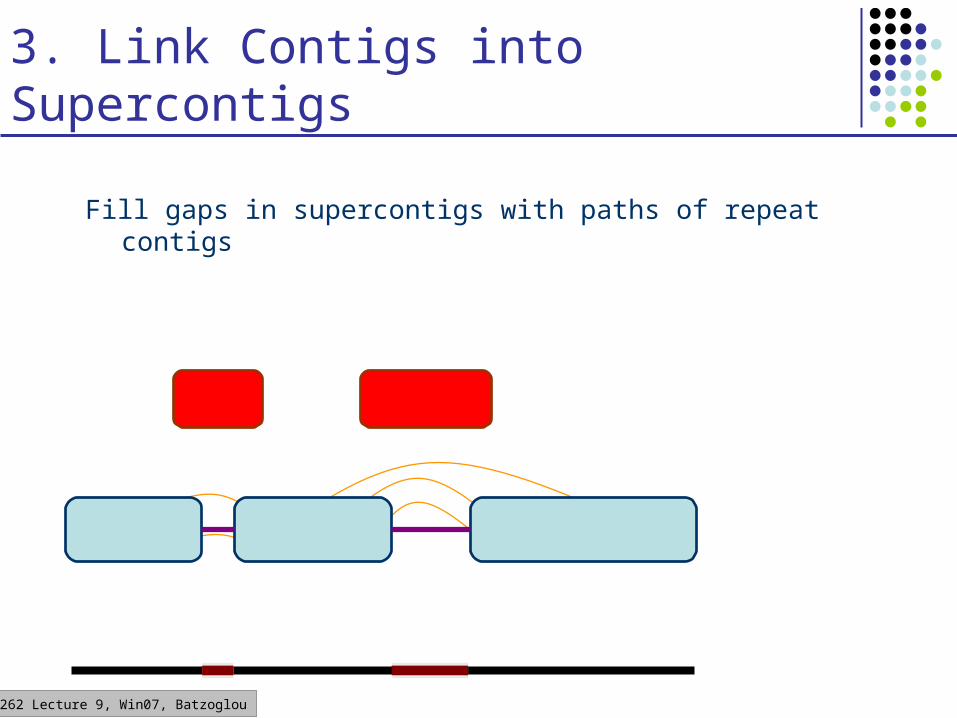
CS262 Lecture 9, Win07, Batzoglou
Fill gaps in supercontigs with paths of repeat contigs
3. Link Contigs into Supercontigs

CS262 Lecture 9, Win07, Batzoglou
4. Derive Consensus Sequence
Derive multiple alignment from pairwise read alignments
TAGATTACACAGATTACTGA TTGATGGCGTAA CTATAGATTACACAGATTACTGACTTGATGGCGTAAACTATAG TTACACAGATTATTGACTTCATGGCGTAA CTATAGATTACACAGATTACTGACTTGATGGCGTAA CTATAGATTACACAGATTACTGACTTGATGGGGTAA CTA
TAGATTACACAGATTACTGACTTGATGGCGTAA CTA
Derive each consensus base by weighted voting
(Alternative: take maximum-quality letter)

CS262 Lecture 9, Win07, Batzoglou
Some Assemblers
• PHRAP• Early assembler, widely used, good model of read errors
• Overlap O(n2) layout (no mate pairs) consensus
• Celera• First assembler to handle large genomes (fly, human, mouse)
• Overlap layout consensus
• Arachne• Public assembler (mouse, several fungi)
• Overlap layout consensus
• Phusion• Overlap clustering PHRAP assemblage consensus
• Euler• Indexing Euler graph layout by picking paths consensus

CS262 Lecture 9, Win07, Batzoglou
Quality of assemblies—mouse
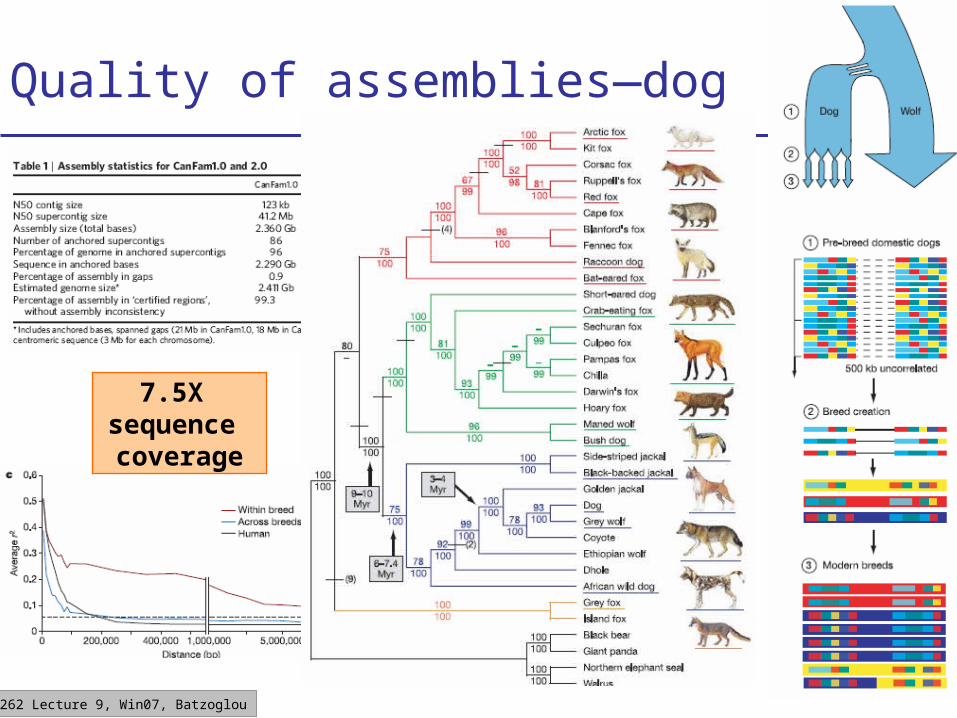
Terminology: N50 contig lengthN50 contig lengthIf we sort contigs from largest to smallest, and startCovering the genome in that order, N50 is the lengthOf the contig that just covers the 50th percentile.
7.7X sequence coverage
CS262 Lecture 9, Win07, Batzoglou
Quality of assemblies—dog
7.5X sequence coverage

CS262 Lecture 9, Win07, Batzoglou
History of WGA
• 1982: -virus, 48,502 bp
• 1995: h-influenzae, 1 Mbp
• 2000: fly, 100 Mbp
• 2001 – present human (3Gbp), mouse (2.5Gbp), rat*, chicken, dog, chimpanzee,
several fungal genomes
Gene Myers
Let’s sequence the human
genome with the shotgun
strategy
That is impossible, and
a bad idea anyway
Phil Green
1997
CS262 Lecture 9, Win07, Batzoglou
Genomes Sequenced
• http://www.genome.gov/10002154