Embed Size (px)
Citation preview

Convex Demixing¦
Sharp Thresholds for Recovering Superimposed Signals
Joel A. TroppMichael B. McCoy
Computing + Mathematical Sciences
California Institute of Technology
Research supported in part by ONR, AFOSR, DARPA, and the Sloan Foundation 1
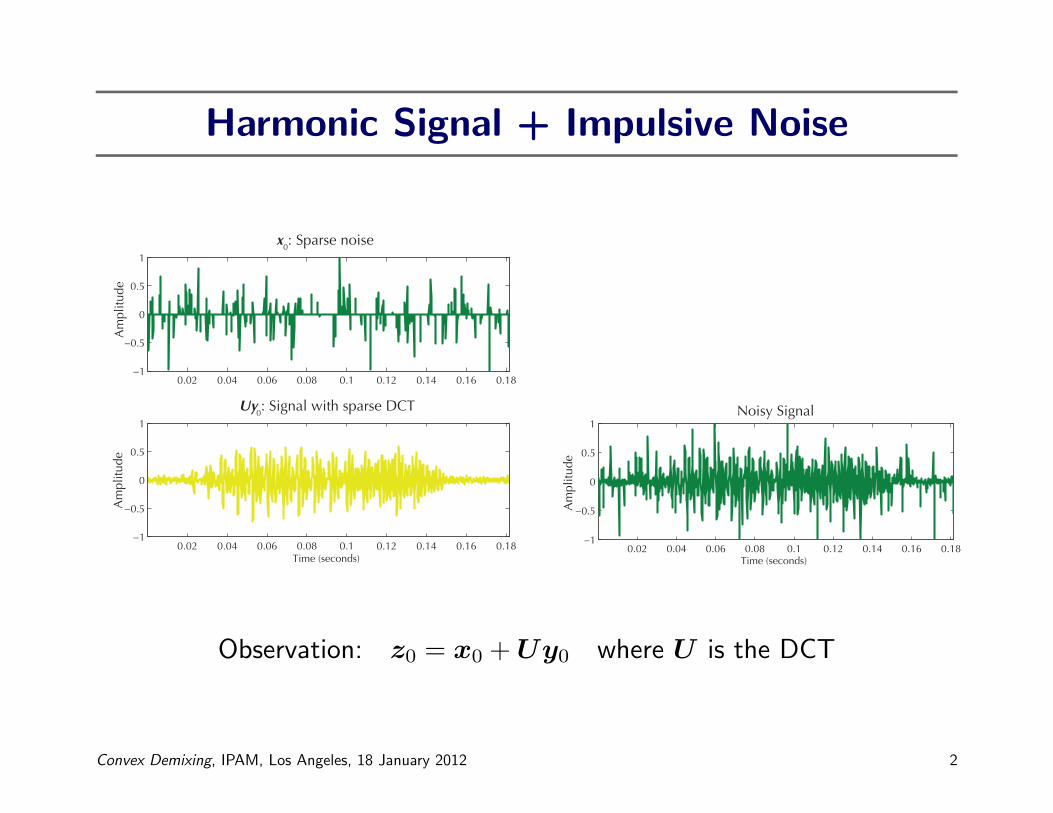
Harmonic Signal + Impulsive Noise
0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16 0.18−1
−0.5
0
0.5
1
Time (seconds)
axis([A(1:2),1,1]);
Uy0: Signal with sparse DCT
0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16 0.18−1
−0.5
0
0.5
1
x0: Sparse noise
Am
plitu
deA
mpl
itude
0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16 0.18−1
−0.5
0
0.5
1 Noisy Signal
Am
plitu
deTime (seconds)
Observation: z0 = x0 +Uy0 where U is the DCT
Convex Demixing, IPAM, Los Angeles, 18 January 2012 2
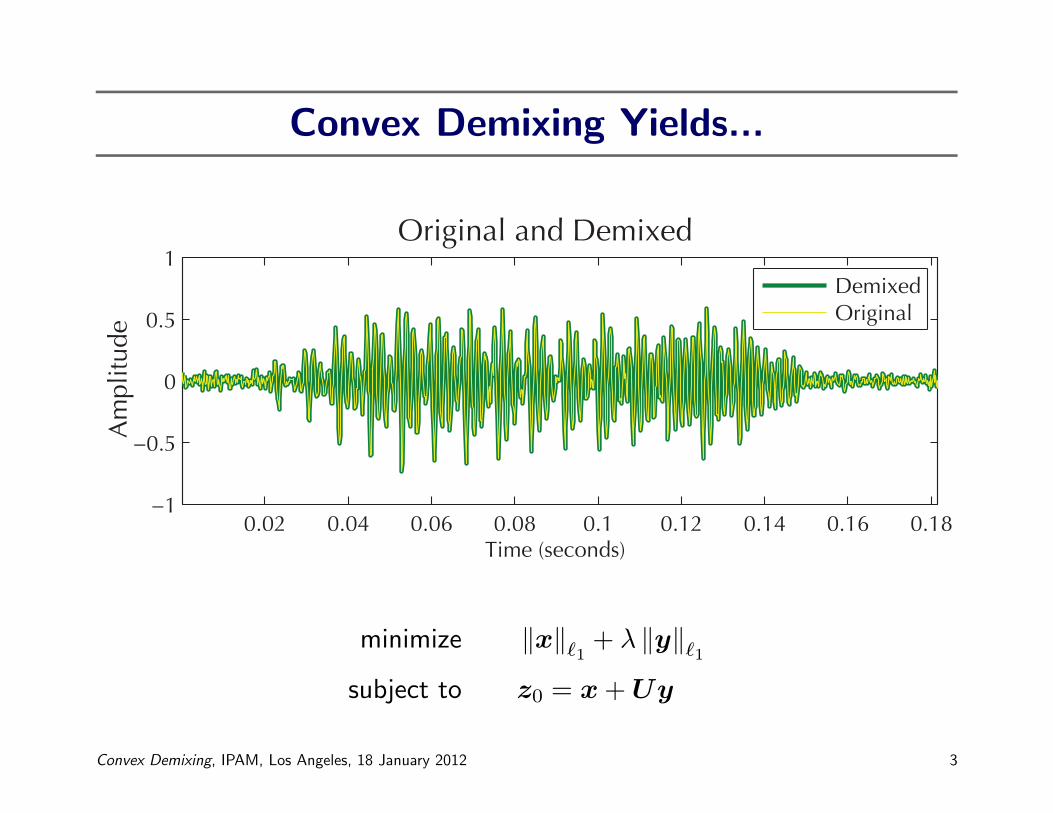
Convex Demixing Yields...
0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16 0.18−1
−0.5
0
0.5
1Original and Demixed
Time (seconds)
DemixedOriginal
Am
plitu
de
minimize ‖x‖`1 + λ ‖y‖`1subject to z0 = x+Uy
Convex Demixing, IPAM, Los Angeles, 18 January 2012 3

Morphological Component Analysis
§ Observe z0 = x0 +Uy0
§ U is a known orthobasis; x0 and y0 are unknown vectors
§ To identify this model, we can assume
§ [Structure] The vectors x0 and y0 are sparse
§ [Incoherence] Columns of U are weakly correlated with std basis
§ Perform demixing using convex optimization:
minimize ‖x‖`1 + λ ‖y‖`1subject to z0 = x+Uy
§ Application: Astronomical image processing
[Refs] Starck et al. (2003), Starck et al. (2005)
Convex Demixing, IPAM, Los Angeles, 18 January 2012 4

Rank–Sparsity Decomposition
§ Observe matrix Z0 = X0 + Y0
§ To make this model identifiable, we can assume
§ [Structure] Matrix X0 is low rank and Y0 is sparse in std basis
§ [Incoherence] Singular vectors of X0 uncorrelated with std basis
§ Perform demixing using convex optimization:
minimize ‖X‖S1 + λ ‖Y ‖`1subject to Z0 = X + Y
§ Application: Identifying latent variables in graphical models
[Refs] Chandrasekaran et al. (2009), Candes et al. (2010)
Convex Demixing, IPAM, Los Angeles, 18 January 2012 5
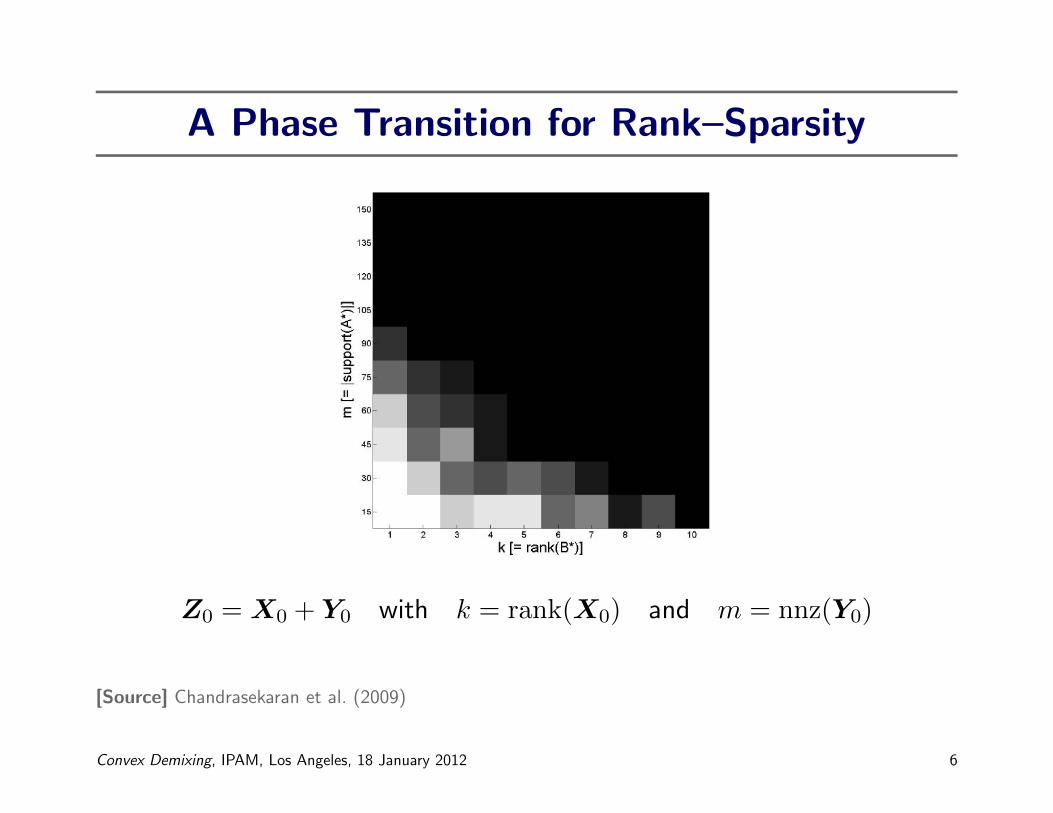
A Phase Transition for Rank–Sparsity
Z0 = X0 + Y0 with k = rank(X0) and m = nnz(Y0)
[Source] Chandrasekaran et al. (2009)
Convex Demixing, IPAM, Los Angeles, 18 January 2012 6

Examples of Structural Penalties
Structure Structural Penalty
Sparse vector `1 norm
Sign vector `∞ norm
Low-rank matrix S1 norm
Orthogonal mtx S∞ norm
§ Many, many others!
[Refs] DeVore & Temlyakov (1996), Temlyakov (2003), Chandrasekaran et al. (2010)
Convex Demixing, IPAM, Los Angeles, 18 January 2012 7
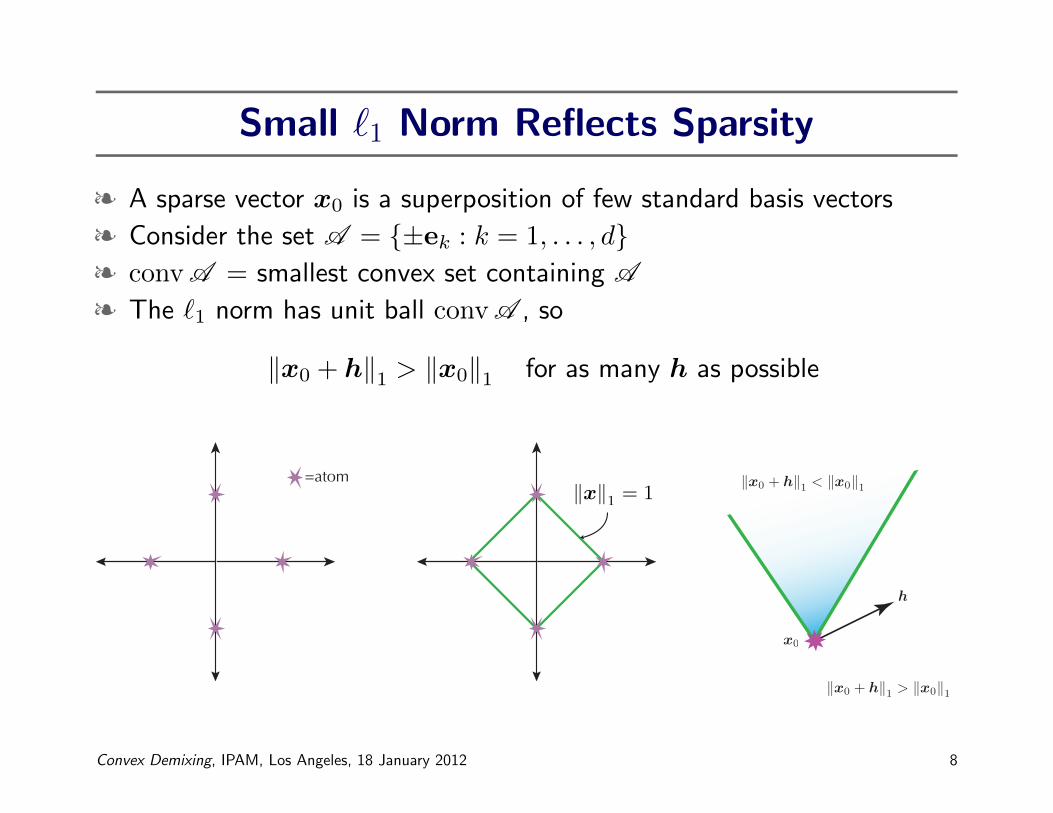
Small `1 Norm Reflects Sparsity
§ A sparse vector x0 is a superposition of few standard basis vectors
§ Consider the set A = {±ek : k = 1, . . . , d}§ convA = smallest convex set containing A
§ The `1 norm has unit ball convA , so
‖x0 + h‖1 > ‖x0‖1 for as many h as possible
=atom
Convex Demixing, IPAM, Los Angeles, 18 January 2012 8
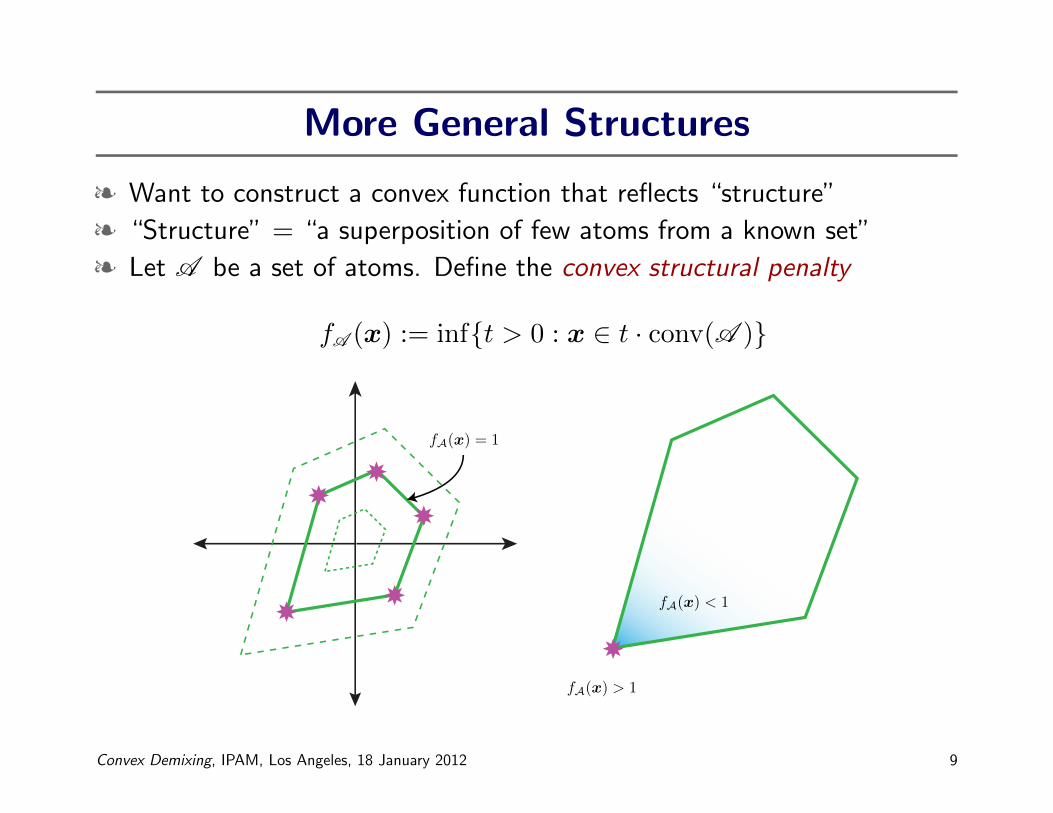
More General Structures
§ Want to construct a convex function that reflects “structure”
§ “Structure” = “a superposition of few atoms from a known set”
§ Let A be a set of atoms. Define the convex structural penalty
fA (x) := inf{t > 0 : x ∈ t · conv(A )}
fA(x) = 1
fA(x) < 1
fA(x) > 1
Convex Demixing, IPAM, Los Angeles, 18 January 2012 9

Examples of Structural Penalties, Redux
Structure Dictionary Penalty
Sparse vector A = {±ei : i = 1, . . . , d} `1 norm
Sign vector A = {±1}d `∞ norm
Low-rank matrix A = {unit norm, rank-one mtx} S1 norm
Orthogonal mtx A = {orthogonal mtx} S∞ norm
§ Every set of atoms gives a convex structural penalty!
§ Not all convex penalties lead to tractable optimization problems...
[Refs] DeVore & Temlyakov (1996), Temlyakov (2003), Chandrasekaran et al. (2010)
Convex Demixing, IPAM, Los Angeles, 18 January 2012 10

An Abstract Demixing Problem
§ Let x0 and y0 be structured vectors with convex penalties f and g
§ Let U be a known orthogonal matrix
§ Observe z0 = x0 +Uy0
§ We pose the convex demixing method
minimize f(x)
subject to g(y) ≤ α and z0 = x+Uy
where α = g(y0) is side information
§ Hope: The pair (x0,y0) is the unique solution
Convex Demixing, IPAM, Los Angeles, 18 January 2012 11
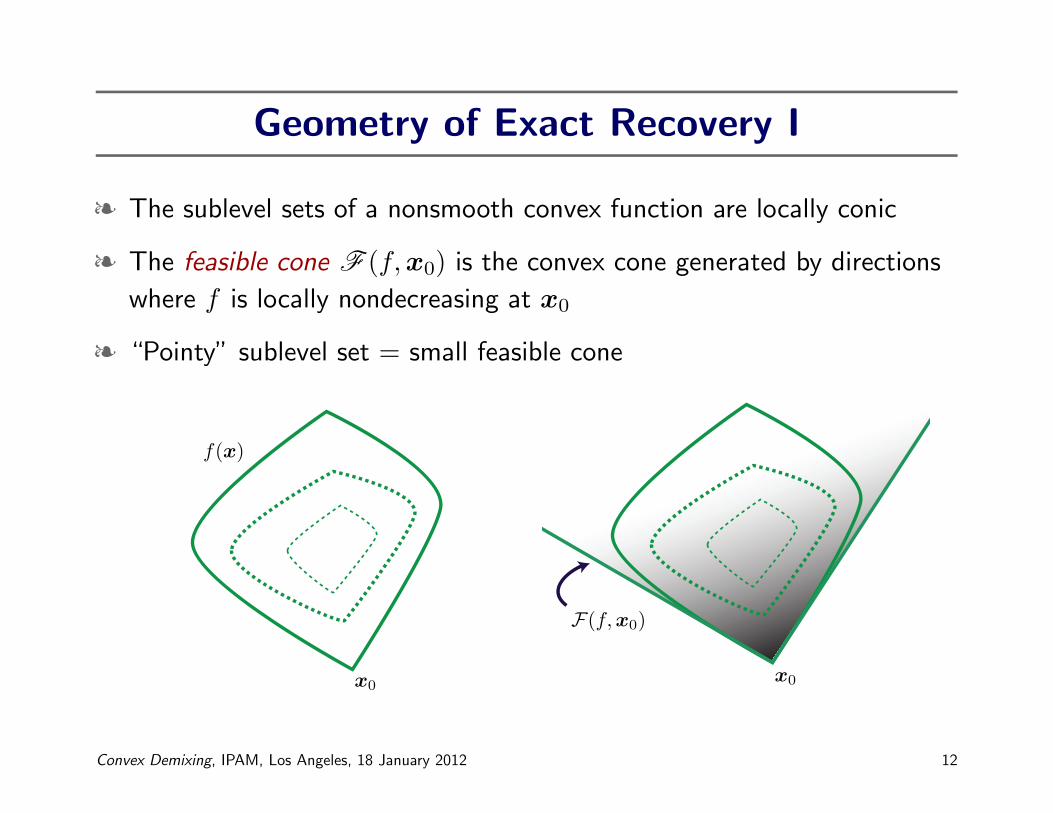
Geometry of Exact Recovery I
§ The sublevel sets of a nonsmooth convex function are locally conic
§ The feasible cone F (f,x0) is the convex cone generated by directions
where f is locally nondecreasing at x0
§ “Pointy” sublevel set = small feasible cone
x0
f(x)
F(f, x0)
x0
Convex Demixing, IPAM, Los Angeles, 18 January 2012 12
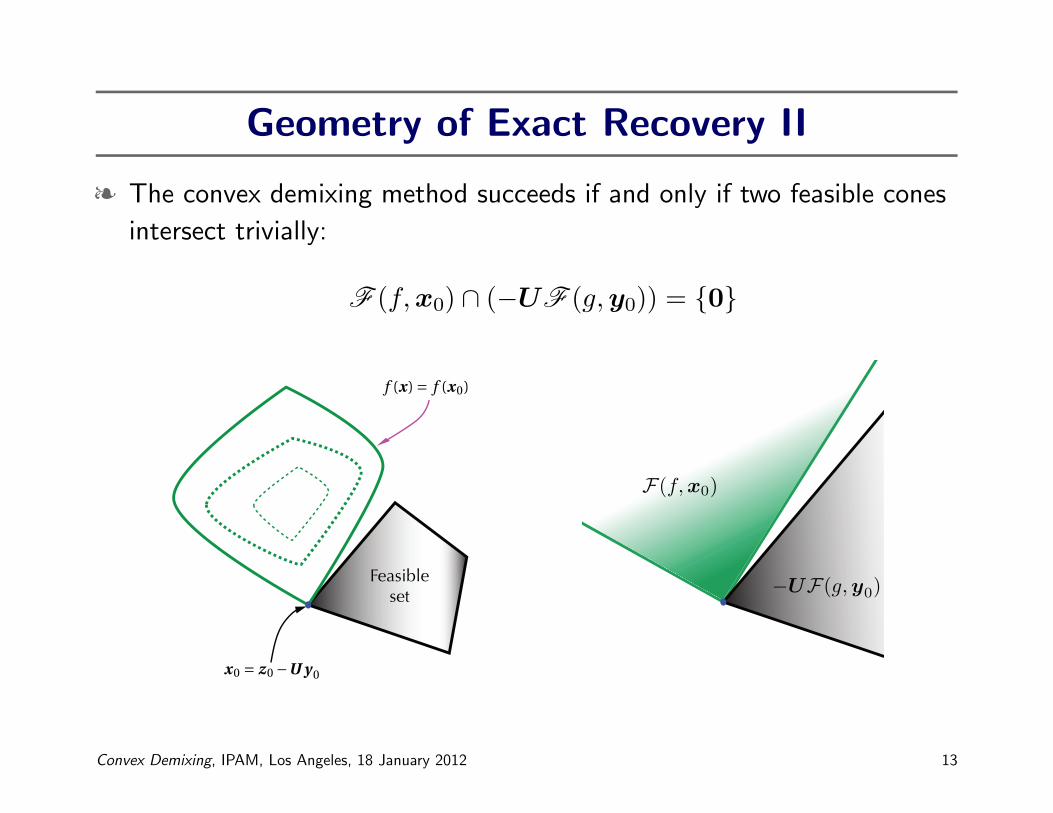
Geometry of Exact Recovery II
§ The convex demixing method succeeds if and only if two feasible cones
intersect trivially:
F (f,x0) ∩ (−UF (g,y0)) = {0}
x0 = z0 −U y 0
f (x) = f (x0)
Feasibleset
F(f, x0)
−UF(g, y0)
Convex Demixing, IPAM, Los Angeles, 18 January 2012 13

A Randomized Model for Incoherence
§ We want to study the case where signal structures are oblique
§ Idea: Use a random model for incoherence
§ Let Q be a uniformly random orthogonal matrix, and we observe
z0 = x0 +Qy0
§ Convex demixing succeeds if and only if
F (f,x0) ∩ (−QF (g,y0)) = {0}
[Refs] Donoho & Stark (1989), Donoho & Huo (2001)
Convex Demixing, IPAM, Los Angeles, 18 January 2012 14

The Spherical Kinematic Formula
§ Need to study when two randomly oriented cones strike
§ There is an exact expression for this quantity!
Spherical Kinematic Formula
Let K and K be closed convex cones, one of which is not a subspace
P{K ∩QK 6= {0}
}=
d∑j=0
(1 + (−1)j+1)
d∑i=j
vi(K) · vd−i+j(K)
where vi is the ith spherical intrinsic volume for i = 0, 1, . . . , d
[Refs] Allendorfer & Weil (1943), Glasauer (1996)
Convex Demixing, IPAM, Los Angeles, 18 January 2012 15

Spherical Intrinsic Volumes
§ The spherical intrinsic volumes vi are measures of content for cones
§ Let K be a polyhedral cone. Define
vi(K) := P{
ΠK(ω) lies inside an i-dimensional face of K
}§ ΠK is the Euclidean projection of a point onto the cone K
§ ω is a standard Gaussian vector
§ In non-polyhedral case, define vi by approximating with polyhedral cones
[Refs] Glasauer (1996), Schneider & Weil (2008), Amelunxen (2011)
Convex Demixing, IPAM, Los Angeles, 18 January 2012 16

Example: The Nonnegative Orthant
Rd+ := {x ∈ Rd : xi ≥ 0}
§ Up to rotation, the orthant is the feasible cone of `∞ at a sign vector
§ The projection of x onto the orthant satisfies (Π+(x))i = max{xi, 0}§ The i-dimensional faces contain vectors with exactly i positive entries
vi(Rd+) = P{Π+(ω) lies inside an i-dim. face of Rd+
}= P {ω has exactly i positive entries} = 2−d
(d
i
)§ For the normalized index θ = i/d, the normalized intrinsic volume
d−1 log vi(Rd+)→ H(θ)− log(2) where H = bit entropy
Convex Demixing, IPAM, Los Angeles, 18 January 2012 17
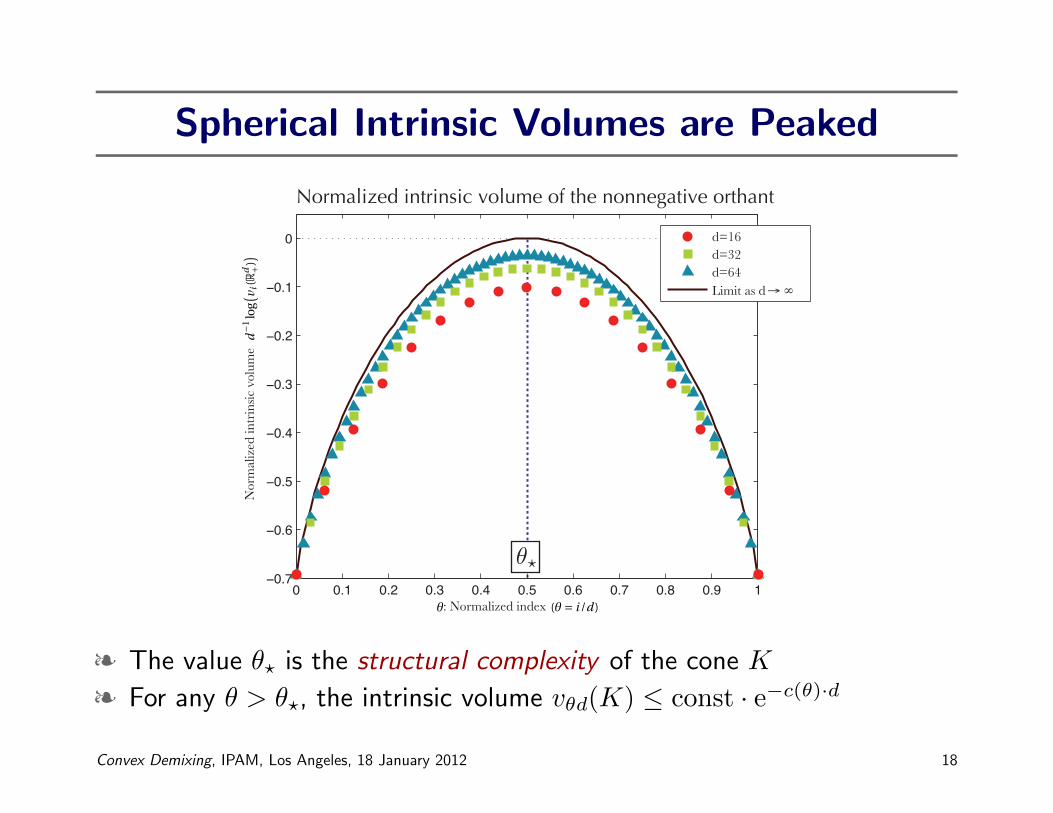
Spherical Intrinsic Volumes are Peaked
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1−0.7
−0.6
−0.5
−0.4
−0.3
−0.2
−0.1
0
Nor
mal
ized
intr
insi
c vo
lum
e
Normalized intrinsic volume of the nonnegative orthant
d=16d=32d=64Limit as d → ∞
: Normalized index θ (θ = i / d )
d−1
log
v i(R
d +)
§ The value θ? is the structural complexity of the cone K
§ For any θ > θ?, the intrinsic volume vθd(K) ≤ const · e−c(θ)·d
Convex Demixing, IPAM, Los Angeles, 18 January 2012 18

Examples of Structural Complexity
Structure Penalty Parameter Structural Complexity
Subspace Indicator σ = subspace dimambient dim θ? = σ
Sparse vector `1 norm τ = sparsitydimension θ? = ϕ(τ)
Sign vector `∞ norm — θ? =12
Square, low-rank S1 norm ρ = rankside length θ? ≤ 6ρ− 5ρ2
Orthogonal mtx S∞ norm — θ? ≤ 34
Structural complexity = “dimension” of cone / ambient dimension!
Convex Demixing, IPAM, Los Angeles, 18 January 2012 19

Demixing of Structured Incoherent Signals
Theorem 1. Suppose that
§ x0 and y0 are structured signals with convex penalties f and g;
§ Q is a uniformly random orthobasis;
§ We observe z0 = x0 +Qy0 and side information α = g(y0);
§ The structural complexities satisfy
θ?(f,x0) + θ?(g,y0) < 1.
Then, w.h.p. over Q, the pair (x0,y0) is the unique solution to
minimize f(x)
subject to g(y) ≤ α and z0 = x+Qy.
Conversely, if θ?(f,x0) + θ?(g,y0) > 1, the optimization fails w.h.p.
Convex Demixing, IPAM, Los Angeles, 18 January 2012 20
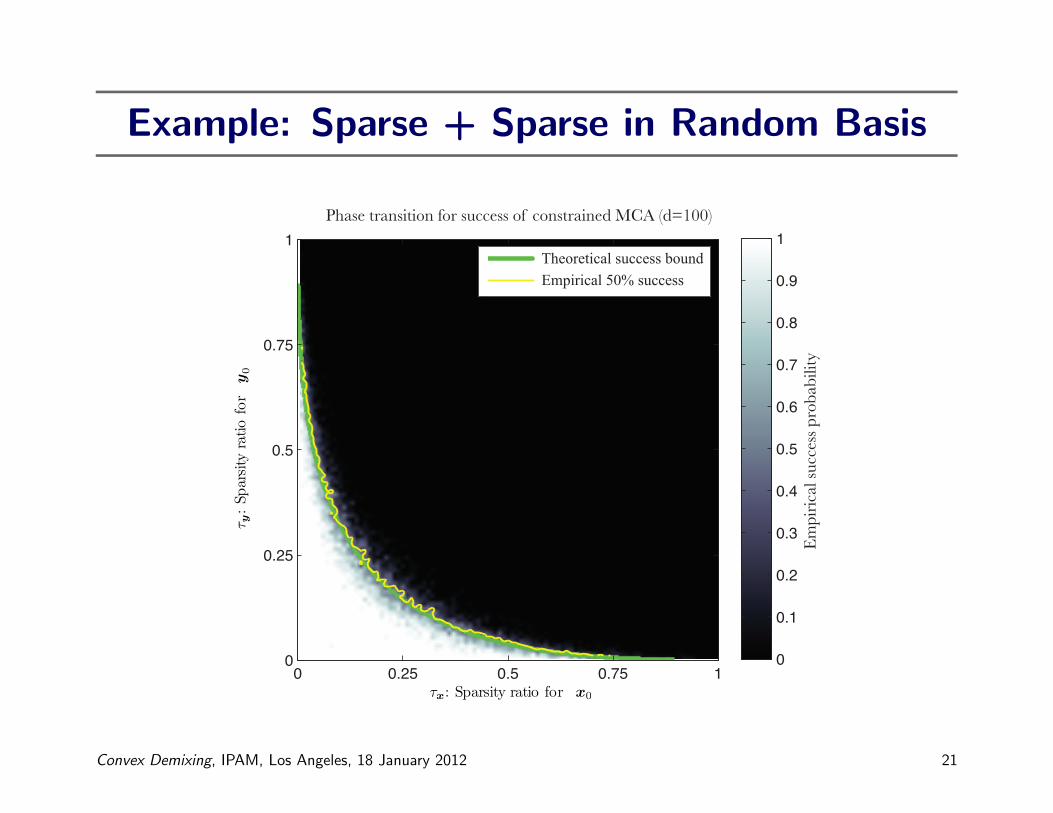
Example: Sparse + Sparse in Random Basis
0 0.25 0.5 0.75 10
0.25
0.5
0.75
1
Em
piri
cal s
ucce
ss p
roba
bilit
y
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Theoretical success boundEmpirical 50% success
Phase transition for success of constrained MCA (d=100)
τx : Sparsity ratio for x 0
τ y:Sp
arsity
ratio
for
y0
Convex Demixing, IPAM, Los Angeles, 18 January 2012 21
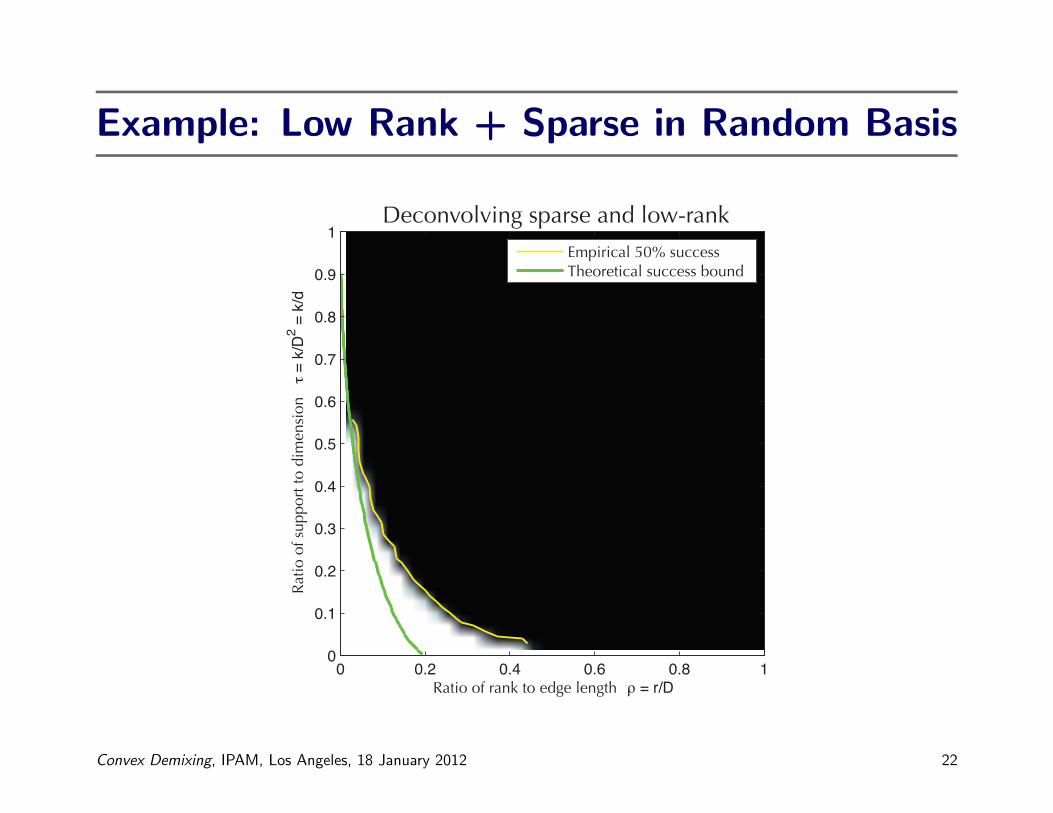
Example: Low Rank + Sparse in Random Basis
Ratio of rank to edge length ρ = r/D
Ratio
of s
uppo
rt to
dim
ensi
on τ =
k/D2 =
k/d
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Empirical 50% successTheoretical success bound
Deconvolving sparse and low-rank
Convex Demixing, IPAM, Los Angeles, 18 January 2012 22

Example: Spread-Spectrum Communications
§ Want to transmit a binary message m0 ∈ {±1}d§ Modulate with a random matrix Q, known at transmitter and receiver
§ Receiver observes
z0 = Qm0 + c0
where c0 is a sparse corruption
§ Decode using convex demixing method
minimize ‖c‖`1subject to ‖m‖`∞ ≤ 1 and z0 = Qm+ c
§ When does the receiver correctly identify the true message?
[Refs] Wyner (1979), Donoho & Huo (2001)
Convex Demixing, IPAM, Los Angeles, 18 January 2012 23
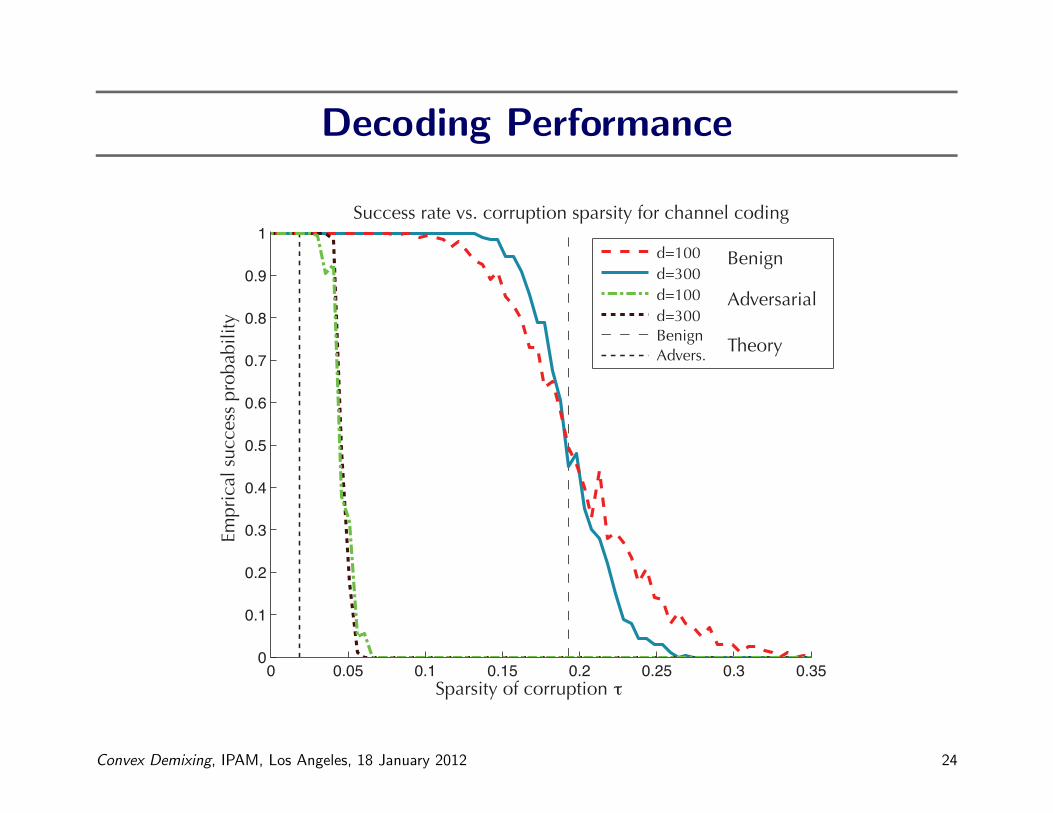
Decoding Performance
0 0.05 0.1 0.15 0.2 0.25 0.3 0.350
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Sparsity of corruption τ
Empr
ical
suc
cess
pro
babi
lity
Success rate vs. corruption sparsity for channel coding
d=100d=300
Benign
d=100d=300
Adversarial
BenignAdvers. Theory
Convex Demixing, IPAM, Los Angeles, 18 January 2012 24

To learn more...
E-mail: [email protected]
Web: http://users.cms.caltech.edu/~mccoy
http://users.cms.caltech.edu/~jtropp
Papers:
§ MT, “Sharp recovery bounds for convex deconvolution, with applications.” arXiv cs.IT
1205.1580
§ More to come...
Convex Demixing, IPAM, Los Angeles, 18 January 2012 25





























