Embed Size (px)
Citation preview

CS 4100 Artificial Intelligence
Prof. C. Hafner
Class Notes April 5, 2012

Outline• Presenters on April 12 (one week from today)
– Determined in python by: • import random• random.uniform(1,9) performed 4 times
1. Brackets (Longyear)
2. MARC (Thompson)
3. Senioritis (Luis)
4. Eldridge team
• Perceptrons: single layer neural nets• BriefBrief overview of support vector machines• Continue with NLP concepts/examples
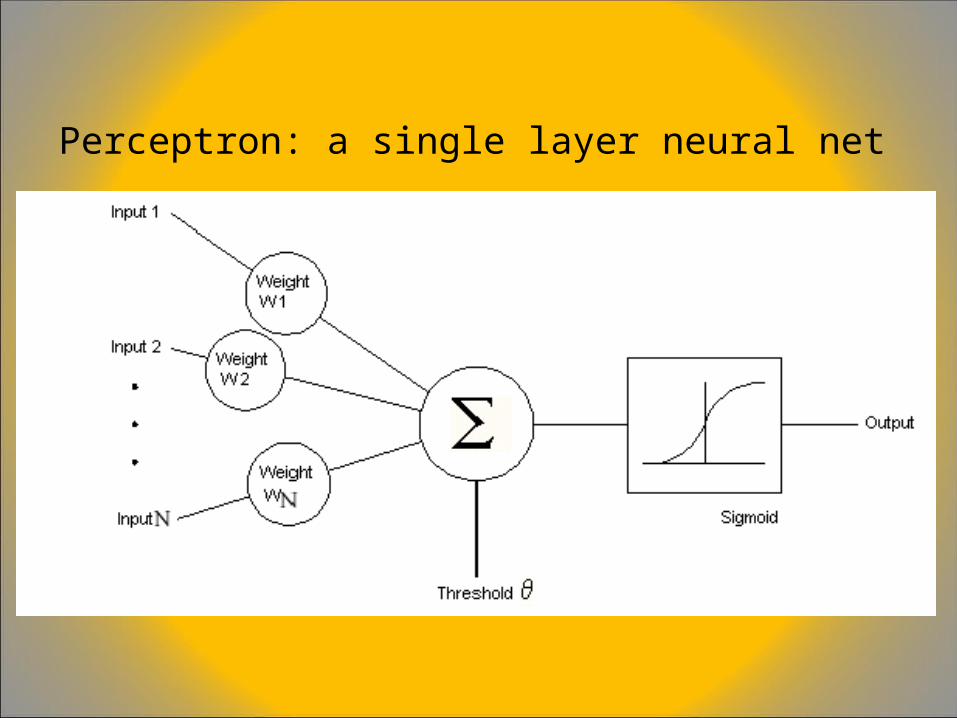
Perceptron: a single layer neural net

The PerceptronThe Perceptron is a kind of a single-layer artificial network with only one neuron
The Percepton is a network in which the neuron unit calculates the linear combination of its real-valued or boolean inputs and passes it through a threshold activation function:
o = Threshold( Σ i=0N
wi xi ) where xi are the components of
the input xe= ( xe1, xe2,..., xeN ) from the set {( xe, ye )}e=1D
Threshold is the activation function defined as follows:
Threshold ( s ) = 1 if s > 0 and –1 otherwise

The Perceptron is sometimes referred to a threshold logic unit (TLU) since it discriminates the data depending on whether the sum is greater than the threshold value: Σ i=0
N wi xi > 0
or the sum is less than the threshold value Σ i=0
N wi xi <= 0
In the above formulation we implement the threshold using a pseudo-input x0 which is always equal to 1, and if the threshold value is T then w0 (called the bias weight) is set to –T. The Perceptron is strictly equivalent to a linear discriminant, and it is often used as a device that decides whether an input pattern belongs to one of two classes.
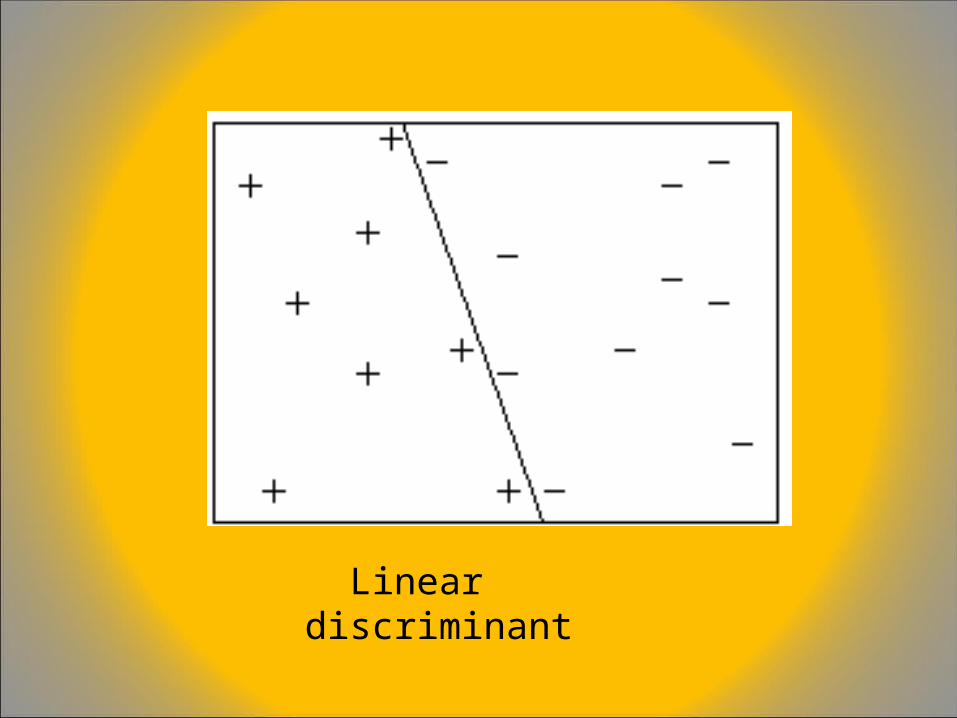
Linear discriminant

Networks of such threshold units can represent a rich variety of functions while single units alone can not.
For example, every boolean function can be presented by some network of interconnected units.
The Perceptron (a single layer network) can represent most of the primitive boolean functions: AND, OR, NAND and NOR but can not represent XOR.

Perceptron Learning Algorithms
As with other linear discriminants the main learning task is to learn the weights. Unlike the normal linear discriminant, no means or covariances are calculated. Instead of examining sample statistics, sample cases are presented sequentially, and errors are corrected by adjusting the weights. If the output is correct, the weights are not adjusted.
There are several learning algorithms for training single-layer Perceptrons based on: - the Perceptron rule - the Gradient descent rule - the Delta rule
All these rules define error-correction learning procedures, that is, the algorithm:
cycles through the training examples over and overadjusting the weights when the perceptron’s answer is wronguntil the perceptron gets the right answer for all inputs

Initialization: • Examples {( xe, ye )}e=1
D,
• initial weights wi set to small random values, • Learning rate parameter = 0.1 (or other learning rate)
Repeat for each training example ( xe, ye )
• calculate the output: o = Threshold( i=0Nwi xie )
• if the Perceptron does not respond correctly update the weights:
wi = wi + ( ye - oe ) xie // this is the Perceptron Rule
until termination condition is satisfied. where: ye is the desired output, oe is the output generated by the Perceptron,
wi is the weight associated with the i-th input xie
Note that if xie is 0 then wi does not get adjusted.

The role of the learning parameter is to moderate the degree to which weights are changed at each step of the learning algorithm.
During learning the decision boundary defined by the Perceptron moves, and some points that have been previously misclassified will become correctly classified.

The Perceptron convergence theorem states that for any data set which is linearly separable the Perceptron learning rule is guaranteed to find a solution in a finite number of steps.
In other words, the Perceptron learning rule is guaranteed to converge to a weight vector that correctly classifies the examples provided the training examples are linearly separable.
A function is said to be linearly separable when its outputs can be discriminated by a function which is a linear combination of features, that is we can discriminate its outputs by a line or a hyperplane.
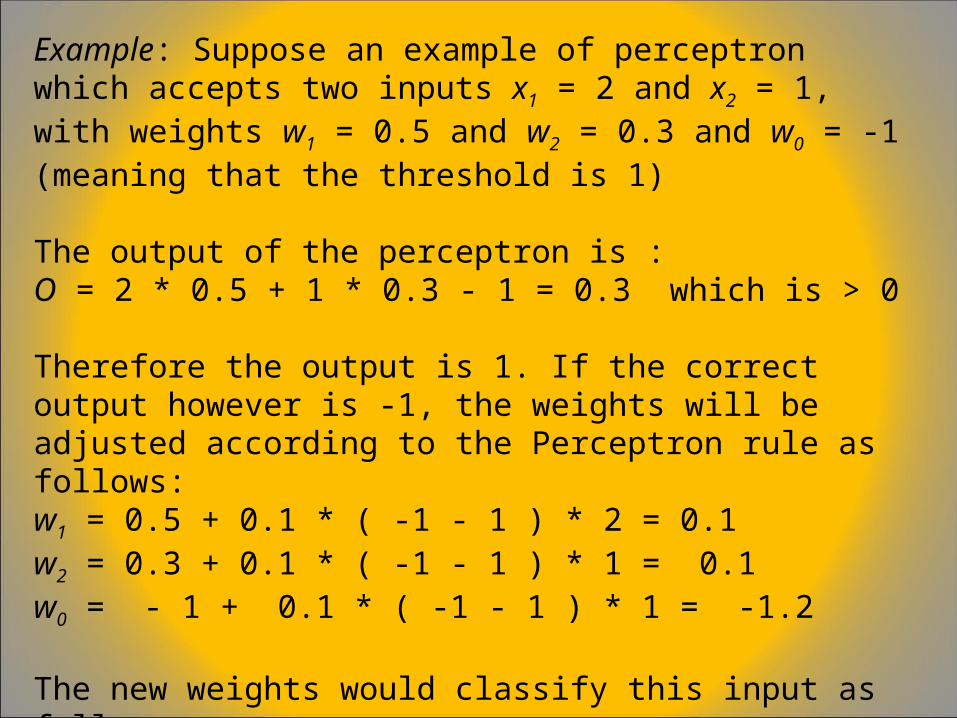
Example: Suppose an example of perceptron which accepts two inputs x1 = 2 and x2 = 1, with weights w1 = 0.5 and w2 = 0.3 and w0 = -1 (meaning that the threshold is 1)
The output of the perceptron is :O = 2 * 0.5 + 1 * 0.3 - 1 = 0.3 which is > 0
Therefore the output is 1. If the correct output however is -1, the weights will be adjusted according to the Perceptron rule as follows:w1 = 0.5 + 0.1 * ( -1 - 1 ) * 2 = 0.1w2 = 0.3 + 0.1 * ( -1 - 1 ) * 1 = 0.1w0 = - 1 + 0.1 * ( -1 - 1 ) * 1 = -1.2
The new weights would classify this input as follows:O = 2 * 0.1 + 1 * 0.1 – 1.2 = - 0.9Therefore we have done “error correction”
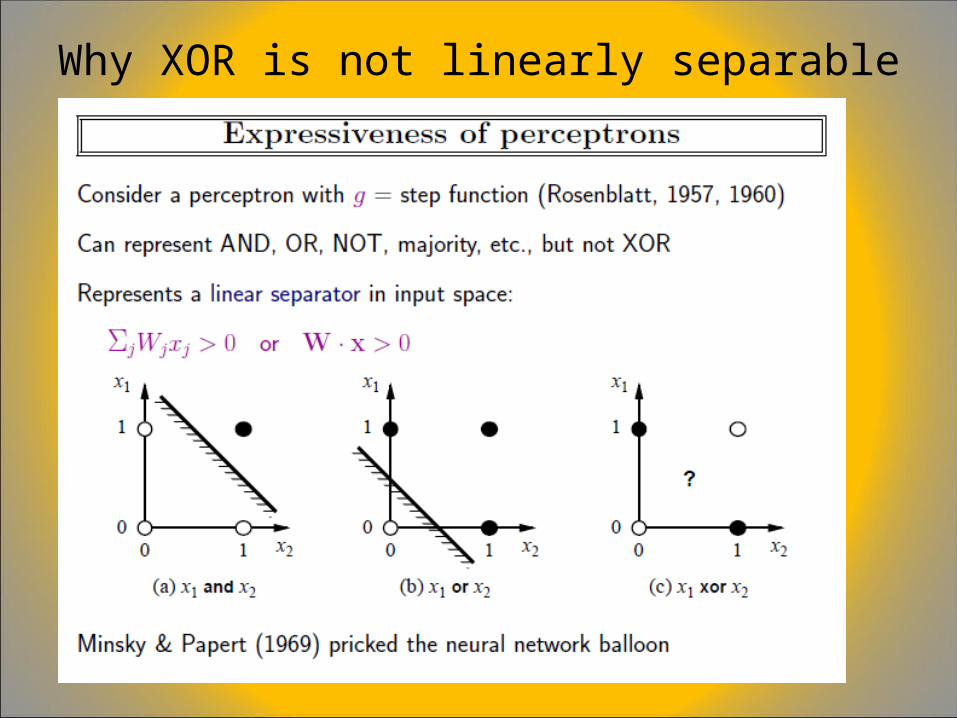
Why XOR is not linearly separable

New topic: Hill Climbing: optimization searchgiven an (unknown) numerical function F: Rn Rfind the x that gives best F by sampling the space
• Choose a point in n-dimensional space to search as your current ‘guess” x = x1 . . xn
• Take a small step in k directions• Choose the direction that results in maximum
improvement in F(x)• Make that the new guess• Continue until no more improvement is possible
(plateau) or result satisfies a criterion
Variant: simulated annealing:
random jump at intervals to find better region
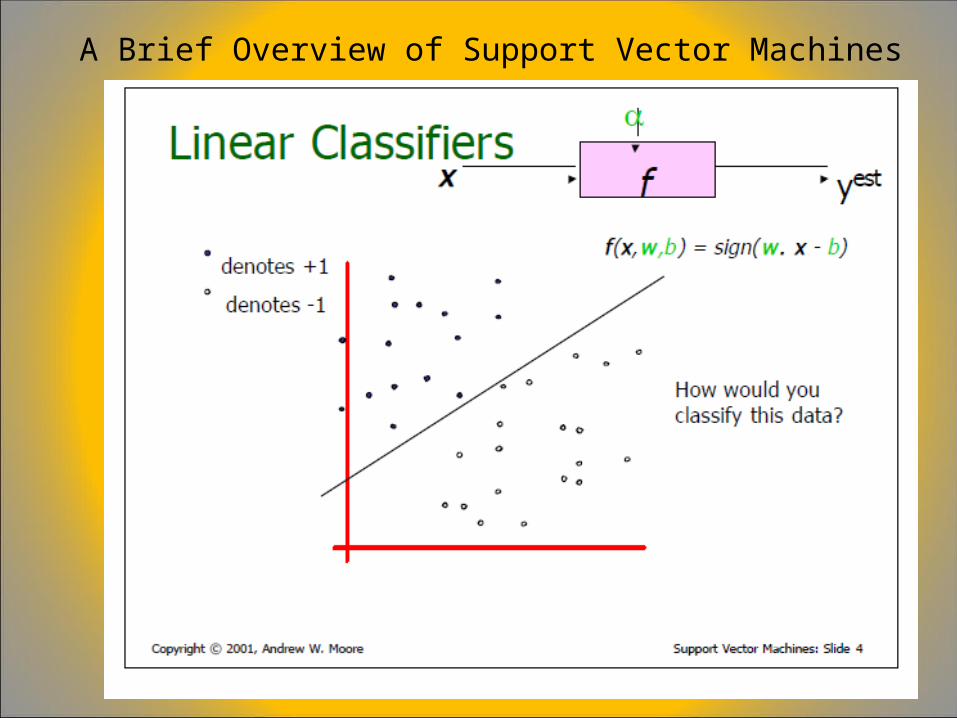
A Brief Overview of Support Vector Machines
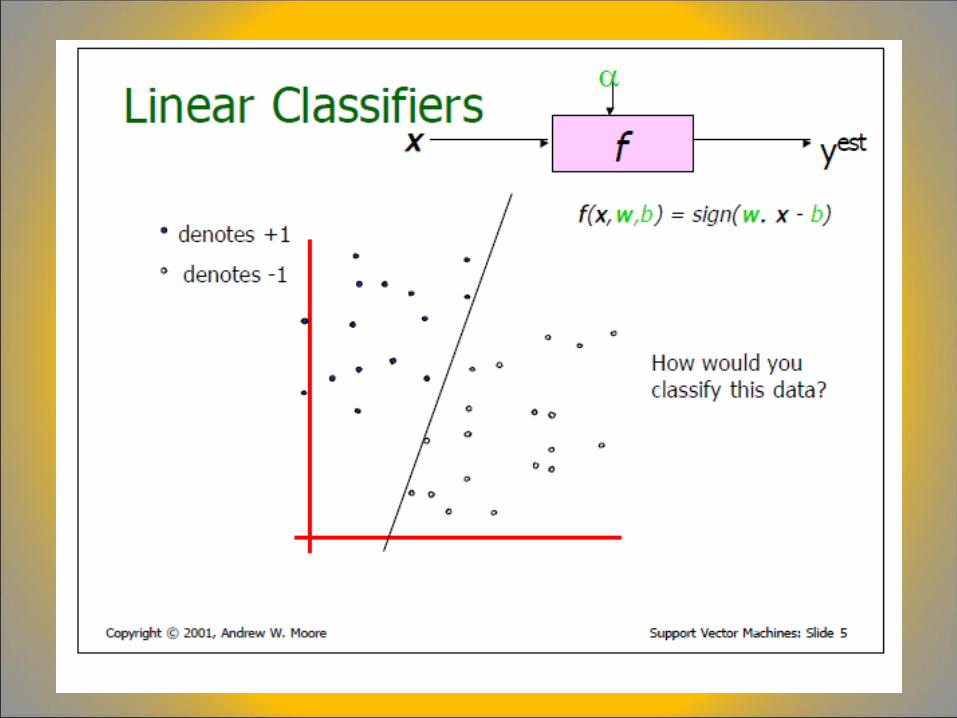
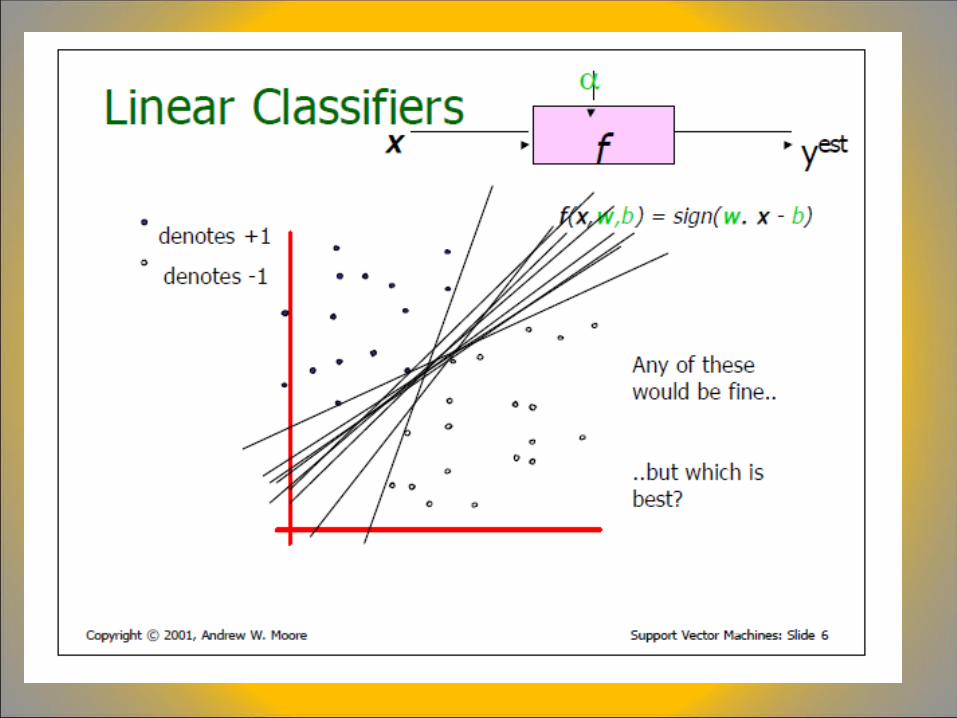
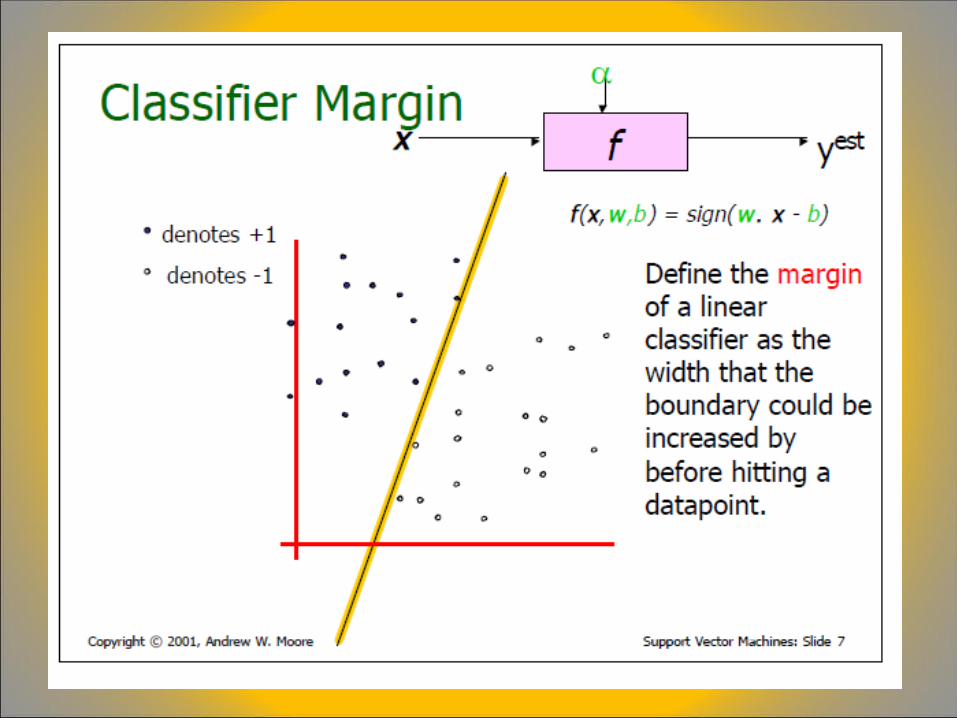
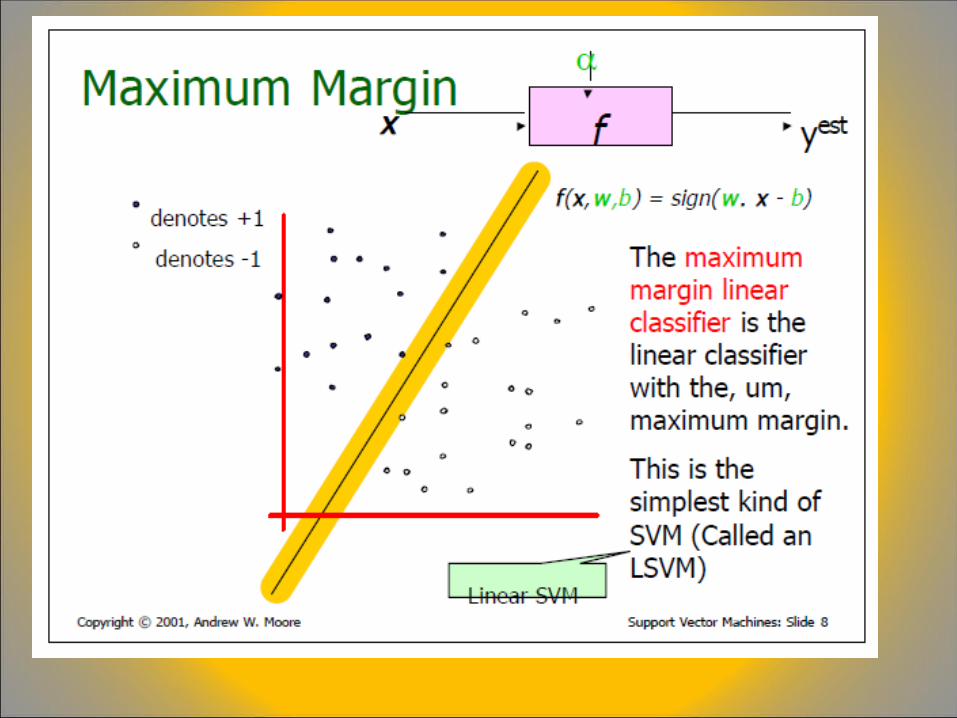

LOOCV = “leave one out cross validation”

Suppose we have a model with one or more unknown parameters, and a data set to which the model can be fit (the training data set). The fitting process optimizes the model parameters to make the model fit the training data as well as possible. If we then take an independent sample of validation data from the same population as the training data, it will generally turn out that the model does not fit the validation data as well as it fits the training data. This is called overfitting, and is particularly likely to happen when the size of the training data set is small, or when the number of parameters in the model is large. Cross-validation is a way to predict the fit of a model to a hypothetical validation set when an explicit validation set is not available.
Cross Validation

In K-fold cross-validation, the original sample is randomly partitioned into K subsamples. Of the K subsamples, a single subsample is retained as the validation data for testing the model, and the remaining K − 1 subsamples are used as training data. The cross-validation process is then repeated K times (the folds), with each of the K subsamples used exactly once as the validation data. The K results from the folds then can be averaged (or otherwise combined) to produce a single estimation. The advantage of this method over repeated random sub-sampling is that all observations are used for both training and validation, and each observation is used for validation exactly once. 10-fold cross-validation is commonly used

As the name suggests, leave-one-out cross-validation (LOOCV) involves using a single observation from the original sample as the validation data, and the remaining observations as the training data. This is repeated such that each observation in the sample is used once as the validation data. This is the same as a K-fold cross-validation with K being equal to the number of observations in the original sample. Leave-one-out cross-validation is usually very expensive from a computational point of view because of the large number of times the training process is repeated.


Natural Language Processing (cont.)
• Levels– Phonological– Lexical– Syntactic– Semantic– Pragmatic
What is each level concerned with? What are some of the difficulties?

Part of Speech Tagging: A success storyfor corpus linguistics
TaggingThe process of associating labels with each token in a text
TagsThe labels
Tag SetThe collection of tags used for a particular task
Thanks to: Marti Hearst, Diane Litman, Steve Bird

Example from the GENIA corpus
Typically a tagged text is a sequence of white-space separated base/tag tokens:
These/DTfindings/NNSshould/MDbe/VBuseful/JJfor/INtherapeutic/JJstrategies/NNSand/CCthe/DTdevelopment/NNof/INimmunosuppressants/NNStargeting/VBGthe/DTCD28/NNcostimulatory/NNpathway/NN./.

What does Tagging do?
1. Collapses Distinctions• Lexical identity may be discarded• e.g., all personal pronouns tagged with PRP
1. Introduces Distinctions• Ambiguities may be resolved• e.g. deal tagged with NN or VB
1. Helps in classification and prediction

Significance of Parts of Speech
A word’s POS tells us a lot about the word and its neighbors:
Limits the range of meanings (deal), pronunciation (object vs object) or both (wind)
Helps in stemming
Limits the range of following words
Can help select nouns from a document for summarization
Basis for partial parsing (chunked parsing)
Parsers can build trees directly on the POS tags instead of maintaining a lexicon

Choosing a tagset
The choice of tagset greatly affects the difficulty of the problem
Need to strike a balance betweenGetting better information about context
Make it possible for classifiers to do their job
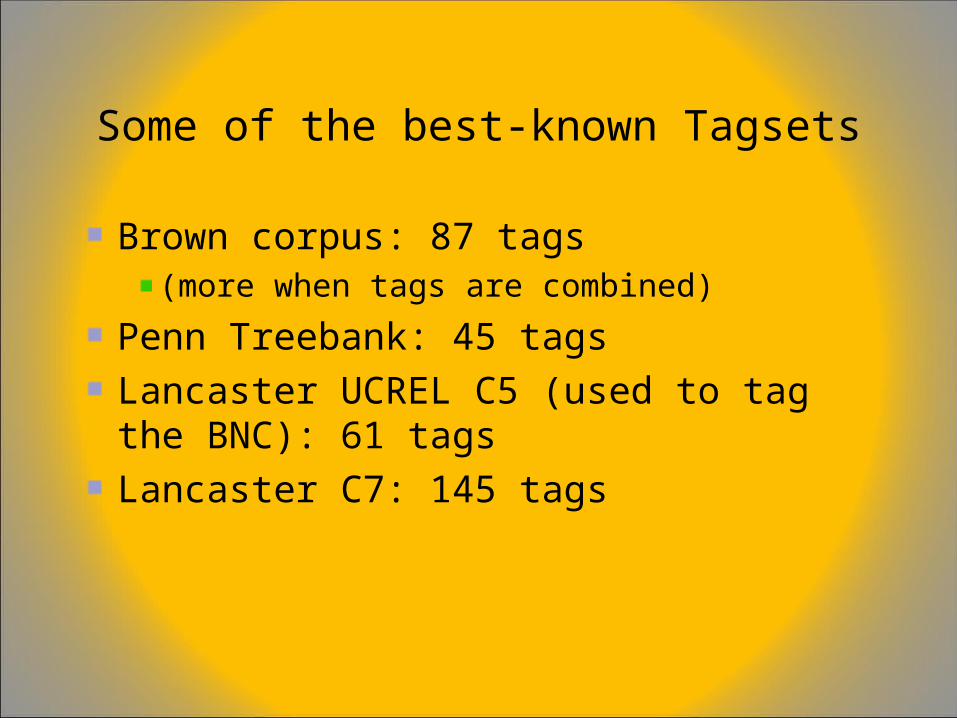
Some of the best-known Tagsets
Brown corpus: 87 tags(more when tags are combined)
Penn Treebank: 45 tags
Lancaster UCREL C5 (used to tag the BNC): 61 tags
Lancaster C7: 145 tags

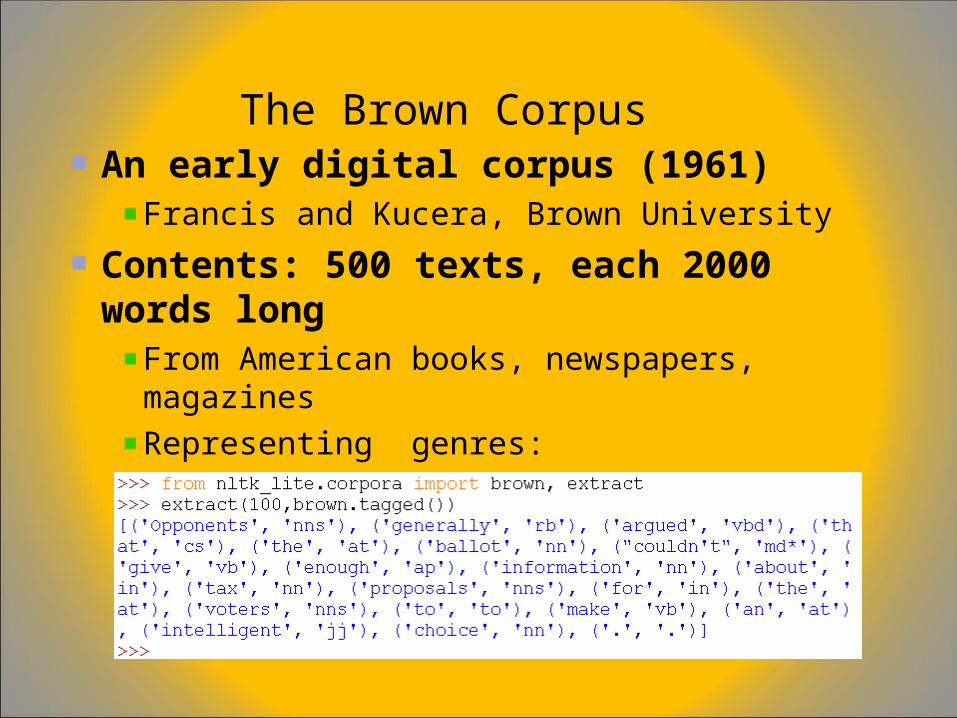
The Brown CorpusAn early digital corpus (1961)
Francis and Kucera, Brown University
Contents: 500 texts, each 2000 words longFrom American books, newspapers, magazines
Representing genres:– Science fiction, romance fiction, press reportage
scientific writing, popular lore

Penn Treebank
First large syntactically annotated corpus
1 million words from Wall Street Journal
Part-of-speech tags and syntax trees

How hard is POS tagging?
Number of tags 1 2 3 4 5 6 7
Number of word types
35340 3760 264
61 12 2 1
In the Brown corpus, 12% of word types ambiguous 40% of word tokens ambiguous

Tagging methods
Hand-coded
Statistical taggers (supervised learning)
Brill (transformation-based) tagger

Supervised Learning Approcah
• Algorithms that “learn” from data see a set of examples and try to generalize from them.
• Training set: – Examples trained on
• Test set:– Also called held-out data and unseen data– Use this for evaluating your algorithm– Must be separate from the training set
• Otherwise, you cheated!
• “Gold” standard– A test set that a community has agreed on and
uses as a common benchmark.

Cross-Validation of Learning Algorithms• Cross-validation set
– Part of the training set.
• Used for tuning parameters of the algorithm without “polluting” (tuning to) the test data.– You can train on x%, and then cross-validate on
the remaining 1-x%• E.g., train on 90% of the training data, cross-validate
(test) on the remaining 10%• Repeat several times with different splits
– This allows you to choose the best settings to then use on the real test set.
• You should only evaluate on the test set at the very end, after you’ve gotten your algorithm as good as possible on the cross-validation set.

Strong Baselines
• When designing NLP algorithms, you need to evaluate them by comparing to others.
• Baseline Algorithm: – An algorithm that is relatively simple but can be
expected to do well– Should get the best score possible by doing the
somewhat obvious thing.
• A Tagging Baseline: for each word, assign its most frequent tag in the training set

N-Grams• The N stands for how many terms are used
– Unigram: 1 term (0th order) Ex: P(Xi)– Bigram: 2 terms (1st order) Ex: P(Xi | Xi-1)– Trigrams: 3 terms (2nd order) Ex: P(Xi | Xi-1, Xi-2)
• Usually don’t go beyond this
• You can use different kinds of terms, e.g.:– Character based n-grams– Word-based n-grams– POS-based n-grams
• We use n-grams to help determine the context in which some linguistic phenomenon happens.– E.g., look at the words before and after the period to see if it is the end of a
sentence or not.

Unigram Tagger
• Train on a set of sentences• Keep track of how many times each word
is seen with each tag.• After training, associate with each word
its most likely tag.– Problem: many words never seen in the
training data.– Solution: have a default tag to “backoff” to.

What’s wrong with unigram?
• Most frequent tag isn’t always right!• Need to take the context into account
– Which sense of “to” is being used?– Which sense of “like” is being used?

N-gram (Bigram) Tagging
– For tagging, in addition to considering the token’s type, the context also considers the tags of the n preceding tokens
• What is the most likely tag for word n, given word n-1 and tag n-1?
– The tagger picks the tag which is most likely for that context.
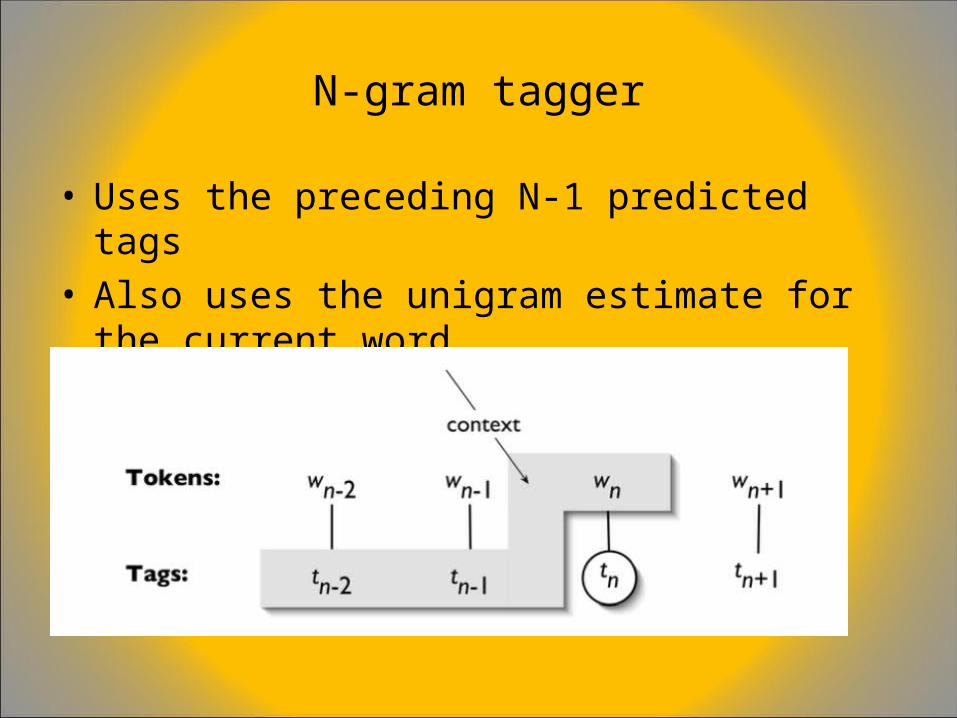
N-gram tagger
• Uses the preceding N-1 predicted tags• Also uses the unigram estimate for the current
word
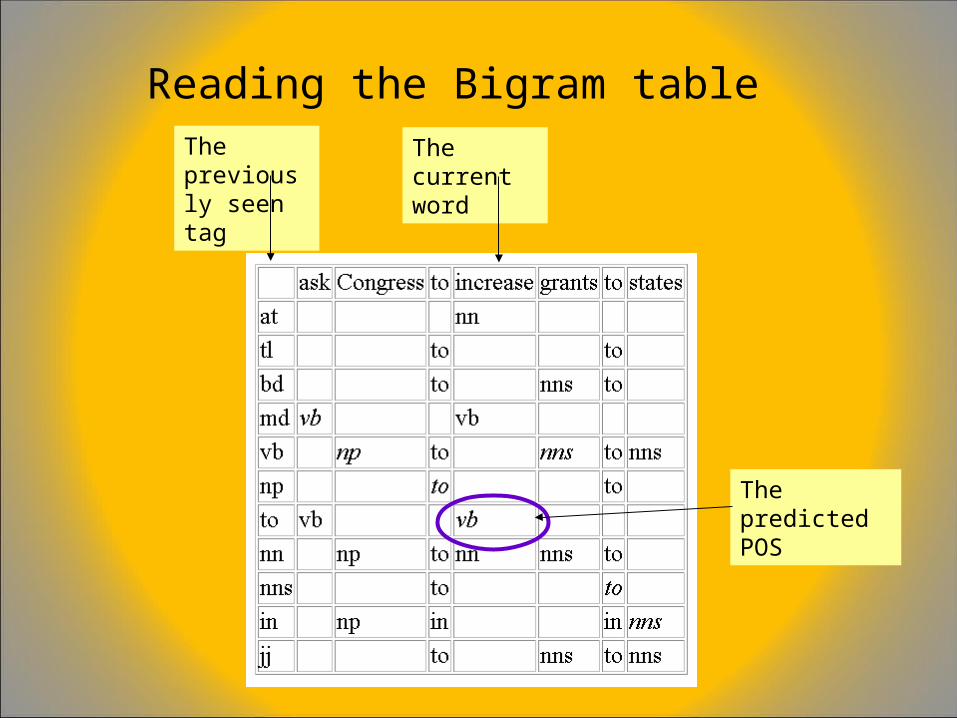
Reading the Bigram tableThe current word
The predicted POS
The previously seen tag




Syntax (cont.)• Define context free grammar for L
– A set of terminal (T) symbols (words)– A set of non terminal (N) symbols (phrase types)– A distinguished non terminal symbol “S” for sentence– A set PR of production rules of the form:
NT a sequence of one or more symbols from T U NT
• A sentence of L is a sequence of terminal symbols that can be generated by:– Starting with S– Replace a non-terminal N with the RHS of a rule from
PR with N as its LHS.– Until no more non-terminals remain

Syntax tree for a sentence
• Any sentence of L has one or more syntax trees that show how it can be derived from S by repeated applications of the rules in PR
• The syntax tree (also called the parse tree) represents a grammatical structure which may also represent a semantic interpretation

• Example: a grammar for arithmetic expressions• 3 * 4 + 5 has two valid parse trees with different
semantics. What are they? (class exercise)
S digit
S S + S
S S * S
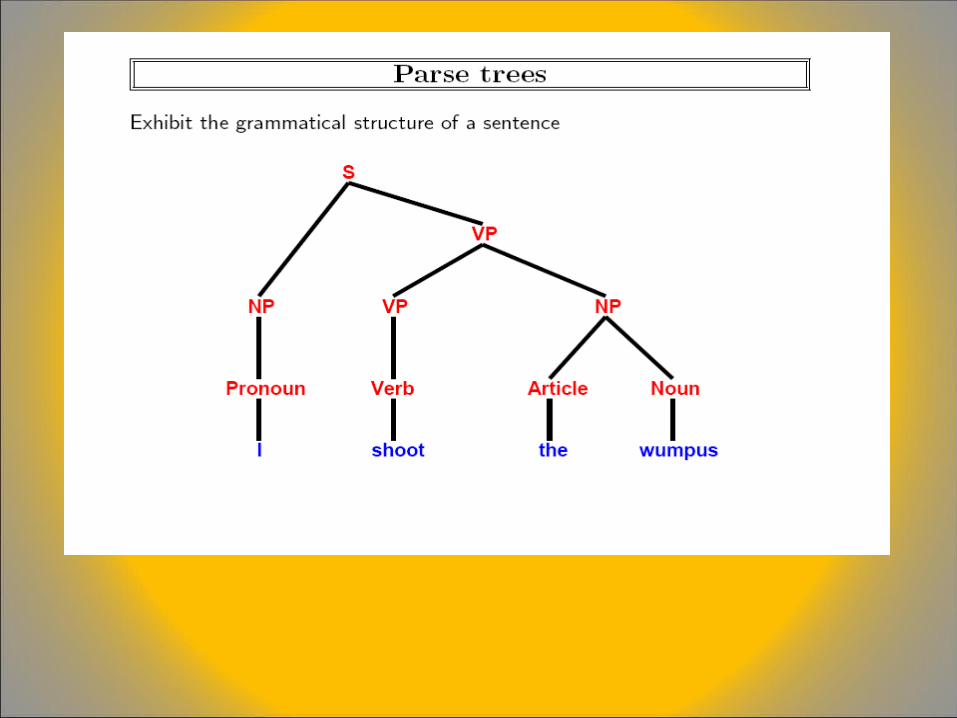

Parsing
• Parsing with CFGs refers to the task of assigning syntax trees to input sequences of terminal symbols
• A valid parse tree covers all and only the elements of the input and has an S at the top
• It doesn’t actually mean that the system can select the semantically “correct “ tree from among the possible syntax trees
• As with everything of interest, parsing involves a search that involves the making of choices
• Example: “I SAW A MAN IN THE PARK WITH A TELESCOPE”

The problem of “scaling up” – the same as in knowledge representation, planning, etc but even more difficult

A Simple CFG for English• S NP VP• S aux NP VP• S VP• NP det Nom• NP propN• NP Nom• Nom noun• Nom adj Nom• VP verb• VP verb NP• VP verb PP• PP prep NP
propN John, Boston, United States
det the, that, . ..
noun flight, book, pizza
adj small, red, happy
verb book, see
aux be, do, have
prep of, in, at, to, before
Example sentence: Book that flight

Top-Down Parsing
• Since we are trying to find trees rooted with an S (Sentences) start with the rules that give us an S.
• Then work your way down from there to the words.

Top Down Space

Bottom-Up Parsing
• Of course, we also want trees that cover the input words. So start with trees that link up with the words in the right way.
• Then work your way up from there.
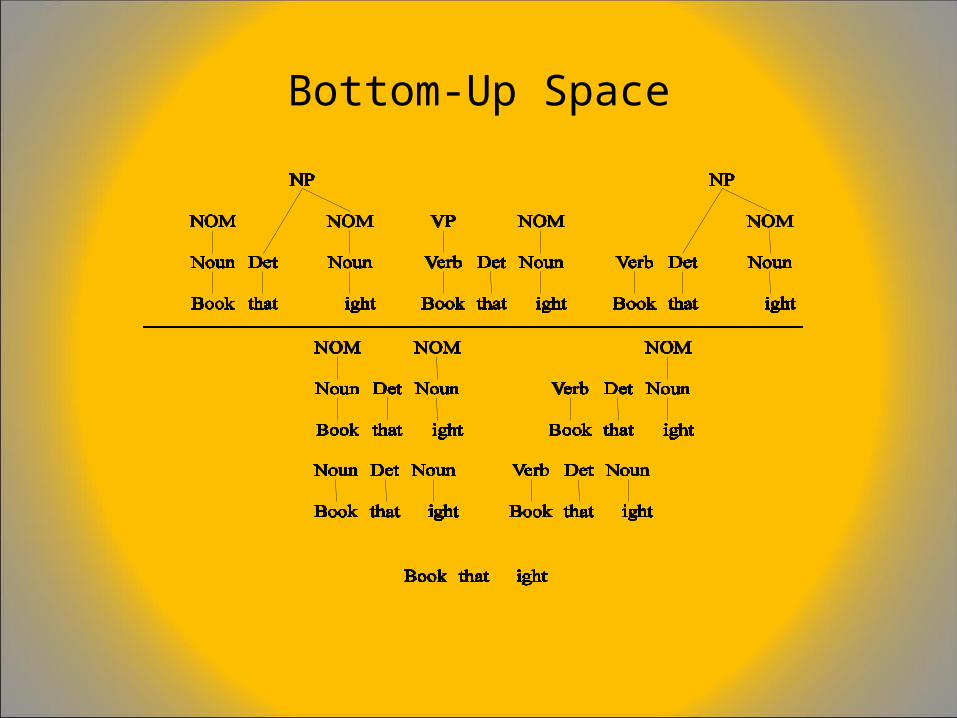
Bottom-Up Space

Top-Down VS. Bottom-Up
• Top-down– Only searches for trees that can be answers– But suggests trees that are not consistent with the words– Guarantees that tree starts with S as root– Does not guarantee that tree will match input words
• Bottom-up– Only forms trees consistent with the words– Suggest trees that make no sense globally– Guarantees that tree matches input words– Does not guarantee that parse tree will lead to S as a root
• Combine the advantages of the two by doing a search constrained from both sides (top and bottom)
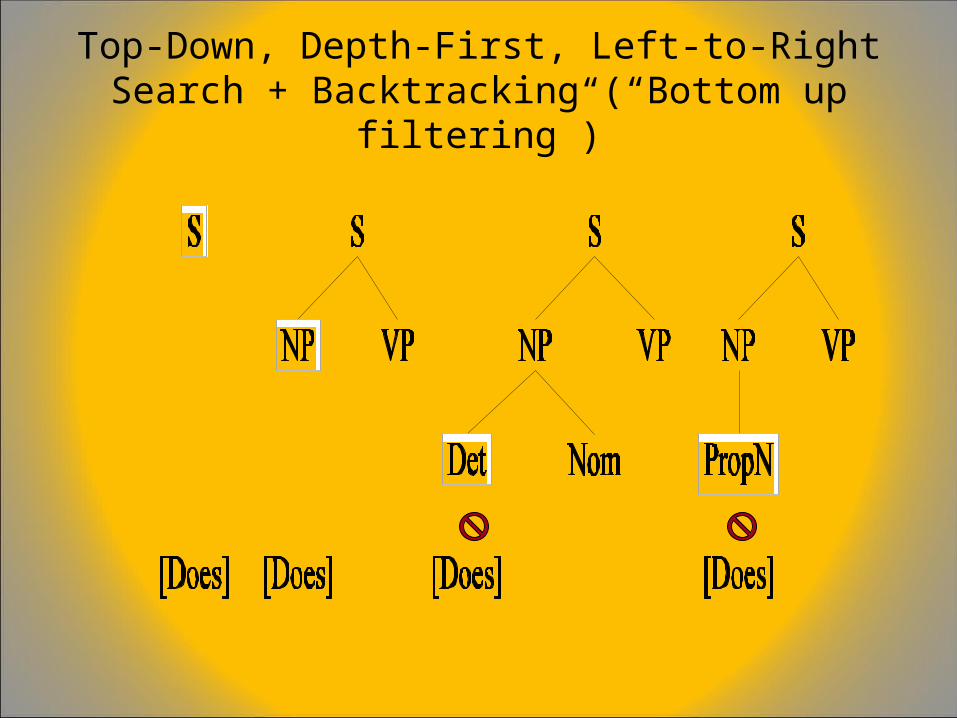
Top-Down, Depth-First, Left-to-Right Search + Backtracking (“Bottom up filtering”)
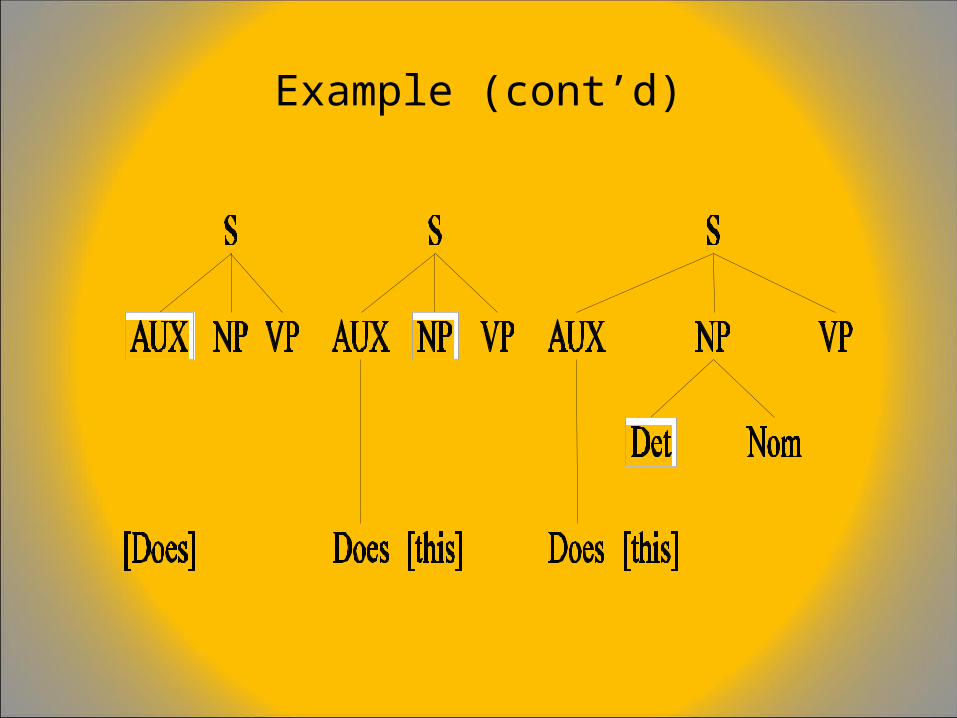
Example (cont’d)
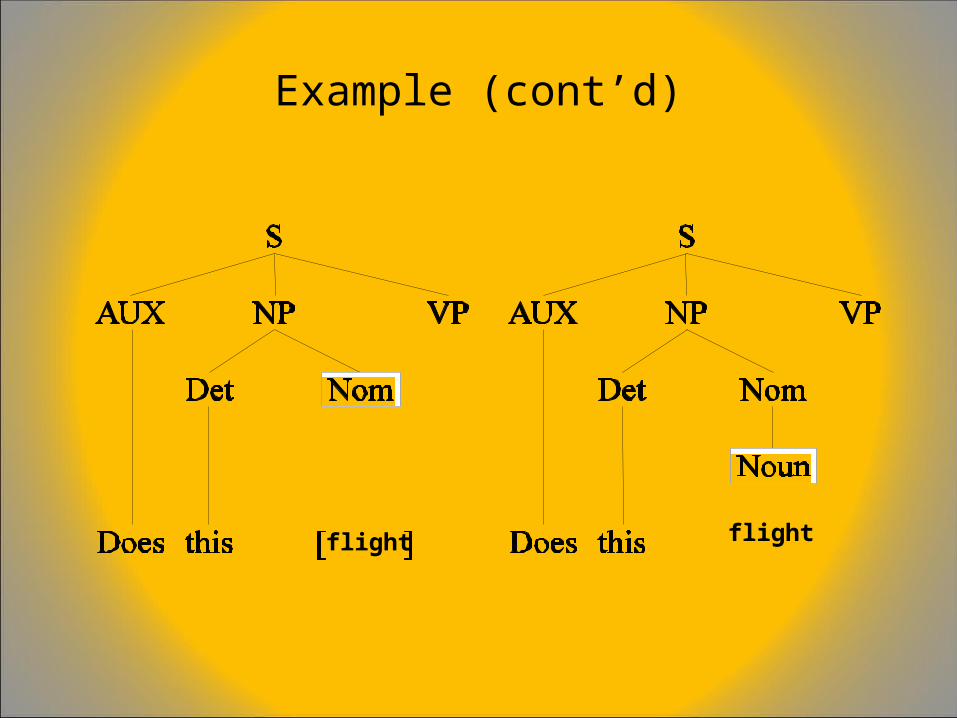
Example (cont’d)
flight flight
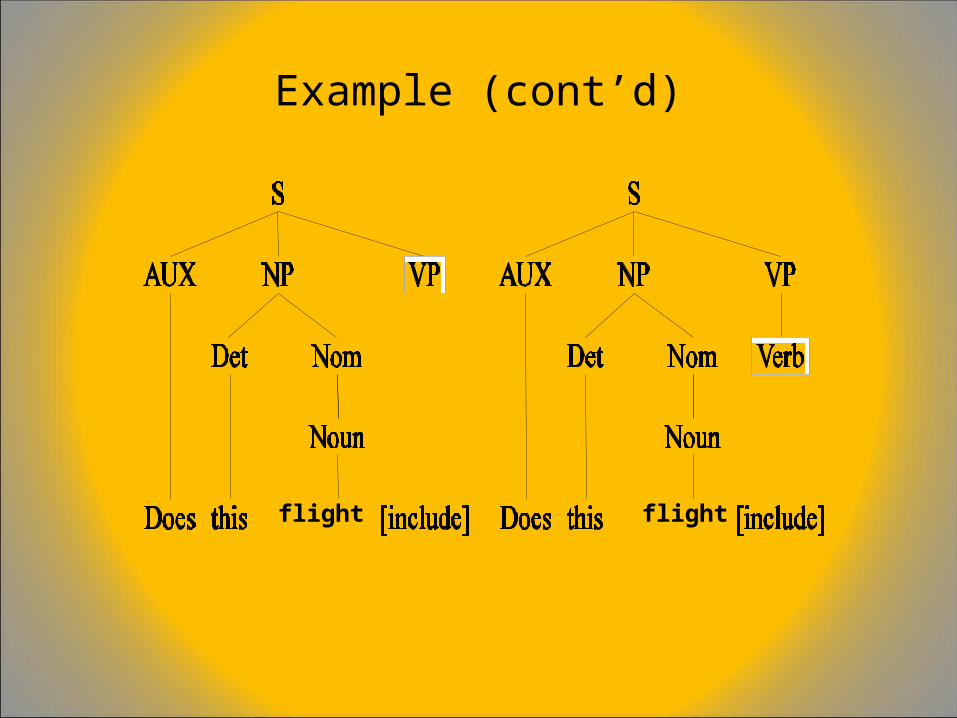
Example (cont’d)
flightflight

Problem: Left-Recursion
• What happens in the following situation– S -> NP VP– S -> Aux NP VP– NP -> NP PP– NP -> Det Nominal– …– With the sentence starting with
• Did the flight

Avoiding Repeated Work
• Parsing is hard, and slow. It’s wasteful to redo stuff over and over and over.
• Consider an attempt to top-down parse the following as an NP
• A flight from Indianapolis to Houston on TWA

flight

flight
flight































