-
Contributions to Profile Monitoring andMultivariate Statistical
Process Control
James D. Williams
Dissertation submitted to the faculty of the
Virginia Polytechnic Institute & State University
in partial fulfillment of the requirements for the degree of
Doctor of Philosophyin
Statistics
Jeffrey B. Birch, Co-Chairman
William H. Woodall, Co-Chairman
Christine M. Anderson-Cook
Dan J. Spitzner
G. Geoffrey Vining
December 1, 2004
Blacksburg, Virginia
KEYWORDS: Bioassay, False Alarm Rate, Functional Data,
Heteroscedasticity,
Hotelling’s T 2 Statistic, Lack-of-Fit, Minimum Volume
Ellipsoid, Nonlinear Regres-
sion, Sample Size, Successive Differences, Vertical Density
Profile.
c© 2004 by James D. WilliamsALL RIGHTS RESERVED
-
Contributions to Profile Monitoring andMultivariate Statistical
Process Control
James D. Williams
Abstract
The content of this dissertation is divided into two main
topics: 1) nonlinear profile
monitoring and 2) an improved approximate distribution for the T
2 statistic based
on the successive differences covariance matrix estimator.
Nonlinear Profile Monitoring
In an increasing number of cases the quality of a product or
process cannot ad-
equately be represented by the distribution of a univariate
quality variable or the
multivariate distribution of a vector of quality variables.
Rather, a series of measure-
ments are taken across some continuum, such as time or space, to
create a profile. The
profile determines the product quality at that sampling period.
We propose Phase I
methods to analyze profiles in a baseline dataset where the
profiles can be modeled
through either a parametric nonlinear regression function or a
nonparametric regres-
sion function. We illustrate our methods using data from Walker
and Wright (2002)
and from dose-response data from DuPont Crop Protection.
Approximate Distribution of T 2
Although the T 2 statistic based on the successive differences
estimator has been
shown to be effective in detecting a shift in the mean vector
(Sullivan and Woodall
(1996) and Vargas (2003)), the exact distribution of this
statistic is unknown. An
accurate upper control limit (UCL) for the T 2 chart based on
this statistic depends on
knowing its distribution. Two approximate distributions have
been proposed in the
literature. We demonstrate the inadequacy of these two
approximations and derive
-
useful properties of this statistic. We give an improved
approximate distribution and
recommendations for its use.
iii
-
Acknowledgments
The first person to whom I owe an eternal debt of gratitude is
my precious wife, Gina,
who not only gave birth to two beautiful children since we moved
to Blacksburg, but
bore a disproportionate load of raising our three children while
I worked towards
finishing this degree. Since our marriage over five years ago, I
have been a full-time
graduate student. I am extremely thankful for how supportive she
has been through
these tough graduate school years.
From the beginning I knew that Dr. Jeffrey B. Birch would not
only be an
inspirational teacher and mentor, but a good friend as well.
After taking three classes
from him, I was impressed with his ability to teach and inspire
students to rise to
their potential. I have tried to pattern my own teaching style
according to his. Dr.
Birch has been like a second father to me. He puts his own work
on hold to hear my
thoughts on a moments notice. I owe him a huge debt of gratitude
for the countless
selfless hours he spend teaching me, guiding me, counselling me,
and simply listening
to me. There are too many things to thank him for than can be
adequately listed
here.
Dr. William H. Woodall has been an inspiration to me as well. At
one point
while deriving the results from Chapter 4, I asked him if he
thought it would be
alright if I used a simulation study to prove a theorem. His
response was, “You
could do that, but it would be better if you proved it
analytically.” He left it at that,
and I walked away scratching my head. It took me several months
to figure it out,
iv
-
but the analytical proof was finally completed. In addition to
inspiring me to be a
better researcher, Dr. Woodall helped me get through my final
semester at Virginia
Tech by selecting me to be supported in part by National Science
Foundation Grant
DMII-0354859.
I also thank Dr. G. Geoffrey Vining for “that hallway
conversation” during my
first semester here at Virginia Tech, which lifted my sights and
gave me a new vision
of what I can become in the statistical profession. I also thank
him for the many
hours he spent preparing my dossier for the Virginia Tech
College of Science Most
Outstanding Graduate Student Award.
During my tenure here at Virginia Tech, I counselled with many
faculty and
graduate students who greatly helped me. I thank Dr. George
Terrell for always
holding an “open door policy” and for giving many insightful
hints that lead to
big steps forward in completing my proofs. I thank Dr. J. P.
Morgan for helping
me to get started on my proofs. I also thank Mahmoud A. Mahmoud,
Landon Sego,
Willis Jensen, and Mike Joner for many insightful conversations
in our quality control
research group meetings.
Most importantly, I lift a voice of gratitude to my Heavenly
Father for hearing
and answering my many sincere prayers for help in finishing this
work. During the
more difficult days I found myself on my knees multiple times in
my graduate student
carrell pleading for help. I acknowledge the hand of divinity in
guiding my thoughts
to find solutions when my mortal mind could not.
— James D. Williams
v
-
Contents
List of Figures ix
List of Tables xi
Glossary of Acronyms xii
Common Notation xiii
1 Introduction 1
1.1 Multivariate Statistical Process Control . . . . . . . . . .
. . . . . . . 1
1.1.1 Phase I Analysis . . . . . . . . . . . . . . . . . . . . .
. . . . 1
1.1.2 Phase II Analysis . . . . . . . . . . . . . . . . . . . .
. . . . . 2
1.1.3 Research Scope . . . . . . . . . . . . . . . . . . . . . .
. . . . 3
1.2 Nonlinear Profile Monitoring . . . . . . . . . . . . . . . .
. . . . . . . 3
1.3 Distribution of the T 2 Statistic . . . . . . . . . . . . .
. . . . . . . . 4
1.4 Example of Monitoring Dose-Response Profiles . . . . . . . .
. . . . . 5
1.5 Proposals for Future Work . . . . . . . . . . . . . . . . .
. . . . . . . 5
2 Literature Review 7
2.1 Nonlinear Profile Monitoring . . . . . . . . . . . . . . . .
. . . . . . . 7
2.2 Distribution of the T 2 Statistic . . . . . . . . . . . . .
. . . . . . . . 11
vi
-
3 Nonlinear Profile Monitoring 13
3.1 Methodology . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . 13
3.1.1 Nonlinear Model Estimation . . . . . . . . . . . . . . . .
. . . 14
3.1.2 Multivariate T 2 Control Chart . . . . . . . . . . . . . .
. . . . 16
3.1.3 Control Limits . . . . . . . . . . . . . . . . . . . . . .
. . . . 19
3.1.4 Monitoring the Variance . . . . . . . . . . . . . . . . .
. . . . 21
3.1.5 Nonparametric Approach . . . . . . . . . . . . . . . . . .
. . . 22
3.2 Example . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . 23
3.3 Autocorrelation . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . 34
3.4 Discussion . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . 35
4 Distribution of the T 2 Statistic Based on the Successive
Differences
Covariance Matrix Estimator 37
4.1 The T 2 Statistic . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . 37
4.1.1 Asymptotic Marginal Distribution . . . . . . . . . . . . .
. . . 39
4.1.2 Approximate Marginal Distribution . . . . . . . . . . . .
. . . 40
4.2 Performance Comparison . . . . . . . . . . . . . . . . . . .
. . . . . . 48
4.2.1 Control Limits . . . . . . . . . . . . . . . . . . . . . .
. . . . 48
4.2.2 Simulation Study . . . . . . . . . . . . . . . . . . . . .
. . . . 49
4.3 Example . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . 52
4.4 Discussion . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . 53
4.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . 55
5 Example of Monitoring Dose-Response Profiles from High
Through-
put Screening 56
5.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . 56
5.2 Bioassay Protocol . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . 58
vii
-
5.3 Methods: Homoscedastic Case . . . . . . . . . . . . . . . .
. . . . . . 60
5.3.1 Dose-Response Model . . . . . . . . . . . . . . . . . . .
. . . . 60
5.3.2 Phase I Profile Analysis . . . . . . . . . . . . . . . . .
. . . . 61
5.3.3 Phase II Profile Monitoring . . . . . . . . . . . . . . .
. . . . 68
5.4 Proposed Methods: Heteroscedastic Case . . . . . . . . . . .
. . . . . 72
5.4.1 Phase I Profile Analysis . . . . . . . . . . . . . . . . .
. . . . 72
5.4.2 Phase II Monitoring . . . . . . . . . . . . . . . . . . .
. . . . 77
5.5 Analysis of Dose-Response Profiles . . . . . . . . . . . . .
. . . . . . 77
5.5.1 Analysis Assuming Homoscedasticity . . . . . . . . . . . .
. . 78
5.5.2 Analysis Accounting for Heteroscedasticity . . . . . . . .
. . . 85
5.6 Discussion . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . 93
6 Future Work and Conclusion 97
6.1 Profile Monitoring . . . . . . . . . . . . . . . . . . . . .
. . . . . . . 97
6.2 Distribution of T 2D,i . . . . . . . . . . . . . . . . . . .
. . . . . . . . . 98
6.3 Combining Multivariate T 2 Control Charts . . . . . . . . .
. . . . . . 100
6.3.1 A Proposed Simulation Study . . . . . . . . . . . . . . .
. . . 102
6.3.2 Discussion . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . 105
6.4 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . 106
A Appendix A: Result from Chapter 3 107
B Appendix B: Results from Chapter 4 109
B.1 Asymptotic Distribution of T 2D,i . . . . . . . . . . . . .
. . . . . . . . 109
B.2 Maximum Value of T 2D,i Statistics . . . . . . . . . . . . .
. . . . . . . 110
References 124
Vita 130
viii
-
List of Figures
3.1 Vertical Density Profile (VDP) of 24 Particleboards . . . .
. . . . . . 24
3.2 “Bathtub” Function Fit to Board 1 . . . . . . . . . . . . .
. . . . . . 26
3.3 Nonlinear Regression Parameter Estimates a1, a2, b1, b2, c,
and d by
Board for the VDP Data . . . . . . . . . . . . . . . . . . . . .
. . . . 28
3.4 The T 2 Control Charts for the VDP Data . . . . . . . . . .
. . . . . 29
3.5 Spline Fit of Board 1 and Average Spline for the VDP Data .
. . . . 31
3.6 Control Charts on Metrics . . . . . . . . . . . . . . . . .
. . . . . . . 32
4.1 Q-Q plots of empirical quantiles of the T 2D,i statistic (i
= 1 and 2)
versus a χ2(p) distribution . . . . . . . . . . . . . . . . . .
. . . . . . 40
4.2 Boxplots of T 2D,i for p = 2 and m = 5. . . . . . . . . . .
. . . . . . . . 42
4.3 Q-Q plots of empirical quantiles of the scaled T 2D,i
statistics for combi-
nations of p = 4 and m = 30, 60 . . . . . . . . . . . . . . . .
. . . . . 46
4.4 Q-Q plots of empirical quantiles of the T 2D,i statistic for
combinations
of p = 8 and m = 30, 60 . . . . . . . . . . . . . . . . . . . .
. . . . . 47
4.5 Overall Probability of a False Alarm for p = 2, 3, 4, 5 . .
. . . . . . . 50
4.6 Overall Probability of a False Alarm for p = 6, 7, 8, 9 . .
. . . . . . . 51
4.7 T 2D,i statistics and UCL values for the Quesenberry (2001)
data . . . . 53
5.1 Estimated profiles for all 44 weeks, in a trellis plot. . .
. . . . . . . . 80
5.2 Estimated profiles for all 44 weeks, overlaid. . . . . . . .
. . . . . . . 81
ix
-
5.3 Variance chart. . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . 82
5.4 Lack-of-fit chart. . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . 82
5.5 First T 2 chart for the mean profiles. . . . . . . . . . . .
. . . . . . . . 83
5.6 Second T 2 chart for the mean profiles. . . . . . . . . . .
. . . . . . . 84
5.7 Estimated in-control profiles. . . . . . . . . . . . . . . .
. . . . . . . . 85
5.8 Fitted variance profiles for all 44 weeks. . . . . . . . . .
. . . . . . . . 87
5.9 Fitted variance profiles for all 44 weeks, overlaid. . . . .
. . . . . . . 88
5.10 T 2 chart based on successive differences (a) and the MVE
(b). . . . . 89
5.11 Fitted mean profiles based on estimated weights for all 44
weeks. . . . 90
5.12 Lack-of-fit chart based on the weighted sums of squares. .
. . . . . . 91
5.13 First T 2 chart for the mean profiles, heteroscedastic case
. . . . . . . 91
5.14 Second T 2 chart for the mean profiles, heteroscedastic
case . . . . . . 92
5.15 Estimated in-control mean profiles for the analysis
assuming heteroscedas-
ticity. . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . 93
x
-
List of Tables
3.1 Estimated Parameter Values and T 2 Statistics for the VDP
Data . . . 27
4.1 The T 2D,i statistics scaled according to Sullivan and
Woodall (1996),
Mason and Young (2002), and Equation (4.6) for a data set. . . .
. . 41
4.2 The T 2D,i statistics and UCLvec values based on the
Quesenberry (2001)
data. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . 52
5.1 Estimated parameter values, Wi, LOFi, and T2D,i statistics
for the
DuPont Crop Protection data . . . . . . . . . . . . . . . . . .
. . . . 79
5.2 S2ij values for every dose and week combination of the
DuPont Crop
Protection data. . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . 95
5.3 Estimated θ1,i (Slope) values, their standard errors, and
99.88% one-
sided lower Wald confidence limit. . . . . . . . . . . . . . . .
. . . . . 96
xi
-
Glossary of Acronyms
ANSS Average Number of Samples to Signal . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . 3
ARL Average Run Length . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . 3
ATS Average Time to Signal . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . 2
GLIM Generalized Linear Model . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . 73
HDS Historical Dataset . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
HTS High Throughput Screening . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . 56
i.i.d. independent and identically distributed . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . 9
IPP Inter-profile Pooling . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
LCL Lower Control Limit . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
LOF Lack-of-fit . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
65
MCUSUM Multivariate Cumulative Sum . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . 100
MEWMA Multivariate Exponentially Weighted Moving Average . . . .
. . . . . . . . . . . 100
MSE Mean Squared Error . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . 21
MVE Minimum Volume Ellipsoid . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . 18
OD Optical Density . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
PC Percent Control . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
PE Pure Error . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
63
POX Power of x . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
73
SPC Statistical Process Control . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . 1
UCL Upper Control Limit . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
VDP Vertical Density Profile . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . 24
WNLS Weighted Nonlinear Least Squares . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . 72
xii
-
Common Notationyijk The response of replication k of the jth
dose of profile i
f(·) Nonlinear regression function for the meanX Historical
dataset matrix
βi Parameter vector for profile i
Di Matrix of derivatives of f(·) with respect to βidi The number
of doses in profile i (as in Chapter 5)
rij The number of replications in dose j of profile i
m The number of samples in the historical dataset
p The number of parameters (dimension of βi)
α The probability of a false alarm (for an individual
observation)
αoverall The probability that a control chart will have at least
one false alarm
θi Variance function parameter vector for profile i
θ̂GLIM
i Estimate of θi obtained by generalized linear models
techniques
S2ij Sample variance estimator for dose j in profile i
SP Sample (pooled) variance-covariance matrix estimator
SD Successive differences variance-covariance matrix
estimator
SIPP Intra-profile pooling variance-covariance matrix
estimator
SMV E Minimum volume ellipsoid variance-covariance matrix
estimator
T 2P,i T2i statistic based on SP
T 2D,i T2i statistic based on SD
T 2IPP,i T2i statistic based on SIPP
T 2MV E,i T2i statistic based on SMV E
T 2P T2 chart based on T 2P,i statistics
T 2D T2 chart based on T 2D,i statistics
T 2IPP T2 chart based on T 2IPP,i statistics
T 2MV E T2 chart based on T 2MV E,i statistics
MV (m, i) The maximum value of the T 2D,i statistic
F(df1, df2) The F-distribution with df1 and df2 numerator and
denominatordegrees of freedom, respectively
F(q, df1, df2) The qth quantile of an F-distribution with df1
and df2 numeratorand denominator degrees of freedom,
respectively
BETA(p1, p2) The beta distribution with first and second shape
parameters p1 andp2, respectively
BETA(q, p1, p2) The qth quantile of a beta distribution with
first and second shapeparameters p1 and p2, respectively
χ2(p) The χ2 distribution with p degrees of freedom
χ2(q, p) The qth quantile of a χ2 distribution with p degrees of
freedom
xiii
-
Chapter 1
Introduction
1.1 Multivariate Statistical Process Control
Multivariate Statistical Process Control (SPC) is a broad field
of research and ap-
plications devoted to the improvement of products and processes.
In monitoring
the quality of a product or process, quite often more than one
quality characteris-
tic is measured on each manufactured item, thus producing a
multivariate response.
These quality measurements are usually correlated with each
other. Multivariate
SPC methods are designed to account for the correlations among
the variables and
to simultaneously monitor the variables through time.
There are two phases of Multivariate SPC, Phase I and Phase II.
A successful
Phase II analysis depends on a successful Phase I analysis.
Although the two phases
are both dedicated to identifying out-of-control situations,
each phase has a unique
objective.
1.1.1 Phase I Analysis
The Phase I analysis begins with an analysis of a historical
data set (HDS) or a set of
baseline data consisting of multivariate observations taken on
the product or process
1
-
consecutively for a specified period of time. In a Phase I
analysis one seeks to identify
a stable subset of the HDS with which to estimate the in-control
mean vector and the
in-control variance-covariance matrix for use in a Phase II
analysis. Some examples
of unstable product or process conditions that one looks for are
multivariate outliers,
shifts in the mean vector, or shifts in the variance-covariance
matrix. Once out-of-
control data have been identified and eliminated, then a stable
subset of the HDS is
used to estimate in-control parameters.
When evaluating the performance of competing control charts in a
Phase I anal-
ysis, one usually sets the false alarm rates of the competing
charts to be the same
by adjusting their respective control limits. Once the competing
charts are set on
“equal footing,” then one calculates the probability of signal
for given shifts in the
mean vector or covariance matrix, or some other out-of-control
situation. The chart
that has the highest probability of signal for a given shift is
the most desirable chart.
1.1.2 Phase II Analysis
The Phase II analysis depends on the success of the Phase I
analysis in estimating
in-control mean, variance, and covariance parameters. The
estimates of the in-control
parameters become the target values in Phase II analysis control
charts. The lower
control limit (LCL) and upper control limit (UCL) also depend on
the in-control
parameter estimates. The purpose of a Phase II analysis is,
thus, continuous process
monitoring through time. Control limits are designed with the
purpose of achieving
an acceptable false alarm rate. If an out-of-control signal is
found, then assignable
causes of the signal are sought.
When evaluating the performance of competing control charts in a
Phase II analy-
sis, one usually adjusts the control limits so that the
in-control average time to signal
(ATS) of the competing charts are equal. Other similar
performance measures may
2
-
also be used, such as the average run length (ARL) or the
average number of samples
to signal (ANSS). One then calculates the ATS (or other
performance measure) value
for a given shift from control for various out-of-control
conditions. The chart that
has the lowest ATS value is the desirable chart since the
objective is quick detection
of an out-of-control situation.
1.1.3 Research Scope
The scope of the research for this dissertation will be mostly
restricted to Phase I
analyzes. Correspondingly, the performance measure employed to
evaluate competing
control charts is the probability of signal given an
out-of-control condition. In Chapter
5 we give both Phase I and Phase II profile monitoring methods
to monitor the dose-
response quality profiles of herbicides in high throughput
screening.
This research is divided into two general areas: (1) profile
monitoring and (2)
properties of the multivariate T 2 control chart based on the
successive differences
variance-covariance matrix estimator. In Chapter 2 we review
published literature on
these two topics. Chapters 3 and 4 are dedicated to developing
new statistical theory
and methodology in these two areas. Chapter 5 contains an
example of nonlinear
profile monitoring applied to dose-response bioassay data.
Chapter 6 contains a
proposal for future work.
1.2 Nonlinear Profile Monitoring
In many quality control applications, use of a single (or
several distinct) quality
characteristic(s) is insufficient to characterize the quality of
a produced item. In
an increasing number of cases, a response curve (profile), is
required. Such profiles
can frequently be modeled using linear or nonlinear regression
models. In recent
research others have developed multivariate T 2 control charts
and other methods for
3
-
monitoring the coefficients in a simple linear regression model
of a profile. However,
little work has been done to address the monitoring of profiles
that can be represented
by a parametric nonlinear regression model.
In Chapter 3 we extend the use of the T 2 control chart to
monitor the coeffi-
cients resulting from a nonlinear regression model fit to
profile data. We give four
general approaches to the formulation of the T 2 statistics and
determination of the
associated upper control limits for Phase I applications. We
also consider the use of
nonparametric regression methods and the use of metrics to
measure deviations from
a baseline profile. These approaches are illustrated using the
vertical board density
profile data presented in Walker and Wright (2002).
1.3 Distribution of the T 2 Statistic
In the historical or retrospective data analysis of Phase I,
especially with individual
observations, the choice of the estimator for the
variance-covariance matrix is crucial
to successfully detecting the presence of special causes of
variation. The traditional
estimator based on pooling all the historical observations is
not useful in detecting a
shift in the mean vector, because such a shift near the middle
of the data actually
reduces the probability that the corresponding T 2 chart will
signal. The estimator
based on successive differences is useful in detecting such
shifts, but the exact dis-
tribution for the corresponding T 2 chart statistic has not been
determined. Three
approximate marginal distributions have been proposed.
In Chapter 4, several useful properties of the T 2 statistic
based on the successive
differences estimator are demonstrated and an improved
distribution for calculating
the UCL for individual observations in a Phase I analysis is
given. This improved
method for calculating the UCL is evaluated by comparing the
estimated false alarm
rate with the desired false alarm rate. It is shown that the
proposed method achieves
4
-
a false alarm rate which is closer to the desired false alarm
rate than the competing
methods when the sample size is small. For large sample sizes,
the method based on
the asymptotic distribution is shown to be superior. We give
recommendations when
to use each.
1.4 Example of Monitoring Dose-Response Pro-
files
In pharmaceutical drug discovery and agricultural crop product
development, in vitro
bioassay experiments are used to identify promising compounds
for future research.
The reproducibility and accuracy of the bioassay is crucial to
be able to correctly dis-
tinguish between active and inactive compounds. In the case of
agricultural product
development, compound activity for a given test organism, such
as weeds, insects, or
fungi, is characterized by a dose-response curve measured from
the bioassay. These
curves determine the quality of the bioassay procedure. When
undesirable conditions
in the bioassay arise, such as equipment failure or hormetic
effects, then a bioassay
monitoring procedure is needed to quickly detect such causes. In
Chapter 5 we illus-
trate the proposed nonlinear profile monitoring methods to
monitor the variability
of assay, the adequacy of the dose-response model chosen, and
the estimated dose-
response curves for aberrant cases. We illustrate these methods
with in vitro bioassay
data from DuPont Crop Protection collected over one year.
1.5 Proposals for Future Work
The concept of combining two or more control charts into one
overall monitoring
procedure has been around for several years. The purpose of
running two or more
charts simultaneously is to leverage the strengths of each
chart. For example, one
5
-
chart may be sensitive to certain out-of-control situations and
insensitive to others,
whereas the second chart may have the opposite sensitivity
properties. The idea
is that the combination of the two charts will form an overall
procedure which has
sensitivity to both classes of out-of-control situations. It is
conjectured that the chart
combination’s loss in power to detect any specific
out-of-control situation is small
compared to the large gain in overall performance over a wider
class of problems.
As noted earlier, the purpose of a Phase I analysis is to
identify a subset of stable
data from the HDS with which to estimate the in-control mean
vector and variance-
covariance matrix. Two out-of-control situations that we seek to
find are multivariate
outliers and shifts in the mean vector. It has been shown by
Vargas (2003) that the
T 2 chart based on the minimum volume ellipsoid (MVE) mean and
covariance matrix
estimators is very effective in detecting multivariate outliers
for a Phase I analysis.
However, this chart is not very effective in detecting a shift
in the mean vector.
Sullivan and Woodall (1996) studied the performance of the T 2
chart based on the
successive difference variance-covariance matrix estimator and
found that this chart
is very effective in detecting a shift in the mean vector.
However, this chart is not
very effective in detecting a multivariate outlier.
In order to have a multivariate control chart that performs well
in both detecting
multivariate outliers and shifts in the mean vector, a new chart
that combines the
chart proposed by Vargas (2003) and Sullivan and Woodall (1996)
could be explored.
The details of how this chart is constructed are given in
Chapter 6. The design for
a simulation study is proposed to evaluate the power properties
of this new chart
compared to the Vargas (2003) chart alone, the Sullivan and
Woodall (1996) chart
alone, and the T 2 control chart based on the usual sample
variance-covariance matrix
estimator. The simulation consists of various out of control
situations and the charts
can be evaluated based on the probability of detecting the
out-of-control observations.
6
-
Chapter 2
Literature Review
2.1 Nonlinear Profile Monitoring
In SPC applications, manufactured items are sampled over time
and quality character-
istics are measured. Often a product’s quality can be determined
through measuring
several characteristics at each sampling interval. Multivariate
T 2 control charts and
other methods have been developed for this scenario. See, for
example, Fuchs and
Kenett (1998) and Mason and Young (2002). Increasingly, however,
a sequence of
measurements of one or more quality characteristics are taken
across some continuum
producing a curve or surface that represents the quality of the
item. This curve or
surface is referred to as a profile. Very little work has been
done in developing sta-
tistical process control methodology for monitoring profile
data. For an overview of
profile monitoring techniques see Woodall, Spitzner, Montgomery,
and Gupta (2004).
Profile data consist of a set of measurements with a response
variable y and one
or more explanatory variables xj, j = 1, . . . , k, which are
used to assess the quality of
a manufactured item. For example, the density profile of a
particleboard is measured
on a vertical cross-section, which reveals patterns in board
density across the depth of
the board. Another example is the estimated dose-response curve
of a manufactured
7
-
drug. Once a batch of the drug is produced, several different
doses of the drug are
administered to subjects and the responses measured. The
resultant dose-response
curve summarizes the quality of the particular batch of the
drug, indicating the maxi-
mal effective response, minimal effective response, and the rate
in which the response
changes between the two. In these examples, a single measurement
is insufficient to
adequately assess quality. Instead, a relationship between two
variables, referred to
as the profile, should be monitored over time. Profile data is
multivariate, but it is
not appropriate to apply standard multivariate control chart
methods since this leads
to overparameterization. It is more efficient to model the
structure of the data.
Profiles can take on several different functional forms,
depending on the specific
application. For many calibration problems, the profile can be
represented by a
simple linear regression model (see, e.g., Mahmoud and Woodall
(2004)). Kang and
Albin (2000) proposed two methods, including a multivariate T 2
control chart, to
monitor such profiles. Specifically, we let the subscript i
index each individual profile
(i = 1, . . . , m) in the historical Phase I data. In the simple
linear regression case, the
ith profile is modeled as
yij = βi0 + βi1xij + ²ij, (2.1)
where yij is the jth measurement (j = 1, . . . , n), ²ij is the
j
th random error, and xij is
the jth value of the explanatory variable corresponding to the
ith profile. It is assumed
that the values of xij are the same for all i. This assumption
is often reasonable since
in many engineering applications product or process profiles are
measured at fixed
values of the explanatory variable at each sampling stage. Kang
and Albin’s (2000)
multivariate T 2 chart is used to monitor simultaneously the β0,
the y-intercept, and
β1, the slope. Kim, Mahmoud, and Woodall (2003) proposed an
alternative approach
with better statistical properties such that individual control
charts can be used for
the y-intercept and slope independently.
8
-
In general we refer to any profile that can be modeled by the
linear regression
function
yij = βi0 + βi1xij1 + βi2xij2 + · · ·+ βikxijk + ²ij (2.2)
as a linear profile, where xijl, l = 1, . . . , k, are k
predictor variables. The predictor
variables can be the original variables themselves, any function
of the variables, or
any combination of both. In matrix notation, we let yi = [yi1,
yi2, . . . , yin]′ be the
vector of responses for profile i, βi = [βi0, βi1, . . . , βik]′
be the vector of parameters to
be monitored, x′ij = [1, xij1, xij2, . . . , xijk] be the vector
of explanatory variables for
item i, and ²i = [²i1, ²i2, . . . , ²in]′ be the corresponding
vector of random errors. After
collecting the x′ij vectors into an n× p matrix, where p = k +
1, as
Xi =
x′i1x′i2...
x′in
,
then model (2.2) can be written in matrix form as
yi = Xiβi + ²i, i = 1, . . . ,m.
We assume that Xi is the same for each profile and that the
vectors ²i are independent
and identically distributed (i.i.d.) multivariate normal random
vectors with mean
vector zero and covariance matrix σ2I.
Jensen, Hui, and Ghare (1984) proposed a control chart based on
the F -distribution
to monitor the k +1 parameters (coefficients) from a multiple
linear regression model
for Phase II applications. Given the parameter vector estimator
for item i, β̂i, and
the target parameter vector β0, one plots on their control chart
the well-known F
statistic
Fi = (β̂i − β0)′X′iXi(β̂i − β0)/(k + 1)s2i
against i, where s2i =∑n
i=1(yi − ŷ)2/(n − p). A Phase I procedure for this
generallinear case has yet to be developed.
9
-
In many cases, however, profiles cannot be well-modeled by a
linear regression
function. Walker and Wright (2002) proposed a nonparametric
approach for com-
paring profiles using additive models. Such models do not have a
specific functional
form and have no model parameters to estimate, but rather one
employs smooth-
ing techniques such as local polynomial regression or spline
smoothing to model a
profile. Nonparametric regression techniques provide great
flexibility in modeling the
response. One disadvantage of nonparametric smoothing methods is
that the subject-
specific interpretation of the estimated nonparametric curve may
be more difficult,
and may not lead the user to discover as easily assignable
causes that lead to an
out-of-control signal.
Often, however, scientific theory or subject-matter knowledge
leads to a natural
nonlinear function that well-describes the profiles. Hence, an
alternative method is
to model each profile by a nonlinear regression function. A
nonlinear profile of an
item can be modeled by the nonlinear regression model given
generally by
yij = f(xij,βi) + ²ij, (2.3)
where xij is a k× 1 vector of regressors for the jth observation
of the ith profile, ²ij isthe random error, βi is a p×1 vector of
parameters for profile i, and f(·) is a functionwhich is nonlinear
in the parameter vector βi. The random errors ²ij are assumed
to be i.i.d. normal random variables with mean zero and variance
σ2. In many
applications, there is only one regressor (k = 1), but there are
multiple parameters
to monitor (p > 1). An example of this form of the model is
the 4-parameter logistic
model, often used to model dose-response profiles of a drug,
given by
yij = Ai +Di − Ai
1 +
(xijCi
)Bi + ²ij, (2.4)
where yij is the measured response of the subject exposed to
dose xij for batch i,
i = 1, . . . , m, j = 1, . . . , d, where d is the number of
doses. In equation (2.4), we
10
-
have k = 1 and p = 4, giving four parameters to monitor, each
parameter having a
specific interpretation. For example, Ai is the upper asymptote
parameter, Di is the
lower asymptote parameter, Ci is the ED50 parameter (the dose
required to elicit a
50% response), and Bi is the rate parameter for the ith batch.
Another example is
the “bathtub” function described in Section 3.2 where the
density of particleboard is
measured across the vertical profile. Note that for any given
application, the specific
form of the nonlinear function, f , in equation (2.3) must be
specified by the user.
In Phase I analysis, we are concerned with distinguishing
between in-control con-
ditions and the presence of assignable causes so that in-control
parameters may be
estimated for further product or process monitoring in Phase II
analysis. In Chapter
3 we discuss some procedures for Phase I analysis for monitoring
items or processes
whose quality is reflected by a nonlinear profile.
2.2 Distribution of the T 2 Statistic
Multivariate SPC is prevalent in many aspects of industry and
manufacturing wher-
ever several different measures of a product or process are
taken at each sampling
stage to assess quality. A common statistical method used to
simultaneously monitor
the multiple quality characteristics is use of the Hotelling T 2
statistic.
For a retrospective Phase I analysis of an HDS the objective is
twofold: (1) to
identify and eliminate multivariate outliers, and (2) to
identify shifts in the mean
vector which might distort the estimation of the in-control mean
vector and variance-
covariance matrix. The T 2 control chart is a tool to detect
multivariate outliers and
mean shifts. The T 2 statistic one plots in the chart can be
based on the usual sample
variance-covariance matrix estimator or some other alternative.
One alternative is
the estimator based on the successive differences of observation
vectors. As shown in
both Sullivan and Woodall (1996) and Vargas (2003) the T 2
statistic based on the
11
-
successive differences variance-covariance matrix estimator is
effective in detecting
sustained step and ramp shifts in the mean vector. Sullivan and
Woodall (1996)
found that the T 2 statistic based on the usual sample
variance-covariance matrix
estimator is not only less effective in detecting a shift in the
mean vector, but as the
magnitude of the shift increased, the power to detect the shift
decreased. They found
that the sample variance-covariance matrix has the effect of
“pooling” the data all
together such that a large step shift “inflates” the variance,
thus making detection of
the shift more difficult.
Imperative to constructing any multivariate control chart is
knowing the marginal
distribution of the test statistic. The UCL of the control chart
is calculated from a
specified quantile of this marginal distribution. If the
marginal distribution of the
test statistic is unknown or untractable, then the UCL is
calculated from either an
approximate marginal distribution, where available, or from a
Monte Carlo simula-
tion. If an approximate marginal distribution is used, the
researcher should be aware
of the cases under which the approximation performs well and
when it does not.
Unfortunately, the exact small-sample marginal distribution of
the T 2 statistic
based on the successive differences variance-covariance matrix
estimator is unknown.
Two approximate marginal distributions have been proposed, one
by Sullivan and
Woodall (1996) and the other by Mason and Young (2002). Another
possible approx-
imate marginal distribution is the asymptotic distribution. In
Chapter 4 we give the
asymptotic marginal distribution and give recommendations for
its use. We propose
an improved small-sample marginal distribution and demonstrate
that the proposed
approximate distribution gives rise to UCLs that perform much
better than the other
approaches for small sample sizes. We will discuss some useful
properties of the dis-
tribution of the T 2 statistic based on the successive
differences variance-covariance
matrix estimator and compare the performance of the two
approximate distributions.
12
-
Chapter 3
Nonlinear Profile Monitoring
In Section 3.1 we give a brief review of nonlinear regression.
We introduce the multi-
variate T 2 statistic in the context of monitoring nonlinear
profiles. We then introduce
four formulations of the T 2 statistic and discuss the
determination of the UCL for the
corresponding charts. In addition, a control chart to monitor
the variance σ2 in the
context of monitoring profile data is proposed. Finally, we
discuss a nonparametric
regression approach to monitoring the profiles. In Section 3.2
we illustrate the T 2
control charts and the nonparametric approaches using the
vertical density profile
data of Walker and Wright (2002). In Section 3.3 we discuss the
effects that auto-
correlation in the error terms may have on the analysis.
Finally, in Section 3.4 we
discuss potential alternative methods and give directions for
future research topics in
nonlinear profile monitoring.
3.1 Methodology
We begin a Phase I analysis with a baseline dataset consisting
of m items sampled
over time. For each item i we observe a response yij and a set
of predictor vari-
ables xij, i = 1, . . . ,m, j = 1, . . . , n, resulting in the
quality profile for item i, i.e.,
(yi1,xi1), (yi2,xi2), . . . , (yin,xin). In this section we
develop the methodology to ana-
lyze the profiles to gain understanding of the product or
process in a Phase I setting.
13
-
3.1.1 Nonlinear Model Estimation
For simplicity of notation, we write the scalar model given in
equation (2.3) in matrix
form by stacking the n observations within each profile as yi =
(yi1, yi2, . . . , yin)′,
f(Xi, βi) = (f(xi1,βi), f(xi2,βi), . . . , f(xin,βi))′, and ²i =
(²i1,²i2, . . . ,²in)′. The vec-
tor form is then given by
yi = f(Xi,βi) + ²i, i = 1, . . . , m. (3.1)
For the nonlinear regression model given in (3.1), estimates of
βi for each sample
must be obtained. This is usually accomplished by employing the
Gauss-Newton pro-
cedure and iterating until convergence to obtain the maximum
likelihood estimates.
Specifically, for each sampling stage we define the m × p matrix
of derivatives off(Xi,βi) with respect to βi as
Di =∂f(Xi, βi)
∂βi=
∂f(xi1,βi)∂βi1
∂f(xi1,βi)∂βi2
. . . ∂f(xi1,βi)∂βip
∂f(xi2,βi)∂βi1
∂f(xi2,βi)∂βi2
. . . ∂f(xi2,βi)∂βip
......
. . ....
∂f(xin,βi)∂βi1
∂f(xin,βi)∂βi2
. . . ∂f(xin,βi)∂βip
. (3.2)
We let f(Xi, β̂
(h)
i
)=
(f(xi1, β̂
(h)
i ), f(xi2, β̂(h)
i ), . . . , f(xin, β̂(h)
i ))′
, where β̂(h)
i is the
estimate of β at iteration h and we let D̂(h)i be the matrix of
derivatives of f given
in equation (3.2) evaluated at β̂(h)
i . Then an iterative solution for β̂i is given by
β̂(h+1)
i = β̂(h)
i +(D̂i
′(h)D̂
(h)i
)−1D̂′(h)i
(yi − f(Xi, β̂(h)i )
).
Upon convergence of the algorithm, the estimated covariance
matrix of β̂i is the
estimated Fisher information matrix and is given as
ˆV ar(β̂i
)= σ̂2i (D̂
′iD̂i)
−1,
where σ̂2i =∑m
j=1(yij−f(xij, β̂i))2/(n−p) and D̂i is the derivative matrix in
equation(3.2) evaluated at the converged parameter vector estimate
β̂i. See Myers (1990, chap.
14
-
9) or Schabenberger and Pierce (2002, chap. 5) for a concise
discussion of nonlinear
regression model estimation. A more detailed treatment can be
found in Gallant
(1987) and Seber and Wild (1989).
Unlike linear regression, the small-sample distribution of
parameter estimators in
nonlinear regression is unobtainable, even if the errors ²ij are
assumed to be i.i.d.
normal random variables. Instead, asymptotic results must be
applied. Seber and
Wild (1989, chap. 12) give the asymptotic distribution of β̂i
and the necessary
assumptions and regularity conditions for the asymptotic
distribution to be obtained.
Given their assumptions and assuming that n−1D̂′iD̂i converges
to some nonsingular
matrix Ωi as n →∞, the asymptotic distribution of β̂i is given
by
√n(β̂i − βi) D−→ Np(0, σ2Ω−1i ) (3.3)
where βi is the asymptotic expected value of β̂i and Np
indicates a p-dimensional mul-
tivariate normal distribution. For practical purposes, the
distribution given by (3.3)
is incalculable since the matrix Ωi is unknown. Instead the
approximate asymptotic
distribution of β̂i is commonly used, given by
β̂i·∼ Np(βi, σ2i (D′iDi)−1). (3.4)
The standard estimator of V ar(β̂i) is σ̂2i D̂
′iD̂i. For the most traditional “in-control”
case, we have βi = β for all profiles i = 1, . . . , m, where β
is the in-control parameter
vector. Consequently, the Ωi and Di matrices are the same across
all m items since
all items have the same underlying model, f , the same x-values
are observed, and the
same values of βi. However, the D̂i matrices are not equal since
the β̂i values vary
from profile to profile.
15
-
3.1.2 Multivariate T 2 Control Chart
In order to develop the methodology to monitor nonlinear
profiles, we first consider the
general framework of the multivariate T 2 statistic. Given a
sample of m independent
observation vectors to be monitored, wi (i = 1, . . . ,m), each
of dimension p, the
general form of the T 2 statistic in Phase I for observation i
is
T 2i = (wi − w̄)′ S−1 (wi − w̄) , (3.5)
where w̄ = 1m
∑mj=1 wi and S is some estimator of the variance-covariance
matrix of
wi (Mason and Young 2002, chap. 2). We then plot the T2i
statistics, i = 1, . . . ,m,
against i in a T 2 control chart, and out-of-control signals
will be given for any T 2i value
exceeding the UCL. For determining the statistical properties of
the T 2 chart it is
usually assumed that each of the wi vectors follows a
multivariate normal distribution
with common mean vector µ and covariance matrix Σ. This
assumption is critical
to finding the marginal distribution of T 2i , as discussed in
Section 3.1.3.
In the nonlinear regression model given in equation (2.3), βi is
a p × 1 vectorof parameters that determines the curve f(Xi,βi). We
employ the multivariate T
2
statistic to assess stability of the the p parameters
simultaneously, i.e., to evaluate
the assumption βi = β, i = 1, . . . , m. We do not employ
individual control charts for
each of the p nonlinear regression parameters since this may
give misleading results
due to the built-in correlation structure of the parameter
estimators in nonlinear
regression.
Once β̂i is obtained from each sample in the baseline dataset,
we calculate the
average vector¯̂β and some corresponding estimate of the
covariance matrix, replace
wi with β̂i and w̄ with¯̂β in equation (3.5) to obtain
T 2i =(β̂i − ¯̂β
)′S−1
(β̂i − ¯̂β
). (3.6)
A large value of T 2i indicates an unusual β̂i, suggesting that
the profile for item i
16
-
is out-of-control. In contrast to the traditional use of the T 2
statistic to monitor a
multivariate quality characteristic vector, we employ the T 2
statistic to monitor the
coefficient vectors of the nonlinear regression fit to each
individual profile.
There are several choices for the estimator S. Here we discuss
the effects of four
choices and later discuss under what conditions, if any, each
should be used.
The first choice we consider for S is the sample covariance
matrix, given by
SP =1
m− 1m∑
i=1
(β̂i − ¯̂β
)(β̂i − ¯̂β
)′. (3.7)
Consequently, the T 2i statistics take on the form
T 2P,i =(β̂i − ¯̂β
)′S−1P
(β̂i − ¯̂β
).
We use the subscript “P ” to emphasize the fact that SP is the
sample variance-
covariance matrix based on pooling all the data in the HDS. We
refer to the T 2 chart
based on values of T 2P,i as the T2P chart. Use of the T
2P,i values was mentioned by
Brill (2001) in the context of monitoring nonlinear profiles of
a chemical product.
The advantage of this statistic is that it is very well
understood and widely used.
However, as was shown by Sullivan and Woodall (1996) and Vargas
(2003), a T 2
statistic based on SP is ineffective in detecting sustained
shifts in the mean vector
during the Phase I period. In fact, it was shown that as the
step shift size increased,
the power to detect the shift actually decreased.
An alternative choice of S is one based on successive
differences, proposed origi-
nally by Hawkins and Merriam (1974) and later by Holmes and
Mergen (1993). To
obtain the estimator, we define vi = β̂i+1 − β̂i for i = 1, . .
. , m − 1 and stack thetranspose of these m− 1 difference vectors
into the matrix V as
V =
v′1v′2...
v′m−1
.
17
-
The estimator of the variance-covariance matrix is
SD =V′V
2(m− 1) . (3.8)
Sullivan and Woodall (1996) showed that SD is an unbiased
estimator of the true
covariance matrix if the process is stable in Phase I. The
resulting T 2i statistics are
given by
T 2D,i =(β̂i − ¯̂β
)′S−1D
(β̂i − ¯̂β
). (3.9)
We refer to the T 2 chart based on values of T 2D,i as the T2D
chart. Sullivan and Woodall
(1996) showed that the T 2D chart was effective in detecting
both a step and ramp shift
in the mean vector during Phase I. They also showed that the T
2D,i values are invariant
to a full-rank linear transformation on the observations.
Neither SP or SD, however, directly incorporate the information
on the variation
in the regression parameter estimators from the nonlinear
regression estimation of
β̂i. Consequently, a third choice for S is to pool the m
covariance matrices resulting
from the estimation of each β̂i vector. We refer to this method
of calculating S as
intra-profile pooling (IPP). If we let D̂i be the derivative
matrix for item i evaluated
at converged parameter vector estimate β̂i, then a third
estimator of the variance-
covariance matrix is
SIPP =1
m
m∑i=1
ˆV ar(β̂i
)=
1
m
m∑i=1
σ̂2i (D̂′iD̂i)
−1. (3.10)
Consequently, the T 2 statistics are given as
T 2IPP,i =(β̂i − ¯̂β
)′S−1IPP
(β̂i − ¯̂β
), i = 1, . . . , m. (3.11)
We refer to the T 2 chart based on values of T 2IPP,i as the
T2IPP chart.
Our fourth choice for S is a robust estimator of the
variance-covariance ma-
trix known as the minimum volume ellipsoid (MVE) estimator,
first proposed by
18
-
Rousseeuw (1984). In our application of the MVE method, we find
outlier-robust es-
timates for both the in-control parameter vector and the
variance-covariance matrix
based on finding the ellipsoid with the smallest volume that
contains at least half
of the β̂i vectors, i = 1, . . . , m. The MVE estimator of β is
the mean vector of the
smallest ellipsoid, and the estimator of the variance-covariance
matrix is the sample
covariance matrix of the observations within the smallest
ellipsoid multiplied by a
constant to make the estimator unbiased for multivariate normal
data. In a simu-
lation study, Vargas (2003) studied the power properties of
several different choices
of S in the context of the T 2 statistic given in (3.5) and
found that the T 2 statistic
based on the MVE estimators of β and the variance-covariance
matrix is very pow-
erful in detecting multivariate outliers. We denote the MVE
estimators of β and the
covariance matrix by β̂MV E and SMV E, respectively. Hence, the
fourth choice of T2
is
T 2MV E,i =(β̂i − β̂MV E
)′S−1MV E
(β̂i − β̂MV E
), i = 1, . . . , m. (3.12)
We refer to the T 2 chart based on values of T 2MV E,i as the
T2MV E chart.
3.1.3 Control Limits
The distribution of the T 2i statistics for monitoring nonlinear
profiles is more complex
than in the linear profile case. Recall that the distribution of
the parameter estimators
in nonlinear regression is difficult to obtain for small sample
sizes. Instead we employ
the asymptotic distribution (as n → ∞) of β̂i, i = 1, . . . , m.
Hence, in order todetermine the marginal distribution of T 2i in
this case, we assume that the sample size,
n, from each item in the baseline data set is of sufficient size
such that the distributions
of β̂i, i = 1, . . . , m are approximately multivariate normal.
The subsequent UCLs for
the multivariate T 2 control charts are determined based on this
normality assumption.
In order to control the overall probability of a false alarm,
based on some ap-
19
-
propriate UCL, the joint distribution of the T 2i values is
required. However, these
values are correlated since¯̂β and S are used in all T 2i
statistics (i = 1, . . . , m), thus
making the joint distribution of the T 2i values difficult to
obtain. As an alternative,
Mahmoud and Woodall (2004) suggested using an approximate joint
distribution as-
suming that the T 2i statistics are independent. We let α be the
probability of a false
alarm for any individual T 2i statistic. Then the approximate
overall probability of a
false alarm for a sample of m items is given by αoverall = 1 −
(1 − α)m. Thus, fora given overall probability of a false alarm, we
use α = 1 − (1 − αoverall)1/m in thecalculation of UCLs. In their
simulation study, Mahmoud and Woodall (2004) found
that this approximation used to determine the UCLs performed
well.
As noted in Tracy, Young, and Mason (1992), Gnanadesikan and
Kettenring
(1972) suggested that for a stable process the marginal
distribution of the T 2P,i statistic
is proportional to a beta distribution, i.e.,
T 2P,im
(m− 1)2 ∼ BETA(
p
2,m− p− 1
2
).
A formal proof can be found in Chou, Mason, and Young (1999).
Note that it
is assumed that the distribution of β̂i is approximately normal,
as given in equa-
tion (3.4). Therefore, an approximate UCL is (m−1)2
mBETA(1 − α, p
2, m−p−1
2), where
BETA(1 − α, p2, m−p−1
2) is the 1 − α quantile of a beta distribution with first
and
second shape parameters p/2 and (m− p− 1)/2,
respectively.Sullivan and Woodall (1996) proposed an approximate
marginal distribution for
the T 2D,i statistic as
T 2D,im
(m− 1)2 ∼ BETA(
p
2,f − p− 1
2
), (3.13)
where f = 2(m−1)2
3m−4 . Mason and Young (2002, pp. 26-27) gave a correction to
the
distribution proposed by Sullivan and Woodall (1996), by
replacing each m in equa-
tion (4.4) with f . Hence, an approximate UCL is (f−1)2
fBETA(1− α, p
2, f−p−1
2). Our
20
-
simulation results, not shown here, showed that neither one of
these approximations
worked well in obtaining the appropriate UCL, so in our example
in Section 3.2 we
used simulation to find the appropriate UCL. In Chapter 4 we
give an approximate
distribution that yields improved UCL values.
Since the small-sample exact distribution of the T 2IPP,i
statistic is difficult to obtain
we use instead the asymptotic distribution. As proven in
Appendix A, the asymptotic
distribution is χ2(p). The asymptotic distribution of T 2IPP,i
must be used in practice
since the small-sample distribution is unknown. Hence, an
approximate UCL is χ21−α,p.
The exact marginal distribution of the T 2MV E,i statistic is
unknown and intractable.
Hence, in order to find the UCL for T 2MV E,i we used
simulation.
3.1.4 Monitoring the Variance
In addition to checking the stability of each profile in the
baseline dataset, it is
important to check the stability of the variability about each
profile. This is anal-
ogous to monitoring the process variance in the standard
univariate case. In the
case of monitoring profiles, we seek to monitor the variability
about each profile, or
the within-profile variability. Our measure of within-profile
variability is the mean
squared error (MSE) defined as MSEi =∑n
j=1(yij − ŷij)2/(n − p), where ŷij is thepredicted value of
yij based on the nonlinear regression model in equation (2.3).
Wludyka and Nelson (1997) recommended a method to monitor
variances based on
an analysis-of-means-type test utilizing S2i = MSEi. In their
paper, S2i is plotted
against i with associated lower- and upper-control limits equal
to (Lα,m,n−p)mS2 and
(Uα,m,n−p)mS2, respectively, where L and U are critical values
given in their paper
and S2 is the average of the S2i values, i = 1, . . . , m. For
large n, their approximate
upper and lower control limits are S2 ± hα,m,∞σ̂ where h is a
critical value given inNelson (1983) and σ̂ = S2
√2(m− 1)/m(n− p). The S2i statistics are plotted on
21
-
a separate control chart to monitor the variance of the error
terms and lack of fit
simultaneously with a T 2 control chart for the nonlinear
regression parameters. We
recommend use of this method when within-profile error terms are
independent. An
approach to monitor the variance when there is replication is
given in Chapter 5.
3.1.5 Nonparametric Approach
When a parametric form of a profile would be overly complex,
nonparametric proce-
dures may be more appropriate. These include fitting each
profile via some smoothing
method, such as local polynomial regression, spline smoothing,
or wavelets. Walker
and Wright (2002) give a spline-fitting approach to the vertical
density profile (VDP)
of particleboard, which we use as an illustration in Section
3.2. However, these au-
thors discussed using splines to assess variation, not to
monitor profiles in a Phase I
analysis to check for process stability. Winistorfer, Young, and
Walker (1996) illus-
trated the use of splines to model the VDP of oriented
strandboard generated from
a 32 factorial design with 3 replicates. However, their
spline-fitting method is used
in the context of comparing profiles among differing
experimental conditions, not
monitoring profiles in a Phase I or Phase II analysis.
For the case of a single explanatory variable, we denote the
nonparametric fit of
profile i by ẏij, for the corresponding value of the
explanatory variable equal to xj,
j = 1, . . . , n. The general nonparametric approach to
monitoring profiles in Phase I
analysis is to establish a “baseline” curve with which to
compare all other curves. A
natural choice of baseline profile is the average estimated
profile across all m profiles,
denoted by ỹj =∑m
i=1 ẏij/m, j = 1, . . . , n. Once a baseline curve is found,
some
appropriate distance metric can be used to measure how
“different” each individual
curve is from the baseline. Researchers at Boeing (1998, pp.
140-144) proposed the
following three metrics:
22
-
1. Mi1 = sign(ẏij∗ − ỹij∗)×maxj |ẏij − ỹij|2. Mi2 =
∑nj=1 |ẏij − ỹij|
3. Mi3 =∑n
j=1 |ẏij − ỹij|/m,
where j∗ is the value of j that produces the maximum absolute
deviation. The three
metrics, Mi1, Mi2, and Mi3, are referred to as the maximum
deviation, sum of absolute
deviations, and the mean absolute deviation, respectively.
Further, it may be of
interest to compute the absolute value of Mi1, which obviously
reflects the magnitude
of the dissimilarity between ẏij and ỹij disregarding the
direction of dissimilarity. We
denote this metric by Mi4. Other metrics are proposed in
Gardner, et. al. (1997), who
note that metrics can be defined to detect changes in profiles
resulting from particular
known process faults. One of these metrics is the sum of squared
differences between
each estimated profile and the average profile, denoted Mi5
=∑n
j=1(ẏij − ỹij)2. Fora given metric, one plots the metric value
for profile i against i (i = 1, . . . , m) and
checks for unusual observations. Researchers at Boeing (1998)
suggested using a
standard univariate I-chart on the metrics to establish control
limits. The method of
smoothing splines with several dissimilarity metrics is
illustrated in Section 3.2.
3.2 Example
To illustrate the application of the various approaches we use
the vertical density pro-
file data from Walker and Wright (2002), available at the
website http://bus.utk.edu/
stat/walker/VDP.Allstack.TXT. In the manufacture of
particleboard, the density
properties of the finished boards are quality characteristics
that are monitored through
time. It is well known that the density (in pounds per ft3) near
the core of a parti-
cleboard is much less than the density at the top and bottom
faces of a board (see
Young, Winistorfer, and Wang (1999)). The standard sampling
procedure calls for
a laser-aided density measuring device to scan fixed vertical
depths of a board and
23
-
record the density at each depth. Since the depths are fixed for
each board, we de-
note the depth xij by simply xj. Density measurements for this
dataset were taken
at depths of xj = (0.002)j inches, j = 0, 1, 2, . . . , 313.
Correspondingly, a sequence
of ordered pairs, (xi, yij), j = 1, . . . , n, results for board
i and forms a vertical density
profile (VDP) of the board. A baseline sample of twenty-four
particleboards was
measured in this way, and the twenty-four profiles are
illustrated in Figure 3.1.
Figure 3.1: Vertical Density Profile (VDP) of 24
Particleboards
0.0 0.1 0.2 0.3 0.4 0.5 0.6
3540
4550
5560
65
Depth (inches)
Den
sity
(lbs
ft3)
An approach to understand the profile variation in Phase I is a
method proposed
by Jones and Rice (1992) and discussed in Woodall, et. al.
(2004). This method is
based on principal components where each profile is represented
as an n × 1 vectorof responses and mutually orthogonal linear
combinations of the responses are found
which explain as much variation as possible. Jones and Rice
(1992) then recommended
24
-
plotting the profiles with the largest and smallest principal
component scores to give
a visual interpretation of what each principal component
represents. An example of
this method using the VDP data can be found in Woodall, et. al.
(2004). They show
that the first two principal components correspond to the level
and the flatness of
the profiles and explain 84% and 10.77% of the variation,
respectively. We strongly
recommend the use of such plots.
Young, Winistorfer, and Wang (1999) introduced a statistical
method to monitor
VDP data. With their method, one summarizes the density
measurements into three
average density measurements: one near the core and one near
each face. The three
averages are the quality characteristics that are subsequently
monitored using a stan-
dard multivariate T 2 control chart. With this method one
basically summarizes each
nonlinear profile into only three numbers with a corresponding
loss of information.
An alternative approach without such a considerable loss of
information is to
model the profiles themselves parametrically. The nonlinear
function we use to model
profile i is a “bathtub” function given by
f(xij,β) =
a1(xij − c)b1 + d xj > ca2(−xij + c)b2 + d xj ≤ c
i = 1, . . . ,m; j = 1, . . . , n, (3.14)
where β = (a1, a2, b1, b2, c, d)′. One advantage of this
nonlinear model is the inter-
pretability of the model parameters. For example, a1, a2, b1,
and b2 determine the
“flatness”, c is the center, and d is the bottom, or the “level”
of the curve. Differing
values of a1 and a2 or different values of b1 and b2 allow for
an asymmetric curve about
the center c. Other parameterizations of this model are
possible. However, reparam-
eterizing can effect the outcome of the Phase I analysis since
different parameters
can produce different T 2 statistics. A strategy one should take
is to parameterize
the model so that parameters of interest can be estimated and
monitored. For this
example, the proposed parameterization addresses the shape,
center, and symmetry
25
-
of the profiles. Figure 3.2 contains the “bathtub” function fit
to board 1 from the
VDP data.
Figure 3.2: “Bathtub” Function Fit to Board 1
0.0 0.1 0.2 0.3 0.4 0.5 0.6
4045
5055
6065
Depth (inches)
Den
sity
(lbs
ft3)
The profile of board 1 is well-modeled by this parametric fit
(R2 > 0.9999). For
each of the twenty-four boards in the baseline sample we fit the
nonlinear model
in equation (3.14), and calculated the T 2P,i, T2D,i, T
2IPP,i, and T
2MV E,i statistics based
on the β̂i values. Parameter estimates for each of the
twenty-four boards and the
corresponding T 2 statistics are given in Table 3.1. We plot the
six parameter estimates
for each of the twenty-four boards in Figure 3.3. The plots of
a1 and b1 expose a
potential outlier in board 15. The plots of a2 and b2 reveal
potential outliers in
boards 4, 18, and 24. Boards 4 and 15 also appear as potential
outliers in the plot of
d.
26
-
Table 3.1: Estimated Parameter Values and T 2 Statistics for the
VDP Data
Board â1 â2 b̂1 b̂2 ĉ d̂ T2P;i T
2D;i T
2IPP;i T
2MVE;i
1 6560 3259 5.63 4.40 45.98 0.29 2.65 1.91 2261.01 6.002 470 291
3.01 2.74 42.08 0.32 7.56 5.27 4310.54 6.973 1812 2871 3.99 5.02
47.66 0.34 5.83 7.17 11255.64 8.644 6171 15009 4.25 7.39 46.63 0.39
12.21 17.28 4084.67 1131.815 4963 2251 5.14 4.20 43.43 0.30 1.65
2.27 1031.75 2.886 4556 3758 5.28 4.72 40.13 0.30 8.49 13.03
20105.39 9.837 5542 3815 5.25 5.00 44.15 0.31 2.15 3.49 211.32
3.588 3664 2979 4.89 4.41 44.06 0.30 0.79 0.97 129.64 2.699 28041
8872 7.58 4.95 43.22 0.26 4.62 7.10 3137.89 385.0310 1640 1207 4.17
3.39 41.84 0.28 4.30 5.05 5882.99 4.6111 3492 1031 5.82 3.17 46.06
0.25 8.66 8.95 2964.00 10.0012 915 750 3.45 3.52 44.37 0.32 1.80
1.99 334.45 2.2213 989 1392 3.58 4.05 45.47 0.32 3.42 4.42 1830.18
5.1814 1474 620 4.82 3.29 42.52 0.27 3.28 4.50 3218.19 7.0415
129068 5420 12.40 3.33 45.90 0.15 21.45 22.18 2048.70 17018.9116
10166 3822 5.83 4.86 44.19 0.30 3.83 5.60 266.80 12.9317 1483 603
4.07 3.26 44.83 0.30 2.30 2.53 663.30 2.3618 31156 31069 7.70 5.94
46.46 0.27 14.55 19.75 3113.48 8221.0019 418 198 3.22 2.67 42.84
0.30 4.58 3.90 1915.40 5.1620 3207 4741 4.88 5.02 44.45 0.30 5.34
5.59 23.82 34.0021 672 773 3.37 3.37 44.46 0.31 2.64 3.42 471.33
2.7922 3520 1807 5.10 4.01 45.52 0.29 1.71 1.37 1324.44 1.7323 1979
845 4.24 3.66 45.53 0.32 4.45 4.85 1843.91 7.3824 6095 26778 5.41
6.67 44.46 0.31 9.75 10.55 416.01 6676.21
We simulated UCLs for all four of the T 2 statistics to achieve
an overall probability
of a signal equal to 0.05 for m = 24 boards. In our simulations,
we sampled from
a multivariate normal distribution of dimension six, mean vector
zero, and variance-
covariance matrix I, since the in-control performance of the
methods does not depend
on the assumed in-control parameter vector or the
variance-covariance matrix. We
repeated our simulation 200,000 times for each T 2 statistic,
giving a standard error
for the estimated control limits less than 0.0005. The four UCL
values are 14.72,
23.33, 28.22, and 65.37, for the T 2P , T2D, T
2IPP , and T
2MV E control charts, respectively.
27
-
Figure 3.3: Nonlinear Regression Parameter Estimates a1, a2, b1,
b2, c, and d byBoard for the VDP Data
5 10 15 20
040
000
1000
00
Board
a 1
5 10 15 20
010
000
2500
0
Board
a 2
5 10 15 20
46
810
12
Board
b 1
5 10 15 20
34
56
7
Board
b 2
5 10 15 20
4042
4446
Board
c
5 10 15 20
0.15
0.25
0.35
Board
d
In Section 3.1.3 we gave theoretical UCLs for the T 2P , T2D,
and T
2IPP control charts.
For m = 24 boards and p = 6 parameters, the theoretical UCLs are
14.71, 11.85,
and 20.63 for the T 2P , T2D, and T
2IPP control charts, respectively. The exact marginal
distribution of the T 2P,i statistic is known, thus the
theoretical and simulated UCL
values are very similar. On the other hand, the exact marginal
distribution of the
T 2D,i statistic is not known, so we used instead the correction
given by Mason and
Young (2002, pp. 26-27). The large difference between the
simulated and theoretical
UCL for the T 2D control chart shows that the approximate
marginal distribution is
28
-
inadequate. The UCL of the T 2IPP control chart was computed
based on the marginal
asymptotic distribution of the T 2IPP,i statistic because the
small-sample distribution
is unknown. For our VDP example, the number of samples in the
baseline dataset
is only m = 24 boards. The theoretical UCL values become more
exact as m gets
larger.
In Phase I analysis, we are interested in identifying “outlying”
or out-of-control
boards or a shift in the process which might affect the
estimation of in-control pa-
rameters. We compared the four T 2 control charts for assessing
process stability and
identifying outlying profiles. In Figure 3.4 we illustrate all
four T 2 control charts for
the VDP data.
Figure 3.4: The T 2 Control Charts for the VDP Data. (a) The T
2P control chart basedon the pooled sample covariance matrix, (b) T
2D control chart based on the successivedifferences estimator, (c)
T 2IPP control chart based on the intra-profile pooling method,and
(d) T 2MV E control chart based on the minimum volume ellipsoid,
with UCL valuesof 14.72, 23.33, 28.22, and 65.37, respectively.
5 10 15 20
05
1015
2025
(a)
Board
5 10 15 20
05
1015
2025
(b)
Board
5 10 15 20
050
0015
000
(c)
Board
5 10 15 20
050
0010
000
(d)
Board
29
-
The T 2P control chart based on the pooled sample
variance-covariance matrix esti-
mator indicates that board 15 has the only out-of-control
profile, although the profile
for board 18 is borderline. The T 2D chart based on the
successive differences estimator
does not produce an out-of-control signal. Note that the T 2D,i
statistic accentuates
the same outlying observations of the T 2P chart, but has a
larger UCL. As discussed in
Sullivan and Woodall (1996), the T 2P control chart has greater
power to detect isolated
outlying observations than the T 2D control chart based on the
successive differences
variance-covariance matrix estimator, however the T 2D chart is
better for detecting a
sustained shift in the mean vector. For this dataset, there is
no apparent sustained
shift in the regression parameter vector.
In the T 2IPP control chart based on the intra-profile pooling
variance-covariance
matrix estimator, all the T 2IPP,i statistics are above the UCL
except for board 20,
indicating that most of the profiles are significantly different
from each other in the
statistical sense. Recall that SIPP in the T2IPP,i statistic is
the average of the m
within-profile variance-covariance matrices of the β̂i vectors.
For this dataset, the
within-profile variability is much smaller than the
between-profile variability, causing
the T 2IPP,i statistics to be very large. The use of this method
is appropriate only if
there is no expected common cause variation between profiles. We
expect that in
most applications there will be some common cause variation
between profiles.
The T 2MV E control chart based on the MVE estimator indicates
that boards 4,
9, 15, 18, and 24 have outlying profiles. The most pronounced
outlier is board 15,
which the T 2P chart also indicated as the most severe outlier.
As shown by Vargas
(2003), the T 2MV E control chart is very powerful in detecting
multivariate outliers.
Investigating the table of parameter estimates for these boards,
given in Table 3.1,
it seems reasonable that the boards 15 and 18 are outliers, with
boards 4, 9, and 24
worthy of further investigation.
30
-
As discussed in Section 3.1.5, an alternative approach to
modeling the profiles
with a parametric curve is to employ nonparametric smoothing
techniques to model
the profiles. Walker and Wright (2002) employed spline smoothing
with 16 degrees of
freedom to model the twenty-four boards of the VDP data. We
replicated their spline
fits to each profile. After obtaining the spline fits to each
profile, ẏij, i = 1, . . . , m; j =
1, . . . , n, the average spline, ỹj, is calculated. For
example, the spline fit to board 1
and the average spline are illustrated in Figure 3.5.
Figure 3.5: Spline Fit of Board 1 (Above) and Average Spline
(Below) for the VDPData
0.0 0.1 0.2 0.3 0.4 0.5 0.6
4045
5055
6065
Depth (inches)
Den
sity
(lbs
ft3)
The spline fit with 16 degrees of freedom provides a concise
summary of the shape
of the profile from board 1. The average spline fit is
systematically lower than the
spline fit to board 1. In order to determine which boards are
in-control we calculated
31
-
dissimilarity metrics as given in Section 3.1.5. Since the
metrics Mi2 and Mi3 differ
only by a constant, it is not helpful to consider both metrics
simultaneously. Instead
we calculate the metrics Mi1, Mi3, Mi4, and Mi5, and then employ
an I-chart based
on the moving range to establish control limits, as suggested by
researchers at Boeing
(1998). We plot each metric versus i with associated control
limits to obtain control
charts. The four charts are given in Figure 3.6.
Figure 3.6: Control Charts on Metrics: (a) Mi1, the Maximum
Deviation, (b) Mi3,the Maximum Absolute Deviation, (c) Mi4, the Sum
of Squared Differences, and (d)Mi5, the Mean Absolute Deviation for
the VDP Data
5 10 15 20
−10
−50
510
(a)
Board
Max
imum
Dev
iatio
n
5 10 15 20
−50
510
(b)
Board
Max
imum
Abs
olut
e De
viatio
n
5 10 15 20
−200
00
2000
6000
(c)
Board
Sum
of S
quar
ed D
iffer
ence
s
5 10 15 20
−20
24
(d)
Board
Mea
n Ab
solu
te D
evia
tion
The charts based on metrics Mi1 and Mi4 both give the same
conclusion, that all
the profiles of the boards are in-control. This is not
surprising since Mi4 is the absolute
32
-
value of Mi1, but both are given for illustrative purposes. The
most extreme value
of the metrics came from board 14, with values of M14,1 = −5.79
and M14,4 = 5.79 .This value represents the maximum (absolute)
deviation of the spline fit to board 14
from the average spline fit.
Similarly, the charts based on metrics Mi3 and Mi5 both give the
same conclusion,
that the profile for board 6 is out-of-control. Referring to
Figure 3.1, board 6 is
the one with the profile that is consistently lower than all
other boards. The next
most extreme value of the two metrics is that of board 3,
although it does not give
an out-of-control signal. Again, referring to Figure 3.1, board
3 is the one with the
profile that is consistently higher than all the other boards.
It is apparent that these
two metrics measure how consistently different each profile is
from the average profile
across the depth values, whereas metrics Mi1 and Mi4 measure the
greatest extent to
which a profile is from the average at any particular depth
value. It is important to
note that the results for the control charts on the metrics
(Figure 3.6) do not show
the same results as the control charts based on the regression
estimators in Figure
3.4. If the profile can be adequately represented by a
parametric model, then this, in
general, will lead to more effective charts.
In addition to monitoring the regression parameter vectors of
the profiles in a
Phase I analysis, we should monitor the variation about the
profiles to check for
stability. As mentioned in Section 2.4, we recommend using the
methods of Wludyka
and Nelson (1997) to monitor the variance σ2. Use of their
method is appropriate
when the error terms within a profile are independent. In our
VDP example, however,
the within-profile density measurements are spatially
correlated. A more appropriate
control chart in this case to monitor the process variance σ2 is
a topic for further
research.
33
-
3.3 Autocorrelation
Engineering applications that give rise to nonlinear profile
data may lead to autocor-
related error terms. A common source of autocorrelated errors is
the spatial or serial
manner in which data are collected. The VDP data, for example,
is spatially corre-
lated because the density measurements are taken at close
intervals along the vertical
depth of the particleboard. On the other hand, some nonlinear
profiles may have
independent error terms. One example of this is typical
dose-response data where
several doses of a particular drug are administered to different
subjects and their
responses are measured. The subsequent error terms in the
nonlinear dose-response
curve are typically assumed to be independent.
When the error terms are autocorrelated due to either serial,
spatial or any other
effects, the correlation structure should be taken into account
in the analysis. Failure
to do so might yield misleading results in some cases,
particularly with the control
chart to monitor σ2. In the example of Section 3.2, we estimated
parameters of a
nonlinear regression model for each board. For our nonlinear
model we assumed that
the errors ²ij are i.i.d. For the VDP data, it may be reasonable
to assume that the
²ij are correlated. If this is the case, perhaps an alternative
approach would be to
employ either nonlinear mixed model methods or generalized
estimating equations
(GEE) methodology. Both methods can be used to estimate the mean
function, or
profile, while accounting for autocorrelation in the error
structure. A more detailed
treatment of these methods can be found in Schabenberger and
Pierce (2002) and
Hardin and Hilbe (2003). In the context of analyzing nonlinear
profiles for Phase I
applications, this approach is a topic that requires further
investigation.
34
-
3.4 Discussion
In Phase I, we are interested in identifying outlying
observations as well as identifying
step or ramp shifts in the mean vector over time. As shown by
Vargas (2003), the
robust variance-covariance matrix and mean vector estimators
employed in the T 2MV E,i
statistic are very powerful in detecting multivariate outliers,
but are not powerful in
detecting a step shift. However, the opposite is true of the T
2D,i statistic. As shown
by Sullivan and Woodall (1996), the T 2D chart is powerful in
detecting a step shift,
but not powerful in detecting multivariate outliers. One
possible alternative is to
employ both the T 2D and T2MV E charts simultaneously, the
former chart sensitive to
step shifts and the latter sensitive to outliers. However, in
examining both charts
simultaneously, one must be cautious of inflating the false
alarm probability. This
approach is also a topic for research, as discussed in Chapter
6.
We have not given a detailed treatment of the nonparametric
approaches to moni-
toring profiles discussed in Section 3.1.5. Rather, we have only
described some meth-
ods that have been proposed and then illustrated their use with
the VDP data. Some
issues that need to be addressed, for example, are the best
nonparametric estimation
technique for a given scenario, the best metrics to apply, the
strengths and weaknesses
of each metric, and the distributional properties of the metrics
in order to establish
valid control limits. It is our hope that the present work will
generate interest in
investigating these and other unresolved issues.
The field of profile monitoring using control charts has
potential to extend statis-
tical process control to a wide variety of engineering and
pharmaceutical applications.
With the increasing ease and efficiency in which processes and
products can be mea-
sured, there is a need for statistical methodology to be
developed which can accom-
modate the growing needs of industry. We have encountered a
number of engineering
applications in which a response curve is needed to assess
quality. In some cases, the
35
-
shape of the response curve can be well-represented by a
parametric nonlinear regres-
sion function. In this paper we have developed control chart
methodology to monitor
such nonlinear profiles for Phase I applications. When a profile
cannot be easily de-
scribed by a parametric function, nonparametric methods may be
applied. Our VDP
example shows, however, that the parametric and nonparametric
approaches do not
always lead to the same conclusions regarding outlying
profiles.
36
-
Chapter 4
Distribution of the T 2 StatisticBased on the
SuccessiveDifferences Covariance MatrixEstimator
4.1 The T 2 Statistic
In a Phase I analysis, we begin with an HDS consisting of m
independent vectors
of dimension p observed over time, where p is the number of
quality characteristics
that are being measured, and p < m. We make a standard
assumption that when
the process is in-control the observation vectors, xi, i = 1, .
. . , m, are independent
and identically distributed multivariate normal random vectors
with common mean
vector and covariance matrix, i.e.,
xi ∼ Np(µ,Σ).
For example, in the context of nonlinear profile monitoring
discussed in Chapter 3,
each xi is equal to β̂i, i = 1, . . . , m. It is useful to
define the m× p HDS matrix X as
X =
x′1x′2...
x′m
.
37
-
The Hotelling’s T 2 statistic measures the Mahalanobis distance
of the correspond-
ing vector from the sample mean vector. The general form of the
statistic is
T 2i = (xi − x̄)′ S−1 (xi − x̄) ,
where x̄ = 1m
∑mi=1 xi and S is some estimator of Σ.
A common choice for S is the sample variance-covariance
estimator given by
SP =1
m− 1m∑
i=1
(xi − x̄) (xi − x̄)′ .
The T 2 statistics based on SP are then
T 2P,i = (xi − x̄)′ S−1P (xi − x̄) , i = 1, 2, . . . , m
(4.1)
As shown in Chapter 3, the exact distribution of T 2P,i is
proportional to a beta distri-
bution, i.e.,
T 2P,im
(m− 1)2 ∼ BETA(
p
2,m− p− 1
2
); i = 1, . . . , m. (4.2)
An alternative choice of S is one based on SD of Equation (3.8),
where β̂i is
replaced with xi. The resulting T2 statistics based on SD are
given by
T 2D,i = (xi − x̄)′ S−1D (xi − x̄) . (4.3)
As noted in Sullivan and Woodall (1996), Holmes and Mergen
(1993) incorrectly
specify the Phase I UCL of a T 2 chart based on T 2D,i
statistics by applying con-
trol limits based on a Phase II analysis. Sullivan and Woodall
(1996) proposed an
approximate distribution for T 2D,i as
T 2D,im
(m− 1)2 ∼ BETA(
p
2,f − p− 1
2
), (4.4)
where f = 2(m−1)2
3m−4 . Mason and Young (2002, pp. 26-27) suggested an adjustment
to
this approximation, replacing each m in Equation (4.4) with











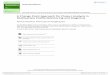


![INDEX [pandorafms.com] · MONITORING SAP&Security&Monitoring& SAP"ALL"user"profile"control."An"email"will"be"fired"if" the"user"assigns"themselves"to"this"cri9cal" authorizaon"profile."](https://img.pdfslide.us/doc/110x75/6011896876780c683854f579/index-monitoring-sapsecuritymonitoring-sapalluserproilecontrolanemailwillbeiredif.jpg)














