Embed Size (px)
Citation preview

CS 7960-4 Lecture 25
Wire Delay is not a Problem for SMT
Z. Chishti, T.N. VijaykumarProceedings of ISCA-31
June, 2004

Prior Results
• Hrishikesh et al. [ISCA’02]: Optimal pipeline depth is 6-8 FO4 at 100nm technology
• Agarwal et al. [ISCA’00]: IPCs will decrease dramatically due to wire delays
Goals:• How does pipeline depth vary with technology?
• How does SMT influence thruput and pipeline depth?
• Identify and alleviate bottlenecks (bandwidth)
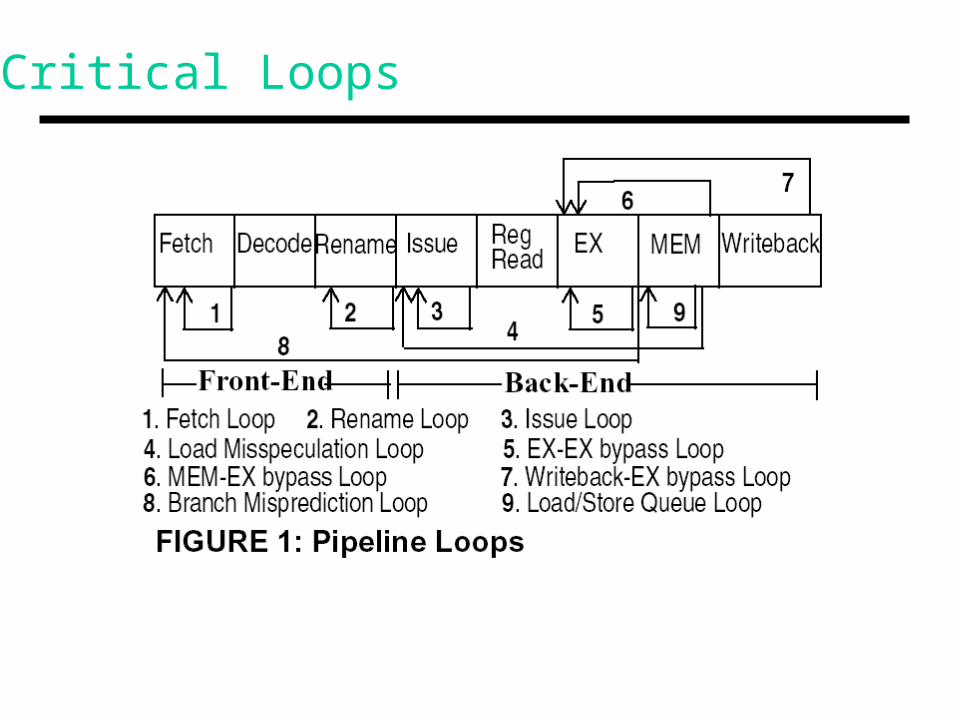
Critical Loops

Back-to-Back Instructions
• The loop lengths determine the delay between back-to-back dependent instructions
• Some loops can be optimized with aggressive designs (rename, ALUs)
• Difficult loops: cache access, branch prediction

Superscalar vs. SMT
• For superscalars, deep pipelining more overheads in each loop more delay between b2b instrs performance loss
• For SMT, slowing a dependence chain is not a problem – can find other useful work
• Deep pipelines can benefit SMT since it affords more parallelism – how do you build deep pipelines?

Wire Delays and Bandwidth
• Wire delays can limit bandwidth in RAM/CAMs – they control the delay between successive accesses
• Bitline signals are weak – a latch can be introduced only after the sense-amp

Bitline-Scaling
Decode
Mux+output driver
Latency-optimizedLow bandwidth
Low latency Bitline-scaledHigh bandwidth
High latency

Delay Results

Examining Deep Pipelines
• Bitline-scaling allows high bandwidth enables deep pipelining (high parallelism, longer chains)
• Range of implementations: b2b: aggressive design that allows instrs to issue back-2-back in spite of long loops nb2b: low-complexity design that can severely limit single-thread ILP

Effect of Wire Delays on IPC
• Assumes that all structures are perfectly pipelined

Effect of Technology on Pipeline Depth
• For a single thread, as we move from 100nm50nm, optimal depth goes from 810 and 68 FO4, for nb2b and b2b
• Multiprogrammed workload remains at 8 (nb2b) and 6FO4 (b2b)
• Multiprogramming lets you keep up with Moore’s Law

Effect of Bandwidth Constraints
• Perfect has the latency of latency-optimized and the bandwidth of bitline-scaled
• l-o does well for single-thread, but very poorly for five threads

Conclusions
• For superscalars, the optimal logic depth shall grow because of longer wire delays and lack of parallelism
• SMT is unaffected – has parallelism to offset back-2-back inefficiencies
• SMT meets Moore’s Law expectations by increasing the number of threads
• SMT has high bandwidth needs – soln: bitline-scaling

Title
• Bullet





























