Embed Size (px)
Citation preview

Creating Shareable Models
By: Eric Hutton
CSDMS is the Community Surface Dynamics Modeling System
(pronounced ˈsɪstəms)
Image by Flickr user Let There Be More Light

A model can more easily be used by others if it is readable and has an API
Readable
Application Programming Interface (API)
Someone new to your code should be able to give it a quick read and know what’s going on.
The interface will allow someone to use it without worrying about implementation details.

But before all that though, choose a license and a language
The GNU General Public License is a good choice.
But there lots more. For example,
MIT
Apache
LGPL
GPLv3
OSL
As far as languages, C is a good choice.

Writing readable code mostly means sticking to a standard
The code should speak for itself. That doesn’t just mean adding more comments.
Super simple things help:
Spaces instead of tabs
Useful variable names – especially for global variables and function names
Underscores in names – water_density is better than iCantReadThis
In the end though, just be consistent.

Makefiles and configure scripts help to make code portable
Software distributions on UNIX are usually compiled with,
> ./configure> make
Creates a make file specific to your system
Compiles the code
Easy, right? Well… the magic that goes on behind the scenes to make this tick is complicated.
Uses “programming languages” such as: automake, autoconf, m4, make, sh

A better alternative to configure/make is cmake
Cmake is free, open-source software that replaces autotools/make.
• Simple syntax• Much easier to learn than autotools• Supports nearly every Unix, Windows, Mac OSX• Features a testing framework• Features a packaging framework• am2cmake script to convert automake files
Random compile tip:compile with –Wall compile flag and pay attention to the warnings.
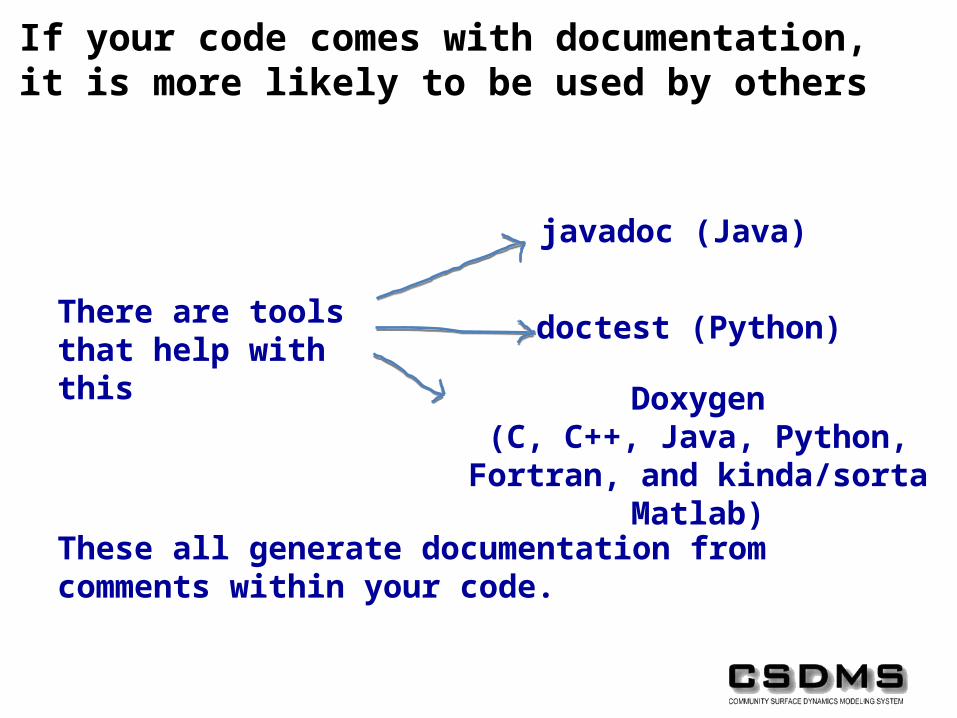
If your code comes with documentation, it is more likely to be used by others
There are tools that help with this
javadoc (Java)
doctest (Python)
Doxygen(C, C++, Java, Python, Fortran,
and kinda/sorta Matlab)
These all generate documentation from comments within your code.

For example, a C function can be documented directly above it’s definition/declaration.
/** Calculate the area of a circle.
@param r Radius of the circle
@returns The circle’s area
*/
double area_of_circle ( double r );
This is similar to annotations in Java. We’ll come back to this later.

It would be nice if there existed a set of standard annotations for our modeling community.
Some examples of annotation that would be useful to someone wanting to use your model:
• @initialize, @run, @finalize
• @author, @keyword, @version
• @in, @out, @unit
Your source code could then be parsed for these annotations.
Since they are ignored by the compiler, they inject very little of the framework into your code.

Annotations could be used to describe three categories of meta data (this list comes from OMS)
Component
@description
@author
@bibliography
@status
@version
@source
@keywords
@label
Field
@description
@unit
@in
@out
@range
@role
@bound
@label
Method
@run
@initialize
@finalize
Others?

Example annotation for a component that calculates the area of a circle
@description(“Circle computation”)
@author(“me”)
Public class CircleArea {
@description(“Radius”)
@range(min=0)
@in public double r;
@out public double area;
@run
public void runme() {
area = Math.PI * r * r;
}
}

Our models are difficult to couple because of implementation details
Some reasons that models are difficult to link or share:
Languages
Time steps
Numerical schemes
Complexity
These are all implementation details. The user shouldn’t have to worry about these details.
Design an interface!

A modeling interface hides implementation details from the application developer
Lots of crazy, hard-to-
understand code
Lots of crazy, hard-to-
understand code
A coastal evolution model, sayYou
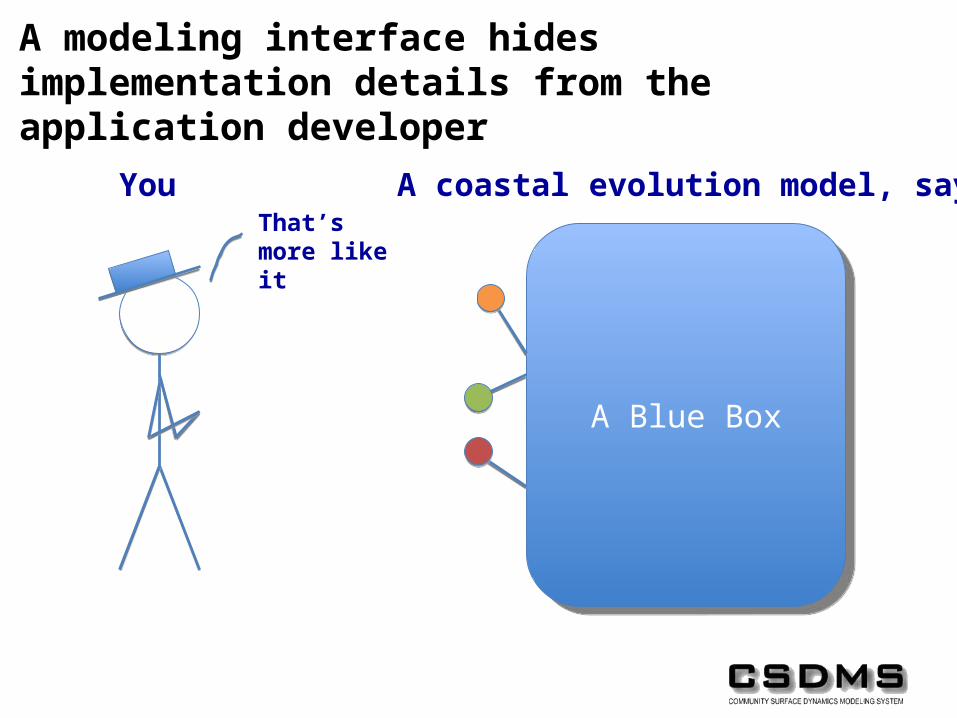
A Blue BoxA Blue Box
A modeling interface hides implementation details from the application developer
A coastal evolution model, sayYouThat’s more like it
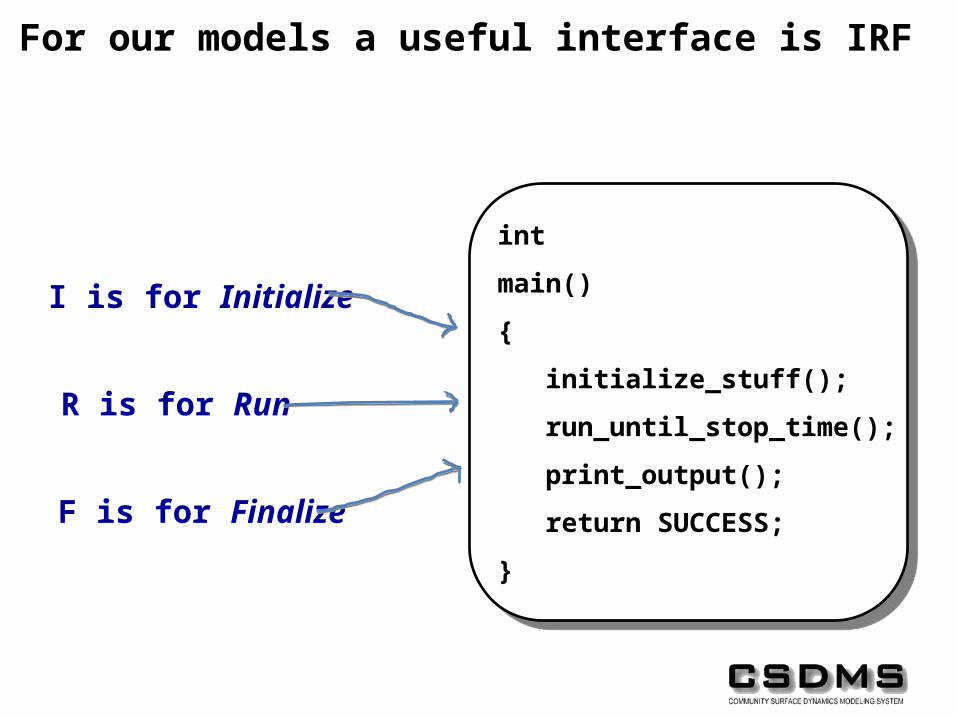
For our models a useful interface is IRF
I is for Initialize
R is for Run
F is for Finalize
int
main()
{
initialize_stuff();
run_until_stop_time();
print_output();
return SUCCESS;
}
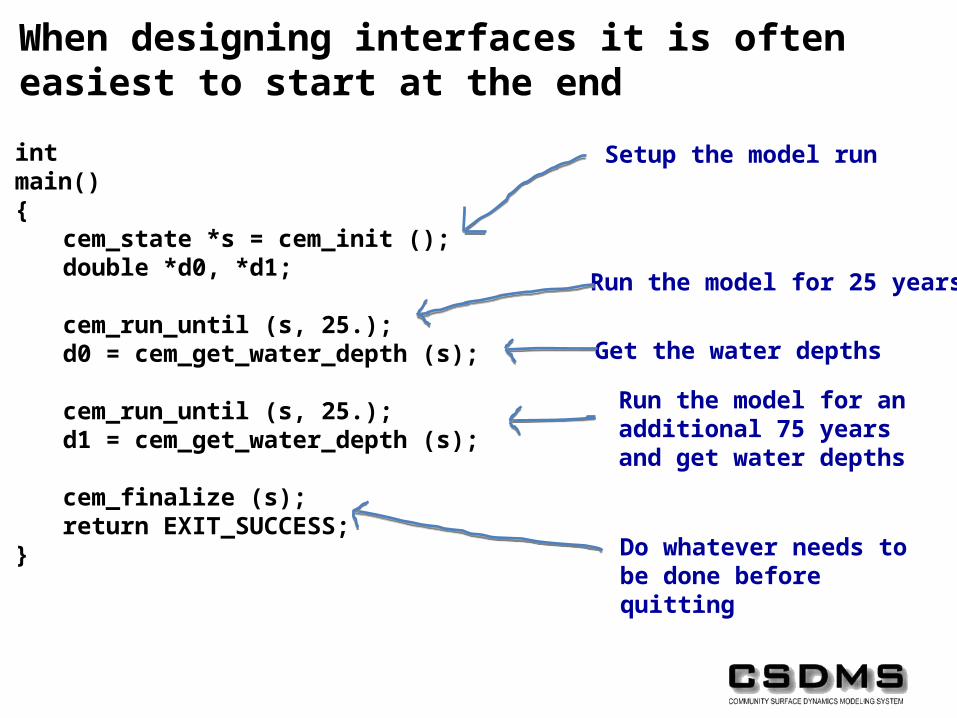
When designing interfaces it is often easiest to start at the end
Setup the model run
Run the model for 25 years
Get the water depths
Run the model for an additional 75 years and get water depths
Do whatever needs to be done before quitting
intmain(){
cem_state *s = cem_init ();double *d0, *d1;
cem_run_until (s, 25.);d0 = cem_get_water_depth (s);
cem_run_until (s, 25.);d1 = cem_get_water_depth (s);
cem_finalize (s);return EXIT_SUCCESS;
}

The initialize step sets up a new model run (instance)
Things that might be done within the initialize method:
Create a new state for the model
Allocate memory
Set initial conditions
Pretty much anything that is done before the time looping begins

The initialize step shouldn’t interfere with another program’s initialize step
Things that probably shouldn’t be done within the initialize method:
• Gather input from the command line (argc, argv)
• Most any user interface
• Anything that might interfere with another component

The finalize step destroys an existing model run (instance)
Things that might be done within the finalize method:
Free resources
Close files
Print final output
Pretty much anything that is done after the time looping ends
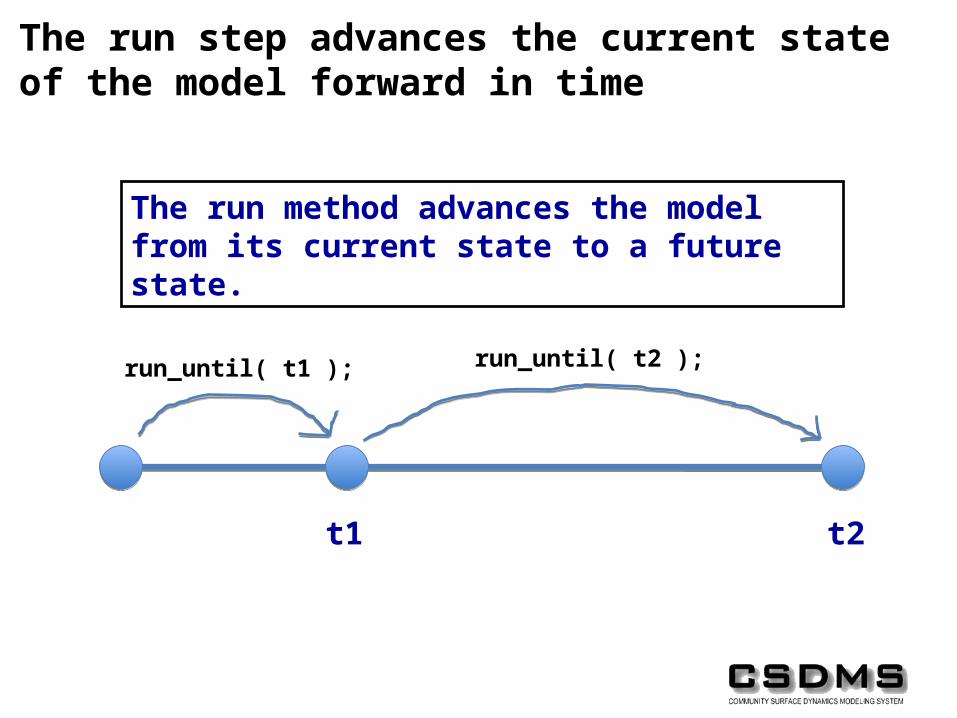
The run step advances the current state of the model forward in time
The run method advances the model from its current state to a future state.
run_until( t1 ); run_until( t2 );
t1 t2

Oftentimes it is useful to create a data type that holds the current state of the model
This is the hard part.
Identify all of the variables that need to be remembered to advance the model forward in time.
Collect these variables (I generally wrap them in a struct or class). I suppose a common block or a set of global variables would do.
This data structure can then be passed to the various methods of the API.

Getters and setters are used to interact with the model’s state
The state structure should be opaque to the user – that is implementation stuff
Instead, use get and set functions. For instance,
get_water_depth( );
set_input_file( “input” );
It is up to the API designer to decide what variables are allowed to be get/set.

Refactoring your code in this way should not change model output
…unless you find (and fix) a bug.
To make sure that you don’t add bugs when refactoring,
Make lots of tests
Run these tests often
Keep in mind that output may not be byte-for-byte comparable to your benchmarks

In conclusion, there are really only two “rules”
Questions?
Write code that someone else can understand. Pick a standard and stick to it.
Create an API.
Leave implementation details to the experts.
Worry about your own model.

![Абрамцева В. А. лицей № 1367 г. Москва. New words: hard-working ['h ɑː d ˌ w ɜː k ɪ ŋ] silly ['s ɪ l ɪ ] lazy ['le ɪ z ɪ ] cunning ['k ʌ n ɪ](https://img.pdfslide.us/doc/110x75/5a4d1b187f8b9ab05999285f/-1367-new-words.jpg)
![For Christmas, I’d like ….. A bike A scooter [ ˈ sku:tər] Roller blades [ ˈ rə ʊ lə ɼ ] [ble ɪ dz] A racket A soccer ball [ ˈ s ɒ kər] [b ɔ :l] I’d like](https://img.pdfslide.us/doc/110x75/56649d1a5503460f949ef69c/for-christmas-id-like-a-bike-a-scooter-skutr-roller-blades.jpg)
![Facebook ([ ˈ fe ɪ s ˌ b ʊ k])-Social Network, founded in 2004 by Mark Zuckerberg and his roommates while studying at Harvard University, including Eduardo](https://img.pdfslide.us/doc/110x75/56649f4d5503460f94c6d9a6/facebook-fe-s-b-k-social-network-founded-in-2004-by-mark.jpg)
![LISD Special Education SY 12-13. in·te·grat·ed / ɪ nt ɪ gre ɪ t ɪ d/ Show Spelled [in-ti-grey-tid] –adjective 1. combining or coordinating separate](https://img.pdfslide.us/doc/110x75/56649e0c5503460f94af4cea/lisd-special-education-sy-12-13-integrated-nt-gre-t-.jpg)
![Professions. a businessman [‘b ɪ zn ɪ smæn] a computer programmer [k ə m'pju ː t ə 'pr ə ugræm ə ] a dentist ['dent ɪ st] a doctor ['d ɔ kt ə ] a driver](https://img.pdfslide.us/doc/110x75/56649cef5503460f949bcce3/professions-a-businessman-b-zn-smaen-a-computer-programmer-k-.jpg)


![prov ince BrE / ˈ pr ɒ v ɪ ns / NAmE / ˈ pr ɑː v ɪ ns / noun word origin example bank 1 [ countable ] one of the areas that some](https://img.pdfslide.us/doc/110x75/56649de45503460f94adbdfb/prov-ince-bre-pr-v-ns-name-pr-v-ns-noun-word-origin.jpg)


![Lets recap the vocabulary Turn off the water tap [ ˈ w ɔ :tə ɼ ] [tæp] Electrical appliances / at the same time [ ɪˈ lektr ɪ kl] [ə ˈ pla ɪ əns ɪ z] switch](https://img.pdfslide.us/doc/110x75/551a273f550346545e8b46d1/lets-recap-the-vocabulary-turn-off-the-water-tap-w-t-taep-electrical-appliances-at-the-same-time-lektr-kl-pla-ns-z-switch.jpg)






![By Tiberius Helvius Honorius. de·i·ty / ˈ di ɪ ti/ Show Spelled[ dee -i-tee] –noun, plural -ties. 1. a god or goddess.god 2. divine character](https://img.pdfslide.us/doc/110x75/551add835503465e7d8b45ee/by-tiberius-helvius-honorius-deity-di-ti-show-spelled-dee-i-tee-noun-plural-ties-1-a-god-or-goddessgod-2-divine-character.jpg)




![WE ARE GOING TO THE MOON. [e ɪ ] [e] [a ɪ ] [z] [m]](https://img.pdfslide.us/doc/110x75/56649e905503460f94b952b1/we-are-going-to-the-moon-e-e-a-z-m.jpg)





