Embed Size (px)
Citation preview

logoonly
Lecture 6: EITF20 Computer Architecture
Anders Ardö
EIT – Electrical and Information Technology, Lund University
November 13, 2013
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 1 / 56
logoonly
Outline
1 Reiteration
2 Memory hierarchy
3 Cache memory
4 Cache performance
5 Main memory
6 Summary
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 2 / 56
logoonly
Dynamic scheduling, speculation - summary
tolerates unpredictable delayscompile for one pipeline - run effectively on anotherallows speculation
multiple branchesin-order commitprecise exceptionstime, energy; recovery
significant increase in HW complexityout-of-order execution, completionregister renaming
Tomasulo, CDB, ROB
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 3 / 56
logoonly
CPU Performance Equation - Pipelining
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 4 / 56

logoonly
Summary Pipelining - ImplementationProblem Simple Scoreboard Tomasulo Tomasulo +
SpeculationStatic Sch Dynamic Scheduling
RAW forwarding wait (Read) CDB CDBstall stall stall
WAR - wait (Write) Reg. rename Reg. renameWAW - wait (Issue) Reg. rename Reg. renameExceptions precise ? ? precise, ROBIssue in-order in-order in-order in-orderExecution in-order out-of-order out-of-order out-of-orderCompletion in-order out-of-order out-of-order out-of-orderCommit in-order out-of-order out-of-order in-orderStructural - many FU many FU, many FU,hazard stall CDB, stall CDB, stallControl Delayed Branch Branch Br. pred,hazard br., stall prediction prediction speculation
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 5 / 56
logoonly
Getting CPI < 1!
Issuing multiple instructions per clock cycleSuperscalar : varying number of instructions/cycle (1-8) scheduledby compiler or HW
IBM Power5, Pentium 4, Core2, AMD, Sun SuperSparc, DEC AlphaSimple hardware, complicated compiler or...Complex hardware but simple for compiler
Very Long Instruction Word (VLIW): fixed number of instructions(3-5) scheduled by the compiler
HP/Intel IA-64, ItaniumSimple hardware, difficult for compilerhigh performance through extensive compiler optimization
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 6 / 56
logoonly
Approaches for multiple issue
Issue Hazard Scheduling Characteristicsdetection /examples
Superscalar dynamic HW static in-order executionARM
Superscalar dynamic HW dynamic out-of-orderexecution
Superscalar dynamic HW dynamic speculationPentium 4
IBM power5VLIW static compiler static TI C6xEPIC static compiler mostly static Itanium
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 7 / 56
logoonly
AMD Phenom CPU
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 8 / 56

logoonly
Intel Core2
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 9 / 56
logoonly
Intel Core2 chip (Nehalem)
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 10 / 56
logoonly
Questions!
QUESTIONS?
COMMENTS?
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 11 / 56
logoonly
Lecture 6 agenda
Chapters 5.1, 5.3 (and Appendix C.1-C.3) in "Computer Architecture"
1 Reiteration
2 Memory hierarchy
3 Cache memory
4 Cache performance
5 Main memory
6 Summary
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 12 / 56

logoonly
Outline
1 Reiteration
2 Memory hierarchy
3 Cache memory
4 Cache performance
5 Main memory
6 Summary
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 13 / 56
logoonly
Memory
You want a memory to be:
FASTAND CHEAP
BIG
Contradiction!
How?
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 14 / 56
logoonly
Memory - big, fast and cheap
Use two “magic” tricks
Make a small memory seem bigger virtual memory(Without making it much slower)Make a slow memory seem faster cache memory(Without making it smaller)
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 15 / 56
logoonly
Memory tricks (techniques)
Use a hierarchyCPU superfast Registers instructions
FAST Cachecache memory (HW)
Memory CHEAP Main memoryvirtual memory (SW)
BIG Disk
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 16 / 56

logoonly
Levels of the Memory Hierarchy
SRAM DRAM
(From Dubois, Annavaram, Stenström: “Parallel Computer Organization and Design”, ISBN 978-0-521-88675-8)
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 17 / 56
logoonly
Initial model of Memory Hierarchy
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 18 / 56
logoonly
RAM
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 19 / 56
logoonly
Levels of the Memory Hierarchy
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 20 / 56

logoonly
Who cares?
1980: no cache in microprocessors1995: 2-level caches in a processor package2000: 2-level caches on a processor die2003: 3-level caches on a processor die
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 21 / 56
logoonly
Example – bandwidth need
Assume an “ideal” CPU with no stalls, running at 3 GHz and capable ofissuing 3 instructions (32 bit) per cycle.
Instruction fetch 4 bytes/instrLoad & store 1 byte/instrInstruction frequency 3 ∗ 3 = 9 GHzBandwidth 9 ∗ (4 + 1) = 45 GB/sec
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 22 / 56
logoonly
Memory Hierarchy Functionality
CPU tries to access memory at address A. If A is in the cache,deliver it directly to the CPUIf not – transfer a block of memory words, containing A, from thememory to the cache. Access A in the cache.If A not present in the memory – transfer a page of memoryblocks, containing A, from disk to the memory, then transfer theblock containing A from memory to cache. Access A in the cache.
words blocks pages
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 23 / 56
logoonly
The Principle of Locality
A program access a relatively small portion of the addressspace at any instant of timeTwo different types of locality:
Temporal locality (Locality in Time): If an item is referenced, it willtend to be referenced again soon.Spatial locality (Locality in space): If an item is referenced, itemswhose addresses are close, tend to be referenced soon.
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 24 / 56

logoonly
Memory hierarchy – Terminology
Sizeupper < SizelowerAccess timeupper < Access timelowerCostupper > Costlower
Upper level = cache; Lower level = Main memoryBlock : The smallest amount of data moved between levelsHit : A memory reference that is satisfied in the cacheMiss: A memory reference that cannot be satisfied in the cache
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 25 / 56
logoonly
Outline
1 Reiteration
2 Memory hierarchy
3 Cache memory
4 Cache performance
5 Main memory
6 Summary
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 26 / 56
logoonly
Cache measures
hit rate = no of accesses that hit/no of accessesclose to 1, more convenient with
miss rate = 1.0− hit ratehit time: cache access time plus time to determine hit/missmiss penalty: time to replace a block
measured in ns or number of clock cyclesdepends on:
latency: time to get first wordbandwidth: time to transfer block
out-of-order execution can hide some of the miss penaltyAverage memory access time= hit time + miss rate ∗miss penalty
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 27 / 56
logoonly
4 questions for the Memory Hierarchy
Q1: Where can a block be placed in the upper level?(Block placement)Q2: How is a block found if it is in the upper level?(Block identification)Q3: Which block should be replaced on a miss?(Block replacement)Q4: What happens on a write?(Write strategy)
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 28 / 56

logoonly
Block placement
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 29 / 56
logoonly
Block identification
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 30 / 56
logoonly
Block identification
Store a part of the address: Tag
Example: a 1 KB, Direct Mapped Cache, 32 byte blocks
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 31 / 56
logoonly
Block replacement
Direct mapped caches don’t need a block replacement policy(why?)Primary strategies:
Random (easiest to implement)LRU – Least Recently Used (best)FIFO – Oldest
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 32 / 56

logoonly
Cache read
CPU tries to read memory address ASearch the cache to see if A is therehit miss⇓ Copy the block that contains A from lower-level memory to
the cache. (Possibly replacing an existing block.)Send data to the CPU
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 33 / 56
logoonly
Write strategy
Write through: The information is written to both the block in thecache and to the block in the lower-level memory
Is always combined with write buffers so that the CPU doesn’t haveto wait for the lower level memory
Write back : The information is written only to the block in thecache.
Copy a modified cache block to main memory only when replacedIs the block clean or modified? (dirty bit)
Do we allocate a cache block on a write miss?Write allocate (allocate a block in the cache)No-write allocate (only write to memory)
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 34 / 56
logoonly
Cache write
Write through Write back
Always write in bothcache and lower-levelmemory
Only write in cacheUpdate lower-levelmemory when a block isreplaced
CPU Cache Memory
- w - wCPU Cache Memory
- wwrite
...
CPU Cache Memory
w - wreplace
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 35 / 56
logoonly
Cache micro-ops sequencing
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 36 / 56

logoonly
Cache micro-ops sequencing – read
1: Address division2: Set/block selection2a: Tag read3: Tag/Valid bit checking4: Hit: Data out
Miss: Signal cache miss; initiate replacement
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 37 / 56
logoonly
Outline
1 Reiteration
2 Memory hierarchy
3 Cache memory
4 Cache performance
5 Main memory
6 Summary
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 38 / 56
logoonly
Cache Performance
memory stall cyclescache
= no of misses ∗miss penalty
= IC ∗ missesinstruction
∗miss penalty
= IC ∗ mem accessesinstruction
∗miss rate ∗miss penalty
CPU execution Time
= IC ∗ CPIexecution ∗ TC + memory stall cyclescache ∗ TC
= IC ∗ (CPIexecution +mem accesses
instruction∗miss rate ∗miss penalty) ∗ TC
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 39 / 56
logoonly
Interlude - CPU Performance Equation
CPU execution Time =
IC ∗ (CPIexecution + CPIcache) ∗ TC =
IC ∗ (CPIideal + CPIpipeline + CPIcache) ∗ TC =
IC ∗ (CPIideal+
Structural Stalls + Data Hazard Stalls + Controll Stalls+mem accesses
instruction∗miss rate ∗miss penalty
) ∗ TC
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 40 / 56

logoonly
Cache Performance
CPU execution Time =
IC ∗ (CPIexecution +mem accesses
instruction∗miss rate ∗miss penalty) ∗ TC
Three ways to increase performance:Reduce miss rateReduce miss penaltyReduce hit time (improves TC)
Average memory access time =hit time + miss rate ∗miss penalty
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 41 / 56
logoonly
Performance aspects
CPU execution Time =
IC ∗ (CPIexecution +mem accesses
instruction∗miss rate ∗miss penalty) ∗ TC
Example:
miss rate (%) 1miss penalty (cycles) 50mem accesses
instruction kCPI increase k ∗ 0.01 ∗ 50
1 instruction fetch plus dataaccesses from ca 35 % ofthe instructions=⇒ k ≈ 1.35;assume CPIexecution = 2.0
Texe_ideal_cacheTexe_example_cache
= IC∗2.0∗TCIC∗(2.0+1.35∗0.01∗50)∗TC
≈ 0.75
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 42 / 56
logoonly
Why does a memory reference miss?
A cache miss can be classified as a:Compulsory miss: The first reference is always a missCapacity miss: If the cache memory is to small it will fill up andsubsequent references will missConflict miss: Two memory blocks may be mapped to the samecache block with a direct or set-associative address mapping
3 C’s
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 43 / 56
logoonly
Miss rate components – 3 C’s
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 44 / 56

logoonly
Miss rate components – 3 C’s
Small percentage of compulsory missesCapacity misses are reduced by larger cachesfull associativity avoids all conflict missesConflict misses are relatively more important for smallset-associative caches
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 45 / 56
logoonly
Outline
1 Reiteration
2 Memory hierarchy
3 Cache memory
4 Cache performance
5 Main memory
6 Summary
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 46 / 56
logoonly
Serial memory
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 47 / 56
logoonly
Main memory: Background
Performance of main memory:Latency affects: Cache miss penalty
Access time: time between request and word arrivesCycle time: time between requests
Bandwidth affects: I/O, multiprocessors (& cache miss penalty)Main memory is DRAM : Dynamic RAM
Dynamic - memory cells need to be refreshed1 transistor and a capacitor per bit
Cache memory is SRAM : Static RAMNo refresh6 transistors per bit
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 48 / 56

logoonly
SRAM technology
Address typically not multiplexedEach cell consists of 6 transistors and a capacitorFast access timeOptimizes speed and capacityExpensive
Used in caches
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 49 / 56
logoonly
DRAM technology
The address is multiplexed in order to reduce the number of pins(increases latency)Refresh of memory cells decreases bandwidthThe need of sense amplifiers increases latencyEach cell consists of 1 transistor and 1 capacitorOptimizes cost/bit and capacityInternal optimizations: SDRAM, DDR, DDR2, DDR3
Used in main memory
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 50 / 56
logoonly
DRAM organization
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 51 / 56
logoonly
Improving main memory performance
normal wide memory interleavingmemory
Improves bandwidth.
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 52 / 56

logoonly
Memory interleave timing
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 53 / 56
logoonly
Outline
1 Reiteration
2 Memory hierarchy
3 Cache memory
4 Cache performance
5 Main memory
6 Summary
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 54 / 56
logoonly
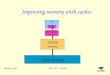
Summary
The performance gapbetween CPU andmemory is widening
Memory HierarchyCache level 1Cache level ...Main memoryVirtual memory
Four design issues:Block placementBlock identificationBlock replacementWrite strategy
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 55 / 56
logoonly
Summary – cont
Cache misses increases the CPI for instructions that accessmemoryThree types of misses:
CompulsoryCapacity 3 C’sConflict
Main memory performance:LatencyBandwidth (interleaving)
A. Ardö, EIT Lecture 6: EITF20 Computer Architecture November 13, 2013 56 / 56