Embed Size (px)
Citation preview

CS 4432 lecture #5 1
Data Items
Records
Blocks
Files
Memory
Next:
CS 4432 lecture #5 2
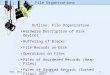
Goal : placing records into blocks
blocks ...
a file
assume fixedlength blocks
assume a single file (for now)
records

CS 4432 lecture #5 3
(1) separating records(2) spanned vs. unspanned(3) mixed record types – clustering(4) split records(5) sequencing(6) indirection
Options for storing records in blocks:
CS 4432 lecture #5 4
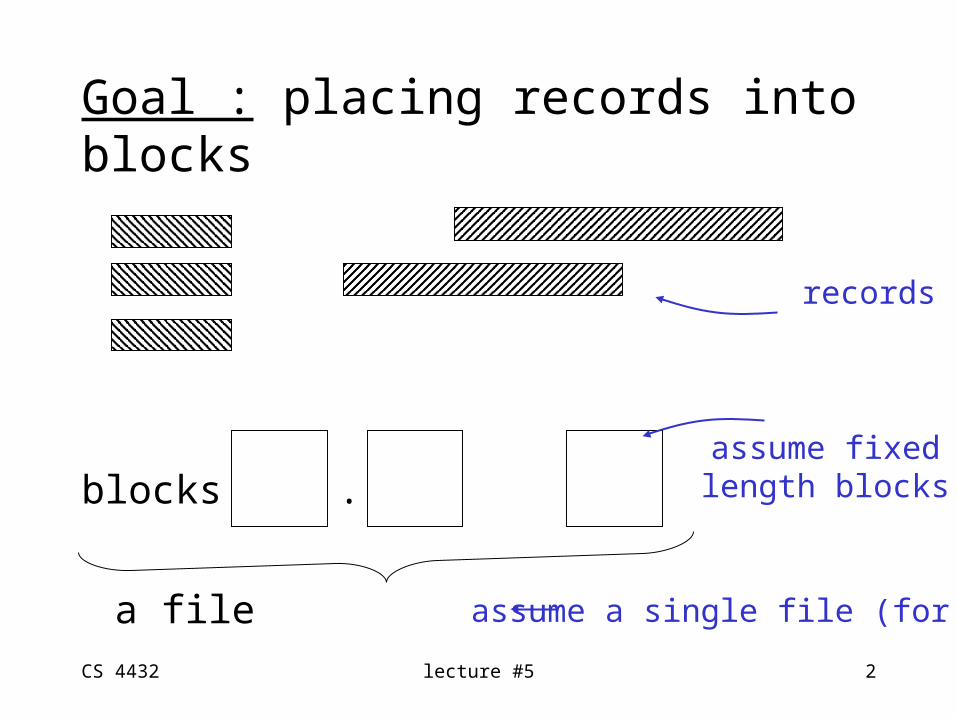
Block
(a) no need to separate if fixed size records.(b) or, use special marker(c) or, give record lengths (or offsets)
- within each record- in block header
(1) Separating records
R2R1 R3
CS 4432 lecture #5 5
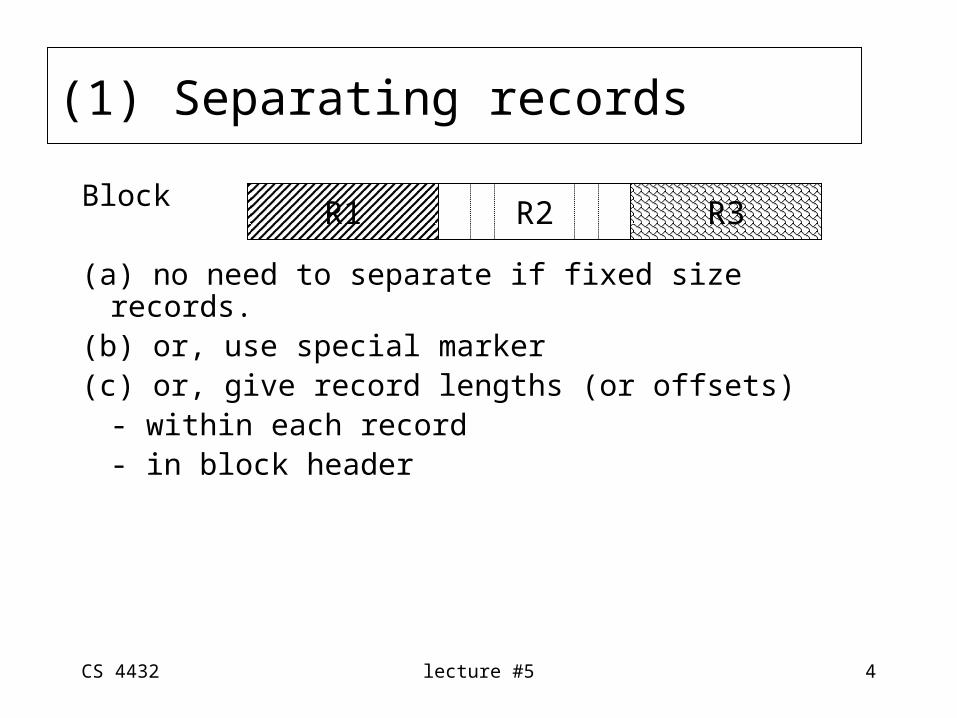
• Unspanned: records within one blockblock 1 block 2
...
• Spanned : records wrap across 2 blocks
block 1 block 2
...
(2) Spanned vs. Unspanned
R1 R2
R1
R3 R4 R5
R2 R3(a)
R3(b) R6R5R4 R7
(a)

CS 4432 lecture #5 6
• Unspanned is much simpler, but may sometimes waste space…
• Spanned essential if record size > block size
Spanned vs. unspanned:

CS 4432 lecture #5 7
Example
106 recordseach of size 2,050 bytes (fixed)block size = 4096 bytes
block 1 block 2
2050 bytes wasted 2046 2050 bytes wasted 2046
R1 R2
• Utiliz = 50% -> ½ of space is wasted

CS 4432 lecture #5 8
• Mixed - records of different types(e.g., EMPLOYEE, DEPT)allowed in same block
e.g., a block
(3) Mixed versus uniform record types
EMP e1 DEPT d1 DEPT d2

CS 4432 lecture #5 9
Why do we want to mix?
• Answer: CLUSTERING
Records that are frequently accessed together should beplaced into the same block

CS 4432 lecture #5 10
Example Clustering
Q1: select C_NAME, C_CITY, AMOUNT, …from DEPOSIT, CUSTOMERwhere DEPOSIT.C_NAME =
CUSTOMER.C.NAME
a blocklayout:
CUSTOMER,NAME=SMITH
DEPOSIT,NAME=SMITH
DEPOSIT,NAME=SMITH
CUSTOMER,NAME=JONES
Question: Good idea or bad idea ?

CS 4432 lecture #5 11
• If Q1 frequent with join on customer and deposit relations, then clustering good
• But if instead Q2 frequent with :Q2: SELECT *
FROM CUSTOMERthen clustering is counter-productive

CS 4432 lecture #5 12
Mixing of record types on one block?
Problems:
• Creates variable length records in block
• May cause us to store duplicates
• Insert/deletes are harder

CS 4432 lecture #5 13
Other Ideas ?
Compromise: No mixing, but keep related
records in same cylinder ...

CS 4432 lecture #5 14
(1) Separating records(2) Spanned vs. Unspanned(3) Mixed record types - Clustering(4) Split records(5) Sequencing(6) Indirection
Recap: Storing records in blocks

CS 4432 lecture #5 15
(1) separating records(2) spanned vs. unspanned(3) mixed record types – clustering(4) split records(5) sequencing(6) indirection
Options for storing records in blocks:

CS 4432 lecture #5 16
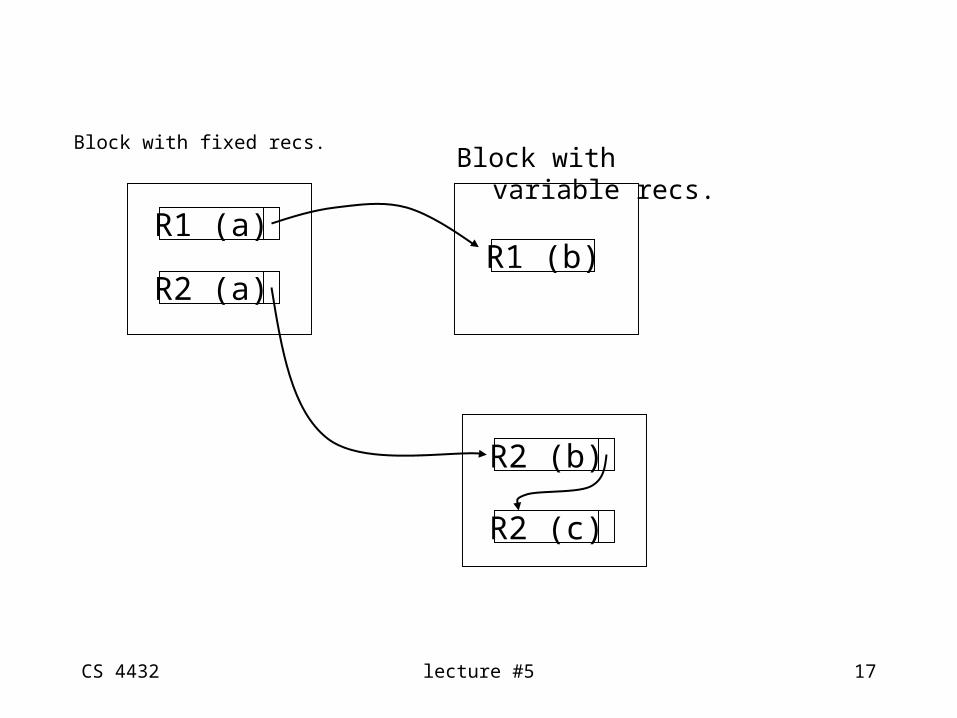
Fixed part in one block
Typically forhybrid format
Variable part in another block
(4) Split records
CS 4432 lecture #5 17
Block with fixed recs.
R1 (a)R1 (b)
Block with variable recs.
R2 (a)
R2 (b)
R2 (c)

CS 4432 lecture #5 18
• Ordering records in file (and thus blocks) by some key value– Sequential file ( sequenced file )
• Why sequencing ?– Typically maked it possible to efficiently read
records in order
(5) Sequencing

CS 4432 lecture #5 19
Sequencing Options
(a) Next record physically contiguous
...
(b) Linked
What about INSERT/ DELETE ?
Next (R1)R1
R1 Next (R1)
CS 4432 lecture #5 20
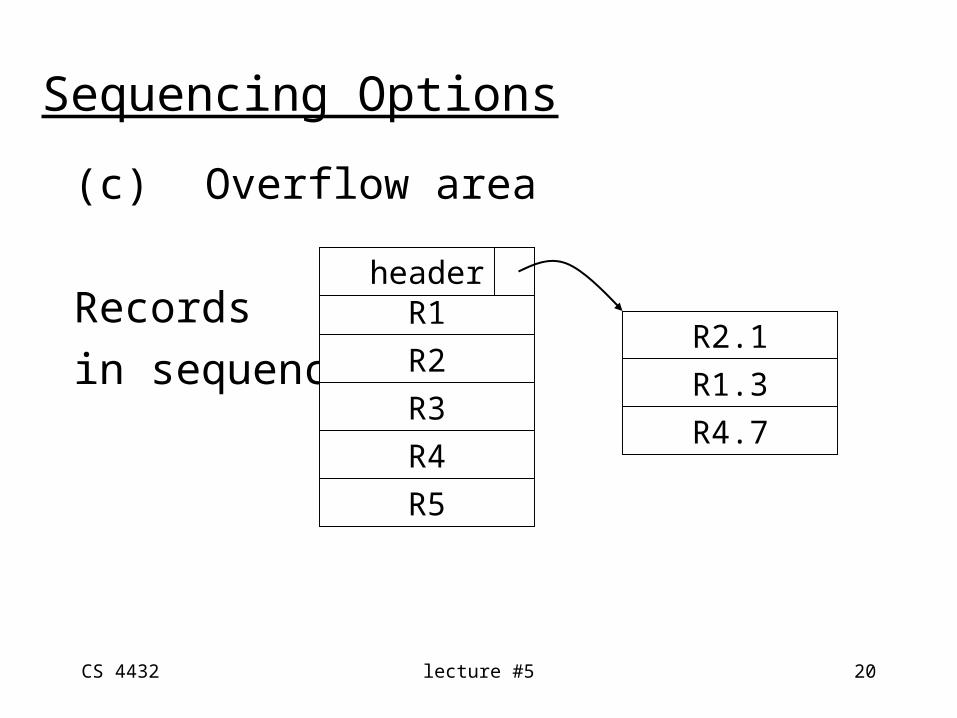
(c) Overflow area
Recordsin sequence
R1
R2
R3
R4
R5
Sequencing Options
header
R2.1
R1.3
R4.7

CS 4432 lecture #5 21
• How does one refer to records?
• Problem: Records can be on disk or in (virtual) memory. Need common address, but have different physical locations.
(6) Indirection Addressing
Rx
Many options: Physical Indirect
CS 4432 lecture #5 22
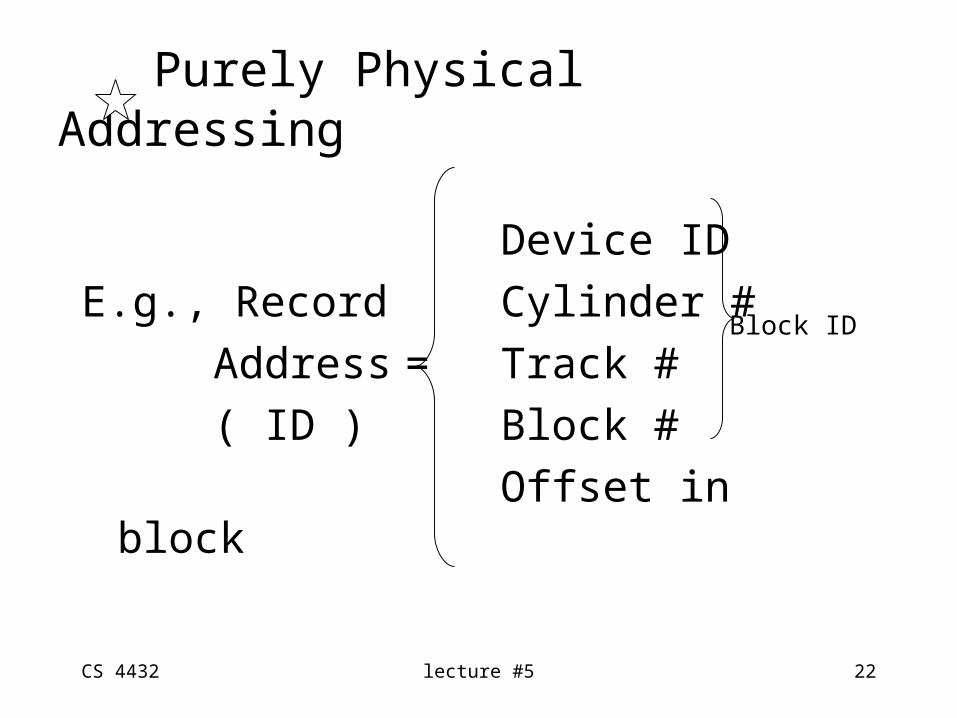
Purely Physical Addressing
Device ID E.g., Record Cylinder #
Address = Track #( ID ) Block #
Offset in block
Block ID

CS 4432 lecture #5 23
Fully Indirect Addressing
Solution: Record ID (Oracle: ROWID) as global address, maintain a map table.
Map Tablerec ID r address
a
Physicaladdr.Rec ID

CS 4432 lecture #5 24
Tradeoff
Flexibility Costto move records of indirection(for deletions, insertions) (lookup)
What to do : Options inbetween ?
Physical Indirect
CS 4432 lecture #5 25
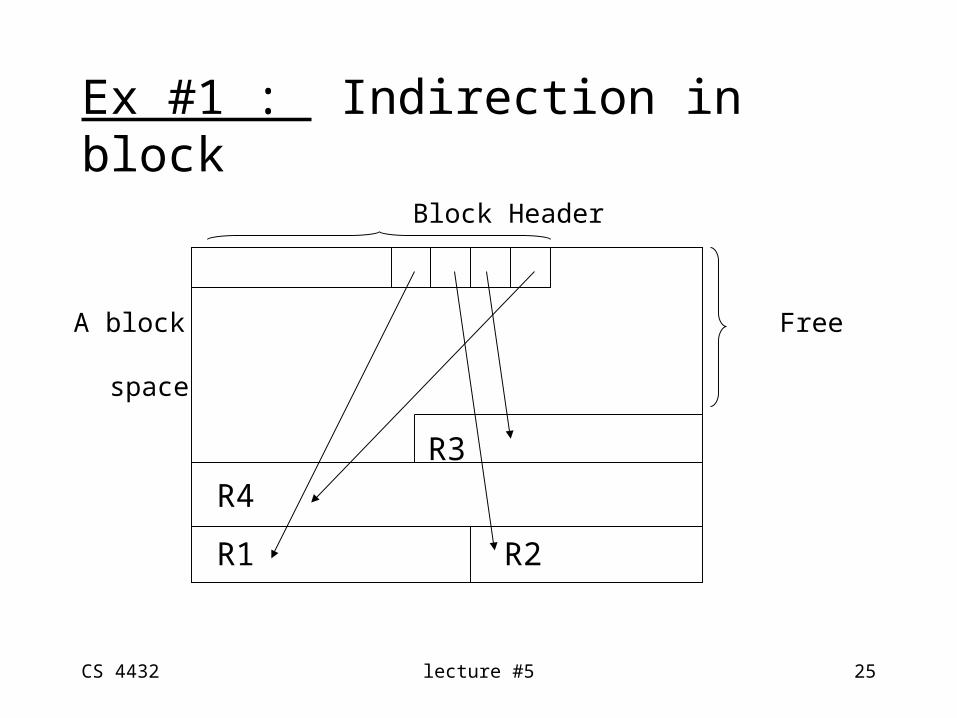
Ex #1 : Indirection in block
Block Header
A block: Free
space
R3
R4
R1 R2

CS 4432 lecture #5 27
Ex. #2 Use logical block #’s understood by file system
instead of direct disk accessREC ID File ID
Block # Record # or Offset
File ID, PhysicalBlock # Block ID
File System Map

CS 4432 lecture #5 28
(1) Separating records(2) Spanned vs. Unspanned(3) Mixed record types - Clustering(4) Split records(5) Sequencing(6) Indirection
Recap: Storing records in blocks













![pp.ipd.kit.edu · Elementary blocks A statement consists of a set of elementary blocks blocks : Stmt → P(Blocks) blocks([x := a]!)={[x := a]!} blocks([skip]!)={[skip]!} blocks(S1;S2](https://img.pdfslide.us/doc/110x75/5e812e885fca162f91121c3f/ppipdkitedu-elementary-blocks-a-statement-consists-of-a-set-of-elementary-blocks.jpg)