Embed Size (px)
Citation preview

Lecture originally by Luke Durant and Tamas Szalay
CS179 GPU Programming:CUDA Memory

CS179 GPU Programming
CUDA Memory Review of Memory Spaces Memory syntax Constant Memory Allocation Issues Global Memory Gotchas Shared Memory Gotchas Texture Memory Memory best practices
2
CS179 GPU Programming
Review
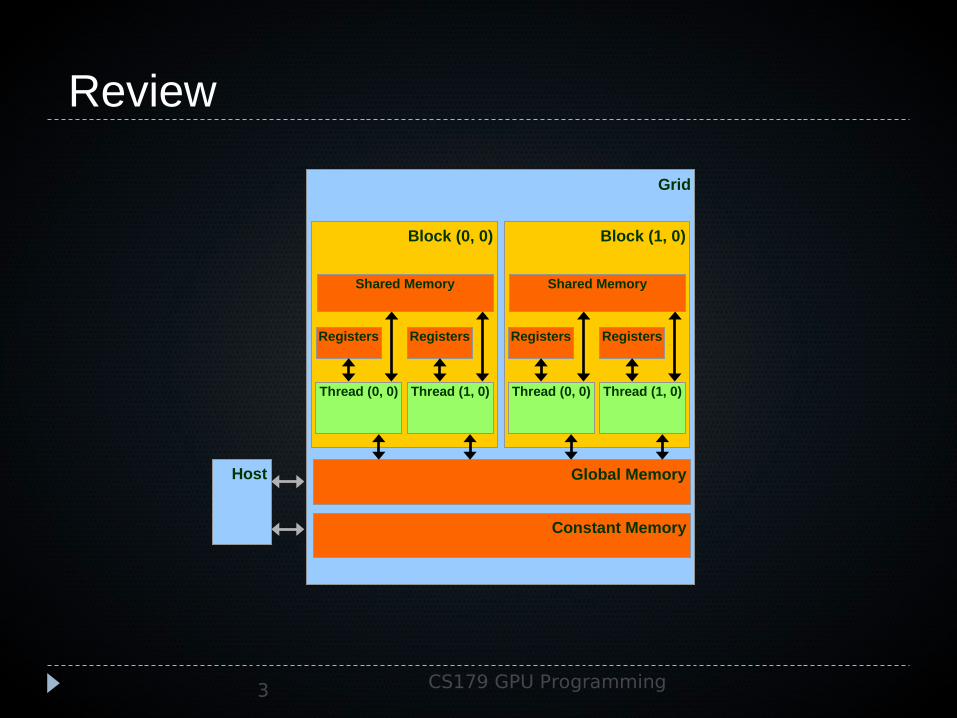
Grid
Global Memory
Block (0, 0)
Shared Memory
Thread (0, 0)
Registers
Thread (1, 0)
Registers
Block (1, 0)
Shared Memory
Thread (0, 0)
Registers
Thread (1, 0)
Registers
Host
Constant Memory
3

CS179 GPU Programming
Registers
Registers are read/write per-thread– Can’t access registers outside of each thread
Physically stored in each MP Can’t index
– No arrays…
4

CS179 GPU Programming
Local Memory Also read/write per thread Can’t read other thread’s local memory Can index
– This is where local arrays go
5

CS179 GPU Programming
Shared Memory Read/write per-block All threads in a block share the same memory In general, pretty quick
Certain cases can hinder this
6

CS179 GPU Programming
Global Memory Read/write per-application Can share between blocks, and grids Persistent across kernel executions Completely un-cached Really slow
7

CS179 GPU Programming
Constant Memory Read-only from device Cached in each MP Cache can broadcast to every thread currently
running – super efficient!
8

CS179 GPU Programming
Texture Memory Read-only from Device 2D caching method – shared between two MPs Linear filtering available
9

CS179 GPU Programming
Syntax Register memory
This is the default for memory within a device function
No special syntax● Just declare your local variables as usual
Remember – no indexing = no array Obviously, can’t access from host code
10

CS179 GPU Programming
Syntax Local Memory
Remember, local to a thread, not necessarily a function
Can’t access/declare outside of thread Keyword: __device__ __local__ Or just __local__
11

CS179 GPU Programming
Syntax Shared Memory
Keyword: __device__ __shared__ Or just __shared__ Can’t have a pointer, use array instead
12

CS179 GPU Programming
Syntax: Global Device Memory Just __device__ outside of a function will give
global memory Can pass pointers to global memory into kernel,
unlike other memory areas cudaMalloc gives you global memory cudaMallocPitch gives you global memory with
more efficient pitch (talk about this soon) Probably want to pass the pitch to the kernel too
13

CS179 GPU Programming
Useful Functions for Global Memory cudaMemcpy
Takes device pointers into global memory cudaMemcpy2D
Memcpy arrays with differing pitches Remember to specify
cudaMemcpyHostToDevice, etc. Don’t mix up your host/global pointers!
14

CS179 GPU Programming
Useful Functions for Global Memory cudaMemcpyToSymbol
Instead of pointer, takes symbol or char*. DeviceToDevice or HostToDevice
cudaMemcpyFromSymbol DeviceToHost
Use cudaGetSymbolAddress and cudaGetSymbolSize to find symbols
15

CS179 GPU Programming
Syntax: Constant Memory Slightly awkward interface Define with __device__ __constant__ or
__constant__ Access from device code as-is Access from host code with
cudaMemcpyToSymbol– Can’t use pointers– Can’t dynamically allocate, even from host
16

CS179 GPU Programming
Useful Functions for Constant Mem cudaMemcpyToSymbol
Instead of pointer, takes symbol or char*. DeviceToDevice or HostToDevice
cudaMemcpyFromSymbol DeviceToHost
cudaGetSymbolAddress FAILS! Why?
All pointers are assumed to be in global space
17

CS179 GPU Programming
Syntax: Texture Memory Even more awkward than constant memory We’ll talk about this later today But first…
18

CS179 GPU Programming
Allocation Issues As noted, each block only runs on one
multiprocessor This means that the resources each block uses
determines the total number of blocks that can run per MP
Since we have limited MPs, and no swapping is done, this puts a limit on the number of blocks we can run
19

CS179 GPU Programming
Allocation Issues: Registers 32K of registers on each multiprocessor Each register is 4 bytes
– i.e. 8K registers per MP Registers are never swapped, so this is a hard
limit!
20

CS179 GPU Programming
Allocation Issues: Registers However, basically no rules on minimum
allocation size of registers You can have lots of threads that use a few
registers Or, a few threads that use many registers
– Watch out! You don’t want to waste parallel execution power
– In general, it’s a good idea to have more than one block running per MP
21

CS179 GPU Programming
Allocation Issues: Shared Memory 16KB of shared memory per MP Broken up into 1KB “banks”
We’ll talk about why this is important Again, this 16KB might be the limiting factor in
the number of blocks per MP
22

CS179 GPU Programming
Allocation Issues: Local Memory Local memory is not stored per-chip This means it usually is not a limiting factor for
number of total threads However, accesses are as slow as global
memory!– So, try not to use local arrays in kernels
23

CS179 GPU Programming
Warps To understand memory coalescing, we need to
understand the concept of a warp– Name comes from weaving – group of threads
In this context, it means a group of threads that are scheduled together
– In CUDA, a warp is 32 threads The fact that 32 threads are executing together is
important, but today we’ll just cover what this means for memory
24

CS179 GPU Programming
Warps In current hardware, “half-warps” (i.e. 16
threads) access memory at the same time– But this is not part of the CUDA standard and will
almost certainly change in the future
25

CS179 GPU Programming
Memory Coalescing Remember, Global memory accesses are
SLOW! Often we want to access data indexed by the
thread ID Luckily, under certain conditions there is
hardware support to copy chunks of data at once
Ensuring this occurs is called “memory coalescing”
26

CS179 GPU Programming
Aligned Accesses Threads can read 4, 8, or 16 bytes at a time
from global memory.– However, only if accesses are aligned!
4 byte reads must be aligned to 4-byte boundaries, 8 byte reads must be aligned to 8-byte boundaries, etc.
So, which takes longer: reading 16 bytes from address 0xABCD0 or 0xABCDE?
27

CS179 GPU Programming
Aligned Accesses Built-in types force correct alignment
Note that this means float3 takes up the same amount of space as float4!
Arrays of float3 are NOT aligned! For structs, use the __align__(x) keyword
x = 4, 8, 16
28

CS179 GPU Programming
Memory Coalescing Multiple threads making coalesced accesses
are much faster Coalesced means:
Contiguous In-order – i.e. thread 0 takes index 0, thread 15 takes
index 15 Aligned to a multiple of the total data size
i.e. if accessing 4-byte float, thread 0 should access a multiple of 4*16!
29

CS179 GPU Programming
Memory Coalescing Luckily, cudaMalloc already aligns the start of
each block for you– Remember to use cudaMalloc2D for 2-dimensional
arrays so that each row will be aligned as well
30

CS179 GPU Programming
Memory Coalescing
: ● Fast!– Contiguous
– In-order
– Accesses aligned
31

CS179 GPU Programming
Memory Coalescing
● Slow:– Thread 2 and 3 do
not access in order
– Thread accesses not aligned

CS179 GPU Programming
Memory Coalescing
● Slow:– Address skipped
– Not in order
33

CS179 GPU Programming
Memory Coalescing: New Hardware On the newest cards, memory coalescing
restrictions are slightly relaxed Sequentialness is no longer mandatory – you
can have random access within an aligned chunk
34

CS179 GPU Programming
Memory Coalescing: New Hardware It will try to get around misaligned accesses by
grabbing a bigger chunk i.e. accessing 64B from 0x101 will access 128B from
0x100 Can’t always do this - 256B is the maximum
read/write size Also, has to be “sort of” aligned
No way to convert 64B from 0x078 to 1 aligned 128B access
35

CS179 GPU Programming
Shared Memory Shared memory is generally pretty fast, since
it’s on-chip To maximize usage, we want each thread in a
half-warp to use shared memory at the same time
This can only happen in certain situations – similar in concept to global memory coalescing However, shared memory is optimized for different
use cases
36

CS179 GPU Programming
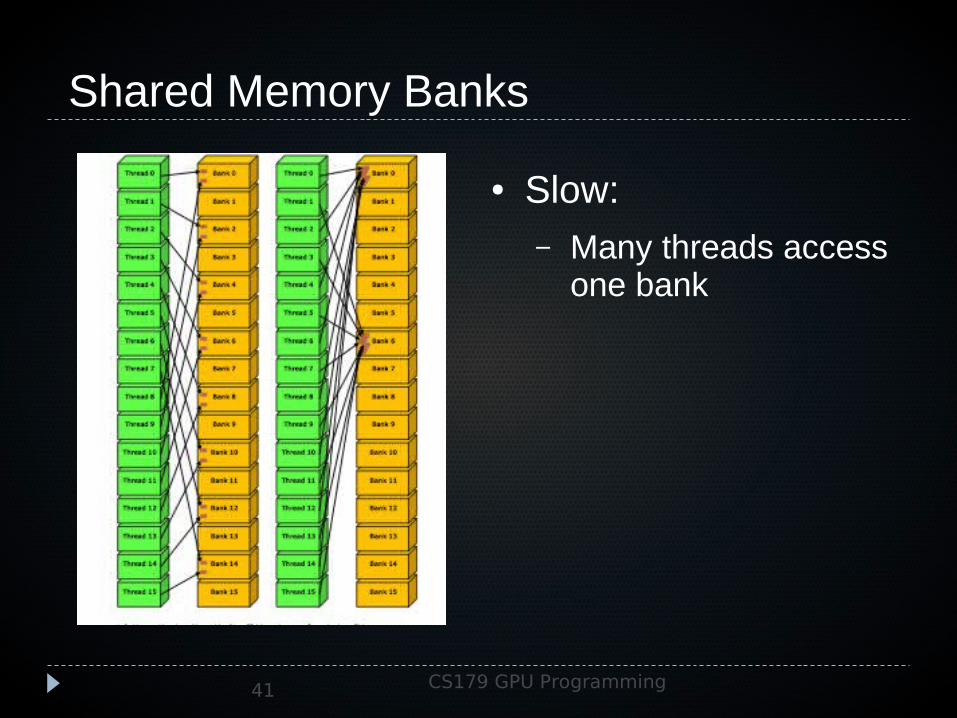
Shared Memory Banks Shared memory is divided into 1K banks
Each bank can service one thread at a time If multiple threads access the same bank, one
of them will have to wait Again, it’s thread safe in the sense that both
operations will occur, but the order is undefined
37

CS179 GPU Programming
Shared Memory Banks Each bank services 32 bit words at addresses
mod 16 * 4 = 64.– i.e. bank 0 services 0x00, 0x40, 0x80, … – Bank 1 services 0x04, 0x44, 0x84, …
Unlike in global memory in older hardware, no need for threads to do sequential accesses – Bank 1 has no special connection with Thread 1, for example
38

CS179 GPU Programming
Shared Memory Banks Want to avoid multiple threads accessing the
same bank Don’t close-pack data – keep everything spread out
by at least 4 bytes Split data elements that are more than 4 bytes into
multiple accesses Watch out for structures with even strides
39

CS179 GPU Programming
Shared Memory Banks
● Fast!– One thread, one
bank
– Even misaligned case is fast
40
CS179 GPU Programming
Shared Memory Banks
● Slow:– Many threads access
one bank
41

CS179 GPU Programming
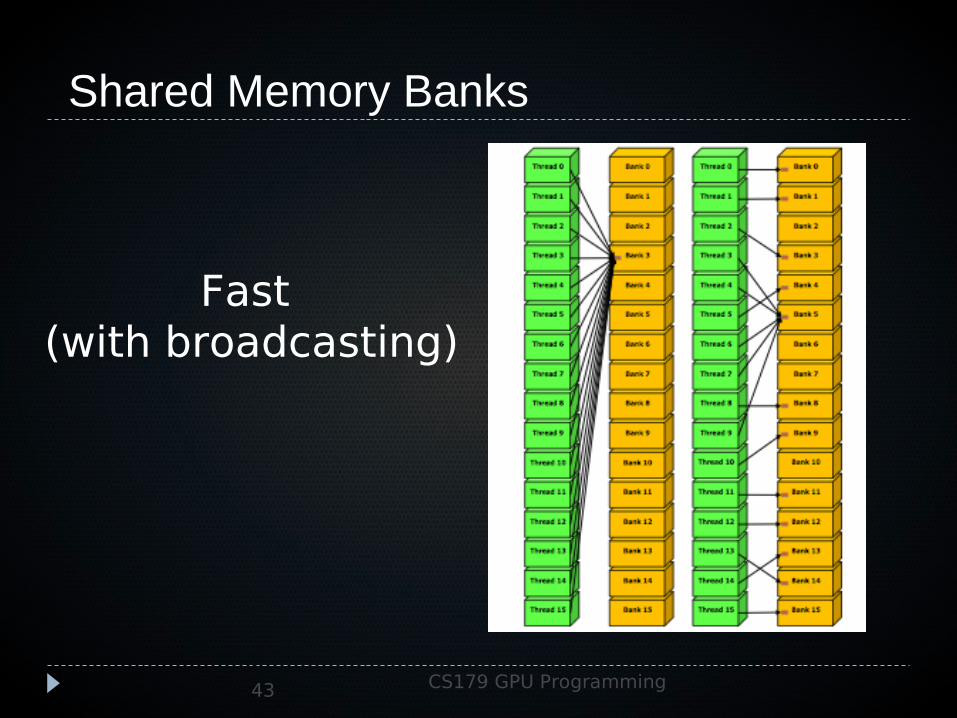
Shared Memory Banks One helpful feature for reading from memory
banks: broadcast!– If multiple threads read the same address at the
same time, only one read will be performed, and the data will be broadcast to all reading threads
42
CS179 GPU Programming
Shared Memory Banks
Fast (with broadcasting)
43

CS179 GPU Programming
Notes on Constants and Textures. Both of these memories have two levels of
caching– To achieve good usage, locality is far more
important than alignment– Textures use 2D locality rules
In general, writing optimized accesses to constants is about what you’d expect from CPU coding
44

CS179 GPU Programming
Syntax: Texture Space Syntax similar to GLSL textures
“CUDA arrays” are stored in texture memory and accessed only from texture lookups on device side
You can declare regions of global memory as “texture memory”, but you lose many benefits. No support for wrapping/clamping No support for floating point coordinates No support for filtering
45

CS179 GPU Programming
Textures from Linear Memory However, still get caching benefits
– Since cache is stored on-chip, don’t have to worry so much about coalescing
Step1: Creating texture ref– Use templates (C++)– texture<Type> texRef;– Type: float, float4, etc.
Step 2: Bind memory to texture reference– cudaBindTexture(0, texRef, devPtr, size);
46

CS179 GPU Programming
Performing Texture Fetches Special syntax for accessing textures in device
code Must get texRef from host somehow – probably
parameter to kernel. Remember texRef is a templated type
Accessing is simple: tex1Dfetch(texRef, x);
x is an int!
47

CS179 GPU Programming
Texture Fetch Extra Feature If you want, you can convert ints to normalized
floats automatically (fast) To do this, set the readmode of the texRef texRef<unsigned char, 1,
cudaReadModeNormalizedFloat> 0 -> 0.0 255 -> 1.0
Here, the 1 is for 1 dimensional texture
48

CS179 GPU Programming
Important Caveat Since this “texture” is stored in global memory, it
is possible to write to it from the same kernel that is reading from it
– While this is possible, this is a TERRIBLE idea!– Even without caching, it’s a synchronization
nightmare Nothing is done in hardware to keep texture
caches coherent with global memory
49

CS179 GPU Programming
More notes on linear “textures” Dimension is forced to be 1
– This means if you’re doing some sort of 2D array, pitch might not be ideal
● Because of caching, doesn’t really matter
However, caching is done assuming 1D locality accesses
Conclusion: Since this isn’t really read-write, might as well use “real” textures, i.e. CUDA arrays
50

CS179 GPU Programming
CUDA Arrays CUDA Arrays live in texture memory space, and
can only be accessed through texture fetches– This allows us to use some of the hardware
support for texturing, which might come in handy, even for non-graphics applications
Most of our options here will look familiar from GLSL
51

CS179 GPU Programming
CUDA Arrays Step 1: Create “channel description”
Describes what format the texture is in cudaCreateChannelDesc(int x, int y, int z, int w, enum
cudaChannelFormatKind f); cudaChannelFormatKindFloat, …Signed, or …
Unsigned x, y, z, w are number of bytes in each field
52

CS179 GPU Programming
CUDA Arrays Step 2: Allocate array
Similar to global memory, however we MUST dynamically allocate
cudaMallocArray Takes channel desc as a parameter
Most available functions to interface with global memory are available for arrays cudaMemcpyToArray, etc
53

CS179 GPU Programming
CUDA Arrays Step 3: Create texRef:
Same as global memory case, but type *must* match channelDesc given when you allocated array:
texture<Type, Dim, ReadMode> texRef Step 4: Edit texture settings
Settings are encoded as members of the texRef struct
54

CS179 GPU Programming
CUDA Array Parameters normalized
– Texture coords go from 0->1 filterMode
– Point or Linear– No 3D texture support– Linear has basically no guarantees on
precision/accuracy addressMode
– Clamp or Wrap All these are ignored for linear mode textures
55

CS179 GPU Programming
CUDA Arrays Step 5: Bind Texture reference
cudaBindTextureToArray(texRef, array); Access it from device code in a similar way:
tex1DFetch(texRef, x) Here, x is an int, or a float if normalized
tex2DFetch(texRef, x, y) Again, x and y are ints or normalized floats
Remember, coords are either clamped or wrapped
56

CS179 GPU Programming
One Final note on Textures Textures are cached in two levels Texture caches are shared between pairs of
MPs
57

CS179 GPU Programming
Memory Best Practices Remember, the key to optimization in CUDA is
to balance memory optimization with parallelism In general:
– More blocks/threads = more parallel– Fewer blocks/threads = better memory usage
58

CS179 GPU Programming
Memory Best Practices The balance usually lies with better memory
accesses, until multiprocessors begin idling
59

CS179 GPU Programming
Memory Best Practices Better coalescing means less time waiting for
data, which means less latency. In general, you should break up the problem so
you can do coalesced copies into shared memory
– Then do processing in shared memory without bank conflicts, and copy back into global memory
60





























