Embed Size (px)
Citation preview

Convey Computer
Status
Steve Wallach
swallach”at”conveycomputer.com

swallach - April 2009 - HPC Users Forum
2
Company Background
• Started in June 2007– 28 people
• Raised $15.1 mill, series A– Intel, Xilinx, Centerpoint, Interwest, Rho
• Located Richardson, Texas• Announced at SC’08
– Markoff Article in New York Times
• Convey Convex++– No plans for Convez

swallach - April 2009 - HPC Users Forum
3
The Convey Hybrid-Core Computer
• Extends x86 ISA with performance of a hardware-based architecture
• Adapts to application workloads
• Programmed in ANSI standard C/C++ and Fortran
• Leverages x86 ecosystem
swallach - April 2009 - HPC Users Forum
4
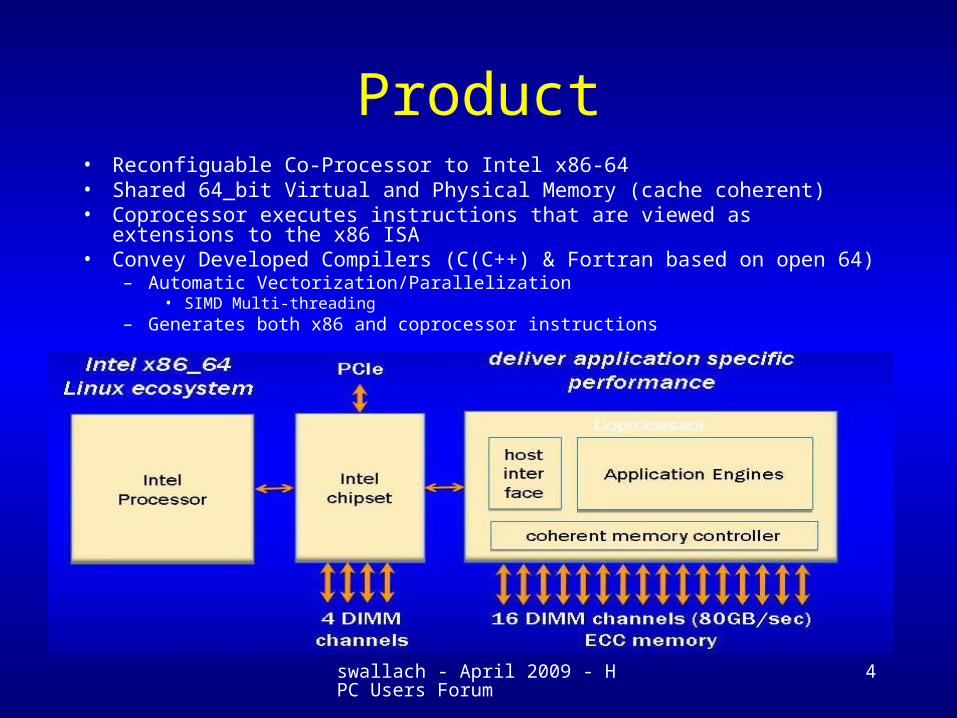
Product• Reconfiguable Co-Processor to Intel x86-64• Shared 64_bit Virtual and Physical Memory (cache coherent)• Coprocessor executes instructions that are viewed as extensions to the x86 ISA• Convey Developed Compilers (C(C++) & Fortran based on open 64)
– Automatic Vectorization/Parallelization• SIMD Multi-threading
– Generates both x86 and coprocessor instructions
swallach - April 2009 - HPC Users Forum
5
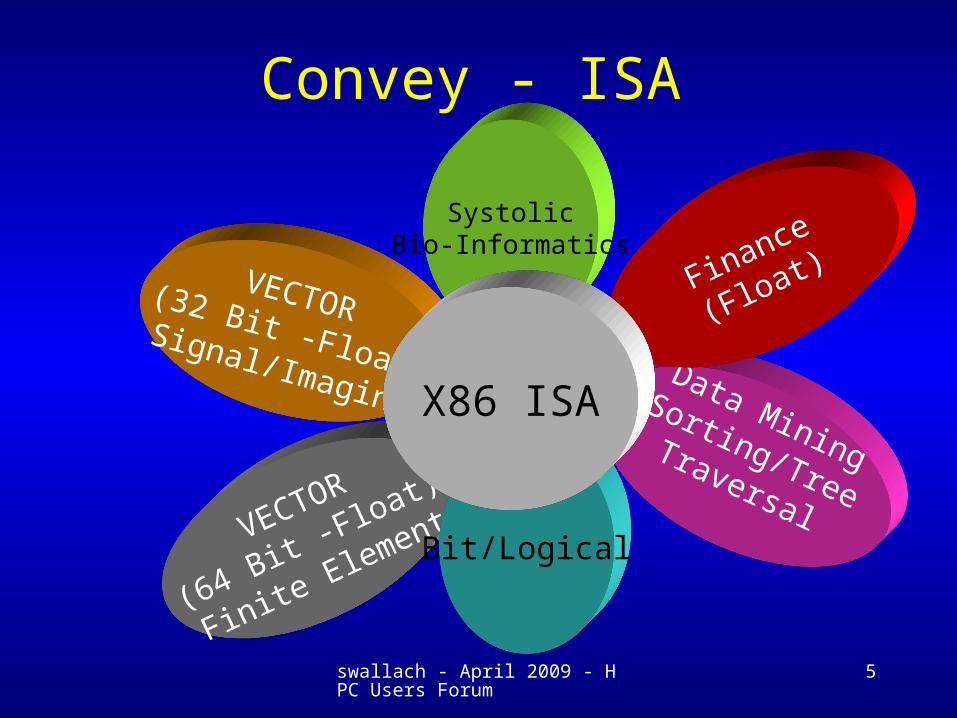
VECTOR
(64 Bit -Float)
Finite Element
Convey - ISA
VECTOR(32 Bit -Float)Signal/Imaging
Bit/Logical
Data MiningSorting/TreeTraversal
SystolicBio-Informatics
Finance
(Float)
X86 ISA
swallach - April 2009 - HPC Users Forum
6
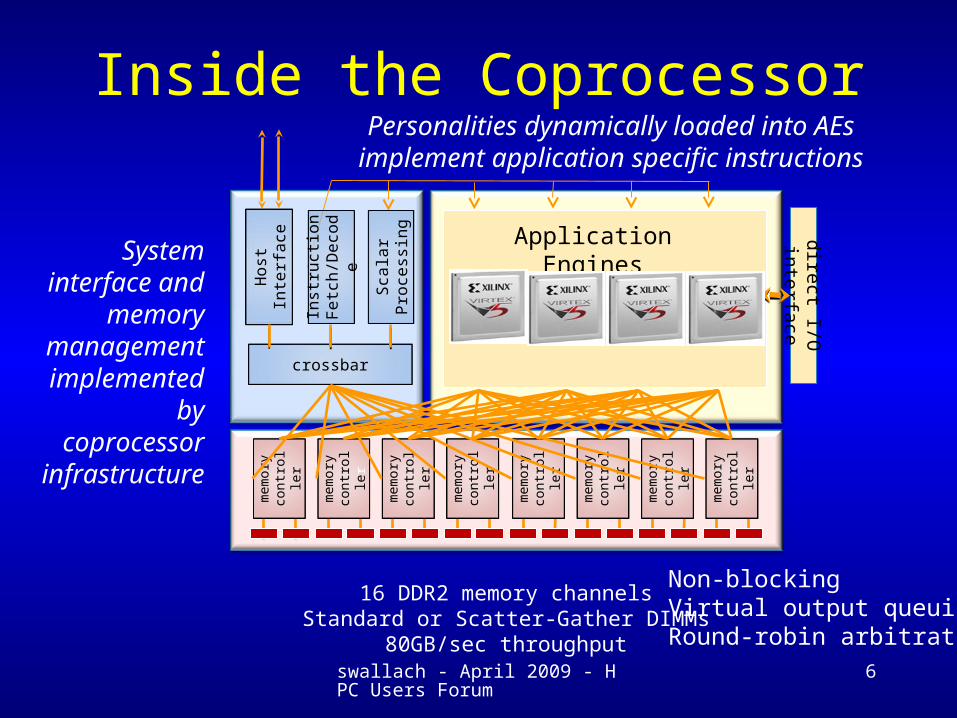
Inside the Coprocessor
crossbar
mem
ory
co
ntr
olle
r
Sca
lar
Pro
cess
ing
Inst
ruct
ion
Fetc
h/D
eco
de
Host
Inte
rface
mem
ory
co
ntr
olle
r
mem
ory
co
ntr
olle
r
mem
ory
co
ntr
olle
r
mem
ory
co
ntr
olle
r
mem
ory
co
ntr
olle
r
mem
ory
co
ntr
olle
r
mem
ory
co
ntr
olle
r
Application Engines
Personalities dynamically loaded into AEs implement application specific
instructions
16 DDR2 memory channelsStandard or Scatter-Gather DIMMs
80GB/sec throughput
System interface
and memory managemen
t implemente
d by coprocessor infrastructur
e
dire
ct I/O
inte
rface
Non-blockingVirtual output queuingRound-robin arbitration

swallach - April 2009 - HPC Users Forum
7
Convey Scatter-Gather DIMMs• Standard DIMMs are optimized for
cache line transfers– performance drops dramatically
when access pattern is strided or random
• Convey Scatter-Gather DIMMs are optimized for 8-byte transfers– deliver high bandwidth for random
or strided 64-bit accesses– prime number (31) interleave
maintains performance for power-of-two strides
– Supports both SIMD and Parallel multi-threading compute model
– Out of order loads and stores

swallach - April 2009 - HPC Users Forum
8
Personalities• A personality implements a set of extended instructions
– multiple personalities may be installed on the system– one is active on coprocessor at any one time– reloaded dynamically by the operating system as needed
• Vector personalities– implement a load/store vector accumulator architecture with
multiple function pipes– Convey vectorizing compilers automatically identify loops that can
be executed with vector instructions– can operate on floating point, integer, or bit data
• “Procedural” personalities– implement an entire routine or algorithm in logic– invoked by one or more instructions– called as procedures or functions
1/30/2009 8
swallach - April 2009 - HPC Users Forum
9
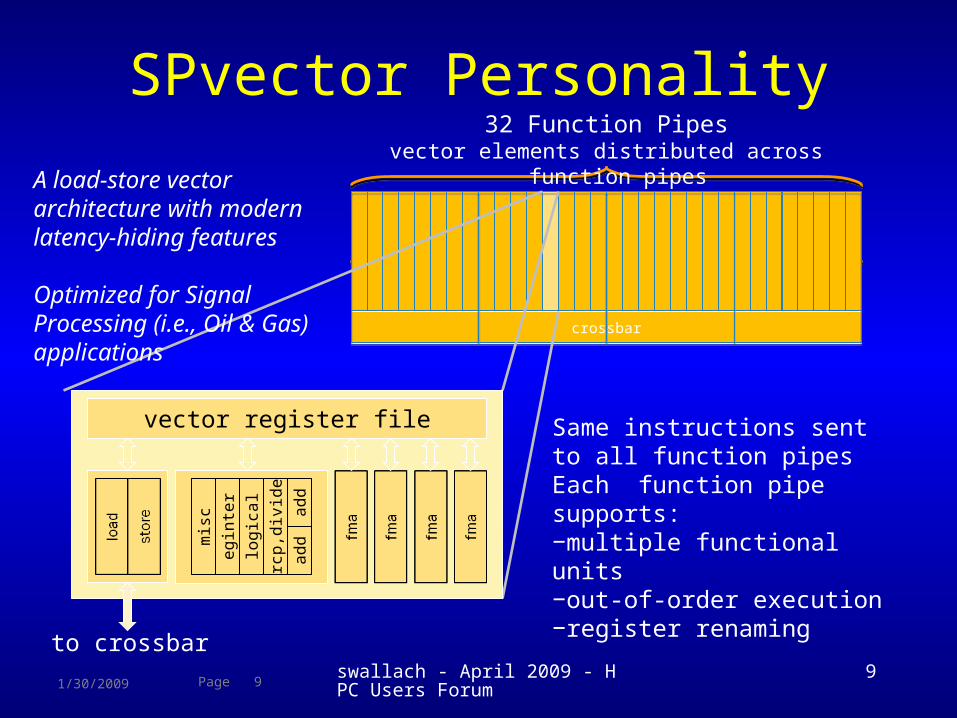
SPvector Personality
1/30/2009 Page 9
crossbar
Same instructions sent to all function pipesEach function pipe supports:−multiple functional units−out-of-order execution−register renaming
32 Function Pipesvector elements distributed across function
pipes
to crossbar
vector register file
A load-store vector architecture with modern latency-hiding features
Optimized for Signal Processing (i.e., Oil & Gas) applications
egin
ter
logic
al
rcp,d
ivid
e
mis
c add
add

swallach - April 2009 - HPC Users Forum
10
Financial Vector Personality
1/30/2009 Page 10
crossbar
Add functional units for common functions such as log, exp, random number generation
Supported by the compiler as vector intrinsics
32 Function Pipesvector elements distributed across function
pipes
to crossbar
Same overall structure and datapaths of SPvector personality
Pairs of single precision functional units replaced by double precision units vector register file
inte
ger
logic
al
rcp
mis
c
exp,log,C
ND
add
Para
llel R
NG
swallach - April 2009 - HPC Users Forum
11
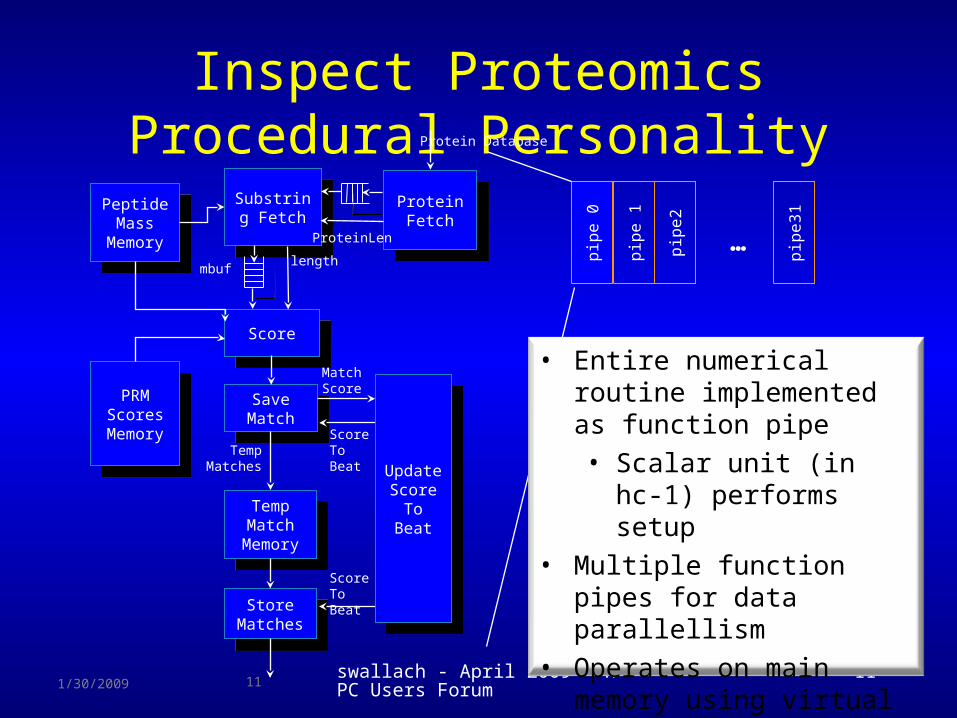
Inspect ProteomicsProcedural Personality
1/30/2009 11
pip
e 0
pip
e 1
pip
e2
pip
e3
1
…Substring
Fetch
Substring Fetch Protein
Fetch
Protein FetchPeptide
MassMemory
PeptideMass
Memory
PRMScores
Memory
PRMScores
Memory
ScoreScore
SaveMatch
SaveMatch
TempMatch
Memory
TempMatch
Memory
StoreMatches
StoreMatches
length
ProteinLen
ScoreTo Beat
TempMatches
mbuf
• Entire numerical routine implemented as function pipe• Scalar unit (in hc-1)
performs setup• Multiple function pipes
for data parallellism• Operates on main
memory using virtual addresses
MatchScore
ScoreTo Beat
Protein Database
Update
ScoreTo
Beat
Update
ScoreTo
Beat
swallach - April 2009 - HPC Users Forum
12
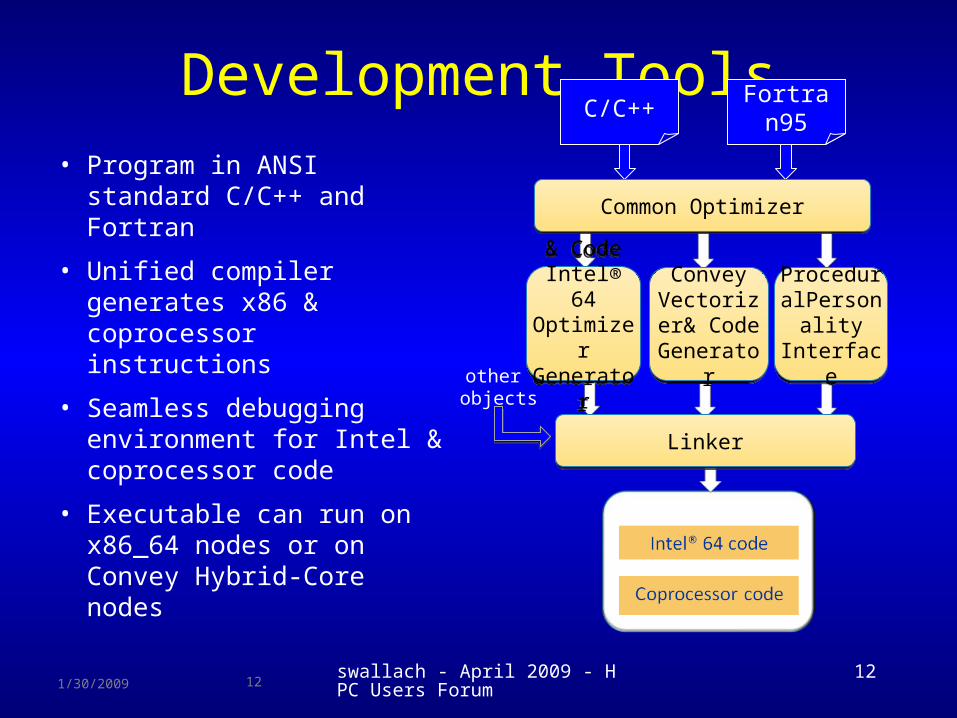
Development Tools
1/30/2009 12
executable
C/C++ Fortran95
Common OptimizerCommon Optimizer
& Code Intel® 64 Optimize
r Generato
r
& Code Intel® 64 Optimize
r Generato
r
Convey Vectorizer& Code Generato
r
Convey Vectorizer& Code Generato
r
ProceduralPerson
ality Interface
ProceduralPerson
ality Interface
LinkerLinker
other objects
• Program in ANSI standard C/C++ and Fortran
• Unified compiler generates x86 & coprocessor instructions
• Seamless debugging environment for Intel & coprocessor code
• Executable can run on x86_64 nodes or on Convey Hybrid-Core nodes

swallach - April 2009 - HPC Users Forum
13
Where we are
• Shipping Beta– Bioinformatics, seismic, speech processing,
architectural simulation, etc
• 35 People
• Production Summer 2009
• Expanding sales, service, manufacturing

swallach - April 2009 - HPC Users Forum
14





























