Embed Size (px)
Citation preview

Sandia National Laboratories is a multi-program laboratory managed and operated by Sandia Corporation, a wholly owned subsidiary of Lockheed Martin Corporation, for the U.S. Department of Energy’s National Nuclear Security Administration under contract DE-AC04-94AL85000. SAND NO. 2011-XXXXP
Crea%ng the Next Genera%on of Stable, Interoperable and Performant Simulator – A Call for Open Standards
Jeremiah Wilke*, Joseph Kenny*, Robert Clay*, Simon Hammond+, Arun Rodrigues+, ScoG Hemmert+, James Ang+, Sudhakar Yalamanchilił
*Sandia CA, +Sandia ABQ, łGeorgia Tech

We need models of varying fidelity How many tools do we need for all of them? § High fidelity
§ What you care about only at exists at cycle-‐accurate detail § Cache reuse policies in memory § Flit-‐level flow control
§ Valida%on of lower fidelity models
§ Medium fidelity § Coarse-‐grained modeling of architecture at
system scale § Adap%ve rou%ng without flit detail § Scaling of collec%ves with network conges%on
§ Valida%on of cons%tu%ve models at scale
§ Cons%tu%ve models § Poten%ally good accuracy with right fiXng § Rapid parameter space explora%on
2

We need models of varying fidelity How many tools do we need for all of them?
3
SST Structural Simulation Toolkit

We need models of varying fidelity How many tools do we need for all of them?
4
SST Sonic Screwdriver Toolchain

How do we defeat the Daleks?
§ Common Core § Scale up performance = scale up
performance simula%on = parallel simula%on (PDES)
§ Composability § Define standards for composing models
that speak same language and share the same no%on of %me
§ Community § Concerted effort to define standards and
reuse code
5

How do we defeat the Daleks?
§ Common Core § Scale up performance = scale up
performance simula%on = parallel simula%on (PDES)
§ Composability § Define standards for composing models
that speak same language and share the same no%on of %me
§ Community § Concerted effort to define standards and
reuse code
6

Virtual()me(
Time(window(
LP(0(
LP(1(
Scheduling(future(events(
What is the major source of suffering in parallel discrete event simula%on (PDES)?
§ Scale up machines = scale up simula%ons of machines = PDES § Need event management and scheduling
§ Avoid %me-‐order viola%ons!
7
Dependencies between events

What is the major source of suffering in parallel discrete event simula%on?
8
Virtual()me(
Time(window(
LP(0(
LP(1(
Scheduling(future(events(
Wall()me(=(2s(
Violation!!!

What is the major source of suffering in parallel discrete event simula%on?
9
Virtual()me(
Time(window(
LP(0(
LP(1(
Scheduling(future(events(
Wall()me(=(2s(
True for all models and fideli0es!

Virtual()me(
Time(window(
LP(0(
LP(1(
Scheduling(future(events(
What is the major source of suffering in parallel discrete event simula%on? § Parallelism possible mainly from lookahead (safe %me window)
based on virtual latency between components
10

Solu%ons to the problem exist, but are non-‐trivial: Why rewrite over and over? § “Naïve” conserva%ve %me-‐stepping algorithm
§ Global, collec%ve communica%on § Communica%on op%miza%ons to lower prefactor, but has scalability limits
11
LP#2#Queue# Event#B#
t=17#Lookahead##δ=10#
tmin=17#tmax=27#
Event#C#t=10#
Event#D#T=21#
Local#queue#(LP#0)#
tlocal=7#Local# Global#
tmax=18#
LP#1#Queue# Event#A#
T=8#Tmin=8#Tmax=18#
Figure 3. Snapshot of events and timestamps for example conservative PDESwith LP queues
LP#2#Queue#
Lookahead##δ=10#
tmin=17#tmax=27#
Event#D#T=21#
Local#queue#(LP#0)#
tlocal=17#Local# Global#
tmax=27#
LP#1#Queue# Event#E#
T=19#Tmin=19#Tmax=29#
Figure 4. Snapshot of events and timestamps for example conservative PDESwith LP queues
checkpointing, the entire application state is saved at regularintervals, providing a fallback point. In reverse computation,the entire state is not saved - only an event list is maintained.When violations occur, the events must provide a “reverse”mechanism to undo all state changes. Checkpointing inducesa significant overhead even if no time violations occur. Reversecomputation only induces overhead when violations occur. De-tailed packet-level network simulations have been performedat very large scales using reverse computation with the ROSSsimulator []. Both checkpointing and reverse computationpresent special challenges for our desired simulation mode.There is a large amount (several TB) of application state tosave when simulating 100K-1M network endpoints, causinga very high storage and time overhead. Checkpoint strate-gies may not be feasible. Reverse computation also presentssignificant challenges since we want to allow arbitrary codeto be executed on real software stacks. If the simulationproceeds through a simple and well-defined state machine,programming reverse computation can be straightforward. Apacket sent that empties a queue, e.g. can be reinserted intothe queue. It is not obvious (or likely even possible) to definereverse computation for arbitrary code. Thus, despite potentialfor increased parallelism with optimistic PDES, we pursue aconservative strategy here.
Conservative approaches generally operate through event
queues []. Each LP maintains an event queue for every LPit might receive events from (Figures 3,4). Each event queuehas an associated time stamp indicating the last known virtualtime at the other LP. As an LP receives events on a queue,the new events advance the timestamp In Figure 3, the localprocess (LP 0) has synchronized and received events with thetimestamp t = 8 and t = 17 from the remote LPs 1 and 2.Because the lookahead is � = 10, LP 0 is guaranteed that LP 1will not deliver anything new with timestamp less than 18 andLP 2 will not deliver anything with timestamp less than 27.The local process can therefore safely run Event C at t = 10,Event B at t = 17 and advance time until t = 18. The localprocess now stalls and is unable to run Event D. In the nextsynchronization, LP 0 receives Event E with time t = 19.It has not received any new messages from LP 2, but it canstill advance its time window until t = 27 and can safely runEvent E and Event D. This scheme requires an LP to regularlyreceive events on each queue. If no events are received, thequeue time is never updated and an LP will block waiting forupdates. If such a block occurs, an LP must send so-callednull messages to “request” a time update. Once a new timeupdate is received, the LP can advance its time window andrun more events.
This scheme can be highly efficient for certain workloads.Even if there are 100 LPs, each LP might only communi-cate with, e.g., 3 other neighbors. Only local point-to-pointcommunication is required to synchronize times rather than aglobal communication. When many events are sent betweenLPs (i.e null messages are not needed), it also provides somedegree of asynchrony as LPs do not explicitly block waiting oneach other. For our workloads, however, the above algorithmbecomes highly inefficient. In many network topologies andmodels, each LP is connected to every other LP, erasingthe benefit of local communication. Furthermore, our simula-tor emphasizes coarse-grained compute and network models.Large time gaps often exist between consecutive events, oftenmuch larger than the lookahead. This leads to a pathologicalsituation in which LPs are consumed sending null messagesback and forth.
while t < ttermination
doRun all events until t + �Log event sends to S = {NLP0
events
, NLP0bytes
, NLP1events
, . . .}MPI ReduceScatter with SUM array SMPI ReduceScatter returns N total
events
, N total
bytes
N left
bytes
= N total
bytes
for msgNum < N total
events
doMPI Recv(void*, MPI ANY, N left
bytes
)N left
bytes
= N left
bytes
� msgSizeend forDetermine tlocal
min
MPI Allreduce(tglobal
min
, tlocal
min
)t = tglobal
min
end while
Here we instead use a global synchronization algorithm.While in some ways the simplest, it actually represents anoptimization on the event queue framework for workloads en-countered with macroscale SST. The simulation begins at t = 0with lookahead � determined from the network parameters. Weconsider a simulation with N
lp
logical processes. Within the
Figure 3. Snapshot of events and timestamps for example conservative PDESwith LP queues
LP#2#Queue# Event#B#
t=17#Lookahead##δ=10#
tmin=17#tmax=27#
Event#C#t=10#
Event#D#T=21#
Local#queue#(LP#0)#
tlocal=7#Local# Global#
tmax=18#
LP#1#Queue# Event#A#
T=8#Tmin=8#Tmax=18#
Figure 3. Snapshot of events and timestamps for example conservative PDESwith LP queues
LP#2#Queue#
Lookahead##δ=10#
tmin=17#tmax=27#
Event#D#T=21#
Local#queue#(LP#0)#
tlocal=17#Local# Global#
tmax=27#
LP#1#Queue# Event#E#
T=19#Tmin=19#Tmax=29#
Figure 4. Snapshot of events and timestamps for example conservative PDESwith LP queues
checkpointing, the entire application state is saved at regularintervals, providing a fallback point. In reverse computation,the entire state is not saved - only an event list is maintained.When violations occur, the events must provide a “reverse”mechanism to undo all state changes. Checkpointing inducesa significant overhead even if no time violations occur. Reversecomputation only induces overhead when violations occur. De-tailed packet-level network simulations have been performedat very large scales using reverse computation with the ROSSsimulator []. Both checkpointing and reverse computationpresent special challenges for our desired simulation mode.There is a large amount (several TB) of application state tosave when simulating 100K-1M network endpoints, causinga very high storage and time overhead. Checkpoint strate-gies may not be feasible. Reverse computation also presentssignificant challenges since we want to allow arbitrary codeto be executed on real software stacks. If the simulationproceeds through a simple and well-defined state machine,programming reverse computation can be straightforward. Apacket sent that empties a queue, e.g. can be reinserted intothe queue. It is not obvious (or likely even possible) to definereverse computation for arbitrary code. Thus, despite potentialfor increased parallelism with optimistic PDES, we pursue aconservative strategy here.
Conservative approaches generally operate through event
queues []. Each LP maintains an event queue for every LPit might receive events from (Figures 3,4). Each event queuehas an associated time stamp indicating the last known virtualtime at the other LP. As an LP receives events on a queue,the new events advance the timestamp In Figure 3, the localprocess (LP 0) has synchronized and received events with thetimestamp t = 8 and t = 17 from the remote LPs 1 and 2.Because the lookahead is � = 10, LP 0 is guaranteed that LP 1will not deliver anything new with timestamp less than 18 andLP 2 will not deliver anything with timestamp less than 27.The local process can therefore safely run Event C at t = 10,Event B at t = 17 and advance time until t = 18. The localprocess now stalls and is unable to run Event D. In the nextsynchronization, LP 0 receives Event E with time t = 19.It has not received any new messages from LP 2, but it canstill advance its time window until t = 27 and can safely runEvent E and Event D. This scheme requires an LP to regularlyreceive events on each queue. If no events are received, thequeue time is never updated and an LP will block waiting forupdates. If such a block occurs, an LP must send so-callednull messages to “request” a time update. Once a new timeupdate is received, the LP can advance its time window andrun more events.
This scheme can be highly efficient for certain workloads.Even if there are 100 LPs, each LP might only communi-cate with, e.g., 3 other neighbors. Only local point-to-pointcommunication is required to synchronize times rather than aglobal communication. When many events are sent betweenLPs (i.e null messages are not needed), it also provides somedegree of asynchrony as LPs do not explicitly block waiting oneach other. For our workloads, however, the above algorithmbecomes highly inefficient. In many network topologies andmodels, each LP is connected to every other LP, erasingthe benefit of local communication. Furthermore, our simula-tor emphasizes coarse-grained compute and network models.Large time gaps often exist between consecutive events, oftenmuch larger than the lookahead. This leads to a pathologicalsituation in which LPs are consumed sending null messagesback and forth.
while t < ttermination
doRun all events until t + �Log event sends to S = {NLP0
events
, NLP0bytes
, NLP1events
, . . .}MPI ReduceScatter with SUM array SMPI ReduceScatter returns N total
events
, N total
bytes
N left
bytes
= N total
bytes
for msgNum < N total
events
doMPI Recv(void*, MPI ANY, N left
bytes
)N left
bytes
= N left
bytes
� msgSizeend forDetermine tlocal
min
MPI Allreduce(tglobal
min
, tlocal
min
)t = tglobal
min
end while
Here we instead use a global synchronization algorithm.While in some ways the simplest, it actually represents anoptimization on the event queue framework for workloads en-countered with macroscale SST. The simulation begins at t = 0with lookahead � determined from the network parameters. Weconsider a simulation with N
lp
logical processes. Within the
Figure 4. Snapshot of events and timestamps for example conservative PDESwith LP queues
induces overhead when violations occur. Detailed packet-levelnetwork simulations have been performed at very large scalesusing reverse computation with the ROSS simulator [?], [?].Both checkpointing and reverse computation present specialchallenges for our desired simulation mode. There is a largeamount (several TB) of application state to save when simulat-ing 100K-1M network endpoints, causing a very high storageand time overhead. Checkpoint strategies may not be feasible.Reverse computation also presents significant challenges sincewe want to allow arbitrary code to be executed on real softwarestacks. If the simulation proceeds through a simple and well-defined state machine, programming reverse computation canbe straightforward. A packet sent that empties a queue, e.g.can be placed back into its original position in the queue toreverse the event. It is not obvious (or likely even possible)to define reverse computation for arbitrary code. Thus, despitepotential for increased parallelism with optimistic PDES, wepursue a conservative strategy here.
Conservative approaches generally operate through eventqueues [?], [?]. Each LP maintains an event queue for everyLP it might receive events from (Figures ??,??). Each eventqueue has an associated time stamp indicating the last knownvirtual time at the other LP. As an LP receives events on aqueue, the new events advance the timestamp. In Figure ??,the local process (LP 0) has synchronized and received eventswith the timestamp t = 8 and t = 17 from the remote LPs 1
and 2. Because the lookahead is � = 10, LP 0 is guaranteedthat LP 1 will not deliver anything new with timestamp lessthan 18 and LP 2 will not deliver anything with timestamp lessthan 27. The local process can therefore safely run event C att = 10, event B at t = 17 and advance time until t = 18. Thelocal process now stalls and is unable to run event D. In thenext synchronization, LP 0 receives event E with time t = 19.It has not received any new messages from LP 2, but it canstill advance its time window until t = 27 and can safely runevent E and event D. This scheme requires an LP to regularlyreceive events on each queue. If no events are received, thequeue time is never updated and an LP will block waiting forupdates. If such a block occurs, an LP must send so-called nullmessages to “request” a time update (although methods haveavoiding null messages have been proposed [?]). Once a newtime update is received, the LP can advance its time windowand run more events.
This scheme can be highly efficient for certain workloads.Even if there are 100 LPs, each LP might only communicatewith, e.g., 3 other neighbors. Only local point-to-point commu-nication is required to synchronize times rather than a globalcommunication. When many events are sent between LPs (i.enull messages not needed), it also provides some asynchronyas LPs do not explicitly block waiting on each other.
For our workloads, however, the above algorithm becomeshighly inefficient. In many network topologies and models,each LP is connected to every other LP, erasing the benefit oflocal communication. Furthermore, our simulator emphasizescoarse-grained compute and network models. Large time gapsoften exist between consecutive events, often much larger thanthe lookahead. This leads to a pathological situation in whichLPs are consumed sending null messages back and forth.
while t < ttermination
doRun all events until t + �Log event sends to S = {NLP0
events
, NLP0bytes
, NLP1events
, . . .}MPI ReduceScatter with SUM array SMPI ReduceScatter returns N total
events
, N total
bytes
N left
bytes
= N total
bytes
for msgNum < N total
events
doMPI Recv(void*, MPI ANY, N left
bytes
)N left
bytes
= N left
bytes
� msgSizeend forDetermine tlocal
min
MPI Allreduce(tglobal
min
, tlocal
min
)t = tglobal
min
end while
Here we instead use a global synchronization algorithm.While in some ways the simplest, it actually represents anoptimization on the event queue framework for workloads en-countered with macroscale SST. The simulation begins at t = 0with lookahead � determined from the network parameters. Weconsider a simulation with N
lp
logical processes. Within thetime window (0, �) each LP will call MPI Isend to deliverevents to other LPs. At t = �, every LP performs two blockingMPI collectives. First, they perform a reduce-scatter with asum function, illustrated in Figure ??. Each LP tracks the totalnumber of events and the total number of bytes sent to everyother LP. This array of size 2N
lp
is passed as input to thereduce-scatter. Every LP receives as input from the reduce-

Solu%ons to the problem exist, but are non-‐trivial: Why rewrite over and over? § Conserva%ve algorithm with event queues: Op%miza%on to limit
communica%on for LP’s that are “connected” § Local, point-‐to-‐point communica%on § More difficult to implement
12
LP#2#Queue# Event#B#
t=17#Lookahead##δ=10#
tmin=17#tmax=27#
Event#C#t=10#
Event#D#T=21#
Local#queue#(LP#0)#
tlocal=7#Local# Global#
tmax=18#
LP#1#Queue# Event#A#
T=8#Tmin=8#Tmax=18#
Figure 3. Snapshot of events and timestamps for example conservative PDESwith LP queues
LP#2#Queue#
Lookahead##δ=10#
tmin=17#tmax=27#
Event#D#T=21#
Local#queue#(LP#0)#
tlocal=17#Local# Global#
tmax=27#
LP#1#Queue# Event#E#
T=19#Tmin=19#Tmax=29#
Figure 4. Snapshot of events and timestamps for example conservative PDESwith LP queues
checkpointing, the entire application state is saved at regularintervals, providing a fallback point. In reverse computation,the entire state is not saved - only an event list is maintained.When violations occur, the events must provide a “reverse”mechanism to undo all state changes. Checkpointing inducesa significant overhead even if no time violations occur. Reversecomputation only induces overhead when violations occur. De-tailed packet-level network simulations have been performedat very large scales using reverse computation with the ROSSsimulator []. Both checkpointing and reverse computationpresent special challenges for our desired simulation mode.There is a large amount (several TB) of application state tosave when simulating 100K-1M network endpoints, causinga very high storage and time overhead. Checkpoint strate-gies may not be feasible. Reverse computation also presentssignificant challenges since we want to allow arbitrary codeto be executed on real software stacks. If the simulationproceeds through a simple and well-defined state machine,programming reverse computation can be straightforward. Apacket sent that empties a queue, e.g. can be reinserted intothe queue. It is not obvious (or likely even possible) to definereverse computation for arbitrary code. Thus, despite potentialfor increased parallelism with optimistic PDES, we pursue aconservative strategy here.
Conservative approaches generally operate through event
queues []. Each LP maintains an event queue for every LPit might receive events from (Figures 3,4). Each event queuehas an associated time stamp indicating the last known virtualtime at the other LP. As an LP receives events on a queue,the new events advance the timestamp In Figure 3, the localprocess (LP 0) has synchronized and received events with thetimestamp t = 8 and t = 17 from the remote LPs 1 and 2.Because the lookahead is � = 10, LP 0 is guaranteed that LP 1will not deliver anything new with timestamp less than 18 andLP 2 will not deliver anything with timestamp less than 27.The local process can therefore safely run Event C at t = 10,Event B at t = 17 and advance time until t = 18. The localprocess now stalls and is unable to run Event D. In the nextsynchronization, LP 0 receives Event E with time t = 19.It has not received any new messages from LP 2, but it canstill advance its time window until t = 27 and can safely runEvent E and Event D. This scheme requires an LP to regularlyreceive events on each queue. If no events are received, thequeue time is never updated and an LP will block waiting forupdates. If such a block occurs, an LP must send so-callednull messages to “request” a time update. Once a new timeupdate is received, the LP can advance its time window andrun more events.
This scheme can be highly efficient for certain workloads.Even if there are 100 LPs, each LP might only communi-cate with, e.g., 3 other neighbors. Only local point-to-pointcommunication is required to synchronize times rather than aglobal communication. When many events are sent betweenLPs (i.e null messages are not needed), it also provides somedegree of asynchrony as LPs do not explicitly block waiting oneach other. For our workloads, however, the above algorithmbecomes highly inefficient. In many network topologies andmodels, each LP is connected to every other LP, erasingthe benefit of local communication. Furthermore, our simula-tor emphasizes coarse-grained compute and network models.Large time gaps often exist between consecutive events, oftenmuch larger than the lookahead. This leads to a pathologicalsituation in which LPs are consumed sending null messagesback and forth.
while t < ttermination
doRun all events until t+ �Log event sends to S = {NLP0
events
, NLP0bytes
, NLP1events
, . . .}MPI ReduceScatter with SUM array SMPI ReduceScatter returns N total
events
, N total
bytes
N left
bytes
= N total
bytes
for msgNum < N total
events
doMPI Recv(void*, MPI ANY, N left
bytes
)N left
bytes
= N left
bytes
�msgSizeend forDetermine tlocal
min
MPI Allreduce(tglobalmin
, tlocalmin
)t = tglobal
min
end while
Here we instead use a global synchronization algorithm.While in some ways the simplest, it actually represents anoptimization on the event queue framework for workloads en-countered with macroscale SST. The simulation begins at t = 0with lookahead � determined from the network parameters. Weconsider a simulation with N
lp
logical processes. Within the

What makes us write ad-‐hoc code instead of leverage exis%ng code? § Lack of standards § Lack of documenta%on § Huge monolithic code bases § Compa%bility across platorms § A million and one dependencies § Physical models dependent upon simula%on framework
13
Experiments we care about are model-driven – simulator is a tool to get us what we really care about!
Virtual()me(
Time(window(
LP(0(
LP(1(
Scheduling(future(events(
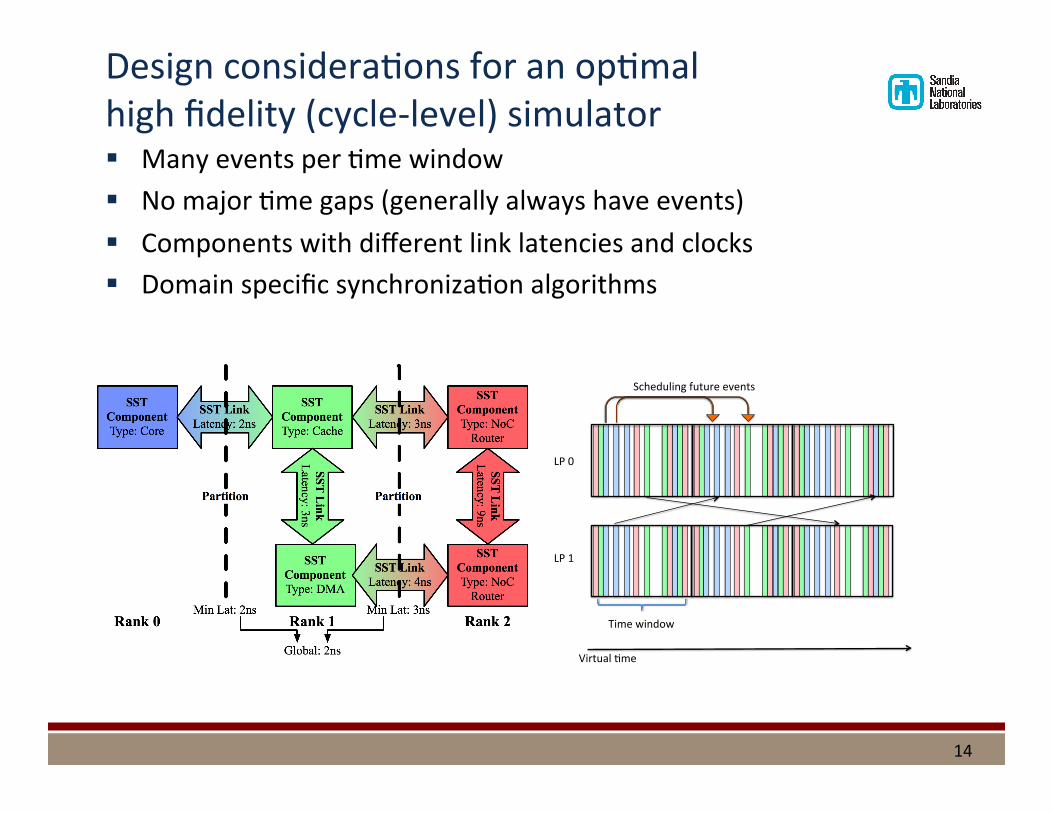
Design considera%ons for an op%mal high fidelity (cycle-‐level) simulator § Many events per %me window § No major %me gaps (generally always have events) § Components with different link latencies and clocks § Domain specific synchroniza%on algorithms
14
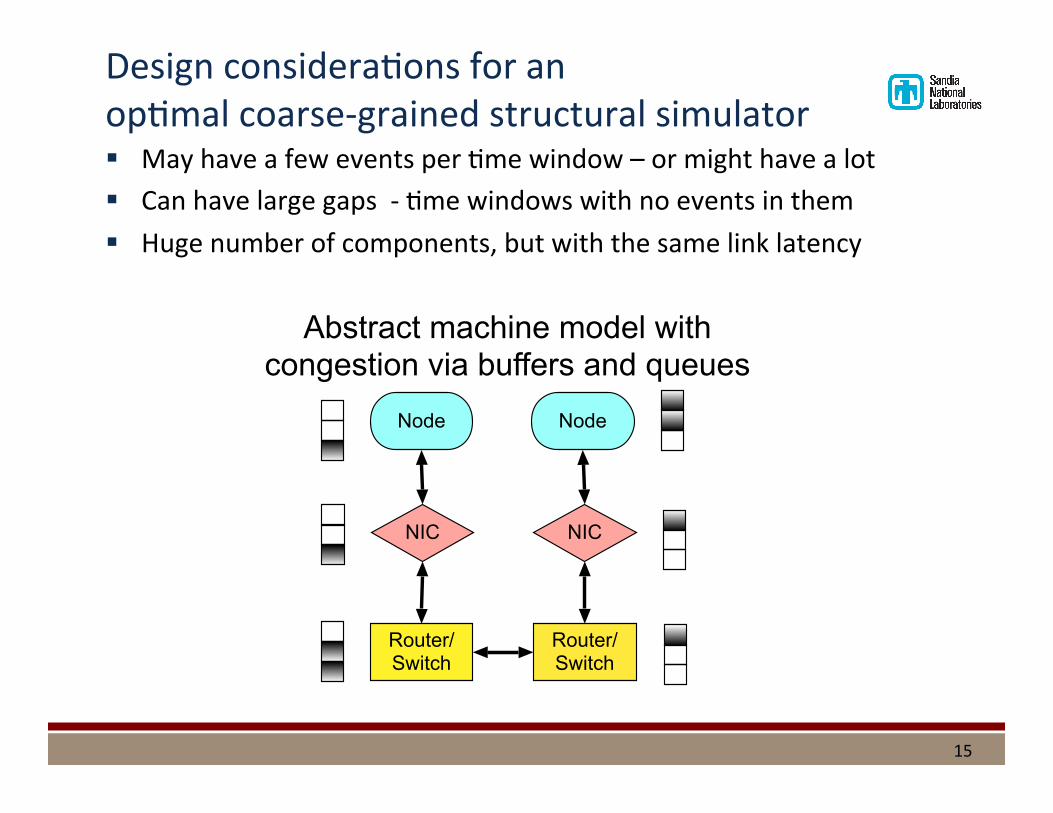
Design considera%ons for an op%mal coarse-‐grained structural simulator § May have a few events per %me window – or might have a lot § Can have large gaps -‐ %me windows with no events in them § Huge number of components, but with the same link latency
15
Router/ Switch
Router/ Switch
Node
NIC
Node
NIC
Abstract machine model with congestion via buffers and queues
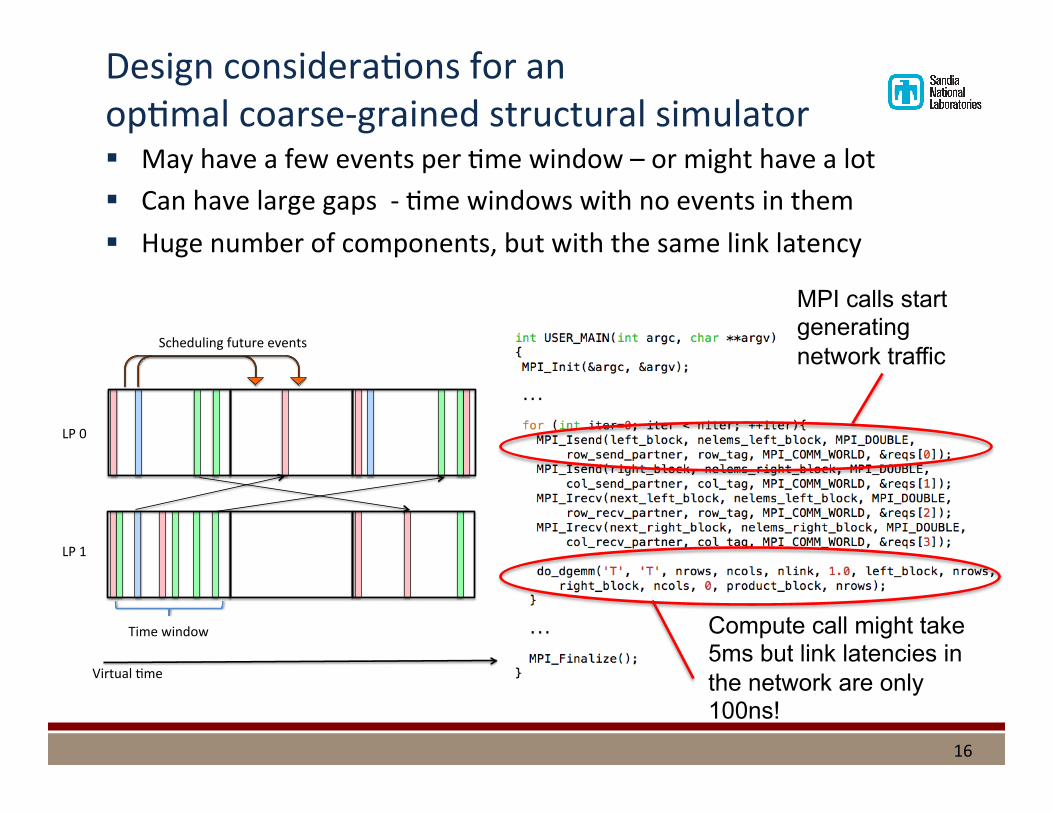
Design considera%ons for an op%mal coarse-‐grained structural simulator § May have a few events per %me window – or might have a lot § Can have large gaps -‐ %me windows with no events in them § Huge number of components, but with the same link latency
16
Virtual()me(
Time(window(
LP(0(
LP(1(
Scheduling(future(events(
Compute call might take 5ms but link latencies in the network are only 100ns!
MPI calls start generating network traffic

Design considera%ons for an op%mal coarse-‐grained structural simulator § May have a few events per %me window – or might have a lot § Can have large gaps -‐ %me windows with no events in them § Huge number of components, but with the same link latency
17
Router/Switch
Compute Nodes
LP 0 LP 3
LP 1 LP 2

Design considera%ons for a simulator based on analy%cal models § Only a few events per %me window § Many different components, but all connected to each other
18
Compute Node
Compute Node
Compute Node
Compute Node
Compute Node
Compute Node
α = Latency β = Inverse bandwidth
N =Message size
ΔT=α + β N

Unifying elements across all fideli%es
§ Sending network messages § Portability layer to network APIs § Serializa%on library for event objects
§ Local/global virtual %me § Event ordering and correctness § Model input and sta%s%cs collec%on
§ Par%%oning components across parallel workers § Mapping of LPs to physical nodes § Op%mize par%%on for cheaper
communica%on
§ Managing/scheduling events § Map/calendar/heap data structures § Cancel events
19

Unifying elements across all fideli%es
§ Sending network messages § Portability layer to network APIs § Serializa%on library for event objects
§ Local/global virtual %me § Event ordering and correctness § Model input and sta%s%cs collec%on
§ Par%%oning components across parallel workers § Mapping of LPs to physical nodes § Op%mize par%%on for cheaper
communica%on
§ Managing/scheduling events § Map/calendar/heap data structures § Cancel events
20

Unifying elements across all fideli%es
§ Sending network messages § Portability layer to network APIs § Serializa%on library for event objects
§ Local/global virtual %me § Event ordering and correctness § Model input and sta%s%cs collec%on
§ Par%%oning components across parallel workers § Mapping of LPs to physical nodes § Op%mize par%%on for cheaper
communica%on
§ Managing/scheduling events § Map/calendar/heap data structures § Cancel events
21
Coarse-grained time
Cycle-level time

Unifying elements across all fideli%es
§ Sending network messages § Portability layer to network APIs § Serializa%on library for event objects
§ Local/global virtual %me § Event ordering and correctness § Model input and sta%s%cs collec%on
§ Par%%oning components across parallel workers § Mapping of LPs to physical nodes § Op%mize par%%on for cheaper
communica%on
§ Managing/scheduling events § Map/calendar/heap data structures § Cancel events
22

Unifying elements across all fideli%es
§ Sending network messages § Portability layer to network APIs § Serializa%on library for event objects
§ Local/global virtual %me § Event ordering and correctness § Model input and sta%s%cs collec%on
§ Par%%oning components across parallel workers § Mapping of LPs to physical nodes § Op%mize par%%on for cheaper
communica%on
§ Managing/scheduling events § Map/calendar/heap data structures § Cancel events
23
T=1,T=2, T=3
T=7 T=17, T=19
T=25 T=36
T=100
O(Log(N)) heap
O(1) calendar

Disunifying elements across fideli%es: par%%oning strategy and parallel algorithm § Par%%oning strategy
§ Cycle-‐level has heterogeneous components – par%%oning really requires intelligent graph par%%oner
§ Coarse-‐grained has many homogenous components – par%%oning s%ll requires intelligent par%%oner, but more about minimizing graph connec%vity than best link latency
§ Parallel algorithm § Global assump%ons on interoperability components
§ Can any memory subsystem model interact with any processor or network model? Or are event messages only “self-‐compa%ble”?
24

Polymorphic components can be tuned for different problems § Components don’t need to be aware of par%%oning strategy § Components don’t need to be aware of parallel algorithm
25
The Simulation framework consists of a i) Core and ii) interacting Components that form the architecture simulation model. The core provides services common across models, such as
instantiating components, providing configuration information, partitioning models for parallel
execution, coordinating a common concept of time (e.g., in parallel execution), and transparently
handling parallel and local communication of events between model components. Model
components communicate through Links which deliver Events between components. Proper temporal sequencing of component execution and event delivery is transparently handled by the
core. Thus architecture component models are easily re-used and shared across system-level
simulation models. Parallel execution is handled by partitioning the simulation model and
assigning components to physical cores in a target parallel machine.
A key principle of the design is that model components are oblivious to sequential or parallel
execution, and hence are transparently reusable in multiple simulation scenarios. For example,
when events are communicated between components over a link, the component is unaware
whether the destination component is local or remote. Delivery is handled by the core including
any serialization necessary for remote communication in the event that the destination core is
remotely located.
The simulation model as a whole is specified via a system description that specifies
components, their interconnection, and their configuration including component-level and
system-level parameters. The latter are used in transparently partitioning the model for parallel
execution. Our current efforts are focused on two main aspects of the preceding framework - i)
the core API, and ii) the component API. These efforts have been influenced by several ongoing
projects notably SST, GEM5, and Manifold. Preliminary efforts at migrating models between SST
and Manifold supports the anticipated benefits of the common API.
A Call To Arms Our position is that this API is critical for the architecture community, but requires broad support
to be successful. We ask for community input and collaboration on this ongoing design project.
Please join in this effort by signing up to our mailing list ______ and visiting our design wiki
______.

Challenge problem: mixing fideli%es
26
LP with heavy-‐weight node opera%ng on different %me scales, but look ahead determined by coarse-‐grained links!
Router/Switch
Compute Nodes

Challenge problem: mixing fideli%es
27
Router/Switch
Compute Nodes
Par%%on creates op%mal lookahead on high latency links

Challenge problem: mixing fideli%es
28
Router/Switch
Compute Nodes Good partitioning balances
number of events per LP
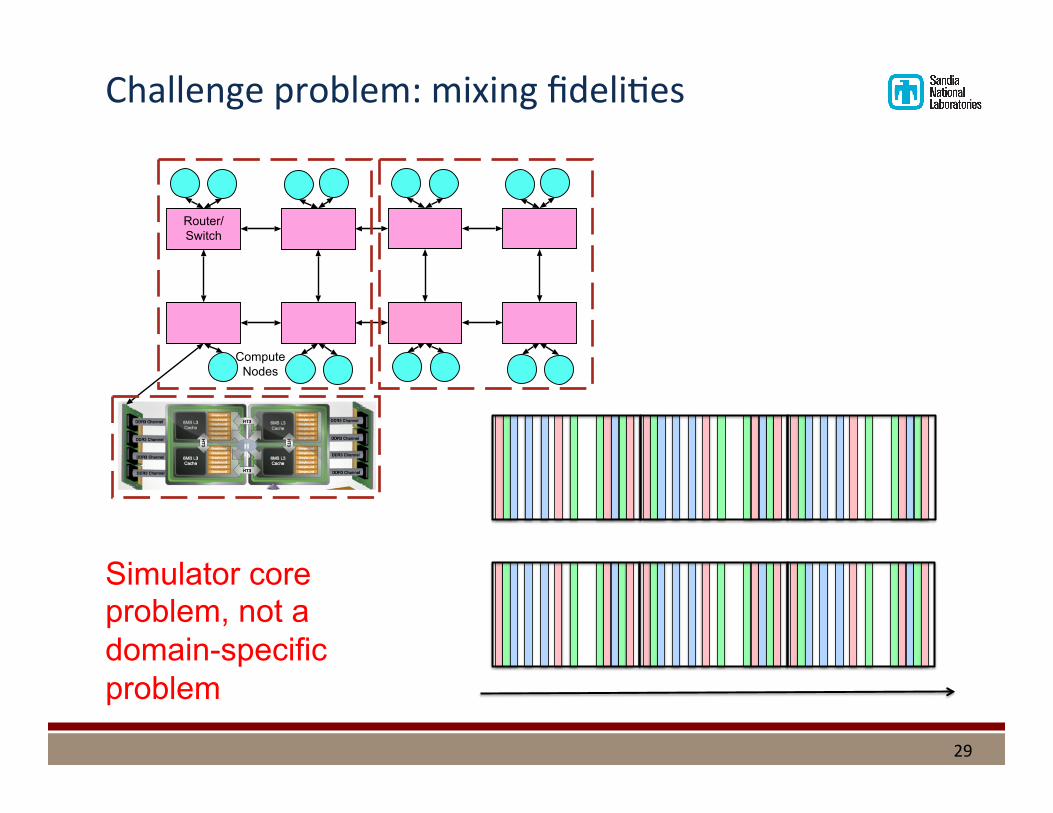
Challenge problem: mixing fideli%es
29
Router/Switch
Compute Nodes
Simulator core problem, not a domain-specific problem

Challenge problem: histogram of message delays in PDES run § Tag packet going out, going in with %me
§ Add single field to exis%ng network message object § No%on of global %me
§ Histogram object that reduces/collects data § hist-‐>add_one(delay) § Object must output usable data format/figure at end of simula%on § Data must be reduced across LPs
30
Minimal routing Adaptive routing

Challenge problem: histogram of message delays in PDES run
Majority of work should already be done for us in common core!
31
Minimal routing Adaptive routing

MODSIM is Camp David, not Sinai
32
Structural simulation toolkit at Sandia (SST) is a jumping off point for discussing universal simulation standards, not C++ framework written on stone tablets!

MODSIM is Camp David, not Sinai
33
We think our PDES core is mature and lightweight enough to make your life easer – enable you to use your own code, not force you to use ours!

Range of simula%on: success stories so far
34
Coarse grain + analytic
Coarse grain Cycle Level Mixed fidelity
The Simulation framework consists of a i) Core and ii) interacting Components that form the architecture simulation model. The core provides services common across models, such as
instantiating components, providing configuration information, partitioning models for parallel
execution, coordinating a common concept of time (e.g., in parallel execution), and transparently
handling parallel and local communication of events between model components. Model
components communicate through Links which deliver Events between components. Proper temporal sequencing of component execution and event delivery is transparently handled by the
core. Thus architecture component models are easily re-used and shared across system-level
simulation models. Parallel execution is handled by partitioning the simulation model and
assigning components to physical cores in a target parallel machine.
A key principle of the design is that model components are oblivious to sequential or parallel
execution, and hence are transparently reusable in multiple simulation scenarios. For example,
when events are communicated between components over a link, the component is unaware
whether the destination component is local or remote. Delivery is handled by the core including
any serialization necessary for remote communication in the event that the destination core is
remotely located.
The simulation model as a whole is specified via a system description that specifies
components, their interconnection, and their configuration including component-level and
system-level parameters. The latter are used in transparently partitioning the model for parallel
execution. Our current efforts are focused on two main aspects of the preceding framework - i)
the core API, and ii) the component API. These efforts have been influenced by several ongoing
projects notably SST, GEM5, and Manifold. Preliminary efforts at migrating models between SST
and Manifold supports the anticipated benefits of the common API.
A Call To Arms Our position is that this API is critical for the architecture community, but requires broad support
to be successful. We ask for community input and collaboration on this ongoing design project.
Please join in this effort by signing up to our mailing list ______ and visiting our design wiki
______.
+Eiger
Logic
clk
clk cond
input
clk
Common Core
+GEM5

MODSIM Summary
§ Gaps: § Lack of standards, lack of code reuse
§ Bigger picture and poten%al collaborators: § Everyone? Anyone who wants to scale experiments through PDES or wants to
compose models mixing different fidelity/physics
§ What would make it easier to leverage results from other groups? § If you find yourself wri%ng a PDES core, who you gonna call…
§ Development/adop5on of standards will be driven by collabora5on and refined through use cases
35





























