Embed Size (px)
Citation preview

CS181: Introduction to Machine Learning
Lecture 21 (MDPs and RL)
Spring 2021
Finale Doshi-Velez and David C. ParkesHarvard Computer Science

Example: House cleaning robot

GridWorld• r(s,a) = 0, except states
(1,4), (2,4). In these states get +1 or -1 when take ANY action. Then no more actions
• Bounce off obstacles. Actuator has 20% noise; e.g., w/ prob 0.1 goes L, prob 0.1 goes R when moving U
• Discounting 0.9 (r + 0.9 r + 0.92 r + …)
(D. Klein, P. Abbeel)

VI, GridWorld
(D. Klein, P. Abbeel) Noise 0.2, Discount 0.9

(D. Klein, P. Abbeel) Noise 0.2, Discount 0.9
VI, GridWorld
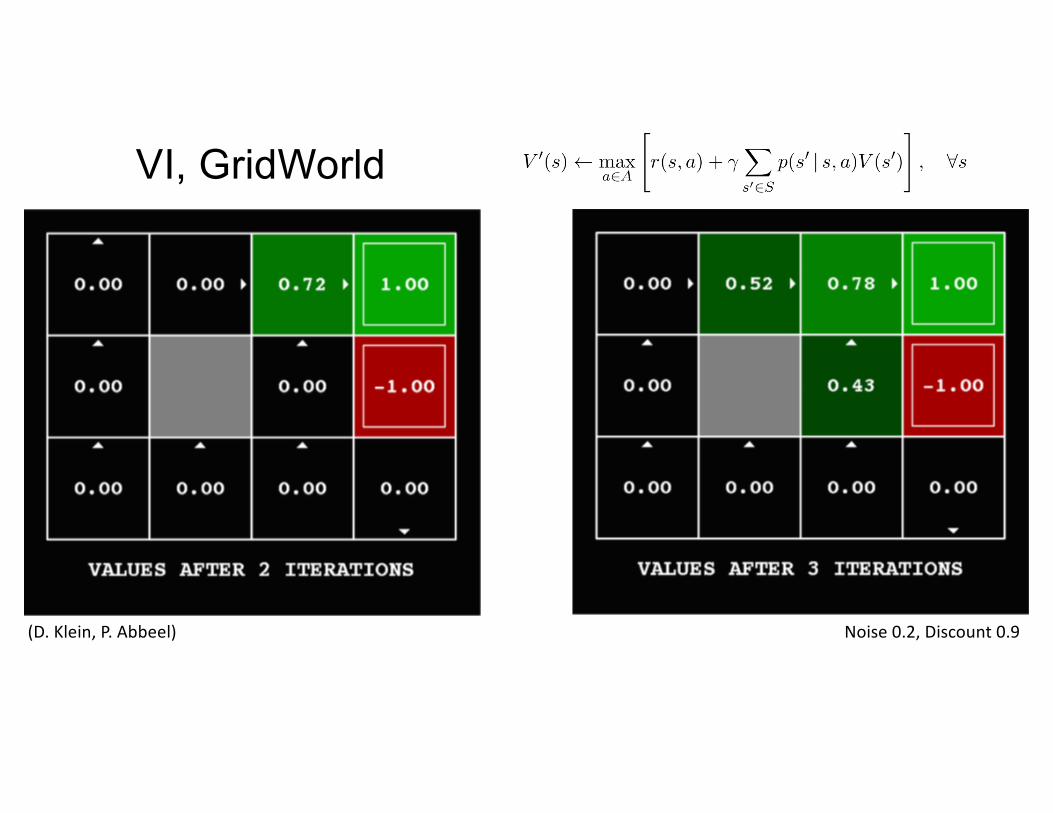
(D. Klein, P. Abbeel) Noise 0.2, Discount 0.9
VI, GridWorld

(D. Klein, P. Abbeel) Noise 0.2, Discount 0.9
VI, GridWorld

(D. Klein, P. Abbeel) Noise 0.2, Discount 0.9
VI, GridWorld

(D. Klein, P. Abbeel) Noise 0.2, Discount 0.9
VI, GridWorld

(D. Klein, P. Abbeel) Noise 0.2, Discount 0.9
VI, GridWorld

(D. Klein, P. Abbeel) Noise 0.2, Discount 0.9
VI, GridWorld

(D. Klein, P. Abbeel) Noise 0.2, Discount 0.9
VI, GridWorld

(D. Klein, P. Abbeel) Noise 0.2, Discount 0.9
VI, GridWorld

(D. Klein, P. Abbeel) Noise 0.2, Discount 0.9
VI, GridWorld

(D. Klein, P. Abbeel) Noise 0.2, Discount 0.9
VI, GridWorld

(D. Klein, P. Abbeel) Noise 0.2, Discount 0.9
VI, GridWorld


Policy Iteration
(Z. Kolter)pi0-> V0 -> pi1 -> V1After 1 improvement step
Don’t stop in goal states in this Grid World Initialize “up” everywhere
Rewards

Policy Iteration
(Z. Kolter)pi0-> V0 -> pi1 -> V1 -> pi2 -> V2After 2 improvement stepsRewards
Don’t stop in goal states in this Grid World

Policy Iteration
(Z. Kolter)pi0-> V0 -> pi1 -> V1 -> pi2 -> V2 -> pi3 -> V3After 3 improvement steps (converged!)Rewards
Don’t stop in goal states in this Grid World


GridWorld• r(s,a) = 0, except states
(1,4), (2,4). In these states get +1 or -1 when take ANY action. Then no more actions
• Bounce off obstacles. Actuator has 20% noise; e.g., w/ prob 0.1 goes L, prob 0.1 goes R when moving U
• Discounting 0.9 (r + 0.9 r + 0.92 r + …)
(D. Klein, P. Abbeel)

Can also look at Q-Values
(D. Klein, P. Abbeel) Noise 0.2, Discount 0.9






![Polynomial-Time Verification of PCTL Properties of MDPs with … · Verification algorithms for Markov Decision Processes (MDPs) [Hansson et al. ’94] Probabilistic Computation Tree](https://img.pdfslide.us/doc/110x75/5f699623e7f12a67df2b2375/polynomial-time-verification-of-pctl-properties-of-mdps-with-verification-algorithms.jpg)























