Embed Size (px)
Citation preview

This lecture… How do users name files? What is a name? Lookup: given a name, how do you translate it
into a file header?

Abstraction: File Systems The user is given the view of a single namespace for files,
but this namespace can be implemented over multiple physical devices or even over multiple systems.
Likewise, it is useful to split a single physical device into several logical devices, such as ones for swap space, different types of uses etc (for example, logical device for regular files and one for multimedia applications).
Can vary the file-system parameters per logical device (e.g., block size, various policies).– 1. Logical file system– 2. Multiple physical file systems– 3. Logical devices– 4. Physical devices

Abstraction: File Systems UNIX:
– file systems must be “mounted” to be used. – Mounting a file system into the hierarchy of the
root file system. – A file system contains a boot block in the first
sector (if it is a boot-able file system) and a superblock, » contains the static parameters of the file system
such as its allocated size, block sizes, allocation policies, etc.
» It can also contain a free block list.

Abstraction: File Systems In the kernel, a file is identified according to its
<logical device number, inode number> pair. Inodes in a file system are numbered
sequentially. In some (early) versions of UNIX the inodes are
kept in a single array, and the inode number is just the index into that array.

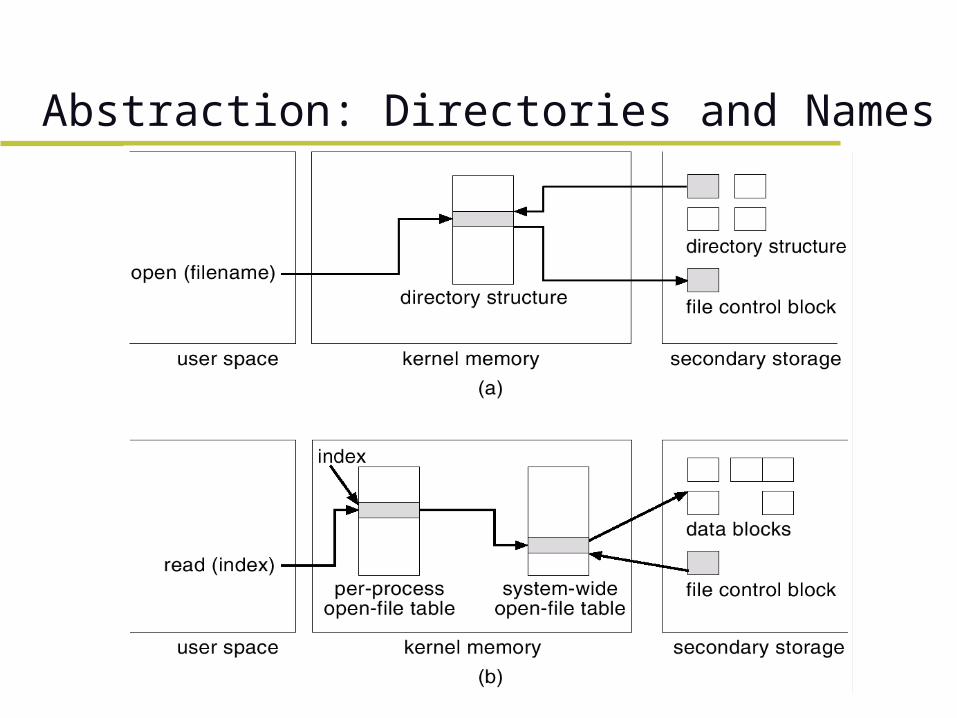
Abstraction: Directories and Names File system provides mapping of human-readable
file names to locations on physical devices. The notion of “directories”,
– files containing mappings of names to inodes (of data files or other directories)
Typically, a human-readable file name is bound to an actual file through the use of an “open” command.
On open, the file path name is traversed and the inode is located.
Permissions and other constraints can be checked at this time.

Abstraction: Directories and Names System maintains an open file table in order to
cache the mapping for use by other file operations (read, write, etc.).
After opening the file, these other operations refer to the file by using the index into this table.
The index points to a file descriptor – important information about the file such as its
current file position pointer, which indicates (at least in UNIX) which byte of the file is to be read or written next.
Abstraction: Directories and Names

Abstraction: Directories and Names Multi-user system: two levels of open file table
– a global table and a per process table. – The per process table keeps track of
» files currently opened by that process and » process-specific information such as the current file
position
– An entry in this table points to the relevant entry in the global (system-wide) table.
– The global table has one entry per open file (regardless of how many processes have opened it). » tracks the number of processes that have opened
the file » closes the file when this number goes to zero.

File Header Storage Where is file header stored on disk?
– In (early) UNIX and DOS/Windows’ FAT file system, it is stored in a special array in the outermost cylinders.
UNIX refers to file by index into array – tells it where to find the file header
UNIX-isms:– “i-node” – file header– “i-number” – index into the array
File header array

File Header Storage Original UNIX file header organization, seems
strange:
1. Header not stored anywhere near the data blocks. – To read a small file, seek to get header, seek back
to data.
2. Fixed size, set when disk is formatted. – Means maximum number of files that can be
created. Later versions of UNIX:
– header information closer to the data blocks – – inode for a file stored in the same “cylinder group”
as the parent directory of the file” – makes ls of that directory run fast

File Header Storage Advantages
– Reliability: whatever happens to the disk, you can find all of the files
– UNIX BSD 4.2 puts portion of the file header array on each cylinder. For small directories, can fit all data, file headers, etc. in same cylinder => no seeks!
– File headers are much smaller than a whole block (a few hundred bytes), so multiple file headers fetched from disk at same time
Question: do you ever look at a file header without reading the file? – If not, put the file header as the first block of the file!– Turns out that fetching the file header is something
like 4 times more common in UNIX than reading the file (ls, make).

Naming
1. Use index (ask users to specify i-node number)– Easier for system, not as easy for users.
2. Text name3. Icon
With icons or text, still have to map name -> index

Directories Directory maps name -> file index (where to find file header)
– A table of <file name, file index> pairs. General idea: relation. Table associating things together.
– Directories just a special kind of a relation, – connecting file name to index (ditto with password file,
caches, etc.) Directories stored as a file, containing a list of <name, index>
pairs.
But, only OS is permitted to modify directory. Any program can read the directory file.
– This is how “ls” works.
Problem: means hard to change file directory structure!– Change the format of the file, applications will access wrong
format of files, will need to change applications– Abstract API – a level of indirection– Gives portability, possible to rewrite file system without
affecting the applications
<name, inode#><afs, 1021><tmp, 1020><bin, 1022><cdrom, 4123><dev, 1001><sbin, 1011>
access (modern OS)

Directory Implementation Linear list of file names with pointer to the data
blocks.– simple to program– time-consuming to execute
Hash Table – linear list with hash data structure.– decreases directory search time– collisions – situations where two file names hash
to the same location– fixed size

Directory Structure Single-level: have a single directory for entire system.
– put directory at known location on disk– if one user uses a name, no one else can– many older personal computers work this way.
Two-level: have a single directory for each user– still clumsy. And ls on 10,000 files is a real pain– many older mathematicians work this way.
Tree-structured: hierarchical name spaces– allow directory to map names to files or other dirs– file system forms a tree (or graph, if links allowed)– large name spaces tend to be hierarchical (ip
addresses, domain names, scoping in programming languages, etc.)

Directory Hierarchy Directories organized into hierarchical structure /joe/abcde/file1
Top-level directory has pair: <joe, #>. joe has pair <abcde, #>, etc.
How many disk I/O’s to access first byte of file1?
root subdir
filename

Directory Hierarchy
1. Read in file header for root (always at fixed spot on disk, replicated).
2. Read in first data block for root.3. Read in file header for joe4. Read in first data block for joe.5. Read in file header for abcde6. Read in first data block for abcde.7. Read in file header for file18. Read in first data block for file1

Directory Hierarchy How can this possibly be efficient? Caching !! Current working directory: short cut for both
user and system. Each address space stores file index for current
directory. Allows user to specify relative filename, instead of
absolute path (if no leading “/”). /joe -> FH in memory
– Thus, to read first byte of file, just last 4 steps above.
Current PATH– /usr/bin, /bin, /etc, …

Directory Hierarchy Not really a hierarchy… Many systems allow directory structure to be organized as
an acyclic graph or even a (potentially) cyclic graph. UNIX does this through the concept of “links”. Two flavors:
Hard links and Soft links Hard links – different names for the same file.
– All names are equally valid– Implemented by having multiple directory entries point to
same inode– Question: how to know when you can delete a file?
» Unix stores count of pointers (“hard links”) to inode– Can only be used with non-directory files.– to make: “ln foo bar” creates a
synonym (‘bar’) for ‘foo’– Can’t cross file system boundaries ref = 2
...
foo bar

Directory Hierarchy Soft links – “shortcut” pointer to other file
– Implemented by simply storing the logical name of the actual file
– Fewer restrictions: can point to directories, cross file systems, etc.
– No protection from deletions/changing – may be “dangling” or point to wrong file!
– Cycles are possible – Question: how does system avoid infinite loops when following a path?» Count the number of refs (8 sym links in Unix)
foo /joe/bar /joe/bar Ref = 2
adj/foo/joe/bar /joe/bar
/adj/foo

File Caching and Related Topics Use caching and prefetching to achieve good
performance in a file system. Three key ideas:
– Caching of disk blocks read into memory– Prefetching of disk blocks expected to be needed
soon– Delayed writes
Caching– Key idea (as usual): exploit locality of use in file systems
by caching disk blocks in memory.– Use an LRU replacement scheme w/ real timestamps– Easy to do since we can afford the overhead of
maintaining timestamps for each disk block being cached.

File Caching Advantages:
– Works very well for name translation,– Works well in general as long as memory is big enough
to accommodate a host’s working set of files. Disadvantages:
– LRU loses when some application scans a big enough part of the file system, thereby flushing the cache with data that is used only once; for example
find . –exec grep foo {} \; Some systems allow applications to provide the file system
with hints about which replacement policy to use. For example, an application might indicate that it will not
use a file more than once. The file system would then know to discard any disk blocks
of the file once they have been used.

File Caching Question: how much memory should the OS
allocate to the file system cache vs. the VM paging store?
If we allocate too much memory to the file system cache then we won’t be able to run many applications in parallel.
If we allocate too little memory to the file system cache then many applications may run slowly.
Solution: let the boundary between the two vary so that the disk access rates for paging and file access are balanced.

Prefetching Key idea: exploit the fact that the most common
form of file access is sequential by prefetching subsequent disk blocks ahead of the current read request (if they’re not already in memory).
How much should one prefetch?– Request too many blocks and we start imposing
unnecessary delays on concurrent file requests by other processes.
– Request too few blocks and too many seeks (and rotational delays) will occur among concurrent file requests.

Delayed Writes Key idea: Batch writes to optimize disk scheduling and allocation. Unix systems use a 30 second write-behind policy:
– Writes only copy data from a user process to kernel disk block buffers,
– Dirty disk block buffers are only flushed to disk once every 30 seconds.
Advantages:– Disk scheduler can efficiently order lots of requests.– Disk allocation algorithm can be run with correct size value
for a file.– Some files need never get written to disk! (E.g. temporary
scratch files written in /tmp frequently don’t exist for 30 seconds.)
Disadvantages:– What if the system crashes before your file has been written
out?– Worse yet, what if the system crashes before a directory file
has been written out? (lose pointer to inode)

Important “ilities” Availability: the probability that the system can
accept and process requests– Often measured in “nines” of probability. So, a
99.9% probability is considered “3-nines of availability”
– Key idea here is independence of failures Durability: the ability of a system to recover data
despite faults– This idea is fault tolerance applied to data– Doesn’t necessarily imply availability:
information on pyramids was very durable, but could not be accessed until discovery of Rosetta Stone

Important “ilities” Reliability: the ability of a system or component
to perform its required functions under stated conditions for a specified period of time (IEEE definition)– Usually stronger than simply availability: means
that the system is not only “up”, but also working correctly
– Includes availability, security, fault tolerance/durability
– Must make sure data survives system crashes, disk crashes, other problems

How to make file system durable? Disk blocks contain Reed-Solomon error
correcting codes (ECC) to deal with small defects in disk drive– Can allow recovery of data from small media
defects Make sure writes survive in short term
– Either abandon delayed writes or– use special, battery-backed RAM (called non-
volatile RAM or NVRAM) for dirty blocks in buffer cache.

How to make file system durable? Make sure that data survives in long term
– Need to replicate! More than one copy of data!– Important element: independence of failure
» Could put copies on one disk, but if disk head fails…» Could put copies on different disks, but if server fails…» Could put copies on different servers, but if building is
struck by lightning…. » Could put copies on servers in different continents…
RAID: Redundant Arrays of Inexpensive Disks– Data stored on multiple disks (redundancy)– Either in software or hardware
» In hardware case, done by disk controller; file system may not even know that there is more than one disk in use
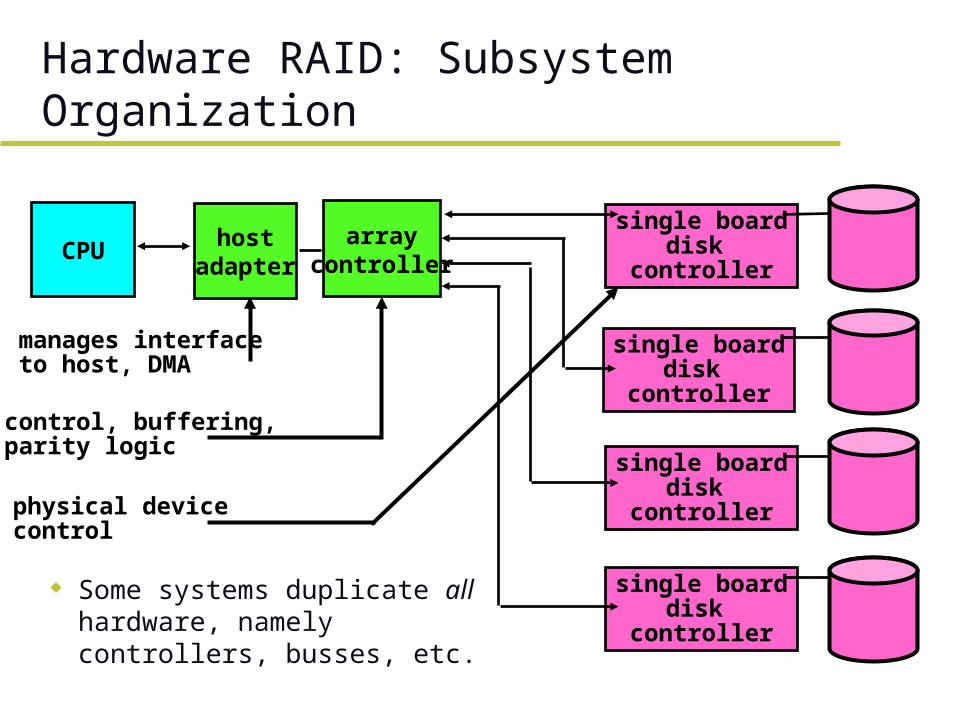
Hardware RAID: Subsystem Organization
often piggy-backedin small format devices
CPUarray
controller
single boarddisk
controller
single boarddisk
controller
single boarddisk
controller
single boarddisk
controller
hostadapter
manages interfaceto host, DMA
control, buffering,parity logic
physical devicecontrol
Some systems duplicate all hardware, namely controllers, busses, etc.

RAID 1: Disk Mirroring/Shadowing
Each disk is fully duplicated onto its "shadow“– For high I/O rate, high availability environments– Most expensive solution: 100% capacity
overhead Bandwidth sacrificed on write:
– Logical write = two physical writes– Highest bandwidth when disk heads and rotation
fully synchronized (hard to do exactly)
recoverygroup

RAID 1 Reads may be optimized
– Can have two independent reads to same data Recovery:
– Disk failure replace disk and copy data to new disk
– Hot Spare: idle disk already attached to system to be used for immediate replacement
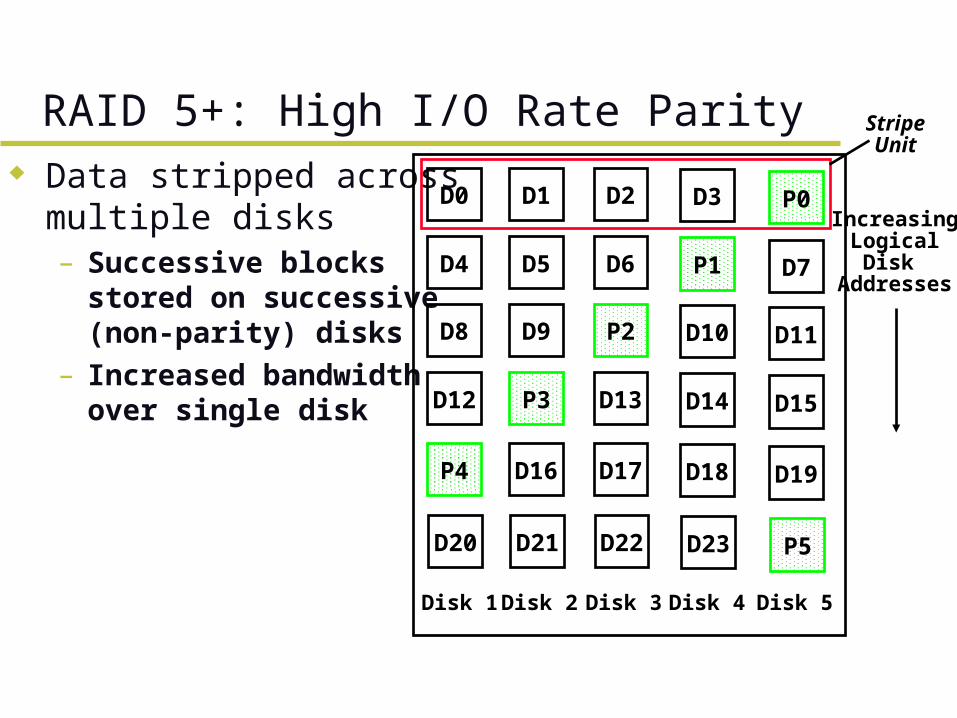
Data stripped across multiple disks – Successive blocks
stored on successive (non-parity) disks
– Increased bandwidthover single disk
RAID 5+: High I/O Rate Parity
IncreasingLogicalDisk
Addresses
StripeUnit
D0 D1 D2 D3 P0
D4 D5 D6 P1 D7
D8 D9 P2 D10 D11
D12 P3 D13 D14 D15
P4 D16 D17 D18 D19
D20 D21 D22 D23 P5
Disk 1 Disk 2 Disk 3 Disk 4 Disk 5

RAID 5+: High I/O Rate Parity Parity block (in green) constructed by XORing
data bocks in stripe– P0=D0D1D2D3– Can destroy any one disk and still reconstruct
data– Suppose D3 fails, then can reconstruct:
D3=D0D1D2P0 Later: talk about spreading information widely
across internet for durability.

Remote File Systems: Virtual File System (VFS)
VFS: Virtual abstraction similar to local file system– Instead of “inodes” has “vnodes”– Compatible with a variety of local and remote file
systems» provides object-oriented way of implementing file
systems

Virtual File System (VFS) VFS allows the same system call interface (the
API) to be used for different types of file systems– The API is to the VFS interface, rather than any
specific type of file system

Network File System (NFS) Three Layers for NFS system
– UNIX file-system interface: open, read, write, close calls + file descriptors
– VFS layer: distinguishes local from remote files» Calls the NFS protocol procedures for remote requests
– NFS service layer: bottom layer of the architecture» Implements the NFS protocol
NFS Protocol: remote procedure calls (RPC) for file operations on server– Reading/searching a directory – manipulating links and directories – accessing file attributes/reading and writing files

Network File System (NFS) NFS servers are stateless; each request provides
all arguments require for execution Modified data must be committed to the server’s
disk before results are returned to the client – lose some of the advantages of caching– Can lead to weird results: write file on one client,
read on other, get old data

Schematic View of NFS Architecture

Protection and Access Control Use access control lists and capability lists to
control access to resources such as files. Protection Goals:
– Prevent accidental and maliciously destructive behavior.
– Ensure fair resource usage.
A key distinction to make: policy vs. mechanism.
Mechanism: how something is to be done. Policy: what is to be done.

Access Control Domain structure
– Access/usage rights associated with particular domains
– Example: user/kernel mode => two domains
Unix:– Each user is a domain– Super-user domain– Groups of users (and groups)

Access Control Types of access rights What kinds of access rights do we need for files?
– Read– Write– Execute
For directories:– List– Modify– Delete
For access rights themselves:– Owner (I have the right to change the access rights for
some resource)– Copy (I have the right to give someone else a copy of
an access right I have)– Control (I have the right to revoke someone else’s
access rights)

Access Control Matrix Conceptually, we can think of the system enforcing
access controls based on a giant table that encodes all access rights held by each domain in the system.
For example:
The access control matrix represents the policy we want to enforce.
File 1 File 2 File 3 Dir 1 Dir 2 …
User A rw r rwx lmd l …
Group B
r rw lm …
… … … … … … …

Access Control There are two principal means of providing a mechanism to
do so:– Access control lists– Capability lists
Access control lists: keep lists of access rights for each domain with each object.
File3: User A: rwx Group B: rw ... Capability lists: keep lists of access rights for each object
with each domain. User A: File1: rw File2: r ...

Access Control Which is better?
– ACLs allow easy changing of an object’s permissions.» Example: add Users C, D, and F with rw permissions.
– Capability lists allow easy changing of a domain’s permissions.» Example: you are promoted to system administrator
and should be given access to all system files.
Combination approach:– Objects have ACLs– Users have capabilities, called “groups” or “roles”– ACLs can refer to users or groups– Change permissions on an object by modifying its ACL– Change broad user permissions via changes in group
membership

Access Control: Revocation How does one revoke someone’s access rights to a particular
object? Easy with ACLs: just remove entry from the list. Takes effect
immediately since the ACL is checked on each object access. Harder to do with capabilities since they aren’t stored with the
object being controlled:– Not so bad in a single machine: could keep all capability lists
in a well-known place (e.g. the OS capability table).– Very hard in distributed system, where remote hosts may
have crashed or may not cooperate. – Various approaches possible:
» Put expiration dates on capabilities and force reacquisition.» Put epoch numbers on capabilities and revoke all capabilities by
bumping the epoch number (which gets checked on each access attempt).
» Maintain back pointers to all capabilities that have been handed out. (Tough if capabilities can be copied.)
» Maintain a revocation list that gets checked on every access attempt.





























