Embed Size (px)
Citation preview

CS 7810
• Paper critiques and class participation: 25%
• Final exam: 25%
• Project: Simplescalar (?) modeling, simulation, and analysis: 50%
• Read and think about the papers before class!
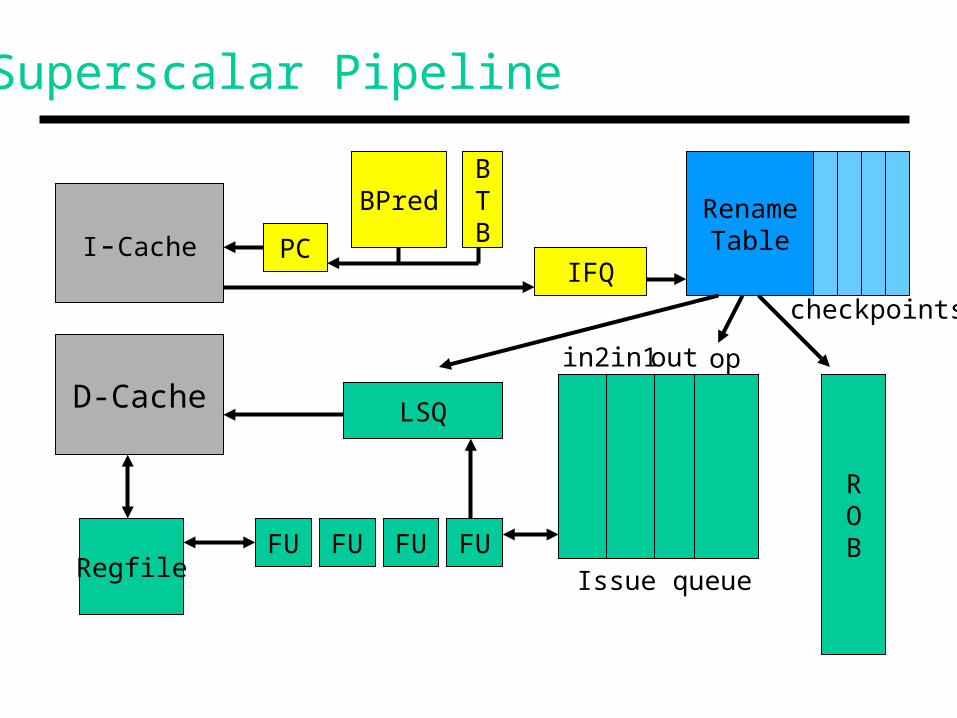
Superscalar Pipeline
I-Cache PC
BPredBTB
IFQ
RenameTable
ROBFU
LSQD-Cache
checkpoints
Issue queue
opin1in2 out
FUFUFURegfile
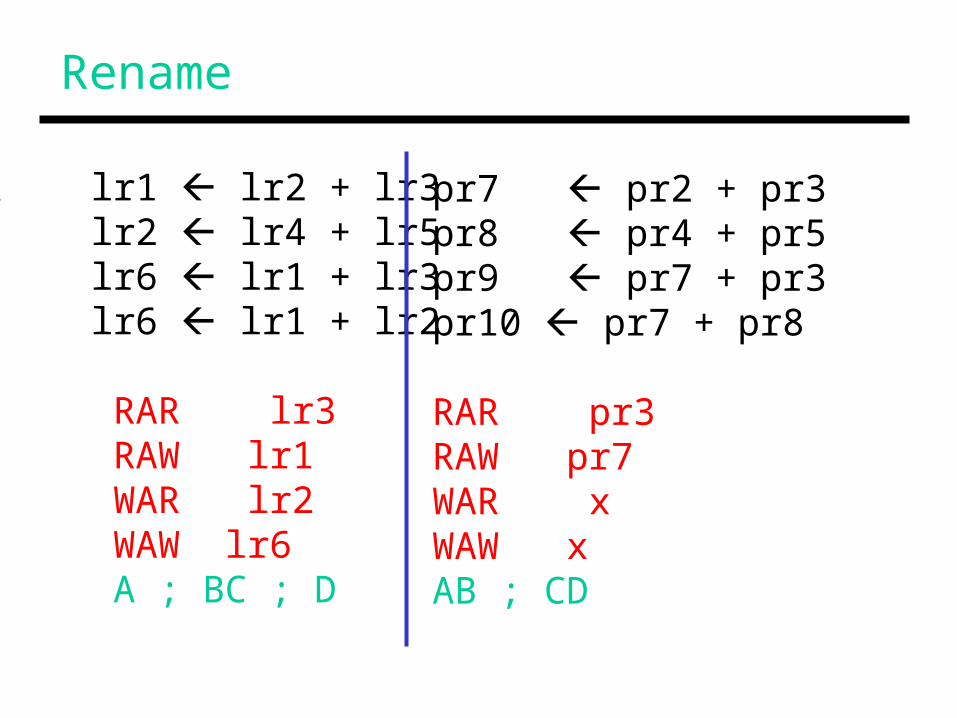
Rename
A lr1 lr2 + lr3B lr2 lr4 + lr5C lr6 lr1 + lr3D lr6 lr1 + lr2
RAR lr3 RAW lr1 WAR lr2 WAW lr6 A ; BC ; D
pr7 pr2 + pr3pr8 pr4 + pr5pr9 pr7 + pr3pr10 pr7 + pr8
RAR pr3RAW pr7WAR xWAW xAB ; CD
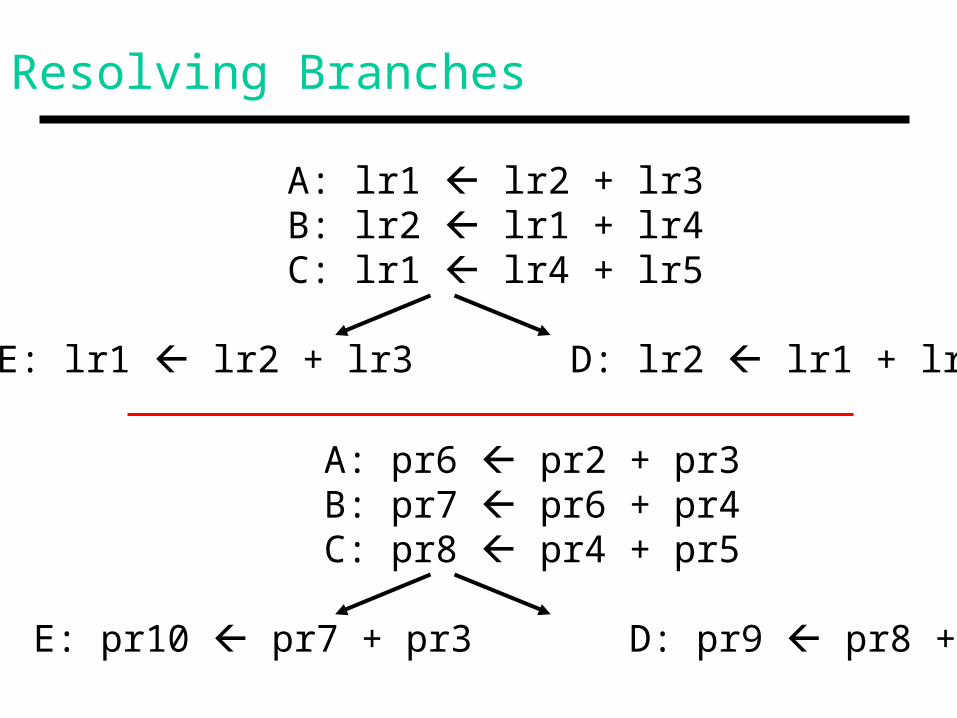
Resolving Branches
A: lr1 lr2 + lr3 B: lr2 lr1 + lr4 C: lr1 lr4 + lr5
E: lr1 lr2 + lr3 D: lr2 lr1 + lr5
A: pr6 pr2 + pr3 B: pr7 pr6 + pr4 C: pr8 pr4 + pr5
E: pr10 pr7 + pr3 D: pr9 pr8 + pr5

Resolving Exceptions
A lr1 lr2 + lr3B lr2 lr1 + lr4 brC lr1 lr2 + lr3D lr2 lr1 + lr5
pr6 pr2 + pr3 pr7 pr6 + pr4 br pr8 pr7 + pr3 pr9 pr8 + pr5
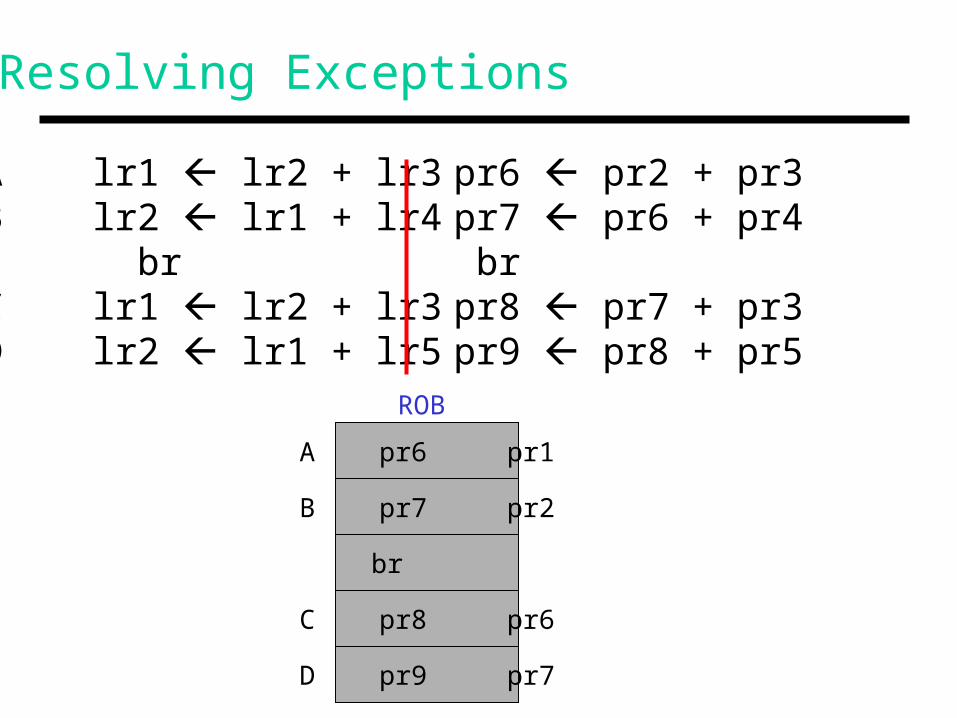
Resolving Exceptions
A lr1 lr2 + lr3B lr2 lr1 + lr4 brC lr1 lr2 + lr3D lr2 lr1 + lr5
pr6 pr2 + pr3 pr7 pr6 + pr4 br pr8 pr7 + pr3 pr9 pr8 + pr5
A pr6 pr1
B pr7 pr2
C pr8 pr6
D pr9 pr7
ROB
br

LSQ
Ld/St Address Data Completed
Store Unknown 1000 --
Load x40000000 -- --
Store x50000000 -- --
Load x50000000 -- --
Load x30000000 -- --

LSQ
Ld/St Address Data Completed
Store Unknown 1000 --
Load x40000000 -- --
Store x50000000 100 Yes
Load x50000000 -- --
Load x30000000 -- --

LSQ
Ld/St Address Data Completed
Store Unknown 1000 --
Load x40000000 -- --
Store x50000000 100 Yes
Load x50000000 100 Yes
Load x30000000 -- --

LSQ
Ld/St Address Data Completed
Store x45000000 1000 Yes
Load x40000000 -- --
Store x50000000 100 Yes
Load x50000000 100 Yes
Load x30000000 -- --
can commit
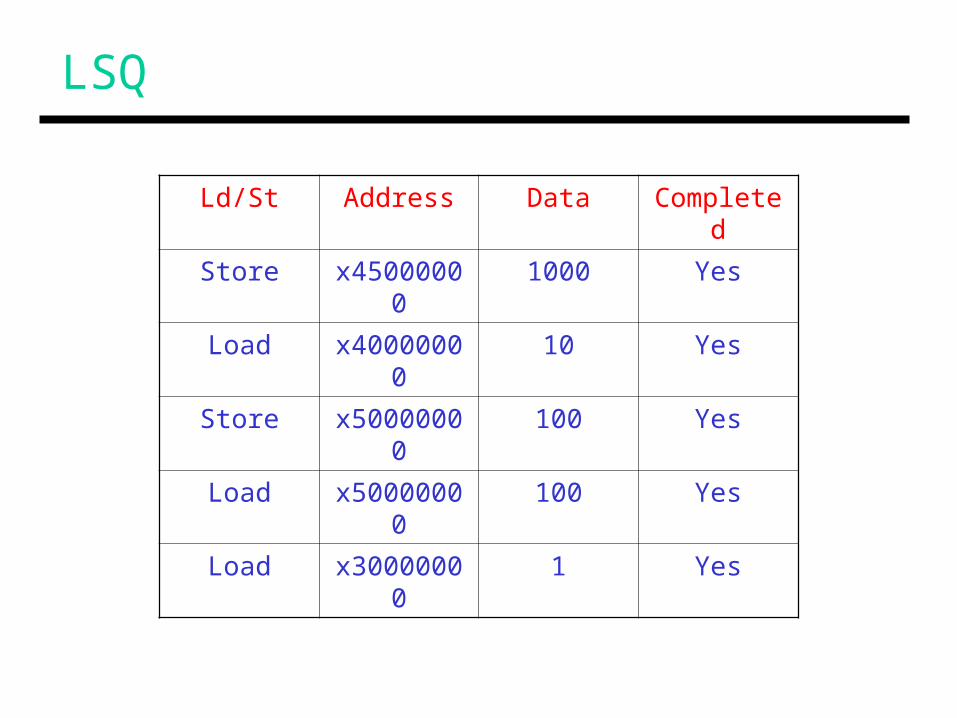
LSQ
Ld/St Address Data Completed
Store x45000000 1000 Yes
Load x40000000 10 Yes
Store x50000000 100 Yes
Load x50000000 100 Yes
Load x30000000 1 Yes
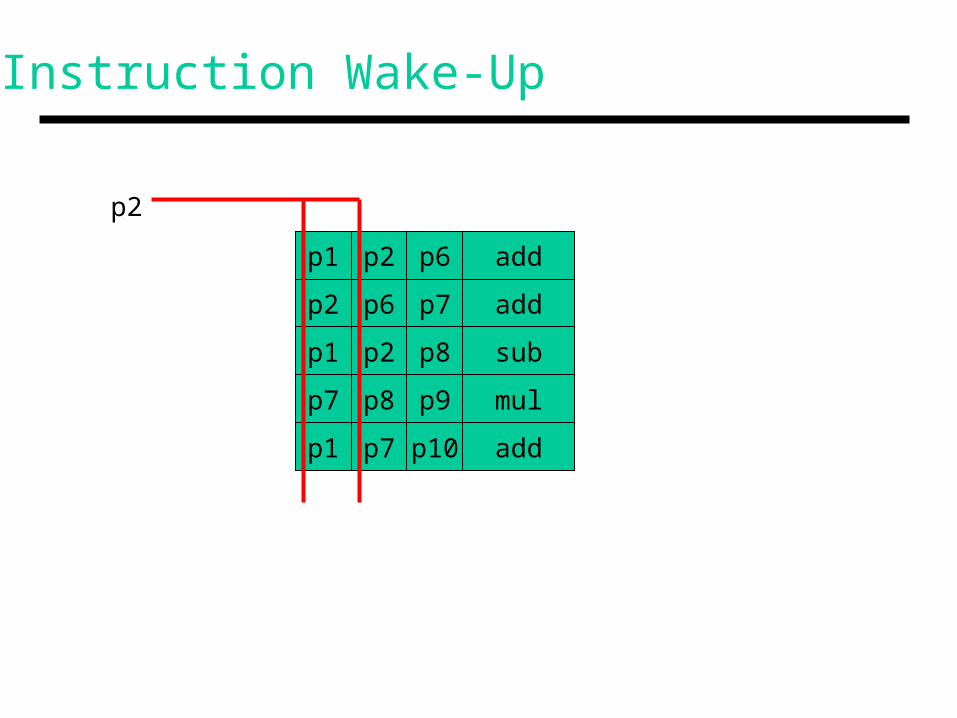
Instruction Wake-Up
addp6p1 p2
addp7
subp8
mulp9
addp10
p2 p6
p1 p2
p7 p8
p1 p7
p2

Paper I
Limits of Instruction-Level Parallelism
David W. WallWRL Research Report 93/6Also appears in ASPLOS’91

Goals of the Study
• Under optimistic assumptions, you can find a very high degree of parallelism (1000!)
What about parallelism under realistic assumptions?
What are the bottlenecks? What contributes to parallelism?

Dependencies
For registers and memory: True data dependency RAW Anti dependency WAR Output dependency WAW
Control dependency
Structural dependency

Perfect Scheduling
For a long loop: Read a[i] and b[i] from memory and store in registers Add the register values Store the result in memory c[i]
The whole program should finish in 3 cycles!!
Anti and output dependences : the assembly code keeps using lr1
Control dependences : decision-making after each iterationStructural dependences : how many registers and cache
ports do I have?

Impediments to Perfect Scheduling
• Register renaming• Alias analysis• Branch prediction• Branch fanout• Indirect jump prediction• Window size and cycle width• Latency

Register Renaming
lr1 … pr22 … … lr1 … pr22 lr1 … pr24 …
• If the compiler had infinite registers, you would not have WAR and WAW dependences• The hardware can renumber every instruction and extract more parallelism• Implemented models:
None Finite registers Perfect (infinite registers – only RAW)

Alias Analysis
• You have to respect RAW dependences for memory as well – store value to addrA load from addrA
• Problem is: you do not know the address at compile-time or even during instruction dispatch

Alias Analysis
• Policies: Perfect: You magically know all addresses and only delay loads that conflict with earlier stores
None: Until a store address is known, you stall every subsequent load
Analysis by compiler: (addr) does not conflict with (addr+4) – global and stack data are allocated by the compiler, hence conflicts can be detected – accesses to the heap can conflict with each other
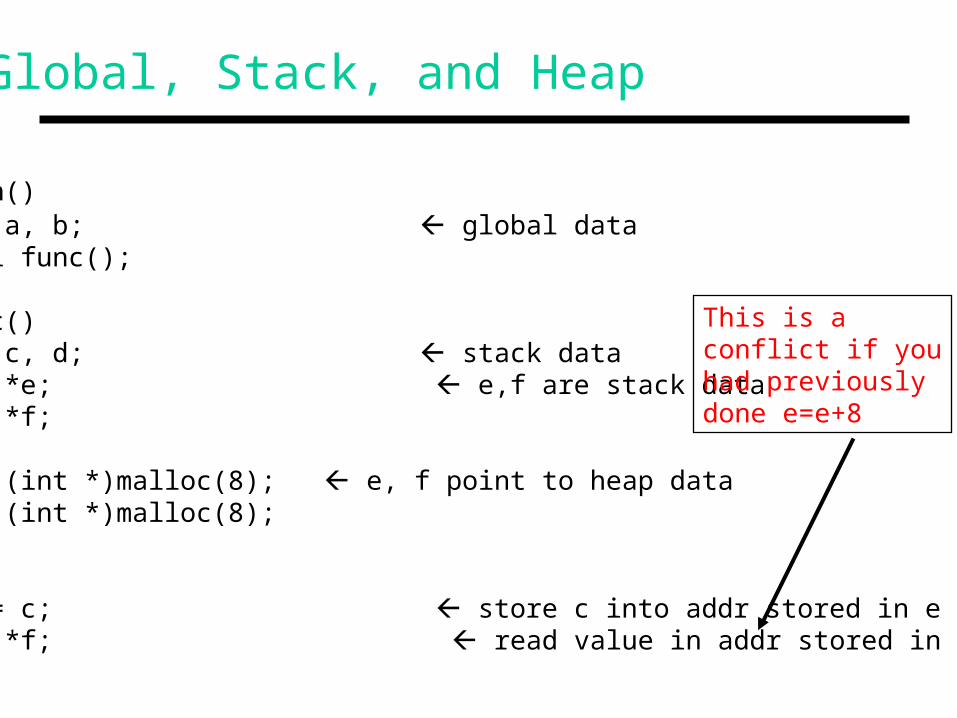
Global, Stack, and Heap
main() int a, b; global data call func(); func() int c, d; stack data int *e; e,f are stack data int *f; e = (int *)malloc(8); e, f point to heap data f = (int *)malloc(8); …
*e = c; store c into addr stored in e d = *f; read value in addr stored in f
This is aconflict if youhad previouslydone e=e+8

Branch Prediction
• If you go the wrong way, you are not extracting useful parallelism
• You can predict the branch direction statically or dynamically
• You can execute along both directions and throw away some of the work (need more resources)

Dynamic Branch Prediction
• Tables of 2-bit counters that get biased towards being taken or not-taken
• Can use history (for each branch or global)
• Can have multiple predictors and dynamically pick the more promising one
• Much more in a few weeks…

Static Branch Prediction
• Profile the application and provide hints to the hardware
• Dynamic predictors are much better

Branch Fanout
• Execute both directions of the branch – an exponential growth in resource requirements
• Hence, do this until you encounter four branches, after which, you employ dynamic branch prediction
• Better still, execute both directions only if the prediction confidence is low
Not commonly used in today’s processors.

Indirect Jumps
• Indirect jumps do not encode the target in the instruction – the target has to be computed
• The address can be predicted by using a table to store the last target using a stack to keep track of subroutine call and returns (the most common indirect jump)
• The combination achieves 95% prediction rates

Latency
• In their study, every instruction has unit latency -- highly questionable assumption today!
• They also model other “realistic” latencies
• Parallelism is being defined as cycles for sequential exec / cycles for superscalar, not as instructions / cycles
• Hence, increasing instruction latency can increase parallelism – not true for IPC
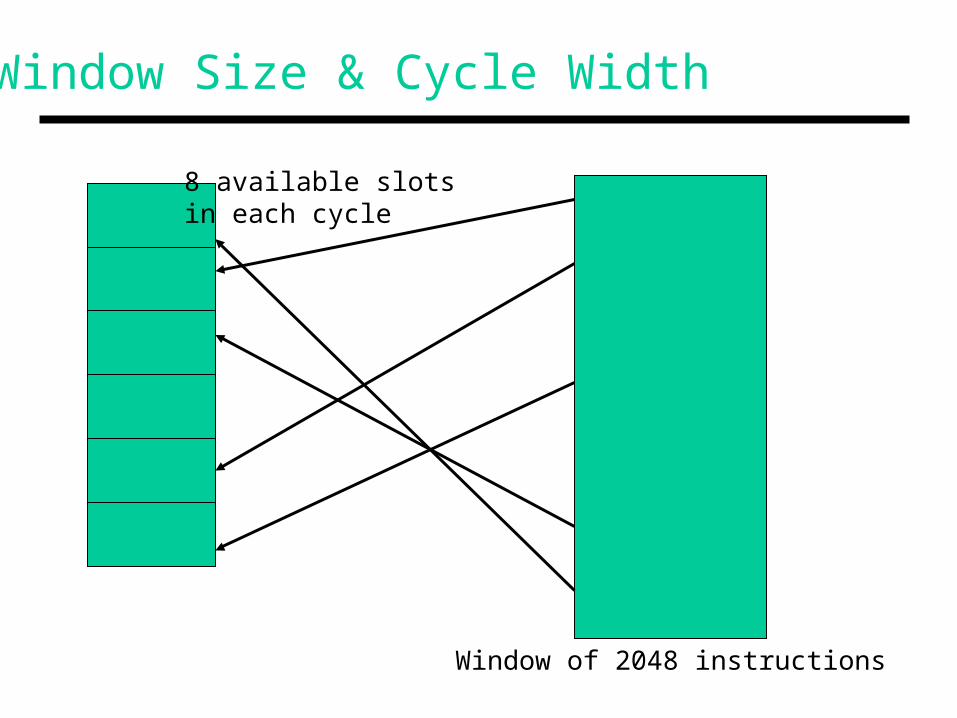
Window Size & Cycle Width
8 available slotsin each cycle
Window of 2048 instructions

Window Size & Cycle Width
• Discrete windows: grab 2048 instructions, schedule them, retire all cycles, grab the next window
• Continuous windows: grab 2048 instructions, schedule them, retire the oldest cycle, grab a few more instructions
• Window size and register renaming are not related

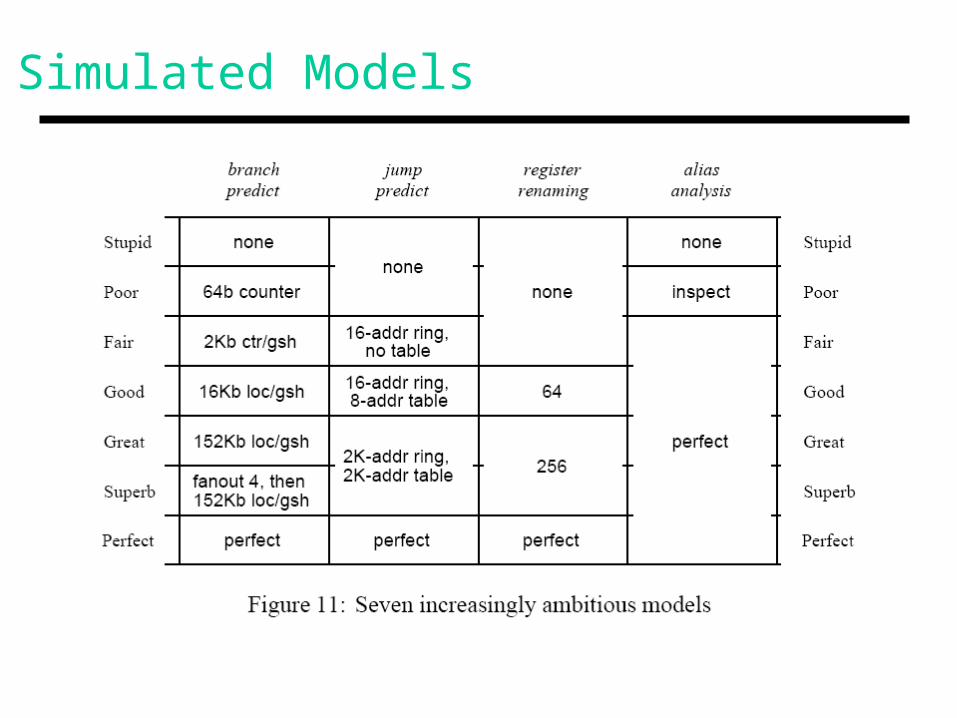
Simulated Models
• Seven models: control, register, and memory dependences
• Today’s processors: ?
• However, note optimistic scheduling, 2048 instr window, cycle width of 64, and 1-cycle latencies
• SPEC’92 benchmarks, utility programs (grep, sed, yacc), CAD tools
Simulated Models

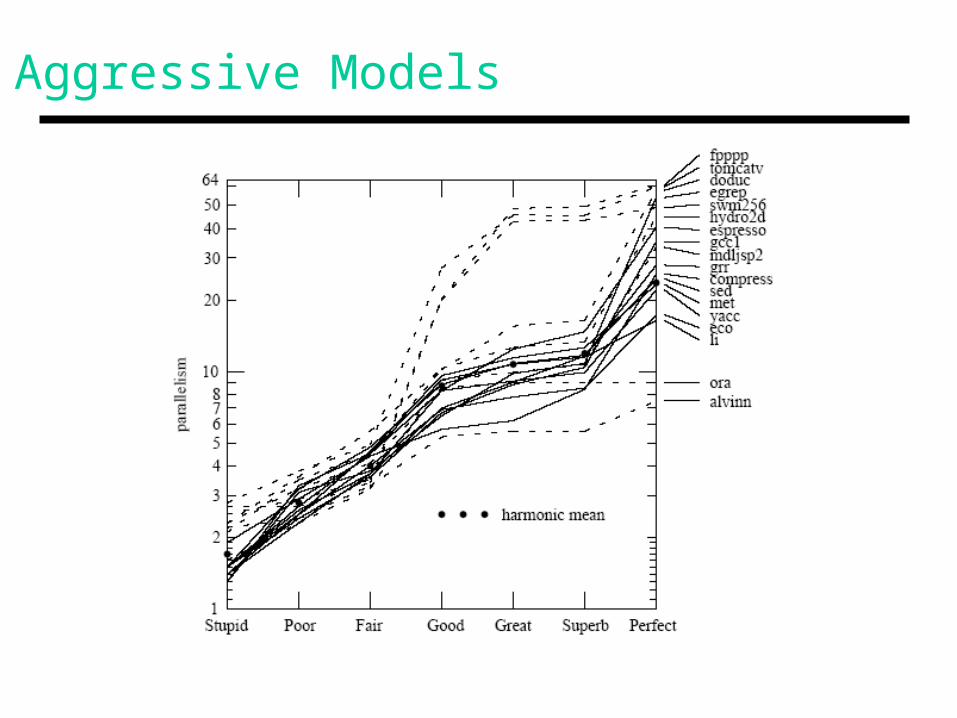
Aggressive Models
• Parallelism steadily increases as we move to aggressive models (Fig 12, Pg. 16)
• Branch fanout does not buy much
• IPC of Great model: 10 Reality: 1.5
• Numeric programs can do much better
Aggressive Models

Cycle Width and Window Size
• Unlimited cycle width buys very little (much less than 10%) (Figure 15)
• Decreasing the window size seems to have little effect as well (you need only 256?! – are registers the bottleneck?) (Figure 16)
• Unlimited window size and cycle widths don’t help (Figure 18)
Would these results hold true today?

Memory Latencies
• The ability to prefetch has a huge impact on IPC – to hide a 300 cycle latency, you have to spot the instruction very early
• Hence, registers and window size are extremely important today!

Branch Prediction
• Obviously, better prediction helps (Fig. 22)
• Fanout does not help much (Fig. 24-b) – not selecting the right branches?
• Luckily, small tables are good enough for good indirect jump prediction
• Mispredict penalty has a major impact on ILP (Fig. 30)
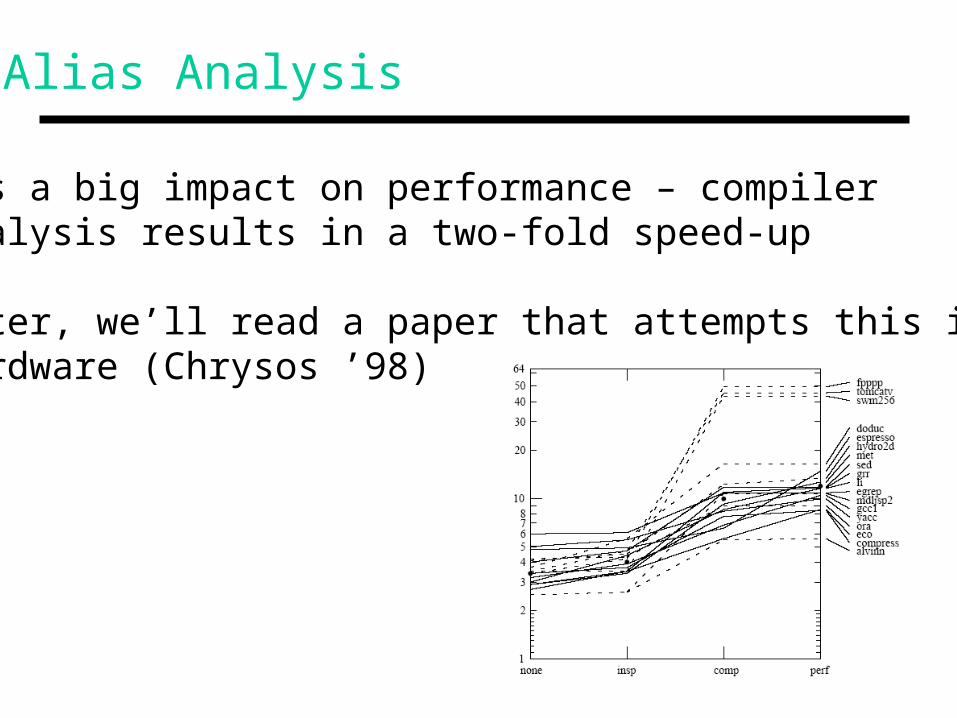
Alias Analysis
• Has a big impact on performance – compiler analysis results in a two-fold speed-up
• Later, we’ll read a paper that attempts this in hardware (Chrysos ’98)

Instruction Latency
• Parallelism almost unaffected by increased latency (increases marginally in some cases!)
• Note: “unconventional” definition of parallelism
• Today, latency strongly influences IPC

Conclusions of Wall’s Study
• Branch prediction, alias analysis, mispredict penalty are huge bottlenecks • Instr latency, registers, window size, cycle width are not huge bottlenecks
• Today, they are all huge bottlenecks because they all influence effective memory latency…which is the biggest bottleneck

Questions
• Weaknesses: caches, register model, value pred
• Will most of the available IPC (IPC = 10 for superb model) go away with realistic latencies?
• What stops us from building the following: 400Kb bpred, cache hierarchies, 512-entry window/regfile, 16 ALUs, memory dependence predictor?
• The following may need a re-evaluation: effect of window size, branch fan-out

Next Week’s Paper
• “Complexity-Effective Superscalar Processors”, Palacharla, Jouppi, Smith, ISCA ’97
• The impact of increased issue width and window size on clock speed

Title
• Bullet





























