Embed Size (px)
Citation preview

CS 620 Advanced Operating Systems
Lecture 4 – Distributed System Architectures
Professor Timothy Arndt
BU 331

Architectures
• We distinguish between software architectures (how are software module/components structured) and system architectures in which how the placement of the modules/components on several (distributed) machines is the main issue.
• In the rest of this lecture we will examine several different system architectures.

The Client-Server Model
– In this model, the system is structured as a collection of users (clients) and providers (servers) of services.
– This is an example of a centralized architecture

Clients and Servers
• General interaction between a client and a server.

Clients and Servers
• Example C source code for a simple file server structured as a client-server application is given in the following three slides.

An Example Client and Server (1)
• The header.h file for a trivial file server.

An Example Client and Server (2)
• A sample server - typically with infinite loop.

An Example Client and Server (3)
• A client using the server to copy a file.
1-27 b

Multitiered Architectures
• The decision of how to divide up the workload between the client and the server is essentially arbitrary – many different choices can be made– Running only a bare minimum of the
application on the client leads to the thin client approach
– For more powerful clients, to avoid overloading the server, we may adopt a fat client approach

Client-Server Architectures
• Alternative client-server organizations (a) – (e).
1-29

Multitiered Architectures
• The concept of client-server can be extended by having the server machine act as a client for another server (e.g. first server is the web server, second is the database server).– This gives us a three-tiered architecture.– The complete generalization of client-server is
a multitiered architecture.

Three-tiered Architecture
• An example of a server acting as a client.
1-30

Client-Server Clusters
• A single server can easily become overloaded.
• One solution is to replicate the server and use a single machine as a front end to redirect client requests.
• This can lead to the front end becoming a bottleneck.

Web Server Cluster
• An example of horizontal distribution of a Web service.
1-31

Client-Server Design Issues
– Addressing the server.• Need to specify the machine that the server is on
and the "process" number.• Actually it is more common to use the port number.• Server tells kernel that it wants to listen on this port.
– Can we avoid giving the machine name (location transparency)?• We could have each server pick a random number
from a large space (so the probability of duplicates is low).

Client-Server Design Issues
– When a client wants a service S it broadcasts an I need S and the server supplying S responds with its location. • So now the client knows the address.
– This first broadcast and reply can be used to eliminate duplicate servers (if desired) and different services accidentally using the same number.• Another method is to use a name server that has a
mapping from service names to locations (and ports).

Client-Server Design Issues
• At startup servers tell the name server their location.• Is the name server a bottleneck?
– We can replicate it and keep it consistent (horizontal distribution).
– Blocking vs. non-blocking.• Synchronous vs. asynchronous.• Send and receive synchronous is often called
rendezvous.• Asynchronous send: Do not wait for the message to
be received, return control immediately.– How can you re-use the message variable?

Client-Server Design Issues
• Have the kernel copy the message and then return. This costs performance.
• Don't copy but send an interrupt when message sent. This makes programming harder.
• Offer a system call to tell when the message has been sent.
– Similar to above but "easier" to program. – However it is difficult to guess how often to ask if the
message has been sent.
– Asynchronous Receive: Return control before kernel has filled in message variable with received messages.

Client-Server Design Issues
– How can this be useful?• Wait system call (until message available).• Test system call (has message arrived).• Conditional receive (receive or announce no
message yet).• Interrupt.• None of these is perfect.
– Timeouts• If we have blocking primitives, send or receive
could wait forever.• Some systems/languages offer timeouts.

Client-Server Design Issues
• Buffered vs. unbuffered.– If unbuffered, the receiver tells where to put
the message.• This doesn't work if an asynchronous send is done
before the receive (where does the kernel put the message?).
– For buffered, the kernel keeps the message (in a mailbox) until the receiver asks for it.• This raises buffer management questions.

Client-Server Design Issues
• Reliable vs. Unreliable Primitives– We can define the send primitive to be
unreliable.• Error checking is done at a higher level.
– Kernel can acknowledge every message.• Senders and repliers keep message until they receive
an ack.
– Kernel can use reply to ack every request but explicitly ack replies.

Client-Server Design Issues
– Kernel can use reply as ack to every request but not ack replies.• Client will resend request if the reply doesn’t reply
in time.• Not always good (e.g. if server had to work hard to
calculate reply).
– Kernel at client end can deliver request and send ack if reply not forthcoming soon enough. • Again it can either ack the reply or not.

The Client-Server Model

Decentralized Architectures
• Multitiered client-server architectures can be described as using vertical distribution– Analogy to vertical fragmentation in
distributed database systems
• If we distribute the processing in a uniform manner among the hosts, we are using horizontal distribution (analogy to horizontal fragmentation in ddbms)
• This describes peer-to-peer systems

Peer-to-Peer Architectures
• In the peer-to-peer approach, each system participating in the architecture has a similar role.– Each system acts as both client and server.– Key issues in P2P include
• Development of an abstract overlay network for communication among peers
• Partitioning the (tasks, workload, data items) among the peers
– Should do this in such a way as to achieve load balancing, ease of joining/leaving network, ease of locating resources, etc.

Structured Peer-to-Peer Architectures
• P2P networks can be either structured or unstructured.
• In a structured P2P network, the overlay network is constructed using a deterministic procedure.– A popular approach is to use an approach called
distributed hash table (DHT)• Nodes and data items are randomly assigned keys
from a large keyspace• The keyspace is then partitioned so that each node is
associated with a unique set of keys

Structured Peer-to-Peer Architectures
• A function f(k1, k2) defines the distance in the keyspace between two keys k1 and k2 – Each node is assigned a key which is used as an
ID.– A node with an ID ix owns all of the keys ky for
which the distance f(ix, ky) is minimum.
– The Chord DHT treats the keys as points on a circle and f(k1, k2) is the distance travelling clockwise around the circle from k1 to k2 • The overlay network is a logical ring

Structured Peer-to-Peer Architectures

Structured Peer-to-Peer Architectures
• A competitor to Chord is Content Addressable Network (CAN) – CAN uses a d-dimensional Cartesian coordinate
keyspace• The space is partitioned for each node in the system• Entering nodes cause a further partition of a region• Leaving nodes cause merging of two adjacent
regions• Overlay network is defined by the adjacency of
regions in the d-dimensional space
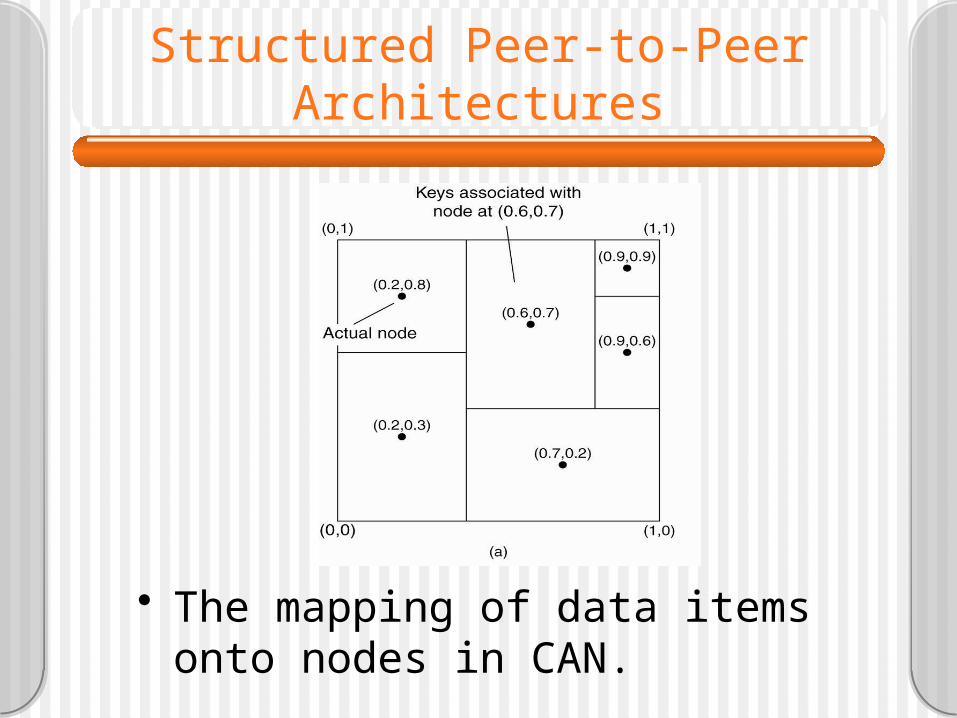
Structured Peer-to-Peer Architectures
• The mapping of data items onto nodes in CAN.

Structured Peer-to-Peer Architectures
• Splitting a region when a node joins.

Unstructured Peer-to-Peer Architectures
• Unstructured peer-to-peer systems used randomized algorithms for constructing an overlay network– Each node maintains a list of c neighbors
• Each of the neighbors represents a randomly chosen live node from the current set of nodes
• This is called a partial view• Nodes may regularly exchange entries from their
partial views with neighbors in order to update the list (this is how we handle newly arriving nodes and departing nodes)

The steps taken by the active thread.

The steps take by the passive thread

Combining Structured and Unstructured
• We can also have a two-layered approach which combines features of both structured and unstructured.
• By exchanging and selecting entries from partial views it is possible to construct and maintain specific topologies of overlay networks– The topology is built up over time as more and
more randomly selected nodes are passed up from lower to higher layer

Topology Management of Overlay Networks
• A two-layered approach for constructing and maintaining specific overlay topologies using techniques from unstructured peer-to-peer systems.

Topology Management of Overlay Networks (2)
• Generating a specific overlay network using a two-layered unstructured peer-to-peer system.

Superpeers
• We may differentiate between the functionality of the peers leading to a hierarchical arrangement with superpeers– The superpeers are connected in P2P manner– “Normal” peers are associated with a particular
superpeer (hierarchical organization)– Can ne used, for example, in a collaborative
content delivery network (CDN)

Superpeers
• A hierarchical organization of nodes into a superpeer network.

Hybrid Architectures
• Similar to the superpeer variant of P2P, we can combine client-server and P2P in a hybrid architecture
• Example: edge-server systems– Edge server acts as a server to end users clients
and as a peer with other edge servers.

Edge-Server Systems
• Viewing the Internet as consisting of a collection of edge servers.





























