Embed Size (px)
Citation preview

Shortest Path Algorithms Application to Traffic
Assignment Problem Comparing Central
Processing
Unit (CPU) vs. Graphical Processing Unit (GPU)
Vishal SinghDepartment of Computer Science & Engineering
University of Texas-ArlingtonArlington, TX
Advisor: Dr. Srinivas PeetaMentor: Dr. Xiaozheng He & Mr. Amit Kumar
NEXTRANS Center/Department of Civil Engineering
Purdue UniversityWest Lafayette, Indiana

Traffic Assignment Problem A historical problem which over the course of the past
five decades has been addressed through a number of different iterative algorithms [3].
It is the fourth phase of the classical urban transportation planning system model following: Trip Generation, Trip Distribution, and Mode Choice [4].
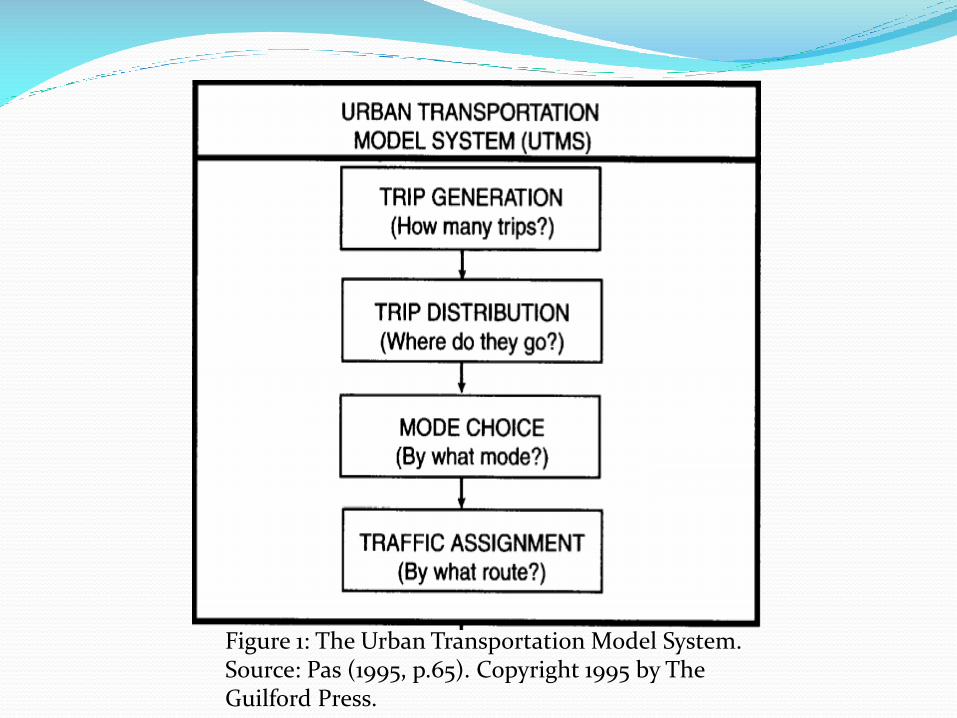
Figure 1: The Urban Transportation Model System. Source: Pas (1995, p.65). Copyright 1995 by The Guilford Press.

Traffic Assignment Problem(TAP) To estimate the volume of traffic on the links of the
network
To provide estimates of travel costs between trip origins and destinations.
To identify heavily traveled or congested arcs (links) as well as the routes used between each origin-destination (O-D) pair.

Traffic Assignment Problem(TAP)
The optimal goal for TAP is User Equilibrium which is
based on minimizing the travel time of individual users
[3].

User Equilibrium
User Equilibrium is achieved when there no
alternative in path choice that is available for
drivers to improve one’s travel time [2].
Every used route connecting an origin and destination has equal and minimal travel time.
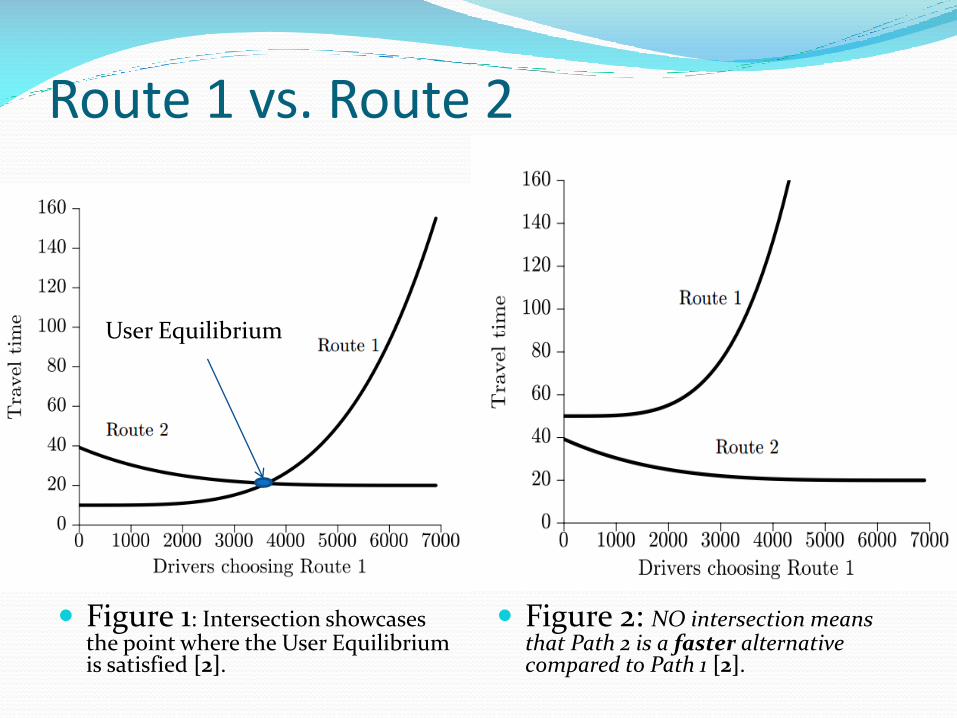
Route 1 vs. Route 2
Figure 1: Intersection showcases the point where the User Equilibrium is satisfied [2].
Figure 2: NO intersection means that Path 2 is a faster alternative compared to Path 1 [2].
User Equilibrium

Slope-based MultiPath Algorithm
Several approaches have been established to solve TAP
Gradient projection(GP) algorithm of Jayakrishnan
Frank-Wolfe(F-W) algorithm
Origin-based algorithm(OBA)
SMPA seeks to move path costs towards the average cost for an O-D pair at each respective iteration.

Flow Update MechanismFigure 3: At each
iteration, the flow
update seeks to
reduce the costs of
costlier paths and
bring them
to the average cost
(Cav) for the O-D
pair and aims to
increase the costs
of the cheaper paths
to a value μ [3].
Costlier paths
Cheaper paths

What is GPU Computing?
GPU computing is the use of a GPU (graphics processing
unit) together with a CPU to accelerate general-purpose
scientific and engineering applications.

CUDA
CUDA is the language for GPU computing
It enables dramatic increases in computing performance by harnessing the power of the graphics processing unit (GPU).
Good for lots of computations and heavy data sets.
Tailored for engineering simulation and massive data sets.

How is this beneficial to TAP problem
In transportation Engineering, simulations play a vital role in attaining data and network modeling.
In case of the Winnipeg network and Austin network, the data sets are so massive that implementation through CPU would take hours.
Whereas this is where GPU computing comes into play as it is efficient for massive data, where parallel computing is utilized to a greater extent.
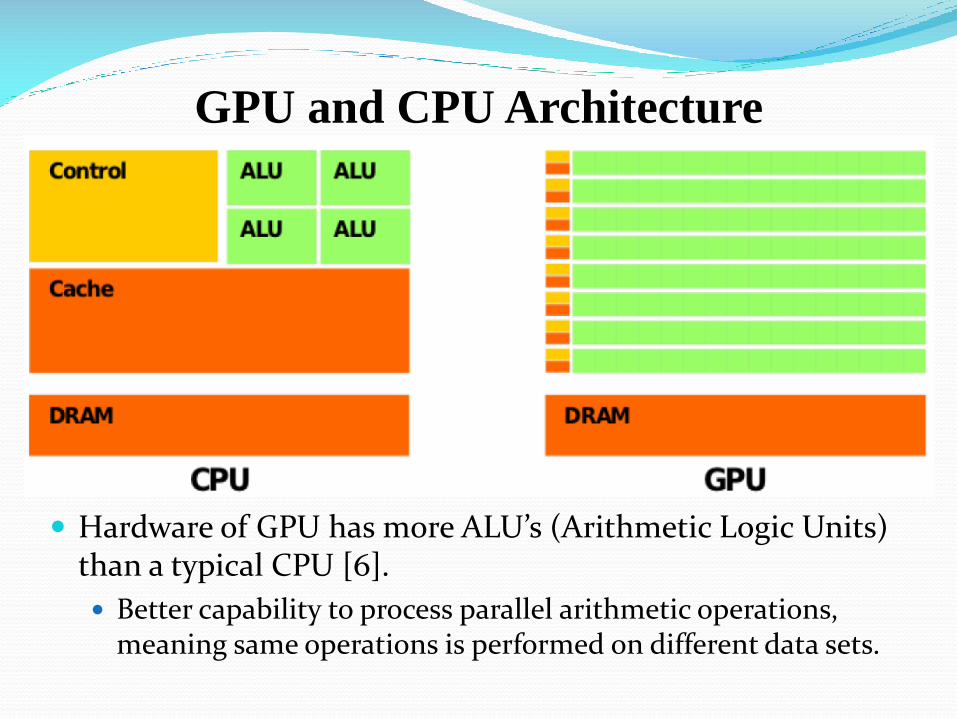
Hardware of GPU has more ALU’s (Arithmetic Logic Units) than a typical CPU [6].
Better capability to process parallel arithmetic operations, meaning same operations is performed on different data sets.
GPU and CPU Architecture
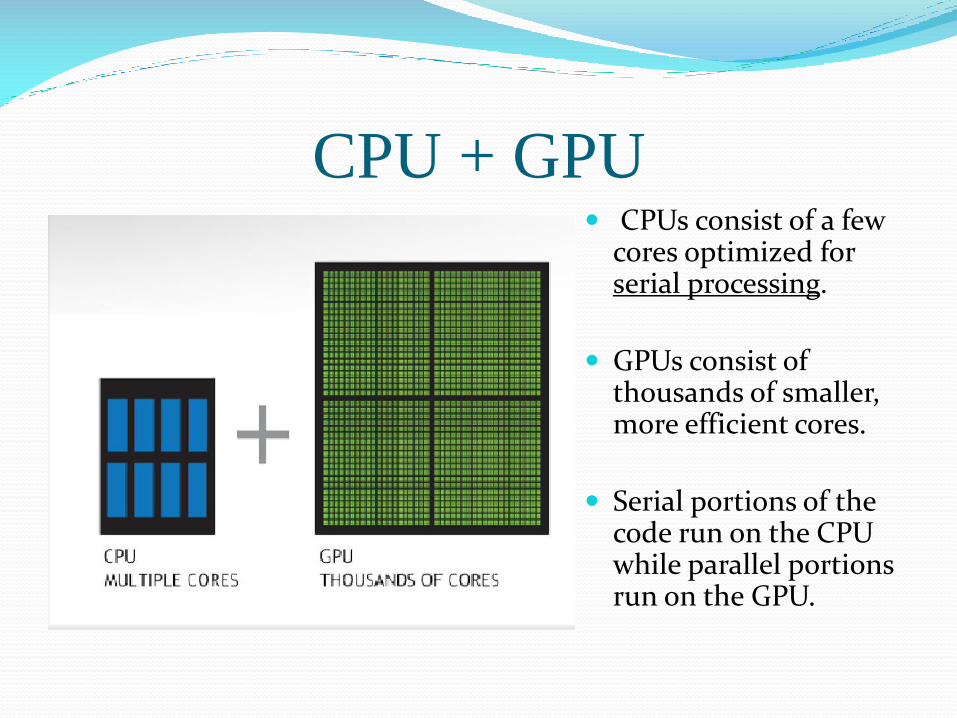
CPU + GPU CPUs consist of a few
cores optimized for serial processing.
GPUs consist of thousands of smaller, more efficient cores.
Serial portions of the code run on the CPU while parallel portions run on the GPU.

CPU vs. GPU CPUs are designed for a wide variety of applications
and to provide fast response times to a single task.
Limited number of cores limits how many pieces of data can be processed simultaneously.
GPUs, whereas are built specifically for rendering and other graphics applications that have a large degree of data parallelism [2].
Larger number of cores makes its ideal for throughput computing.

CPU Implementation The CPU code for the shortest has been implemented
in C language as it is the most efficient in terms of computational speed.
Dijikstra’s algorithm is used to implement the shortest path, as this step is the most time consuming, which has been implemented successfully.

Constrains
But the algorithm faces bugs as there is memory management problems as well as a lack of data structure knowledge.
Not the best language in terms of my skill sets.

GPU coding Require more time to digest GPU CUDA programming
as the language is new in the market and there is limited number of resources.
Program written in CUDA are compiled by NVIDIA’s nvcc compiler and can be run only on NVIDIA’s GPU’s so in terms of implementation the restriction on the hardware limits the access for the programmer.
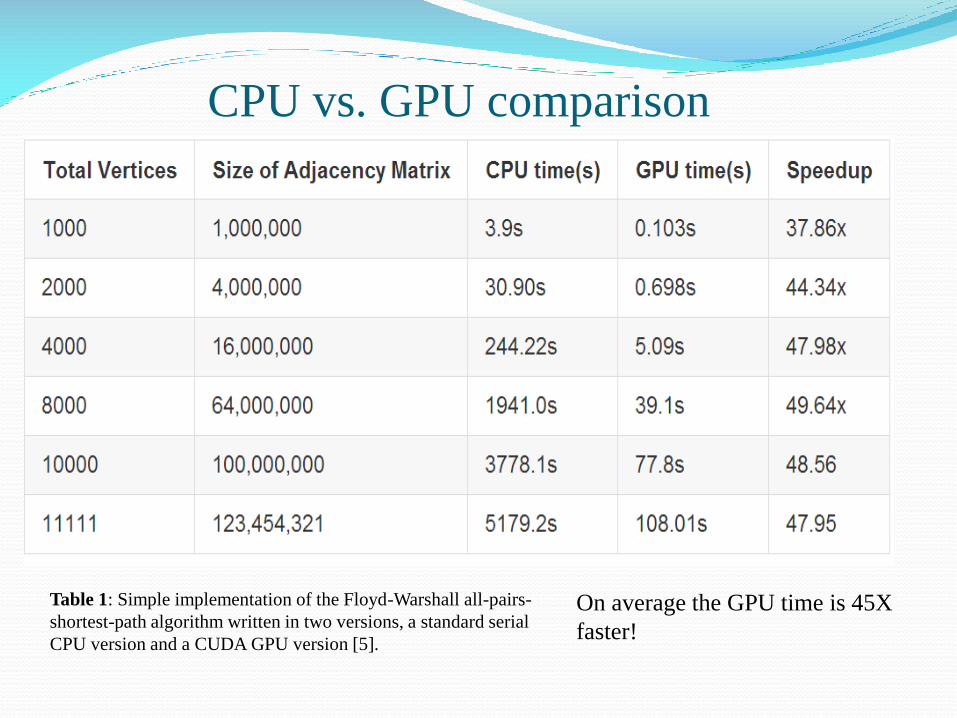
CPU vs. GPU comparison
Table 1: Simple implementation of the Floyd-Warshall all-pairs-
shortest-path algorithm written in two versions, a standard serial
CPU version and a CUDA GPU version [5].
On average the GPU time is 45X
faster!

Conclusion
The GPU aspect of shortest path algorithm has not yet been programmed in CUDA so the comparison between CPU vs. GPU is only partially satisfied.
Sample output on the Floyd-Warshall shortest path algorithm notions GPU speeds to be 45 times faster [5].
For smaller tasks, the GPU is not much faster than CPU as the overhead cost of data transfer is more than time saved by parallelization [6].
Many factors play a role in the large performance gap, with regards to which CPU and GPU are used and especially what optimizations are applied to the code on each platform [1].

What I learned essentially… The significance of C language has been more evident that ever
for me as it is clearly the most time efficient language but C is difficult to optimize due to its low-level nature, there are very few clues to the compiler as to where data structures and algorithms can be optimized or parallelized.
GPU computing is gaining momentum as in today’s age of massive data, parallel computation holds precedence. Will surely work on CUDA programming over the course of
Undergraduate studies
Data Structures is an area which I want to gain a strong grasp on as without a structure to data we cannot convert it into information.

My Doctorate Analogy Grad school is like an
isolated journey towards monkhood, as the student can be compared to the likes of Luke Skywalker.
With the advisor assuming the role of Yoda, the wise One.

References[1] Abhranil Das. Process Time Comparsion between GPU and CPU. High Performance
computing on graphics processing unit. Hamburg University. (July 2011), pp.1-11
[2] Jesse Gawling. CUDA Floyd Warshall. GitHub.com. Collaborative Revision Control. (March 2013). Web. (July 2013)
[3] R.A.Johnston. “The Urban Transportation Planning Process.” 2004. Book ch. for The Geography of Urban Transportation. Ed. by Susan Hanson and Genevieve Guiliano.
[4] Srinivas Peeta, Amit Kumar. Slope-Based Multipath Flow Update Algorithm for Static User Equilibrium Traffic Assignment Problem. Transportation Research Record: Journal of the Transportation Research Board, Vol. 2196. (Feburary 2010), pp. 1-10
[5] Stephen D. Boyles. User Equilibrium and System Optimum. https://webspace.utexas.edu/sdb382/www/teaching/ce392c/ueso.pdf
[6] Victor W. Lee, Changkyu Kim, Jatin Chhugani, Michael Deisher, Daehyun Kim, Anthony D. Nguyen, Nadathur Satish, Mikhail Smelyanskiy, Srinivas Chennupaty, Per Hammarlund, Ronak Singhal, Pradeep Dubey. Debunking the 100X GPU vs. CPU Myth: An Evaluation of Throughput Computing on CPU and GPU. SIGARCH Comput. Archit. News, Vol. 38, No. 3. (June 2010), pp. 451-460

Acknowledgements Srinivas Peeta, Ph.D.NEXTRANS Center DirectorPurdue UniversityProfessor of Civil Engineering
Xiaozheng "Sean" He, Ph.D.Research AssociatePurdue UniversityDepartment of Civil Engineering
Amit KumarDoctoral StudentPurdue UniversityDepartment of Civil Engineering
Kumer Pial Das, Ph.D.Lamar UniversityDepartment of Mathematics
Mamta Singh, Ph.D. (My Mum )Lamar UniversityDepartment of Teacher Education





























